













Configurando o AWS CLI e AWS S3
Antes de mergulhar no comando aws s3 cp, você precisa ter o AWS CLI instalado e configurado corretamente no seu sistema. Não se preocupe se nunca trabalhou com a AWS antes – o processo de configuração é fácil e deve levar menos de 10 minutos.
Vou dividir isso em três fases simples: instalando a ferramenta AWS CLI, configurando suas credenciais e criando seu primeiro bucket S3 para armazenamento.
Instalando o AWS CLI
O processo de instalação difere ligeiramente com base no sistema operacional que você está usando.
Para sistemas Windows:
- Acesse a página oficial de documentação do AWS CLI
- Obtenha o instalador de 64 bits para Windows
- Execute o arquivo baixado e siga o assistente de instalação
Para sistemas Linux:
Execute os seguintes três comandos no Terminal:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Para sistemas macOS:
Assumindo que você tenha o Homebrew instalado, execute esta linha no Terminal:
brew install awscli
Se você não tiver o Homebrew, use estes dois comandos em vez disso:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Para confirmar uma instalação bem-sucedida, execute aws --version no seu terminal. Você deve ver algo assim:
Imagem 1 – Versão do AWS CLI
Configurando o AWS CLI
Com o CLI instalado, é hora de configurar suas credenciais da AWS para autenticação.
Primeiro, acesse sua conta da AWS e vá para o painel de serviços IAM. Crie um novo usuário com acesso programático e anexe a política de permissões apropriada do S3:
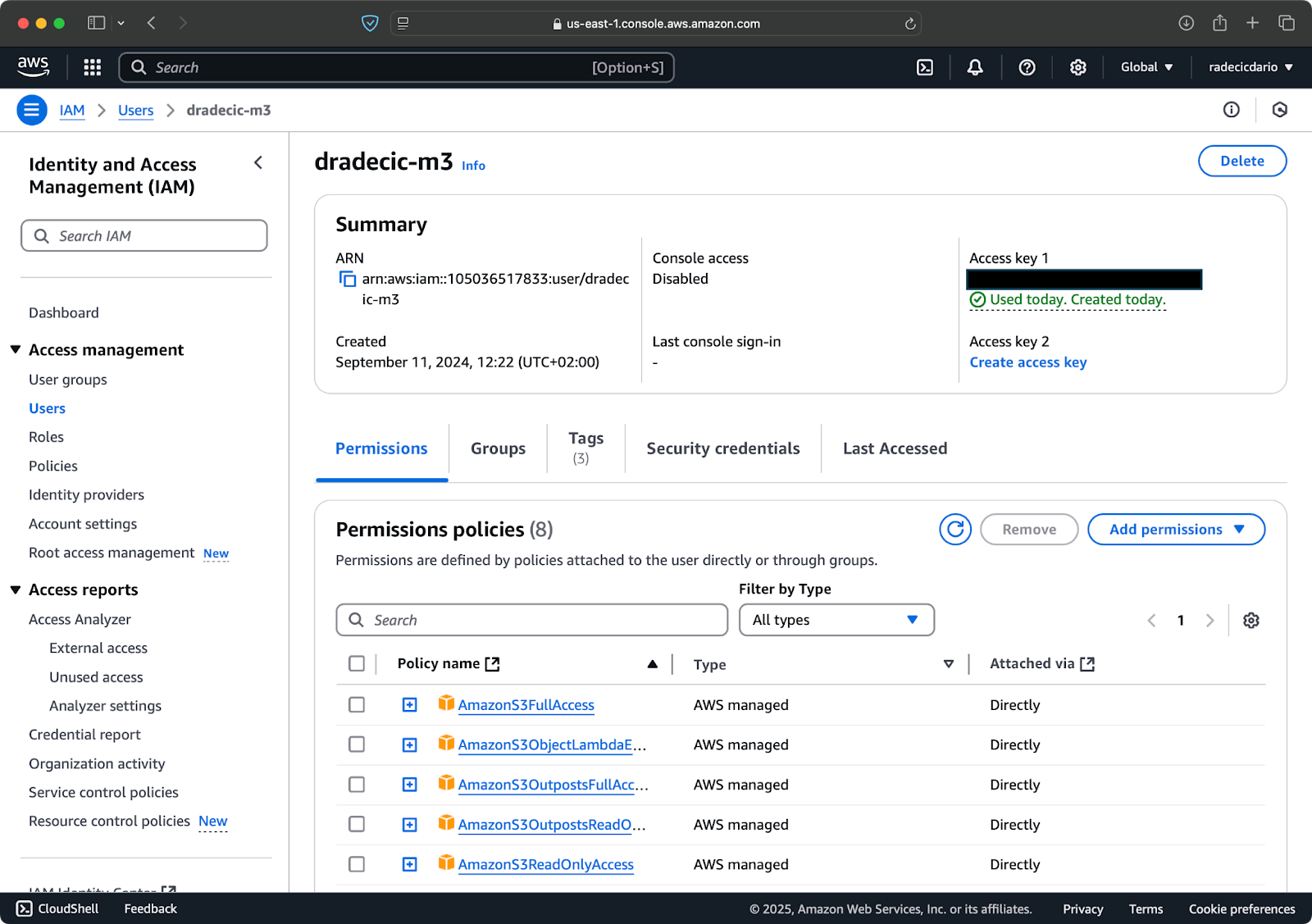
Imagem 2 – Usuário IAM da AWS
Em seguida, visite a aba “Credenciais de segurança” e gere um novo par de chaves de acesso. Certifique-se de salvar tanto o ID da chave de acesso quanto a chave de acesso secreta em um local seguro – a Amazon não mostrará a chave secreta novamente após esta tela:
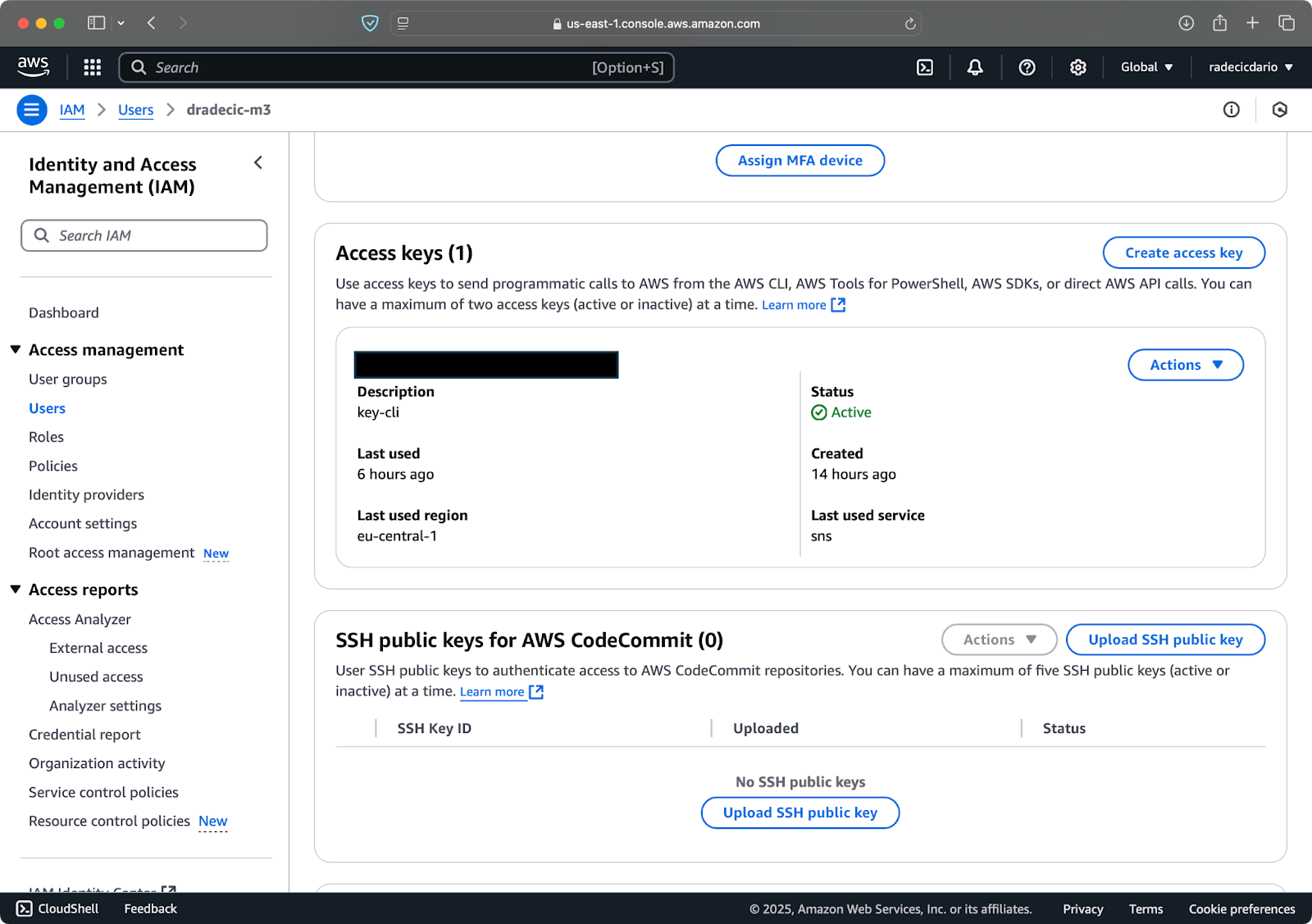
Imagem 3 – Credenciais do usuário IAM da AWS
Agora abra o seu terminal e execute o comando aws configure. Você será solicitado a fornecer quatro informações: sua ID de chave de acesso, chave de acesso secreta, região padrão (estou usando eu-central-1), e formato de saída preferido (tipicamente json):
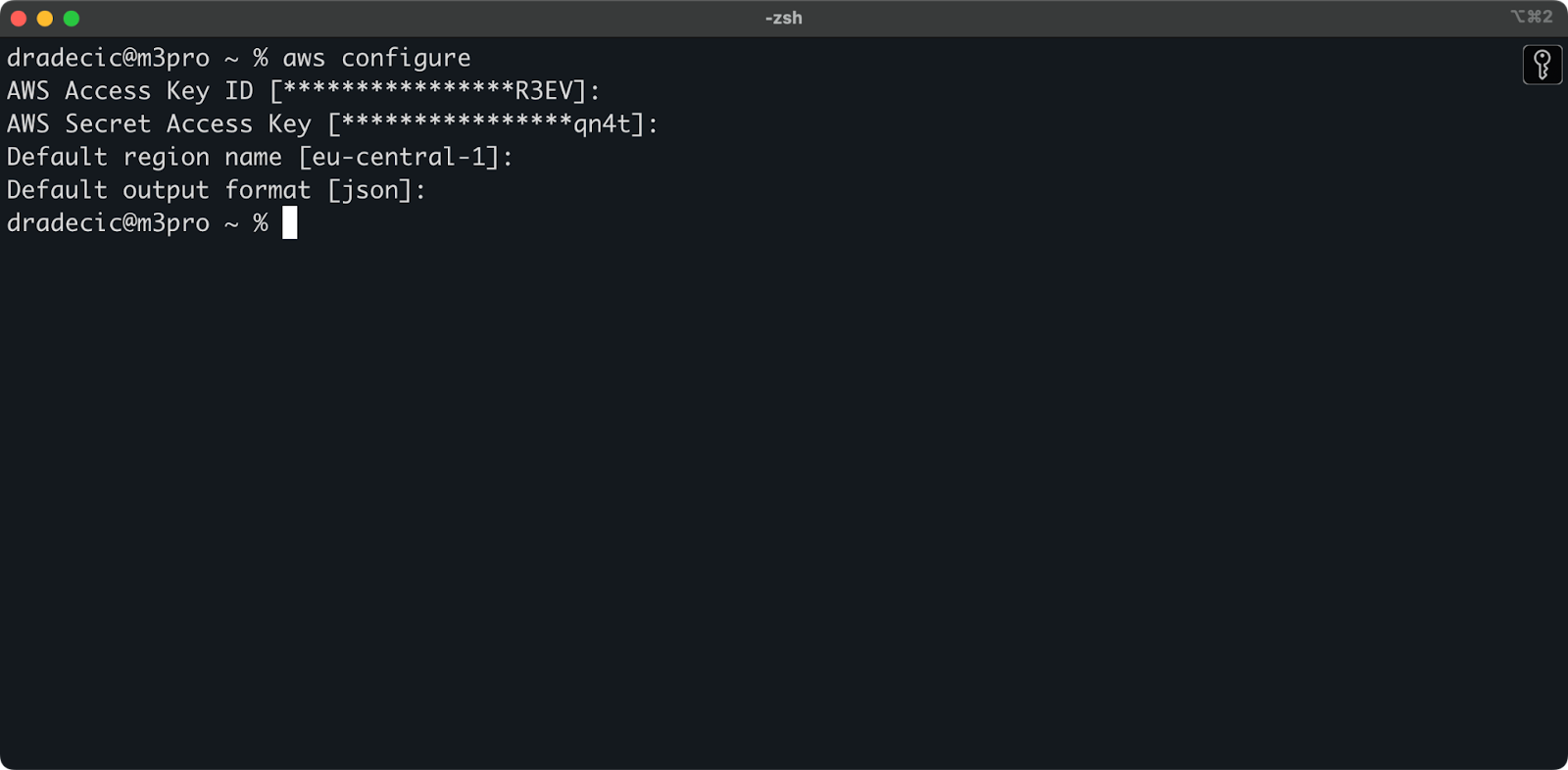
Imagem 4 – Configuração AWS CLI
Para garantir que tudo esteja conectado corretamente, verifique sua identidade com o seguinte comando:
aws sts get-caller-identity
Se configurado corretamente, você verá os detalhes da sua conta:
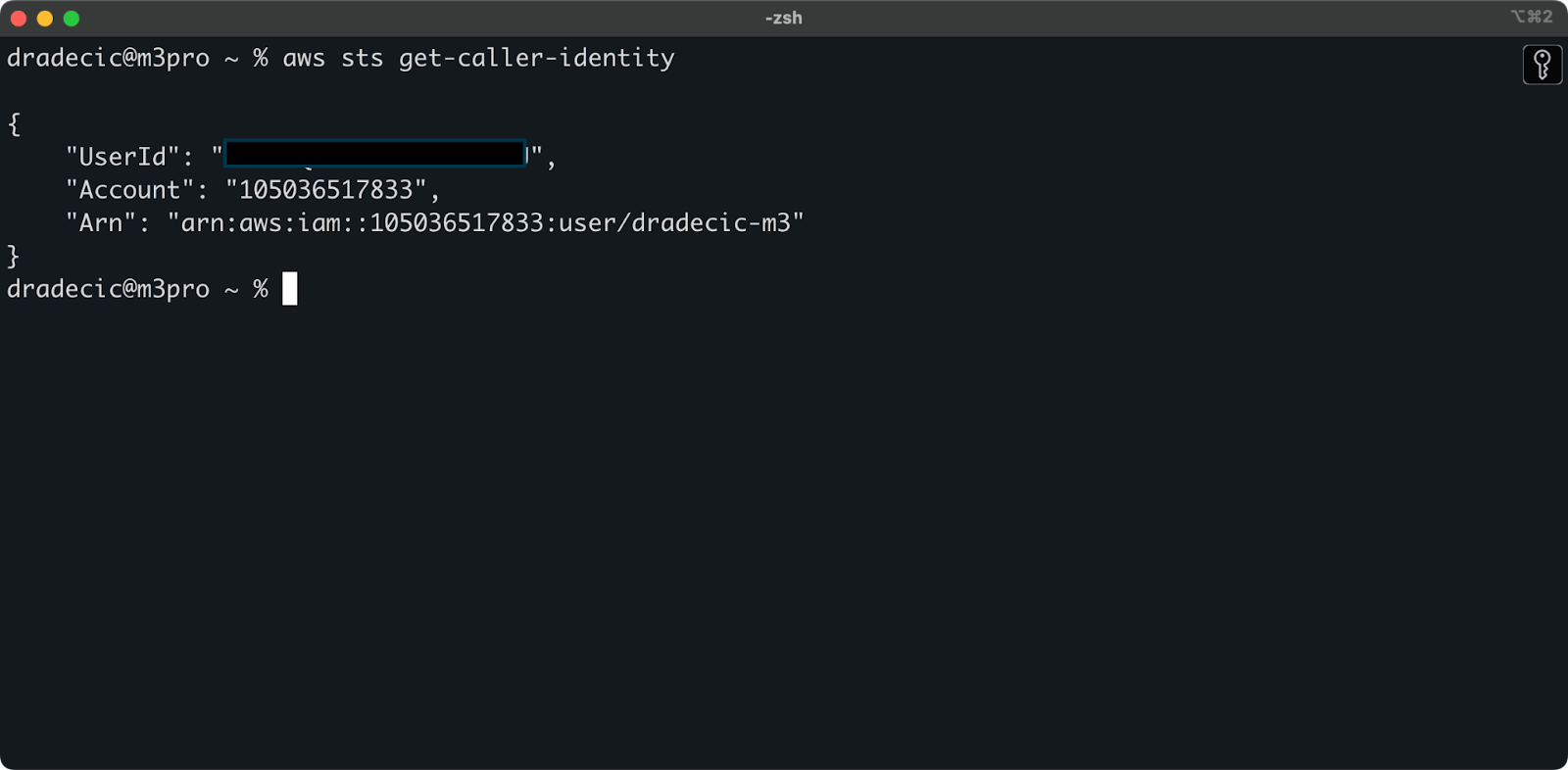
Imagem 5 – Comando de teste de conexão AWS CLI
Criando um bucket S3
Finalmente, você precisa criar um bucket S3 para armazenar os arquivos que serão copiados.
Acesse a seção de serviço S3 no seu Console AWS e clique em “Criar bucket”. Lembre-se de que os nomes dos buckets devem ser globalmente únicos em toda a AWS. Escolha um nome distinto, deixe as configurações padrão por enquanto e clique em “Criar”:
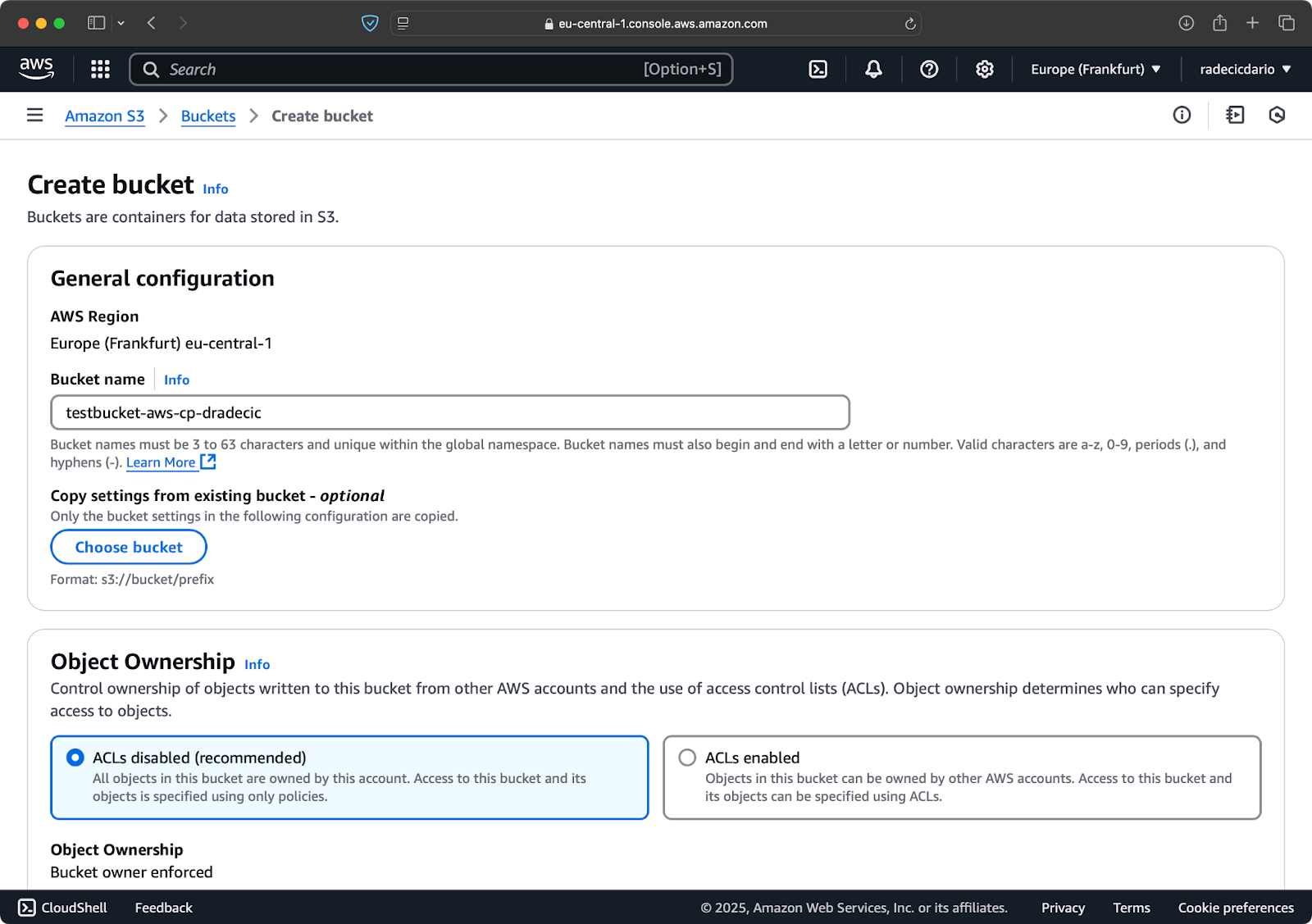
Imagem 6 – Criação de bucket AWS
Depois de criado, seu novo bucket aparecerá no console. Você também pode confirmar sua existência por meio da linha de comando:
aws s3 ls
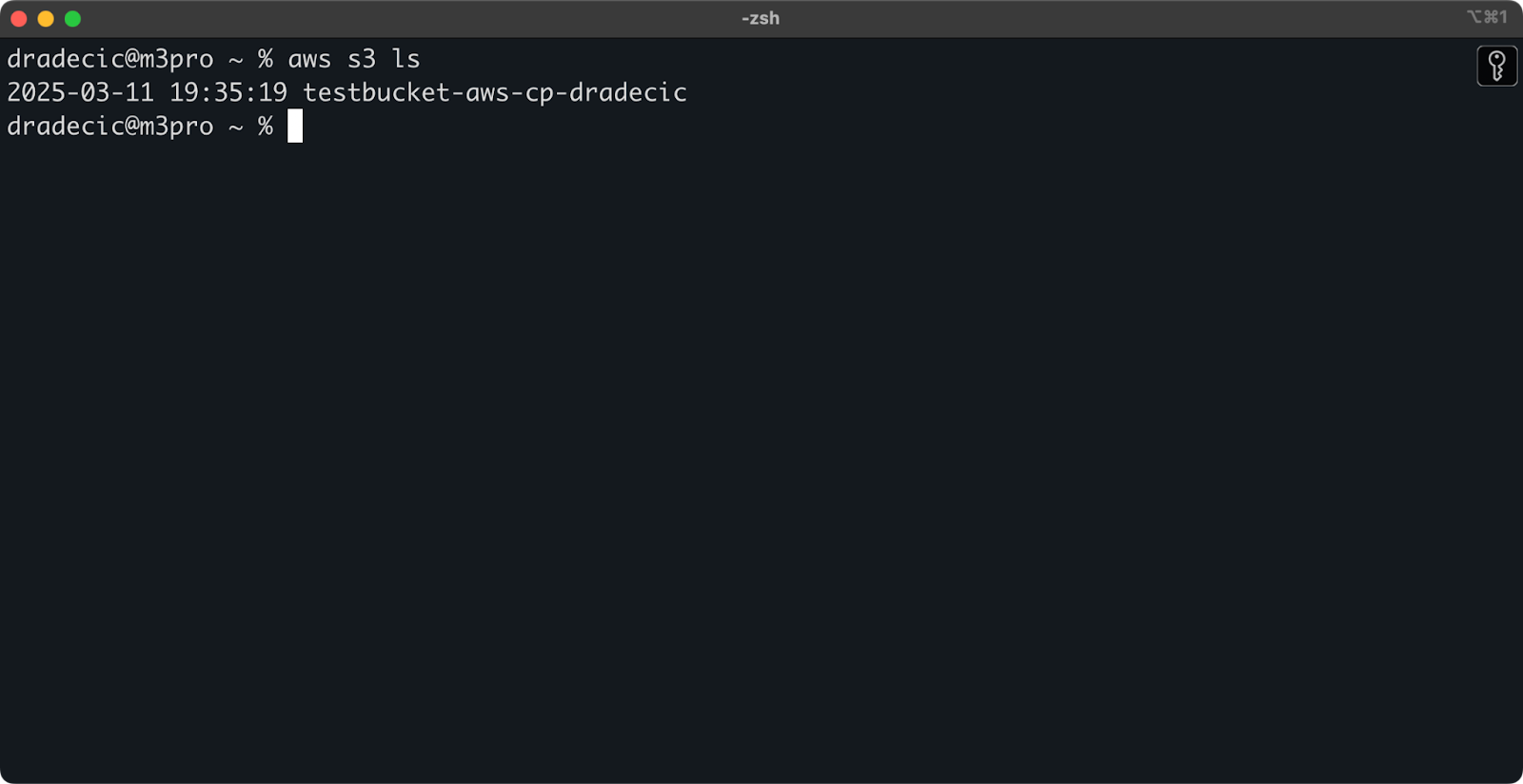
Imagem 7 – Todos os buckets S3 disponíveis
Todos os buckets S3 são configurados como privados por padrão, então tenha isso em mente. Se pretende usar este bucket para arquivos acessíveis publicamente, você precisará modificar as políticas do bucket adequadamente.
Agora você está totalmente equipado para começar a usar o comando aws s3 cp para transferir arquivos. Vamos começar com o básico a seguir.
Sintaxe básica do comando AWS S3 cp
Agora que você tem tudo configurado, vamos mergulhar no uso básico do comando aws s3 cp. Como de costume com a AWS, a beleza está na simplicidade, mesmo que o comando possa lidar com diferentes cenários de transferência de arquivos.
Na sua forma mais básica, o comando aws s3 cp segue esta sintaxe:
aws s3 cp <source> <destination> [options]
Onde <source> e <destination> podem ser caminhos de arquivos locais ou URIs do S3 (que começam com s3://). Vamos explorar os três casos de uso mais comuns.
Copiando um arquivo de local para S3
Para copiar um arquivo do seu sistema local para um bucket S3, a origem será um caminho local e o destino será uma URI do S3:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
Este comando faz o upload do arquivo test_file.txt do diretório fornecido para o bucket S3 especificado. Se a operação for bem-sucedida, você verá uma saída no console como esta:
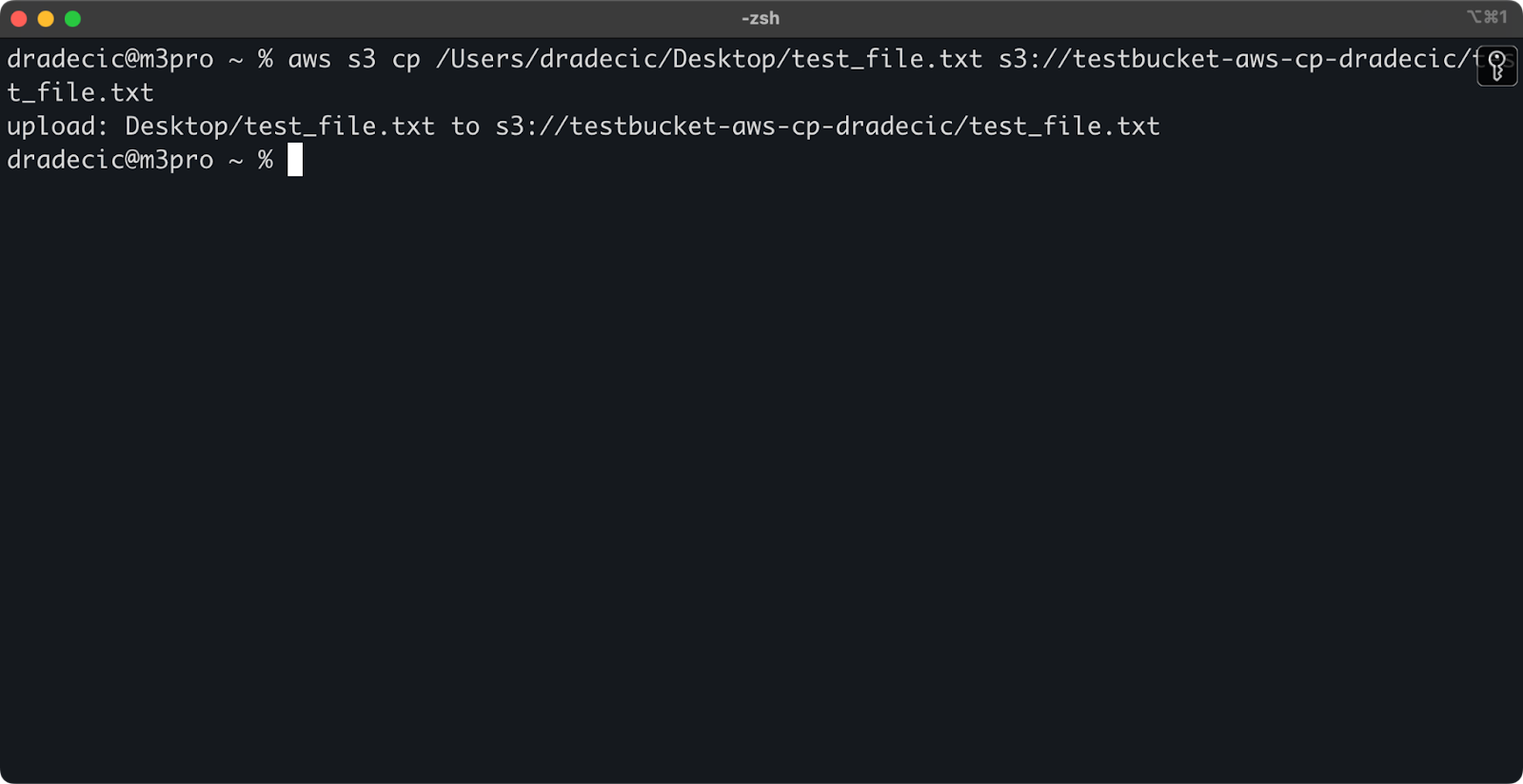
Imagem 8 – Saída do console após copiar o arquivo local
E, no console de gerenciamento da AWS, você verá seu arquivo carregado:
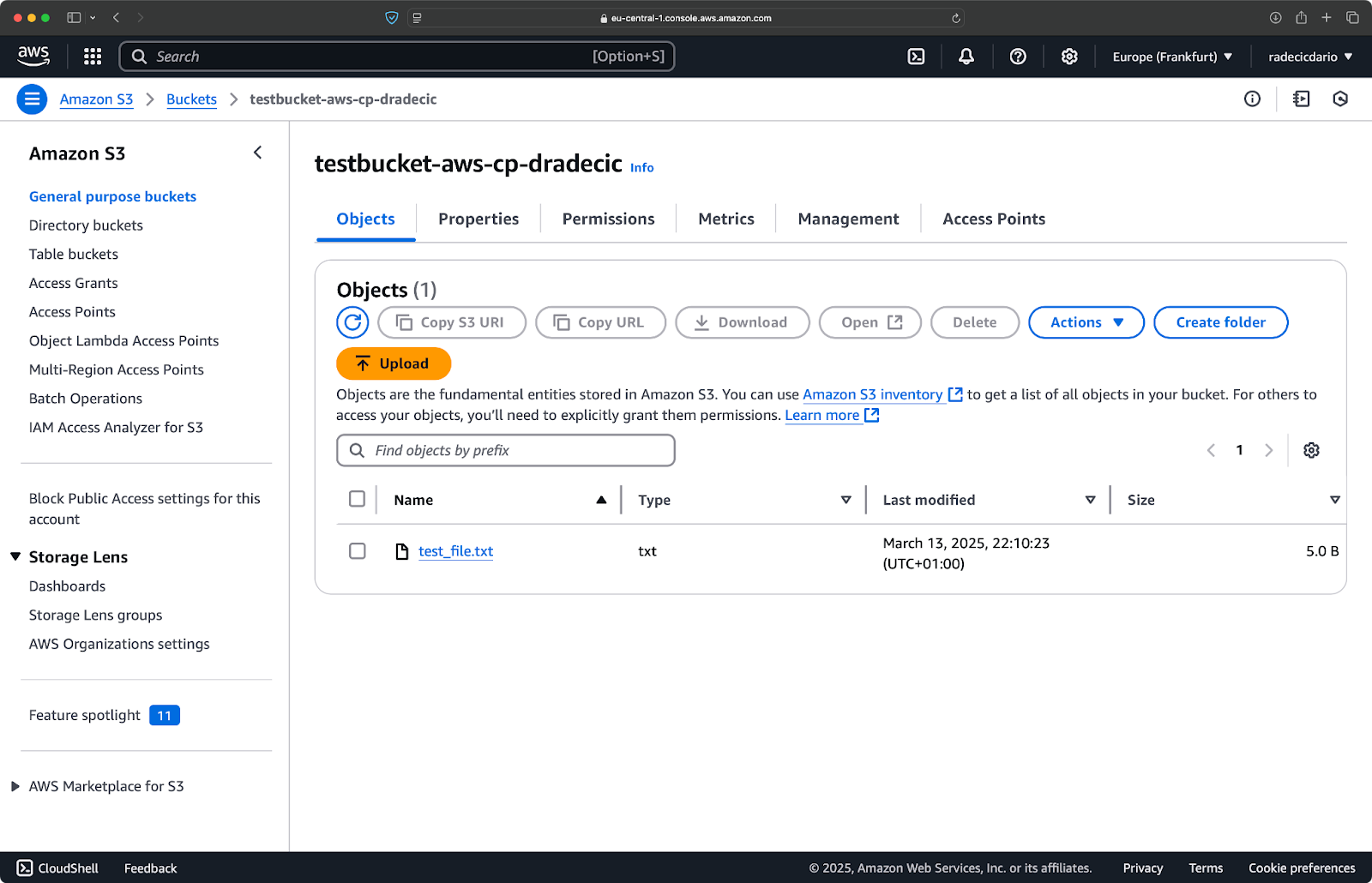
Imagem 9 – Conteúdo do bucket S3
Da mesma forma, se você quiser copiar uma pasta local para o seu bucket S3 e colocá-la, digamos, em outra pasta aninhada, execute um comando semelhante a este:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
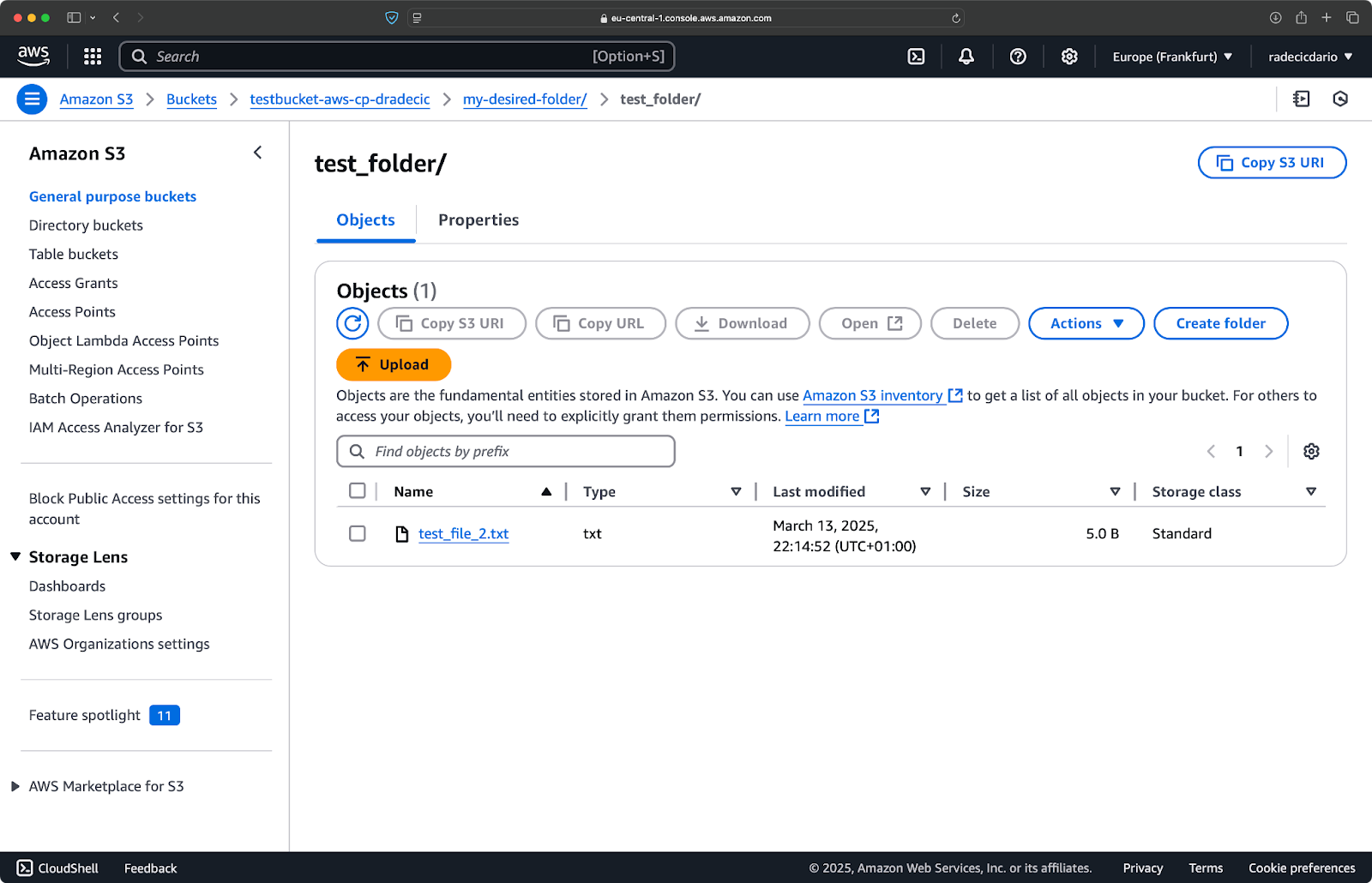
Imagem 10 – Conteúdo do bucket S3 após o upload de uma pasta
O parâmetro --recursive garantirá que todos os arquivos e subpastas dentro da pasta sejam copiados.
Só tenha em mente – o S3 na verdade não possui pastas – a estrutura de caminho é apenas parte da chave do objeto, mas funciona conceitualmente como pastas.
Copiando um arquivo do S3 para local
Para copiar um arquivo do S3 para o seu sistema local, basta inverter a ordem – a origem se torna o URI do S3 e o destino é o seu caminho local:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
Este comando baixa o test_file.txt do seu bucket do S3 e o salva como downloaded_test_file.txt no diretório fornecido. Você o verá imediatamente em seu sistema local:
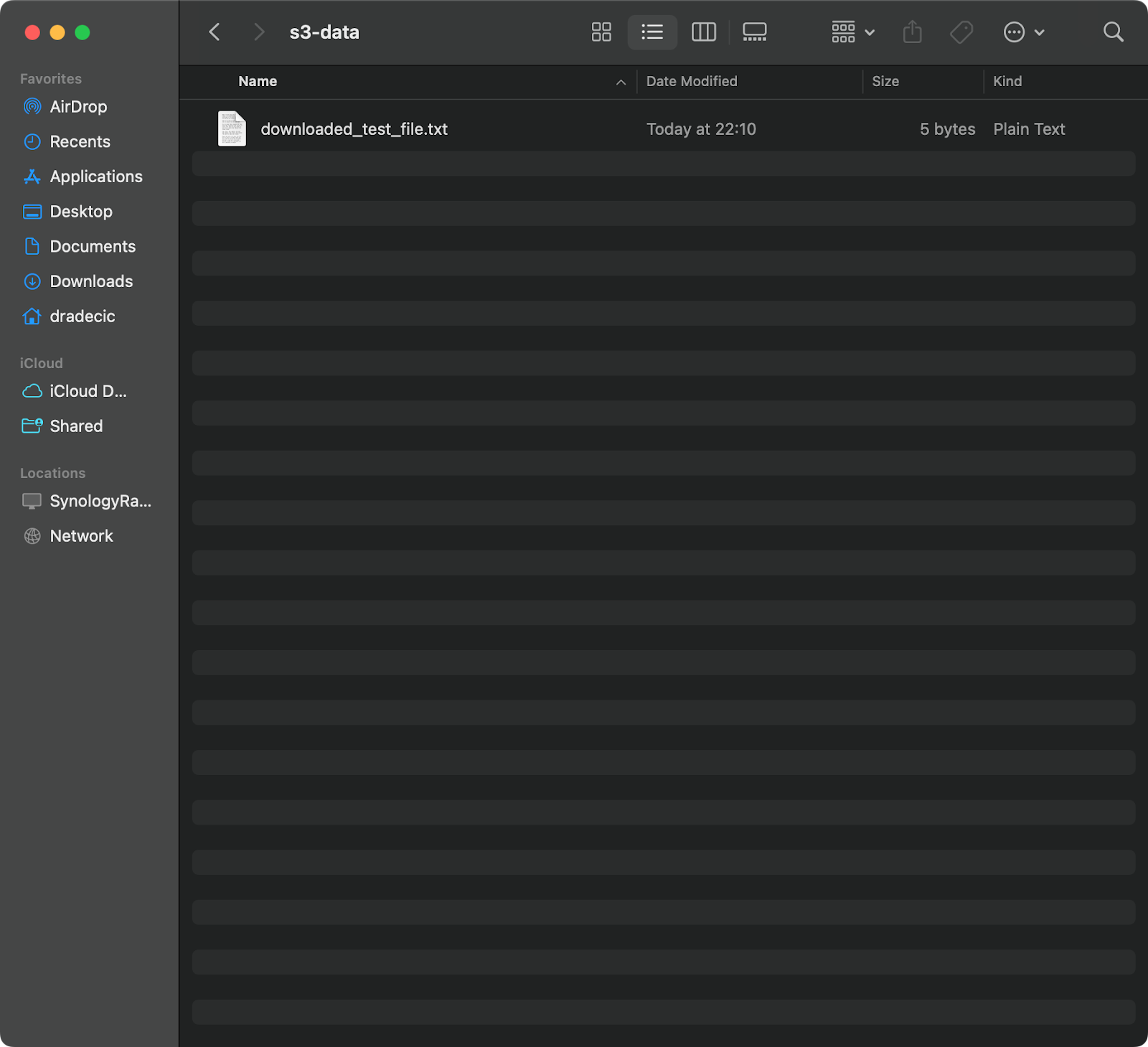
Imagem 11 – Baixando um único arquivo do S3
Se você omitir o nome do arquivo de destino, o comando usará o nome original do arquivo:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
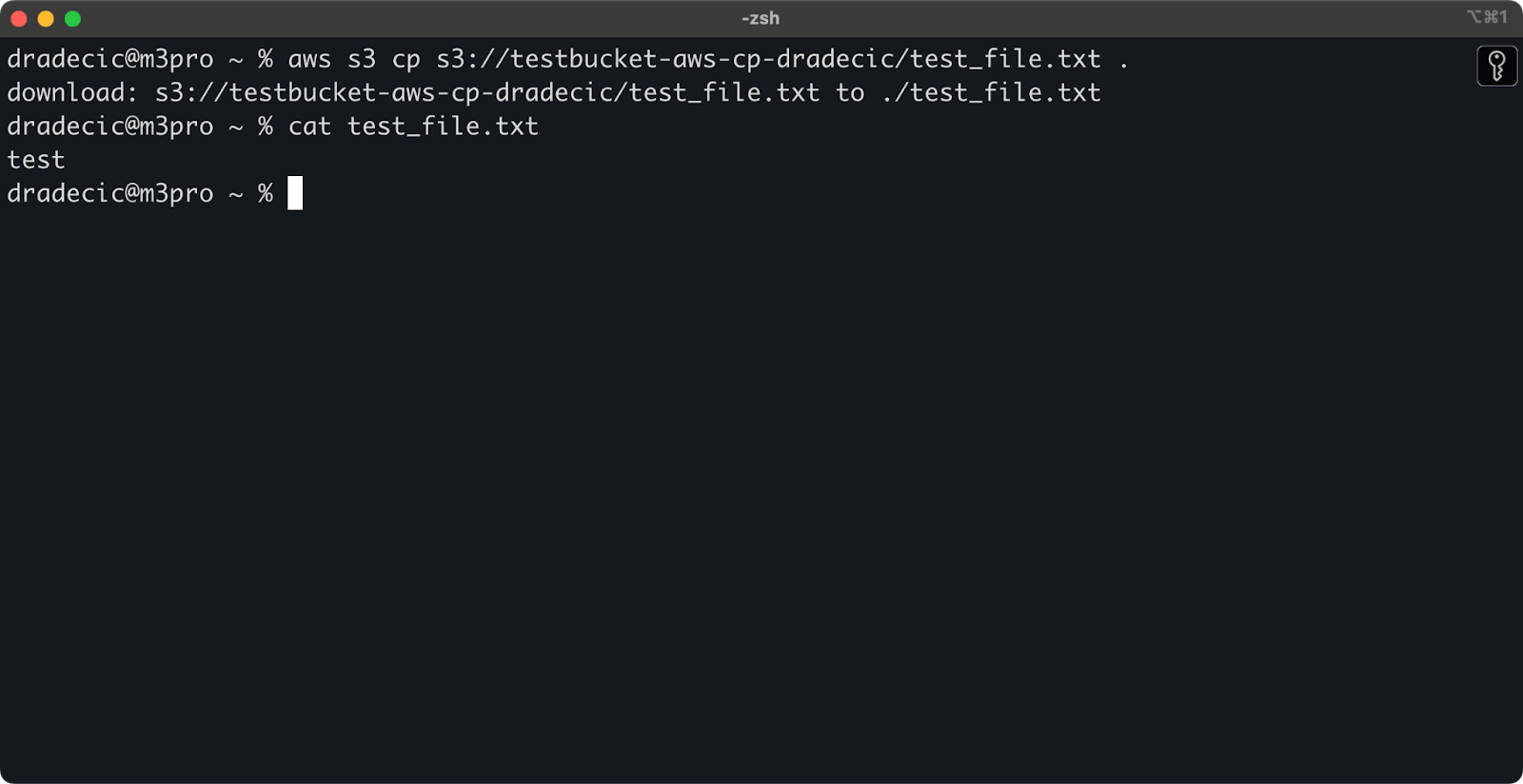
Imagem 12 – Conteúdo do arquivo baixado
O ponto (.) representa o seu diretório atual, então isso baixará o test_file.txt para a sua localização atual.
E, finalmente, para baixar um diretório inteiro, você pode usar um comando semelhante a este:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
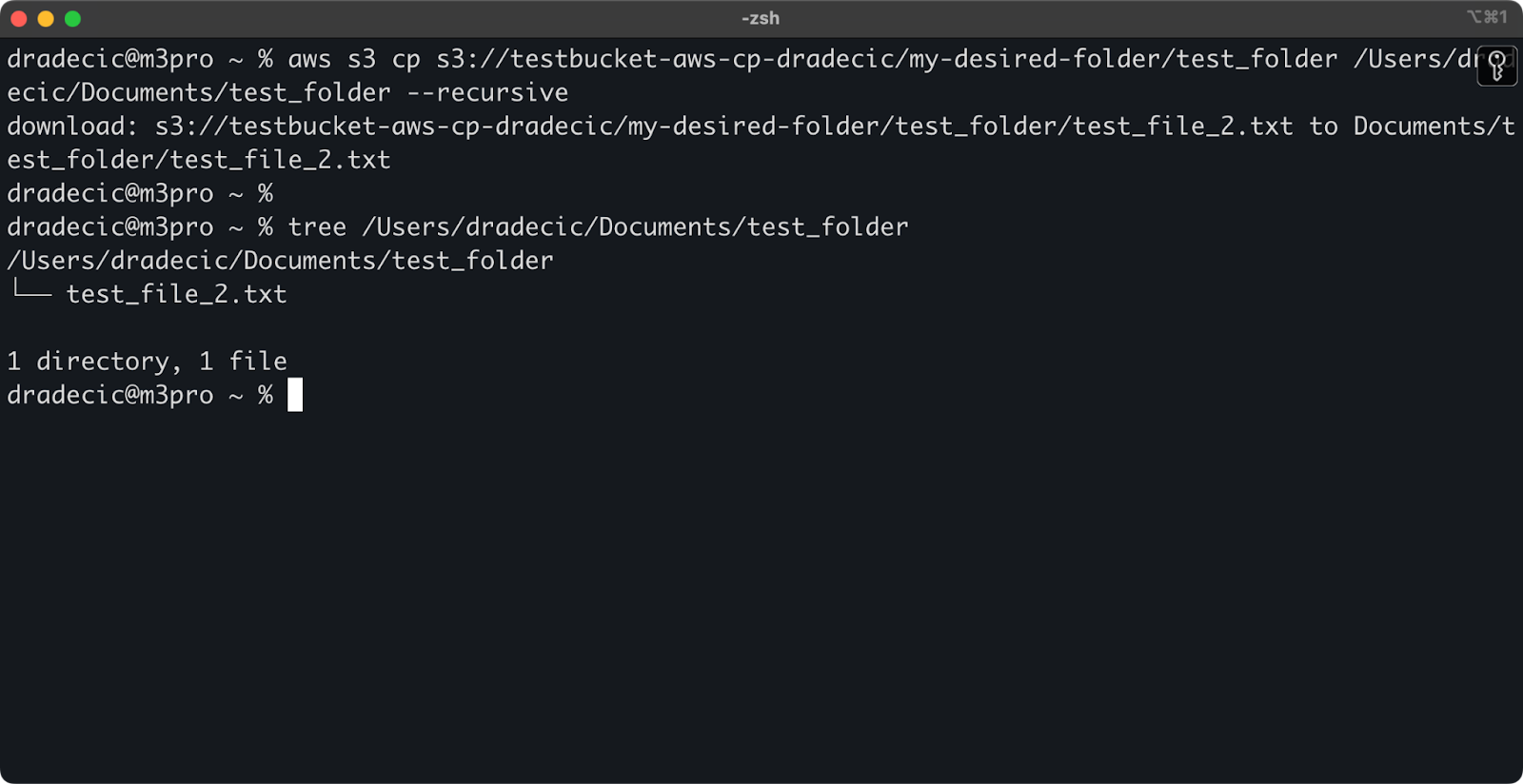
Imagem 13 – Conteúdo da pasta baixada
Tenha em mente que a flag --recursive é essencial ao trabalhar com vários arquivos – sem ela, o comando falhará se a origem for um diretório.
Com esses comandos básicos, você já pode realizar a maioria das tarefas de transferência de arquivos de que precisará. Mas, na próxima seção, você aprenderá opções mais avançadas que lhe darão melhor controle sobre o processo de cópia.
Opções e Recursos Avançados do AWS S3 cp
A AWS oferece algumas opções avançadas que permitem maximizar as operações de cópia de arquivos. Nesta seção, vou mostrar algumas das flags e parâmetros mais úteis que ajudarão você em suas tarefas diárias.
O uso das flags –exclude e –include
Às vezes, você só quer copiar certos arquivos que correspondem a padrões específicos. As bandeiras --exclude e --include permitem filtrar arquivos com base em padrões e oferecem controle preciso sobre o que é copiado.
Apenas para contextualizar, esta é a estrutura de diretórios com a qual estou trabalhando:
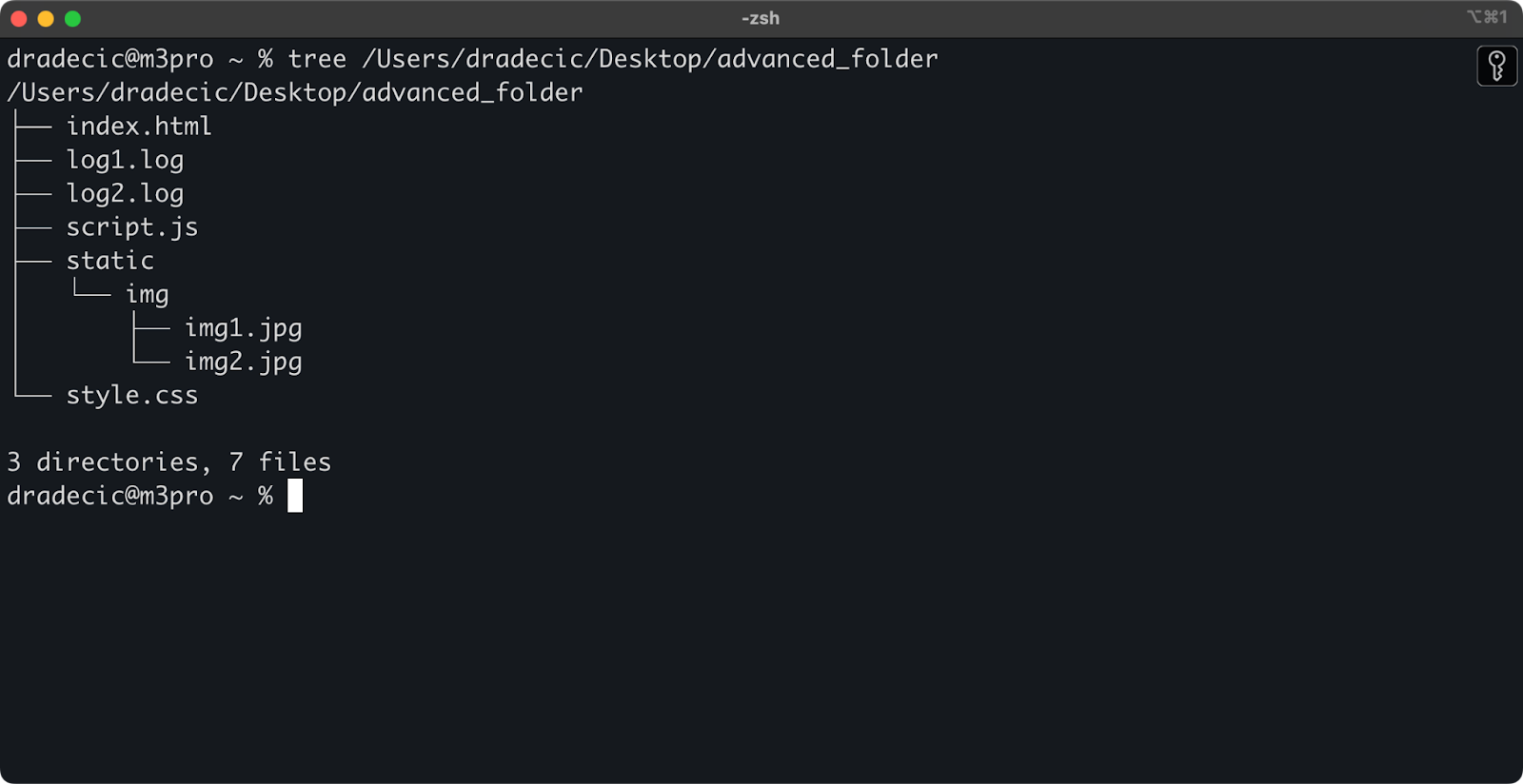
Imagem 14 – Estrutura de diretórios
Agora, digamos que você queira copiar todos os arquivos do diretório, exceto os arquivos .log:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
Este comando copiará todos os arquivos do diretório advanced_folder para o S3, excluindo qualquer arquivo com a extensão .log:
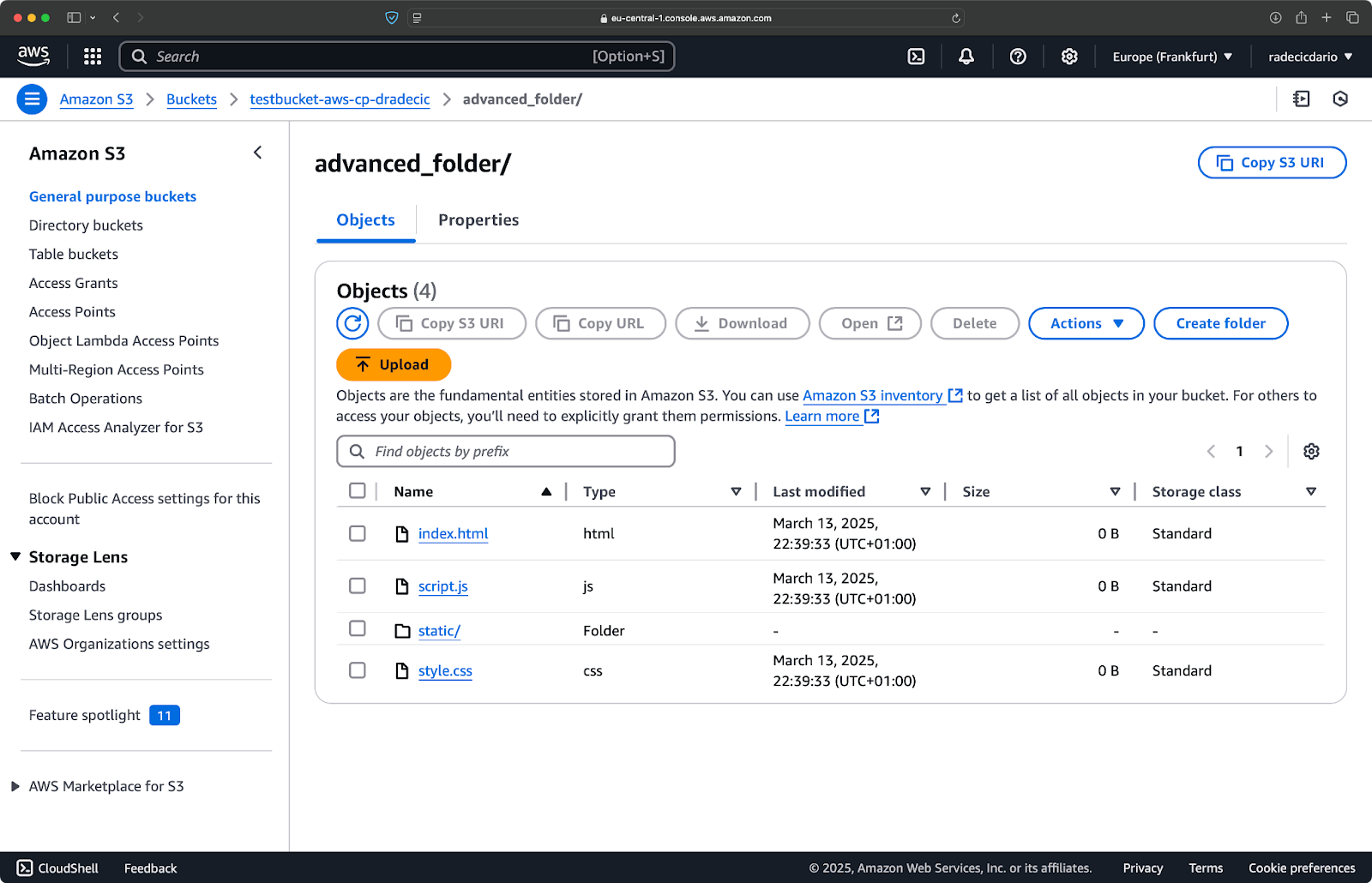
Imagem 15 – Resultados da cópia do diretório
Você também pode combinar vários padrões. Digamos que você queira copiar apenas os arquivos HTML e CSS da pasta do projeto:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
Este comando primeiro exclui tudo (--exclude "*"), e depois inclui apenas arquivos com extensões .html e .css. O resultado será assim:
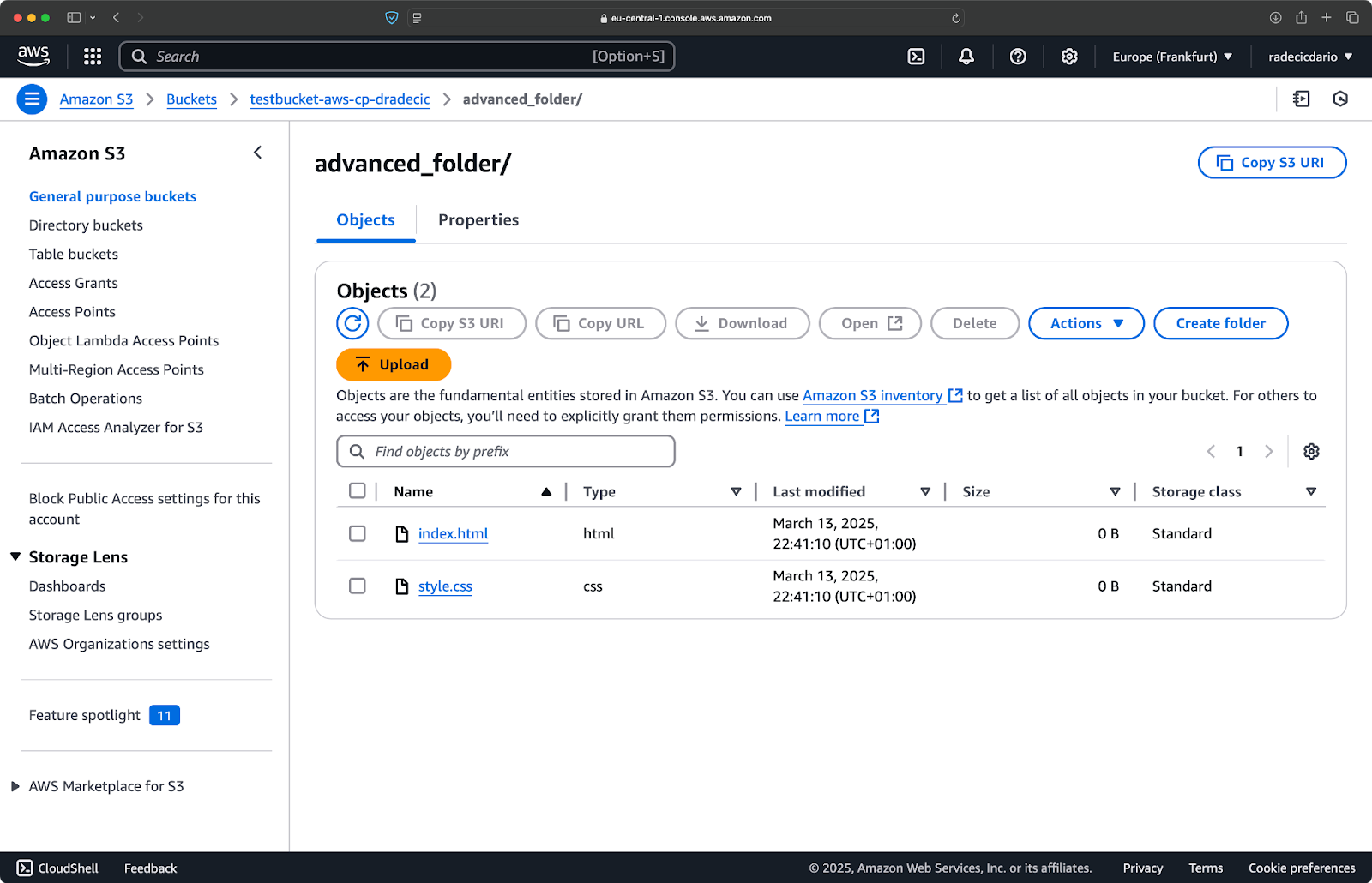
Imagem 16 – Resultados da cópia do diretório (2)
Tenha em mente que a ordem das bandeiras é importante – o AWS CLI processa essas bandeiras sequencialmente, então se você colocar --include antes de --exclude, você obterá resultados diferentes:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
Desta vez, nada foi copiado para o bucket:
Imagem 17 – Resultados da cópia do diretório (3)
Especificar a classe de armazenamento do S3
O Amazon S3 oferece diferentes classes de armazenamento, cada uma com custos e características de recuperação diferentes. Por padrão, aws s3 cp faz upload de arquivos para a classe de armazenamento Standard, mas você pode especificar uma classe diferente usando a flag --storage-class:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
Este comando faz upload do arquivo large-archive.zip para a classe de armazenamento Glacier, que é significativamente mais barata, mas tem custos de recuperação mais altos e tempos de recuperação mais longos:
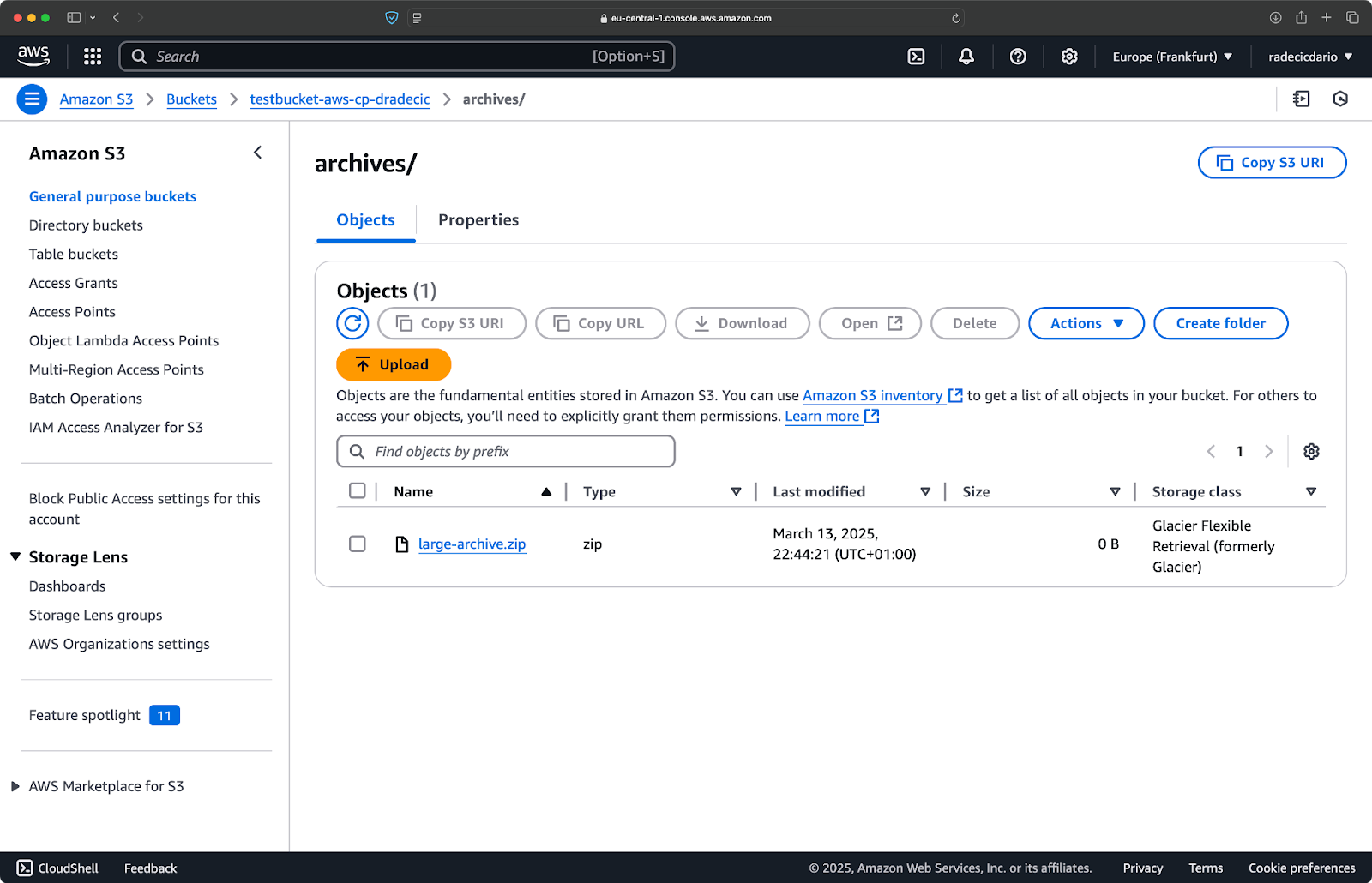
Imagem 18 – Copiando arquivos para o S3 com diferentes classes de armazenamento
As classes de armazenamento disponíveis incluem:
STANDARD(padrão): Armazenamento de uso geral com alta durabilidade e disponibilidade.REDUCED_REDUNDANCY(não mais recomendado): Opção de custo mais baixo, agora obsoleta.STANDARD_IA(Acesso Infrequente): Armazenamento com custo mais baixo para dados acessados com menos frequência.ONEZONE_IA(Acesso Infrequente em Zona Única): Armazenamento com custo mais baixo para acesso infrequente em uma única Zona de Disponibilidade da AWS.INTELLIGENT_TIERING: Move automaticamente dados entre camadas de armazenamento com base em padrões de acesso.GLACIER: Armazenamento de arquivo de baixo custo para retenção de longo prazo, recuperação em minutos a horas.DEEP_ARCHIVE: Armazenamento de arquivo mais barato, recuperação em horas, ideal para backups de longo prazo.
Se você estiver fazendo backup de arquivos dos quais não precisa de acesso imediato, usar GLACIER ou DEEP_ARCHIVE pode economizar custos significativos de armazenamento.
Sincronizando arquivos com a flag –exact-timestamps
Ao atualizar arquivos no S3 que já existem, você pode querer copiar apenas os arquivos que foram alterados. A opção --exact-timestamps ajuda nisso ao comparar os carimbos de data/hora entre a origem e o destino.
Aqui está um exemplo:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
Com essa opção, o comando irá copiar somente os arquivos se os carimbos de data/hora forem diferentes dos arquivos já existentes no S3. Isso pode reduzir o tempo de transferência e o uso da largura de banda quando você está atualizando regularmente um grande conjunto de arquivos.
Então, por que isso é útil? Apenas imagine cenários de implantação nos quais você deseja atualizar os arquivos de sua aplicação sem transferir desnecessariamente ativos inalterados.
Embora --exact-timestamps seja útil para realizar algum tipo de sincronização, se você precisa de uma solução mais sofisticada, considere usar aws s3 sync em vez de aws s3 cp. O comando sync foi especificamente projetado para manter diretórios sincronizados e possui capacidades adicionais para esse fim. Eu escrevi tudo sobre o comando sync no Tutorial de Sincronização AWS S3.
Com essas opções avançadas, você agora tem um controle mais preciso sobre suas operações de arquivos no S3. Você pode direcionar arquivos específicos, otimizar os custos de armazenamento e atualizar eficientemente seus arquivos. Na próxima seção, você aprenderá a automatizar essas operações usando scripts e tarefas agendadas.
Automatizando Transferências de Arquivos com AWS S3 cp
Até agora, você aprendeu como copiar arquivos manualmente para e de S3 usando a linha de comando. Uma das maiores vantagens de usar aws s3 cp é que você pode facilmente automatizar essas transferências, o que economizará muito tempo.
Vamos explorar como você pode integrar o comando aws s3 cp em scripts e trabalhos agendados para transferências de arquivos sem intervenção manual.
Usando o AWS S3 cp em scripts
Aqui está um exemplo simples de script bash que faz backup de um diretório para o S3, adiciona um carimbo de data/hora ao backup e implementa tratamento de erros e registro em um arquivo:
#!/bin/bash # Definir variáveis SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # Garantir que o diretório de logs exista mkdir -p "$(dirname "$LOG_FILE")" # Criar o backup e registrar a saída echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # Verificar se o backup foi bem-sucedido if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
Salve isso como backup.sh, torne-o executável com chmod +x backup.sh e você terá um script de backup reutilizável!
Você pode então executá-lo com o seguinte comando:
./backup.sh
Imagem 19 – Script sendo executado no terminal
Imediatamente após, a pasta backups no bucket será populada:
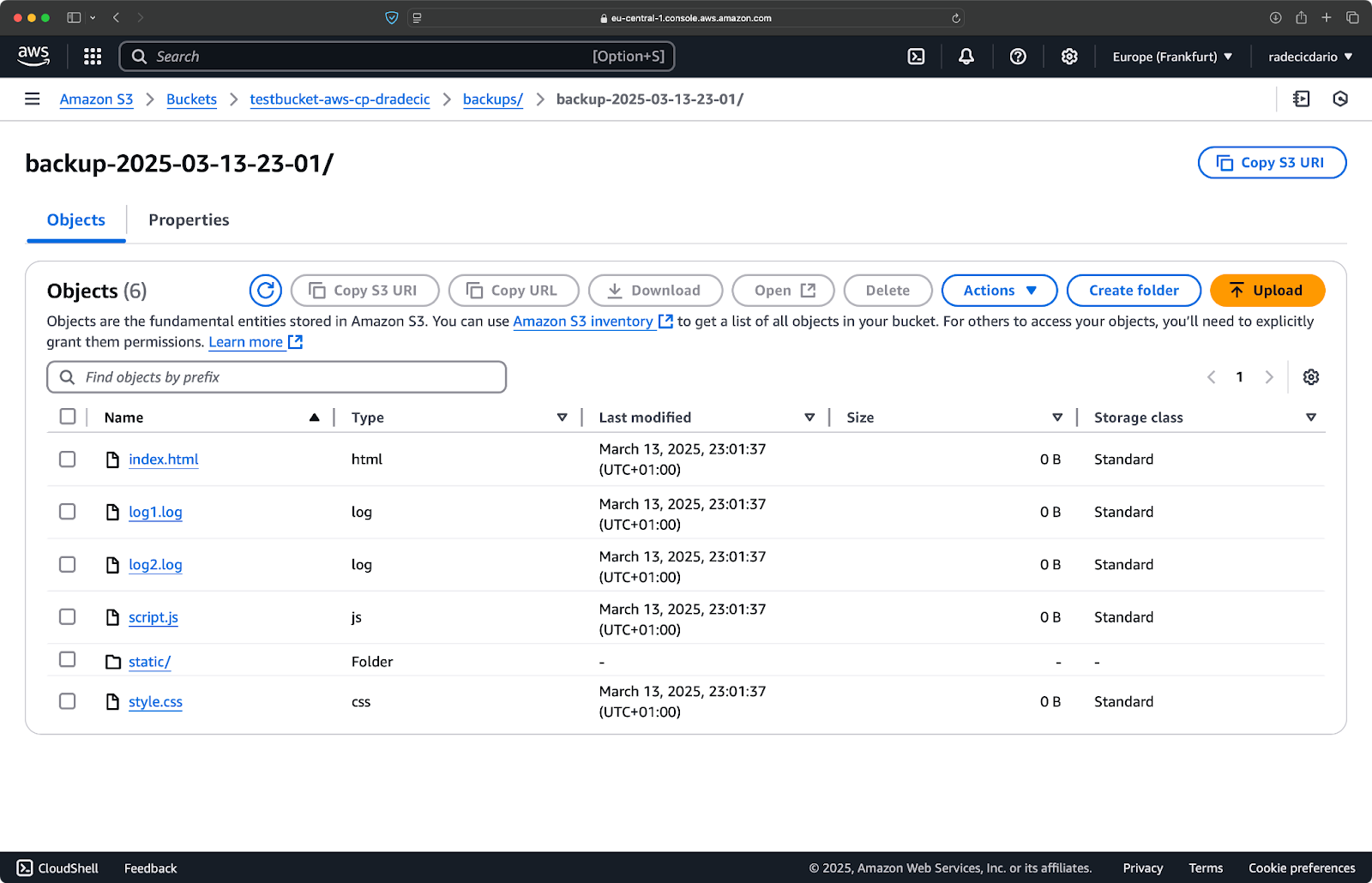
Imagem 20 – Backup armazenado no bucket S3
Vamos levar isso para o próximo nível executando o script em um agendamento.
Agendando transferências de arquivos com trabalhos cron
Agora que você tem um script, o próximo passo é agendá-lo para ser executado automaticamente em horários específicos.
Se estiver no Linux ou macOS, você pode usar cron para agendar seus backups. Veja como configurar um trabalho cron para executar seu script de backup todos os dias à meia-noite:
1. Abra seu crontab para edição:
crontab -e
2. Adicione a seguinte linha para executar seu script diariamente à meia-noite:
0 0 * * * /path/to/your/backup.sh
Imagem 21 – Trabalho Cron para executar script diariamente
O formato para trabalhos cron é minuto hora dia-do-mês mês dia-da-semana comando. Aqui estão mais alguns exemplos:
- Executar a cada hora:
0 * * * * /caminho/para/seu/backup.sh - Executar toda segunda-feira às 9h:
0 9 * * 1 /caminho/para/seu/backup.sh - Executar no dia 1 de todo mês:
0 0 1 * * /caminho/para/seu/backup.sh
E é isso! O script backup.sh agora será executado no intervalo agendado.
Automatizar suas transferências de arquivos S3 é uma ótima opção. É especialmente útil para cenários como:
- Backups diários de dados importantes
- Sincronização de imagens de produtos para um site
- Movendo arquivos de log para armazenamento de longo prazo
- Implantando arquivos de site atualizados
Técnicas de automação como essas ajudarão você a configurar um sistema confiável que lida com transferências de arquivos sem intervenção manual. Você só precisa escrever uma vez e depois pode esquecer.
Nesta próxima seção, vou abordar algumas melhores práticas para tornar suas operações aws s3 cp mais seguras e eficientes.
Melhores Práticas para Usar o AWS S3 cp
Embora o comando aws s3 cp seja fácil de usar, as coisas podem dar errado.
Se você seguir as melhores práticas, evitará armadilhas comuns, otimizará o desempenho e manterá seus dados seguros. Vamos explorar essas práticas para tornar suas operações de transferência de arquivos mais eficientes.
Gerenciamento eficiente de arquivos
Ao trabalhar com o S3, organizar seus arquivos de forma lógica economizará tempo e dores de cabeça no futuro.
Primeiro, estabeleça uma convenção de nomenclatura consistente para o bucket e prefixo. Por exemplo, você pode separar seus dados por ambiente, aplicativo ou data:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
Esse tipo de organização torna mais fácil:
- Encontrar arquivos específicos quando você precisa deles.
- Aplicar políticas e permissões de bucket no nível certo.
- Configurar regras de ciclo de vida para arquivar ou excluir dados antigos.
Outra dica: Ao transferir grandes conjuntos de arquivos, considere agrupar primeiro pequenos arquivos juntos (usando zip ou tar) antes de enviar. Isso reduz o número de chamadas de API para o S3, o que pode reduzir custos e acelerar as transferências.
# Em vez de copiar milhares de pequenos arquivos de log # compacte-os primeiro e depois faça o upload tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
Manuseio de transferência de dados grandes
Ao copiar arquivos grandes ou muitos arquivos de uma vez, existem algumas técnicas para tornar o processo mais confiável e eficiente.
Você pode usar a opção --quiet para diminuir a saída ao executar em scripts:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
Isto suprime as informações de progresso para cada arquivo, o que torna os logs mais gerenciáveis. Também melhora ligeiramente o desempenho.
Para arquivos muito grandes, considere usar uploads multipartes com a flag --multipart-threshold:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
A configuração acima diz ao AWS CLI para dividir arquivos maiores que 100MB em várias partes para upload. Fazê-lo tem algumas vantagens:
- Se a conexão cair, apenas a parte afetada precisa ser reenviada.
- As peças podem ser carregadas em paralelo, potencialmente aumentando o rendimento.
- Você pode pausar e retomar uploads grandes.
Ao transferir dados entre regiões, considere usar a Aceleração de Transferência do S3 para uploads mais rápidos:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
O acima encaminha sua transferência através da rede de borda da Amazon, o que pode acelerar significativamente as transferências entre regiões.
Garantindo segurança.
A segurança deve ser sempre uma prioridade ao trabalhar com seus dados na nuvem.
Em primeiro lugar, certifique-se de que as suas permissões IAM seguem o princípio do menor privilégio.Apenas conceda as permissões específicas necessárias para cada tarefa.
Aqui está um exemplo de política que você pode atribuir ao usuário:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
Esta política permite copiar arquivos somente para e a partir do prefixo “backups” no “meu-bucket”.
Uma maneira adicional de aumentar a segurança é ativar a criptografia para dados sensíveis. Você pode especificar a criptografia do lado do servidor ao fazer upload:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
Ou, para mais segurança, use o Serviço de Gerenciamento de Chaves da AWS (KMS):
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
No entanto, para operações altamente sensíveis, considere usar pontos de extremidade da VPC para o S3. Isso mantém seu tráfego dentro da rede AWS e evita a internet pública completamente.
Na próxima seção, você aprenderá como solucionar problemas comuns que você pode encontrar ao trabalhar com este comando.
Resolução de Erros AWS S3 cp
Uma coisa é certa – você ocasionalmente terá problemas ao trabalhar com aws s3 cp. Mas, ao entender os erros comuns e suas soluções, você economizará tempo e frustração quando as coisas não saírem como o planejado.
Nesta seção, mostrarei os problemas mais frequentes e como corrigi-los.
Erros comuns e soluções
Erro: “Acesso Negado”
Este é provavelmente o erro mais comum que você encontrará:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
Geralmente isso significa uma das três coisas:
- Seu usuário IAM não tem permissões suficientes para realizar a operação.
- A política do bucket está restringindo o acesso.
- As credenciais da AWS expiraram.
Para solucionar:
- Verifique suas permissões IAM para garantir que você tenha as permissões necessárias
s3:PutObject(para uploads) ous3:GetObject(para downloads). - Verifique se a política do bucket não está restringindo suas ações.
- Execute
aws configurepara atualizar suas credenciais se elas expiraram.
Erro: “Arquivo ou diretório não encontrado”
Esse erro ocorre quando o arquivo ou diretório local que você está tentando copiar não existe:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
A solução é simples – verifique cuidadosamente seus caminhos de arquivo. Os caminhos diferenciam maiúsculas de minúsculas, então tenha isso em mente. Além disso, certifique-se de estar no diretório correto ao usar caminhos relativos.
Erro: “O bucket especificado não existe”
Se você visualizar esse erro:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
Verifique:
- Possíveis erros no nome do seu bucket.
- Verifique se você está usando a região correta da AWS.
- Se o bucket realmente existe (ele pode ter sido deletado).
Você pode listar todos os seus buckets com aws s3 ls para confirmar o nome correto.
Erro: “Tempo de conexão esgotado”
Problemas de rede podem causar esgotamento de conexão:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
Para resolver isso:
- Verifique sua conexão com a internet.
- Tente usar arquivos menores ou habilitar uploads multipart para arquivos grandes.
- Considere usar o AWS Transfer Acceleration para obter melhor desempenho.
Tratando falhas de upload
É muito mais provável que ocorram erros ao transferir arquivos grandes. Quando isso acontecer, tente lidar com as falhas de forma adequada.
Por exemplo, você pode usar a flag --only-show-errors para facilitar o diagnóstico de erros em scripts:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
Isso suprime mensagens de transferências bem-sucedidas, mostrando apenas erros, o que facilita a resolução de problemas em transferências grandes.
Para lidar com transferências interrompidas, o comando --recursive irá automaticamente pular arquivos que já existem no destino com o mesmo tamanho. No entanto, para ser mais minucioso, você pode usar as tentativas embutidas da AWS CLI para problemas de rede configurando essas variáveis de ambiente:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
Isto diz à AWS CLI para tentar automaticamente operações falhadas até 5 vezes.
Mas para conjuntos de dados muito grandes, considere usar aws s3 sync em vez de cp, pois é projetado para lidar melhor com interrupções:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
O comando sync transferirá apenas arquivos diferentes do que já está no destino, tornando-o perfeito para retomar transferências grandes interrompidas.
Se você compreender esses erros comuns e implementar um tratamento de erro adequado em seus scripts, tornará suas operações de cópia no S3 muito mais robustas e confiáveis.
Resumindo, o AWS S3 cp
Para concluir, o comando aws s3 cp é um ponto único para copiar arquivos locais para o S3 e vice-versa.
Você aprendeu tudo sobre isso neste artigo. Você começou pelos fundamentos e configuração do ambiente, e acabou escrevendo scripts agendados e automatizados para copiar arquivos. Você também aprendeu como lidar com alguns erros comuns e desafios ao mover arquivos, especialmente os grandes.
Portanto, se você é um desenvolvedor, profissional de dados ou administrador de sistemas, acredito que encontrará este comando útil. A melhor maneira de se sentir confortável com ele é usando-o regularmente. Certifique-se de entender os fundamentos e, em seguida, dedique um tempo automatizando partes tediosas do seu trabalho.
Para saber mais sobre a AWS, siga estes cursos da DataCamp:
Você até pode usar a DataCamp para se preparar para os exames de certificação da AWS – Praticante de Nuvem AWS (CLF-C02).