













O que significa transformar linhas em colunas no SQL?
Pivotar em SQL refere-se a transformar dados de um formato baseado em linhas para um formato baseado em colunas. Essa transformação é útil para relatórios e análise de dados, permitindo uma visualização de dados mais estruturada e compacta. Pivotar linhas em colunas também permite que os usuários analisem e resumam dados de uma maneira que destaca insights-chave de forma mais clara.
Considere o seguinte exemplo: Eu tenho uma tabela com transações de vendas diárias, e cada linha registra a data, o nome do produto e o valor da venda.
| Date | Product | Sales |
|---|---|---|
| 2024-01-01 | Notebook | 100 |
| 2024-01-01 | Mouse | 200 |
| 2024-01-02 | Notebook | 150 |
| 2024-01-02 | Mouse | 250 |
Ao pivotar esta tabela, posso reestruturá-la para mostrar cada produto como uma coluna, com os dados de vendas para cada data sob sua coluna correspondente. Observe também que uma agregação ocorre.
| Date | Laptop | Mouse |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Tradicionalmente, as operações de pivô requeriam consultas SQL complexas com agregação condicional. Com o tempo, as implementações do SQL evoluíram, com muitos bancos de dados modernos agora incluindo os operadores PIVOT e UNPIVOT para permitir transformações mais eficientes e diretas.
Compreendendo a Transformação de Linhas em Colunas no SQL
A operação de pivô no SQL transforma os dados convertendo os valores das linhas em colunas. A seguir está a sintaxe básica e estrutura do pivô no SQL com as seguintes partes:
-
SELECT: A declaração
SELECTfaz referência às colunas a serem retornadas na tabela de pivô do SQL. -
Subconsulta: A subconsulta contém a fonte de dados ou tabela a ser incluída na tabela dinâmica SQL.
-
PIVOT: O operador
PIVOTcontém as agregações e filtros a serem aplicados na tabela dinâmica.
-- Selecione colunas estáticas e colunas pivotadas SELECT <static columns>, [pivoted columns] FROM ( -- Subconsulta definindo os dados de origem para o pivot <subquery that defines data> ) AS source PIVOT ( -- Função de agregação aplicada à coluna de valor, criando novas colunas <aggregation function>(<value column>) FOR <column to pivot> IN ([list of pivoted columns]) ) AS pivot_table;
Vamos olhar para o seguinte exemplo passo a passo para demonstrar como pivotar linhas para colunas em SQL. Considere a tabela SalesData abaixo.

Exemplo de tabela para transformar usando o operador SQL PIVOT. Imagem do Autor.
Eu quero pivotar esses dados para comparar as vendas diárias de cada produto. Começarei selecionando a subconsulta que estruturará o operador PIVOT.
-- Subconsulta definindo os dados de origem para o pivot SELECT Date, Product, Sales FROM SalesData;
Agora, usarei o operador PIVOT para converter os valores de Produto em colunas e agregar Vendas usando o operador SOMA.
-- Selecionar Data e colunas pivotadas para cada produto SELECT Date, [Laptop], [Mouse] FROM ( -- Subconsulta para buscar as colunas Data, Produto e Vendas SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Agregar Vendas por Produto, pivotando os valores do produto para colunas SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;

Exemplo de transformação de saída usando SQL para pivotar linhas em colunas. Imagem do Autor.
Embora a pivô de dados simplifique o resumo de dados, essa técnica pode apresentar problemas potenciais. A seguir estão os desafios potenciais com o pivô SQL e como abordá-los.
-
Nomes de Colunas Dinâmicas: Quando os valores a serem pivotados (por exemplo, Tipos de Produto) são desconhecidos, a codificação fixa dos nomes das colunas não funcionará. Alguns bancos de dados, como o SQL Server, suportam SQL dinâmico com procedimentos armazenados para evitar esse problema, enquanto outros exigem que isso seja tratado na camada da aplicação.
-
Lidando com Valores NULOS: Quando não há dados para uma coluna específica pivoteada, o resultado pode incluir
NULL. Você pode usarCOALESCEpara substituir os valoresNULLpor zero ou outro marcador. -
Compatibilidade entre Bancos de Dados: Nem todos os bancos de dados suportam diretamente o operador
PIVOT. Você pode obter resultados semelhantes com declaraçõesCASEe agregação condicional se o seu dialeto SQL não suportar.
Transformar Linhas em Colunas no SQL: Exemplos e Casos de Uso
Métodos diferentes são usados para pivotar dados em SQL, dependendo do banco de dados utilizado ou de outros requisitos. Enquanto o operador PIVOT é comumente usado no SQL Server, outras técnicas, como as instruções CASE, permitem transformações semelhantes no banco de dados sem suporte direto ao PIVOT. Vou abordar os dois métodos comuns de pivotar dados em SQL e falar sobre os prós e contras.
Usando o operador PIVOT
O operador PIVOT, disponível no SQL Server, fornece uma maneira direta de pivotar linhas em colunas, especificando uma função de agregação e definindo as colunas a serem pivotadas.
Considere a seguinte tabela chamada sales_data.

Exemplo de tabela de Pedidos a ser transformada usando o operador PIVOT. Imagem de Autor.
Vou usar o operador PIVOT para agregar os dados para que o total de sales_revenue de cada ano seja mostrado em colunas.
-- Usar PIVOT para agregar a receita de vendas por ano SELECT * FROM ( -- Selecionar as colunas relevantes da tabela de origem SELECT sale_year, sales_revenue FROM sales_data ) AS src PIVOT ( -- Agregar a receita de vendas para cada ano SUM(sales_revenue) -- Criar colunas para cada ano FOR sale_year IN ([2020], [2021], [2022], [2023]) ) AS piv;

Exemplo de transformação de saída usando o PIVOT SQL. Imagem do Autor.
O uso do operador PIVOT tem as seguintes vantagens e limitações:
-
Vantagens: O método é eficiente quando as colunas são adequadamente indexadas. Também possui uma sintaxe simples e mais legível.
-
Limitações: Nem todos os bancos de dados suportam o operador
PIVOT. É necessário especificar as colunas antecipadamente e o pivoteamento dinâmico requer complexidade adicional.
Pivotação manual com declarações CASE
Você também pode usar declarações CASE para pivotar manualmente dados em bancos de dados que não suportam operadores PIVOT, como MySQL e PostgreSQL. Esta abordagem utiliza agregação condicional avaliando cada linha e atribuindo condicionalmente valores às novas colunas com base em critérios específicos.
Por exemplo, podemos pivotar manualmente dados na mesma tabela sales_data com declarações CASE.
-- Agregar receita de vendas por ano usando declaraçõesCASESELECT -- Calcular a receita total de vendas para cada ano SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020, SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021, SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022, SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023 FROM sales_data;

Exemplo de transformação de saída usando a declaração CASE do SQL. Imagem por Autor.
O uso da declaração CASE para transformação tem as seguintes vantagens e limitações:
-
Vantagens: O método funciona em todos os bancos de dados SQL e é flexível para gerar dinamicamente novas colunas, mesmo quando os nomes dos produtos são desconhecidos ou mudam frequentemente.
-
Limitações: As consultas podem se tornar complexas e extensas se houver muitas colunas para pivotar. Devido às múltiplas verificações condicionais, o método é ligeiramente mais lento que o operador
PIVOT.
Considerações de Desempenho ao Transformar Linhas em Colunas
Transformar linhas em colunas no SQL pode ter implicações de desempenho, especialmente ao trabalhar com grandes conjuntos de dados. Aqui estão algumas dicas e melhores práticas para ajudá-lo a escrever consultas de pivot eficientes, otimizar seu desempenho e evitar armadilhas comuns.
Melhores práticas
As seguintes são as melhores práticas para otimizar suas consultas e melhorar o desempenho.
-
Estratégias de indexação: A indexação adequada é crucial para otimizar consultas de pivô, permitindo que o SQL recupere e processe os dados mais rapidamente. Sempre indexe as colunas frequentemente usadas na cláusula
WHEREou as colunas em que você está agrupando para reduzir os tempos de varredura. -
Avoid Nested Pivots:Empilhar várias operações de pivô em uma consulta pode ser difícil de ler e mais lento para executar. Simplifique dividindo a consulta em partes ou usando uma tabela temporária.
-
Limitar Colunas e Linhas no Pivot:Apenas as colunas do pivô são necessárias para a análise, pois pivotar muitas colunas pode ser intensivo em recursos e criar tabelas grandes.
Evitando armadilhas comuns
A seguir estão os erros comuns que você pode encontrar em consultas de tabela dinâmica e como evitá-los.
-
Escaneamentos de Tabela Completos Desnecessários: Consultas de tabela dinâmica podem acionar escaneamentos completos de tabela, especialmente se não houver índices relevantes disponíveis. Evite escaneamentos completos de tabela indexando colunas-chave e filtrando dados antes de aplicar a tabela dinâmica.
-
Uso de SQL Dinâmico para Pivotação Frequente: Usar SQL dinâmico pode diminuir o desempenho devido à recompilação da consulta. Para evitar esse problema, armazene em cache ou limite pivôs dinâmicos a cenários específicos e considere lidar com colunas dinâmicas na camada de aplicação sempre que possível.
-
Agregando em Grandes Conjuntos de Dados Sem Pré-filtragem: Funções de agregação como
SUMouCOUNTem grandes conjuntos de dados podem diminuir o desempenho do banco de dados. Em vez de pivoteamento do conjunto de dados inteiro, filtre os dados primeiro usando uma cláusulaWHERE. -
Valores Nulos em Colunas Pivoteadas: Operações de pivoteamento frequentemente produzem valores
NULLquando não há dados para uma coluna específica. Isso pode retardar as consultas e tornar os resultados mais difíceis de interpretar. Para evitar esse problema, use funções comoCOALESCEpara substituir os valoresNULLpor um valor padrão. -
Testando Apenas com Dados de Amostra: Consultas de pivoteamento podem se comportar de forma diferente com conjuntos de dados grandes devido ao aumento da demanda de memória e processamento. Sempre teste consultas de pivoteamento em dados reais ou amostras representativas para avaliar com precisão os impactos de desempenho.
Experimente nossa trilha de carreira em SQL Server Developer, que abrange tudo, desde transações e tratamento de erros até a melhoria do desempenho de consultas.
Implementações Específicas de Banco de Dados
As operações de pivô diferem significativamente entre bancos de dados como SQL Server, MySQL e Oracle. Cada um desses bancos de dados possui uma sintaxe e limitações específicas. Vou cobrir exemplos de pivô de dados nos diferentes bancos de dados e suas principais características.
SQL Server
O SQL Server fornece um operador PIVOT embutido, que é simples ao pivotar linhas para colunas. O operador PIVOT é fácil de usar e integra-se com as poderosas funções de agregação do SQL Server. As principais características do pivotamento em SQL incluem o seguinte:
-
Suporte Direto para PIVOT e UNPIVOT: O operador
PIVOTdo SQL Server permite uma rápida transformação de linhas para colunas. O operadorUNPIVOTtambém pode reverter esse processo. -
Opções de Agregação: O operador
PIVOTpermite várias funções de agregação, comoSOMA,CONTAReMÉDIA.
A limitação do operador PIVOT no SQL Server é que ele requer que os valores das colunas a serem pivotados sejam conhecidos com antecedência, tornando-o menos flexível para dados que mudam dinamicamente.
No exemplo abaixo, o operador PIVOT converte os valores de Product em colunas e agrega Sales usando o operador SUM.
-- Selecionar data e colunas pivoteadas para cada produto SELECT Date, [Laptop], [Mouse] FROM ( -- Subconsulta para obter as colunas de Data, Produto e Vendas SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Agregar Vendas por Produto, pivotando os valores do produto para colunas SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;
Recomendo fazer o curso Introdução ao SQL Server da DataCamp para dominar os conceitos básicos do SQL Server para análise de dados.
MySQL
O MySQL não possui suporte nativo para o operador PIVOT. No entanto, você pode usar a instrução CASE para pivotar manualmente as linhas para colunas e combinar outras funções de agregação como SUM, AVG e COUNT. Embora esse método seja flexível, pode se tornar complexo se você tiver muitas colunas para pivotar.
A consulta abaixo alcança a mesma saída do exemplo PIVOT do SQL Server condicionalmente agregando vendas para cada produto usando a declaração CASE.
-- Selecionar Data e colunas pivotadas para cada produto SELECT Date, -- Usar CASE para criar uma coluna para vendas de Laptop e Mouse SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop, SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse FROM SalesData GROUP BY Date;
Oracle
O Oracle suporta o operador PIVOT, que permite a transformação direta de linhas em colunas. Assim como no SQL Server, você precisará especificar explicitamente as colunas para a transformação.
Na consulta abaixo, o operador PIVOT converte os valores de ProductName em colunas e agrega SalesAmount usando o operador SUM.
SELECT * FROM ( -- Seleção de dados de origem SELECT SaleDate, ProductName, SaleAmount FROM SalesData ) PIVOT ( -- Agregar Vendas por Produto, criando colunas pivotadas SUM(SaleAmount) FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse) );

Exemplo de transformação de saída usando o operador PIVOT em SQL no Oracle. Imagem do Autor.
Técnicas Avançadas para Transformar Linhas em Colunas no SQL
Técnicas avançadas para transformar linhas em colunas são úteis quando você precisa de flexibilidade no manuseio de dados complexos. Técnicas dinâmicas e o manuseio de múltiplas colunas simultaneamente permitem que você transforme dados em cenários onde a pivotação estática é limitada. Vamos explorar esses dois métodos em detalhes.
Pivots Dinâmicos
Pivots dinâmicos permitem que você crie consultas pivot que se adaptam automaticamente a alterações nos dados. Essa técnica é particularmente útil quando você tem colunas que mudam com frequência, como nomes de produtos ou categorias, e deseja que sua consulta inclua novas entradas automaticamente sem precisar atualizá-la manualmente.
Suponha que temos uma tabela SalesData e podemos criar um pivô dinâmico que se ajusta se novos produtos forem adicionados. Na consulta abaixo, @columns constrói dinamicamente a lista de colunas pivotadas, e sp_executesql executa o SQL gerado.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX); -- Passo 1: Gerar uma lista de produtos distintos para pivotar SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ') FROM (SELECT DISTINCT Product FROM SalesData) AS products; -- Passo 2: Construir a consulta SQL dinâmica SET @sql = N' SELECT Date, ' + @columns + ' FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT ( SUM(Sales) FOR Product IN (' + @columns + ') ) AS pivot_table;'; -- Passo 3: Executar o SQL dinâmico EXEC sp_executesql @sql;
Manuseando múltiplas colunas
Em cenários onde você precisa pivotar múltiplas colunas simultaneamente, você usará o operador PIVOT e técnicas adicionais de agregação para criar múltiplas colunas na mesma consulta.
No exemplo abaixo, eu pivotar as colunas Sales e Quantity por Product.
-- Vendas e Quantidade de Laptops e Mouses por Data SELECT p1.Date, p1.[Laptop] AS Laptop_Sales, p2.[Laptop] AS Laptop_Quantity, p1.[Mouse] AS Mouse_Sales, p2.[Mouse] AS Mouse_Quantity FROM ( -- Pivot para Vendas SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT (SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales ) p1 JOIN ( -- Pivot para Quantidade SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Quantity FROM SalesData) AS source PIVOT (SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity ) p2 ON p1.Date = p2.Date;
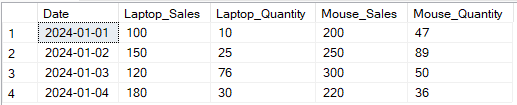
Exemplo de transformação de saída de múltiplas colunas usando o operador PIVOT do SQL. Imagem do Autor.
Pivotar várias colunas permite relatórios mais detalhados, pivotando múltiplos atributos por item, possibilitando insights mais ricos. No entanto, a sintaxe pode ser complexa, especialmente se existirem muitas colunas. Pode ser necessário codificar manualmente, a menos que combinado com técnicas de pivot dinâmico, adicionando maior complexidade.
Conclusão
Pivotar linhas para colunas é uma técnica do SQL que vale a pena aprender. Já vi técnicas de pivot do SQL sendo usadas para criar uma tabela de retenção de coorte, onde você pode rastrear a retenção de usuários ao longo do tempo. Também já vi técnicas de pivot do SQL sendo usadas ao analisar dados de pesquisa, onde cada linha representa um respondente, e cada pergunta pode ser pivotada em sua coluna.
Nosso curso Reporting em SQL é uma ótima opção se você deseja aprender mais sobre resumir e preparar dados para apresentações e/ou construção de painéis. Nossas trilhas de carreira Analista de Dados Associado em SQL e Engenheiro de Dados Associado em SQL são outra excelente ideia, e agregam muito a qualquer currículo, então matricule-se hoje.
Source:
https://www.datacamp.com/tutorial/sql-pivot-rows-to-columns