













Quando você tem máquinas virtuais críticas e serviços críticos em execução nelas, sua disponibilidade deve ser garantida durante os horários de funcionamento de sua organização. Uma das maneiras de alcançar alta disponibilidade é usar um cluster para garantir a execução contínua de serviços e aplicativos.
A plataforma de virtualização VMware vSphere permite que você use um cluster para executar máquinas virtuais (VMs) e use o VMware vSphere High Availability (HA). Esta postagem no blog explica a configuração do VMware vSphere HA para familiarizá-lo com os parâmetros a serem configurados.
O que é o HA no VMware vSphere?
O VMware High Availability (HA) é um recurso que proporciona disponibilidade ideal para máquinas virtuais do vSphere, incluindo aplicativos e serviços em execução nas VMs, para minimizar o tempo de inatividade em caso de falhas. Alta Disponibilidade (HA), ou a capacidade de um ambiente virtual resistir a falhas de host, é uma das razões importantes para você escolher implantar VMware vCenter e um cluster em vez de um host VMware ESXi independente.
Quando o HA está sendo executado em um cluster VMware, um agente é instalado em cada anfitrião participante no cluster. Cada agente de anfitrião se comunica entre si e monitora a可达性 dos anfitriões no cluster através de heartbeats. Se um intervalo de 15 segundos passa sem a recepção de heartbeats de um anfitrião particular e as tentativas de ping no anfitrião também falharam, o anfitrião é declarado como falho. As VMs executadas nas recursos de computação/memória desse anfitrião falho são transferidas para um anfitrião saudável e reiniciadas nesse anfitrião.
O HA no vSphere pode monitorizar a saúde do hardware dos seus anfitriões de modo proativo para mover as VMs de anfitriões que têm problemas de hardware. Existem também prioridades de reinício e orquestração integradas no HA, e como resultado, as VMs designadas são colocadas online antes das demais no caso de um failover. Essas funcionalidades estão disponíveis nas versões VMware vSphere 6.7 e vSphere 7.
Requisitos do Cluster VMware
Há algumas exigências de VMware para criar um cluster VMware com HA habilitado. As exigências incluem:
- Os anfitriões no cluster HA devem estar licenciados para o vSphere HA. Aplicam-se as licenças de VMware vSphere Standard ou Enterprise Plus, incluindo as licenças vCenter Standard.
- São necessários dois anfitriões para habilitar o HA. É recomendado ter três ou mais anfitriões.
- Endereços IP estáticos configurados em cada host são a melhor prática.
- Você precisa de pelo menos uma rede de gerenciamento comum entre os hosts.
- Para que as VMs possam ser executadas em todos os hosts caso sejam movidas para diferentes hosts no cluster, os hosts precisam ter as mesmas redes e datastores configurados.
- O armazenamento compartilhado é necessário para a HA.
- VMware Tools precisam estar em execução nas VMs monitoradas na HA.
Configuração Passo a Passo do VMware HA
Você pode habilitar o VMware HA enquanto estiver criando um cluster ou quando já tiver criado um cluster. Neste guia de configuração do vSphere HA, estamos focados na configuração de Alta Disponibilidade e já temos um cluster criado. Usamos VMware vSphere 7 para explicar a configuração passo a passo do VMware HA.
Como habilitar a HA no VMware vSphere
Para habilitar a HA no VMware vSphere em um cluster existente, faça o seguinte:
- Abra o VMware vSphere Client em seu navegador web.
- Vá para Hosts e clusters e navegue até o seu cluster.
- Clique com o botão direito no nome do cluster no painel Navigator.
- Clique em Configurações no menu de contexto.
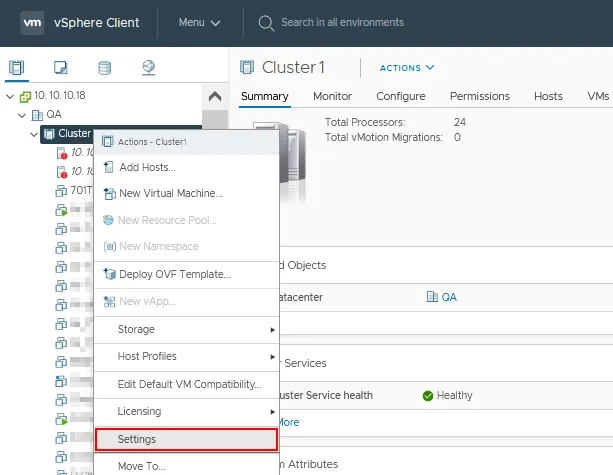
- Selecione vSphere Availability na seção Serviços da página Configurar para o seu cluster.
- Clique em Editar próximo a vSphere HA que está desativado no nosso caso.
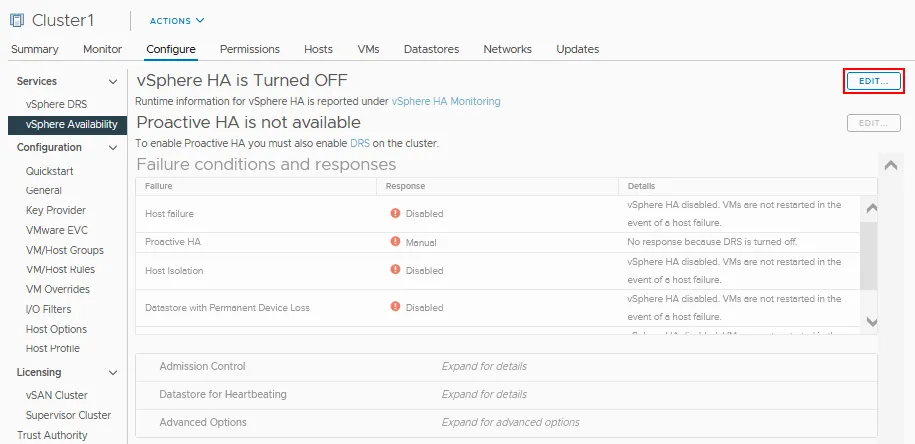
- Clique no interruptor vSphere HA para habilitar Alta Disponibilidade.
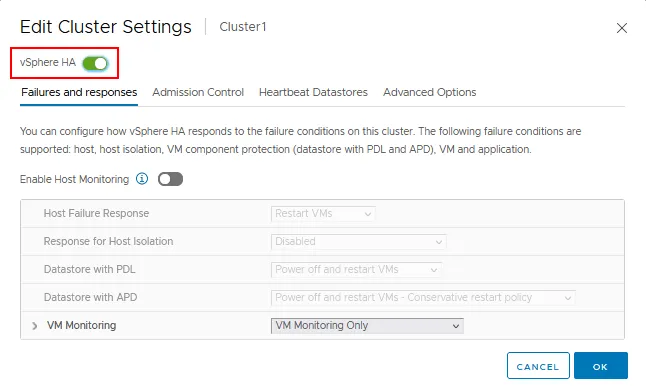
Há quatro guias com as configurações do vSphere HA:
- Falhas e respostas
- Controle de Admissão
- Datastores de Batimento Cardíaco
- Opções Avançadas
Vamos olhar para a configuração do vSphere HA que você pode fazer editando as configurações nessas guias.
A guia Falhas e respostas
A guia Falhas e respostas é usada para personalizar o comportamento de um cluster HA e definir o que fazer com as VMs em diferentes situações.
Habilitar Monitoramento de Host. Habilite esta opção para permitir que os hosts ESXi troquem batimentos cardíacos no cluster. Um cluster VMware vSphere HA usa batimentos cardíacos para detectar quando quaisquer componentes do cluster estão indisponíveis. Desabilite esta opção ao realizar manutenção na rede para evitar migração indesejada de VMs e failover.
Vamos revisar todas as configurações na guia Falhas e respostas.
Resposta a Falha do Host
- Resposta de falha. Use estas configurações para definir como um cluster HA responde às condições de falha neste cluster. Dois modos estão disponíveis:
- Desativado – O monitoramento do host ESXi está desligado.
- Reiniciar VMs – As VMs são reiniciadas na ordem determinada em caso de falha do host.
- Prioridade de reinicialização da VM padrão. Esta configuração é usada para determinar qual grupo de VMs deve ser reiniciado primeiro. Existem cinco valores: Mais baixa, Baixa, Média, Alta e Mais alta. As VMs são reiniciadas em ordem de prioridade, um grupo de cada vez.
- Condição de reinicialização de dependência de VM. Selecione uma condição que, quando atendida, um cluster detecta que as VMs foram reiniciadas com sucesso e o próximo lote de VMs pode ser reiniciado. Quatro condições estão disponíveis:
- Recursos alocados
- Ativado
- Batimentos cardíacos do convidado detectados
- Batimentos cardíacos do aplicativo detectados
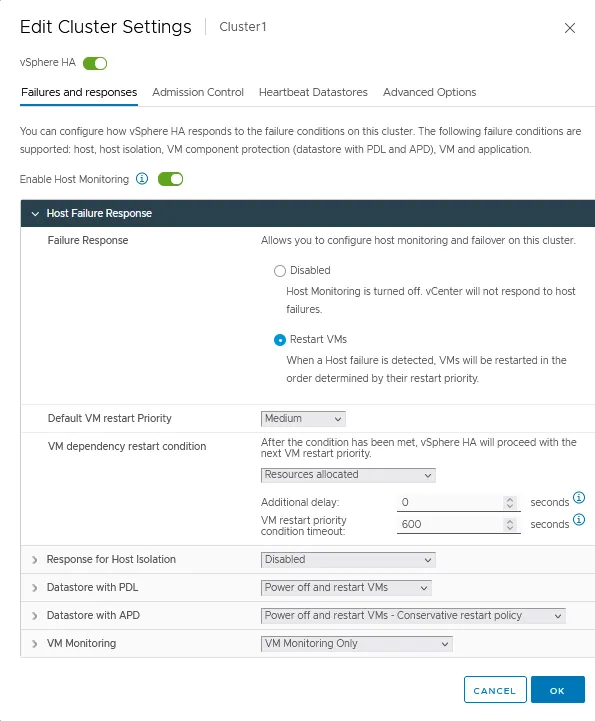
Resposta para Isolamento do Host
A opção Resposta ao isolamento do host permite definir o comportamento de um cluster HA quando um host ESXi continua funcionando, mas perde conexões de rede de gerenciamento:
- Desativado
- Desligar e reiniciar VMs
- Desligar e reiniciar VMs

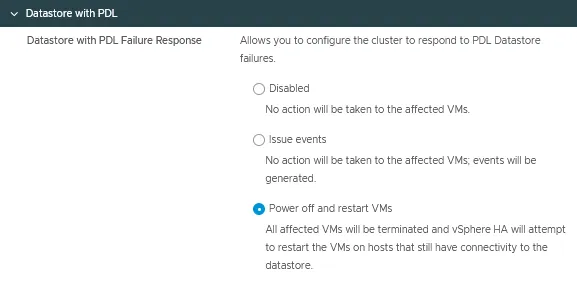
Datastore com PDL
A resposta de falha do Datastore com perda permanente de dispositivo (PDL) pode ser configurada para detectar a inacessibilidade do datastore por um host ESXi e iniciar uma failover automatizada das VMs afetadas.
Existem três modos para essa opção de configuração do vSphere HA:
- Desabilitado
- Emitir eventos
- Desligar e reiniciar VMs
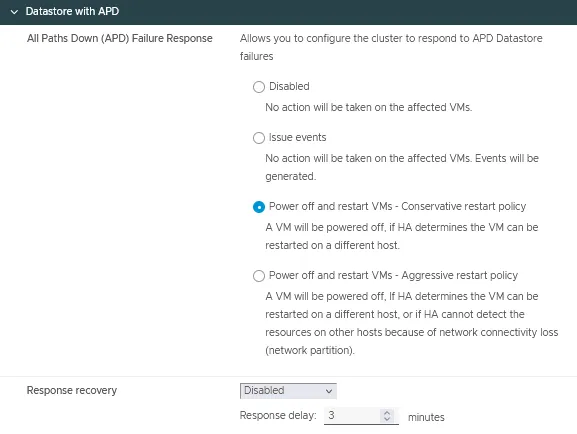
Datastore com APD
- Todas as Paths Desconectadas (APD) – Resposta à Falha é a condição que permite que um cluster responda quando todas as paths estão desconectadas e não há indicação se isso é uma perda temporária ou permanente do dispositivo.
Quatro opções estão disponíveis para essa configuração:- Desabilitado
- Emitir eventos
- Desligar e reiniciar VMs – Política de reinicialização conservadora
- Desligar e reiniciar VMs – Política de reinicialização agressiva
- Recuperação da resposta possui duas opções:
- Desabilitado
- Resetar VMs
Você pode definir o atraso da resposta em minutos.
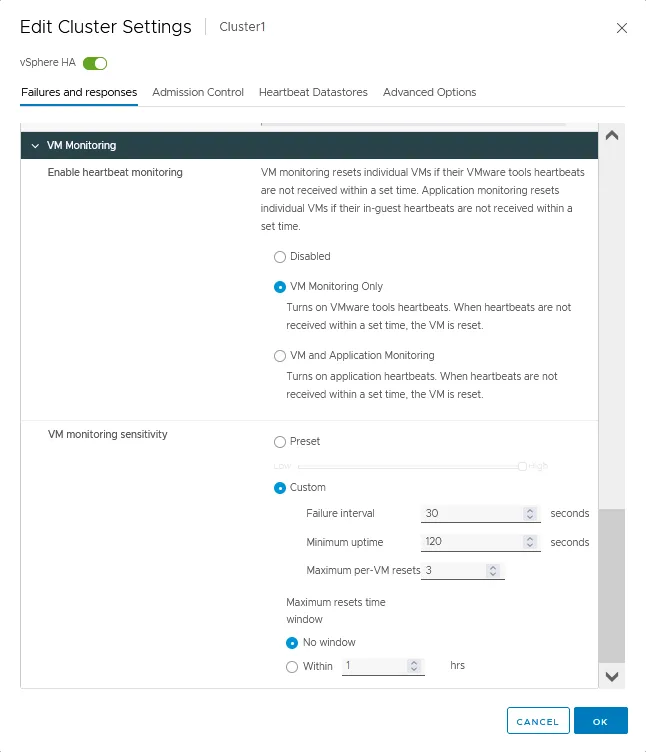
Monitoramento de VMs
- Ativar o monitoramento de batimentos cardíacos para máquinas virtuais usando ferramentas VMware em execução nelas. Você também pode configurar o monitoramento de aplicações usando essas capacidades. Se os batimentos cardíacos da VM não forem recebidos a tempo, é iniciado o reinício da VM. Há três opções para esta configuração no cluster VMware:
- Desabilitado
- Monitoramento de VM Somente
- Monitoramento de VM e Aplicação
- Sensibilidade do monitoramento de VM é usada para definir o tempo depois do qual uma VM é classificada como indisponível e um cluster HA pode iniciar o reinício da VM.
- Pré-definido. Você pode mover o interruptor de baixo para alto valor.
- Personalizado. Defina parâmetros de sensibilidade personalizados, incluindo intervalo de falha, tempo máximo de execução e máximo de reinícios por VM. O período máximo de reinícios pode ser definido para um valor personalizado em horas.
Nota: Você pode também usar uma solução de monitoramento de VM para detectar falhas e problemas para VMs que não estão em um cluster.
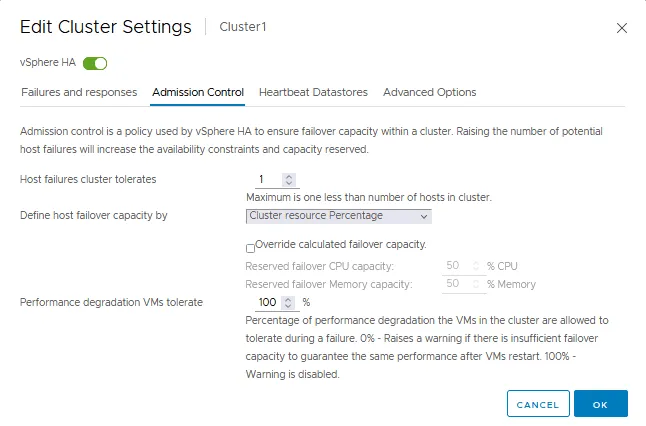
A aba Admissão de Controle
O controle de admissão é uma política usada para garantir que recursos suficientes são reservados para o funcionamento de máquinas virtuais em caso de failover em um cluster HA VMware. As configurações de controle de admissão garantem capacidade de failover. Se uma ação violar as configurações de controle de admissão, essa ação não é permitida. Essas ações proibidas incluem ligar uma VM, migrar uma VM e aumentar as configurações de CPU e memória para uma VM.
- O controle de admissão define quantos falhas um cluster HA pode tolerar e ainda assim tornar possível o failover de VMs (uma garantia de failover de VMs).
- Você pode definir a capacidade de failover de hosts através de:
- Porcentagem de recursos do cluster
- Hosts de failover dedicados
- Política de slot
Se você desabilitar o controle de admissão, não poderá garantir que o número esperado de VMs será reiniciado em um cluster HA em caso de failover.
- Degradação de performance que as VMs toleram é a configuração que define a porcentagem de degradação de performance que seu cluster pode tolerar. 0% significa que o mesmo nível de desempenho das VMs deve ser garantido após o failover/reinício de VM. Caso contrário, é exibida uma advertência. 100% significa que a advertência está desabilitada e o cluster tenta reiniciar a VM mesmo assim.
A aba Datastores de Heartbeat
Os datastores de batimento cardíaco fornecem uma maneira secundária de monitorar a disponibilidade dos hosts ESXi usando datastores se a conexão de rede com os hosts ESXi estiver indisponível e uma rede de gerenciamento falhar. Esta abordagem permite ao vSphere distinguir entre falha do host e indisponibilidade do host via rede. Use datastores de batimento cardíaco na configuração do VMware HA para monitorar hosts quando uma rede HA falhar.
A política de seleção de datastore de batimento cardíaco tem três opções:
- Selecionar automaticamente datastores acessíveis a partir dos hosts
- Usar apenas datastores da lista especificada
- Usar datastores da lista especificada e complementar automaticamente, se necessário

A guia Opções Avançadas
A guia Opções Avançadas permite configurar o vSphere HA inserindo manualmente uma opção e valor em cada string. Você pode usar opções avançadas quando não puder ajustar um cluster HA nas configurações padrão que explicamos anteriormente, disponíveis na GUI do VMware vSphere Client.
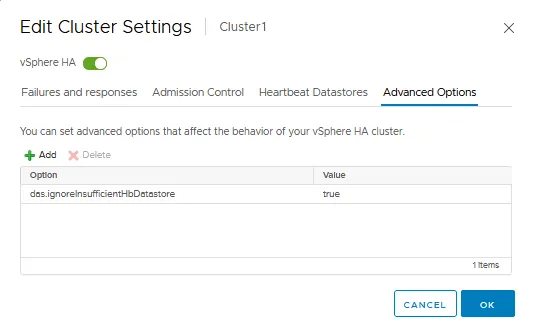
Assim como o VMware Distributed Resource Scheduler (DRS), após clicarmos em OK, o cluster VMware é reconfigurado para as configurações de HA configuradas acima.
VMware vSphere Proactive HA
O Proactive HA é um recurso que faz com que um cluster reaja a um problema antes que ocorra uma falha de todos os hosts ESXi e VMs que residem nesse host. Problemas podem ocorrer com diferentes componentes de um servidor ESXi, e o vSphere Proactive HA pode detectar as condições de hardware de um servidor.
Por exemplo, o Proactive HA pode ser notificado de que há problemas com o fornecimento de energia para um servidor ESXi. As VMs continuam a ser executadas neste servidor, mas esse problema pode levar a uma falha do servidor em breve. Para evitar possíveis falhas das VMs, o vSphere Proactive HA pode iniciar a migração das VMs para outros hosts ESXi de um cluster. O Proactive HA suporta reagir a problemas relacionados ao fornecimento de energia, ventoinha, armazenamento, memória e rede.
Você precisa habilitar e configurar o Balanceamento de Recursos Distribuídos (DRS) em um cluster vSphere antes de poder habilitar o Proactive HA. Você pode configurar o vSphere HA e DRS juntos para um cluster.
Pensamentos Conclusivos
O verdadeiro poder, resiliência e escalabilidade da plataforma VMware vSphere ESXi são desbloqueados assim que o servidor vCenter é provisionado e os hosts ESXi são adicionados a um cluster vSphere ESXi. Configure o vSphere HA e o DRS para fornecer efetivamente proteção contra falhas de host, bem como equilibrar e agendar recursos para as VMs. Tanto o DRS quanto o HA são ainda mais poderosos desde o vSphere 6.5, pois a VMware adicionou monitoramento e insights mais proativos e inteligentes a esses recursos de cluster, permitindo que sejam ágeis e proativos.
Não se esqueça de realizar o backup de VMs da VMware, mesmo que suas VMs estejam em execução no cluster, para evitar a perda de dados.
Source:
https://www.nakivo.com/blog/vmware-cluster-ha-configuration/