













Wanneer u kritieke virtuele machines en kritieke services daarop hebt draaien, moet hun beschikbaarheid worden gegarandeerd tijdens de operationele uren van uw organisatie. Een van de manieren om hoge beschikbaarheid te bereiken, is door een cluster te gebruiken om continu draaiende services en toepassingen te garanderen.
Het virtualisatieplatform VMware vSphere stelt u in staat om een cluster te gebruiken voor het uitvoeren van virtuele machines (VM’s) en gebruik te maken van vSphere High Availability (HA). Deze blogpost legt de configuratie van VMware vSphere HA uit om u vertrouwd te maken met de parameters om te configureren.
Wat Is HA in VMware vSphere?
VMware High Availability (HA) is een functie die optimale beschikbaarheid biedt voor vSphere virtuele machines, inclusief toepassingen en services die op de VM’s draaien, om de downtime in geval van storingen te minimaliseren. High Availability (HA), ofwel de mogelijkheid van een virtuele omgeving om hoststoringen te weerstaan, is een van de belangrijke redenen waarom u ervoor zou kiezen om VMware vCenter en een cluster in te zetten in plaats van een op zichzelf staande VMware ESXi-host .
Wanneer HA draait op een VMware-cluster, wordt er een agent geïnstalleerd op elke host die deelneemt aan het cluster. Elke hostagent communiceert met de andere en controleert de bereikbaarheid van de hosts in het cluster via hartslagen. Als er een interval van 15 seconden verstrijkt zonder ontvangst van hartslagen van een bepaalde host en pings naar de host ook mislukken, wordt de host als mislukt verklaard. De VM’s die draaien op de reken-/geheugenbronnen van die mislukte host worden overgezet naar een gezonde host en opnieuw opgestart op die host.
HA in vSphere kan de hardwaregezondheid van uw hosts controleren om proactief VM’s van hosts met hardwareproblemen te verplaatsen. Er zijn ook herstartprioriteiten en orchestratie opgenomen in HA en als gevolg daarvan worden aangewezen VM’s online gebracht voordat anderen in geval van failover. Deze functies zijn beschikbaar in de VMware vSphere 6.7 en vSphere 7 versies.
Vereisten voor VMware-cluster
Er zijn een paar vereisten van VMware om een VMware-cluster met HA ingeschakeld te maken. De vereisten omvatten:
- Hosts in het HA-cluster moeten gelicentieerd zijn voor vSphere HA. VMware vSphere Standard of Enterprise Plus, inclusief vCenter Standard-licenties, moeten worden toegepast.
- Er zijn twee hosts nodig om HA in te schakelen. Drie of meer hosts worden aanbevolen.
- Statische IP-adressen geconfigureerd op elke host is de beste praktijk.
- Je hebt minstens één beheersnetwerk nodig dat gemeenschappelijk is over de hosts.
- Om ervoor te zorgen dat VM’s kunnen draaien over alle hosts in geval ze worden verplaatst naar verschillende hosts in de cluster, moeten de hosts dezelfde netwerken en datastores geconfigureerd hebben.
- Gedeelde opslag is vereist voor HA.
- VMware Tools moeten draaien op VM’s die worden gemonitord in HA.
VMware HA Configuratie Stap voor Stap
Je kunt VMware HA inschakelen terwijl je een cluster aanmaakt of wanneer je al een cluster hebt aangemaakt. In deze vSphere HA configuratie handleiding, richten we ons op het configureren van High Availability en we hebben al een cluster aangemaakt. We gebruiken VMware vSphere 7 om de VMware HA configuratie stap voor stap uit te leggen.
Hoe HA inschakelen in VMware vSphere
Om HA in te schakelen in VMware vSphere in een bestaand cluster, doe het volgende:
- Open VMware vSphere Client in je webbrowser.
- Ga naar Hosts en clusters en navigeer naar je cluster.
- Klik met de rechtermuisknop op de clusternaam in het Navigatie paneel.
- Klik op Instellingen in het contextmenu.
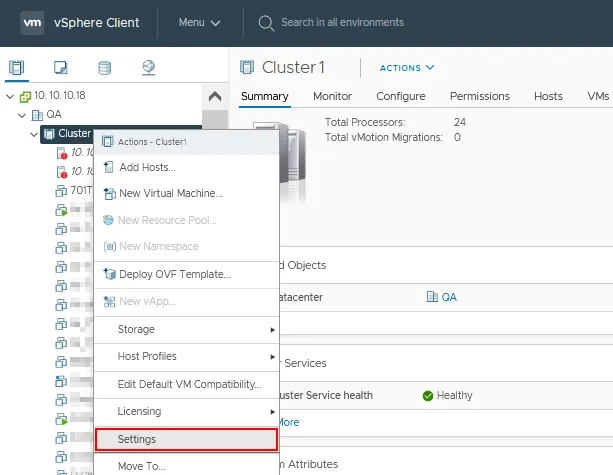
- Selecteer vSphere Beschikbaarheid in de Services sectie van de Configureren pagina voor uw cluster.
- Klik op Bewerken bij vSphere HA dat in ons geval is uitgeschakeld.
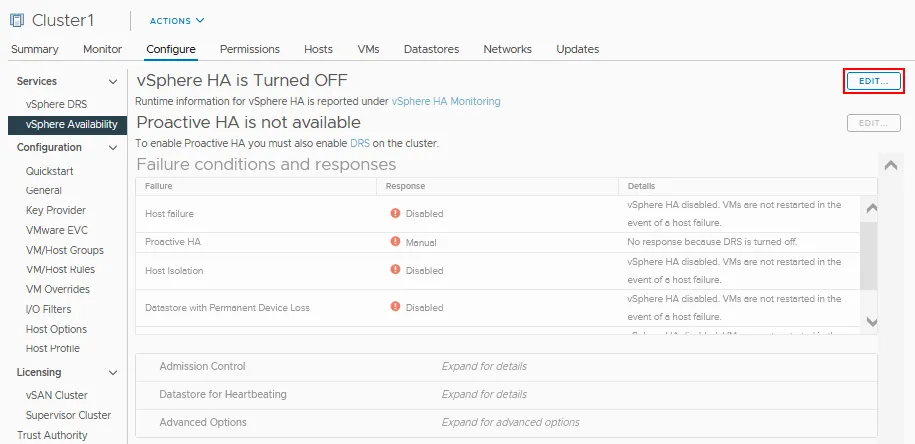
- Klik op de vSphere HA schakelaar om High Availability in te schakelen.
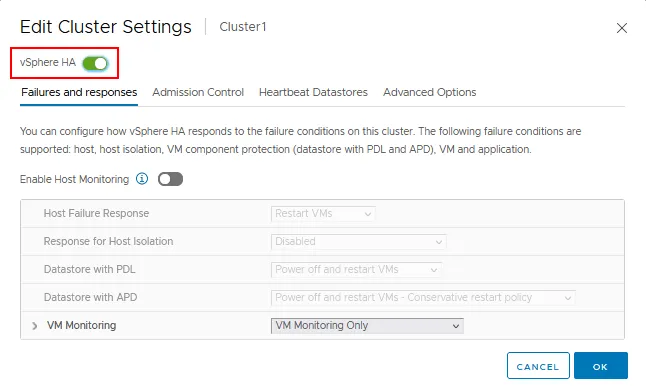
Er zijn vier tabbladen met vSphere HA-instellingen:
- Fouten en reacties
- Toelatingscontrole
- Heartbeat Datastores
- Geavanceerde opties
Laten we kijken naar de vSphere HA-configuratie die u kunt doen door de instellingen in deze tabbladen te bewerken.
Het Fouten en reacties tabblad
Het Fouten en reacties tabblad wordt gebruikt om het gedrag van een HA-cluster aan te passen en in te stellen wat te doen met VM’s in verschillende situaties.
Host Monitoring inschakelen. Schakel deze optie in om ESXi-hosts in staat te stellen hartslagen uit te wisselen in het cluster. Een VMware vSphere HA-cluster gebruikt hartslagen om te detecteren wanneer clustercomponenten niet beschikbaar zijn. Schakel deze optie uit bij het uitvoeren van netwerkonderhoud om ongewenste VM-migratie en failover te voorkomen.
Laten we alle instellingen in het Fouten en reacties tabblad bekijken.
Reactie op Hostfouten
- Mislukte Reactie. Gebruik deze instellingen om in te stellen hoe een HA-cluster reageert op de foutcondities op dit cluster. Er zijn twee modi beschikbaar:
- Uitgeschakeld – ESXi-hostbewaking is uitgeschakeld.
- Herstart VM’s – VM’s worden herstart in de bepaalde volgorde in geval van hostfout.
- Standaard VM-herstartprioriteit. Deze instelling wordt gebruikt om te bepalen welke VM-groep als eerste moet worden herstart. Er zijn vijf waarden: Laagste, Laag, Gemiddeld, Hoog, en Hoogste. De VM’s worden herstart in volgorde van prioriteit, één groep per keer.
- VM-afhankelijkheid herstartvoorwaarde. Selecteer een voorwaarde waaraan moet worden voldaan, zodat een cluster detecteert dat VM’s succesvol zijn herstart, en de volgende batch VM’s kan worden herstart. Vier voorwaarden zijn beschikbaar:
- Toegewezen middelen
- Ingeschakeld
- Gast Heartbeats gedetecteerd
- App Heartbeats gedetecteerd
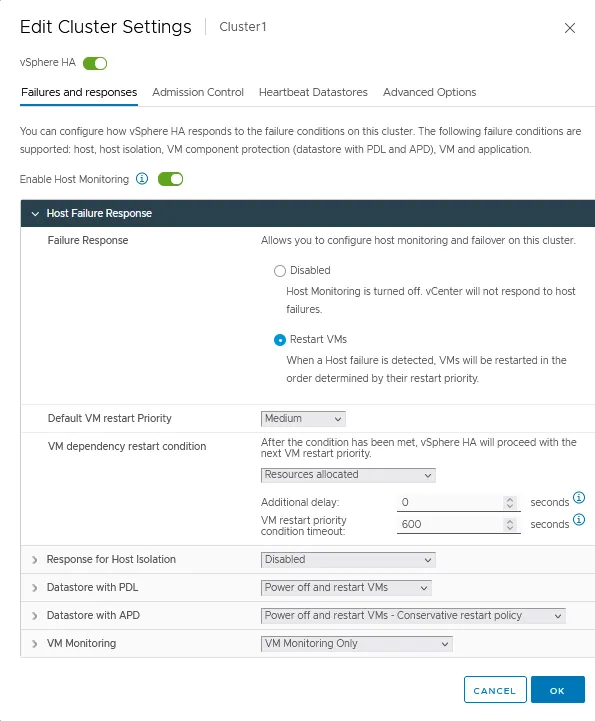
Reactie op Hostisolatie
De optie Hostisolatiereactie stelt u in staat om het gedrag van een HA-cluster in te stellen wanneer een ESXi-host blijft draaien maar de beheersnetwerkverbindingen verliest:
- Uitgeschakeld
- Uitschakelen en VM’s herstarten
- Schakel VM’s uit en herstart ze

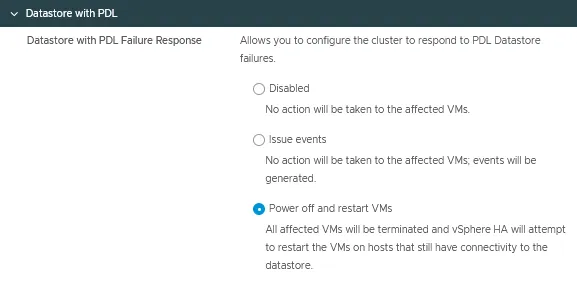
Datastore met PDL
Datastore met permanente apparaatverlies (PDL) foutreactie kan geconfigureerd worden om de ontoegankelijkheid van de datastore door een ESXi-host te detecteren en een geautomatiseerde failover van getroffen VM’s te initiëren.
Er zijn drie modi voor deze vSphere HA-configuratieoptie:
- Uitgeschakeld
- Gebeurtenissen uitgeven
- VM’s uitschakelen en herstarten
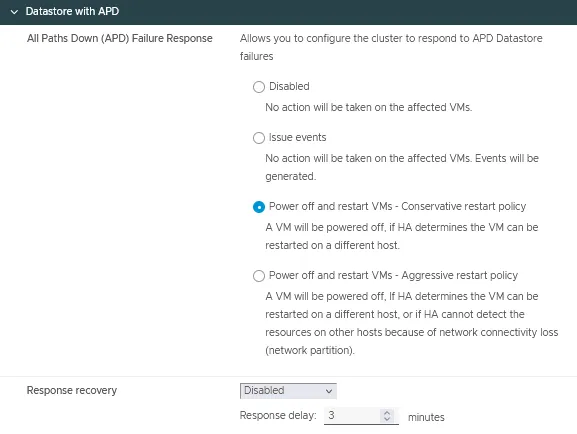
Datastore met APD
- Alle paden down (APD) Foutreactie is de voorwaarde die een cluster toestaat te reageren wanneer alle paden down zijn, en er is geen indicatie of dit tijdelijk of permanent apparaatverlies is.
Vier opties zijn beschikbaar voor deze instelling:- Uitgeschakeld
- Gebeurtenissen uitgeven
- VM’s uitschakelen en herstarten – Conservatief herstartbeleid
- VM’s uitschakelen en herstarten – Agressief herstartbeleid
- Reactieherstel heeft twee opties:
- Uitgeschakeld
- VM’s resetten
Je kunt de responstijd instellen in minuten.
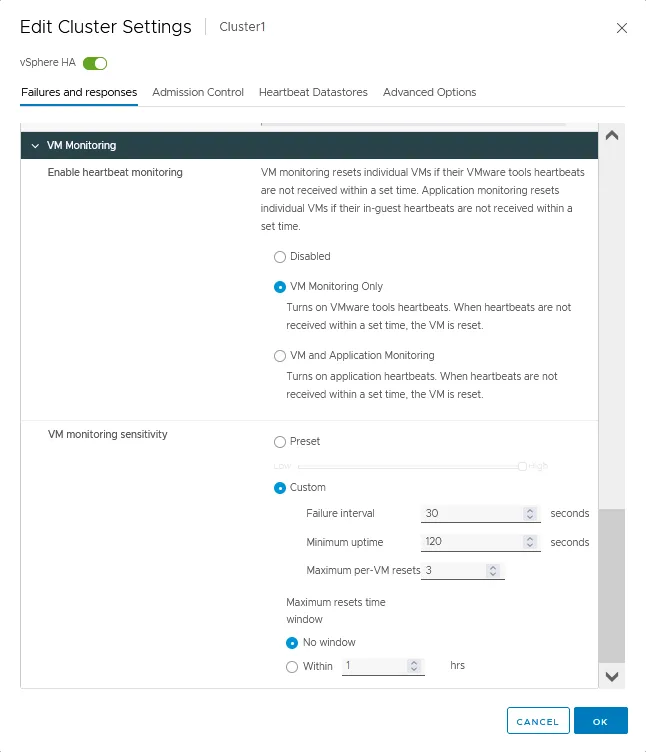
VM Monitoring
- Schakel hartslagmonitoring in voor virtuele machines door VMware Tools te gebruiken die op hen draaien. U kunt ook applicatiemonitoring configureren door gebruik te maken van deze mogelijkheden. Als VM-hartslagen niet op tijd worden ontvangen, wordt de VM-herstart geïnitieerd. Er zijn drie opties voor deze instelling in de VMware-clusterconfiguratie:
- Uitgeschakeld
- Alleen VM-monitoring
- VM- en applicatiemonitoring
- VM-monitoringsgevoeligheid wordt gebruikt om de tijd in te stellen waarop een VM als niet beschikbaar wordt geclassificeerd en een HA-cluster de VM-herstart kan initiëren.
- Vooraf ingesteld. U kunt de schakelaar van de lage naar de hoge waarde verplaatsen.
- Aangepast. Stel aangepaste gevoeligheidsparameters in, waaronder foutinterval, maximale uptime en maximale per-VM-herstarts. Het maximale aantal herstarts binnen een tijdvenster kan worden ingesteld op een aangepaste waarde in uren.
Opmerking: U kunt ook een VM-monitoringoplossing gebruiken om fouten en problemen te detecteren voor VM’s die niet in een cluster zitten.
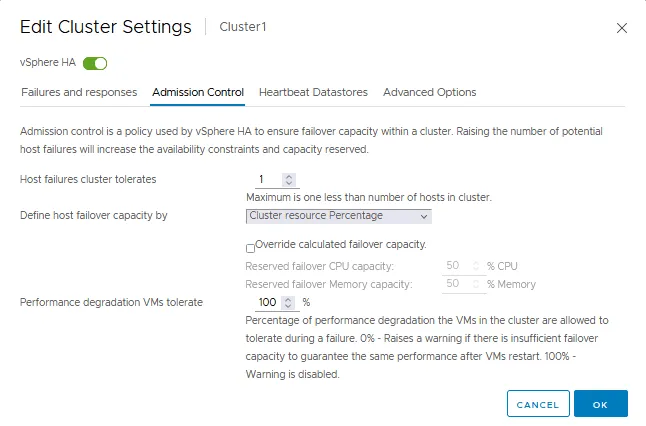
Het tabblad Toelatingscontrole
Toelatingscontrole is een beleid dat wordt gebruikt om ervoor te zorgen dat er voldoende middelen zijn gereserveerd voor het uitvoeren van virtuele machines in geval van een failover in een VMware HA-cluster. Toelatingscontrole-instellingen zorgen voor failover-capaciteit. Als een actie in strijd is met de toelatingscontrole-instellingen, is de actie niet toegestaan. Deze verboden acties kunnen het inschakelen van een VM, migreren van een VM en het verhogen van CPU- en geheugeninstellingen voor een VM omvatten.
- Toelatingscontrole bepaalt hoeveel fouten een HA-cluster kan verdragen en toch VM-failover mogelijk maken (een garantie voor failover van VM’s).
- U kunt de host failover-capaciteit definiëren door:
- Cluster resourcepercentage
- Toegewijde failover-hosts
- Slotbeleid
Als u toelatingscontrole uitschakelt, kunt u niet garanderen dat het verwachte aantal VM’s opnieuw zal worden gestart in een HA-cluster in geval van failover.
- Prestatievermindering die VM’s verdragen is de instelling die het percentage prestatievermindering definieert dat uw cluster kan verdragen. 0% betekent dat hetzelfde niveau van VM-prestaties gegarandeerd moet worden na VM-failover/herstart. Anders wordt er een waarschuwing weergegeven. 100% betekent dat de waarschuwing is uitgeschakeld en dat een cluster toch probeert een VM opnieuw op te starten.
Het Heartbeat-dataschijven-tabblad
Heartbeat-datastores bieden een secundaire manier om de beschikbaarheid van ESXi-hosts te controleren door datastores te gebruiken als de netwerkverbinding met ESXi-hosts niet beschikbaar is en een beheersnetwerk is mislukt. Deze aanpak stelt vSphere in staat om onderscheid te maken tussen hostfouten en onbeschikbaarheid van de host via het netwerk. Gebruik heartbeat-datastores in de VMware HA-configuratie om hosts te controleren wanneer een HA-netwerk is mislukt.
De selectiebeleid voor heartbeat-datastores heeft drie opties:
- Automatisch datastores selecteren die toegankelijk zijn vanaf de hosts
- Alleen datastores gebruiken uit de opgegeven lijst
- Datastores gebruiken uit de opgegeven lijst en automatisch aanvullen indien nodig

Het tabblad Geavanceerde opties
Het tabblad Geavanceerde opties stelt u in staat vSphere HA te configureren door handmatig een optie en waarde in te voeren in elke string. U kunt geavanceerde opties gebruiken wanneer u een HA-cluster niet kunt afstemmen in de standaardinstellingen die we eerder hebben uitgelegd, die beschikbaar zijn in de GUI van VMware vSphere Client.
Net als bij VMware Distributed Resource Scheduler (DRS), zodra we op OK klikken, wordt het VMware-cluster opnieuw geconfigureerd voor de HA-instellingen die hierboven zijn geconfigureerd.
VMware vSphere Proactieve HA
Proactieve HA is een functie die ervoor zorgt dat een cluster reageert op een probleem voordat er een storing optreedt bij alle ESXi-hosts en VM’s die op die host zijn geïnstalleerd. Problemen kunnen zich voordoen met verschillende componenten van een ESXi-server, en vSphere Proactieve HA kan de hardwarecondities van een server detecteren.
Bijvoorbeeld, Proactieve HA kan geïnformeerd worden dat er problemen zijn met een stroomvoorziening naar een ESXi-server. VMs blijven op deze server draaien, maar dit probleem kan snel leiden tot een serverstoring. Om een mogelijke VM-storing te voorkomen, kan vSphere Proactieve HA een VM-migratie naar andere ESXi-hosts van een cluster initiëren. Proactieve HA ondersteunt het reageren op problemen met betrekking tot stroomvoorziening, ventilator, opslag, geheugen en netwerk.
Je moet Distributed Resource Scheduler (DRS) in een vSphere-cluster inschakelen en configureren voordat je Proactieve HA kunt inschakelen. Je kunt vSphere HA en DRS samen voor een cluster configureren.
Conclusieve gedachten
De echte kracht, betrouwbaarheid en schaalbaarheid van het VMware vSphere ESXi-platform worden pas ontsloten zodra de vCenter Server is ingericht en de ESXi-hosts zijn toegevoegd aan een vSphere ESXi-cluster. Configureer vSphere HA en DRS om effectief bescherming te bieden tegen hoststoringen en om bronnen voor VMs te balanceren en in te schakelen. Zowel DRS als HA zijn sinds vSphere 6.5 nog krachtiger, aangezien VMware meer proactieve en intelligente bewaking en inzicht in beide clusterfuncties heeft toegevoegd, waardoor ze wendbaar en proactief kunnen zijn.
Vergeet niet om VMware VM-backups uit te voeren, zelfs als je VMs in het cluster draaien, om gegevensverlies te voorkomen.
Source:
https://www.nakivo.com/blog/vmware-cluster-ha-configuration/