













Используя Amazon Aurora уже некоторое время в различных компаниях, я видел на собственном опыте, насколько он отличается как полностью управляемый реляционный движок базы данных, предлагая высокую производительность, масштабируемость и надежность.
Как облачное решение, которое поддерживает MySQL и PostgreSQL, Aurora отличный выбор для компаний, которым требуется высокая доступность и автоматическое масштабирование. Поскольку AWS автоматически управляет резервными копиями, отказоустойчивостью и репликацией, использование Aurora позволяет повысить эффективность базы данных, снизив при этом затраты на обслуживание.
В этом руководстве я проведу вас через настройку экземпляра Aurora, эффективное управление им, оптимизацию производительности, а также обеспечение безопасности и экономичности.
Что такое AWS Aurora?
Amazon Aurora – это облачная реляционная база данных, которая превосходит традиционные MySQL и PostgreSQL за счет динамического масштабирования хранилища и вычислительных ресурсов.
Согласно AWS, Aurora способна обеспечить до пяти раз большую пропускную способность по сравнению со стандартным MySQL и в три раза большую производительность по сравнению со стандартным PostgreSQL благодаря своей распределенной и высокодоступной архитектуре.
Aurora построена с функциями, такими как автоматические резервные копии, репликация для горизонтального масштабирования и механизмы аварийного восстановления, обеспечивающие минимальное время простоя.
Слой хранения Aurora спроектирован таким образом, чтобы быть устойчивым к сбоям и самовосстанавливающимся.
Кроме того, данные автоматически реплицируются в нескольких доступных зонах (AZ) для обеспечения надежности.
На изображении ниже представлен обзор архитектуры и основных особенностей Amazon Aurora.
Отношения между объемом кластера, основным экземпляром БД-писателем и экземплярами БД-читателями в кластере Aurora. Источник: Документация AWS
Движок базы данных непрерывно отслеживает запросы и оптимизирует планы выполнения, что приводит к значительному улучшению эффективности.
Одним из ключевых преимуществ Aurora является его совместимость с существующими базами данных MySQL и PostgreSQL, что упрощает процесс миграции для бизнеса, не требуя значительной модификации приложений.
Также привлекательной является структура расходов Aurora. Оплата производится на основе реального использования вычислительных и ресурсов хранения. Эта модель расходов позволяет избежать избыточного выделения ресурсов, что в конечном итоге экономит деньги.
> Если вас интересует более широкое понимание опций хранения в AWS, перейдите к этому руководству по хранилищам AWS.
Настройка AWS Aurora
Настройка AWS Aurora включает в себя создание кластера базы данных, конфигурацию параметров безопасности и обеспечение надлежащего сетевого доступа. Давайте сделаем это в этом разделе!
> Если вы новичок в AWS, рассмотрите возможность изучения основных тем в курсеВведение в AWS перед тем, как погружаться в Aurora.
Создание кластера базы данных Aurora
Настройка кластера базы данных Aurora требует выполнения нескольких ключевых шагов, включая выбор подходящего движка базы данных, конфигурацию параметров безопасности и определение характеристик экземпляра.
- Чтобы начать, войдите в консоль управления AWS и перейдите на панель инструментов RDS (Служба реляционных баз данных).
- Вы можете сделать это, выполнив поиск по запросу “Aurora” в панели поиска консоли управления AWS – как показано на изображении ниже.
- Как только вы окажетесь там, нажмите на “Создать базу данных” – как показано на изображении ниже.
- Затем у вас будет возможность выбрать “Amazon Aurora” в качестве движка базы данных.
- Помните, что Aurora поддерживает как MySQL, так и PostgreSQL, поэтому важно выбрать версию, которая лучше всего соответствует требованиям вашего приложения.
На изображении ниже показаны доступные в настоящее время варианты движков. Они могут измениться в будущем, но первые два варианта – Aurora (совместимый с MySQL) и Aurora (совместимый с PostgreSQL) – являются движками Aurora.
- После выбора движка необходимо указать тип экземпляра и конфигурации хранения.
- Aurora обеспечивает гибкость автоматического масштабирования хранилища до 128 ТБ, гарантируя эффективную обработку растущих рабочих нагрузок без необходимости вручную вмешиваться.
- Следующим шагом является определение настроек репликации. Вы можете выбрать развертывание с одним экземпляром или включить чтение реплик для более эффективного распределения трафика базы данных.
- Использование реплик для чтения также повышает доступность и устойчивость к отказам, что обеспечивает более высокую надежность в случае сбоев.
На приведенном ниже изображении выделен раздел “Доступность и безопасность”, где можно настроить эти параметры.
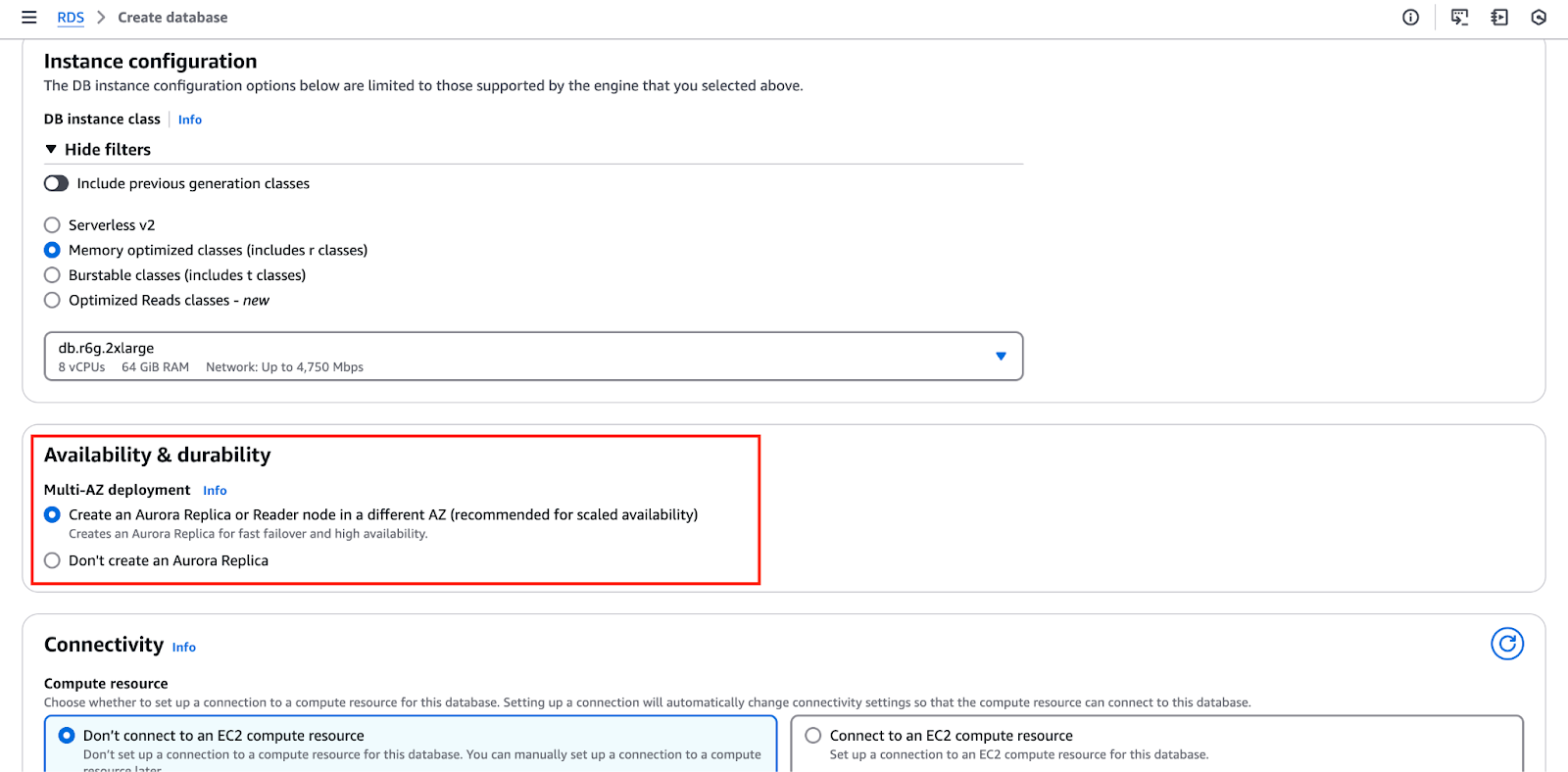
- Этап настройки сети критичен, так как он включает настройку Виртуального частного облака (VPC), выбор группы безопасности и определение контроля доступа.
- Группа безопасности действует как брандмауэр, регулирующий входящий и исходящий трафик базы данных. Для улучшения безопасности рекомендуется разрешать доступ только с доверенных IP-адресов и приложений.
На изображении ниже выделен раздел “Подключение”, где вы можете настроить и настроить эти конфигурации.
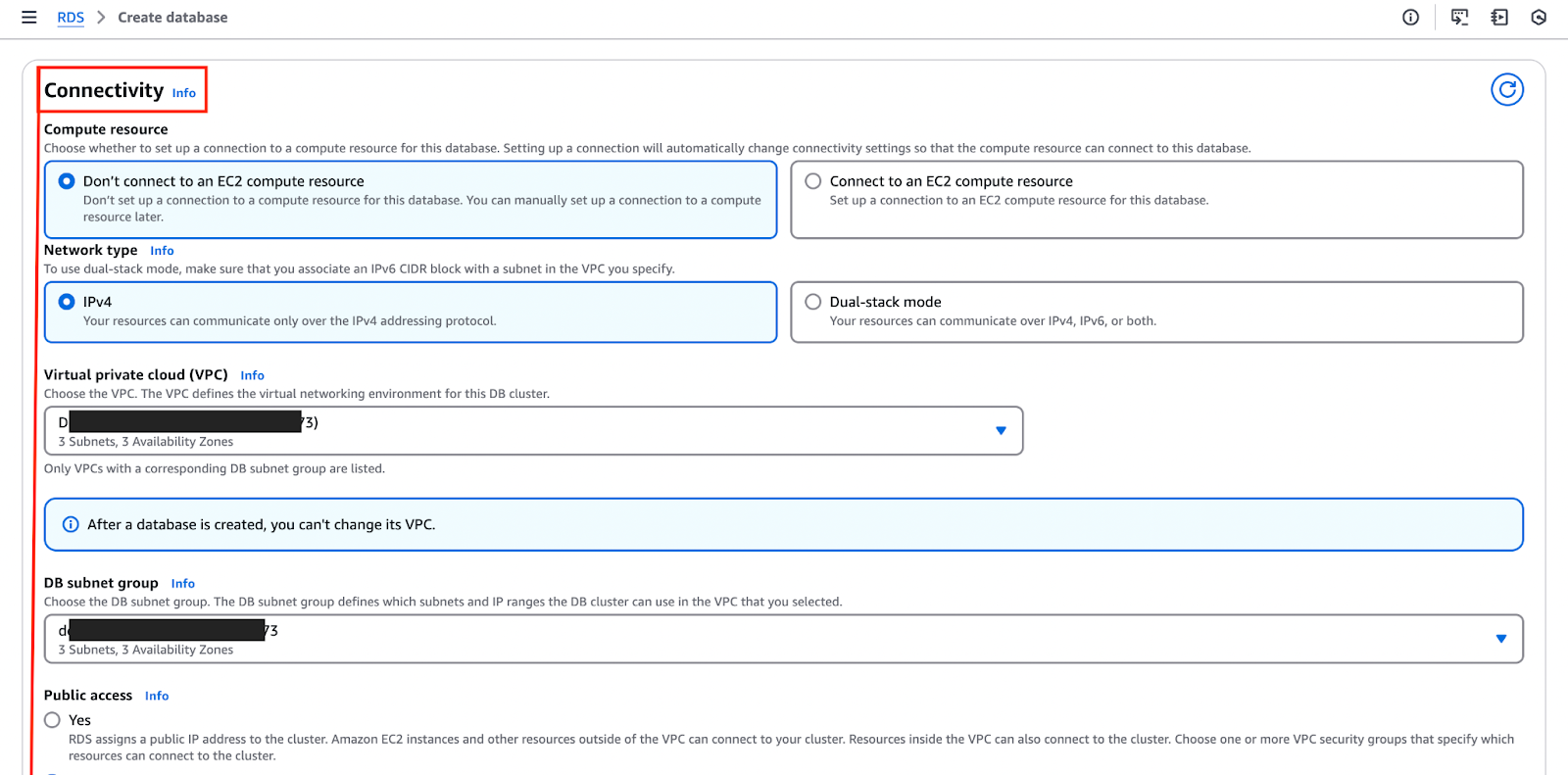
- Учетные данные базы данных также должны быть настроены во время установки – здесь вы назначаете основное имя пользователя и пароль, которые будут использоваться для аутентификации соединений.
- Аврора позволяет включить автоматическое резервное копирование и опцию восстановления до определенного момента. Это гарантирует, что моментальные снимки баз данных создаются последовательно, чтобы предотвратить потерю данных.
После проверки всех конфигураций вы можете приступить к созданию кластера Aurora. На изображении ниже показана кнопка “Создать базу данных”, на которую вы можете нажать, чтобы начать процесс создания.
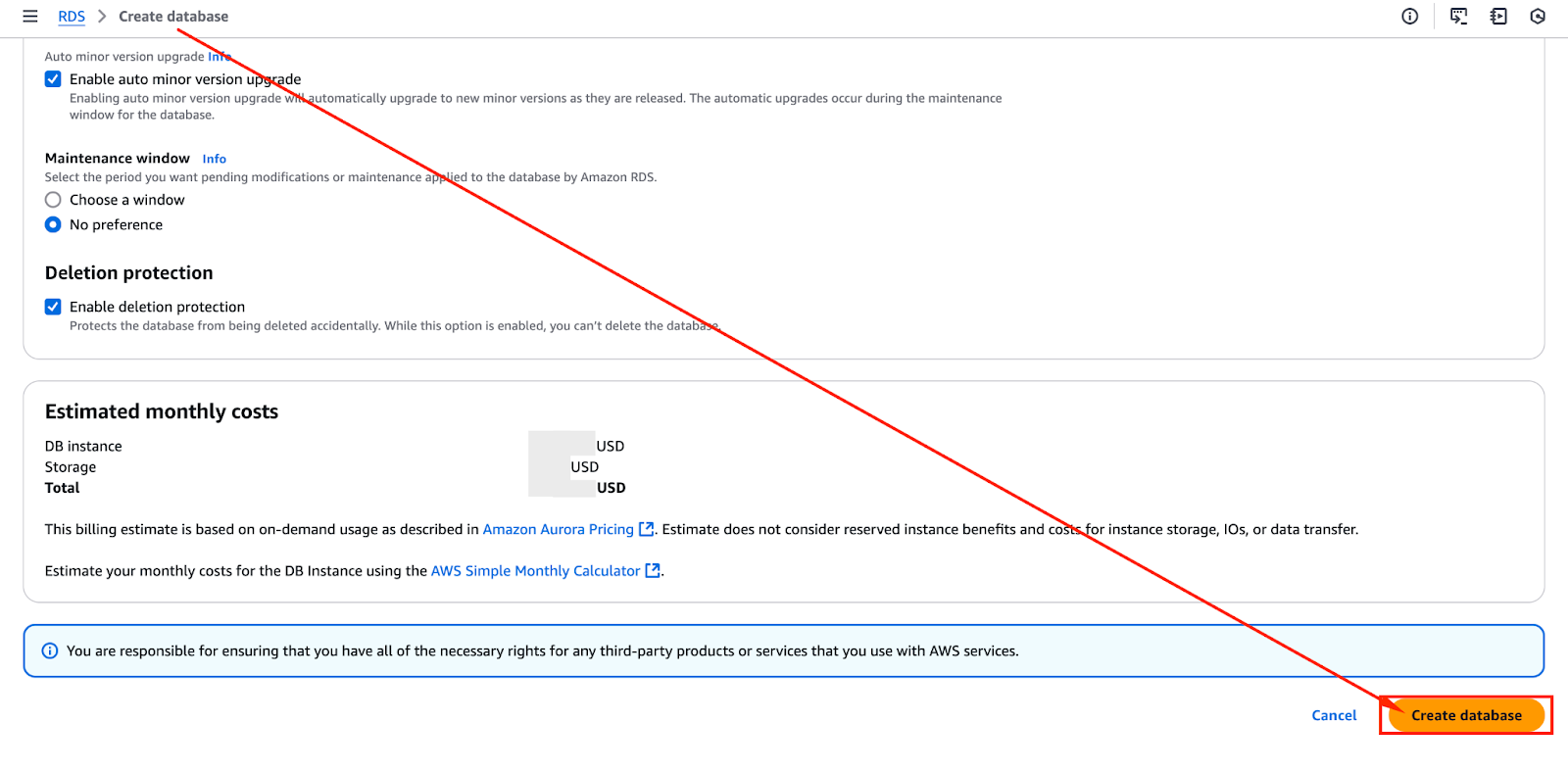
Процесс предоставления может занять несколько минут в зависимости от выбранного размера экземпляра и настроек сети.
> Если вы новичок в службах AWS, просмотр курса технологии облака и услуг AWS поможет вам понять ключевые концепции AWS, относящиеся к настройке Aurora.Настройка сети и безопасности
Безопасность имеет решающее значение для управления базой данных Aurora, и AWS предоставляет множество инструментов для обеспечения сильного контроля доступа.
- Первым шагом в обеспечении безопасности экземпляра Aurora является настройка групп безопасности VPC. Эти группы безопасности определяют, какие IP-адреса и службы могут взаимодействовать с базой данных.
- Вы должны ограничить доступ к конкретным серверам приложений и администраторам, чтобы предотвратить несанкционированные соединения.
- Менеджмент идентификации и доступа AWS (IAM) также может использоваться для определения точных разрешений на операции с базами данных.
- Интеграция ролей IAM позволяет настраивать доступ к базе данных в соответствии с конкретными ролями и обязанностями пользователей.
- Например, разработчики приложений могут иметь только чтение, в то время как администраторам будет предоставлен полный контроль над изменениями в базе данных.
- Шифрование также должно быть включено для защиты чувствительных данных. AWS Aurora поддерживает шифрование в покое и в транзите с использованием службы управления ключами AWS (KMS).
- Шифрование данных в покое гарантирует, что даже если носители данных скомпрометированы, данные остаются недоступными без правильного ключа дешифрования.
- Точно так же, активация шифрования протокола Secure Sockets Layer (SSL) для данных в транзите предотвращает несанкционированный перехват коммуникаций базы данных.
> Для более глубокого погружения в обеспечение безопасности сред AWS рекомендуется ознакомиться с курсом AWS Security and Cost Management. Если вы хотите узнать больше о том, как работает IAM и как его эффективно реализовать, обратитесь к этому руководству по AWS Identity and Access Management (IAM).
Подключение к AWS Aurora
Подключение к AWS Aurora необходимо для взаимодействия с базой данных. Это можно сделать через клиентские инструменты или приложения. Давайте посмотрим, как это сделать в этом разделе!
Подключение к Aurora MySQL
После того как база данных Aurora запущена и работает, необходимо установить соединение для начала взаимодействия с базой данных.
Для Aurora MySQL можно использовать обычные клиенты баз данных, такие как MySQL Workbench и HeidiSQL. В качестве альтернативы можно использовать интерфейсы командной строки.
Для подключения необходимо указать конечную точку базы данных, которую можно найти в консоли управления AWS.
С помощью MySQL CLI подключение можно установить с помощью следующей команды:
mysql -h your-cluster-endpoint -u admin -p
После ввода основного пароля вы сможете выполнять SQL-запросы, создавать таблицы и управлять данными.
Подключение к Aurora PostgreSQL
Для Aurora PostgreSQL можно подключиться с помощью инструментов, таких как pgAdmin или интерфейс командной строки PostgreSQL (psql).
Команда подключения в psql имеет следующий формат:
psql -h your-cluster-endpoint -U admin -d yourdatabasename
Как и в случае с MySQL, для доступа к базе данных необходимо ввести правильные учетные данные.
После получения доступа вы сможете выполнять SQL-запросы, создавать таблицы и управлять данными.
Настройка подключения приложения
Приложения, которые должны взаимодействовать с Aurora, необходимо настраивать с соответствующими строками подключения к базе данных. Обычно эти строки подключения состоят из имени пользователя, пароля, номера порта и конечной точки.
Рекомендуется использовать пул соединений для оптимизации производительности и снижения накладных расходов на установление новых соединений для каждого запроса.
Популярные библиотеки, такие как SQLAlchemy для Python или JDBC для Java, предоставляют эффективные способы управления соединениями в среде приложения.
Управление AWS Aurora
Эффективное управление AWS Aurora включает в себя обеспечение защиты данных, мониторинг производительности и масштабирование ресурсов по мере необходимости. В этом разделе мы рассмотрим эти практики.
Резервные копии и снимки
AWS Aurora предлагает автоматизированные резервные копии, которые постоянно захватывают и хранят изменения в базе данных в Amazon S3. Эти резервные копии хранятся на основе настроек, определенных пользователем, что позволяет восстановить данные в любой момент в пределах периода хранения.
В дополнение к автоматизированным резервным копиям, вы также можете создавать ручные снимки, которые сохраняются за пределами окна хранения. Ручные снимки особенно полезны для долгосрочного архивирования или перед выполнением крупных обновлений базы данных.
Когда я работал над проектом с критическим приложением, мы планировали автоматизированные резервные копии каждые два часа. Однако перед внесением каких-либо изменений или обновлений в приложение мы вручную создавали резервную копию, чтобы убедиться, что мы можем откатиться в случае необходимости. Это демонстрирует, как автоматизированные и ручные резервные копии могут эффективно использоваться вместе.
Изображение ниже показывает, как AWS Backup может быть использован для восстановления после катастрофы с Amazon Aurora.
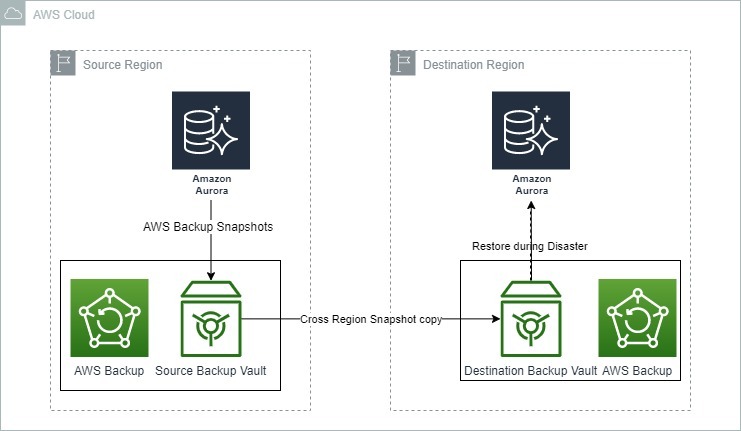
Варианты резервного копирования и восстановления для Amazon Aurora. Источник: Блоги AWS
Мониторинг Aurora с помощью CloudWatch
Мониторинг производительности необходим для поддержания здоровой базы данных.
AWS CloudWatch предоставляет метрики в реальном времени, отслеживающие использование ЦП, использование памяти, ввод-вывод на диске и сетевой трафик.
Настройка тревог CloudWatch может помочь администраторам получать уведомления, когда превышаются пороги производительности, обеспечивая проактивное управление базой данных.
Кроме того, AWS Performance Insights предлагает подробный анализ запросов для идентификации и оптимизации медленных запросов.
На изображении ниже показано, как AWS Performance Insights предоставляет информацию о производительности базы данных.
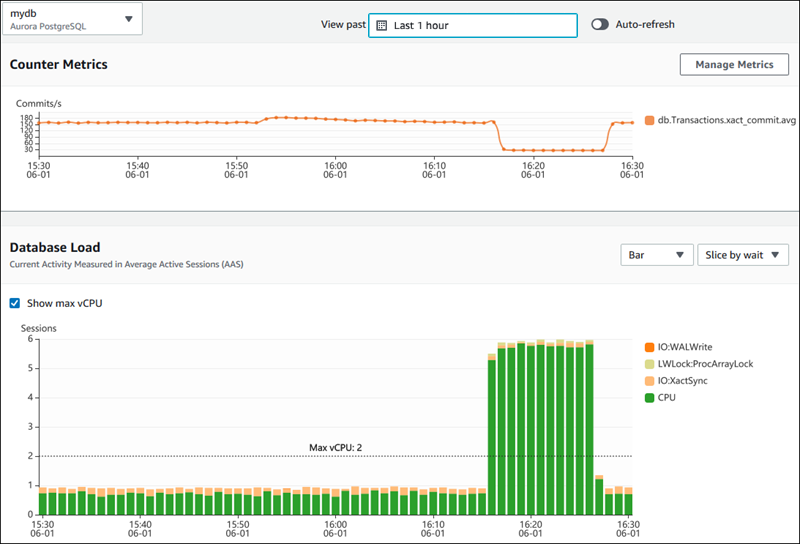
Панель инструментов AWS Performance Insights, отображающая метрики производительности базы данных. Источник: Документация AWS
Масштабирование Aurora
Aurora разработана для автоматического масштабирования путем корректировки объема хранилища по мере необходимости. Однако ресурсы вычислений, такие как ЦП и память, могут потребоваться настраивать вручную в зависимости от рабочей нагрузки.
Aurora предоставляет возможности масштабирования емкости для чтения путем добавления реплик для чтения, которые распределяют трафик на чтение и улучшают производительность.
Когда высокая доступность критична, кластер Aurora может быть настроен с несколькими репликами в разных зонах доступности для обеспечения избыточности отказоустойчивости.
Оптимизация производительности в AWS Aurora
Оптимизация производительности в Amazon Aurora обеспечивает эффективное выполнение запросов и масштабируемость. Давайте рассмотрим некоторые bewt практики в этом разделе.
Индексирование и оптимизация запросов
Оптимизация производительности запросов в Amazon Aurora является ключевым аспектом поддержания высокопроизводительной базы данных.
- Индексирование является одним из наиболее эффективных способов сокращения времени выполнения запроса и улучшения эффективности базы данных.
- Создание индексов на часто запрашиваемых столбцах может помочь быстро найти данные, минимизируя необходимость в полном сканировании таблицы.
- Вы должны стратегически использовать первичные и вторичные индексы, чтобы соответствовать шаблонам запросов и потребностям рабочей нагрузки.
- Помимо вышесказанного, можно использовать составные индексы для запросов, включающих несколько столбцов, чтобы дополнительно улучшить время поиска.
- Оптимизация запросов также играет значительную роль в производительности базы данных. Написание эффективных SQL-запросов обеспечивает более быструю обработку запросов Aurora с минимальным потреблением ресурсов.
- Использование
EXPLAIN или EXPLAIN ANALYZEв SQL-запросах помогает выявить узкие места и предоставляет информацию о планах выполнения. - Такие техники, как избегание
SELECT *(который извлекает ненужные данные), нормализация схемы базы данных для снижения избыточности и использование стратегий партиционирования могут привести к увеличению производительности. - Оптимизатор плана запросов Aurora постоянно уточняет планы выполнения, внося изменения на основе паттернов нагрузки базы данных, тем самым повышая общую эффективность.
Использование реплик чтения Aurora
Для обработки высоких нагрузок Amazon Aurora поддерживает реплики чтения, которые помогают распределять запросы, требующие интенсивного чтения, между несколькими экземплярами.
Реплики для чтения снижают нагрузку на основной экземпляр базы данных, обрабатывая запросы на чтение отдельно, что улучшает отзывчивость и снижает задержку.
Для настройки реплики для чтения в Aurora вам потребуется выбрать существующий кластер Aurora и включить репликацию с минимальной конфигурацией. Aurora автоматически синхронизирует данные между основным экземпляром и его репликами, обеспечивая согласованность данных без ручного вмешательства.
Механизм репликации в Aurora является очень эффективным, обеспечивая практически мгновенную синхронизацию данных с задержкой репликации менее секунды.
Приложения, выполняющие частые операции чтения, такие как отчетные панели или аналитические сервисы, могут значительно выиграть от использования реплик для чтения, направляя запросы с высокой нагрузкой на чтение на эти экземпляры.
В случае отказа первичного экземпляра реплика для чтения может быть повышена до статуса нового первичного экземпляра с минимальным временем простоя, обеспечивая высокую доступность и бесперебойную работу бизнеса.
На изображении ниже показано, как кросс-региональные реплики Aurora могут помочь в восстановлении после катастрофы и обеспечить высокую доступность.
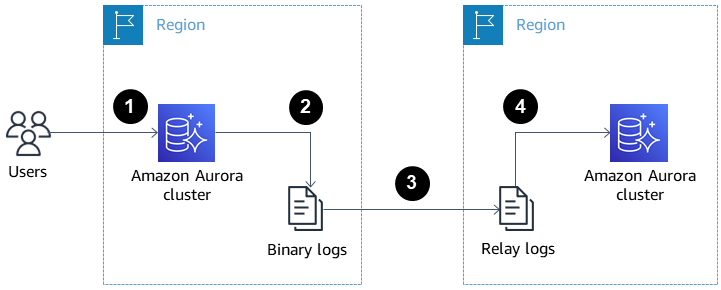
Кросс-региональные реплики Aurora для восстановления после катастрофы и обеспечения высокой доступности. Источник: Документация AWS
Стратегии кэширования для Aurora
Кэширование – мощный метод для улучшения производительности базы данных за счет сокращения прямых запросов к Aurora. Кэширующий слой может значительно ускорить извлечение данных для часто используемых запросов.
Amazon ElastiCache, который поддерживает Redis и Memcached, часто используется наряду с Aurora для хранения результатов запросов и предотвращения избыточных запросов к базе данных.
Интеграция кэширования в архитектуру приложения может помочь улучшить время отклика и сохранить вычислительные ресурсы базы данных.
Стратегии кэширования, такие как кэширование с записью (где данные записываются одновременно как в кэш, так и в Aurora) и ленивая загрузка (где данные кэшируются только при запросе), помогают оптимизировать производительность на основе шаблонов использования.
Настройка соответствующего времени жизни (TTL) для кэшированных данных обеспечивает свежесть кэша и предотвращает получение устаревших данных.
Безопасность и соответствие в AWS Aurora
Обеспечение безопасности вашей базы данных Aurora крайне важно для защиты конфиденциальных данных и обеспечения соответствия. Давайте рассмотрим лучшие практики в этом разделе.
Шифрование данных
Безопасность данных является основой управления базами данных, и AWS Aurora предоставляет надежные механизмы шифрования для защиты конфиденциальной информации.
- Aurora шифрует данные в покое с использованием службы управления ключами AWS (KMS), что обеспечивает сохранение безопасности хранимой информации даже в случае компрометации основного хранилища.
- Включение шифрования во время создания базы данных гарантирует, что все автоматические резервные копии, снимки и реплики наследуют одни и те же настройки шифрования.
- Для данных в транзите Aurora поддерживает шифрование SSL/TLS, которое обеспечивает безопасность соединений с базой данных и предотвращает несанкционированный доступ или перехват передачи данных.
- Приложения, подключающиеся к Aurora, должны быть настроены на использование SSL-сертификатов для поддержки безопасной связи.
Эти меры шифрования могут помочь вам соблюдать лучшие практики в области безопасности и требования регулирующих органов.
Изображение ниже демонстрирует, как AWS KMS интегрируется с Amazon Aurora для шифрования вашей базы данных.
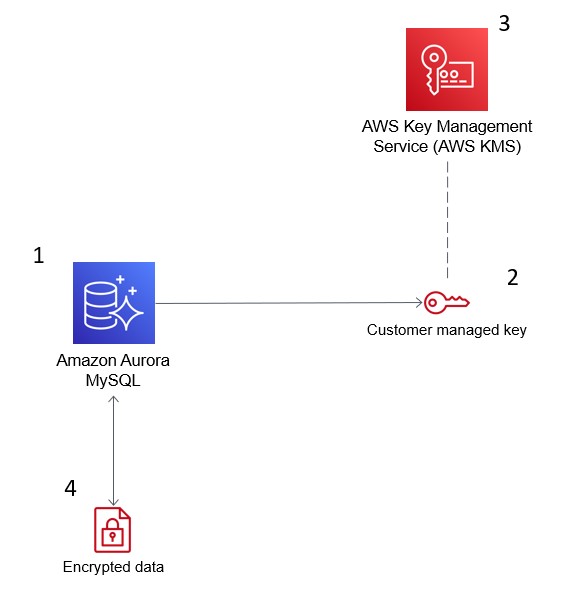
AWS Служба управления ключами (KMS) шифрует данные в Amazon Aurora для соблюдения требований безопасности.Источник: Блоги AWS
Интеграция IAM для контроля доступа
Контроль доступа в Aurora управляется через AWS IAM, что позволяет администраторам определять детализированные разрешения на основе ролей пользователей.
- Политики IAM могут быть использованы для ограничения доступа к экземплярам баз данных, предотвращая несанкционированным пользователям выполнение критически важных операций, таких как изменения данных или административные задачи.
- Аутентификация IAM предоставляет более безопасную альтернативу традиционной аутентификации на основе пароля. Она позволяет приложениям подключаться с использованием временных учетных данных безопасности. Это исключает необходимость хранения и управления паролями базы данных, снижая риск компрометации учетных данных.
Вы должны соблюдать принципы доступа с минимальными привилегиями, которые минимизируют риски безопасности и обеспечивают строгий контроль над доступом к базе данных.
На изображении ниже показано, как настроить аутентификацию IAM для обеспечения безопасного доступа к базе данных Amazon Aurora PostgreSQL.
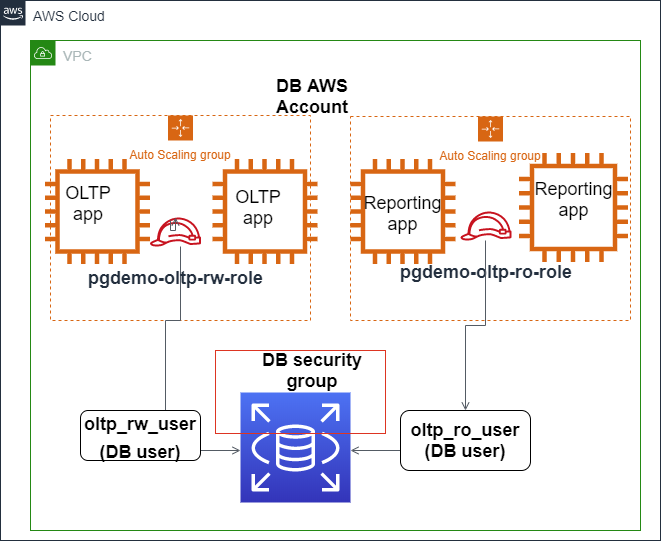
Аутентификация IAM интегрируется с Amazon Aurora PostgreSQL. Источник: Блоги AWS
Аудит с помощью логов Aurora
Мониторинг и аудит активности базы данных являются важными для соблюдения безопасности и устранения неполадок.
Aurora предоставляет несколько механизмов логирования, включая логи ошибок, логи медленных запросов и общие логи, которые помогают администраторам отслеживать активность базы данных и выявлять потенциальные проблемы. Эти логи можно включить через консоль управления AWS и хранить в Amazon CloudWatch для централизованного анализа.
- Логи ошибок фиксируют ошибки и предупреждения движка базы данных.
- Логи медленных запросов помогают выявлять неэффективные запросы, которые могут повлиять на производительность.
Анализ этих журналов может помочь администраторам оптимизировать выполнение запросов, обнаруживать попытки несанкционированного доступа и обеспечивать стабильность базы данных.
Управление стоимостью и оптимизация в AWS Aurora
Для эффективного управления и оптимизации затрат в Amazon Aurora необходимо понимать его структуру ценообразования. Давайте рассмотрим это!
Понимание структуры ценообразования Aurora
Модель ценообразования Amazon Aurora основана на нескольких факторах, включая часы работы экземпляра, потребление хранилища, запросы ввода-вывода и передачу данных.
В отличие от традиционных баз данных, требующих предварительного выделения инфраструктуры, модель оплаты по факту использования в Aurora позволяет бизнесу платить только за потребляемые ресурсы.
Экземпляры вычислений тарифицируются на основе класса экземпляра и времени работы, в то время как объем хранения масштабируется динамически, исключая необходимость вручных настроек.
На изображении ниже приведено разбиение на различные компоненты ценообразования для Amazon Aurora. Однако следует иметь в виду, что цены могут изменяться, поэтому всегда лучше обращаться к странице ценообразования Aurora для самой актуальной информации.
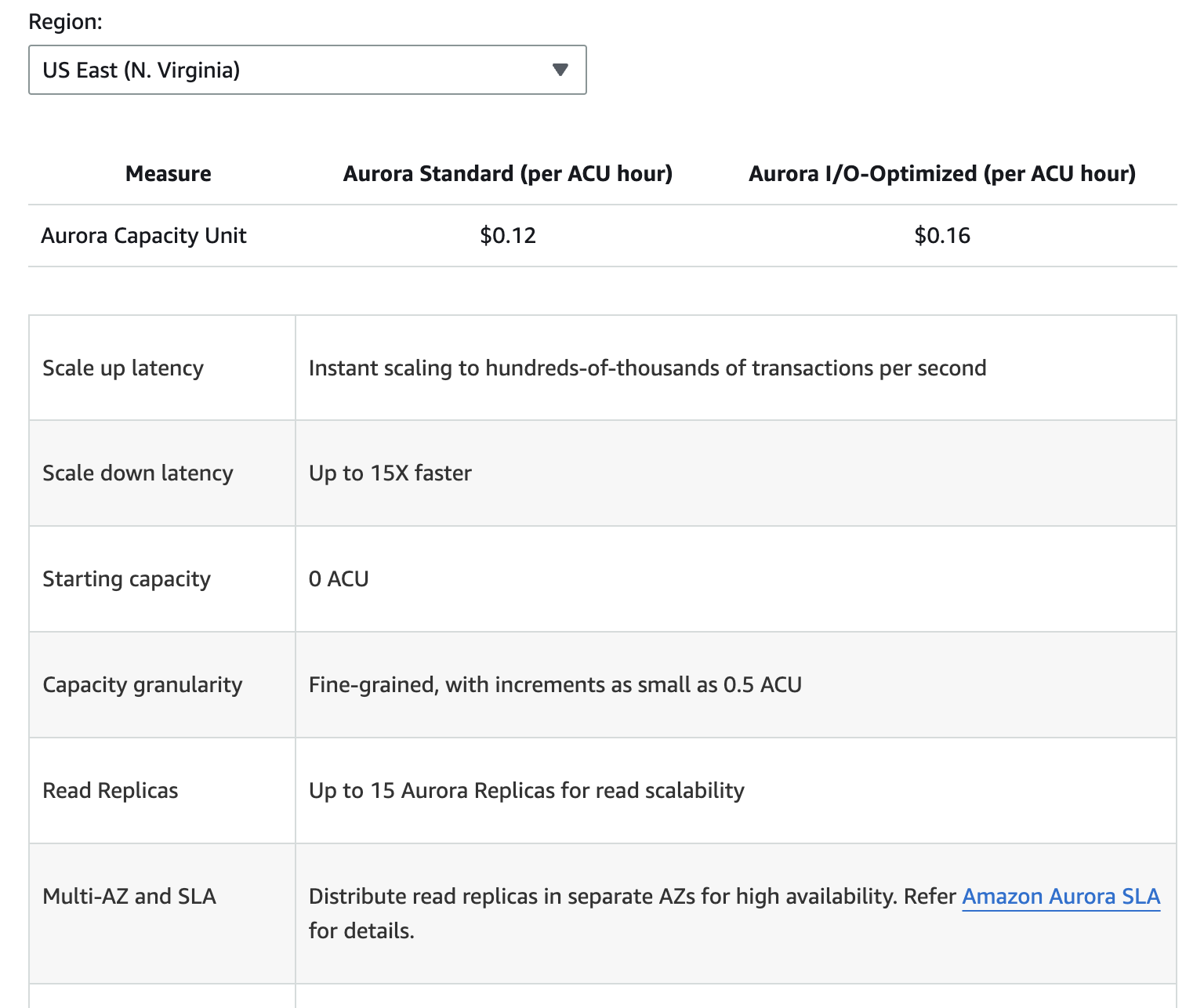
Дополнительные расходы включают хранение резервных копий сверх бесплатного уровня, запросы на чтение и запись ввода-вывода, и сборы за передачу данных при межрегиональной репликации.
Понимание этих компонентов ценообразования может помочь вам прогнозировать расходы и принимать обоснованные решения относительно использования базы данных.
Оптимизация затрат с Aurora
Для эффективного управления затратами организации могут применить несколько стратегий оптимизации.
Выбор подходящего размера экземпляра обеспечит соответствие ресурсов базы данных потребностям рабочей нагрузки без избыточной предварительной настройки.
- Если у вас предсказуемая рабочая нагрузка, используйте Зарезервированные экземпляры, так как они обеспечивают значительную экономию по сравнению с ценами по запросу.
- Техники оптимизации хранения, такие как мониторинг неиспользуемых или недоиспользуемых ресурсов, помогают снизить затраты.
- Автомасштабирование Aurora позволяет динамически настраивать хранение, предотвращая ненужные расходы на хранение.
- Кроме того, внедрение реплик для чтения может разгрузить запросы с основного экземпляра, что потенциально снизит необходимость в более дорогих экземплярах.
- Используйте Amazon Aurora Serverless, поскольку это еще один экономичный вариант для приложений с переменной нагрузкой. Amazon Aurora Serverless автоматически масштабирует вычислительные ресурсы в зависимости от спроса, что гарантирует, что компании платят только за фактическое использование, а не за постоянно работающий экземпляр.
> Если вы хотите получить больше информации о управлении затратами, обратитесь к курсу AWS Security and Cost Management.
Заключение
После работы с Amazon Aurora в нескольких компаниях в течение длительного времени, я уверенно могу сказать, что это мощное и масштабируемое решение базы данных, которое упрощает управление без ущерба для производительности – вы, вероятно, согласитесь с этим после прохождения этого руководства.
Аврора стоит рассмотреть, если вы ищете облачную реляционную базу данных, которая поддерживает MySQL и PostgreSQL, снижая операционную нагрузку. Она была революционной в некоторых моих проектах, и я настоятельно рекомендую изучить ее возможности, если вы работаете с базами данных AWS.
Если вы новичок в базах данных AWS, изучение фундаментальных концепций через курсы, такие как AWS Cloud Practitioner (CLF-C02), может быть полезным!