













Grafana Loki는 수평 확장이 가능하고 고가용성을 갖춘 로그 집계 시스템입니다. Loki는 간단함과 비용 효율성을 위해 설계되었습니다. 2018년 Grafana Labs에 의해 만들어진 Loki는 특히 클라우드 네이티브 및 Kubernetes 환경에 대한 전통적인 로깅 시스템에 대한 매력적인 대안으로 급속히 부상했습니다.
Loki는 포괄적인 로그 여정을 제공할 수 있습니다. 우리는 적절한 로그 스트림을 선택한 다음 관련 로그에 초점을 맞추기 위해 필터링할 수 있습니다. 그런 다음 구조화된 로그 데이터를 파싱하여 사용자 정의 분석 요구에 맞게 형식화할 수 있습니다. 로그는 발표를 위해 적절하게 변환되거나 예를 들어 추가 파이프라인 처리를 수행할 수도 있습니다.
Loki는 넓은 Grafana 생태계와 원활하게 통합됩니다. 사용자는 LogQL을 사용하여 로그를 쿼리할 수 있습니다. 이는 의도적으로 Prometheus PromQL과 유사하게 설계된 쿼리 언어로, 이미 Prometheus 메트릭과 작업하는 사용자에게 친숙한 경험을 제공하며 Grafana 대시보드 내에서 메트릭과 로그 간의 강력한 상관 관계를 활성화합니다.
본 문서는 Loki의 기본 사항으로 시작하여 기본 아키텍처 개요로 이어집니다. LogQL 기본 사항이 이어지며 관련된 트레이드 오프로 마무리됩니다.
Loki 기초개념
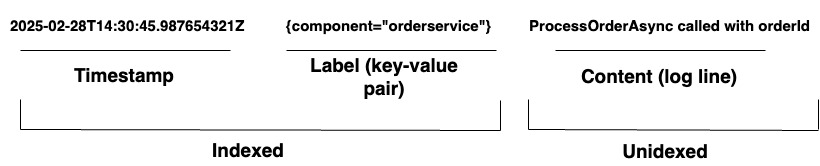
조직이 복잡한 시스템을 관리할 때, Loki는 통합된 로깅 솔루션을 제공합니다. 다양한 하드웨어와 소프트웨어의 포괄적인 커버리지를 보장하기 위해 다양한 에이전트나 API를 통해 어떤 소스에서든 로그를 수집할 수 있습니다. Loki는 로그를 로그 스트림으로 저장하며, 다이어그램 1에 나와 있습니다. 각 항목은 다음을 포함합니다:
- 나노초 정밀도를 갖는 타임스탬프
- 로그를 검색하는 데 사용되는 키-값 쌍인 라벨. 라벨은 로그 라인의 메타데이터를 제공합니다. 데이터의 식별과 검색에 사용됩니다. 라벨은 로그 스트림의 인덱스를 형성하고 로그 저장소를 구조화합니다. 라벨과 그 값의 고유한 조합마다 구별되는 로그 스트림이 정의됩니다. 스트림 내의 로그 항목은 그룹화되어 압축되고 세그먼트에 저장됩니다.
- 실제 로그 내용. 이것은 로우 로그 라인입니다. 인덱싱되지 않으며 압축된 청크에 저장됩니다.
아키텍처
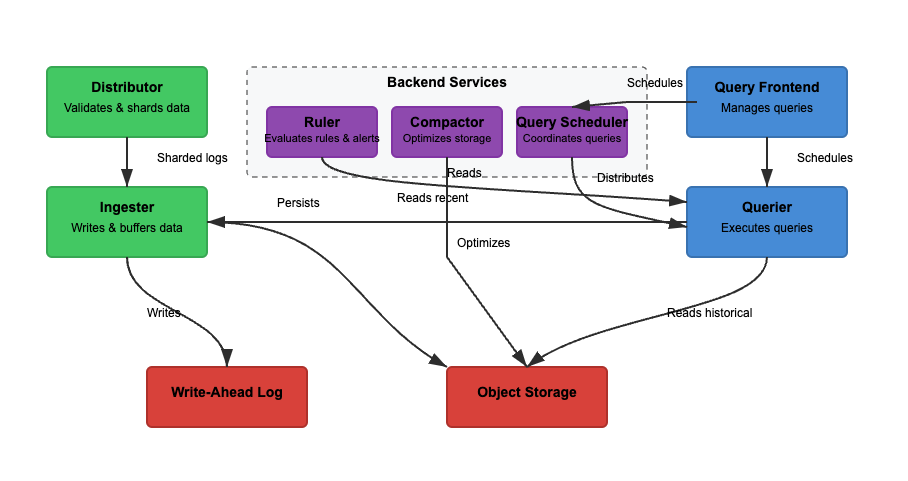
우리는 Loki의 아키텍처를 읽기, 쓰기, 로그 저장을 기반으로 분석할 것입니다. Loki는 모놀리식(단일 이진) 또는 마이크로서비스 모드에서 작동할 수 있으며, 구성 요소가 독립적으로 확장됩니다. 특정 사용 사례에 맞게 독립적으로 확장할 수 있는 읽기 및 쓰기 기능입니다. 각 경로를 자세히 살펴보겠습니다.
쓰기
다이어그램 2에서 쓰기 경로는 녹색 경로입니다. 로그가 Loki에 들어가면 디스트리뷰터는 레이블을 기반으로 로그를 분배합니다. 그런 다음 인제스터는 로그를 메모리에 저장하고 컴팩터가 저장 공간을 최적화합니다. 주요 단계는 다음과 같습니다.
단계 1: Loki에 로그 입력
들어오는 로그에 대한 쓰기는 디스트리뷰터로 전송됩니다. 로그는 레이블(예: {job="nginx", level="error"})과 함께 스트림으로 구성됩니다. 디스트리뷰터는 로그를 분할하고 파티션하며 인제스터로 로그를 보냅니다. 각 스트림의 레이블을 해싱하고 일관된 해싱을 사용하여 인제스터에 할당합니다. 디스트리뷰터는 로그를 확인하고 부적절한 데이터를 방지합니다. 일관된 해싱은 인제스터 간에 일관된 로그 분배를 보장할 수 있습니다.
단계 2: 단기 저장
인제스터는 로그를 빠르게 검색하기 위해 메모리에 저장합니다. 로그는 일괄 처리되어 Write-Ahead Logs (WAL)에 기록되어 데이터 손실을 방지합니다. WAL은 내구성에 도움을 줍니다만 직접 쿼리할 수는 없습니다. 인제스터는 여전히 최근 로그를 쿼리하기 위해 온라인 상태를 유지해야 합니다.
정기적으로 로그는 인제스터에서 객체 저장소로 플러시됩니다. 쿼리어와 룰러는 인제스터를 읽어 가장 최근 데이터에 액세스합니다. 쿼리어는 추가로 객체 저장소 데이터에 액세스할 수 있습니다.
단계 3: 로그가 장기 저장소로 이동
압축기는 주기적으로 장기 저장(object-storage)에 저장된 로그를 처리합니다. 객체 저장소는 저렴하고 확장 가능합니다. 이를 통해 Loki는 높은 비용 없이 대량의 로그를 저장할 수 있습니다. 압축기는 중복 로그를 제거하고 저장 효율성을 위해 로그를 압축하며 보존 설정에 따라 오래된 로그를 삭제합니다. 로그는 청크 형식으로 저장됩니다(전체 텍스트 색인화되지 않음).
읽기
다이어그램 2에서 읽기 경로는 파란색 경로입니다. 쿼리는 쿼리 프론트엔드로 전송되며 쿼리어가 로그를 검색합니다. 로그는 필터링되고 구문 분석되며 LogQL을 사용하여 분석됩니다. 주요 단계는 다음과 같습니다.
단계 1: 쿼리 프론트엔드가 요청을 최적화합니다
사용자는 Grafana에서 LogQL을 사용하여 로그를 쿼리합니다. 쿼리 프론트엔드는 대량의 쿼리를 작은 청크로 분할하고 병렬 실행을 통해 여러 쿼리어에 분산시킵니다. 쿼리 실행을 가속화하고 실패 시 재시도를 보장하는 것이 책임입니다. 쿼리 프론트엔드는 타임아웃과 과부하를 피하도록 도와주며 실패한 쿼리는 자동으로 재시도됩니다.
단계 2: 쿼리어가 로그를 가져옵니다
쿼리어는 LogQL을 구문 분석하고 인게스터 및 객체 저장소에 쿼리를 보냅니다. 최근 로그는 인게스터에서 가져오고 이전 로그는 객체 저장소에서 검색됩니다. 동일한 타임스탬프, 레이블 및 내용을 가진 로그는 중복 제거됩니다.
블룸 필터와 인덱스 레이블을 사용하여 로그를 효율적으로 찾습니다. count_over_time()과 같은 집계 쿼리는 Loki가 로그를 완전히 색인화하지 않기 때문에 더 빨리 실행됩니다. Elasticsearch와 달리 Loki는 전체 로그 내용을 색인화하지 않습니다.
대신, 이는 로그를 효율적이고 저렴하게 찾을 수 있도록 메타데이터 레이블({app="nginx", level="error"})을 색인화합니다. 전체 텍스트 검색은 관련 로그 청크에서만 수행되어 저장 비용을 줄입니다.
LogQL 기본
LogQL은 Grafana Loki에서 사용되는 쿼리 언어로 로그를 효율적으로 검색, 필터링 및 변환하는 데 사용됩니다. 이는 두 가지 주요 구성 요소로 구성됩니다:
- 스트림 선택기 – 레이블 매처를 기반으로 로그 스트림을 선택합니다
- 필터링 및 변환 – 관련 로그 라인을 추출하고 구조화된 데이터를 구문 분석하며 쿼리 결과를 형식화합니다
이러한 기능을 결합하여 LogQL을 사용하면 사용자가 로그를 효율적으로 검색하고 통찰을 추출하며 로그 데이터에서 유용한 메트릭을 생성할 수 있습니다.
스트림 선택기
스트림 선택기는 모든 LogQL 쿼리의 첫 번째 단계입니다. 레이블 매처를 기반으로 로그 스트림을 선택합니다. 쿼리 결과를 특정 로그 스트림으로 정밀 조정하려면 Loki 레이블로 필터링하는 기본 연산자를 사용할 수 있습니다. 로그 스트림 선택의 정밀성을 향상시킴으로써 스캔되는 스트림의 양을 최소화하여 쿼리 속도를 높일 수 있습니다.
예시
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend job라인 필터
로그가 선택된 후 라인 필터는 특정 텍스트를 검색하거나 논리적 조건을 적용하여 결과를 정제합니다. 라인 필터는 레이블이 아닌 로그 콘텐츠에서 작동합니다.
예시
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)파서
로키는 비구조화, 반구조화 또는 구조화된 로그를 수용할 수 있습니다. 그러나 작업 중인 로그 형식을 이해하는 것은 관측 가능성 솔루션을 설계하고 구축할 때 중요합니다. 이렇게 함으로써 로그 데이터를 효과적으로 수집, 저장 및 구문 분석할 수 있습니다. 로키는 JSON, logfmt, pattern, regexp 및 unpack 파서를 지원합니다.
예시
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codes라벨 필터
파싱된 후 추출된 필드로 로그를 필터링할 수 있습니다. 라벨은 파서 및 형식 지정기 식을 사용하여 로그 파이프라인의 일부로 추출될 수 있습니다. 그런 다음 라벨 필터 식을 사용하여 이러한 라벨 중 하나로 로그 라인을 필터링할 수 있습니다.
예시
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=admin라인 형식
필드를 추출하고 형식을 지정하여 로그 출력을 수정하는 데 사용됩니다. 이는 로그가 Grafana에 표시되는 방식을 형식화합니다.
예시
{app="nginx"} | json | line_format "User {user} encountered {status} error"라벨 형식
라벨을 이름 바꾸거나 수정, 생성 또는 삭제하는 데 사용됩니다. 등호 연산의 쉼표로 구분된 목록을 수용하여 여러 작업을 동시에 수행할 수 있습니다.
예시
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level 타협점
Grafana Loki은 압축된 청크에 로그를 저장하고 최소한의 색인화로 비용 효율적이고 확장 가능한 로깅 솔루션을 제공합니다. 이는 쿼리 성능 및 검색 속도에서 타협점을 가지고 있습니다. 로그의 전체 내용을 인덱싱하는 전통적인 로그 관리 시스템과 달리, Loki의 라벨 기반 색인화는 필터링 속도를 높입니다.
그러나 복잡한 텍스트 검색을 느리게 할 수 있습니다. 또한 Loki는 고처리량 분산 환경을 처리하는 데 뛰어나지만 확장성을 위해 객체 저장소에 의존합니다. 이로 인해 지연이 발생할 수 있으며 높은 카디널리티 문제를 피하기 위해 신중한 레이블 선택이 필요할 수 있습니다.
확장성 및 다중 테넌시
Loki는 확장성과 다중 테넌시를 고려하여 설계되었습니다. 그러나 확장성은 아키텍처적 트레이드 오프와 함께 제공됩니다. 기록 쓰기(인제스터)를 확장하는 것은 레이블 기반 파티셔닝을 통해 로그를 샤드화할 수 있기 때문에 간단합니다. 그러나 객체 저장소에서 대량의 데이터 질의를 수행하는 것은 느릴 수 있으므로 기록 읽기(쿼리어)를 확장하는 것은 조금 까다롭습니다. 다중 테넌시는 지원되지만 테넌트별 할당량, 레이블 확산 및 보안(테넌트 데이터 격리)을 관리하려면 신중한 구성이 필요합니다.
사전 구문 분석 없는 간단한 적재
Loki는 전체 로그 내용을 색인화하지 않기 때문에 사전 구문 분석이 필요하지 않습니다. 그것은 압축된 청크 형식으로 로그를 저장합니다. Loki는 전체 텍스트 색인화가 없기 때문에 구조화된 로그(e.g., JSON)를 질의하기 위해서는 LogQL 구문 분석이 필요합니다. 이는 적재 전 로그가 얼마나 잘 구조화되어 있는지에 따라 질의 성능이 달라짐을 의미합니다. 구조화된 로그가 없으면 쿼리 효율이 떨어지게 되며 필터링은 적재 시간이 아닌 검색 시간에 발생해야 합니다.
객체 저장소에 저장하기
Loki는 로그 청크를 객체 저장소(e.g., S3, GCS, Azure Blob)에 플러시합니다. 이는 Elasticsearch와 같은 비싼 블록 저장소에 대한 종속성을 줄입니다.
그러나 객체 저장소에서 로그를 읽는 것은 데이터베이스에서 직접 쿼리하는 것에 비해 느릴 수 있습니다. Loki는 최신 로그를 인젝터에 유지하여 더 빠른 검색을 위해 보상합니다. 병합은 저장 공간을 줄이지만 대규모 쿼리의 경우 로그 검색 지연 문제가 발생할 수 있습니다.
라벨과 카디널리티
라벨은 로그 검색에 사용되기 때문에 효율적인 쿼리를 위해 중요합니다. 잘못된 라벨링은 높은 카디널리티 문제로 이어질 수 있습니다. 높은 카디널리티 라벨(user_id, session_id 등)을 사용하면 메모리 사용량이 증가하고 쿼리가 느려집니다. Loki는 라벨을 해시하여 로그를 인젝터에 분산시키기 때문에 잘못된 라벨 설계는 불균형한 로그 분배를 일으킬 수 있습니다.
초기 필터링
Loki는 객체 저장소에 압축된 원시 로그를 저장하기 때문에 쿼리가 빠르게 실행되길 원한다면 초기에 필터링하는 것이 중요합니다. 작은 데이터 세트에서 복잡한 구문 분석을 처리하면 응답 시간이 증가합니다. 이 규칙에 따르면 좋은 쿼리는 쿼리 1이고, 나쁜 쿼리는 쿼리 2입니다.
쿼리 1
{job="nginx", status_code=~"5.."} | json쿼리 1은 job="nginx"이고 status_code가 5로 시작하는(500-599 오류) 로그를 필터링합니다. 그런 다음 | json을 사용하여 구조화된 JSON 필드를 추출합니다. 이렇게 하면 JSON 파서에서 처리하는 로그 수가 줄어들어 더 빨라집니다.
쿼리 2
{job="nginx"} | json | status_code=~"5.."쿼리 2는 먼저 nginx에서 모든 로그를 검색합니다. 이는 수백만 개의 항목일 수 있습니다. 그런 다음 각 로그 항목에 대해 status_code를 필터링하기 전에 JSON을 구문 분석합니다. 이는 비효율적이며 상당히 느립니다.
마무리
Grafana Loki는 확장성과 단순성을 위해 설계된 강력하고 비용 효율적인 로그 집계 시스템입니다. 메타데이터만 인덱싱하여 저장 비용을 낮추면서 LogQL을 사용하여 빠른 쿼리를 가능하게 합니다.
그의 마이크로서비스 아키텍처는 유연한 배포를 지원하여 클라우드 네이티브 환경에 적합합니다. 이 기사는 Loki의 기본 사항과 쿼리 언어에 대해 다루었습니다. Loki 아키텍처의 주요 기능을 탐색함으로써 관련된 트레이드오프를 더 잘 이해할 수 있습니다.
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture