













Na het gebruik van Amazon Aurora bij verschillende bedrijven gedurende enige tijd, heb ik uit eerste hand gezien hoe het uitblinkt als een volledig beheerde relationele database-engine, met hoge prestaties, schaalbaarheid en betrouwbaarheid.
Als een cloud-native oplossing die MySQL en PostgreSQL ondersteunt, is Aurora een uitstekende keuze voor bedrijven die hoge beschikbaarheid en automatische schaalbaarheid vereisen. Omdat AWS back-ups, failover en replicatie automatisch beheert, stelt het gebruik van Aurora u in staat om de database-efficiëntie te verhogen terwijl de onderhoudskosten worden verlaagd.
In deze zelfstudie zal ik u begeleiden bij het opzetten van een Aurora-instantie, het efficiënt beheren ervan, het optimaliseren van de prestaties en het waarborgen van de beveiliging en kosteneffectiviteit.
Wat is AWS Aurora?
Amazon Aurora is een cloudgebaseerde relationele database die traditionele MySQL en PostgreSQL overtreft door dynamisch schalen van opslag- en rekencapaciteit.
Volgens AWS kan Aurora tot wel vijf keer de doorvoer van standaard MySQL leveren en drie keer de prestaties van standaard PostgreSQL – dankzij de gedistribueerde en zeer beschikbare architectuur.
Aurora is gebouwd met functies zoals geautomatiseerde back-ups, lees-replica’s voor horizontaal schalen, en failover-mechanismen die zorgen voor minimale downtime.
De opslaglaag van Aurora is ontworpen om fouttolerant en zelfherstellend te zijn.
Bovendien wordt data automatisch gerepliceerd over meerdere Beschikbaarheidszones (AZ’s) om duurzaamheid te waarborgen.
De onderstaande afbeelding geeft een overzicht op hoog niveau van de architectuur en belangrijkste kenmerken van Amazon Aurora.
De relatie tussen de cluster volume, schrijvende DB-instantie en lezende DB-instanties in een Aurora-cluster. Dusurce: AWS Docs
De database-engine controleert continu query’s en optimaliseert uitvoeringsplannen, wat leidt tot aanzienlijke efficiëntieverbeteringen.
Een van de belangrijkste voordelen van Aurora is de compatibiliteit met bestaande MySQL en PostgreSQL-databases, waardoor het voor bedrijven gemakkelijk is om over te stappen zonder hun applicaties uitgebreid te hoeven aanpassen.
De kostenstructuur van Aurora is ook aantrekkelijk. Het rekent op basis van het daadwerkelijke gebruik van rekencapaciteit en opslagbronnen. Dit kostenmodel elimineert de noodzaak om infrastructuur overmatig te voorzien, wat op zijn beurt geld bespaart.
> Als u geïnteresseerd bent in een breder begrip van de opslagopties van AWS, bekijk dan deze AWS Storage Tutorial.
Opzetten van AWS Aurora
Het opzetten van AWS Aurora omvat het maken van een databasecluster, het configureren van beveiligingsinstellingen en het zorgen voor de juiste netwerktoegang. Laten we dat in deze sectie doen!
> Als u nieuw bent bij AWS, overweeg dan om de fundamentele onderwerpen te bekijken met de Introductie tot AWS cursus voordat u zich verdiept in Aurora.
Het maken van een Aurora-databasecluster
Het opzetten van een Aurora-databasecluster vereist een paar belangrijke stappen, waaronder het selecteren van de juiste database-engine, het configureren van beveiligingsinstellingen en het definiëren van instantiespecificaties.
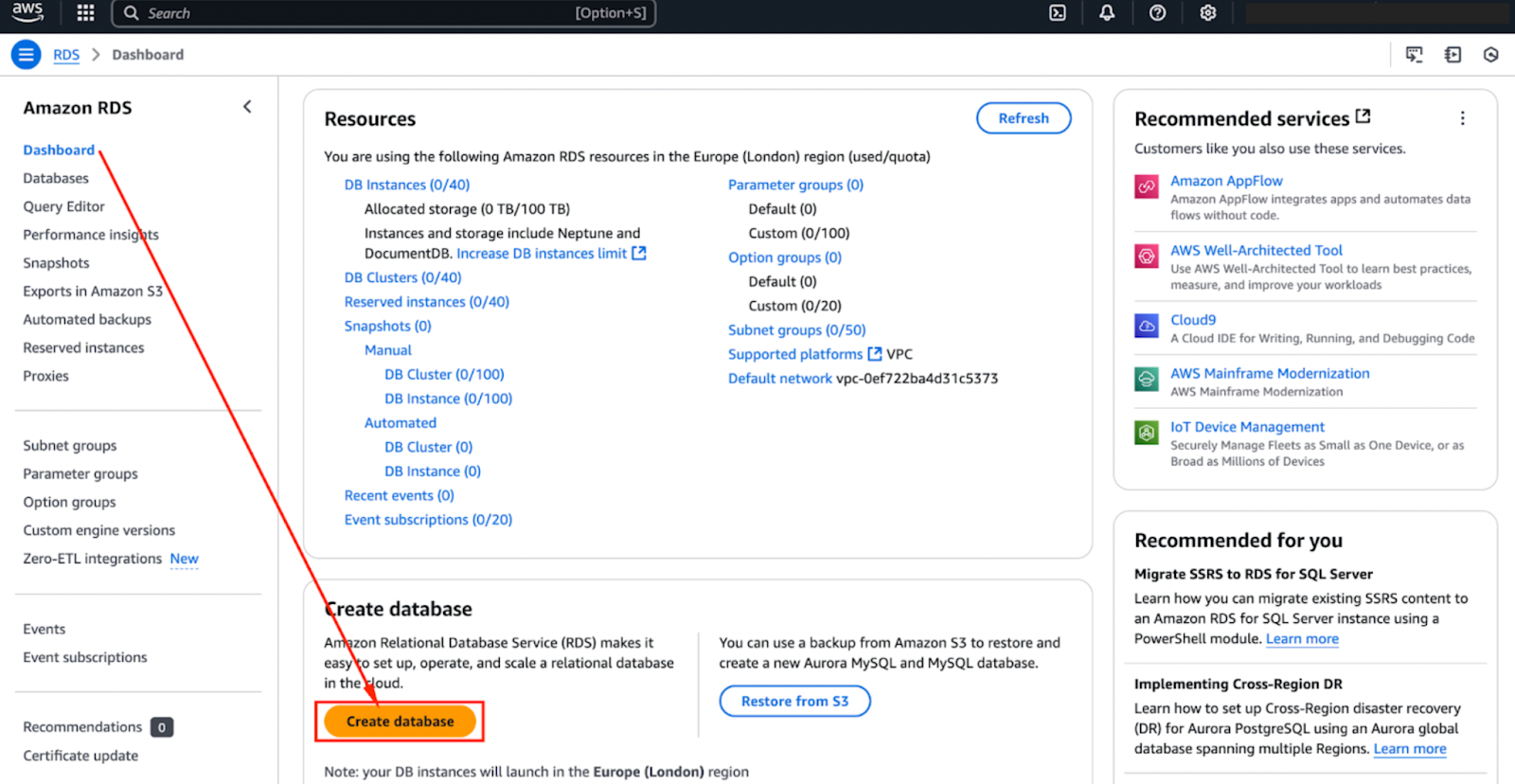
- Om te beginnen, log in op de AWS Management Console en ga naar het RDS (Relational Database Service) dashboard.
- Je kunt dit doen door te zoeken naar “Aurora” in het zoekpaneel van de AWS Management Console – zoals weergegeven in de afbeelding hieronder.
- Als je daar bent, klik dan op “Database maken” – zoals weergegeven in de afbeelding hieronder.
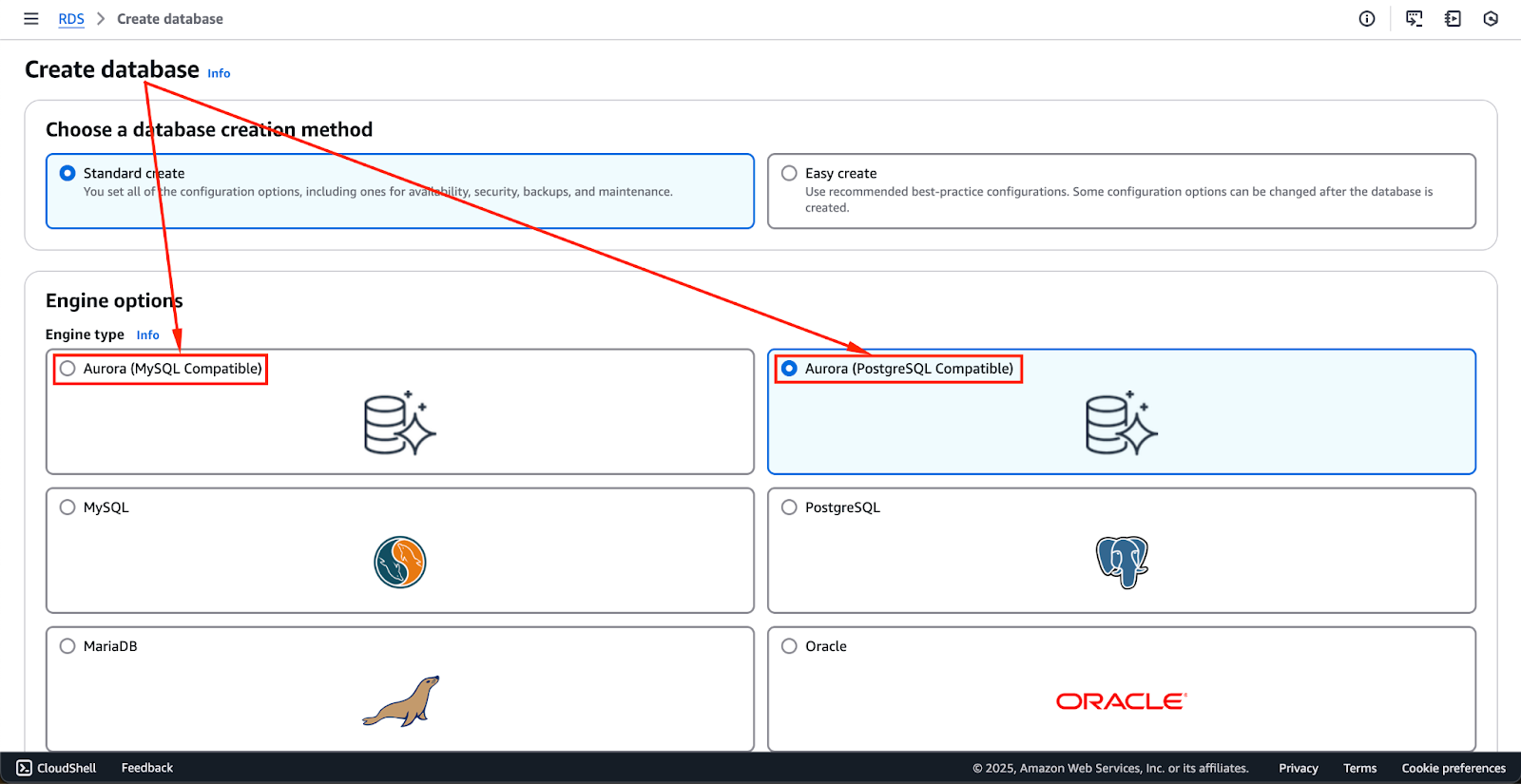
- Je hebt dan de optie om “Amazon Aurora” te kiezen als de database-engine.
- Onthoud dat Aurora zowel MySQL als PostgreSQL ondersteunt, dus het is belangrijk om de versie te kiezen die het beste voldoet aan de eisen van uw toepassing.
De onderstaande afbeelding toont de motoropties die momenteel beschikbaar zijn. Deze kunnen in de toekomst veranderen, maar de eerste twee opties – Aurora (MySQL-compatibel) en Aurora (PostgreSQL-compatibel) – zijn de Aurora-motoren.
- Nadat u de motor heeft geselecteerd, moet u het instantietype en de opslagconfiguraties specificeren.
- Aurora biedt de flexibiliteit om de opslag automatisch te schalen tot 128 TB, waardoor groeiende workloads efficiënt worden afgehandeld zonder handmatige interventie.
- De volgende stap is het definiëren van replicatie-instellingen. U kunt kiezen voor een implementatie met één instantie of read replicas inschakelen om de databaseverkeer effectiever te verdelen.
- Het gebruik van read replicas verbetert ook de beschikbaarheid en fouttolerantie, wat zorgt voor een hogere duurzaamheid in geval van storingen.
De onderstaande afbeelding benadrukt de “Beschikbaarheid & duurzaamheid” sectie, waar u deze instellingen kunt configureren.
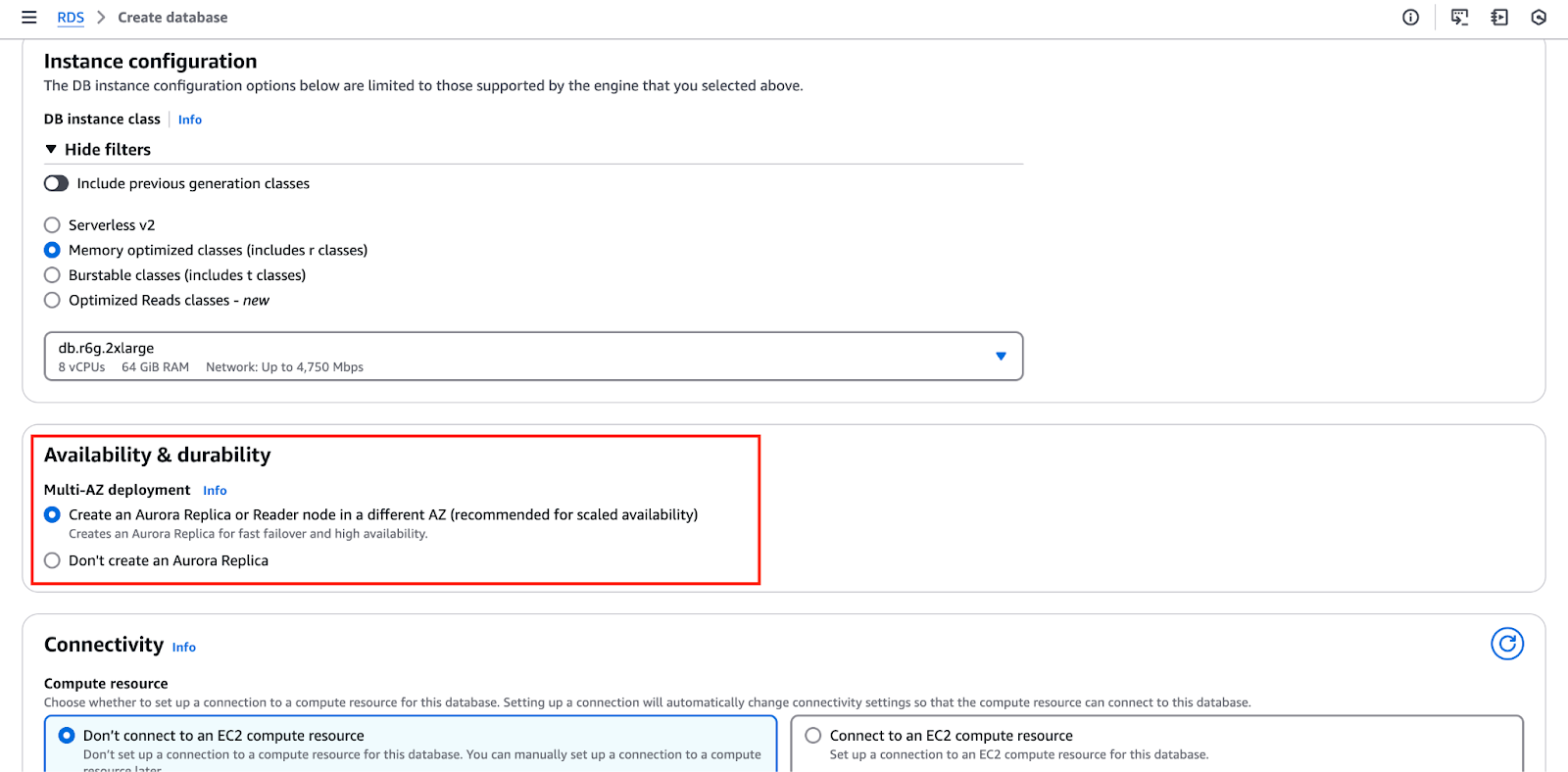
- De netwerkconfiguratiestap is cruciaal, omdat het het opzetten van de Virtual Private Cloud (VPC), het selecteren van een beveiligingsgroep en het definiëren van toegangscontroles omvat.
- Een beveiligingsgroep fungeert als een firewall die inkomend en uitgaand databaseverkeer reguleert. Om de beveiliging te verbeteren, wordt aanbevolen om alleen toegang toe te staan van vertrouwde IP-adressen en applicaties.
De onderstaande afbeelding benadrukt de “Connectiviteit” sectie, waar je deze configuraties kunt instellen en aanpassen.
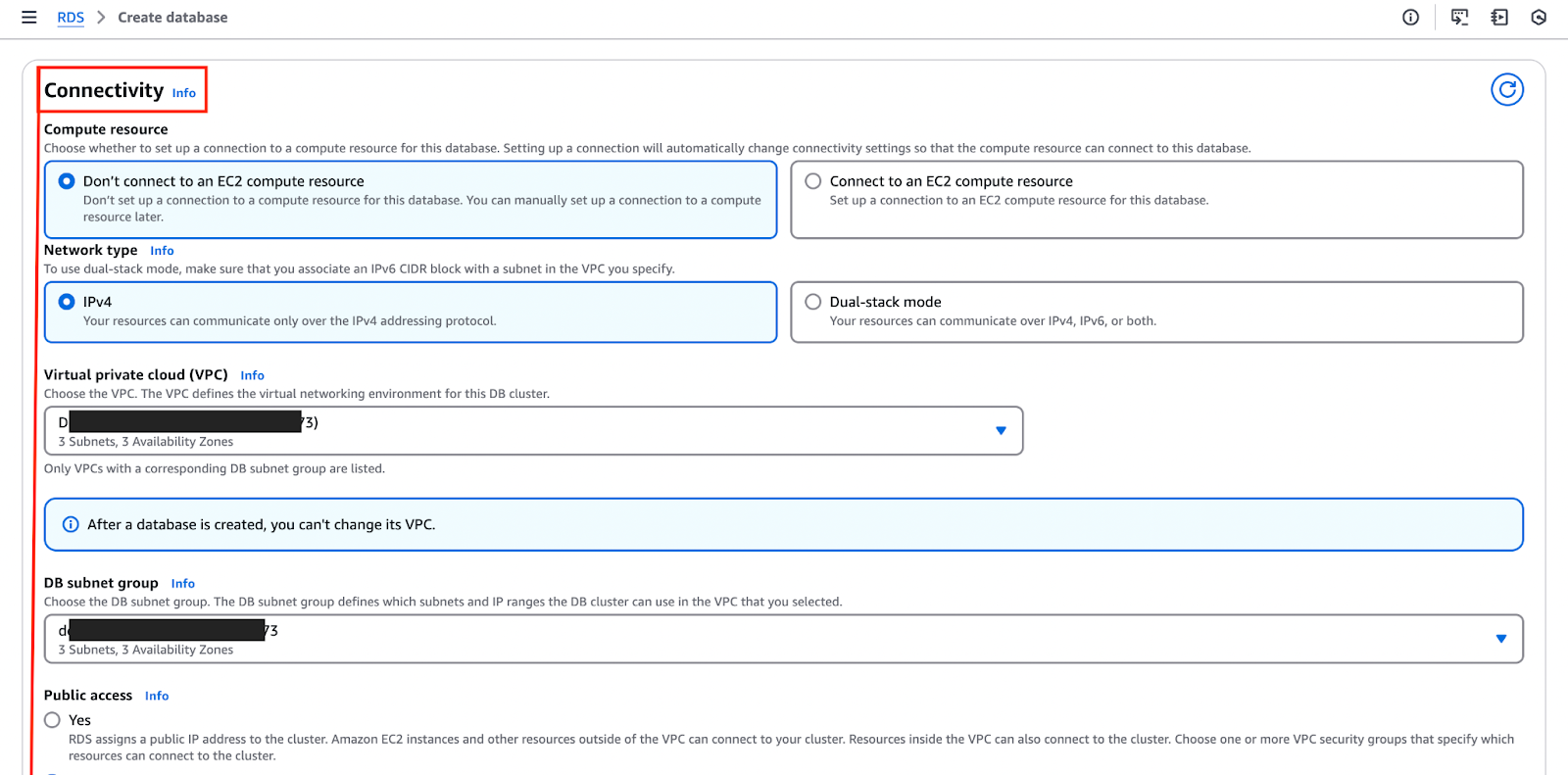
- Tijdens de installatie moeten ook de database referenties geconfigureerd worden – waar je een hoofdgebruikersnaam en wachtwoord toewijst die gebruikt zullen worden voor het verifiëren van verbindingen.
- Aurora biedt geautomatiseerde back-ups en opties voor point-in-time recovery die ingeschakeld kunnen worden. Dit zorgt ervoor dat database snapshots consequent worden gemaakt om dataverlies te voorkomen.
Na het bekijken van alle configuraties kunt u doorgaan met het maken van de Aurora-cluster. De onderstaande afbeelding toont de “Create Database” knop die u kunt klikken om het creatieproces te starten.
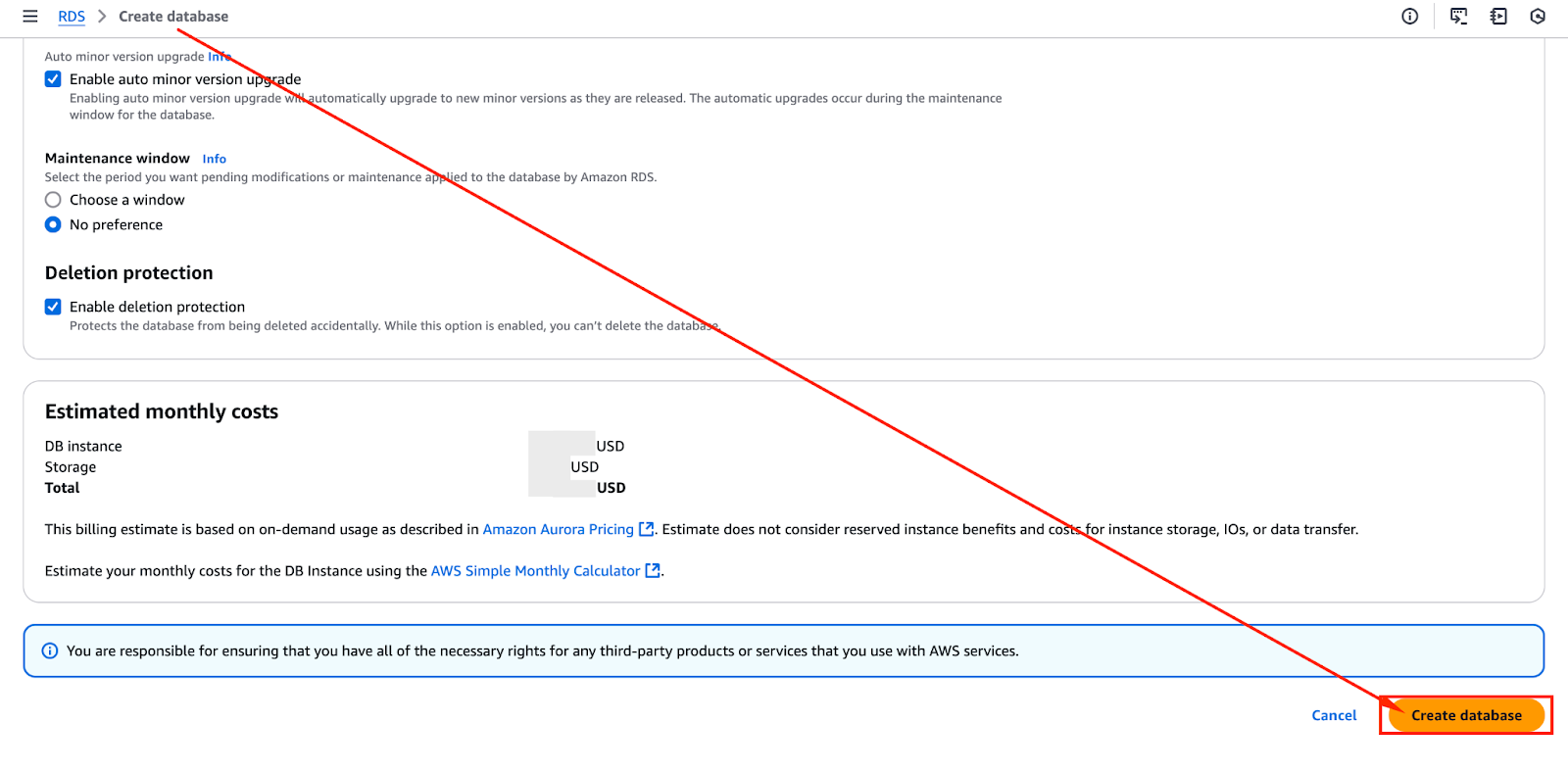
Het voorzieningsproces kan enkele minuten duren, afhankelijk van de geselecteerde instantiegrootte en netwerkinstellingen.
> Als je nieuw bent met AWS-diensten, kan het bekijken van de AWS Cloud Technologie en Diensten cursus je helpen om belangrijke AWS-concepten te begrijpen die relevant zijn voor de opzet van Aurora.
Netwerk- en beveiligingsconfiguratie
Beveiliging is cruciaal voor het beheren van een Aurora-database, en AWS biedt verschillende tools om sterke toegangscontroles af te dwingen.
- De eerste stap in het beveiligen van een Aurora-instantie is het configureren van VPC-beveiligingsgroepen. Deze beveiligingsgroepen bepalen welke IP-adressen en diensten met de database kunnen communiceren.
- Je zou de toegang moeten beperken tot specifieke applicatieservers en beheerders om ongeautoriseerde verbindingen te voorkomen.
- AWS Identity and Access Management (IAM) kan ook worden gebruikt om fijnmazige toestemmingen voor databasebewerkingen te definiëren.
- Door IAM-rollen te integreren, kun je database toegang aanpassen op basis van de specifieke gebruikersrollen en verantwoordelijkheden.
- Zo kunnen bijvoorbeeld applicatieontwikkelaars alleen leestoegang krijgen, terwijl beheerders volledige controle hebben over databaseaanpassingen.
- Encryptie moet ook worden ingeschakeld om gevoelige gegevens te beschermen. AWS Aurora ondersteunt encryptie in rust en in doorvoer met behulp van de AWS Key Management Service (KMS).
- Het versleutelen van gegevens in rust zorgt ervoor dat zelfs als opslagmedia gecompromitteerd is, de gegevens ontoegankelijk blijven zonder de juiste decryptiesleutel.
- Vergelijkbaar voorkomt het inschakelen van Secure Sockets Layer (SSL) encryptie voor gegevens in doorvoer ongeautoriseerde onderschepping van databasecommunicatie.
> Voor een diepere duik in het beveiligen van AWS-omgevingen, bekijk de AWS Security and Cost Management-cursus. Als je meer wilt leren over hoe IAM werkt en hoe je het effectief kunt implementeren, bekijk dan deze gids over AWS Identity and Access Management (IAM).
Verbinding maken met AWS Aurora
Het verbinden met AWS Aurora is essentieel voor de interactie met de database. Dit kan via clienttools of applicaties. Laten we in deze sectie bekijken hoe!
Verbinding maken met Aurora MySQL
Zodra de Aurora-database actief is, moet je een verbinding tot stand brengen om te kunnen communiceren met de database.
Voor Aurora MySQL kunnen veelvoorkomende databasecliënten zoals MySQL Workbench en HeidiSQL worden gebruikt om verbinding te maken. Alternatief kun je gebruikmaken van opdrachtregelinterfaces.
De verbinding vereist het opgeven van het database-eindpunt, dat te vinden is in de AWS Management Console.
Met de MySQL CLI kan de verbinding worden tot stand gebracht met de volgende opdracht:
mysql -h your-cluster-endpoint -u admin -p
Na het invoeren van het masterwachtwoord zou je in staat moeten zijn om SQL-query’s uit te voeren, tabellen te maken en gegevens te beheren.
Verbinden met Aurora PostgreSQL
Voor Aurora PostgreSQL kun je verbinding maken met tools zoals pgAdmin of de PostgreSQL-opdrachtregelinterface (psql).
De verbindingsopdracht in psql volgt dit formaat:
psql -h your-cluster-endpoint -U admin -d yourdatabasename
Net als bij MySQL moeten de juiste inloggegevens worden ingevoerd om toegang te krijgen tot de database.
Zodra je toegang hebt gekregen, zou je in staat moeten zijn om SQL-query’s uit te voeren, tabellen te maken en gegevens te beheren.
Configureren van applicatieverbindingen
Toepassingen die met Aurora moeten interageren, moeten worden geconfigureerd met de juiste databaseverbindingsteksten. Gewoonlijk bestaan deze verbindingsteksten uit de gebruikersnaam, het wachtwoord, het poortnummer en het eindpunt.
Het wordt aanbevolen om verbindingspooling te gebruiken om de prestaties te optimaliseren en de overhead van het tot stand brengen van nieuwe verbindingen voor elke aanvraag te verminderen.
Populaire bibliotheken zoals SQLAlchemy voor Python of JDBC voor Java bieden efficiënte manieren om verbindingen in een applicatieomgeving te beheren.
Het beheren van AWS Aurora
Effectief beheer van AWS Aurora omvat het waarborgen van gegevensbescherming, het monitoren van prestaties en het schalen van middelen indien nodig. In dit gedeelte zullen we deze praktijken bekijken.
Back-ups en snapshots
AWS Aurora biedt geautomatiseerde back-ups die continu databasewijzigingen vastleggen en opslaan in Amazon S3. Deze back-ups worden bewaard op basis van door de gebruiker gedefinieerde instellingen, zodat herstel naar elk punt binnen de bewaartijd mogelijk is.
Naast geautomatiseerde back-ups kunt u ook handmatige snapshots maken die langer meegaan dan het bewaervenster. Handmatige snapshots zijn bijzonder nuttig voor langdurige archivering of voordat belangrijke database-updates worden uitgevoerd.
Toen ik aan een project werkte met een kritieke applicatie, planden we geautomatiseerde back-ups elke twee uur. Echter, voordat we wijzigingen of updates aan de applicatie aanbrachten, maakten we handmatig een back-up om ervoor te zorgen dat we konden terugdraaien indien nodig. Dit toont aan hoe zowel geautomatiseerde als handmatige back-ups effectief samen kunnen worden gebruikt.
De onderstaande afbeelding toont hoe AWS Backup kan worden gebruikt voor noodherstel met Amazon Aurora.
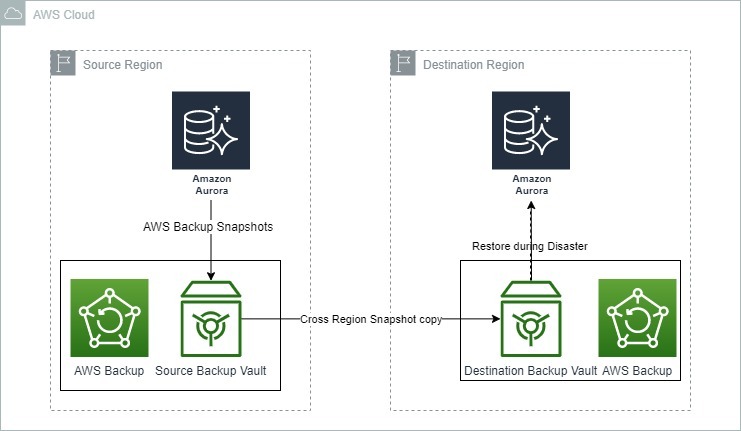
Back-up- en herstelopties voor Amazon Aurora. Bron: AWS Blogs
Monitoring Aurora met CloudWatch
Prestatiebewaking is essentieel voor het onderhouden van een gezonde database.
AWS CloudWatch biedt realtime statistieken die de CPU-gebruik, geheugengebruik, schijf-I/O en netwerkverkeer volgen.
Door CloudWatch Alarms in te stellen, kunnen beheerders worden gewaarschuwd wanneer prestatiedrempels worden overschreden, waardoor proactief databasebeheer mogelijk is.
Daarnaast biedt AWS Performance Insights gedetailleerde query-analyse om trage query’s te identificeren en te optimaliseren.
De onderstaande afbeelding laat zien hoe AWS Performance Insights inzicht biedt in databaseprestaties.
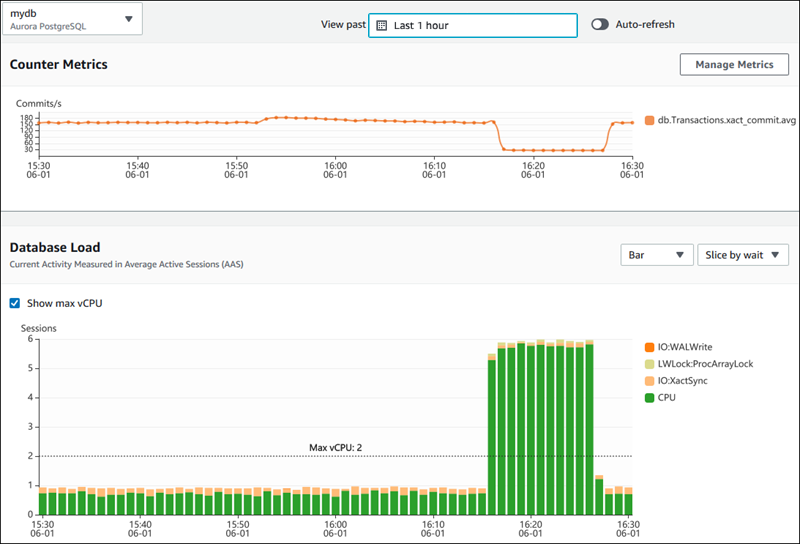
AWS Performance Insights-dashboard met databaseprestatiegegevens. Bron: AWS Docs
Schalen van Aurora
Aurora is ontworpen om automatisch te schalen door de opslagcapaciteit aan te passen indien nodig. Echter, rekencapaciteiten zoals CPU’s en geheugen moeten mogelijk handmatig worden aangepast, afhankelijk van de werklast.
Aurora biedt opties voor het schalen van leescapaciteit door het toevoegen van leesreplica’s, die het leesverkeer verdelen en de prestaties verbeteren.
Wanneer hoge beschikbaarheid cruciaal is, kan een Aurora-cluster worden geconfigureerd met meerdere replica’s over verschillende beschikbaarheidszones om failover-redundantie te waarborgen.
Prestaties Optimalisatie in AWS Aurora
Het optimaliseren van de prestaties in Amazon Aurora zorgt voor efficiënte query-uitvoering en schaalbaarheid. Laten we in dit gedeelte enkele best practices doornemen.
Indexering en query-optimalisatie
Het optimaliseren van de query-prestaties in Amazon Aurora is cruciaal voor het behouden van een hoogpresterende database.
- Indexering is een van de meest effectieve manieren om de query-uitvoeringstijd te verkorten en de efficiëntie van de database te verbeteren.
- Het creëren van indexen op vaak bevraagde kolommen kan helpen om gegevens snel te lokaliseren, waardoor de noodzaak voor volledige tabelscans wordt geminimaliseerd.
- Je moet strategisch gebruikmaken van primaire en secundaire indexen om aan te sluiten bij querypatronen en werklastvereisten.
- Naast het bovenstaande kun je samengestelde indexen gebruiken voor queries die meerdere kolommen omvatten om de opzoekingtijden verder te verbeteren.
- Query-optimalisatie speelt ook een significante rol in de prestaties van de database. Het schrijven van efficiënte SQL-queries zorgt ervoor dat Aurora verzoeken sneller verwerkt met een minimale verbruik van middelen.
- Het gebruik van
EXPLAIN of EXPLAIN ANALYZEin SQL-query’s helpt bij het identificeren van knelpunten en biedt inzicht in uitvoeringsplannen. - Technieken zoals het vermijden van
SELECT *(dat onnodige gegevens ophaalt), het normaliseren van de databaseschema om redundantie te verminderen en het benutten van partitioneringsstrategieën kunnen leiden tot prestatieverbeteringen. - De queryplan-optimizer van Aurora verfijnt continu uitvoeringsplannen, die aanpassingen maakt op basis van patronen in de database-werkbelasting, waardoor de algehele efficiëntie wordt verbeterd.
Het gebruik van Aurora-leesreplica’s
Om hoge verkeersbelastingen aan te kunnen, ondersteunt Amazon Aurora leesreplica’s die helpen bij het verdelen van leesintensieve query’s over meerdere instanties.
Leesreplica’s verminderen de belasting op de primaire database-instantie door leesverzoeken apart te verwerken, wat de reactiesnelheid verbetert en de latentie verlaagt.
Om een Aurora leesreplica in te stellen, moet je een bestaande Aurora-cluster selecteren en replicatie inschakelen met minimale configuratie. Aurora synchroniseert automatisch gegevens tussen de primaire instantie en zijn replica’s, waardoor gegevensconsistentie wordt gegarandeerd zonder handmatige interventie.
Het replicatiemechanisme van Aurora is zeer efficiënt en maakt bijna real-time gegevenssynchronisatie mogelijk met een replicatievertraging van minder dan een seconde.
Toepassingen die vaak leesbewerkingen uitvoeren, zoals rapportagedashboards of analytische services, kunnen aanzienlijk profiteren van leesreplica’s door leesintensieve query’s naar deze instanties te sturen.
In geval van een storing in de primaire instantie kan een read-replica worden gepromoveerd tot de nieuwe primaire instantie met minimale downtime, waardoor hoge beschikbaarheid en bedrijfscontinuïteit worden gewaarborgd.
De onderstaande afbeelding laat zien hoe cross-region Aurora-replica’s kunnen helpen bij rampenherstel en hoge beschikbaarheid.
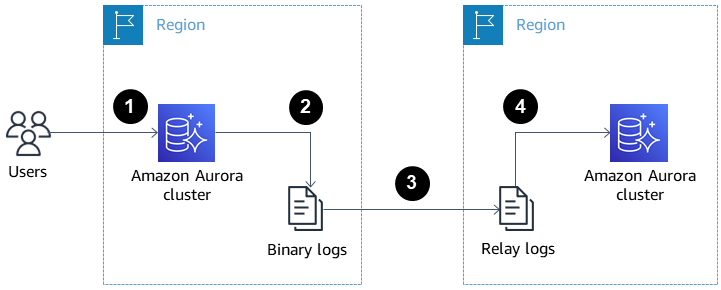
Cross-region Aurora read-replica’s voor rampenherstel en hoge beschikbaarheid. Bron: AWS Docs
Cachingstrategieën voor Aurora
Caching is een krachtige techniek om de prestaties van de database te verbeteren door directe query-belastingen op Aurora te verminderen. Een cachinglaag kan de gegevensopvraging aanzienlijk versnellen voor vaak opgevraagde queries.
Amazon ElastiCache, dat Redis en Memcached ondersteunt, wordt vaak gebruikt in combinatie met Aurora om queryresultaten op te slaan en redundante databasequery’s te voorkomen.
Het integreren van caching in een applicatie-architectuur kan helpen om de responstijden te verbeteren terwijl de rekenbronnen van de database behouden blijven.
Cachingstrategieën zoals write-through caching (waarbij gegevens gelijktijdig naar zowel de cache als Aurora worden geschreven) en lazy loading (waarbij gegevens alleen worden gecached wanneer daarom wordt gevraagd) helpen de prestaties te optimaliseren op basis van gebruikspatronen.
Het configureren van een geschikte time-to-live (TTL) voor gecachte gegevens zorgt ervoor dat de cache vers blijft en voorkomt het ophalen van verouderde gegevens.
Beveiliging en Naleving in AWS Aurora
Het beveiligen van uw Aurora-database is cruciaal voor het beschermen van gevoelige gegevens en het waarborgen van de naleving. Laten we in dit gedeelte de beste praktijken bekijken.
Data-encryptie
Data-beveiliging is fundamenteel voor databasebeheer, en AWS Aurora biedt robuuste versleutelingsmechanismen om gevoelige gegevens te beschermen.
- Aurora versleutelt gegevens in rust met behulp van AWS Key Management Service (KMS), waardoor wordt gegarandeerd dat opgeslagen informatie veilig blijft, zelfs als de onderliggende opslag wordt gecompromitteerd.
- Het inschakelen van versleuteling tijdens het maken van een database zorgt ervoor dat alle geautomatiseerde back-ups, snapshots en replica’s dezelfde versleutelingsinstellingen erven.
- Voor gegevens in transit ondersteunt Aurora SSL/TLS-versleuteling, die databaseverbindingen beveiligt en ongeautoriseerde toegang of onderschepping van datatransmissies voorkomt.
- Applicaties die verbinding maken met Aurora moeten geconfigureerd zijn om SSL-certificaten te gebruiken voor veilige communicatie.
Deze versleutelingsmaatregelen kunnen u helpen om te voldoen aan de beste beveiligingspraktijken en wettelijke vereisten.
De onderstaande afbeelding toont hoe AWS KMS integreert met Amazon Aurora om uw database te versleutelen.
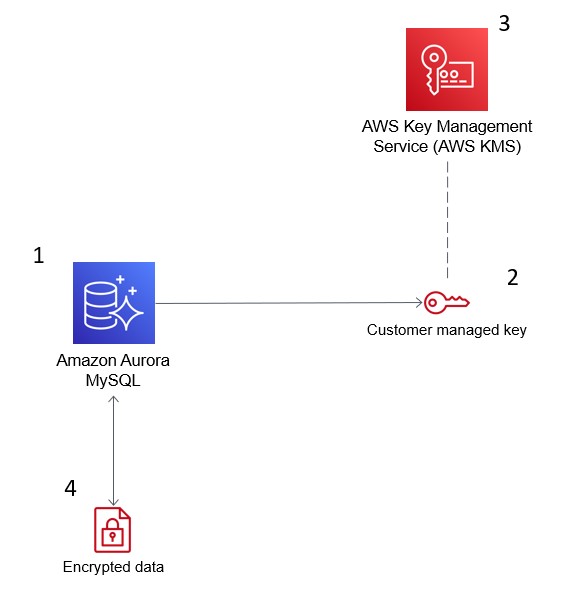
AWS Key Management Service (KMS) versleutelt gegevens in Amazon Aurora voor beveiligingsnaleving. Bron: AWS Blogs
Toegangscontrole met IAM
Toegangscontrole in Aurora wordt beheerd via AWS IAM, waarmee beheerders fijnmazige machtigingen kunnen definiëren op basis van gebruikersrollen.
- IAM-beleid kan worden gebruikt om toegang tot database-instanties te beperken, waardoor onbevoegde gebruikers geen kritieke handelingen zoals gegevenswijzigingen of beheertaken kunnen uitvoeren.
- IAM-authenticatie biedt een veiligere alternatieve voor traditionele op wachtwoorden gebaseerde authenticatie. Het stelt applicaties in staat om verbinding te maken met tijdelijke beveiligingsreferenties. Dit elimineert de noodzaak om databasewachtwoorden op te slaan en te beheren, waardoor het risico op blootstelling van referenties wordt verminderd.
U moet de principes van minimale toegangsrechten handhaven, die de beveiligingsrisico’s minimaliseren en strikte controle over database-toegang behouden.
De onderstaande afbeelding toont hoe IAM-authenticatie kan worden geconfigureerd om de toegang tot de Amazon Aurora PostgreSQL-database te beveiligen.
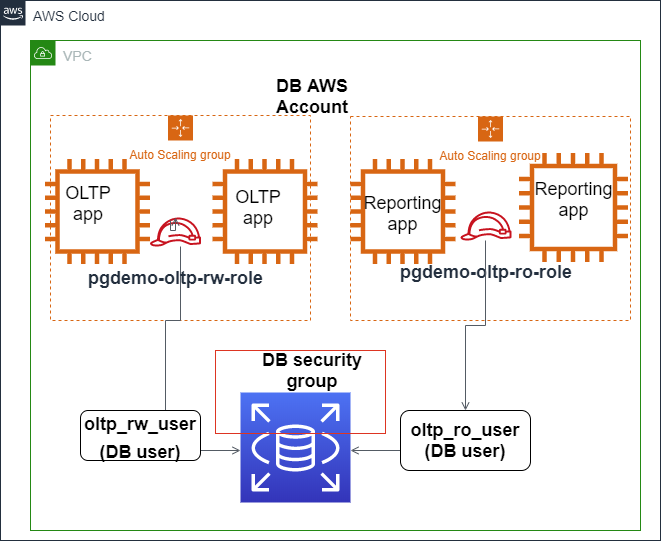
IAM-authenticatie integreert met Amazon Aurora PostgreSQL. Bron: AWS Blogs
Controleren met Aurora-logs
Monitoring en controleren van databaseactiviteiten is essentieel voor beveiligingsnaleving en probleemoplossing.
Aurora biedt verschillende logmechanismen, waaronder foutenlogs, langzame querylogs en algemene logs, die beheerders helpen bij het bijhouden van databaseactiviteiten en het identificeren van mogelijke problemen. Deze logs kunnen worden ingeschakeld via de AWS Management Console en worden opgeslagen in Amazon CloudWatch voor gecentraliseerde analyse.
- Foutenlogs leggen database-enginefouten en waarschuwingen vast.
- Langzame query logs helpen bij het identificeren van inefficiënte queries die de prestaties kunnen beïnvloeden.
Het analyseren van deze logs kan beheerders helpen om query-uitvoering te optimaliseren, ongeautoriseerde toegangspogingen te detecteren en database stabiliteit te waarborgen.
Kostenbeheer en optimalisatie in AWS Aurora
Om kosten effectief te beheren en optimaliseren in Amazon Aurora, moet u de prijsstructuur begrijpen. Laten we dit bekijken!
Begrip van Aurora prijsstelling
Het prijsmodel van Amazon Aurora is gebaseerd op verschillende factoren, waaronder exemplaaruur, opslagverbruik, I/O-verzoeken en gegevensoverdracht.
In tegenstelling tot traditionele databases die voorafgaande infrastructuurprovisionering vereisen, stelt het pay-as-you-go-model van Aurora bedrijven in staat alleen te betalen voor de resources die ze verbruiken.
Compute-instanties worden in rekening gebracht op basis van de instantieklasse en de uptime, terwijl opslag dynamisch wordt geschaald, waardoor handmatige aanpassingen overbodig zijn.
De onderstaande afbeelding geeft een uiteenzetting van de verschillende prijselementen voor Amazon Aurora. Houd er echter rekening mee dat de prijzen kunnen veranderen, dus het is altijd het beste om te verwijzen naar de Aurora prijspagina voor de meest actuele informatie.
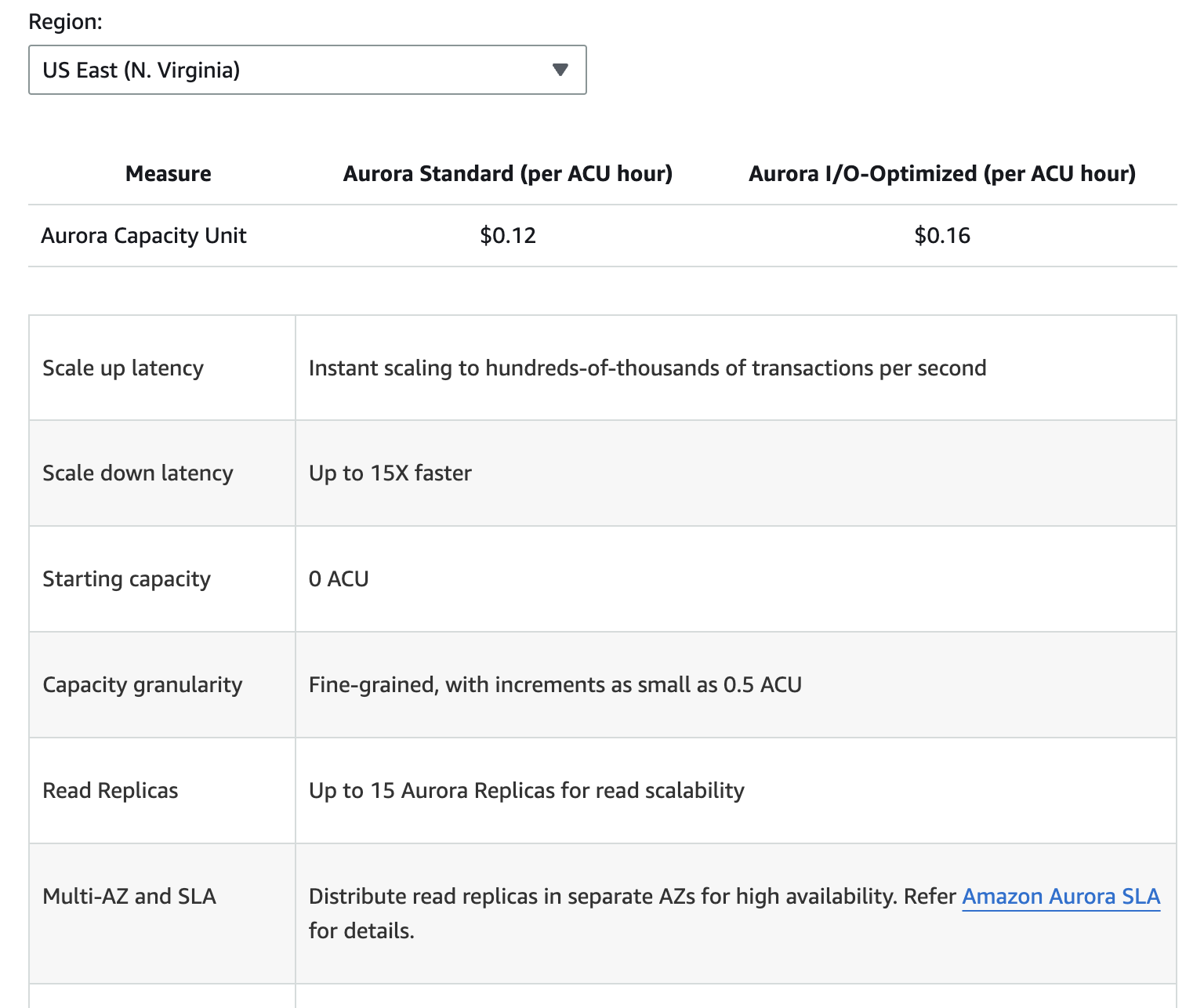
Extra kosten omvatten back-upopslag boven de toegewezen gratis limiet, lees- en schrijf-I/O-verzoeken, en datatransferkosten voor cross-region replicatie.
Het begrijpen van deze prijselementen kan u helpen bij het voorspellen van kosten en het nemen van geïnformeerde beslissingen met betrekking tot het gebruik van de database.
Kosten optimaliseren met Aurora
Om kosten effectief te beheren, kunnen organisaties verschillende optimalisatiestrategieën implementeren.
Door de juiste instantiegrootte te selecteren, zullen databasebronnen goed aansluiten bij werkbelastingsvereisten zonder overdimensionering.
- Als u een voorspelbare werkbelasting heeft, gebruik dan Gereserveerde instanties omdat ze aanzienlijke kostenbesparingen bieden in vergelijking met On-Demand prijzen.
- Opslagoptimalisatietechnieken, zoals het monitoren van onbenutte of onderbenutte middelen, helpen de kosten te verlagen.
- De auto-schaling-functie van Aurora past de opslag dynamisch aan, waardoor onnodige opslagkosten worden voorkomen.
- Bovendien kan het implementeren van leesreplica’s queries van de primaire instantie ontlasten, waardoor mogelijk de noodzaak voor duurdere instanties afneemt.
- Maak gebruik van Aurora Serverless, aangezien dit een andere kosteneffectieve optie is voor toepassingen met variabele werkbelastingen. Aurora Serverless schaalt automatisch rekencapaciteit op basis van de vraag, waardoor bedrijven alleen betalen voor daadwerkelijk gebruik in plaats van het onderhouden van een continu draaiende instantie.
> Als je meer inzicht wilt krijgen in kostenbeheer, verwijs dan naar de AWS Security and Cost Management cursus.
Conclusie
Na enige tijd met Amazon Aurora te hebben gewerkt bij verschillende bedrijven, kan ik met vertrouwen zeggen dat het een krachtige en schaalbare databaseoplossing is die het beheer vergemakkelijkt zonder in te boeten op prestaties—je zult het waarschijnlijk met me eens zijn na het doorlopen van deze tutorial.
Aurora is het overwegen waard als je op zoek bent naar een cloud-native relationele database die MySQL en PostgreSQL ondersteunt en tegelijkertijd de operationele overhead vermindert. Het is revolutionair geweest in enkele van mijn projecten, en ik raad sterk aan om naar de mogelijkheden ervan te kijken als je met AWS-databases werkt.
Als je nieuw bent met AWS-databases, kan het nuttig zijn om fundamentele concepten te leren via cursussen zoals AWS Cloud Practitioner (CLF-C02)!