













Quando si hanno macchine virtuali critiche e servizi critici in esecuzione su di esse, è necessario garantirne la disponibilità durante l’orario di funzionamento dell’organizzazione. Uno dei modi per garantire un’alta disponibilità è utilizzare un cluster per assicurare la continuità dei servizi e delle applicazioni in esecuzione.
La piattaforma di virtualizzazione VMware vSphere consente di utilizzare un cluster per eseguire macchine virtuali (VM) e utilizzare la funzionalità di alta disponibilità di vSphere (HA). Questo post del blog spiega la configurazione di VMware vSphere HA per familiarizzare con i parametri da configurare.
Cos’è HA in VMware vSphere?
VMware High Availability (HA) è una funzionalità che offre un’ottima disponibilità per le macchine virtuali vSphere, comprese le applicazioni e i servizi in esecuzione sulle VM, al fine di ridurre al minimo i tempi di inattività in caso di guasti. L’alta disponibilità (HA), o la capacità di un ambiente virtuale di resistere a guasti dell’host, è una delle ragioni importanti per cui si sceglie di implementare VMware vCenter e un cluster anziché un host VMware ESXi autonomo.
Quando HA è in esecuzione su un cluster VMware, un agente viene installato su ciascun host che partecipa al cluster. Ciascun agente host comunica con gli altri e monitora la raggiungibilità degli host nel cluster tramite heartbeat. Se trascorre un intervallo di 15 secondi senza la ricezione degli heartbeat da un host particolare e i ping all’host falliscono, l’host viene dichiarato come non riuscito. Le VM in esecuzione sulle risorse di calcolo/memoria di quell’host non riuscito vengono spostate su un host sano e riavviate su quell’host.
HA in vSphere può monitorare lo stato di salute dell’hardware dei tuoi host per spostare in modo proattivo le VM dagli host che presentano problemi hardware. Sono inoltre incorporati prioritari di riavvio e orchestrazione in HA e, di conseguenza, le VM designate vengono riportate online prima di altre in caso di failover. Queste funzionalità sono disponibili nelle versioni VMware vSphere 6.7 e vSphere 7.
Requisiti del cluster VMware
Vi sono alcuni requisiti VMware per creare un cluster VMware con HA abilitato. I requisiti includono:
- Gli host nel cluster HA devono essere licenziati per vSphere HA. Deve essere applicata la licenza VMware vSphere Standard o Enterprise Plus, comprese le licenze vCenter Standard.
- Sono necessari due host per abilitare HA. Sono consigliati tre o più host.
- Le IP statiche configurate su ogni host sono la pratica migliore.
- È necessario disporre di almeno una rete di gestione comune tra gli host.
- Affinché le VM possano essere eseguite su tutti gli host del cluster, questi ultimi devono avere le stesse reti e gli stessi datastore configurati.
- È richiesta una storage condivisa per l’HA.
- VMware Tools deve essere in esecuzione sulle VM monitorate dall’HA.
Procedura passo passo per la configurazione di VMware HA
È possibile abilitare VMware HA durante la creazione di un cluster o quando si ha già creato un cluster. In questa guida alla configurazione di vSphere HA, ci concentriamo sulla configurazione dell’Alta Disponibilità e partiamo da un cluster già creato. Utilizziamo VMware vSphere 7 per spiegare la configurazione di VMware HA passo dopo passo.
Come abilitare l’HA in VMware vSphere
Per abilitare l’HA in VMware vSphere in un cluster esistente, seguire questi passi:
- Aprire il client VMware vSphere nel browser web.
- Passare a Host e cluster e selezionare il cluster.
- Fare clic con il tasto destro sul nome del cluster nel riquadro Navigatore.
- Fare clic su Impostazioni nel menu contestuale.
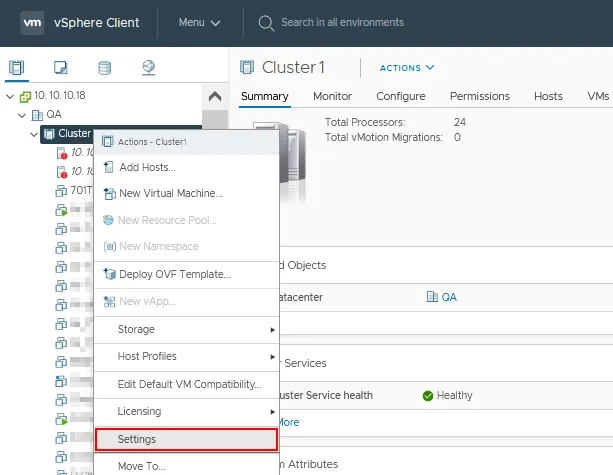
- Selezionare Disponibilità di vSphere nella sezione Servizi della pagina Configura per il tuo cluster.
- Fare clic su Modifica vicino a vSphere HA che è disattivato nel nostro caso.
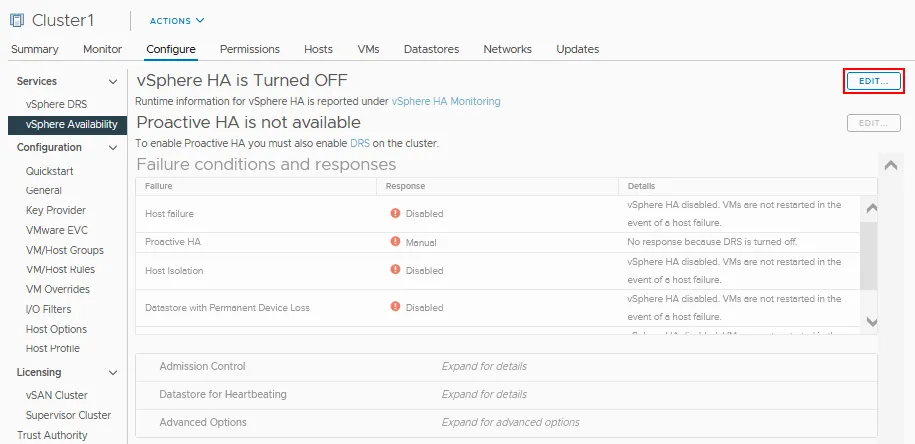
- Fare clic sul commutatore vSphere HA per abilitare l’Alta Disponibilità.
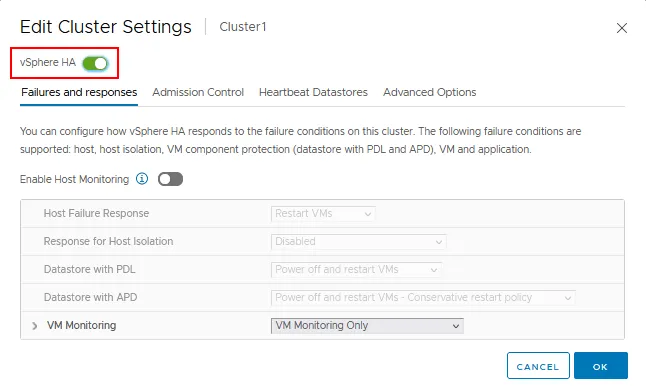
Ci sono quattro schede con impostazioni di vSphere HA:
- Guasti e risposte
- Controllo ammissioni
- Datastore di Heartbeat
- Opzioni avanzate
Diamo un’occhiata alla configurazione di vSphere HA che puoi fare modificando le impostazioni in queste schede.
La scheda Guasti e risposte
La scheda Guasti e risposte viene utilizzata per personalizzare il comportamento di un cluster HA e impostare cosa fare con le VM in diverse situazioni.
Abilita il Monitoraggio Host. Abilitare questa opzione per consentire agli host ESXi di scambiare heartbeat nel cluster. Un cluster VMware vSphere HA utilizza gli heartbeat per rilevare quando i componenti del cluster non sono disponibili. Disabilitare questa opzione durante la manutenzione della rete per evitare migrazioni VM indesiderate e failover.
Diamo un’occhiata a tutte le impostazioni nella scheda Guasti e risposte.
Risposta al Fallimento dell’Host
- Risposta di fallimento. Utilizzare queste impostazioni per impostare come risponde un cluster HA alle condizioni di errore del cluster. Sono disponibili due modalità:
- Disabilitata – Il monitoraggio dell’host ESXi è disattivato.
- Riavvia VM – Le VM vengono riavviate nell’ordine determinato in caso di errore dell’host.
- Priorità predefinita di riavvio VM. Questa impostazione viene utilizzata per determinare quale gruppo di VM deve essere riavviato per primo. Ci sono cinque valori: Più bassa, Bassa, Media, Alta e Massima. Le VM vengono riavviate in ordine di priorità, un gruppo alla volta.
- Condizione di riavvio dipendenza VM. Selezionare una condizione che, quando viene soddisfatta, un cluster rileva che le VM sono state riavviate con successo e può riavviare il prossimo gruppo di VM. Sono disponibili quattro condizioni:
- Risorse allocate
- Acceso
- Rilevati battiti del cuore degli ospiti
- Rilevati battiti del cuore dell’applicazione
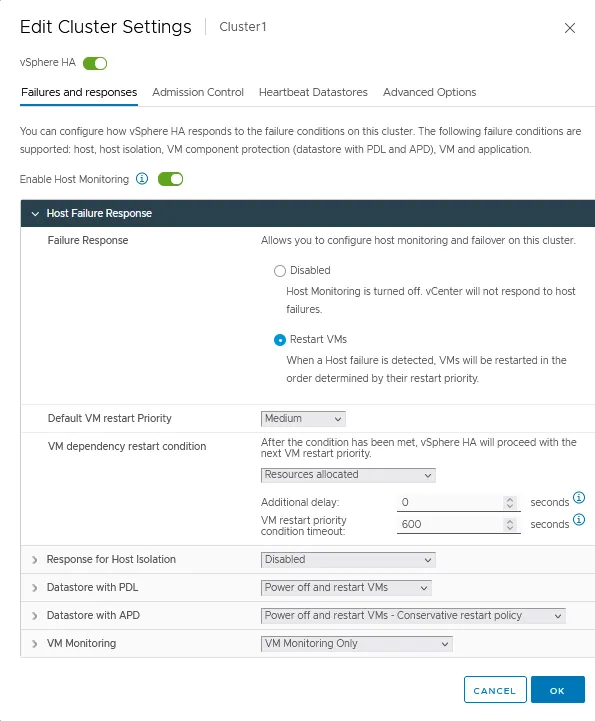
Risposta per isolamento dell’host
L’opzione Risposta all’isolamento dell’host consente di impostare il comportamento di un cluster HA quando un host ESXi continua a funzionare ma perde le connessioni di rete di gestione:
- Disabilitata
- Spegni e riavvia le VM
- Arresta e riavvia le VM

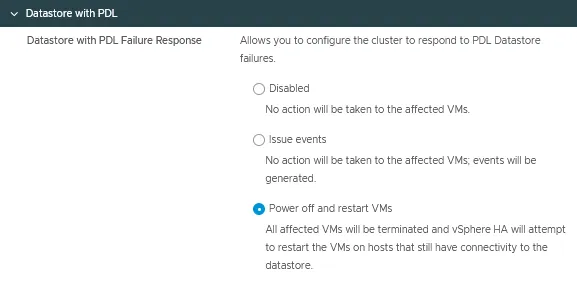
Datastore con PDL
La risposta al fallimento del Datastore con perdita permanente del dispositivo (PDL) può essere configurata per rilevare l’inaccessibilità del datastore da parte di un host ESXi e avviare un failover automatico delle VM interessate.
Ci sono tre modalità per questa opzione di configurazione vSphere HA:
- Disabilitato
- Genera eventi
- Spegni e riavvia le VM
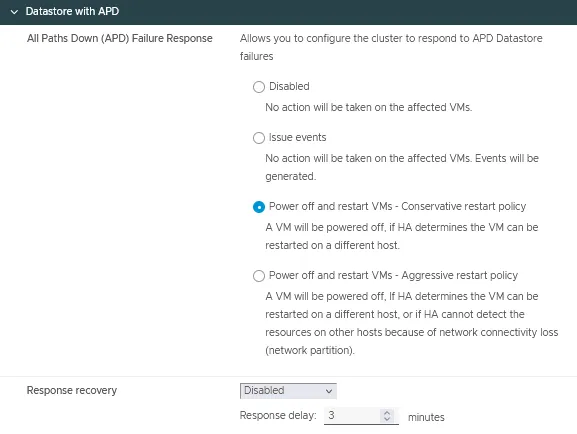
Datastore con APD
- La risposta al fallimento di All Paths Down (APD) è la condizione che consente a un cluster di rispondere quando tutti i percorsi sono inattivi e non c’è indicazione se si tratti di una perdita temporanea o permanente del dispositivo.
Ci sono quattro opzioni disponibili per questa impostazione:- Disabilitato
- Genera eventi
- Spegni e riavvia le VM – Politica di riavvio conservativa
- Spegni e riavvia le VM – Politica di riavvio aggressiva
- Recupero della risposta ha due opzioni:
- Disabilitato
- Reimposta le VM
Puoi impostare il ritardo della risposta in minuti.
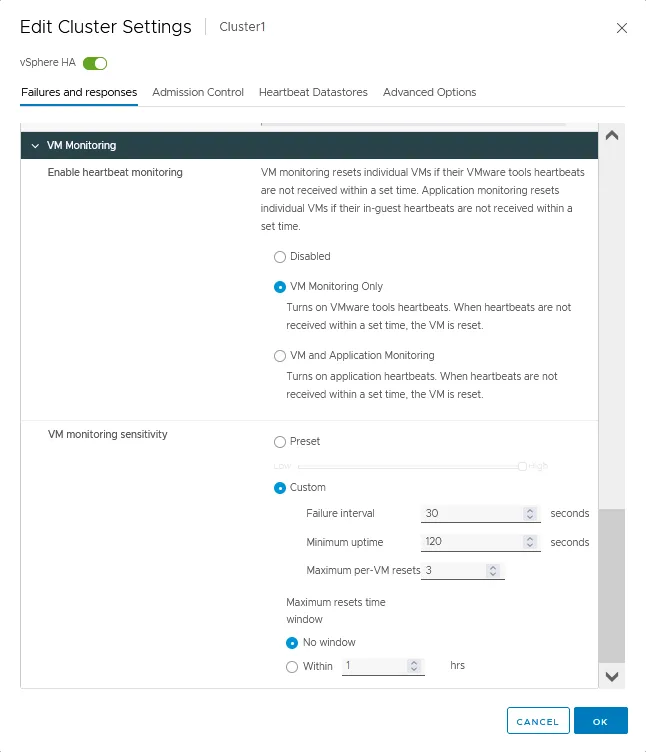
Monitoraggio delle VM
- Abilita il monitoraggio dei battiti cardiaci per le macchine virtuali utilizzando VMware Tools in esecuzione su di esse. È inoltre possibile configurare il monitoraggio delle applicazioni utilizzando queste funzionalità. Se i battiti cardiaci della VM non vengono ricevuti in tempo, viene avviato il riavvio della VM. Ci sono tre opzioni per questa impostazione nella configurazione del cluster VMware:
- Disabilitato
- Solo Monitoraggio VM
- Monitoraggio VM e Applicazioni
- Sensibilità del monitoraggio VM viene utilizzata per impostare il tempo dopo il quale una VM viene classificata come non disponibile e un cluster HA può avviare il riavvio della VM.
- Predefinito. Puoi spostare l’interruttore dal valore basso a quello alto.
- Personalizzato. Imposta parametri di sensibilità personalizzati, inclusi intervallo di errore, uptime massimo e reset massimi per VM. La finestra temporale massima per i reset può essere impostata su un valore personalizzato in ore.
Nota: È inoltre possibile utilizzare una soluzione di monitoraggio VM per rilevare guasti e problemi per le VM che non sono in un cluster.
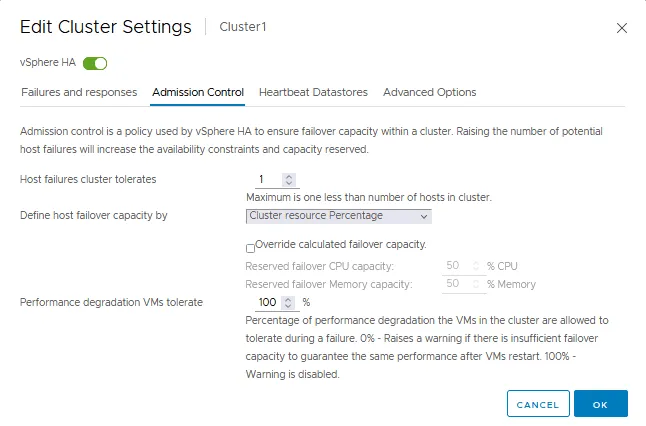
La scheda Controllo di ammissione
Il controllo di ammissione è una politica utilizzata per garantire che sufficienti risorse siano riservate per l’esecuzione di macchine virtuali in caso di failover in un cluster VMware HA. Le impostazioni di controllo di ammissione garantiscono la capacità di failover. Se un’azione viola le impostazioni di controllo di ammissione, l’azione non è consentita. Queste azioni non consentite possono essere l’accensione di una VM, la migrazione di una VM e l’aumento delle impostazioni di CPU e memoria per una VM.
- Il controllo di ammissione definisce quanti fallimenti un cluster HA può tollerare e ancora rendere possibile il failover delle VM (una garanzia di failover delle VM).
- È possibile definire la capacità di failover dell’host da:
- Percentuale delle risorse del cluster
- Host di failover dedicati
- Politica delle fessure
Se si disabilita il controllo di ammissione, non è possibile garantire che il numero previsto di VM verrà riavviato in un cluster HA in caso di failover.
- Degradazione delle prestazioni tollerata dalle VM è la configurazione che definisce la percentuale di degradazione delle prestazioni che il cluster può tollerare. Il 0% significa che deve essere garantito lo stesso livello di prestazioni delle VM dopo il failover/riavvio delle VM. In caso contrario, viene visualizzato un avviso. Il 100% significa che l’avviso è disabilitato e un cluster tenta comunque di riavviare una VM.
La scheda Heartbeat Datastores
I datastore dei battiti cardiaci forniscono un modo secondario per monitorare la disponibilità degli host ESXi utilizzando i datastore nel caso in cui la connessione di rete agli host ESXi non sia disponibile e una rete di gestione sia fallita. Questo approccio consente a vSphere di distinguere tra un guasto dell’host e l’indisponibilità dell’host tramite la rete. Utilizzare i datastore dei battiti cardiaci nella configurazione VMware HA per monitorare gli host quando una rete HA è fallita.
La policy di selezione del datastore dei battiti cardiaci ha tre opzioni:
- Selezionare automaticamente i datastore accessibili dagli host
- Utilizzare solo i datastore dall’elenco specificato
- Utilizzare i datastore dall’elenco specificato e integrare automaticamente se necessario

La scheda Opzioni Avanzate
La scheda Opzioni Avanzate consente di configurare vSphere HA inserendo manualmente un’opzione e un valore in ogni stringa. È possibile utilizzare le opzioni avanzate quando non è possibile ottimizzare un cluster HA nelle impostazioni standard che abbiamo spiegato in precedenza, disponibili nell’interfaccia grafica utente di VMware vSphere Client.
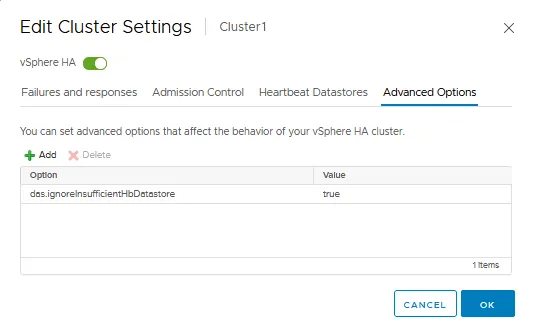
Come con VMware Distributed Resource Scheduler (DRS), una volta cliccato su OK, il cluster VMware viene riconfigurato per le impostazioni HA configurate in precedenza.
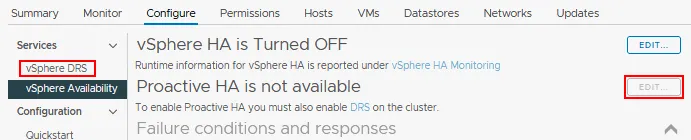
VMware vSphere Proactive HA
Il Proactive HA è una funzionalità che fa sì che un cluster reagisca a un problema prima che si verifichi un guasto di tutti gli host ESXi e delle VM residenti su quell’host. I problemi possono verificarsi con diversi componenti di un server ESXi e vSphere Proactive HA può rilevare le condizioni hardware di un server.
Ad esempio, Proactive HA può essere notificato che ci sono problemi con l’alimentazione di un server ESXi. Le VM continuano a funzionare su questo server, ma questo problema potrebbe portare presto a un guasto del server. Per evitare un possibile fallimento delle VM, vSphere Proactive HA può avviare la migrazione delle VM verso altri host ESXi di un cluster. Proactive HA supporta la reazione a problemi relativi all’alimentazione, alla ventola, allo storage, alla memoria e alla rete.
È necessario abilitare e configurare il Scheduler delle risorse distribuite (DRS) in un cluster vSphere prima di poter abilitare Proactive HA. È possibile configurare vSphere HA e DRS insieme per un cluster.
Pensieri conclusivi
La vera potenza, resilienza e scalabilità della piattaforma VMware vSphere ESXi vengono sbloccate una volta che il server vCenter è stato configurato e gli host ESXi sono stati aggiunti a un cluster vSphere ESXi. Configura vSphere HA e DRS per fornire in modo efficace protezione contro i guasti degli host e per bilanciare e pianificare le risorse per le VM. Sia DRS che HA sono ancora più potenti da vSphere 6.5 in poi, poiché VMware ha aggiunto un monitoraggio e una visione proattivi e intelligenti a entrambe queste funzionalità del cluster, consentendo loro di essere agili e proattivi.
Non dimenticare di eseguire il backup delle VM di VMware anche se le tue VM sono in esecuzione nel cluster per evitare la perdita di dati.
Source:
https://www.nakivo.com/blog/vmware-cluster-ha-configuration/