













Instellen van AWS CLI en AWS S3
Voordat je aan de slag gaat met het aws s3 cp commando, moet je AWS CLI geïnstalleerd en correct geconfigureerd hebben op je systeem. Maak je geen zorgen als je nog nooit met AWS hebt gewerkt – het installatieproces is eenvoudig en zou minder dan 10 minuten moeten duren.
Ik zal dit opsplitsen in drie eenvoudige fasen: het installeren van de AWS CLI-tool, het configureren van je referenties en het aanmaken van je eerste S3-bucket voor opslag.
Het installeren van de AWS CLI
Het installatieproces verschilt enigszins afhankelijk van het besturingssysteem dat je gebruikt.
Voor Windows-systemen:
- Ga naar de officiële AWS CLI documentatiepagina
- Pak de 64-bits Windows-installatieprogramma
- Start het gedownloade bestand en volg de installatiewizard
Voor Linux-systemen:
Voer de volgende drie commando’s uit via de Terminal:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Voor macOS-systemen:
Als je Homebrew geïnstalleerd hebt, voer dan deze ene regel uit in de Terminal:
brew install awscli
Als je geen Homebrew hebt, gebruik dan in plaats daarvan deze twee commando’s:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Om te bevestigen dat de installatie succesvol is, voer aws --version uit in je terminal. Je zou iets als dit moeten zien:
Afbeelding 1 – AWS CLI-versie
Het configureren van de AWS CLI
Met de CLI geïnstalleerd is het tijd om je AWS referenties in te stellen voor authenticatie.
Allereerst, ga naar je AWS-account en navigeer naar het dashboard van de IAM-service. Maak een nieuwe gebruiker met programmatische toegang en koppel het juiste S3-toestemmingsbeleid:
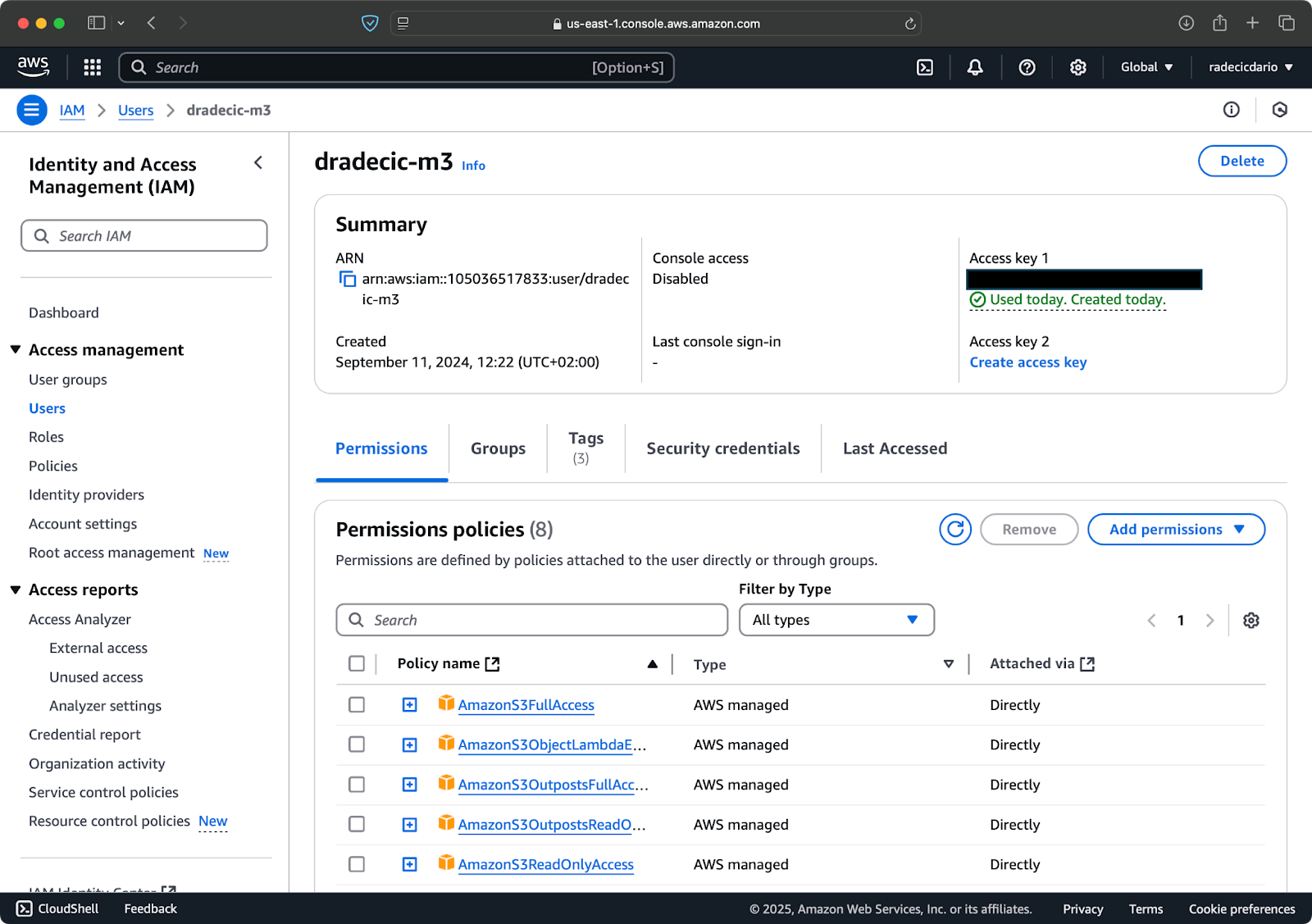
Afbeelding 2 – AWS IAM-gebruiker
Vervolgens, ga naar het tabblad “Beveiligingsreferenties” en genereer een nieuw toegangssleutelpaar. Zorg ervoor dat je zowel de Toegangssleutel-ID als de Geheime toegangssleutel op een veilige plaats opslaat – Amazon zal je de geheime sleutel niet opnieuw tonen na dit scherm:
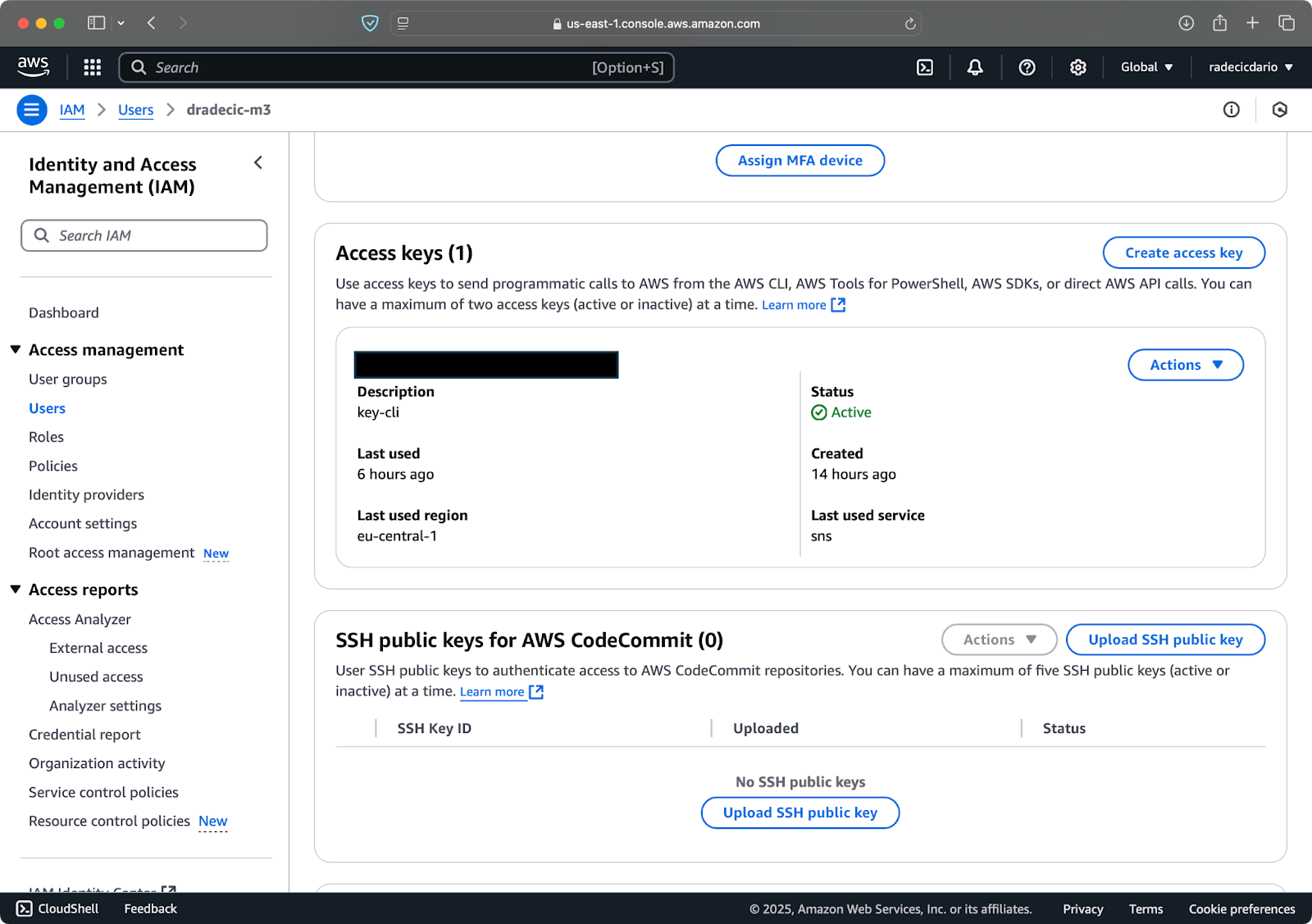
Afbeelding 3 – AWS IAM-gebruikersreferenties
Open nu je terminal en voer het aws configure commando uit. Je wordt gevraagd om vier gegevens: je Access key ID, Secret access key, standaard regio (ik gebruik eu-central-1) en de voorkeur voor uitvoerformaat (typisch json):
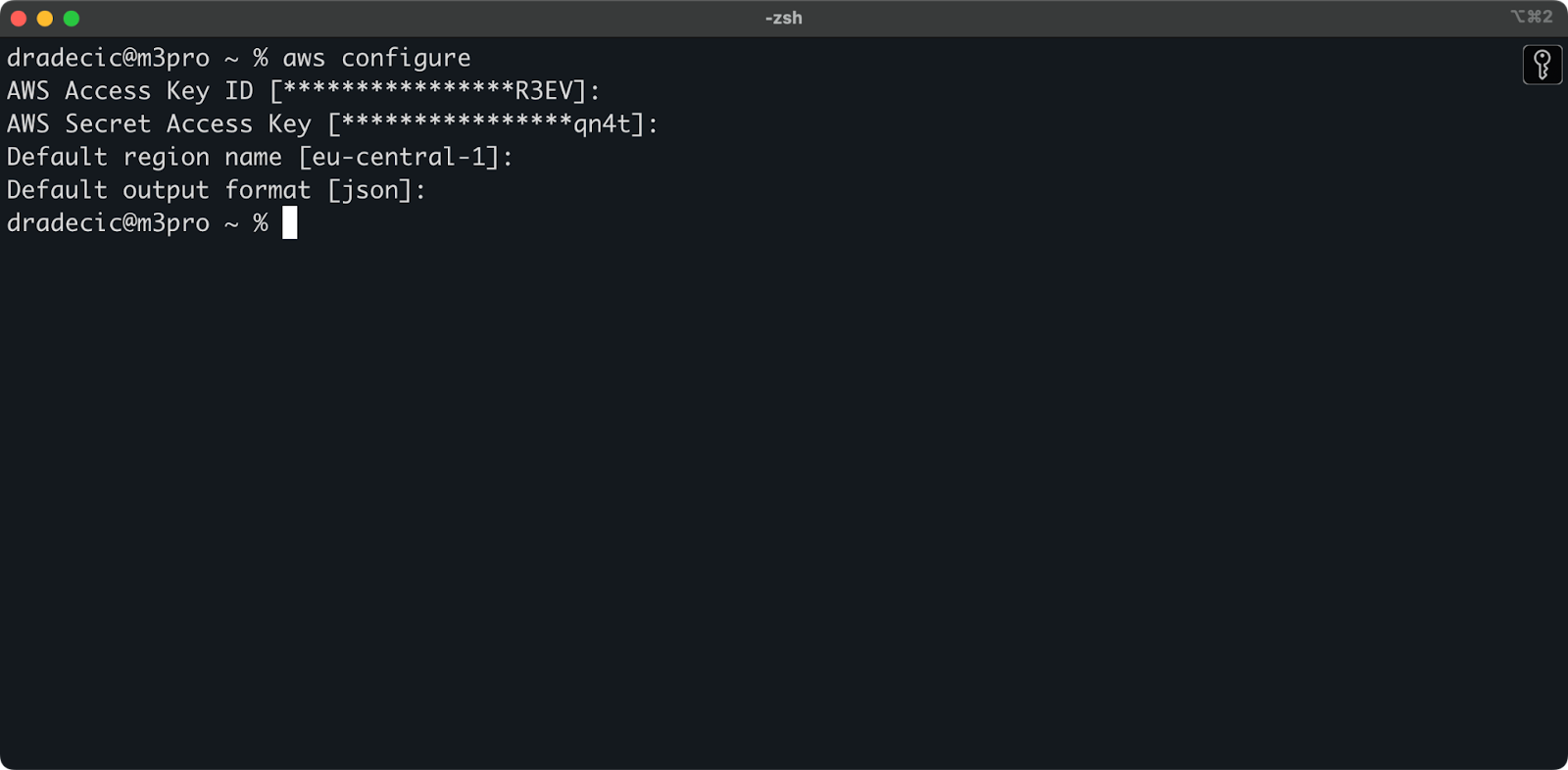
Afbeelding 4 – AWS CLI configuratie
Om te bevestigen dat alles goed is verbonden, verifieer je je identiteit met het volgende commando:
aws sts get-caller-identity
Als het correct is geconfigureerd, zie je je accountgegevens:
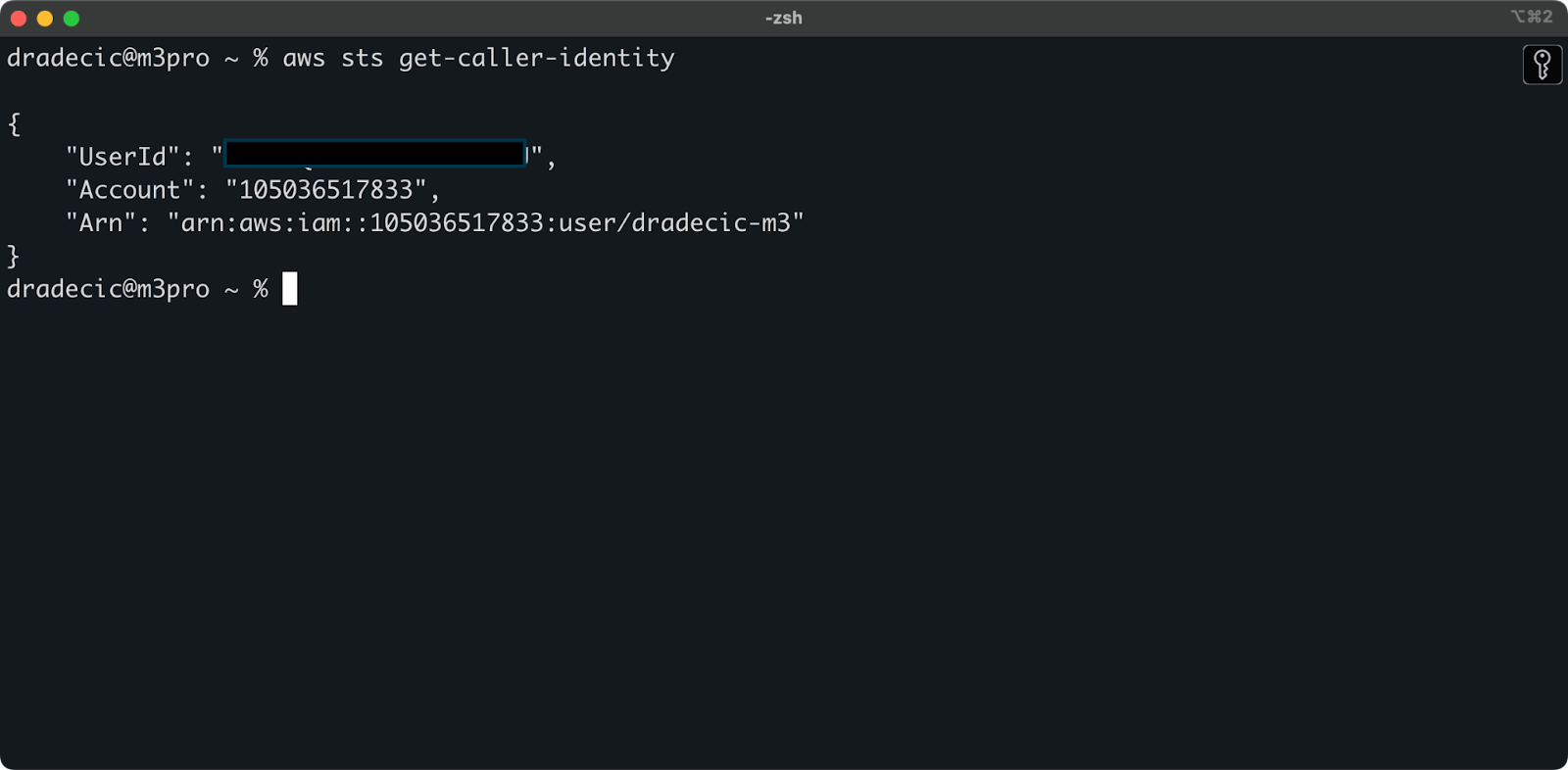
Afbeelding 5 – AWS CLI testverbinding commando
Een S3-bucket aanmaken
Eindelijk moet je een S3-bucket aanmaken om de bestanden op te slaan die je gaat kopiëren.
Ga naar het S3-diensten gedeelte in je AWS Console en klik op “Bucket aanmaken”. Vergeet niet dat bucket-namen wereldwijd uniek moeten zijn in AWS. Kies een onderscheidende naam, laat de standaardinstellingen voorlopig staan en klik op “Aanmaken”:
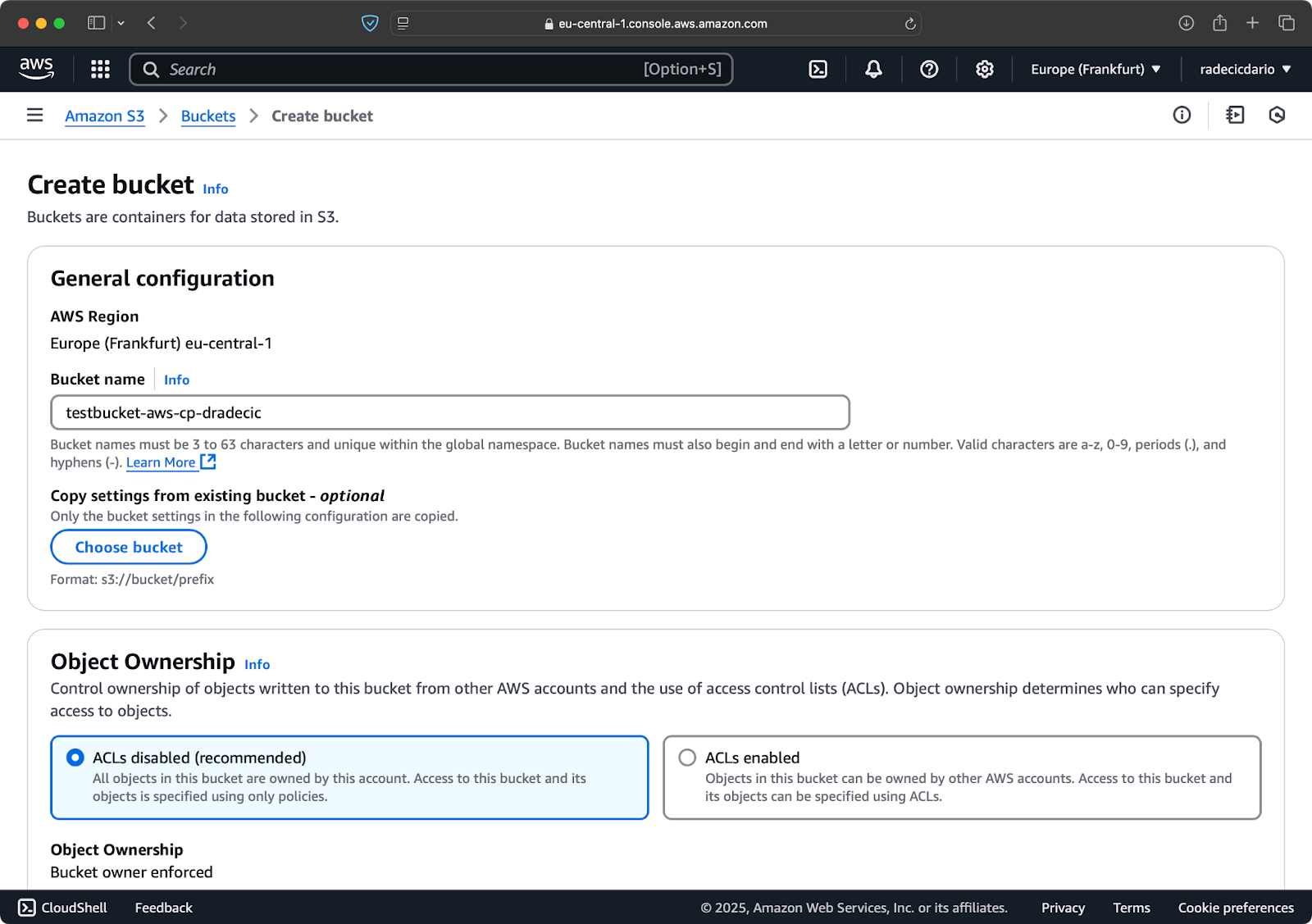
Afbeelding 6 – AWS bucket aanmaken
Eenmaal aangemaakt, verschijnt je nieuwe bucket in de console. Je kunt ook de aanwezigheid ervan bevestigen via de opdrachtregel:
aws s3 ls
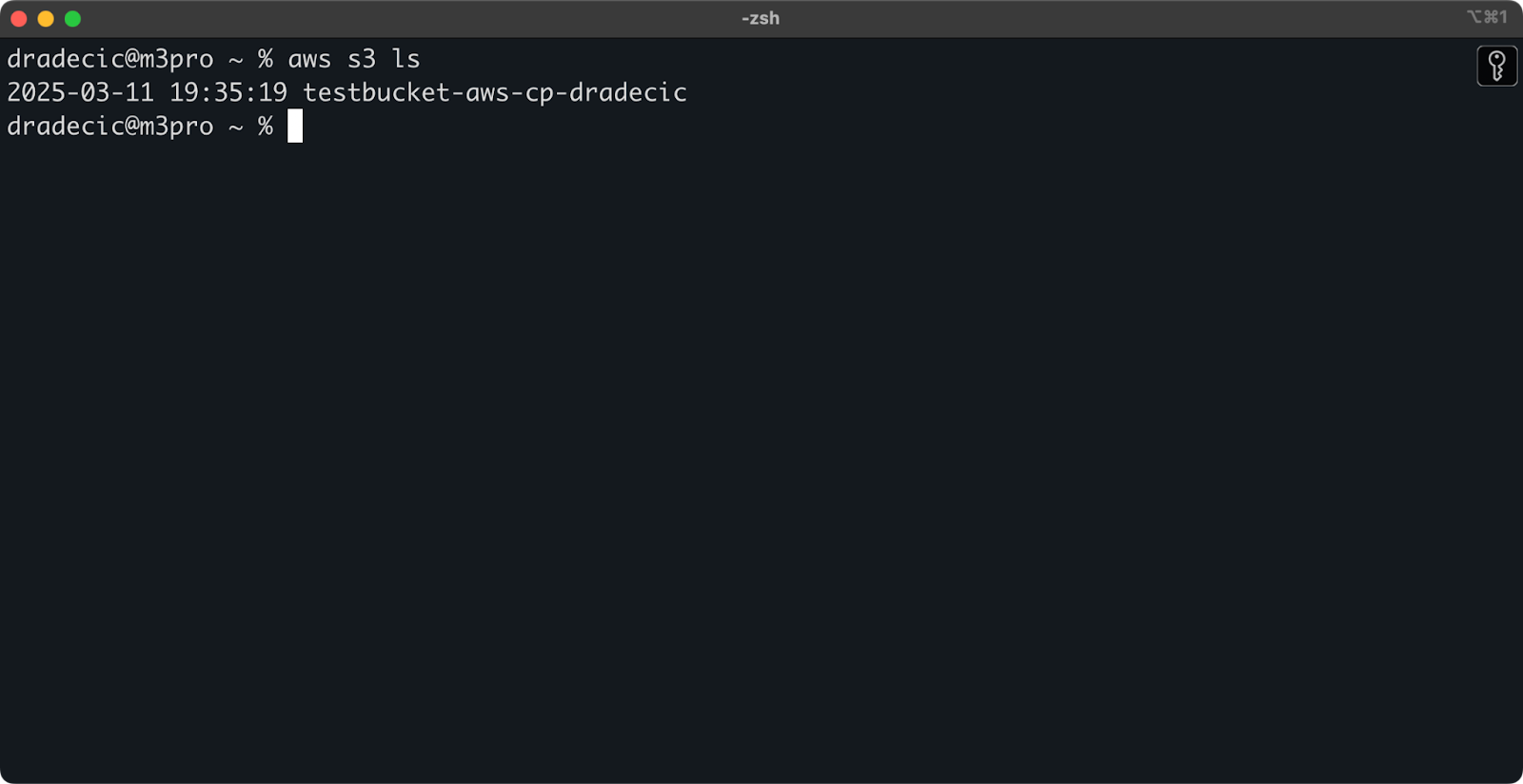
Afbeelding 7 – Alle beschikbare S3-buckets
Alle S3-buckets zijn standaard privé geconfigureerd, dus houd hier rekening mee. Als je deze bucket wilt gebruiken voor openbaar toegankelijke bestanden, moet je de bucketbeleid dienovereenkomstig aanpassen.
Je bent nu volledig uitgerust om het aws s3 cp commando te gebruiken om bestanden over te dragen. Laten we nu beginnen met de basis.
Basis AWS S3 cp Commando Syntax
Nu je alles hebt geconfigureerd, laten we duiken in het basisgebruik van de aws s3 cp opdracht. Zoals gebruikelijk bij AWS ligt de schoonheid in de eenvoud, ook al kan de opdracht verschillende bestandsoverdrachtscenario’s aan.
In zijn meest basale vorm volgt de aws s3 cp opdracht deze syntaxis:
aws s3 cp <source> <destination> [options]
Waarbij <bron> en <bestemming> lokale bestandspaden of S3 URI’s kunnen zijn (die beginnen met s3://). Laten we de drie meest voorkomende gebruiksgevallen verkennen.
Een bestand kopiëren van lokaal naar S3
Om een bestand van je lokale systeem naar een S3-bucket te kopiëren, zal de bron een lokaal pad zijn en de bestemming een S3 URI:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
Deze opdracht uploadt het bestand test_file.txt van de opgegeven directory naar de opgegeven S3-bucket. Als de operatie succesvol is, zie je console-uitvoer zoals deze:
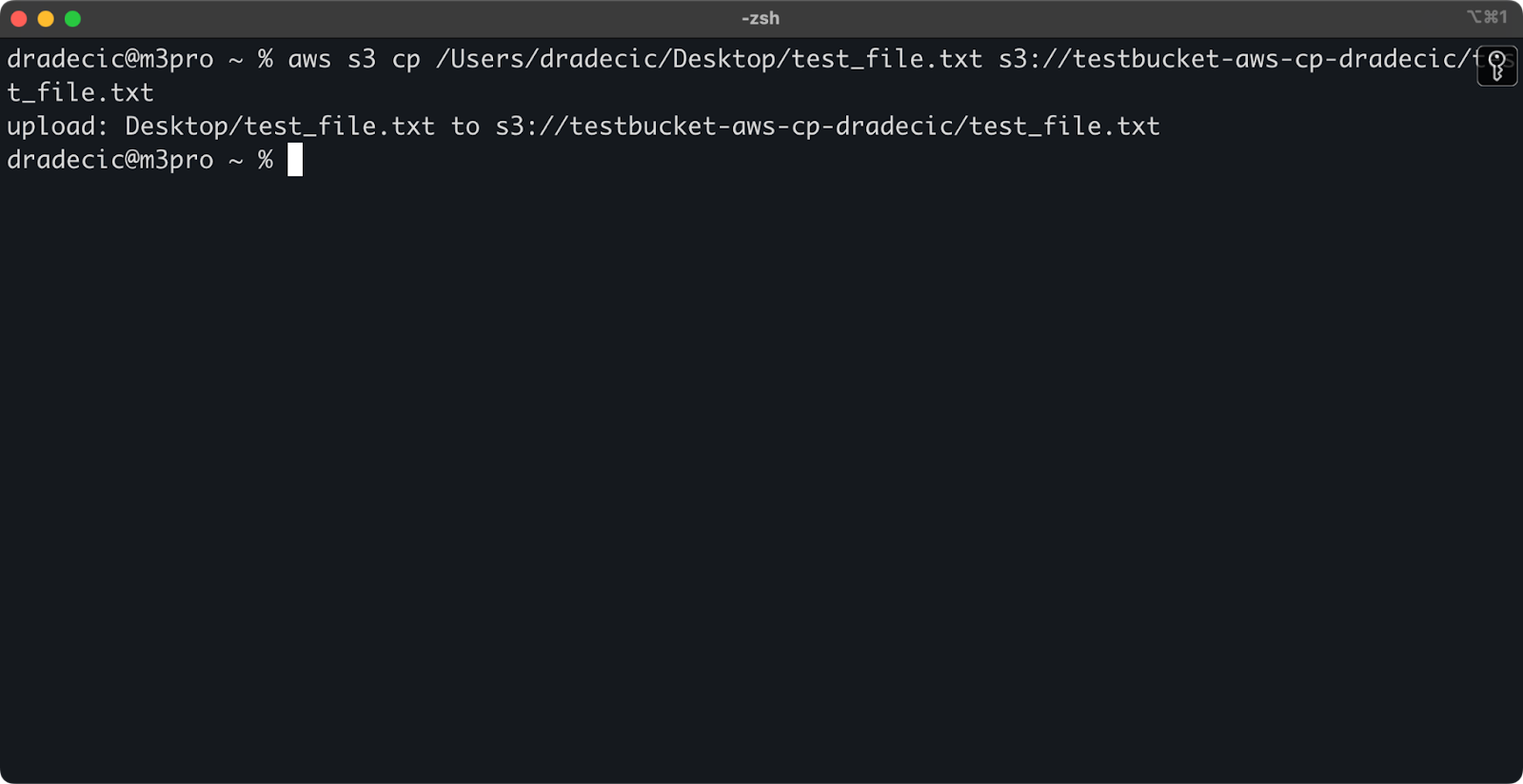
Afbeelding 8 – Console-uitvoer na het kopiëren van het lokale bestand
En, op de AWS-beheerconsole, zie je je bestand geüpload:
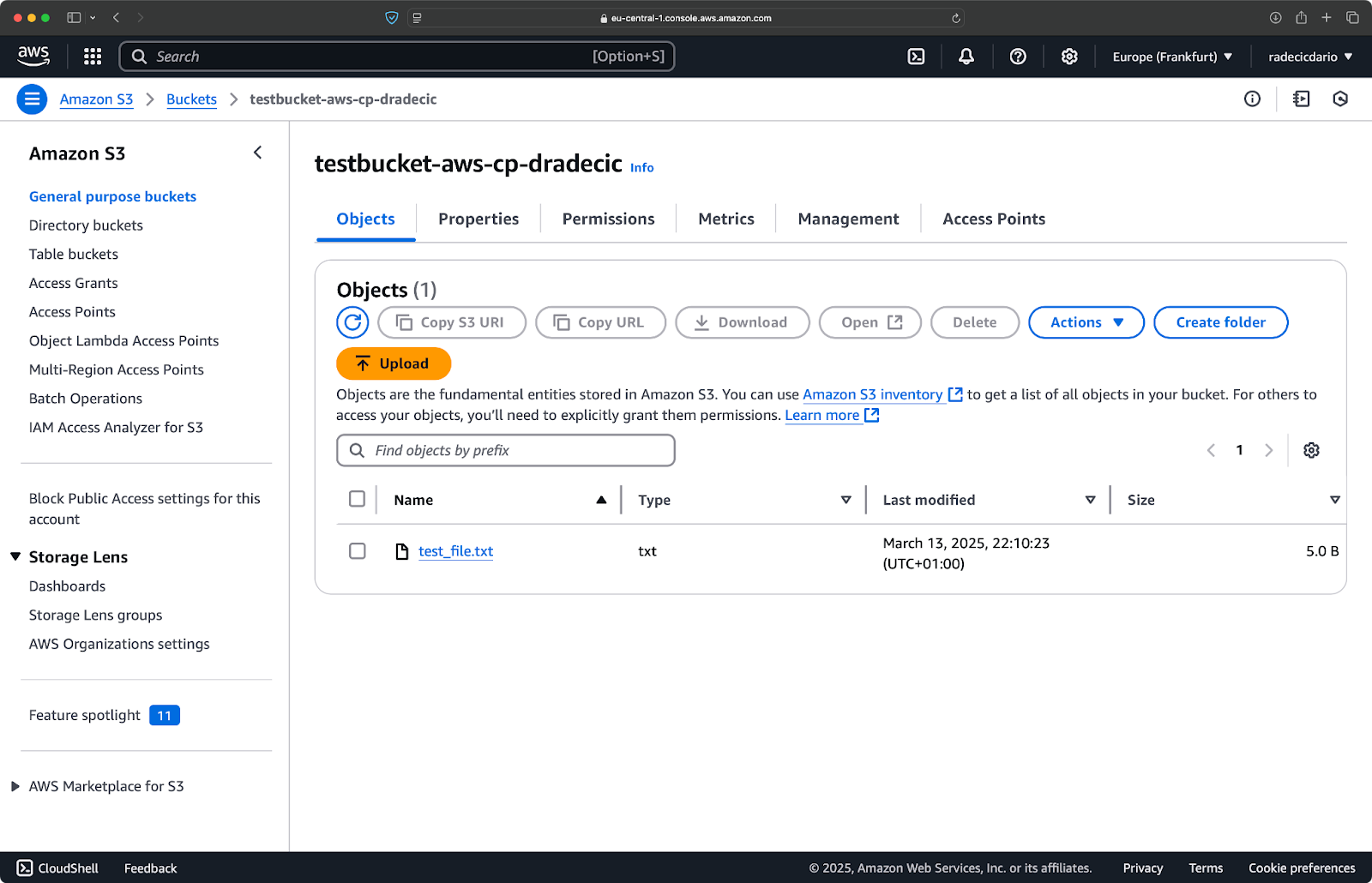
Afbeelding 9 – Inhoud van de S3-bucket
Evenzo, als je een lokale map naar je S3-bucket wilt kopiëren en deze, laten we zeggen, in een andere geneste map wilt plaatsen, voer dan een opdracht uit die lijkt op deze:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
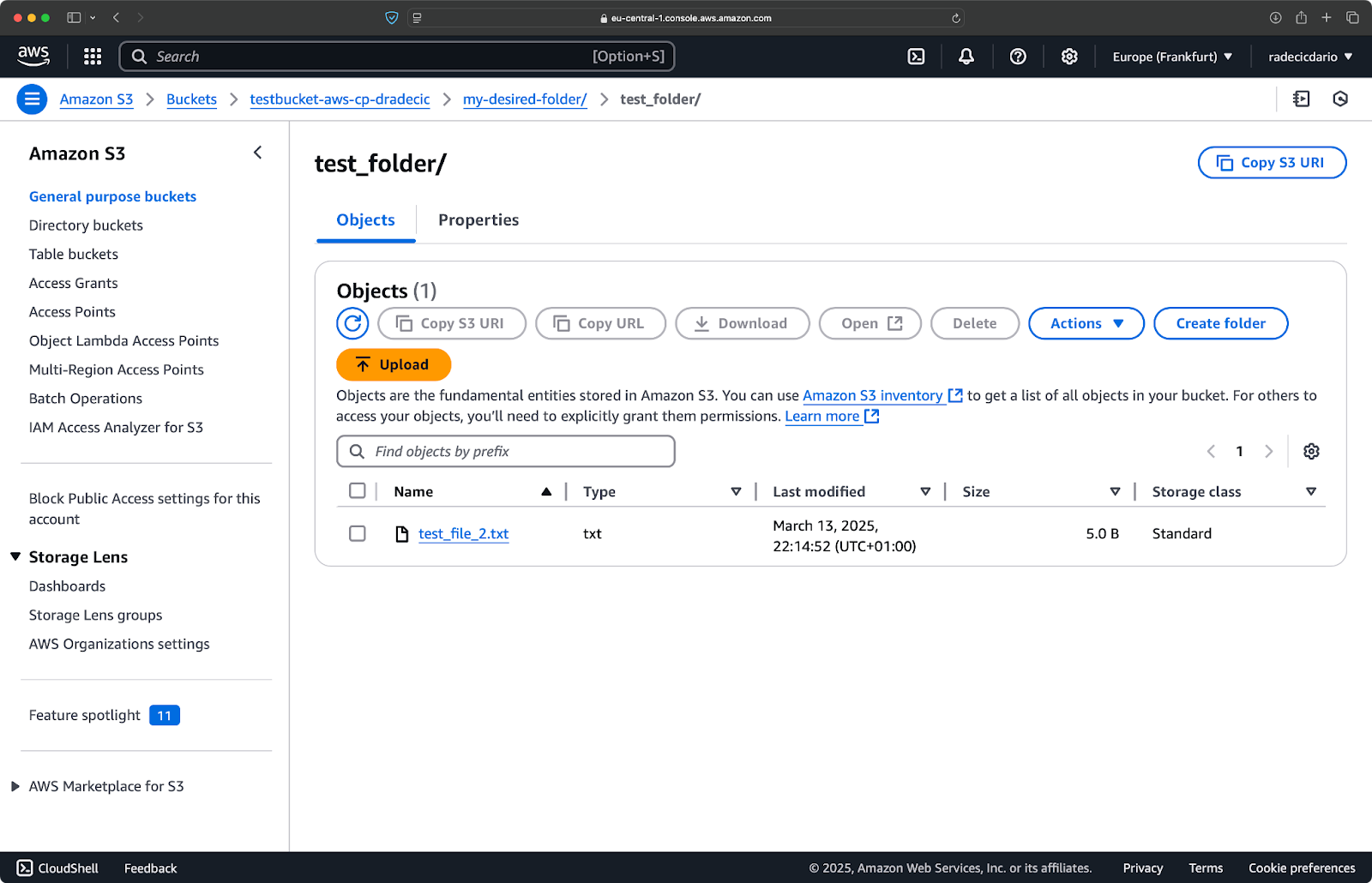
Afbeelding 10 – Inhoud van de S3-bucket na het uploaden van een map
De --recursive vlag zorgt ervoor dat alle bestanden en submappen binnen de map worden gekopieerd.
Houd er wel rekening mee – S3 heeft eigenlijk geen mappen – de padstructuur is gewoon een onderdeel van de sleutel van het object, maar het werkt conceptueel als mappen.
Een bestand kopiëren van S3 naar lokaal
Om een bestand van S3 naar uw lokale systeem te kopiëren, keert u eenvoudig de volgorde om – de bron wordt de S3 URI en de bestemming is uw lokale pad:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
Met dit commando wordt test_file.txt gedownload vanuit uw S3-bucket en opgeslagen als downloaded_test_file.txt in de opgegeven map. U ziet het meteen op uw lokale systeem:
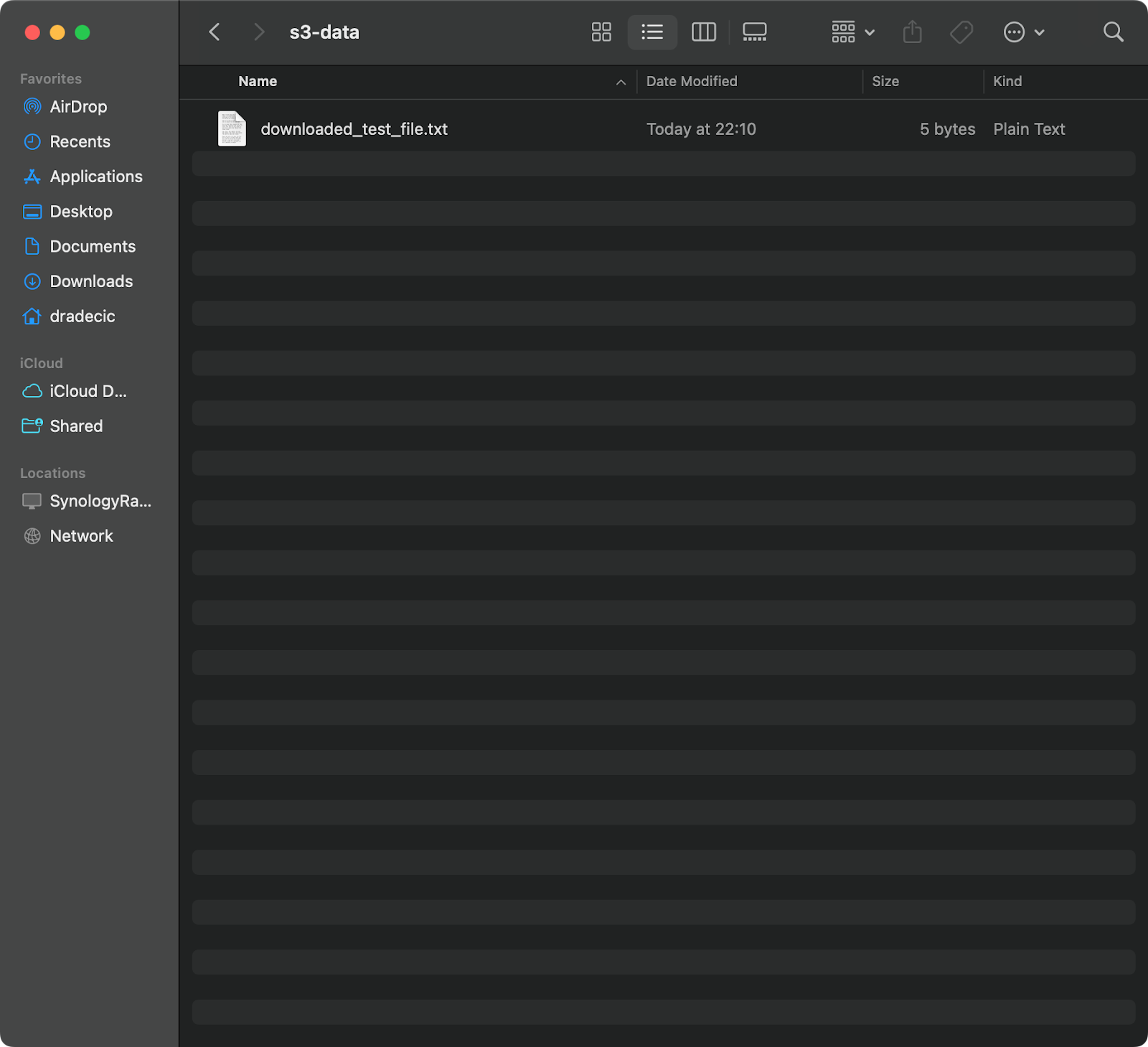
Afbeelding 11 – Downloaden van een enkel bestand van S3
Als u de bestandsnaam van de bestemming weglaat, zal het commando de originele bestandsnaam gebruiken:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
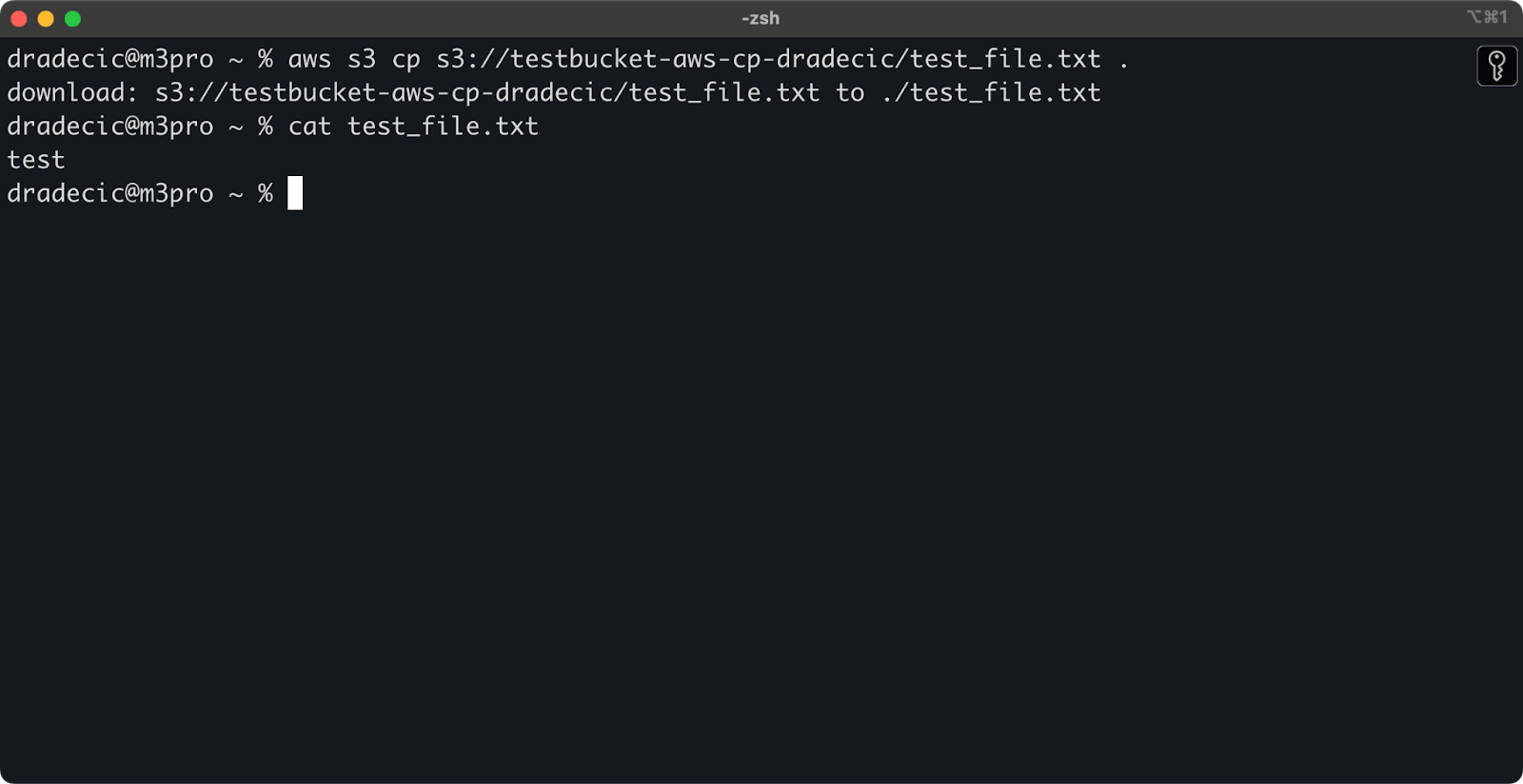
Afbeelding 12 – Inhoud van het gedownloade bestand
De punt (.) vertegenwoordigt uw huidige map, dus dit zal test_file.txt downloaden naar uw huidige locatie.
En tot slot, om een volledige map te downloaden, kunt u een commando gebruiken dat hierop lijkt:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
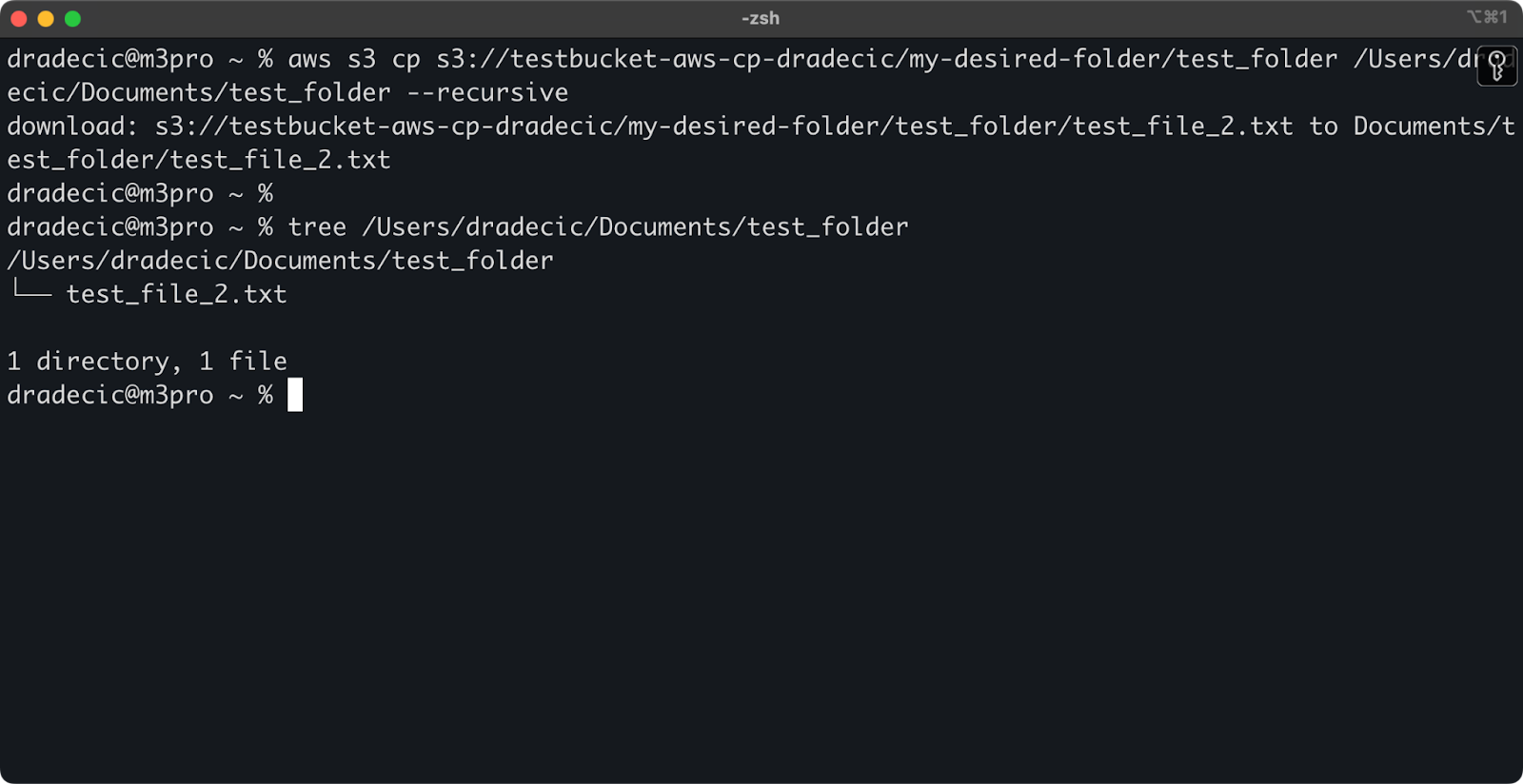
Afbeelding 13 – Inhoud van de gedownloade map
Houd er rekening mee dat de --recursive vlag essentieel is bij het werken met meerdere bestanden – zonder deze vlag zal het commando mislukken als de bron een map is.
Met deze basiscommando’s kunt u al het merendeel van de bestandsoverdrachttaken volbrengen die u nodig hebt. Maar in de volgende sectie zult u meer geavanceerde opties leren die u meer controle geven over het kopieerproces.
Geavanceerde AWS S3 cp-opties en functies
AWS biedt een aantal geavanceerde opties waarmee u bestandsoverdrachtsoperaties kunt maximaliseren. In deze sectie zal ik u enkele van de meest nuttige vlaggen en parameters laten zien die u zullen helpen bij uw dagelijkse taken.
Het gebruik van de –exclude en –include vlaggen
Soms wil je alleen bepaalde bestanden kopiëren die aan specifieke patronen voldoen. De --exclude en --include vlaggen stellen je in staat om bestanden te filteren op basis van patronen, en geven je nauwkeurige controle over wat er gekopieerd wordt.
Om de context te schetsen, dit is de mappenstructuur waar ik mee werk:
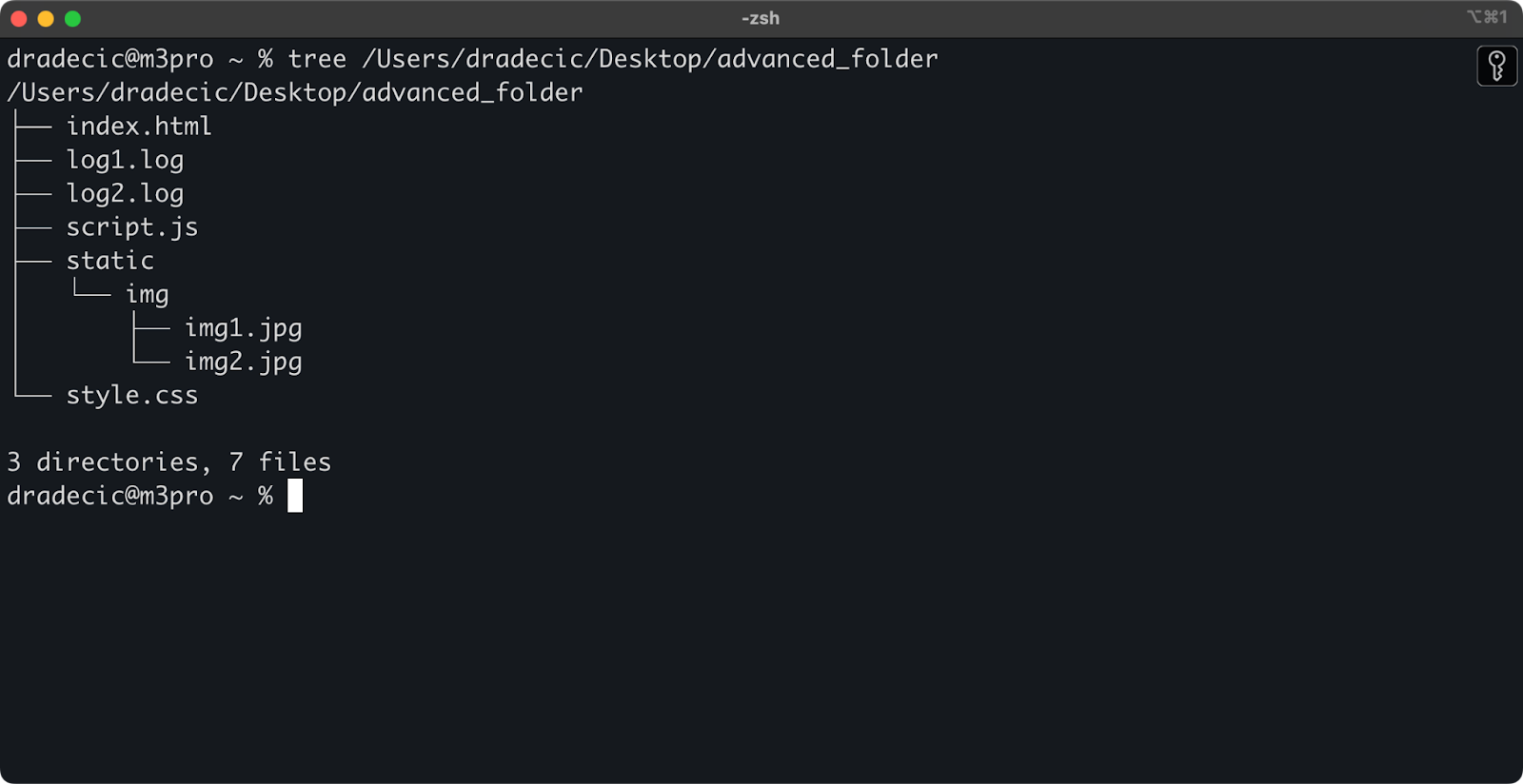
Afbeelding 14 – Mappenstructuur
Stel nu dat je alle bestanden uit de map wilt kopiëren, behalve de .log bestanden:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
Deze opdracht kopieert alle bestanden uit de advanced_folder map naar S3, met uitzondering van bestanden met de .log extensie:
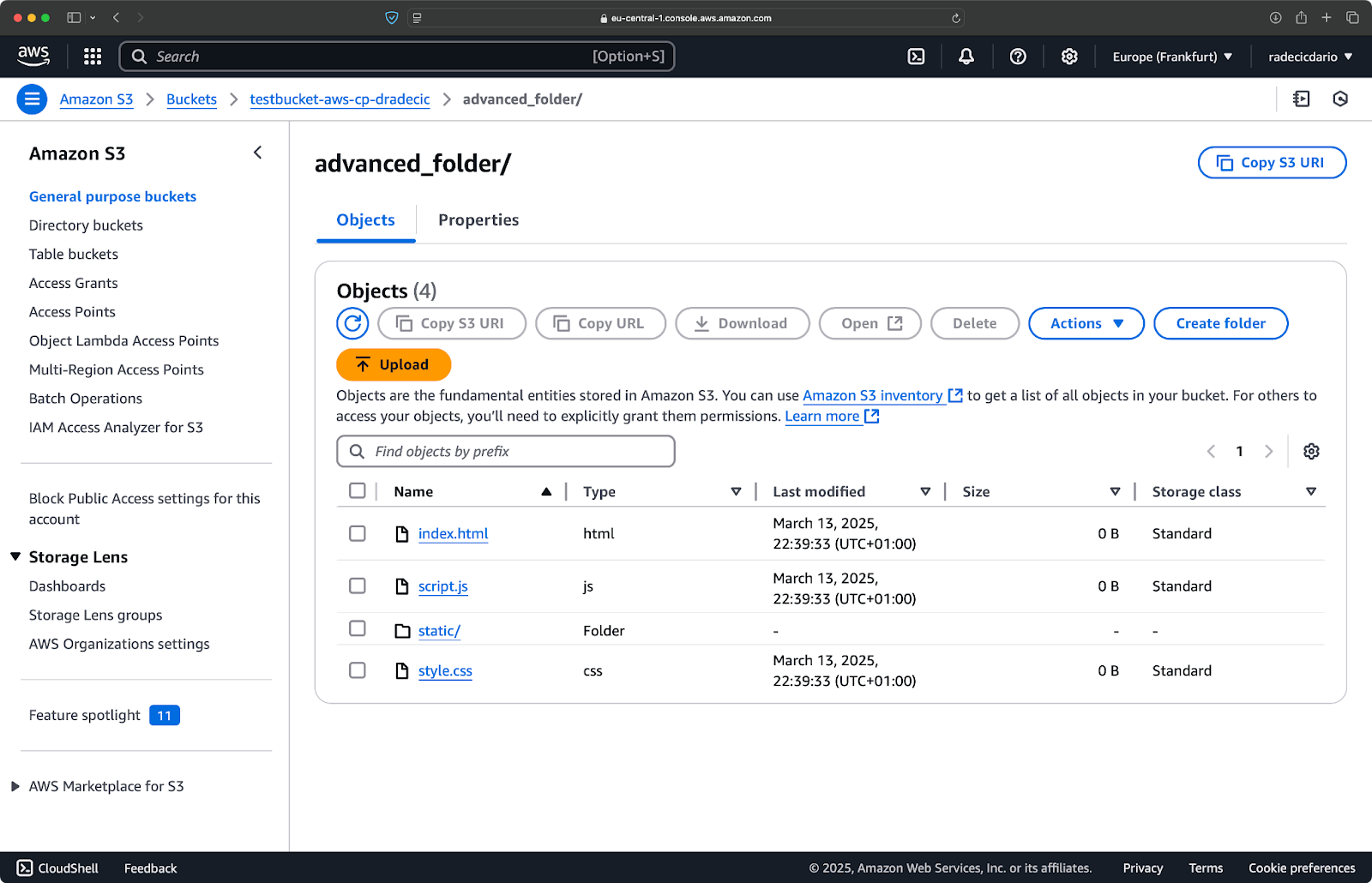
Afbeelding 15 – Resultaten van de mapkopie
Je kunt ook meerdere patronen combineren. Stel dat je alleen de HTML- en CSS-bestanden uit de projectmap wilt kopiëren:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
Deze opdracht sluit eerst alles uit (--exclude "*"), en omvat vervolgens alleen bestanden met de extensies .html en .css. Het resultaat ziet er als volgt uit:
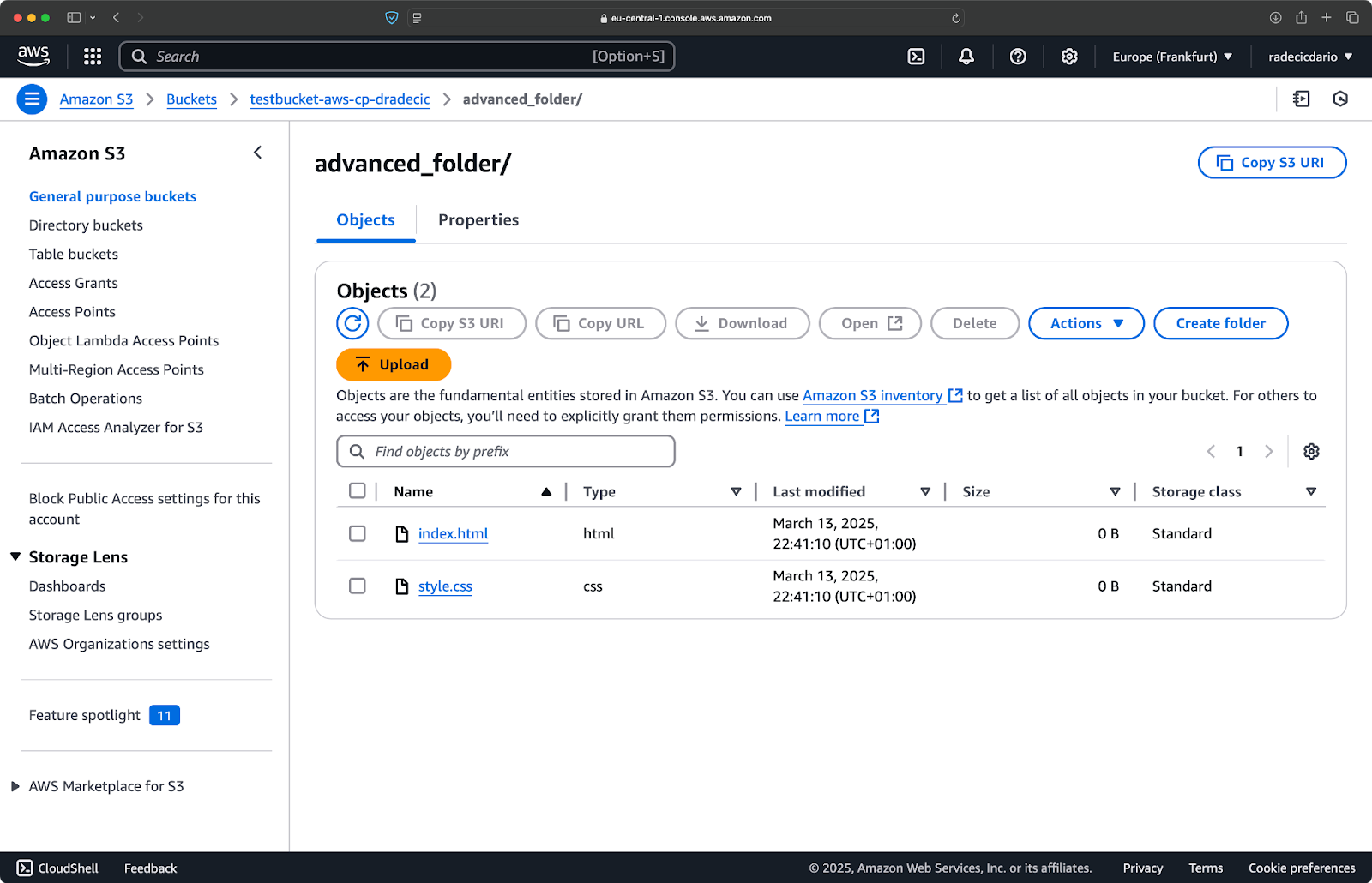
Afbeelding 16 – Resultaten van de mapkopie (2)
Houd er rekening mee dat de volgorde van de vlaggen belangrijk is – AWS CLI verwerkt deze vlaggen sequentieel, dus als je --include vóór --exclude plaatst, krijg je andere resultaten:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
Dit keer werd er niets naar de bucket gekopieerd:
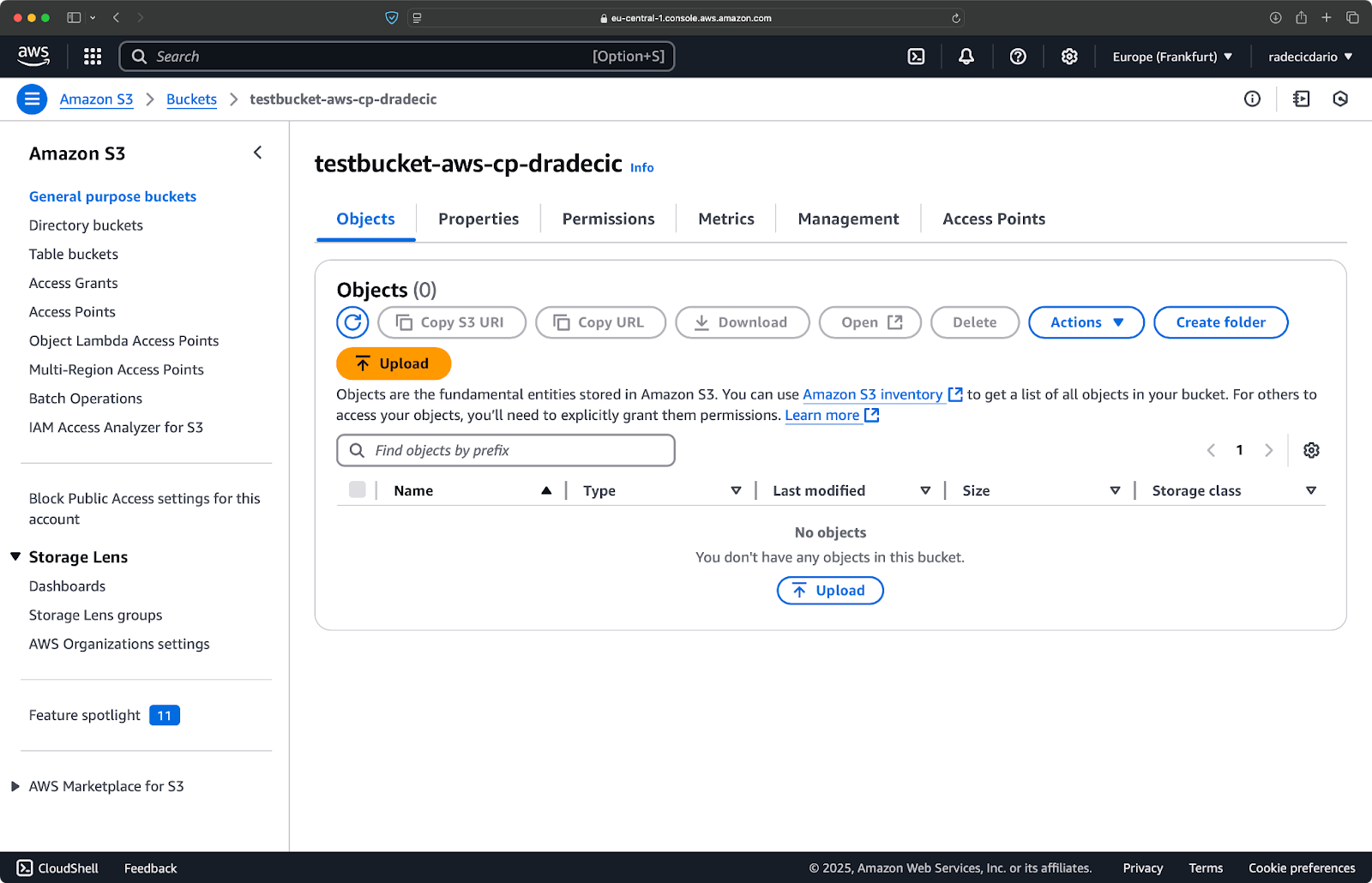
Afbeelding 17 – Resultaten van de mapkopie (3)
Het opgeven van de S3-opslagklasse
Amazon S3 biedt verschillende opslagklassen, elk met verschillende kosten en ophaaleigenschappen. Standaard uploadt aws s3 cp bestanden naar de Standaard opslagklasse, maar je kunt een andere klasse specificeren met de --storage-class vlag:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
Dit commando uploadt large-archive.zip naar de Glacier opslagklasse, die aanzienlijk goedkoper is maar hogere ophaalkosten en langere ophaaltijden heeft:
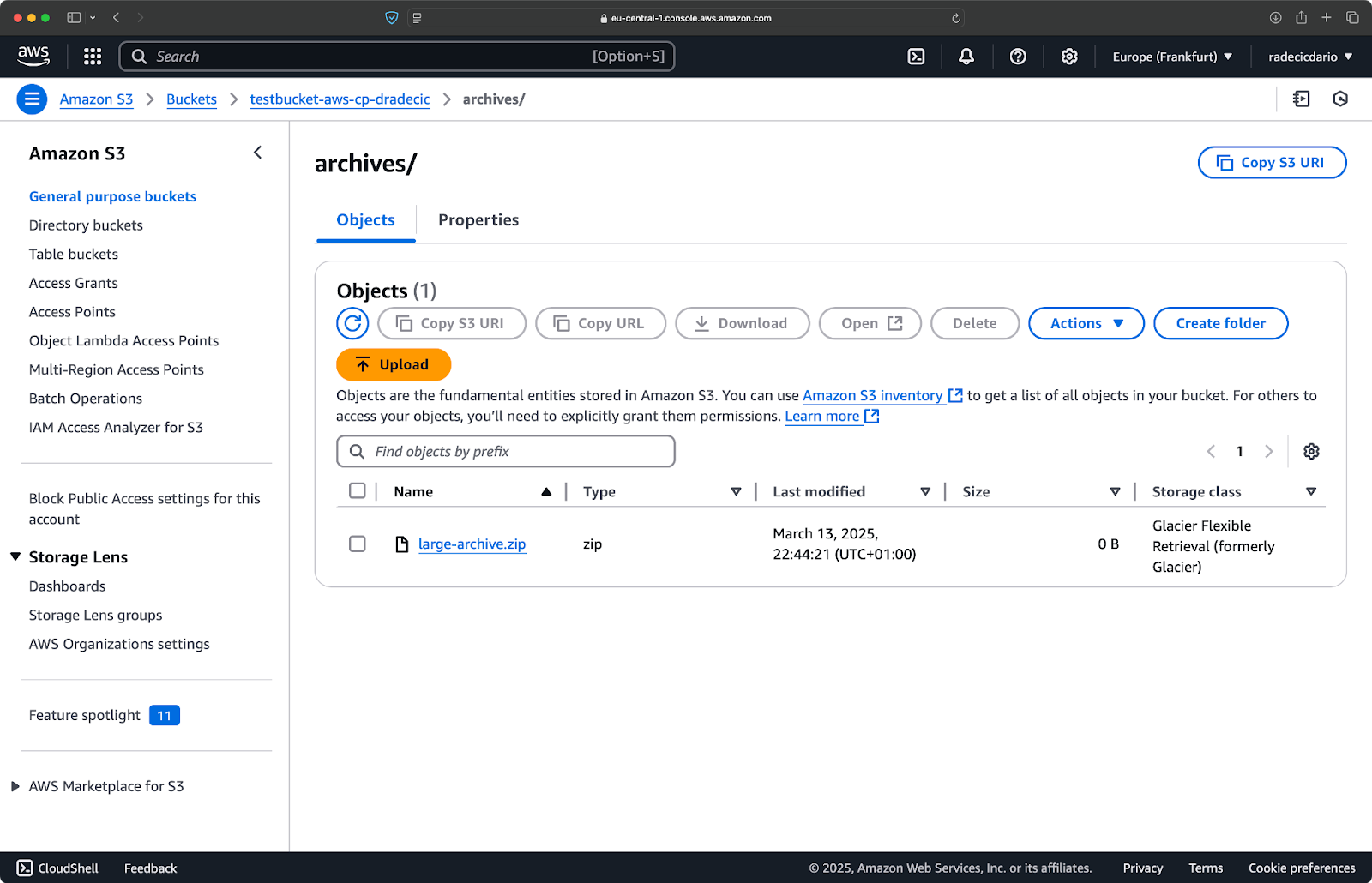
Afbeelding 18 – Bestanden naar S3 kopiëren met verschillende opslagklassen
De beschikbare opslagklassen zijn:
STANDARD(standaard): Algemeen opslag met hoge duurzaamheid en beschikbaarheid.REDUCED_REDUNDANCY(niet meer aanbevolen): Lagere duurzaamheid, kostenbesparende optie, nu verouderd.STANDARD_IA(Infrequent Access): Goedkopere opslag voor gegevens die minder vaak worden geraadpleegd.ONEZONE_IA(Single Zone Infrequent Access): Goedkopere, minder vaak geraadpleegde opslag in een enkele AWS Availability Zone.INTELLIGENT_TIERING: Verplaatst automatisch gegevens tussen opslaglagen op basis van toegangspatronen.GLACIER: Goedkope archiveringsopslag voor langdurige opslag, ophalen binnen enkele minuten tot uren.DEEP_ARCHIVE: Goedkoopste archiveringsopslag, ophalen binnen enkele uren, ideaal voor langdurige back-up.
Als je bestanden back-upt waarvoor je geen directe toegang nodig hebt, kan het gebruik van GLACIER of DEEP_ARCHIVE aanzienlijke opslagkosten besparen.
Bestanden synchroniseren met de –exact-timestamps vlag
Bij het bijwerken van bestanden in S3 die al bestaan, wilt u mogelijk alleen bestanden kopiëren die zijn gewijzigd. De --exact-timestamps vlag helpt hierbij door timestamps tussen de bron en bestemming te vergelijken.
Hier is een voorbeeld:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
Met deze vlag zal het commando alleen bestanden kopiëren als hun timestamps verschillen van de bestanden die al in S3 staan. Dit kan de overdrachtstijd en bandbreedtegebruik verminderen wanneer u regelmatig een grote set bestanden bijwerkt.
Dus, waarom is dit nuttig? Stel je eens voor dat je implementatiescenario’s hebt waarin je je toepassingsbestanden wilt bijwerken zonder onnodige overdracht van ongewijzigde assets.
Hoewel --exact-timestamps handig is voor het uitvoeren van een vorm van synchronisatie, als u een meer geavanceerde oplossing nodig heeft, overweeg dan om aws s3 sync te gebruiken in plaats van aws s3 cp. Het sync commando is specifiek ontworpen om mappen gesynchroniseerd te houden en heeft aanvullende mogelijkheden hiervoor. Ik heb alles geschreven over het sync commando in de AWS S3 Sync zelfstudie.
Met deze geavanceerde opties hebt u nu veel meer controle over uw S3-bestandsbewerkingen. U kunt specifieke bestanden targeten, opslagkosten optimaliseren en efficiënt uw bestanden bijwerken. In de volgende sectie leert u hoe u deze bewerkingen kunt automatiseren met scripts en geplande taken.
Automatiseren van bestandsoverdrachten met AWS S3 cp
Tot nu toe heb je geleerd hoe je handmatig bestanden naar en van S3 kunt kopiëren met de opdrachtregel. Een van de grootste voordelen van het gebruik van aws s3 cp is dat je deze overdrachten eenvoudig kunt automatiseren, wat je veel tijd zal besparen.
Laten we verkennen hoe je het aws s3 cp commando kunt integreren in scripts en geplande taken voor automatische bestandsoverdrachten.
Gebruik van AWS S3 cp in scripts
Hier is een eenvoudig bash-scriptvoorbeeld dat een map naar S3 back-upt, een tijdstempel aan de backup toevoegt en foutafhandeling en logging naar een bestand implementeert:
#!/bin/bash # Stel variabelen in SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # Zorg ervoor dat de logs-directory bestaat mkdir -p "$(dirname "$LOG_FILE")" # Maak de backup en log de output echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # Controleer of de backup succesvol was if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
Bewaar dit als backup.sh, maak het uitvoerbaar met chmod +x backup.sh, en je hebt een herbruikbaar back-upscript!
Je kunt het vervolgens uitvoeren met de volgende opdracht:
./backup.sh
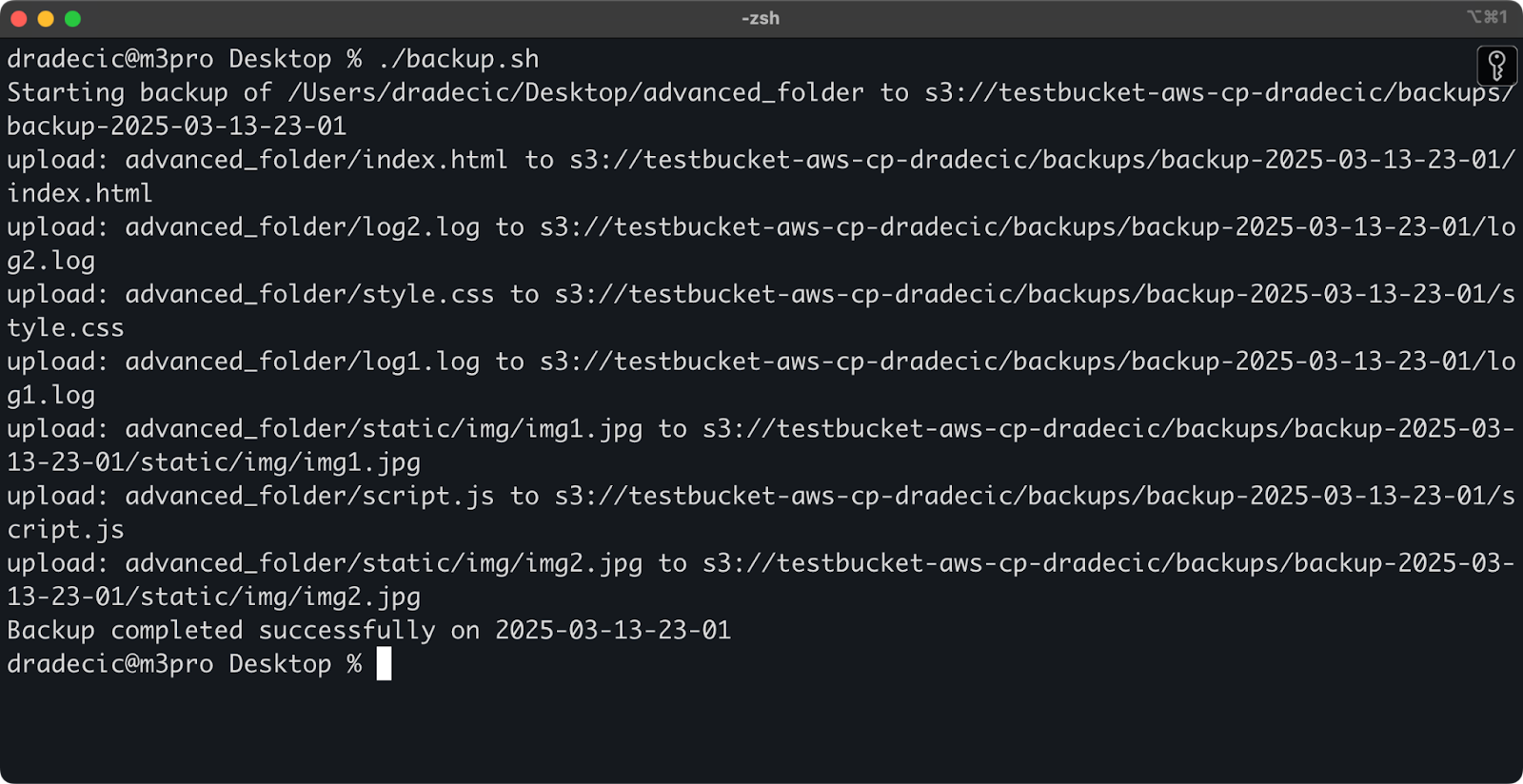
Afbeelding 19 – Script dat in de terminal draait
Onmiddellijk daarna zal de backups map op de bucket gevuld worden:
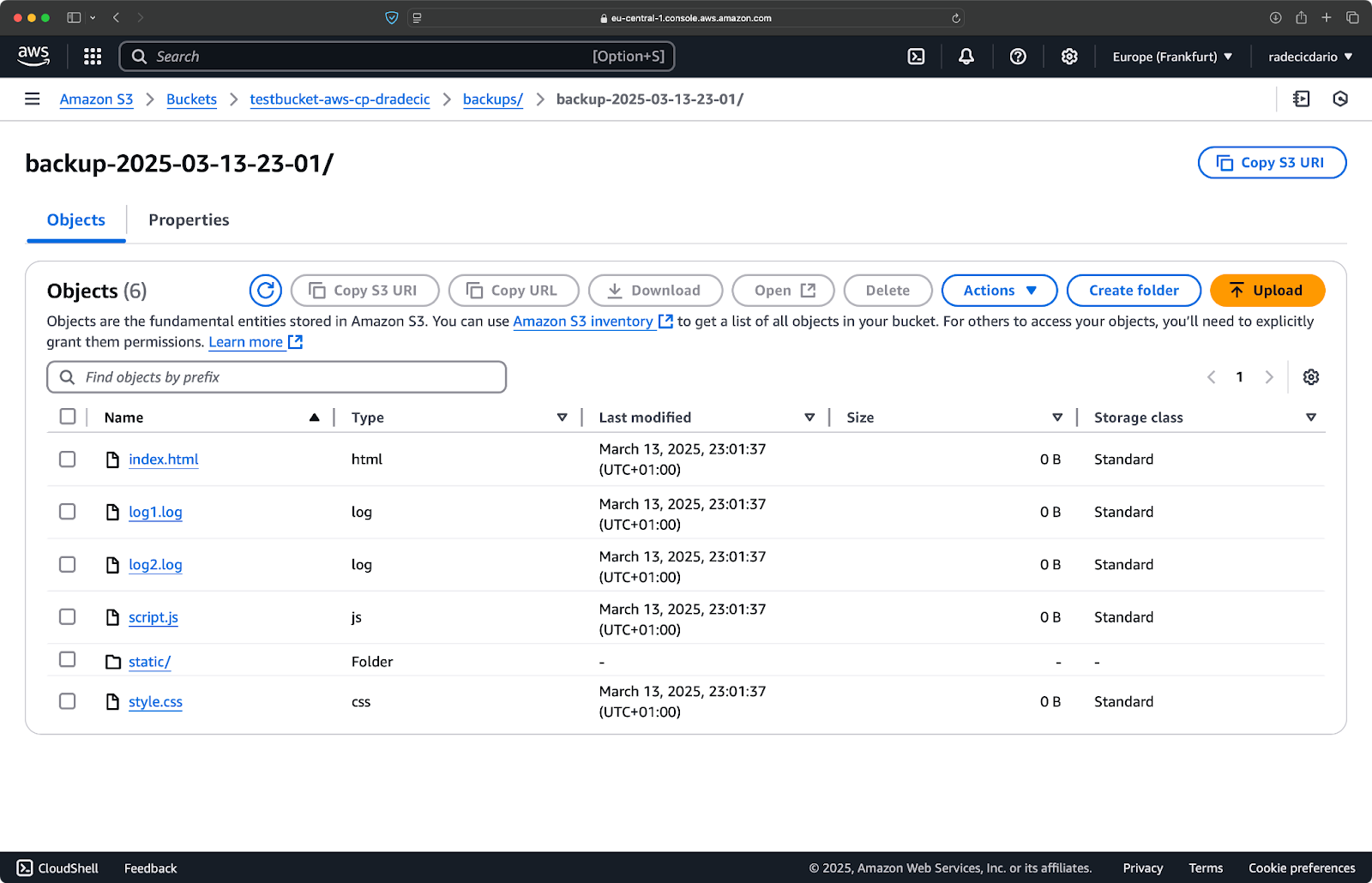
Afbeelding 20 – Backup opgeslagen op S3-bucket
Laten we dit naar een hoger niveau tillen door het script op een schema te draaien.
Bestandoverdrachten plannen met cron-taken
Nu je een script hebt, is de volgende stap om het automatisch te plannen om op specifieke tijden te draaien.
Als je op Linux of macOS bent, kun je cron gebruiken om je back-ups te plannen. Hier is hoe je een cron-taak instelt om je back-upscript elke dag om middernacht uit te voeren:
1. Open je crontab om te bewerken:
crontab -e
2. Voeg de volgende regel toe om je script dagelijks om middernacht uit te voeren:
0 0 * * * /path/to/your/backup.sh
Afbeelding 21 – Cron-taak voor het dagelijks uitvoeren van script
Het formaat voor cron-taken is minuut uur dag-van-maand maand dag-van-week commando. Hier zijn nog een paar voorbeelden:
- Voer elk uur uit:
0 * * * * /pad/naar/jouw/backup.sh - Voer elke maandag om 9 uur ’s ochtends uit:
0 9 * * 1 /pad/naar/jouw/backup.sh - Voer op de 1e van elke maand uit:
0 0 1 * * /pad/naar/jouw/backup.sh
En dat is het! Het backup.sh script zal nu op het geplande interval worden uitgevoerd.
Het automatiseren van je S3-bestandsoverdrachten is de moeite waard. Het is vooral nuttig voor scenario’s zoals:
- Dagelijkse back-ups van belangrijke gegevens
- Productafbeeldingen synchroniseren met een website
- Logbestanden verplaatsen naar langdurige opslag
- Bijwerken van websitebestanden implementeren
Automatietechnieken zoals deze helpen je een betrouwbaar systeem op te zetten dat bestandsoverdrachten zonder handmatige tussenkomst afhandelt. Je hoeft het maar één keer te schrijven, en daarna kun je het vergeten.
In de volgende sectie bespreek ik enkele best practices om je aws s3 cp operaties veiliger en efficiënter te maken.
Best Practices voor het Gebruik van AWS S3 cp
Hoewel het aws s3 cp-commando eenvoudig te gebruiken is, kunnen er dingen misgaan.
Als je de beste praktijken volgt, vermijd je veelvoorkomende valkuilen, optimaliseer je de prestaties en houd je je gegevens veilig. Laten we deze praktijken verkennen om je bestandsoverdrachtsoperaties efficiënter te maken.
Efficiënt bestandsbeheer
Wanneer je met S3 werkt, zal het logisch organiseren van je bestanden je tijd besparen en hoofdpijn in de toekomst voorkomen.
Ten eerste, stel een consistente bucket- en prefixnaamconventie in. Bijvoorbeeld, je kunt je gegevens scheiden op basis van omgeving, toepassing of datum:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
Deze soort organisatie maakt het gemakkelijker om:
- Specifieke bestanden te vinden wanneer je ze nodig hebt.
- Bucketbeleid en -machtigingen op het juiste niveau toe te passen.
- Levenscyclusregels in te stellen voor archivering of het verwijderen van oude gegevens.
Nog een tip: Bij het overdragen van grote hoeveelheden bestanden, overweeg om eerst kleine bestanden samen te groeperen (met zip of tar) voordat je ze uploadt. Dit vermindert het aantal API-oproepen naar S3, wat de kosten kan verlagen en de overdrachten kan versnellen.
# In plaats van duizenden kleine logbestanden te kopiëren # tar ze eerst in en upload ze dan tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
Omgaan met grote gegevensoverdrachten
Wanneer je grote bestanden of veel bestanden tegelijk kopieert, zijn er een paar technieken om het proces betrouwbaarder en efficiënter te maken.
Je kunt de --quiet vlag gebruiken om de uitvoer te verminderen bij het uitvoeren van scripts:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
Dit onderdrukt de voortgangsinformatie voor elk bestand, wat logs beheerbaarder maakt. Het verbetert ook de prestaties enigszins.
Voor zeer grote bestanden is het raadzaam om multipart-uploads te overwegen met de --multipart-threshold vlag:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
De bovenstaande instelling vertelt AWS CLI om bestanden groter dan 100 MB op te splitsen in meerdere delen voor upload. Dit heeft een paar voordelen:
- Als de verbinding wegvalt, hoeft alleen het getroffen deel opnieuw te worden geprobeerd.
- Onderdelen kunnen parallel worden geüpload, wat mogelijk de doorvoer verhoogt.
- U kunt grote uploads onderbreken en hervatten.
Wanneer gegevens overbrengen tussen regio’s, overweeg dan om S3 Transfer Acceleration te gebruiken voor snellere uploads:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
Hiermee wordt uw overdracht via het edge-netwerk van Amazon geleid, wat de overdracht tussen regio’s aanzienlijk kan versnellen.
Beveiliging garanderen
Beveiliging moet altijd een topprioriteit zijn bij het werken met je gegevens in de cloud.
Zorg er eerst voor dat je IAM-rechten het principe van minste privilege volgen.Verleen alleen de specifieke rechten die nodig zijn voor elke taak.
Hier is een voorbeeldbeleid dat je aan de gebruiker kunt toewijzen:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
Dit beleid staat het kopiëren van bestanden van en naar alleen de “back-ups” voorvoegsel in “mijn-emmer” toe.
Een aanvullende manier om de beveiliging te vergroten is door versleuteling in te schakelen voor gevoelige gegevens. Je kunt server-side versleuteling specificeren bij het uploaden:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
Of, voor meer beveiliging, gebruik de AWS Key Management Service (KMS):
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
Overweeg echter, voor zeer gevoelige operaties, om VPC-eindpunten voor S3 te gebruiken. Dit houdt je verkeer binnen het AWS-netwerk en vermijdt het openbare internet volledig.
In de volgende sectie leer je hoe je veelvoorkomende problemen kunt oplossen die je kunt tegenkomen bij het werken met deze opdracht.
Problemen oplossen met AWS S3 cp Fouten
Één ding is zeker – je zult af en toe problemen tegenkomen bij het werken met aws s3 cp. Maar door veelvoorkomende fouten te begrijpen en hun oplossingen, bespaar je tijd en frustratie wanneer dingen niet zoals gepland verlopen.
In deze sectie laat ik je de meest voorkomende problemen zien en hoe je ze kunt oplossen.
Veelvoorkomende fouten en oplossingen
Fout: “Toegang geweigerd”
Dit is waarschijnlijk de meest voorkomende fout die je zult tegenkomen:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
Dit betekent meestal één van de drie dingen:
- Uw IAM-gebruiker heeft niet voldoende rechten om de bewerking uit te voeren.
- De bucket-policy beperkt de toegang.
- Uw AWS-inloggegevens zijn verlopen.
Om het probleem op te lossen:
- Controleer uw IAM-rechten om ervoor te zorgen dat u de benodigde
s3:PutObject(voor uploads) ofs3:GetObject(voor downloads) rechten heeft. - Controleer of de bucket-policy uw acties niet beperkt.
- Voer
aws configureuit om uw referenties bij te werken als ze verlopen zijn.
Foutmelding: “Bestand of map bestaat niet”
Deze fout treedt op wanneer het lokale bestand of de lokale map die u probeert te kopiëren niet bestaat:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
De oplossing is simpel – controleer uw bestandspaden zorgvuldig. Paden zijn hoofdlettergevoelig, houd daar rekening mee. Zorg er ook voor dat u zich in de juiste map bevindt bij het gebruik van relatieve paden.
Foutmelding: “De gespecificeerde bucket bestaat niet”
Als u deze foutmelding ziet:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
Controleer op:
- Typos in de naam van uw bucket.
- Of je de juiste AWS-regio gebruikt.
- Of de bucket daadwerkelijk bestaat (het kan zijn verwijderd).
Je kunt al je buckets vermelden met aws s3 ls om de juiste naam te bevestigen.
Foutmelding: “Verbindingstime-out”
Netwerkproblemen kunnen verbindingstime-outs veroorzaken:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
Om dit op te lossen:
- Controleer je internetverbinding.
- Probeer kleinere bestanden te gebruiken of multipart uploads in te schakelen voor grote bestanden.
- Overweeg om AWS Transfer Acceleration te gebruiken voor betere prestaties.
Omgaan met uploadfouten
Fouten komen veel vaker voor bij het overdragen van grote bestanden. In dat geval, probeer fouten op een elegante manier af te handelen.
Bijvoorbeeld, je kunt de --only-show-errors vlag gebruiken om foutdiagnose in scripts te vergemakkelijken:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
Dit onderdrukt succesvolle overdrachtberichten, zodat alleen fouten worden weergegeven, waardoor het oplossen van problemen bij grote overdrachten veel gemakkelijker wordt.
Voor het omgaan met onderbroken overdrachten zal het --recursive commando automatisch bestanden overslaan die al bestaan in de bestemming met dezelfde grootte. Om echter grondiger te werk te gaan, kun je de ingebouwde herhalingen van de AWS CLI gebruiken voor netwerkproblemen door deze omgevingsvariabelen in te stellen:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
Dit vertelt de AWS CLI om automatisch mislukte bewerkingen tot 5 keer opnieuw te proberen.
Maar voor zeer grote datasets, overweeg om aws s3 sync in plaats van cp te gebruiken, aangezien het beter is ontworpen om onderbrekingen aan te kunnen:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
De sync opdracht zal alleen bestanden overdragen die anders zijn dan wat al in de bestemming staat, wat het perfect maakt voor het hervatten van onderbroken grote overbrengingen.
Als je deze veelvoorkomende fouten begrijpt en passende foutafhandeling in je scripts implementeert, maak je je S3-kopieeroperaties veel robuuster en betrouwbaarder.
Samenvattend AWS S3 cp
Om af te sluiten, is de aws s3 cp opdracht een one-stop-shop voor het kopiëren van lokale bestanden naar S3 en vice versa.
Je hebt hier alles over geleerd in dit artikel. Je begon met de basisprincipes en omgevingsconfiguratie, en eindigde met het schrijven van geplande en geautomatiseerde scripts voor het kopiëren van bestanden. Je hebt ook geleerd hoe je enkele veelvoorkomende fouten en uitdagingen kunt aanpakken bij het verplaatsen van bestanden, vooral grote bestanden.
Dus, als je een ontwikkelaar, dataprofessional of systeembeheerder bent, denk ik dat je deze opdracht nuttig zult vinden. De beste manier om er vertrouwd mee te raken is door het regelmatig te gebruiken. Zorg ervoor dat je de basisprincipes begrijpt en besteed vervolgens wat tijd aan het automatiseren van tijdrovende onderdelen van je werk.
Om meer te weten te komen over AWS, volg deze cursussen van DataCamp:
Je kunt zelfs DataCamp gebruiken om je voor te bereiden op AWS-certificeringsexamens – AWS Cloud Practitioner (CLF-C02).