













Arquiteturas modernas nativas da nuvem exigem soluções robustas, escaláveis e seguras para processamento de logs a fim de monitorar aplicações distribuídas. Este estudo apresenta uma solução híbrida para coleta, agregação e análise de logs utilizando o Azure Kubernetes Service (AKS) para geração de logs, Fluent Bit para coleta de logs, Azure EventHub para agregação intermediária e Splunk implantado em um cluster Apache CloudStack local para indexação e visualização abrangente de logs.
Detalhamos o design, a implementação e a avaliação do sistema, demonstrando como esta arquitetura suporta o processamento de logs confiável e escalável para cargas de trabalho nativas da nuvem, mantendo o controle sobre os dados no local.
Introdução
Soluções de logging centralizado tornaram-se indispensáveis. Aplicações modernas, particularmente aquelas construídas em arquiteturas de microserviços, geram grandes volumes de logs, muitas vezes em formatos diversos e de múltiplas fontes. Esses logs são a principal fonte para monitorar o desempenho da aplicação, diagnosticar problemas e garantir a confiabilidade geral do sistema. No entanto, gerenciar volumes tão altos de dados de log apresenta desafios significativos, especialmente em ambientes de nuvem híbrida que abrangem tanto infraestrutura local quanto baseada na nuvem.
Soluções de registro tradicionais, embora eficazes para aplicações monolíticas, têm dificuldade em escalar sob as demandas de arquiteturas baseadas em microsserviços. A natureza dinâmica dos microsserviços, caracterizada por implantações independentes e atualizações frequentes, produz um fluxo contínuo de logs, cada um variando em formato e estrutura. Esses logs devem ser ingeridos, processados e analisados em tempo real para fornecer insights acionáveis. Além disso, à medida que as aplicações operam cada vez mais em ambientes híbridos, garantir a segurança e os dados de PII se torna primordial, dadas as variadas exigências de conformidade e regulamentares.
Este artigo apresenta uma solução abrangente que aborda esses desafios, aproveitando as capacidades combinadas dos recursos Azure e Apache CloudStack. Ao integrar a escalabilidade e as capacidades analíticas do Azure com a flexibilidade e a economia de custos da infraestrutura local do CloudStack, essa solução oferece uma abordagem robusta e unificada para o registro centralizado.
Revisão da Literatura
A coleta de logs centralizada em microsserviços enfrenta desafios como latência de rede, formatos de dados diversos e segurança em várias camadas. Embora agentes leves como Fluent Bit e FluentD sejam amplamente utilizados, o transporte eficiente de logs continua sendo um desafio.
Soluções como o stack ELK e o Azure Monitor oferecem processamento centralizado de logs, mas normalmente envolvem implementações apenas na nuvem ou apenas no local, limitando a flexibilidade em implantações híbridas. As soluções de nuvem híbrida permitem que as organizações aproveitem a escalabilidade da nuvem, mantendo o controle sobre dados sensíveis em ambientes locais. Pipelines híbridos de processamento de logs, especialmente aqueles que utilizam tecnologias de streaming de eventos, abordam a necessidade de transporte e agregação escaláveis de logs.
Arquitetura do Sistema
A arquitetura, ilustrada abaixo, integra o Azure EventHub e o AKS com o Apache CloudStack e o Splunk no local. Cada componente é otimizado para processamento eficiente de logs e transferência segura de dados entre os ambientes.
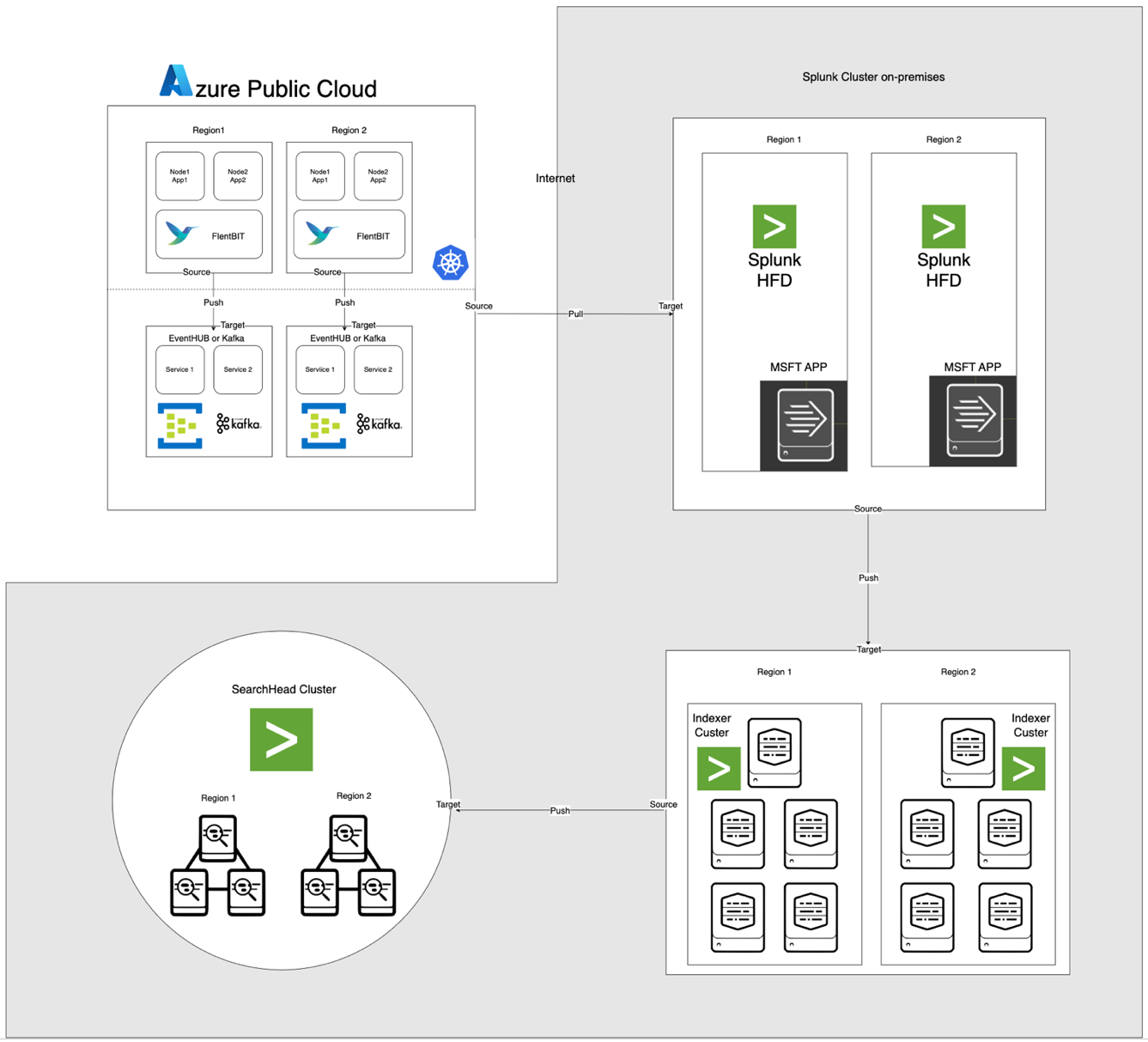
Descrições dos Componentes
- AKS: Hospeda aplicativos containerizados e gera logs acessíveis através da camada de agregação de logs do Kubernetes.
- Fluent Bit: Implementado como um DaemonSet, coleta logs dos nós AKS. Cada instância do Fluent Bit captura logs de /var/log/containers, os filtra e os encaminha no formato JSON para o EventHub.
- Azure EventHub: Atua como um corretor de mensagens de alto rendimento, agregando logs do Fluent Bit e armazenando-os temporariamente até serem extraídos pelo Splunk Heavy Forwarder.
- Apache Kafka: Atua como uma ponte confiável entre o Fluent Bit e o Splunk. O Fluent Bit encaminha logs para o Kafka usando seu plugin de saída do Kafka, onde os logs são armazenados e processados temporariamente. O Splunk então consome os logs do Kafka usando conectores como o Kafka Connect Splunk Sink ou scripts personalizados, garantindo uma arquitetura escalável e desacoplada.
- Splunk Heavy Forwarder (HF): Instalado no Apache CloudStack, o Heavy Forwarder recupera logs do Azure EventHub usando o Splunk Add-on for Microsoft Cloud Services. Este complemento fornece uma integração perfeita, permitindo que o Heavy Forwarder se conecte de forma segura ao EventHub, recupere logs quase em tempo real e os transforme conforme necessário antes de encaminhá-los para o indexador do Splunk para armazenamento e processamento
- Splunk no Apache CloudStack: Fornece indexação de logs, pesquisa, visualização e alerta.
Fluxo de Dados
- Coleta de logs no AKS: O Fluent Bit monitora arquivos de log em /var/log/containers, filtrando logs desnecessários e marcando cada log com metadados (por exemplo, nome do contêiner, namespace).
- Encaminhamento para o EventHub: Logs são enviados para o EventHub via HTTPS usando o plugin de saída azure_eventhub do Fluent Bit, garantindo uma transmissão de dados segura.
- Apache Kafka: Os logs do AKS são coletados pelo Fluent Bit, que roda como um DaemonSet, que analisa e os encaminha para o Apache Kafka através de seu plugin de saída Kafka. O Kafka atua como um buffer de alta capacidade, armazenando e particionando logs para escalabilidade. O Splunk ingere esses logs do Kafka usando conectores ou scripts, permitindo indexação, análise e monitoramento em tempo real.
- Puxando logs com o Splunk Heavy Forwarder: O Heavy Forwarder no Apache CloudStack conecta-se ao EventHub usando o SDK do EventHubs e puxa logs, encaminhando-os para o indexador local do Splunk para armazenamento e processamento.
- Armazenamento e análise no Splunk: Os logs são indexados no Splunk, permitindo buscas em tempo real, visualizações de dashboards e alertas baseados em padrões de logs.
Metodologia
Implantação do DaemonSet Fluent Bit no AKS
A configuração do Fluent Bit é armazenada em um ConfigMap e implantada como um DaemonSet. Abaixo está a configuração expandida para o DaemonSet do Fluent Bit:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- Validar o registro de entrada
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- Gerar uma chave única para reassemblagem com base no fluxo e na tag
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- Lidar com fragmentos de log (logtag == 'P')
if record.logtag == 'P' then
-- Armazenar o fragmento no estado de reassemblagem
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- Lidar com o final de um log fragmentado
if reassemble_state[reassemble_key] then
-- Combinar fragmentos armazenados com o log atual
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- Limpar o estado armazenado para esta chave
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- Se nenhuma reassemblagem for necessária, encaminhar o log como está
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [INPUT] a seção especifica a coleta de logs do diretório /var/log/containers.
- [FILTER] a seção enriquece os logs com metadados do Kubernetes.
- [OUTPUT] a seção configura o Fluent Bit para encaminhar logs para o EventHub no formato JSON.
Configuração do Azure EventHub
O EventHub requer um namespace, uma instância específica do EventHub e controle de acesso por meio de políticas de acesso compartilhado.
- Configuração de Namespace e EventHub: Crie um namespace e uma instância do EventHub no Azure, defina uma política de envio e recupere a string de conexão.
- Configuração para alta taxa de transferência: O EventHub é configurado com um alto número de partições para suportar escalabilidade, buffering e fluxos de dados simultâneos do Fluent Bit.
Configuração do Splunk Heavy Forwarder no Apache CloudStack
O Splunk Heavy Forwarder recupera logs do EventHub e os encaminha para o indexador do Splunk.
- Complemento para Microsoft Cloud Services: Instale o complemento para habilitar a conectividade com o EventHub. Configure a entrada em
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- Processamento em lote: Defina batch_size para 500 e intervalo para 30 segundos para otimizar a ingestão de dados e reduzir a frequência das chamadas de rede.
Indexação e Visualização do Splunk
- Enriquecimento de dados: Os logs são enriquecidos com metadados adicionais no Splunk usando extrações de campo.
- Pesquisas e painéis: As consultas SPL permitem pesquisas em tempo real, e painéis personalizados fornecem visualização de padrões de log.
- Alertas: Os alertas são configurados para acionar em padrões de log específicos, como altas taxas de erro ou avisos repetidos de contêineres específicos.
Desempenho e Escalabilidade
Os testes mostram que o sistema pode lidar com a ingestão de log de alto throughput, com as capacidades de buffer do EventHub evitando a perda de dados durante interrupções de rede. O uso de recursos do Fluent Bit em nós AKS permanece mínimo, e o indexador do Splunk lida eficientemente com o volume de log com configurações apropriadas de indexação e filtragem.
Segurança
O HTTPS é usado para garantir a comunicação entre AKS e EventHub, enquanto o Splunk HF usa chaves seguras para autenticar com o EventHub. Cada componente no pipeline implementa mecanismos de repetição para manter a integridade dos dados.
Utilização de Recursos
- O Fluent Bit tem uma média de 100-150 MiB de memória e 0,2-0,3 de CPU em nós AKS.
- O uso de recursos do EventHub é ajustado dinamicamente com base em configurações de partição e throughput.
- A carga do Splunk HF é equilibrada por meio de processamento em lote, otimizando a transferência de dados sem sobrecarregar os recursos do Apache CloudStack.
Confiabilidade e Tolerância a Falhas
A solução usa o buffer do EventHub para garantir a retenção de logs em caso de falhas downstream. O EventHub também suporta políticas de repetição, melhorando ainda mais a integridade e confiabilidade dos dados.
Discussão
Vantagens da Arquitetura de Nuvem Híbrida
Esta arquitetura oferece flexibilidade, escalabilidade e segurança ao combinar serviços do Azure com controle local. Também aproveita as capacidades de streaming e buffer baseadas em nuvem sem comprometer a soberania dos dados.
Limitações
Embora o EventHub ofereça agregação de dados confiável, os custos aumentam com as unidades de taxa de transferência, tornando essencial otimizar as configurações de encaminhamento de logs. Além disso, a transferência de dados entre ambientes de nuvem e locais introduz potencial latência.
Aplicações Futuras
Esta arquitetura poderia ser ampliada integrando aprendizado de máquina para detecção de anomalias em logs ou adicionando suporte a múltiplos provedores de nuvem para escalar ainda mais o processamento de logs e resiliência em múltiplas nuvens.
Conclusão
Este estudo demonstra a eficácia de um pipeline híbrido de processamento de logs que aproveita recursos de nuvem e locais. Ao integrar o Azure Kubernetes Service (AKS), o Azure EventHub e o Splunk no Apache CloudStack, criamos uma solução escalável e resiliente para gestão e análise centralizada de logs. A arquitetura aborda desafios chave na coleta distribuída de logs, incluindo alta taxa de transferência de dados, segurança e tolerância a falhas.
O uso do Fluent Bit como um coletor de logs leve no AKS garante a coleta eficiente de dados com sobrecarga mínima de recursos. As capacidades de buffer do Azure EventHub permitem a agregação confiável de logs e armazenamento temporário, tornando-o adequado para lidar com o tráfego variável de logs e manter a integridade dos dados em caso de problemas de conectividade. O Splunk Heavy Forwarder e a implementação do Splunk no Apache CloudStack permitem que as organizações mantenham o controle sobre o armazenamento e análise de logs, enquanto se beneficiam da escalabilidade e flexibilidade dos recursos em nuvem.
Essa abordagem oferece vantagens significativas para organizações que necessitam de uma configuração de nuvem híbrida, como um maior controle sobre os dados, conformidade com requisitos de residência de dados e a flexibilidade para escalar conforme a demanda. Trabalhos futuros podem explorar a integração de aprendizado de máquina para aprimorar a análise de logs, detecção automatizada de anomalias e expansão para uma configuração de várias nuvens para aumentar a resiliência e versatilidade. Esta pesquisa fornece uma arquitetura fundamental adaptável às necessidades em evolução de sistemas modernos e distribuídos em ambientes empresariais.
Referências
Azure Event Hubs e Kafka
Monitoramento e Logging Híbrido
- Padrões de Monitoramento Híbrido e Multi-Nuvem
- Estratégias de Monitoramento em Nuvem Híbrida
Integração com Splunk
- Splunking Azure Event Hubs
- Dados do Azure na Plataforma Splunk
Implantação do AKS
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing