













Dit artikel is een fragment uit mijn boek TinyML Cookbook, Tweede Editie. Je kunt de code die in het artikel wordt gebruikt vinden hier.
Voorbereiding
Het toepassingsontwerp dat we in dit artikel zullen maken, heeft als doel om continu een 1-seconden audio clip te registreren en de modelinferentie uit te voeren, zoals weergegeven in de volgende afbeelding:
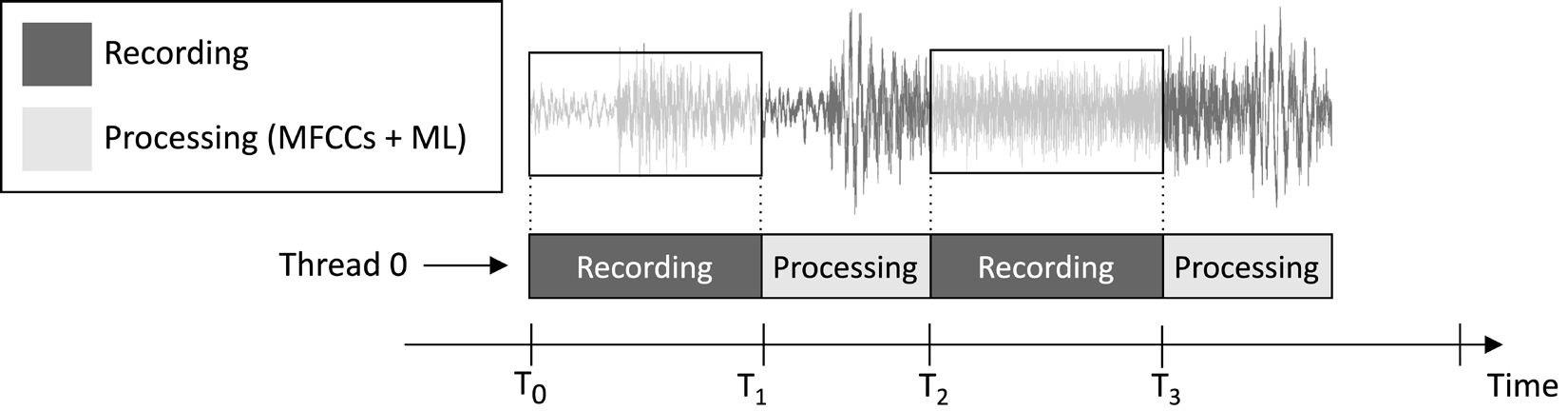
Figuur 1: Opnames en verwerkingstaken die sequentieel worden uitgevoerd
Uit de taakuitvoeringstijdlijn die wordt weergegeven in de bovenstaande afbeelding, kun je zien dat de kenmerkextractie en modelinferentie altijd plaatsvinden na de audio-opname en niet gelijktijdig. Daarom is het duidelijk dat we niet bepaalde segmenten van de live audiostream verwerken.
In tegenstelling tot een echt tijdig sleutelwoordherkenning (KWS) toepassing, die alle delen van de audiostream moet opvangen en verwerken om nooit een gesproken woord te missen, kunnen we hier deze vereiste ontspannen omdat dit de effectiviteit van de toepassing niet in gevaar brengt.
Zoals we weten, is de input voor de MFCC-kenmerkextractie de 1-seconden ruwe audio in Q15-indeling. De metingen die met de microfoon worden verkregen, worden echter weergegeven als 16-bits gehele waarden. Daarom hoe converteren we de 16-bits gehele waarden naar Q15? De oplossing is eenvoudiger dan je misschien denkt: het converteren van de audiowaarnemingen is niet nodig.
Om dit te begrijpen, overweeg de Q15 vaste-punt formaat. Dit formaat kan floating-point waarden binnen het bereik [-1, 1] vertegenwoordigen. Het converteren van floating-point naar Q15 houdt het vermenigvuldigen van de floating-point waarden met 32.768 (2^15) in. Toch, omdat de floating-point representatie voortkomt uit het delen van het 16-bits gehele getal sample door 32.768 (2^15), betekent dit dat de 16-bits gehele getal waarden inherent in Q15 formaat zijn.
Hoe te doen…
Neem de breadboard met de microfoon die is aangesloten op de Raspberry Pi Pico. Verwijder de datakabel van de microcontroller en verwijder de drukknop en de hiermee verbonden stekkeraansluitingen van de breadboard, aangezien deze voor dit recept niet nodig zijn. Figuur 2 toont wat je op de breadboard moet hebben:
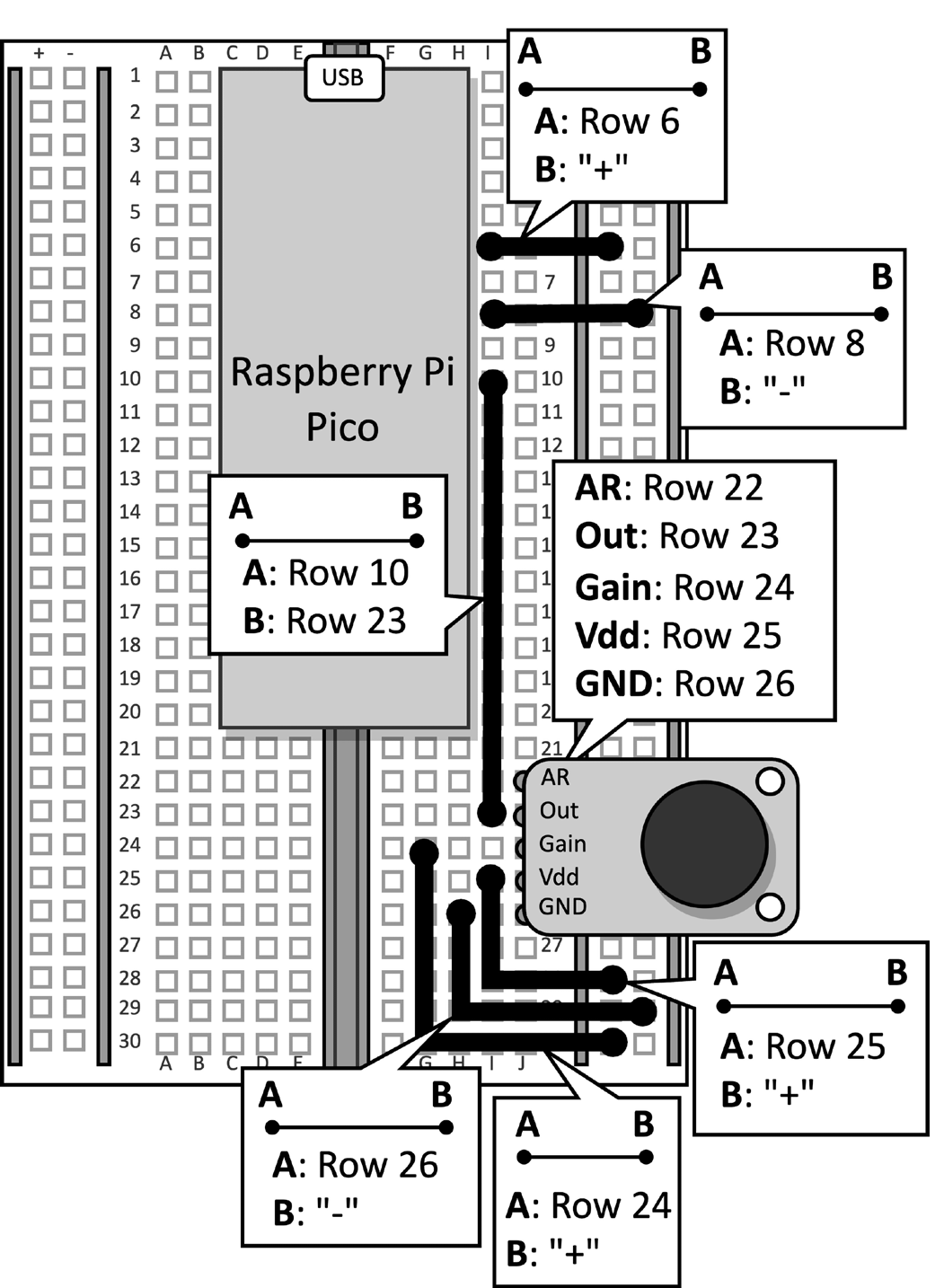
Figuur 2: Het elektronische circuit gebouwd op de breadboard
Na het verwijderen van de drukknop van de breadboard, open de Arduino IDE en maak een nieuw sketch.
Volg nu de volgende stappen om de muziekgenreherkenning applicatie te ontwikkelen op de Raspberry Pi Pico:
Stap 1
Download de Arduino TensorFlow Lite bibliotheek van de TinyML-Cookbook_2E GitHub repository.
Na het downloaden van het ZIP-bestand, importeer het in de Arduino IDE.
Stap 2
Importeer alle gegenereerde C-headerbestanden die nodig zijn voor het MFCCs-kenmerkextractiealgoritme in de Arduino IDE, met uitzondering van test_src.h en test_dst.h.
Stap 3
Kopieer de schets ontwikkeld in Hoofdstuk 6, Implementatie van het MFCCs-kenmerkextractiealgoritme op de Raspberry Pi Pico voor het implementeren van het MFCCs-kenmerkextractie, met uitzondering van de setup() en loop() functies.
Verwijder de inclusie van de test_src.h en test_dst.h headerbestanden. Verwijder vervolgens de toewijzing van de dst-array, aangezien de MFCCs direct in de invoer van het model worden opgeslagen.
Stap 4
Kopieer de schets ontwikkeld in Hoofdstuk 5, Genres herkennen in muziek met TensorFlow en de Raspberry Pi Pico – Deel 1, om audio-samples met de microfoon op te nemen, met uitzondering van de setup() en loop() functies.
Zodra u de code hebt geïmporteerd, verwijder alle verwijzingen naar de LED en de drukknop, aangezien ze niet langer nodig zijn. Wijzig vervolgens de definitie van AUDIO_LENGTH_SEC om audio op te nemen van 1 seconde:
#define AUDIO_LENGTH_SEC 1Stap 5
Importeer het headerbestand dat het TensorFlow Lite-model bevat (model.h) in het Arduino-project.
Zodra het bestand is geïmporteerd, voeg de model.h headerbestand in de schets toe:
#include "model.h"
Bevat de noodzakelijke headerbestanden voor tflite-micro:
#include
#include
#include
#include
#include
#include Stap 6
Declareer globale variabelen voor het tflite-micro model en de interpreter:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
Vervolgens, declareer de TensorFlow Lite tensor objecten (TfLiteTensor) om toegang te krijgen tot de input en output tensoren van het model:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
Stap 7
Declareer een buffer (tensor arena) om de tussenliggende tensoren op te slaan die tijdens de uitvoering van het model worden gebruikt:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
De grootte van de tensor arena is bepaald door empirische testen, aangezien het geheugen dat nodig is voor de tussenliggende tensoren varieert, afhankelijk van hoe de LSTM operator onderliggend wordt geïmplementeerd. Onze experimenten op de Raspberry Pi Pico hebben aangetoond dat het model alleen 16 KB RAM nodig heeft voor inferentie.
Stap 8
In de setup() functie, initialiseer de seriële periferie met een 115200 baud rate:
Serial.begin(115200);
while (!Serial);
De seriële periferie zal worden gebruikt om het herkende muziekgenre over de seriële communicatie te verzenden.
Stap 9
In de setup() functie, laad het TensorFlow Lite model dat is opgeslagen in het model.h headerbestand:
tflu_model = tflite::GetModel(model_tflite);Dan registreer je alle DNN-operaties die door tflite-micro worden ondersteund en initialiseer je de tflite-micro-interpreter:
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;Stap 10
In de setup() functie, geef je het geheugen vrij dat nodig is voor het model en haal je de geheugenpointers op van de input- en outputtensoren:
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
Stap 11
In de setup() functie, gebruik je de Raspberry Pi Pico SDK om de ADC-periferie te initialiseren:
adc_init();
adc_gpio_init(26);
adc_select_input(0);
Stap 12
In de loop() functie, bereid je de invoer van het model voor. Om dit te doen, neem je een audioclip op van 1 seconde:
// Reset audio buffer
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();Na het opnemen van de audio, haal je de MFCC’s op:
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
Zoals je kunt zien uit het voorgaande codefragment, worden de MFCC’s direct in de invoer van het model opgeslagen.
Stap 13
Voer de modellering uit en retourneer het classificatieresultaat via seriële communicatie:
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);Plug nu het micro-USB-datakabel in de Raspberry Pi Pico. Zodra je dit hebt aangesloten, compileer en upload de schets op de microcontroller.
Vervolgens, open de seriële monitor in de Arduino IDE en plaats je smartphone dicht bij de microfoon om een disc, jazz of metal nummer af te spelen. Het toepassingsprogramma zou nu het muziekgenre van het nummer moeten herkennen en het classificatieresultaat in de seriële monitor weergeven!
Conclusie
In deze artikel heb je geleerd hoe je een getraind model voor muziekgenreclassificatie kunt implementeren op de Raspberry Pi Pico met behulp van tflite-micro.
Source:
https://dzone.com/articles/recognizing-music-genres-with-the-raspberry-pi-pic