













2024년 12월 11일, OpenAI 서비스는 새로운 텔레메트리 서비스 배포에서 발생한 문제로 인해 상당한 다운타임을 경험했습니다. 이 사건은 API, ChatGPT 및 Sora 서비스에 영향을 미쳐 몇 시간에 걸쳐 지속되는 서비스 중단을 초래했습니다. 정확하고 효율적인 AI 솔루션을 제공하기를 목표로 하는 회사로서, OpenAI는 무엇이 잘못되었는지에 대해 공개적으로 논의하고 앞으로 이와 유사한 사건을 예방하는 방법에 대해 상세한 사후 분석 보고서를 공유했습니다.
본 문서에서는 사건의 기술적 측면을 설명하고 근본적인 원인을 분석하며, 분산 시스템을 관리하는 개발자와 조직이 이 사건에서 얻을 수 있는 주요 교훈을 탐구할 것입니다.
사건 타임라인
2024년 12월 11일 사건의 경과를 간략히 살펴보면 다음과 같습니다:
| Time (PST) | Event |
|---|---|
| 오후 3:16 |
소규모 고객 영향 발생; 서비스 저하 관측됨 |
| 오후 3:27 | 영향을 받는 클러스터로의 트래픽 리디렉션 시작 |
| 오후 3:40 | 최대 고객 영향 기록; 모든 서비스에서 주요 중단 발생 |
| 오후 4:36 | 첫 번째 Kubernetes 클러스터가 복구 시작 |
| 오후 5:36 | API 서비스의 상당한 복구 시작 |
| 오후 5:45 | ChatGPT의 상당한 복구 관측됨 |
| 오후 7:38 | 모든 클러스터에서 모든 서비스 완전히 복구됨 |
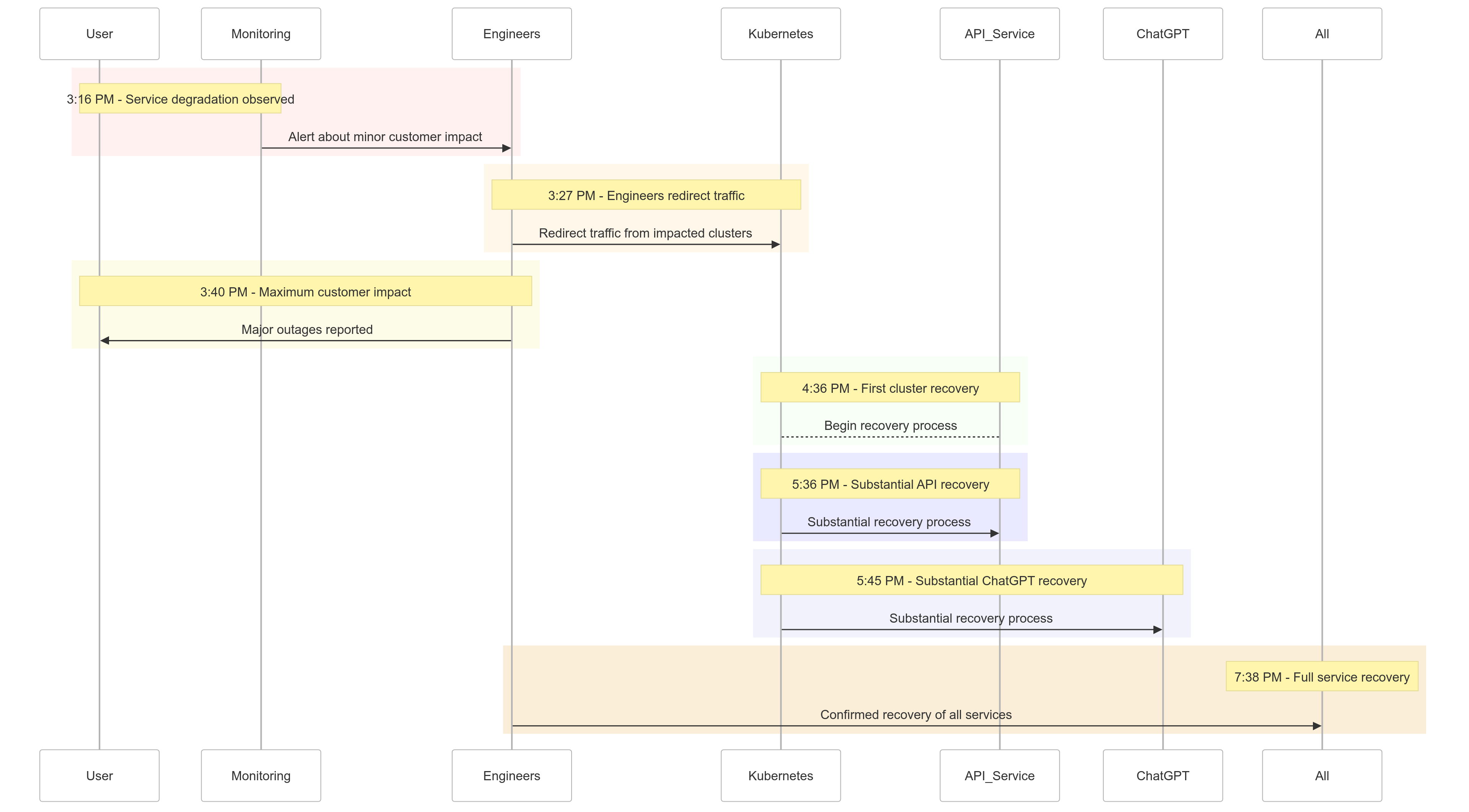
그림 1: OpenAI 사건 타임라인 – 서비스 저하부터 완전 복구까지.
근본 원인 분석
사건의 근본 원인은 Kubernetes 제어 평면의 관측 가능성을 향상시키기 위해 오후 3시 12분 PST에 배포된 새로운 텔레메트리 서비스에 있었습니다. 이 서비스가 여러 클러스터에 걸쳐 Kubernetes API 서버를 압도하여 연쇄적인 장애로 이어졌습니다.
분해하기
텔레메트리 서비스 배포
텔레메트리 서비스는 자세한 Kubernetes 제어 평면 메트릭을 수집하기 위해 설계되었지만, 그 구성이 의도치 않게 수천 개의 노드에 동시에 리소스 집약적인 Kubernetes API 작업을 트리거했습니다.
과부하된 제어 평면
클러스터 관리를 담당하는 Kubernetes 제어 평면이 과부하를 받았습니다. 사용자 요청 처리를 담당하는 데이터 평면은 일부 기능을 유지했지만, DNS 해결을 위해 제어 평면에 의존했습니다. 캐시된 DNS 레코드가 만료되면 실시간 DNS 해결에 의존하는 서비스가 실패하기 시작했습니다.
불충분한 테스트
배포는 스테이징 환경에서 테스트되었지만, 스테이징 클러스터는 프로덕션 클러스터의 규모를 반영하지 않았습니다. 결과적으로 API 서버 부하 문제가 테스트 중 감지되지 않았습니다.
문제 완화 방법
사건이 시작되었을 때 OpenAI 엔지니어들은 빠르게 근본 원인을 파악했지만, 과부하로 인해 Kubernetes 제어 평면에 접근할 수 없어서 수정을 구현하는 데 어려움을 겪었습니다. 다각적인 접근 방식이 채택되었습니다:
- 클러스터 크기 축소: 각 클러스터의 노드 수를 줄이면 API 서버의 부하가 감소했습니다.
- Kubernetes 관리자 API에 대한 네트워크 접근 차단: 추가 API 요청을 방지하여 서버가 복구할 수 있도록 했습니다.
- Kubernetes API 서버 확장: 추가 리소스를 프로비저닝하여 보류 중인 요청을 처리할 수 있었습니다.
이러한 조치 덕분에 엔지니어들은 제어 평면에 대한 접근을 다시 확보하고 문제의 원인인 텔레메트리 서비스를 제거하여 서비스 기능을 복원할 수 있었습니다.
교훈
이번 사건은 분산 시스템에서 강력한 테스트, 모니터링, 및 장애 안전 메커니즘의 중요성을 강조합니다. OpenAI가 이번 중단 사태에서 배운 점은 다음과 같습니다:
1. 강력한 단계적 롤아웃
모든 인프라 변경 사항은 이제 단계적 롤아웃에 따라 지속적인 모니터링을 진행합니다. 이를 통해 문제가 조기에 발견되고 전체 시스템에 확장되기 전에 완화될 수 있습니다.
2. 결함 주입 테스트
제어 평면 비활성화 또는 잘못된 변경 사항 롤아웃과 같은 실패를 시뮬레이션함으로써 OpenAI는 시스템이 자동으로 복구할 수 있는지 확인하고 고객에게 영향을 미치기 전에 문제를 탐지할 것입니다.
3. 긴급 제어 평면 접근
“브레이크 글래스” 메커니즘을 통해 엔지니어는 높은 부하가 걸린 상황에서도 Kubernetes API 서버에 접근할 수 있습니다.
4. 제어 평면과 데이터 평면의 분리
의존성을 줄이기 위해 OpenAI는 Kubernetes 데이터 평면 (작업 부하 처리)과 제어 평면 (오케스트레이션 담당)을 분리하여, 제어 평면 장애가 발생하더라도 중요한 서비스가 계속 실행될 수 있도록 합니다.
5. 더 빠른 복구 메커니즘
새로운 캐싱 및 속도 제한 전략이 클러스터 시작 시간을 개선하여 장애 발생 시 더 빠른 복구를 보장합니다.
샘플 코드: 단계적 롤아웃 예제
Kubernetes에 대한 단계적 롤아웃을 Helm과 Prometheus를 사용하여 구현하는 예제입니다.
단계적 롤아웃을 통한 Helm 배포:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
API 서버 부하 모니터링을 위한 Prometheus 쿼리:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
이 쿼리는 API 서버 요청에 대한 응답 시간을 추적하여 부하 급증을 조기에 탐지하는 데 도움을 줍니다.
장애 주입 예제
OpenAI는 chaos-mesh를 사용하여 Kubernetes 제어 평면의 장애를 시뮬레이션할 수 있습니다.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
이 구성은 시스템의 복원력을 확인하기 위해 API 서버 포드를 의도적으로 종료합니다.
이것이 당신에게 의미하는 바
이 사건은 탄력 있는 시스템을 설계하고 엄격한 테스트 방법론을 채택하는 중요성을 강조합니다. 규모 확장형 분산 시스템을 관리하거나 워크로드에 Kubernetes를 구현하고 있는 경우, 여기 몇 가지 교훈이 있습니다:
- 정기적으로 장애 시뮬레이션: Chaos Mesh와 같은 혼돈 공학 도구를 사용하여 시스템의 강건성을 실제 조건 하에서 테스트하십시오.
- 여러 수준에서 모니터링: 서비스 수준 메트릭과 클러스터 상태 메트릭을 모두 추적하는 가시성 스택을 보장하십시오.
- 핵심 의존성 분리: DNS 기반 서비스 검색과 같은 단일 장애 지점에 대한 의존성을 줄이십시오.
결론
어떤 시스템도 장애에 면역이 되지는 않지만, 이와 같은 사건은 우리에게 투명성, 신속한 조치, 그리고 계속적인 학습의 가치를 상기시켜 줍니다. OpenAI의 사후 분석을 공유하는 적극적인 접근은 다른 조직들이 운영 관행과 신뢰성을 개선하는데 도움이 되는 청사진을 제공합니다.
강화된 단계적 롤아웃, 결함 삽입 테스트, 그리고 탄력 있는 시스템 설계를 우선시함으로써, OpenAI는 대규모 장애로부터 어떻게 대처하고 학습하는지에 대한 강력한 예를 제시하고 있습니다.
분산 시스템을 관리하는 팀들에게, 이 사건은 리스크 관리에 접근하고 핵심 비즈니스 프로세스의 다운타임을 최소화하는 방법에 대한 좋은 사례 연구입니다.
우리는 함께 더 나은, 더 탄력 있는 시스템을 구축하는 기회로 삼아야 합니다.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident