













Lorsque vous avez des machines virtuelles critiques et des services critiques qui s’y exécutent, leur disponibilité doit être assurée pendant les heures de fonctionnement de votre organisation. L’une des façons d’atteindre une haute disponibilité est d’utiliser un cluster pour garantir le fonctionnement continu des services et des applications.
La plateforme de virtualisation VMware vSphere vous permet d’utiliser un cluster pour exécuter des machines virtuelles (VM) et d’utiliser la Haute Disponibilité (HA) de vSphere. Cet article de blog explique la configuration de la Haute Disponibilité de VMware vSphere afin de vous familiariser avec les paramètres à configurer.
Qu’est-ce que la Haute Disponibilité dans VMware vSphere?
La Haute Disponibilité (HA) de VMware est une fonctionnalité offrant une disponibilité optimale pour les machines virtuelles vSphere, y compris les applications et les services s’exécutant sur les VM, afin de minimiser les temps d’arrêt en cas de défaillances. La Haute Disponibilité (HA), ou la capacité d’un environnement virtuel à résister aux défaillances de l’hôte, est l’une des raisons importantes pour lesquelles vous choisiriez de déployer VMware vCenter et un cluster plutôt qu’un hôte VMware ESXi autonome.
Lorsque HA est en cours d’exécution sur un cluster VMware, un agent est installé sur chaque hôte participant au cluster. Chaque agent d’hôte communique avec les autres et surveille la connectivité des hôtes du cluster via des signaux de bienvenue. Si un intervalle de 15 secondes s’écoule sans réception de signaux de bienvenue provenant d’un hôte particulier et que les pings vers l’hôte échouent également, l’hôte est déclaré comme ayant échoué. Les VMs en cours d’exécution sur les ressources de calcul/mémoire de cet hôte en échec sont redémarrées sur un hôte sain.
HA dans vSphere peut surveiller la santé du matériel de vos hôtes pour déplacer proactivement les VMs hors des hôtes présentant des problèmes de matériel. Il existe également des priorités de redémarrage et une orchestration intégrées à HA et, par conséquent, des VMs désignées sont mises en ligne avant les autres en cas de basculement. Ces fonctionnalités sont disponibles dans les versions VMware vSphere 6.7 et vSphere 7.
Exigences du cluster VMware
Il existe quelques exigences de VMware pour créer un cluster VMware avec HA activé. Les exigences incluent:
- Les hôtes du cluster HA doivent être licenciés pour vSphere HA. VMware vSphere Standard ou Enterprise Plus, y compris les licences vCenter Standard, doivent être appliquées.
- Deux hôtes sont requis pour activer HA. Trois hôtes ou plus sont recommandés.
- Les adresses IP statiques configurées sur chaque hôte sont la meilleure pratique.
- Vous avez besoin d’au moins un réseau de gestion commun à travers les hôtes.
- Pour que les machines virtuelles puissent fonctionner sur tous les hôtes en cas de déplacement vers différents hôtes du cluster, les hôtes doivent avoir les mêmes réseaux et datastores configurés.
- Un stockage partagé est nécessaire pour la haute disponibilité.
- VMware Tools doivent fonctionner sur les machines virtuelles surveillées en haute disponibilité.
Configuration étape par étape de VMware HA
Vous pouvez activer VMware HA lorsque vous créez un cluster ou lorsque vous avez déjà créé un cluster. Dans cette démonstration de configuration de vSphere HA, nous nous concentrons sur la configuration de la haute disponibilité et nous avons déjà créé un cluster. Nous utilisons VMware vSphere 7 pour expliquer la configuration de VMware HA étape par étape.
Comment activer HA dans VMware vSphere
Pour activer HA dans VMware vSphere dans un cluster existant, faites ce qui suit :
- Ouvrez VMware vSphere Client dans votre navigateur web.
- Allez dans Hôtes et clusters et accédez à votre cluster.
- Cliquez avec le bouton droit sur le nom du cluster dans le volet Navigateur.
- Cliquez sur Paramètres dans le menu contextuel.
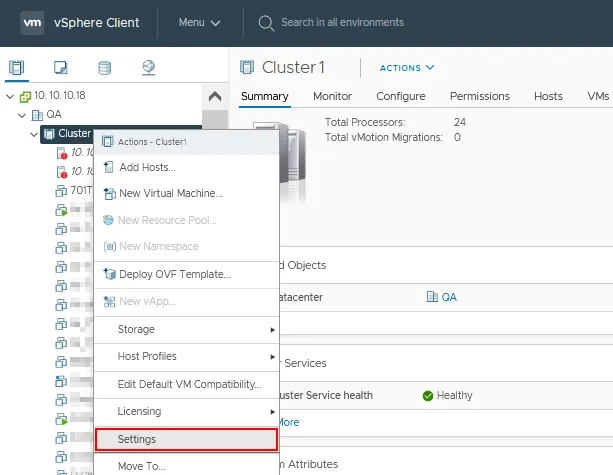
- Sélectionnez Disponibilité vSphere dans la section Services de la page Configurer pour votre cluster.
- Cliquez sur Modifier près de vSphere HA qui est désactivé dans notre cas.
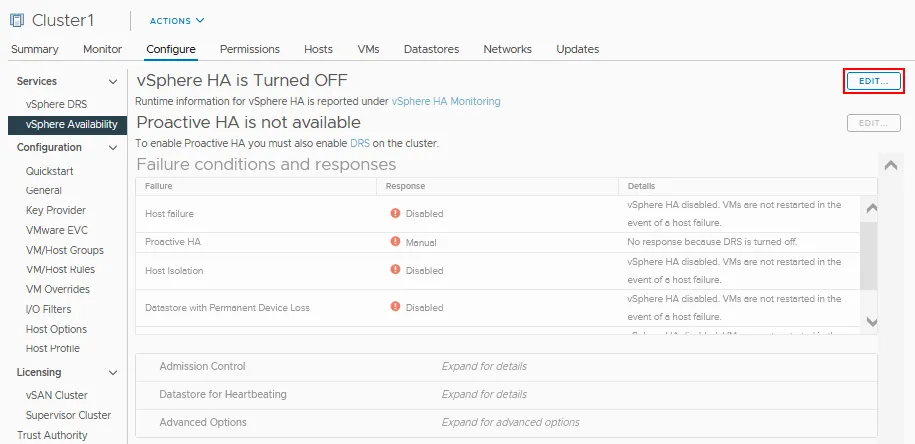
- Cliquez sur l’interrupteur vSphere HA pour activer la haute disponibilité.
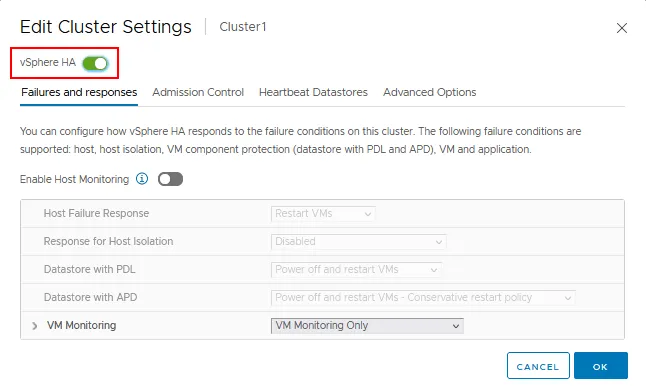
Il y a quatre onglets avec des paramètres vSphere HA :
- Failures and responses
- Admission Control
- Heartbeat Datastores
- Options avancées
Examinons la configuration vSphere HA que vous pouvez faire en modifiant les paramètres dans ces onglets.
L’onglet Failures and responses
L’onglet Failures and responses est utilisé pour personnaliser le comportement d’un cluster HA et définir quoi faire avec les VM dans différentes situations.
Activer la surveillance de l’hôte. Activez cette option pour permettre aux hôtes ESXi d’échanger des signaux vitaux dans le cluster. Un cluster VMware vSphere HA utilise les signaux vitaux pour détecter quand des composants du cluster ne sont pas disponibles. Désactivez cette option lors de la maintenance du réseau pour éviter les migrations non souhaitées des VM et les basculements.
Passons en revue tous les paramètres dans l’onglet Failures and responses.
Réponse en cas de défaillance de l’hôte
- Réponse en cas d’échec. Utilisez ces paramètres pour définir comment un cluster de haute disponibilité réagit aux conditions d’échec sur ce cluster. Deux modes sont disponibles:
- Désactivé – La surveillance de l’hôte ESXi est désactivée.
- Redémarrer les VM – Les VM sont redémarrées dans l’ordre déterminé en cas d’échec de l’hôte.
- Priorité de redémarrage des VM par défaut. Ce paramètre est utilisé pour déterminer quel groupe de VM doit être redémarré en premier. Il existe cinq valeurs: La plus basse, Basse, Moyenne, Haute et La plus haute. Les VM sont redémarrées par ordre de priorité, un groupe à la fois.
- Condition de redémarrage des dépendances des VM. Sélectionnez une condition qui, lorsqu’elle est remplie, permet à un cluster de détecter que les VM ont été redémarrées avec succès, et que le prochain lot de VM peut être redémarré. Quatre conditions sont disponibles:
- Ressources allouées
- Allumées
- Signaux de battement de cœur de l’invité détectés
- Signaux de battement de cœur de l’application détectés
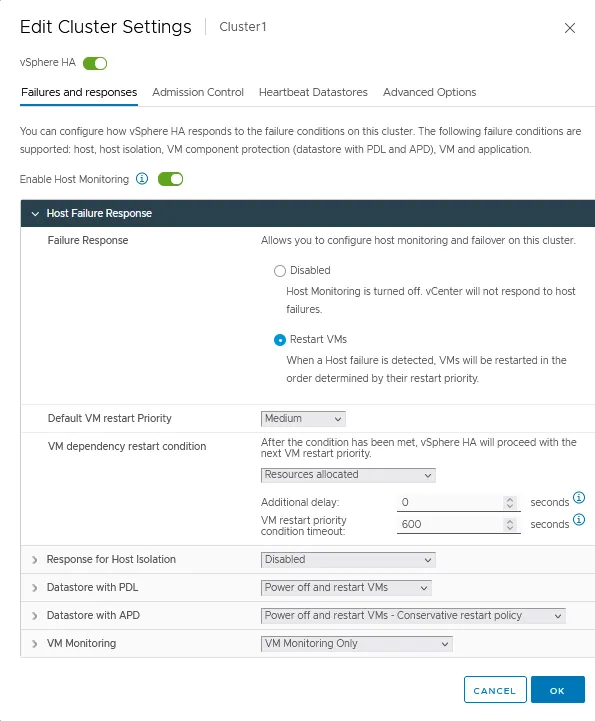
Réponse en cas d’isolement de l’hôte
L’option de réponse en cas d’isolement de l’hôte vous permet de définir le comportement d’un cluster de haute disponibilité lorsqu’un hôte ESXi continue de fonctionner mais perd les connexions au réseau de gestion:
- Désactivé
- Éteindre et redémarrer les VM
- Arrêter et redémarrer les machines virtuelles

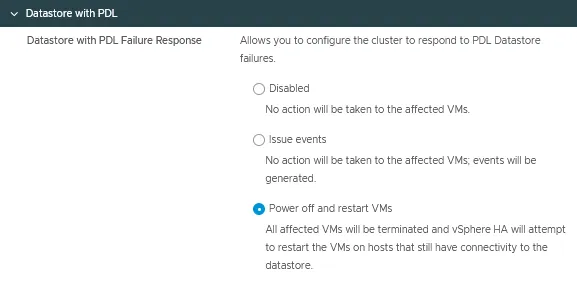
Magasin de données avec PDL
La réponse à l’échec du dispositif permanent (PDL) peut être configurée pour détecter l’inaccessibilité du magasin de données par un hôte ESXi et initier une bascule automatisée des machines virtuelles affectées.
Il existe trois modes pour cette option de configuration vSphere HA :
- Désactivé
- Émettre des événements
- Éteindre et redémarrer les machines virtuelles
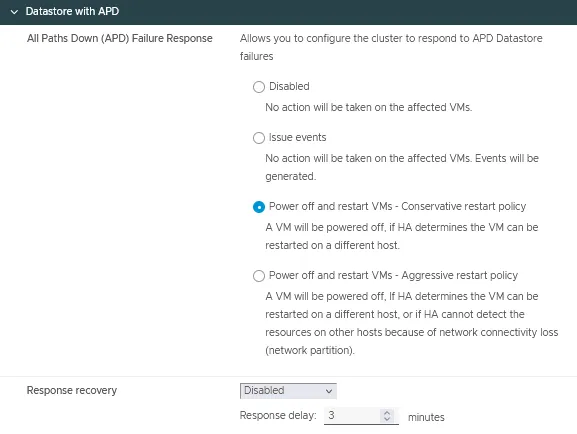
Magasin de données avec APD
- La réponse à l’échec de Tous les Chemins (APD) est la condition qui permet à un cluster de répondre lorsque tous les chemins sont indisponibles, sans indication s’il s’agit d’une perte temporaire ou permanente de dispositif.
Quatre options sont disponibles pour ce paramètre :- Désactivé
- Émettre des événements
- Éteindre et redémarrer les machines virtuelles – Politique de redémarrage conservatrice
- Éteindre et redémarrer les machines virtuelles – Politique de redémarrage agressive
- Reprise de la réponse propose deux options :
- Désactivé
- Réinitialiser les machines virtuelles
Vous pouvez définir le délai de réponse en minutes.
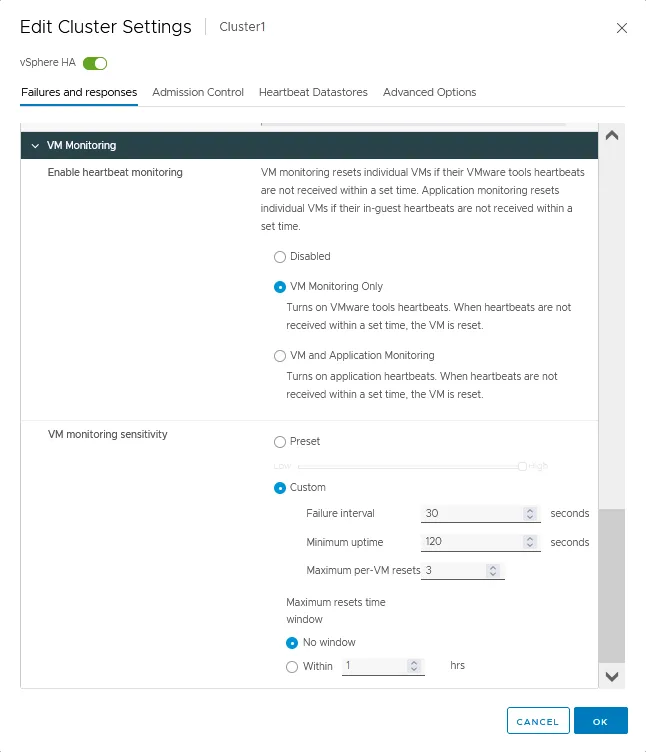
Supervision des machines virtuelles
- Activer la surveillance du pouls pour les machines virtuelles en utilisant VMware Tools s’exécutant sur celles-ci. Vous pouvez également configurer la surveillance des applications en utilisant ces fonctionnalités. Si les battements de cœur des machines virtuelles ne sont pas reçus à temps, le redémarrage de la machine virtuelle est initié. Il existe trois options pour ce paramètre dans la configuration de cluster VMware:
- Désactivé
- Surveillance de la machine virtuelle uniquement
- Surveillance de la machine virtuelle et des applications
- La sensibilité de surveillance de la machine virtuelle est utilisée pour définir le délai après lequel une machine virtuelle est classée comme non disponible et un cluster HA peut initier le redémarrage de la machine virtuelle.
- Prédéfini. Vous pouvez déplacer le commutateur de la valeur basse à la valeur haute.
- Personnalisé. Définissez des paramètres de sensibilité personnalisés, y compris l’intervalle d’échec, le temps de bon fonctionnement maximal et le nombre maximal de réinitialisations par machine virtuelle. La fenêtre temporelle maximale de réinitialisation peut être définie sur une valeur personnalisée en heures.
Remarque: Vous pouvez également utiliser une solution de surveillance de machine virtuelle pour détecter les pannes et les problèmes des machines virtuelles qui ne sont pas dans un cluster.
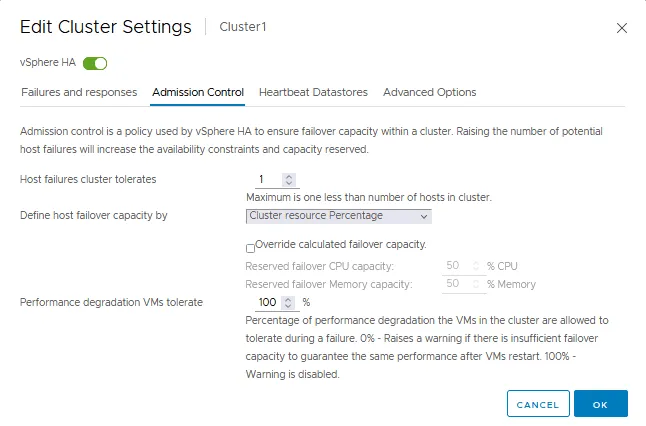
L’onglet Contrôle d’admission
Le contrôle d’admission est une politique utilisée pour s’assurer qu’il y a suffisamment de ressources réservées pour faire fonctionner des machines virtuelles en cas de basculement dans un cluster VMware HA. Les paramètres de contrôle d’admission garantissent la capacité de basculement. Si une action enfreint les paramètres de contrôle d’admission, l’action n’est pas autorisée. Ces actions non autorisées peuvent être le démarrage d’une VM, le déplacement d’une VM et l’augmentation des paramètres de CPU et de mémoire pour une VM.
- Le contrôle d’admission définit le nombre de défaillances qu’un cluster HA peut tolérer et permet encore un basculement des VM (une garantie de basculement des VMs).
- Vous pouvez définir la capacité de basculement des hôtes en:
- Pourcentage de ressources du cluster
- Hôtes de basculement dédiés
- Politique des slots
Si vous désactivez le contrôle d’admission, vous ne pouvez pas garantir que le nombre attendu de VMs sera redémarré dans un cluster HA en cas de basculement.
- La dégradation des performances tolérée par les VMs est le paramètre qui définit le pourcentage de dégradation des performances que votre cluster peut tolérer. 0% signifie que le même niveau de performance des VMs doit être garanti après le basculement/redémarrage des VMs. Sinon, un avertissement est affiché. 100% signifie que l’avertissement est désactivé et qu’un cluster essaie de redémarrer une VM de toute façon.
L’onglet Heartbeat Datastores
Les datastores de battement cardiaque fournissent un moyen secondaire de surveiller la disponibilité des hôtes ESXi en utilisant les datastores si la connexion réseau aux hôtes ESXi est inaccessible et qu’un réseau de gestion a échoué. Cette approche permet à vSphere de distinguer entre une défaillance de l’hôte et l’indisponibilité de l’hôte via le réseau. Utilisez les datastores de battement cardiaque dans la configuration VMware HA pour surveiller les hôtes lorsqu’un réseau HA a échoué.
La politique de sélection des datastores de battement cardiaque comporte trois options :
- Sélectionner automatiquement les datastores accessibles depuis les hôtes
- Utiliser uniquement les datastores de la liste spécifiée
- Utiliser les datastores de la liste spécifiée et compléter automatiquement si nécessaire

L’onglet Options avancées
L’onglet Options avancées vous permet de configurer vSphere HA en entrant manuellement une option et une valeur dans chaque chaîne. Vous pouvez utiliser des options avancées lorsque vous ne pouvez pas ajuster un cluster HA dans les paramètres standard que nous avons expliqués précédemment, disponibles dans l’interface graphique du client VMware vSphere.
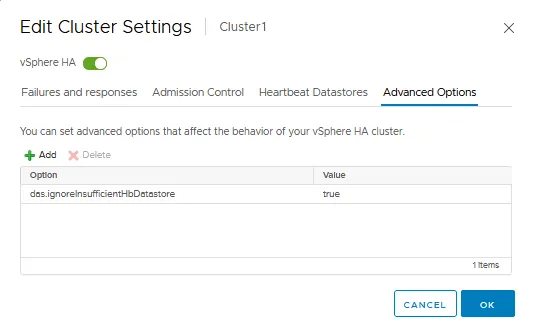
Tout comme avec VMware Distributed Resource Scheduler (DRS), une fois que nous cliquons sur OK, le cluster VMware est reconfiguré pour les paramètres HA qui ont été configurés ci-dessus.
VMware vSphere Proactive HA
Proactive HA est une fonctionnalité qui permet à un cluster de réagir à un problème avant qu’une défaillance de tous les hôtes ESXi et des VM résidant sur cet hôte ne se produise. Des problèmes peuvent survenir avec différents composants d’un serveur ESXi, et vSphere Proactive HA peut détecter les conditions matérielles d’un serveur.
Par exemple, Proactive HA peut être informé qu’il y a des problèmes d’alimentation sur un serveur ESXi. Les machines virtuelles continuent de fonctionner sur ce serveur, mais ce problème peut entraîner une défaillance du serveur prochainement. Pour éviter une éventuelle défaillance de la machine virtuelle, vSphere Proactive HA peut initier la migration de la machine virtuelle vers d’autres hôtes ESXi d’un cluster. Proactive HA prend en charge la réaction aux problèmes liés à l’alimentation, au ventilateur, au stockage, à la mémoire et au réseau.
Vous devez activer et configurer le répartiteur de ressources distribuées (DRS) dans un cluster vSphere avant de pouvoir activer Proactive HA. Vous pouvez configurer vSphere HA et DRS ensemble pour un cluster.
Pensées conclusives
La véritable puissance, la fiabilité et la scalabilité de la plate-forme VMware vSphere ESXi sont débloquées une fois que le serveur vCenter est provisionné et que les hôtes ESXi sont ajoutés à un cluster vSphere ESXi. Configurez vSphere HA et DRS pour assurer efficacement la protection contre les défaillances d’hôte ainsi que l’équilibrage et la planification des ressources pour les machines virtuelles. DRS et HA sont encore plus puissants depuis vSphere 6.5 car VMware a ajouté une surveillance proactive et intelligente et une vision plus approfondie à ces deux fonctionnalités de cluster, ce qui leur permet d’être agiles et proactifs.
N’oubliez pas de effectuer une sauvegarde des machines virtuelles VMware même si vos machines virtuelles s’exécutent dans le cluster pour éviter toute perte de données.
Source:
https://www.nakivo.com/blog/vmware-cluster-ha-configuration/