













Introdução
YOLOv8, desenvolvido pela Ultralytics em 2023, surgiu como um dos algoritmos de detecção de objetos únicos na série YOLO e apresenta melhorias significativas em arquitetura e desempenho em relação aos seus antecessores, como YOLOv5. Essas melhorias incluem uma espinha dorsal CSPNet para melhor extração de características, um pescoço FPN+PAN para melhor detecção de objetos em várias escalas e uma mudança para uma abordagem sem âncoras. Essas mudanças melhoram significativamente a precisão, eficiência e usabilidade do modelo para detecção de objetos em tempo real.
O uso de uma GPU com YOLOv8 pode aumentar significativamente o desempenho para tarefas de detecção de objetos, proporcionando treinamento e inferência mais rápidos. Este guia irá guiá-lo na configuração do YOLOv8 para uso com GPU, incluindo configuração, solução de problemas e dicas de otimização.
YOLOv8
O YOLOv8 baseia-se em seus predecessores com um design avançado de rede neural e técnicas de treinamento para melhorar o desempenho na detecção de objetos. Ele unifica a localização e classificação de objetos em um único framework eficiente, equilibrando velocidade e precisão. A arquitetura é composta por três componentes-chave:
- Backbone: Uma espinha dorsal de CNN altamente otimizada, potencialmente baseada em CSPDarknet, extrai características de múltiplas escalas usando camadas eficientes como convoluções separáveis em profundidade, garantindo alto desempenho com mínimo custo computacional.
- Neck: Uma rede aprimorada de Agregação de Caminhos (PANet) refina e integra características de múltiplas escalas para detectar melhor objetos de tamanhos variados. É otimizado para eficiência e uso de memória.
- Head: A cabeça sem âncora prevê caixas delimitadoras, pontuações de confiança e rótulos de classe, simplificando previsões e melhorando a adaptabilidade a formas e escalas de objetos diversas.
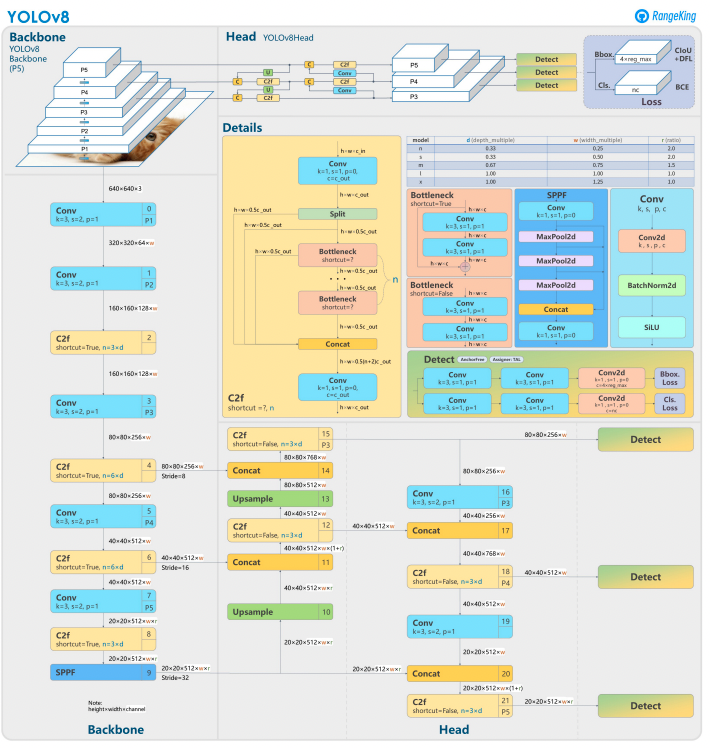
Essas inovações tornam o YOLOv8 mais rápido, preciso e versátil para tarefas modernas de detecção de objetos. Além disso, o YOLOv8 introduz uma abordagem sem âncoras para a previsão de caixas delimitadoras, afastando-se dos métodos baseados em âncoras das versões anteriores.
Por que usar uma GPU com YOLOv8?
YOLOv8 (You Only Look Once, Versão 8) é um framework poderoso de detecção de objetos. Embora ele funcione em CPUs, utilizar uma GPU oferece alguns benefícios-chave, tais como:
- Velocidade: As GPUs lidam com cálculos paralelos de forma mais eficiente, reduzindo os tempos de treinamento e inferência.
- Escalaridade: Conjuntos de dados e modelos maiores são gerenciáveis com GPUs.
- Desempenho Aprimorado: A detecção de objetos em tempo real torna-se viável, possibilitando aplicações como veículos autônomos, vigilância e processamento de vídeo ao vivo.

As GPUs são a escolha clara para obter resultados mais rápidos e lidar com tarefas mais complexas com o YOLOv8.
CPUs vs. GPUs
Ao trabalhar com YOLOv8 ou qualquer modelo de detecção de objetos, a escolha entre CPU e GPU pode impactar significativamente o desempenho do modelo tanto para treinamento quanto para inferência. As CPUs, como sabemos, são ótimas para propósitos gerais e podem lidar eficientemente com tarefas menores. No entanto, as CPUs falham quando a tarefa se torna computacionalmente cara. Tarefas como detecção de objetos requerem velocidade e computação paralela, e as GPUs são projetadas para lidar com tarefas de processamento paralelo de alto desempenho. Portanto, elas são ideais para executar modelos de aprendizado profundo como o YOLO. Por exemplo, o treinamento e a inferência em uma GPU podem ser 10–50 vezes mais rápidos do que em uma CPU, dependendo do hardware e do tamanho do modelo.
| Aspect | CPU | GPU |
|---|---|---|
| Tempo de Inferência (por imagem) | ~500 ms | ~15 ms |
| Velocidade de Treinamento (épocas/hora) | ~2 épocas/hora | ~30 épocas/hora |
| Capacidade de Tamanho de Lote | Pequena (2-4 imagens) | Grande (16-32 imagens) |
| Desempenho em Tempo Real | Não | Sim |
| Processamento Paralelo | Limitado | Excelente (milhares de núcleos) |
| Eficiência Energética | Menor para tarefas grandes | Maior para cargas de trabalho paralelas |
| Eficiência de Custo | Adequado para tarefas pequenas | Ideal para qualquer tarefa de aprendizado profundo |
A diferença se torna ainda mais pronunciada durante o treinamento, onde as GPUs encurtam drasticamente os epochs em comparação com as CPUs. Esse impulso de velocidade permite que as GPUs processem conjuntos de dados maiores e realizem detecção de objetos em tempo real de forma mais eficiente.
Pré-requisitos para usar o YOLOv8 com GPU
Antes de configurar o YOLOv8 para GPU, certifique-se de atender aos seguintes requisitos:
1. Requisitos de Hardware
- GPU NVIDIA: O YOLOv8 depende do CUDA para aceleração de GPU, então você precisará de uma GPU NVIDIA com uma Capacidade de Cálculo CUDA de 6.0 ou superior.
- Memória: Recomenda-se pelo menos 8GB de memória de GPU para conjuntos de dados moderados. Para conjuntos de dados maiores, 16GB ou mais é preferível.
2. Requisitos de Software
- Python: Versão 3.8 ou posterior.
- PyTorch: Instalado com suporte a GPU (via CUDA). Preferencialmente GPU NVIDIA.
- Kit de Ferramentas CUDA e cuDNN: Certifique-se de que estão compatíveis com a sua versão do PyTorch.
- YOLOv8: Instalável a partir do repositório Ultralytics.
3. Requisitos de Driver
- Baixe e instale os drivers mais recentes da NVIDIA no site da NVIDIA.
- Verifique a disponibilidade da sua GPU usando
nvidia-smiapós a instalação do driver.
Guia Passo a Passo para Configurar o YOLOv8 para GPU
1. Instalar Drivers da NVIDIA
Para instalar os drivers da NVIDIA:
- Identifique sua GPU usando o código abaixo:
- Visite a página de download dos drivers da NVIDIA e baixe o driver apropriado.
- Siga as instruções de instalação para o seu sistema operacional.
- Reinicie seu computador para aplicar as mudanças.
- Verifique a instalação executando:
- Este comando exibe informações da GPU e confirma a funcionalidade do driver.
2. Instale o CUDA Toolkit e o cuDNN
Para usar o YOLOv8, precisamos selecionar a versão apropriada do PyTorch, que por sua vez requer a versão do CUDA.
Passos para instalar o CUDA Toolkit
- Baixe a versão apropriada do CUDA Toolkit no site do desenvolvedor da NVIDIA.
- Instale o CUDA Toolkit e configure as variáveis de ambiente (por exemplo,
PATH,LD_LIBRARY_PATH). - Verifique a instalação executando:
Garantir que você tenha a versão mais recente do CUDA permitirá que PyTorch utilize a GPU de maneira eficaz
Passos para instalar o cuDNN
- Baixe o cuDNN do site Desenvolvedor NVIDIA.
- Extraia os conteúdos e copie-os nos diretórios CUDA correspondentes (por exemplo,
bin,include,lib). - Assegure-se de que a versão do cuDNN corresponda à sua instalação do CUDA.
3. Instale o PyTorch com Suporte a GPU
Para instalar o PyTorch com suporte a GPU, visite a página de Início Rápido do PyTorch e selecione o comando de instalação apropriado. Por exemplo:
4. Instale e Execute o YOLOv8
Instale o YOLOv8 seguindo estes passos:
- Instale o Ultralytics para trabalhar com yolov8 e importe as bibliotecas necessárias
- Exemplo de Script em Python:
- Exemplo para Linha de Comando:
5. Verificar Configuração da GPU no YOLOv8
Use o seguinte comando Python para verificar se sua GPU está sendo detectada e o CUDA está habilitado:
6. Treinar ou Inferir com a GPU
Especifique o dispositivo como cuda em seus comandos de treinamento ou inferência:
Exemplo de Linha de Comando
Validar o modelo personalizado
Exemplo de Script em Python
Por que escolher Droplets de GPU da DigitalOcean?
Os droplets de GPU da DigitalOcean são projetados para lidar com tarefas de AI e aprendizado de máquina de alto desempenho. Os H100s alimentam esses Droplets de GPU para oferecer velocidade excepcional e capacidades de processamento em paralelo, tornando-os ideais para treinar e executar modelos YOLOv8 de forma eficiente. Além disso, esses droplets vêm pré-instalados com a versão mais recente do CUDA, garantindo que você possa começar a aproveitar a aceleração da GPU sem gastar tempo em configurações manuais. Esse ambiente simplificado permite que você se concentre inteiramente na otimização de seus modelos YOLOv8 e na escalabilidade de seus projetos sem esforço.
Resolução de Problemas de Problemas Comuns
1. YOLOv8 Não Utilizando a GPU
- Verifique a disponibilidade da GPU usando
- Verifique a compatibilidade com CUDA e PyTorch.
- Certifique-se de especificar
device=0oudevice='cuda'nos comandos ou scripts. - Atualize os drivers da NVIDIA e reinstale o CUDA Toolkit, se necessário.
2. Erros do CUDA
- Assegure-se de que a versão do CUDA Toolkit corresponda aos requisitos do PyTorch.
- Verifique a instalação do cuDNN executando scripts de diagnóstico.
- Verifique as variáveis de ambiente para o CUDA (
PATHeLD_LIBRARY_PATH).
3. Desempenho lento
- Ative o treinamento de precisão mista para otimizar o uso da memória e a velocidade:
- Reduza o tamanho do lote se o uso da memória for muito alto.
- Certifique-se de ter um sistema otimizado para executar o processamento paralelo e considere usar o processamento em lote no seu script de detecção para melhorar o desempenho.
FAQs
Como habilitar a GPU para YOLOv8?
Especifique device='cuda' ou device=0 (se estiver utilizando a primeira GPU) em seus comandos ou scripts ao carregar o modelo. Isso permitirá que o YOLOv8 utilize a GPU para uma computação mais rápida durante a inferência e treinamento. Certifique-se de que sua GPU esteja corretamente configurada e detectada.
Por que o YOLOv8 não está utilizando minha GPU?
O YOLOv8 pode não estar utilizando a GPU se houver problemas com o hardware, drivers ou configuração.
Para começar, verifique a instalação do CUDA e a compatibilidade com o PyTorch. Atualize os drivers, se necessário. Certifique-se de que seu CUDA e CuDNN estejam compatíveis com sua instalação do PyTorch.
Instale o torchvision e verifique a configuração que está sendo instalada e usada.
Além disso, se o PyTorch não estiver instalado com suporte para GPU (por exemplo, uma versão apenas para CPU), ou se o parâmetro device em seus comandos YOLOv8 não estiver explicitamente definido como cuda. Executar o YOLOv8 em um sistema sem uma GPU compatível com CUDA ou com VRAM insuficiente também pode fazer com que ele use a CPU por padrão.
Para resolver isso, certifique-se de que sua GPU seja compatível com CUDA, verifique a instalação de todas as dependências necessárias, verifique se torch.cuda.is_available() retorna True e especifique explicitamente o parâmetro device='cuda' em seus scripts ou comandos YOLOv8.
Quais são os requisitos de hardware para o YOLOv8 na GPU?
Para instalar e executar efetivamente o YOLOVv8 em uma GPU, é recomendado o Python 3.7 ou superior, e é necessário ter uma GPU compatível com CUDA para usar a aceleração da GPU.
É recomendada uma GPU NVIDIA moderna com pelo menos 8GB de memória. Para conjuntos de dados grandes, mais memória é benéfica. Para um desempenho ótimo, é recomendado usar Python 3.8 ou mais recente, PyTorch 1.10 ou superior, e uma GPU NVIDIA compatível com CUDA 11.2+. A GPU deve idealmente ter pelo menos 8GB de VRAM para lidar eficientemente com conjuntos de dados moderados, embora mais VRAM seja benéfico para conjuntos de dados maiores e modelos complexos. Além disso, seu sistema deve ter pelo menos 8GB de RAM e 50GB de espaço em disco livre para armazenar conjuntos de dados e facilitar o treinamento do modelo. Garantir essas configurações de hardware e software ajudará você a obter um treinamento e inferência mais rápidos com o YOLOv8, especialmente para tarefas computacionalmente intensivas.
Por favor, observe: as GPUs AMD podem não oferecer suporte ao CUDA, portanto, escolher uma GPU NVIDIA para compatibilidade com o YOLOv8 é essencial.
O YOLOv8 pode ser executado em várias GPUs?
Para treinar o YOLOv8 usando várias GPUs, você pode usar o DataParallel do PyTorch ou especificar dispositivos múltiplos diretamente (por exemplo, cuda:0,1). Para treinamento distribuído, o YOLOv8 utiliza o Multi-GPU DistributedDataParallel (DDP) do PyTorch por padrão. Certifique-se de que seu sistema tenha várias GPUs disponíveis e especifique as GPUs que deseja usar no script de treinamento ou na linha de comando. Por exemplo, defina --device 0,1,2,3 na CLI ou device=[0,1,2,3] em Python para utilizar as GPUs 0, 1, 2 e 3. O YOLOv8 gerencia automaticamente o treinamento paralelo nas GPUs especificadas sem exigir um argumento explícito data_parallel. Embora todas as GPUs sejam utilizadas durante o treinamento, a fase de validação geralmente é executada em uma única GPU por padrão, pois consome menos recursos do que o treinamento.
Como otimizar o YOLOv8 para inferência em GPU?
Ative a precisão mista e ajuste os tamanhos dos lotes para equilibrar memória e velocidade. Dependendo do seu conjunto de dados, treinar o YOLOv8 requer uma quantidade considerável de poder computacional para funcionar de forma eficiente. Utilize uma variante de modelo menor ou quantizada (por exemplo, YOLOv8n ou versões quantizadas em INT8) para reduzir o uso de memória e o tempo de inferência. No seu script de inferência, defina explicitamente o parâmetro device como cuda para execução em GPU. Use técnicas como inferência em lote para processar várias imagens simultaneamente e maximizar a utilização da GPU. Se aplicável, utilize o TensorRT para otimizar ainda mais o modelo para uma inferência mais rápida na GPU. Monitore regularmente a memória e o desempenho da GPU para garantir um uso eficiente dos recursos.
O código abaixo permitirá que você processe imagens em paralelo dentro do tamanho de lote definido.
Se estiver usando a CLI, especifique o tamanho do lote com -b ou –batch-size. Com Python, certifique-se de que o argumento do lote está corretamente definido ao inicializar seu modelo ou chamar o método de previsão.
Como resolvo problemas de falta de memória CUDA?
Para resolver erros de falta de memória CUDA, reduza o tamanho do lote de validação no seu arquivo de configuração do YOLOv8, uma vez que lotes menores exigem menos memória da GPU. Além disso, se você tiver acesso a várias GPUs, considere distribuir a carga de validação entre elas usando o DistributedDataParallel do PyTorch ou funcionalidade similar, embora isso exija conhecimento avançado de PyTorch. Você também pode tentar limpar a memória em cache usando torch.cuda.empty_cache() em seu script e garantir que nenhum processo desnecessário esteja em execução na sua GPU. Atualizar para uma GPU com mais VRAM ou otimizar seu modelo e conjunto de dados para eficiência de memória são etapas adicionais para mitigar tais problemas.
Conclusão
Configurar o YOLOv8 para utilizar uma GPU é um processo simples que pode melhorar significativamente o desempenho. Seguindo este guia detalhado, você pode acelerar o treinamento e a inferência para suas tarefas de detecção de objetos. Otimize sua configuração, resolva problemas comuns e desbloqueie todo o potencial do YOLOv8 com aceleração por GPU.
Referências
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection