













Usando o Amazon Aurora por um tempo agora em várias empresas, vi em primeira mão como ele se destaca como um mecanismo de banco de dados relacional totalmente gerenciado, oferecendo alto desempenho, escalabilidade e confiabilidade.
Como uma solução nativa da nuvem que suporta MySQL e PostgreSQL, o Aurora é uma excelente escolha para empresas que exigem alta disponibilidade e dimensionamento automático. Como a AWS gerencia backups, failover e replicação automaticamente, usar o Aurora permite aumentar a eficiência do banco de dados enquanto reduz os custos de manutenção.
Neste tutorial, vou orientá-lo na configuração de uma instância do Aurora, gerenciando-a de forma eficiente, otimizando o desempenho e garantindo segurança e custo-efetividade.
O que é o AWS Aurora?
O Amazon Aurora é um banco de dados relacional baseado em nuvem que supera o MySQL e PostgreSQL tradicionais ao escalar dinamicamente os recursos de armazenamento e computação.
De acordo com a AWS, o Aurora pode fornecer até cinco vezes o throughput do MySQL padrão e três vezes o desempenho do PostgreSQL padrão – devido à sua arquitetura distribuída e altamente disponível.
O Aurora é construído com recursos como backups automatizados, réplicas de leitura para escalonamento horizontal e mecanismos de failover que garantem um tempo de inatividade mínimo.
A camada de armazenamento do Aurora é projetada para ser tolerante a falhas e auto-reparável.
Além disso, os dados são automaticamente replicados em várias Zones de Disponibilidade (AZs) para garantir durabilidade.
A imagem abaixo fornece uma visão geral da arquitetura e principais recursos do Amazon Aurora.
A relação entre o volume do cluster, instância de banco de dados escritor e instâncias de banco de dados leitor em um cluster Aurora. Fonte: Documentos da AWS
O mecanismo de banco de dados monitora continuamente as consultas e otimiza os planos de execução, resultando em melhorias significativas de eficiência.
Um dos principais benefícios do Aurora é sua compatibilidade com bancos de dados MySQL e PostgreSQL existentes, o que facilita a migração para as empresas sem a necessidade de modificar extensivamente suas aplicações.
A estrutura de custos do Aurora também é atraente. Ele cobra com base no uso real de recursos de computação e armazenamento. Esse modelo de custo elimina a necessidade de superprovisionar a infraestrutura, o que, por sua vez, economiza dinheiro.
> Se você estiver interessado em uma compreensão mais ampla das opções de armazenamento da AWS, confira este Tutorial de Armazenamento da AWS.
Configurando o AWS Aurora
Configurar o AWS Aurora envolve criar um cluster de banco de dados, configurar as configurações de segurança e garantir o acesso adequado à rede. Vamos fazer isso nesta seção!
> Se você é novo no AWS, considere revisar tópicos fundamentais com oo Curso de Introdução ao AWS antes de mergulhar no Aurora.
Criando um cluster de banco de dados Aurora
Configurar um cluster de banco de dados Aurora requer algumas etapas-chave, incluindo selecionar o mecanismo de banco de dados apropriado, configurar as configurações de segurança e definir as especificações da instância.
- Para começar, faça login no Console de Gerenciamento da AWS e navegue até o painel do RDS (Serviço de Banco de Dados Relacional).
- Você pode fazer isso procurando por “Aurora” no painel de busca do console de gerenciamento da AWS – conforme mostrado na imagem abaixo.
- Uma vez lá, clique em “Criar Banco de Dados” – conforme mostrado na imagem abaixo.
- Você terá então a opção de escolher “Amazon Aurora” como o mecanismo do banco de dados.
- Lembre-se de que o Aurora suporta tanto MySQL quanto PostgreSQL, portanto, é importante selecionar a versão que melhor atenda aos requisitos da sua aplicação.
A imagem abaixo mostra as opções de mecanismo que estão atualmente disponíveis. Essas opções podem mudar no futuro, mas as duas primeiras opções—Aurora (Compatível com MySQL) e Aurora (Compatível com PostgreSQL)—são os mecanismos do Aurora.
- Após selecionar o mecanismo, você deve especificar o tipo de instância e as configurações de armazenamento.
- O Aurora oferece a flexibilidade de escalar automaticamente o armazenamento até 128TB, garantindo que cargas de trabalho em crescimento sejam tratadas de forma eficiente sem necessidade de intervenção manual.
- O próximo passo é definir as configurações de replicação. Você pode optar por uma implantação de instância única ou habilitar réplicas de leitura para distribuir o tráfego do banco de dados de forma mais eficaz.
- O uso de réplicas de leitura também melhora a disponibilidade e a tolerância a falhas, garantindo maior durabilidade em caso de falhas.
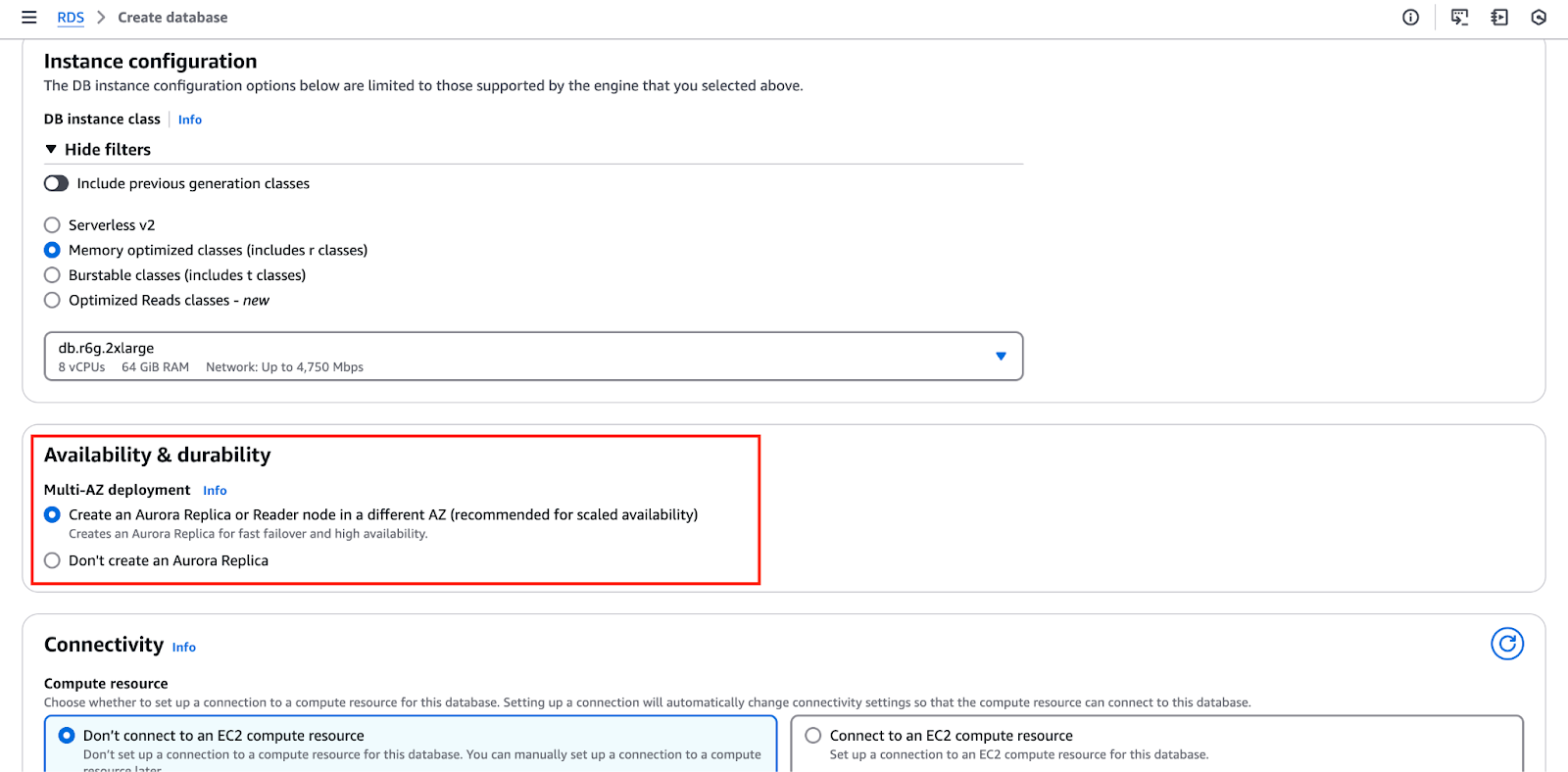
A imagem abaixo destaca a seção “Disponibilidade e durabilidade”, onde você pode configurar essas definições.
- A etapa de configuração de rede é crucial, pois envolve a configuração da Virtual Private Cloud (VPC), a seleção de um grupo de segurança e a definição de controles de acesso.
- Um grupo de segurança atua como um firewall que regula o tráfego de banco de dados de entrada e saída. Para aprimorar a segurança, recomenda-se que você permita o acesso apenas de endereços IP e aplicativos confiáveis.
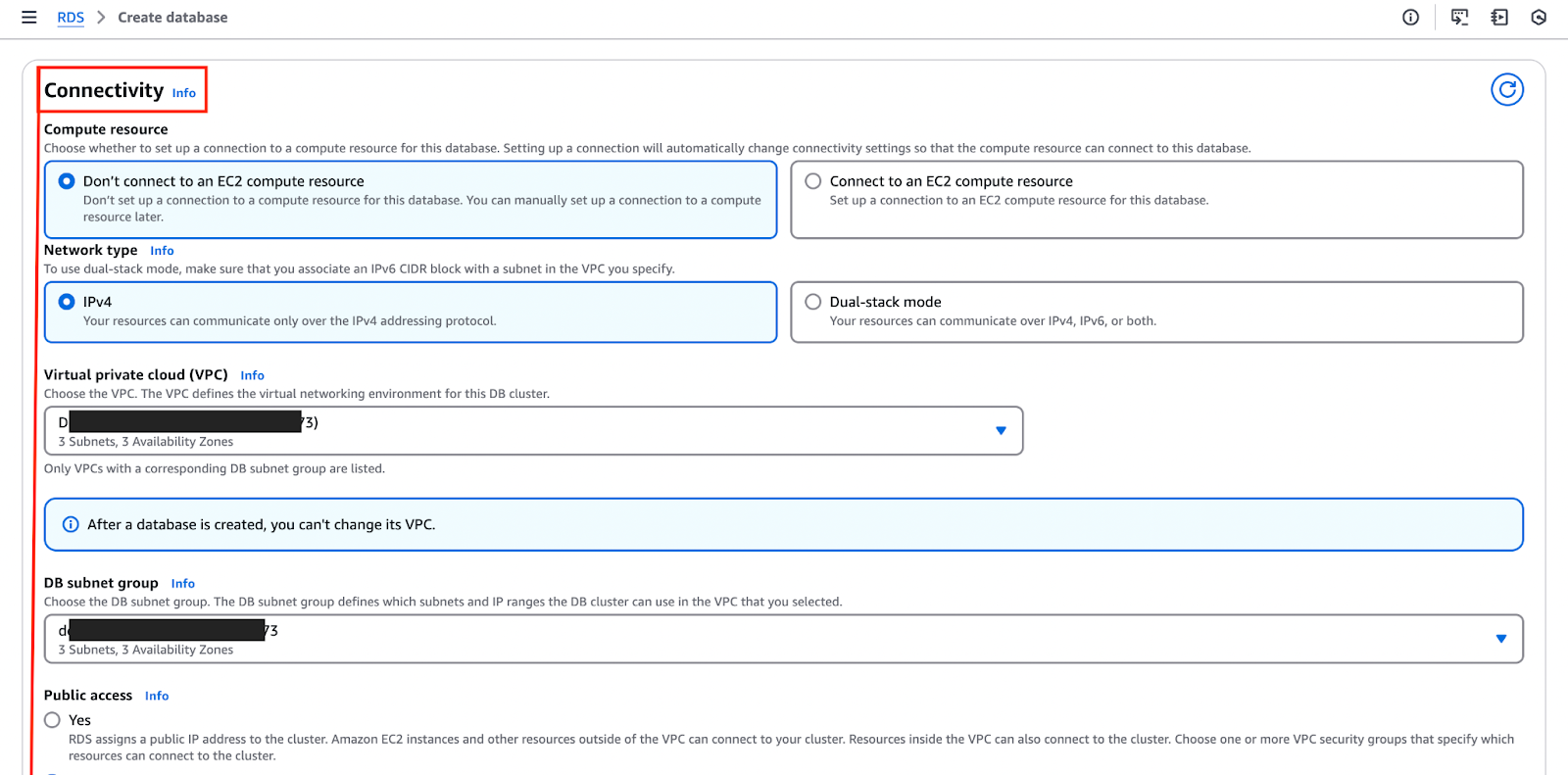
A imagem abaixo destaca a “Conectividade” seção, onde você pode configurar e personalizar essas configurações.
- As credenciais do banco de dados também devem ser configuradas durante a configuração – onde você atribui um nome de usuário mestre e uma senha que serão usados para autenticar as conexões.
- O Aurora permite que backups automatizados e opções de recuperação ponto no tempo sejam ativados. Isso garante que snapshots do banco de dados sejam criados de forma consistente para evitar perda de dados.
Após revisar todas as configurações, você pode prosseguir com a criação do cluster Aurora. A imagem abaixo mostra o botão “Criar Banco de Dados” que você pode clicar para iniciar o processo de criação.
O processo de provisionamento pode levar vários minutos, dependendo do tamanho da instância selecionada e das configurações de rede.
> Se você é novo nos serviços da AWS, revisar o curso de Tecnologia e Serviços da AWS pode ajudá-lo a entender conceitos-chave da AWS relevantes para a configuração do Aurora.
Configurando rede e segurança
A segurança é crítica para gerenciar um banco de dados Aurora, e a AWS fornece várias ferramentas para impor controles de acesso fortes.
- O primeiro passo para proteger uma instância do Aurora é configurar grupos de segurança da VPC. Esses grupos de segurança determinam quais endereços IP e serviços podem interagir com o banco de dados.
- Você deve limitar o acesso a servidores de aplicativos específicos e administradores para evitar conexões não autorizadas.
- O AWS Identity and Access Management (IAM) também pode ser usado para definir permissões detalhadas para operações de banco de dados.
- A integração de funções do IAM permite personalizar o acesso ao banco de dados de acordo com as funções e responsabilidades específicas do usuário.
- Por exemplo, os desenvolvedores de aplicativos podem ter acesso apenas para leitura, enquanto os administradores terão controle total sobre as modificações no banco de dados.
- A criptografia também deve ser ativada para proteger dados sensíveis. O AWS Aurora suporta criptografia em repouso e em trânsito usando o AWS Key Management Service (KMS).
- A criptografia de dados em repouso garante que, mesmo se o meio de armazenamento for comprometido, os dados permaneçam inacessíveis sem a chave de descriptografia adequada.
- Da mesma forma, habilitar a criptografia de Secure Sockets Layer (SSL) para dados em trânsito evita a interceptação não autorizada das comunicações do banco de dados.
> Para uma análise mais aprofundada sobre a segurança de ambientes AWS, dê uma olhada no curso deSegurança e Gerenciamento de Custos da AWS. Se você deseja aprender mais sobre como o IAM funciona e como implementá-lo de forma eficaz, dê uma olhada neste guia sobre o AWS Identity and Access Management (IAM).
Conectando-se ao AWS Aurora
Conectar-se ao AWS Aurora é essencial para interagir com o banco de dados. Você pode fazer isso por meio de ferramentas de cliente ou aplicativos. Vamos ver como nesta seção!
Conectando-se ao Aurora MySQL
Depois que o banco de dados Aurora estiver funcionando, você precisa estabelecer uma conexão para começar a interagir com o banco de dados.
Para o Aurora MySQL, clientes de banco de dados comuns como MySQL Workbench e HeidiSQL podem ser usados para se conectar. Alternativamente, você pode usar interfaces de linha de comando.
A conexão requer a especificação do endpoint do banco de dados, que pode ser encontrado no AWS Management Console.
Usando o MySQL CLI, a conexão pode ser estabelecida com o seguinte comando:
mysql -h your-cluster-endpoint -u admin -p
Após inserir a senha mestre, você deve ser capaz de executar consultas SQL, criar tabelas e gerenciar dados.
Conectando ao Aurora PostgreSQL
Para o Aurora PostgreSQL, você pode se conectar usando ferramentas como pgAdmin ou a interface de linha de comando do PostgreSQL (psql).
O comando de conexão em psql segue este formato:
psql -h your-cluster-endpoint -U admin -d yourdatabasename
Assim como no MySQL, as credenciais corretas devem ser inseridas para acessar o banco de dados.
Uma vez que você tenha obtido acesso, deverá ser capaz de executar consultas SQL, criar tabelas e gerenciar dados.
Configurando a conectividade da aplicação
Aplicações que precisam interagir com o Aurora devem ser configuradas com as strings de conexão de banco de dados apropriadas. Normalmente, essas strings de conexão consistem no nome de usuário, senha, número da porta e endpoint.
É recomendado que você use o pooling de conexões para otimizar o desempenho e reduzir a sobrecarga de estabelecer novas conexões para cada solicitação.
Bibliotecas populares como SQLAlchemy para Python ou JDBC para Java oferecem maneiras eficientes de gerenciar conexões em um ambiente de aplicativo.
Gerenciando o AWS Aurora
Gerenciar efetivamente o AWS Aurora envolve garantir a proteção dos dados, monitorar o desempenho e escalar recursos conforme necessário. Nesta seção, revisaremos essas práticas.
Backups e instantâneos
O AWS Aurora oferece backups automatizados que capturam e armazenam continuamente as alterações do banco de dados no Amazon S3. Esses backups são retidos com base nas configurações definidas pelo usuário, permitindo a restauração a qualquer ponto dentro do período de retenção.
Além dos backups automatizados, você também pode criar instantâneos manuais que persistem além da janela de retenção. Instantâneos manuais são particularmente úteis para arquivamento de longo prazo ou antes de realizar grandes atualizações no banco de dados.
Quando trabalhei em um projeto com uma aplicação crítica, agendamos backups automatizados a cada duas horas. No entanto, antes de fazer quaisquer alterações ou atualizações na aplicação, criávamos manualmente um backup para garantir que pudéssemos reverter se necessário. Isso demonstra como os backups automatizados e manuais podem ser usados efetivamente juntos.
A imagem abaixo mostra como o AWS Backup pode ser utilizado para recuperação de desastres com o Amazon Aurora.
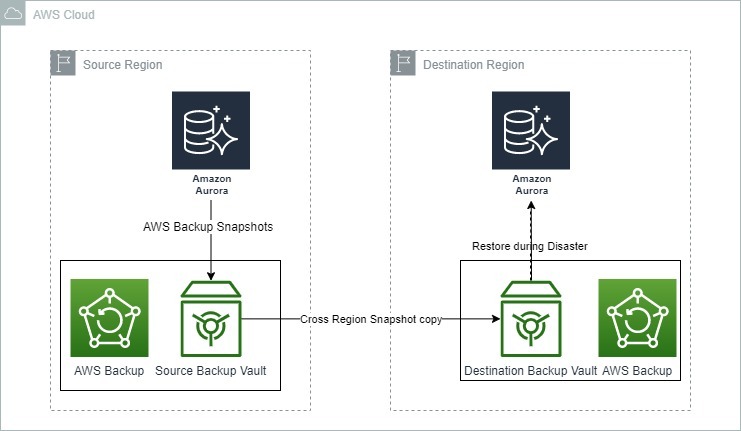
Opções de backup e recuperação para o Amazon Aurora. Fonte: Blogs da AWS
Monitorando o Aurora com o CloudWatch
O monitoramento de desempenho é essencial para manter um banco de dados saudável.
O AWS CloudWatch fornece métricas em tempo real que rastreiam a utilização da CPU, o uso da memória, o I/O de disco e o tráfego de rede.
Configurar Alarmes do CloudWatch pode ajudar administradores a serem notificados quando os limites de desempenho são excedidos, permitindo uma gestão proativa do banco de dados.
Além disso, o AWS Performance Insights oferece uma análise detalhada de consultas para identificar e otimizar consultas que estão demorando para ser executadas.
A imagem abaixo demonstra como o AWS Performance Insights fornece insights sobre o desempenho do banco de dados.
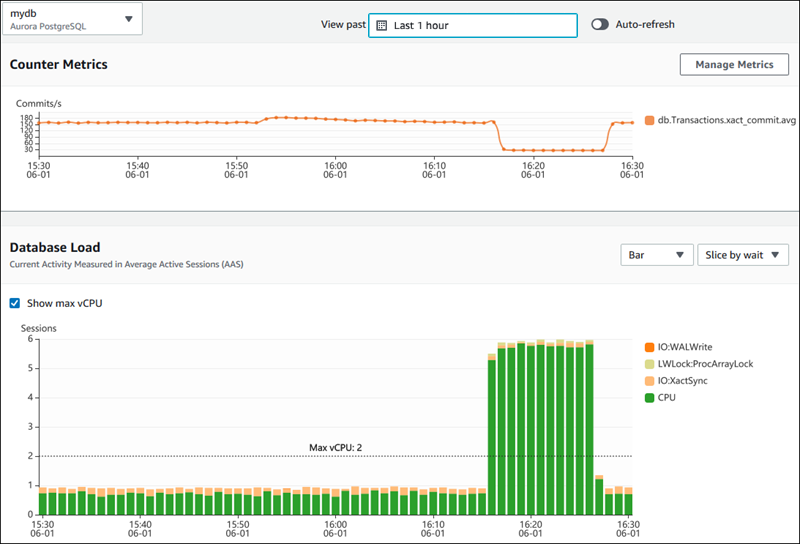
Dashboard do AWS Performance Insights exibindo métricas de desempenho do banco de dados. Fonte: Documentos da AWS
Escalonando o Aurora
O Aurora foi projetado para escalar automaticamente ajustando a capacidade de armazenamento conforme necessário. No entanto, os recursos de computação, como CPUs e memória, podem precisar ser ajustados manualmente dependendo da carga de trabalho.
Aurora oferece opções para escalar a capacidade de leitura adicionando réplicas de leitura, que distribuem o tráfego de leitura e melhoram o desempenho.
Quando a alta disponibilidade é crítica, um cluster Aurora pode ser configurado com várias réplicas em diferentes Zonas de Disponibilidade para garantir redundância em caso de falha.
Otimização de Desempenho no AWS Aurora
Otimizar o desempenho no Amazon Aurora garante execução de consultas eficiente e escalabilidade. Vamos revisar algumas melhores práticas nesta seção.
Indexação e otimização de consultas
Otimizar o desempenho das consultas no Amazon Aurora é crucial para manter um banco de dados de alto desempenho.
- A indexação é uma das maneiras mais eficazes de reduzir o tempo de execução das consultas e aumentar a eficiência do banco de dados.
- Criar índices em colunas frequentemente consultadas pode ajudar a localizar dados rapidamente, minimizando a necessidade de varreduras completas de tabela.
- Você deve usar estrategicamente índices primários e secundários para alinhar com os padrões de consulta e as demandas de carga de trabalho.
- Além do acima, você pode empregar índices compostos para consultas que envolvem várias colunas para melhorar ainda mais os tempos de busca.
- A otimização de consultas também desempenha um papel significativo no desempenho do banco de dados. Escrever consultas SQL eficientes garante que o Aurora processe solicitações mais rapidamente, com consumo mínimo de recursos.
- Usar
EXPLAIN ou EXPLAIN ANALYZEem consultas SQL ajuda a identificar gargalos e fornece insights sobre planos de execução. - Técnicas como evitar
SELECT *(que recupera dados desnecessários), normalizar o esquema do banco de dados para reduzir redundância e aproveitar estratégias de particionamento podem levar a ganhos de desempenho. - O otimizador de plano de consulta do Aurora refina continuamente os planos de execução, fazendo ajustes com base nos padrões de carga de trabalho do banco de dados, aprimorando assim a eficiência geral.
Usando réplicas de leitura do Aurora
Para lidar com cargas de tráfego elevado, o Amazon Aurora suporta réplicas de leitura que ajudam a distribuir consultas intensivas em leitura entre várias instâncias.
Réplicas de leitura reduzem a carga na instância do banco de dados primário ao processar solicitações de leitura separadamente, o que melhora a capacidade de resposta e diminui a latência.
Para configurar uma réplica de leitura Aurora, você precisará selecionar um cluster Aurora existente e habilitar a replicação com uma configuração mínima. Aurora sincroniza automaticamente os dados entre a instância primária e suas réplicas, garantindo consistência de dados sem intervenção manual.
O mecanismo de replicação do Aurora é altamente eficiente, permitindo sincronização de dados em quase tempo real com um atraso de replicação de menos de um segundo.
Aplicações que realizam operações de leitura frequentes, como painéis de relatórios ou serviços de análise, podem se beneficiar significativamente das réplicas de leitura, direcionando consultas pesadas de leitura para essas instâncias.
No caso de uma falha na instância principal, uma réplica de leitura pode ser promovida para se tornar a nova instância principal com um tempo de inatividade mínimo, garantindo alta disponibilidade e continuidade dos negócios.
A imagem abaixo mostra como réplicas do Aurora entre regiões podem ajudar na recuperação de desastres e alta disponibilidade.
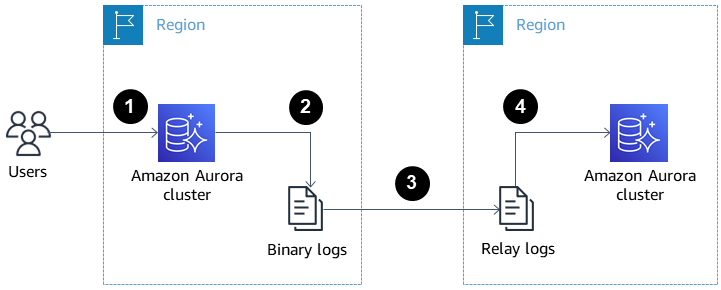
Réplicas de leitura do Aurora entre regiões para recuperação de desastres e alta disponibilidade. Fonte: Documentos da AWS
Estratégias de cache para o Aurora
O cache é uma técnica poderosa para melhorar o desempenho do banco de dados, reduzindo as cargas de consulta direta no Aurora. Uma camada de cache pode acelerar significativamente a recuperação de dados para consultas frequentemente acessadas.
O Amazon ElastiCache, que suporta Redis e Memcached, é comumente usado ao lado do Aurora para armazenar resultados de consultas e evitar consultas redundantes ao banco de dados.
A integração de cache em uma arquitetura de aplicativo pode ajudar a melhorar os tempos de resposta enquanto preserva os recursos de computação do banco de dados.
Estratégias de cache como o write-through caching (onde os dados são escritos tanto no cache quanto no Aurora simultaneamente) e o lazy loading (onde os dados são armazenados em cache somente quando solicitados) ajudam a otimizar o desempenho com base nos padrões de uso.
Configurar um tempo de vida útil (TTL) apropriado para os dados em cache garante que o cache permaneça atualizado e evita a recuperação de dados obsoletos.
Segurança e Conformidade no AWS Aurora
Proteger seu banco de dados Aurora é crucial para proteger dados sensíveis e garantir conformidade. Vamos revisar as melhores práticas nesta seção.
Criptografia de dados
A segurança dos dados é fundamental para a gestão de bancos de dados, e o AWS Aurora fornece mecanismos de criptografia robustos para proteger dados sensíveis.
- O Aurora criptografa dados em repouso usando o AWS Key Management Service (KMS), o que garante que as informações armazenadas permaneçam seguras mesmo que o armazenamento subjacente seja comprometido.
- A ativação da criptografia durante a criação do banco de dados garante que todos os backups automatizados, snapshots e réplicas herdem as mesmas configurações de criptografia.
- Para dados em trânsito, o Aurora suporta criptografia SSL/TLS, que garante conexões de banco de dados e previne acesso não autorizado ou interceptação de transmissões de dados.
- Aplicações conectadas ao Aurora devem ser configuradas para usar certificados SSL a fim de manter a comunicação segura.
Essas medidas de criptografia podem ajudá-lo a cumprir as melhores práticas de segurança e requisitos regulatórios.
A imagem abaixo demonstra como o AWS KMS integra-se ao Amazon Aurora para criptografar seu banco de dados.
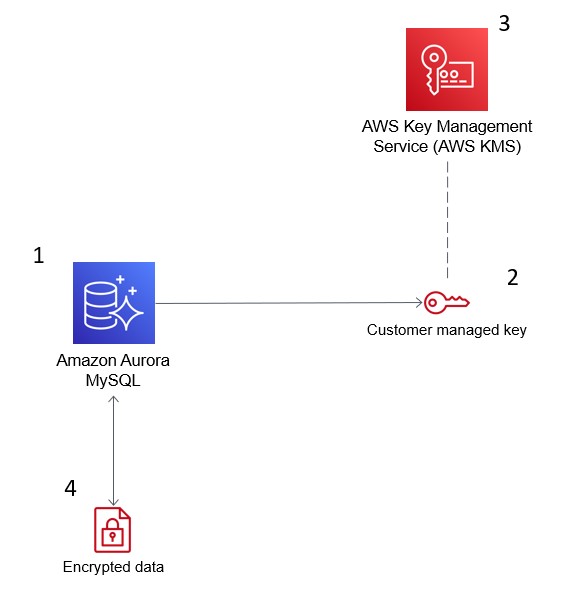
O AWS Key Management Service (KMS) criptografa dados no Amazon Aurora para conformidade de segurança. Fonte: Blogs da AWS
Integração do IAM para controle de acesso
O controle de acesso no Aurora é gerenciado por meio do AWS IAM, que permite aos administradores definir permissões detalhadas com base em funções de usuário.
- As políticas do IAM podem ser usadas para restringir o acesso às instâncias do banco de dados, impedindo que usuários não autorizados realizem operações críticas, como modificações de dados ou tarefas administrativas.
- A autenticação IAM fornece uma alternativa mais segura à autenticação tradicional baseada em senha. Permite que aplicativos se conectem usando credenciais de segurança temporárias. Isso elimina a necessidade de armazenar e gerenciar senhas de banco de dados, reduzindo o risco de exposição de credenciais.
Você deve aplicar os princípios de acesso de privilégio mínimo, que minimizam os riscos de segurança e mantêm um controle rígido sobre o acesso ao banco de dados.
A imagem abaixo mostra como a autenticação IAM pode ser configurada para garantir o acesso seguro ao banco de dados Amazon Aurora PostgreSQL.
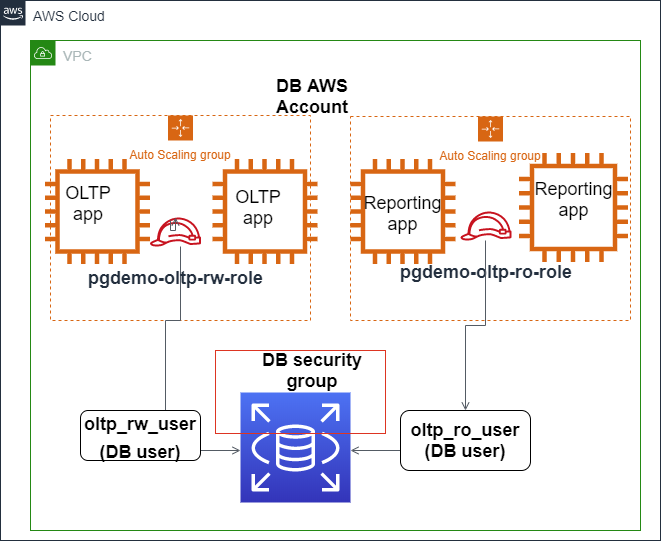
A autenticação IAM integra-se com o Amazon Aurora PostgreSQL. Fonte: Blogs da AWS
Auditoria com logs do Aurora
Monitorar e auditar a atividade do banco de dados é essencial para conformidade de segurança e solução de problemas.
O Aurora fornece vários mecanismos de registro, incluindo logs de erro, logs de consultas lentas e logs gerais, que ajudam os administradores a rastrear a atividade do banco de dados e identificar possíveis problemas. Esses logs podem ser ativados por meio do Console de Gerenciamento da AWS e armazenados no Amazon CloudWatch para análise centralizada.
- Logs de erro capturam erros e avisos do motor do banco de dados.
- Logs de consultas lentas ajudam a identificar consultas ineficientes que podem impactar o desempenho.
Analisar esses logs pode ajudar os administradores a otimizar a execução de consultas, detectar tentativas de acesso não autorizadas e garantir a estabilidade do banco de dados.
Gestão e Otimização de Custos no AWS Aurora
Para gerenciar e otimizar efetivamente os custos no Amazon Aurora, você deve entender sua estrutura de preços. Vamos revisá-la!
Entendendo a precificação do Aurora
O modelo de preços do Amazon Aurora é baseado em vários fatores, incluindo horas de instância, consumo de armazenamento, solicitações de I/O e transferência de dados.
Diferente dos bancos de dados tradicionais que requerem provisionamento de infraestrutura antecipado, o modelo pay-as-you-go do Aurora permite que as empresas paguem apenas pelos recursos que consomem.
As instâncias de computação são faturadas com base na classe da instância e no tempo de atividade, enquanto o armazenamento é dimensionado dinamicamente, eliminando a necessidade de ajustes manuais.
A imagem abaixo fornece uma análise detalhada dos diferentes componentes de preços para o Amazon Aurora. No entanto, é importante lembrar que os preços podem mudar, então é sempre melhor consultar a página de preços do Aurora para obter as informações mais atualizadas.
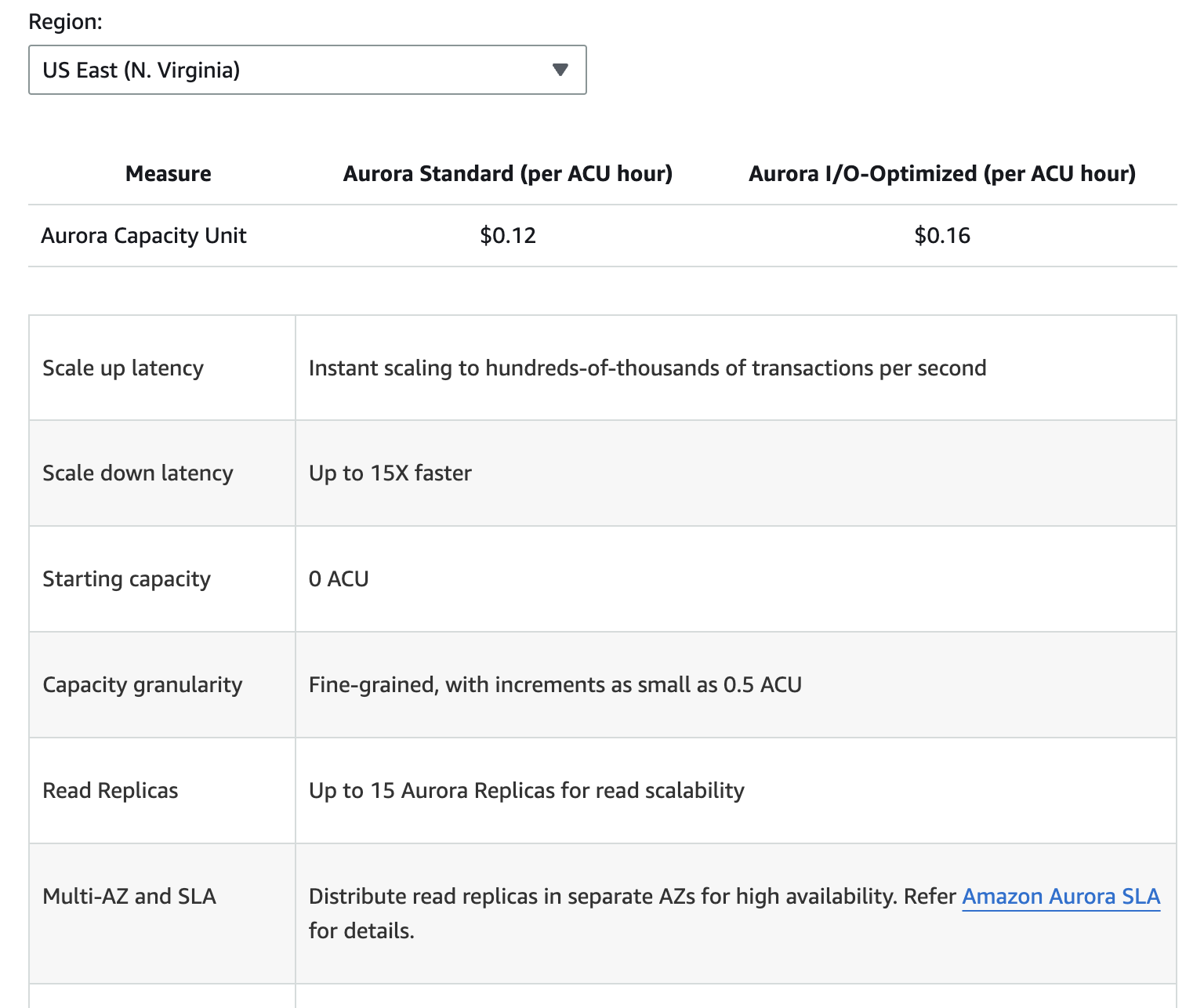
Os custos adicionais incluem armazenamento de backup além do limite gratuito alocado, solicitações de leitura e gravação de E/S, e taxas de transferência de dados para replicação entre regiões.
Compreender esses componentes de preços pode ajudar a prever despesas e tomar decisões informadas sobre o uso do banco de dados.
Otimização de custos com Aurora
Para gerenciar custos de forma eficaz, as organizações podem implementar várias estratégias de otimização.
Selecionar o tamanho de instância adequado garantirá que os recursos do banco de dados estejam alinhados com as demandas de carga de trabalho, sem superprovisionamento.
- Se você tiver uma carga de trabalho previsível, use Instâncias Reservadas, pois elas oferecem economias significativas em comparação com a precificação sob demanda.
- Técnicas de otimização de armazenamento, como monitoramento de recursos não utilizados ou subutilizados, ajudam a reduzir custos.
- A funcionalidade de escala automática da Aurora ajusta o armazenamento de forma dinâmica, prevenindo despesas desnecessárias com armazenamento.
- Além disso, a implementação de réplicas de leitura pode aliviar consultas da instância principal, potencialmente reduzindo a necessidade de instâncias de nível superior.
- Aproveite Aurora Serverless, pois é outra opção econômica para aplicações com cargas de trabalho variáveis. O Aurora Serverless escala automaticamente os recursos de computação com base na demanda, o que garante que as empresas paguem apenas pelo uso real em vez de manter uma instância em execução continuamente.
> Se você deseja obter mais insights sobre gestão de custos, consulte o curso de Segurança e Gestão de Custos da AWS.
Conclusão
Depois de trabalhar com o Amazon Aurora em várias empresas por um bom tempo, posso afirmar com confiança que é uma solução de banco de dados poderosa e escalável que facilita a gestão sem comprometer o desempenho—provavelmente você concordará depois de passar por este tutorial.
O Aurora vale a pena considerar se você está procurando um banco de dados relacional nativo da nuvem que suporte MySQL e PostgreSQL enquanto reduz a sobrecarga operacional. Tem sido revolucionário em alguns dos meus projetos, e recomendo fortemente que você explore suas capacidades se estiver trabalhando com bancos de dados da AWS.
Se você é novo em bancos de dados da AWS, aprender conceitos fundamentais através de cursos como AWS Cloud Practitioner (CLF-C02) pode ser benéfico!