













소개
이 글에서는 LeNet5라는 最早に導入された convolutional neural networks(CNN) 중 하나를 構築할 것입니다. PyTorch를 사용하여 이 CNN을 Ground Zero에서 시작하여, 실제 세계의 데이터셋에 대해 其의 パフォーマン스를 보실 수 있습니다.
LeNet5의 구조를 이해하기 위해 시작하고, 제공하는 torchvision クラス을 사용하여 MNIST 데이터셋을 로드하고 분석하겠습니다. PyTorch를 사용하여 LeNet5을 Ground Zeroから 構築하고 我们的 데이터에 기반하여 トレーニング하고, 결국 見た적이 없는 테스트 데이터에 대한 모델의 パフォーマン스를 보여줍니다.
사전 요구 사항
이 글을 이해하기 위해서는 Neural networks의 知識가 도움이 됩니다. 이는 신경망의 다양한 层次(input layer, hidden layers, output layer)과 활성화 함수, 最適化 알고리즘(gradient descent의 варианты), 손실 函數 등을 熟悉하다는 것을 意味합니다. 加えて Python 문법과 PyTorch 라이브러리를 熟悉하는 것은 이 글에서 보여지는 コード スニペット을 이해하기 위해 不可或缺합니다.
CNNs(Convolutional Neural Networks)의 이해도가 필요합니다. 이것은 컨볼루켄 层层, 풀링 层层의 roll in 입력 데이터에서 특징을 추출하는 역할을 이해하는 것을 포함합니다. 스트라이드, 패딩과 内核/필터 크기의 영향을 이해하는 것이 유용합니다.
LeNet5
LeNet5는 手写字体認識에 사용되었으며, Yann LeCun과 다른 사람들이 1998年に 论文, Gradient-Based Learning Applied to Document Recognition에서 제안했습니다.
下面的 그림에 보여지는 LeNet5의 아키텍처에 대해 이해해봅시다:
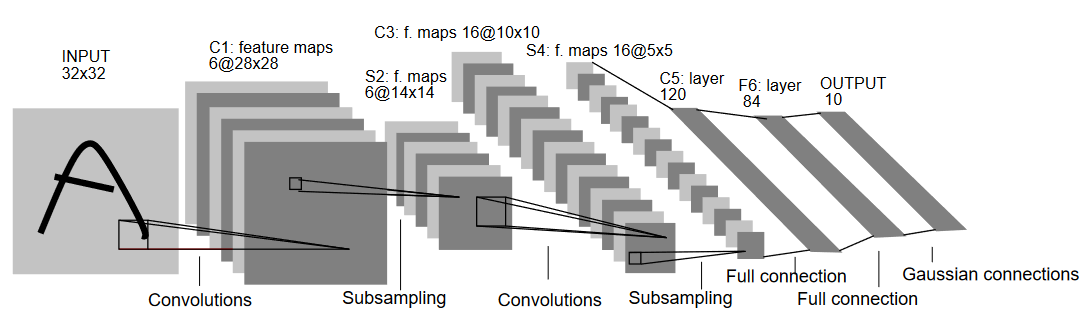
이름에 照らして, LeNet5는 5层로 두 개의 컨볼루켄 层层, 세 개의 완전히 연결 层层을 가지고 있습니다. 시작하자 입력에서 LeNet5는 32×32 그리yscale 이미지를 입력받습니다. 이는 아키텍처가 RGB 이미지(다수의 채널)에 적용되지 않는다는 것을 나타냅니다. 따라서 입력 이미지는 한 채널만 있어야 합니다. 이후, 우리는 컨볼루켄 层层을 시작합니다.
첫 번째 컨볼루켄 层层은 5×5 크기의 필터를 6개의 필터로 가지며, 이는 이미지의 너비와 높이를 减小하면서 깊이(채널 수)를 increase 합니다. 이 출력은 28x28x6가 됩니다. 이 다음, 풀링 层层을 적용하여 특징 맵을 절반으로 减小하는 것이므로, 14x14x6가 됩니다. 같은 필터 크기(5×5)의 16개의 필터를 출력에 적용하고 다음 풀링 层层을 적용합니다. 이것은 출력 특징 맵을 5x5x16로 减小합니다.
이 이후, 120개의 필터를 갖는 5×5 convolutional layer를 적용하여 特徴 맵을 120個의 값으로 壓平합니다. 그 다음 첫 번째 완전 연결 層(fully connected layer)이 도입되며, 84개의 Neuron을 갖고 있습니다. 마지막으로, MNIST 데이터는 각 10개의 숫자 기호를 나타내는 10개의 클래스가 있기 때문에 10개의 输出行 neuron의 output layer가 있습니다.
Data Loading
우선 데이터를 로드하고 분석해봅시다. 우리는 MNIST 데이터셋을 사용하겠습니다. MNIST 데이터셋은 手写的 숫자 기호의 이미지가 들어있습니다. 이미지는 그레이 스케일로, 모두 28×28의 사이즈로 구성되며, 60,000개의 트레이닝 이미지와 10,000개의 시험 이미지로 구성되어 있습니다.
아래와 같이 이미지 샘플을 볼 수 있습니다:

Importing the Libraries
우선 필요한 라이브러리를 導入하고 一些 변수(hyerparameters과 device는 에서도 详しく 기술되어 包包 로직에 따라 GPU 또는 CPU에서 트레이닝을 할지 결정하기 위해 도움이 됩니다):
# 相應한 라이브러리를 로드하고 적절한 별칭을 지정합니다
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# ML 任务에 대한 相关한 変수를 정의합니다
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# Device는 트레이닝을 GPU 또는 CPU로 실행할지 결정하는 것입니다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
데이터 로ading 및 변환
torchvision 를 사용하여 dataset을 로드하我们将允许我们轻松执行任何预处理步骤。
#dataset 로ading 및 전처리
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
코드에 대해 이해하让我们理解一下代码:
- 首に、MNIST 데이터는 LeNet5 아키텍처에서 사용할 수 없습니다. LeNet5 아키텍처는 32×32의 입력을 받습니다. MNIST 이미지는 28×28입니다. 이를 수정하는 것은 이미지를 리사이징하고, 사이트에서 사용할 수 있는 미분산과 표준편차를 사용하여 정규화하고, 결국 tensor로 저장합니다.
- 我们设置
download=True인 경우에 데이터가 이미 다운로드되지 않았습니다. - 次に、dataset loaders를 사용합니다. MNIST과 같은 작은 dataset일 때 performance에 영향을 미칠 것이 없지만, 대규모 dataset에서는 실제로 성능에 영향을 미칠 수 있으며, 일반적으로 좋은 慣例입니다. Data loaders는 우리가 dataset을 배치 단위로 이룰 수 있게 해줍니다. 이는 시작할 때 한번에 로드되지 않고, 이를 이용하여 iterate dataset while iterating and not at once in start.
- batch size를 지정하고, 로드할 때 dataset을 shuffle하여 모든 batch가 어느 程度의 이미지 유형의 변异性를 가지도록 합니다. 이렇게 하면 우리의 결국적인 model의 효과를 높여줍니다.
스크래치로 LeNet5
우선 코드를 살펴보자:
# 卷積 신경망 정의
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
LeNet5 모델 정의
코드를 선형적으로 설명하겠습니다:
- PyTorch에서는 신경망을 정의할 때
nn.Module를 계승하는 클래스를 생성하게 됩니다. 필요로 하는 많은 메서드들이 포함되어 있기 때문입니다. - 그 후에는 주요한 두 가지 단계가 있습니다. 첫 번째는 우리의 CNN에서 사용할 계층을
__init__안에서 초기화하는 것이고, 두 번째는 그 계층들이 이미지를 처리하는 순서를 정의하는 것입니다. 이는forward함수 안에서 정의됩니다. - 아키텍처 자체를 보면, 우선
nn.Conv2D함수를 사용하여 적절한 커널 크기와 입/출력 채널로 卷積 계층을 정의합니다. 또한nn.MaxPool2D함수를 사용하여 최대 풀링을 적용합니다. PyTorch의 좋은 점은 卷積 계층, 활성화 함수, 최대 풀링을 하나의 계층으로 결합할 수 있다는 것입니다.nn.Sequential함수를 사용해서입니다. (각각 별도로 적용되지만, 구성을 돕습니다.) - 결합 层层(Fully Connected Layers)를 정의합니다. 여기에
nn.Sequential을 사용할 수 있으며, 활성화 함수와 선형 层层을 조합하여 사용할 수 있지만, 이를 보여주기 위해서는 어느 것도 가능하다는 것을 보여주고자 합니다. - 결국, 마지막 层层은 10개의 神经元(neurons)를 출력하며, 숫자의 결과적 예측입니다.
하이퍼 파라미터 세팅
훈련 전에 一些 하이퍼 파라미터를 설정해야 합니다. 예를 들어 손실 函數(loss function)과 사용할 오timizer를 정의합니다.
model = LeNet5(num_classes).to(device)
# 손실函數 설정
cost = nn.CrossEntropyLoss()
# 오timizer 설정
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 이 부분은 훈련 과정 中에 몇 단계가 남았는지 출력합니다.
total_step = len(train_loader)
우선, 이 경우 10개의 클래스를 인자로 모델을 초기화합니다. 그리고 我们的 비용 函數을 交叉 엔ropy 손실(cross entropy loss)로 정의하고, 오timizer를 Adam로 정의합니다. 이러한 것들은 많은 선택이 있지만, 이들은 모델과 given 데이터를 보다 좋은 결과를 얻을 수 있습니다. 마지막으로, total_step를 정의하여 훈련 과정 中의 단계를 更好的 추적할 수 있습니다.
모델 훈련
이제, 우리의 모델을 훈련할 수 있습니다:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# 전파(Forward Pass)
outputs = model(images)
loss = cost(outputs, labels)
# 역전파 및 최적화(Backward and Optimize)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
코드가 무엇을 하는지 보겠습니다:
- 우리는 에poch의 수를 통해 iterate하고, 그 다음에 我们的 training data에서 batch를 뽑습니다.
- 이미지와 레이블을 우리가 사용하는 장치에 따라 변환합니다. 즉, GPU나 CPU입니다.
- forward pass에서, 우리의 model을 사용하여 예측을 하고, 우리의 실제 레이블과 那些 예측에 기반하여 loss를 계산합니다.
- 다음으로, backward pass를 하여 우리의 가중치를 改善하기 위해 실제로 更新합니다.
- 그 다음,
optimizer.zero_grad()함수를 사용하여 更新하기 전에 가중치를 zero하는 것을 합니다. loss.backward()함수를 사용하여 새로운 가중치를 계산합니다.- 결국,
optimizer.step()함수를 사용하여 가중치를 업데이트합니다.
우리는 다음과 같은 출력을 보을 수 있습니다:
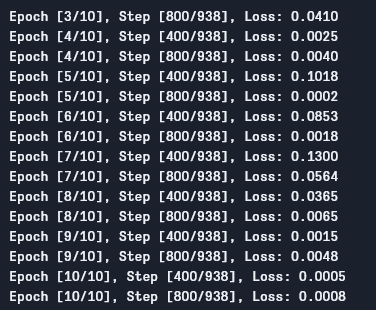
如图所见, 随着 every epoch, loss가 감소하는 것을 보여줍니다. 이는 우리의 model가 indeed learning하고 있음을 보여줍니다. 이 loss는 训练 셋에 대해 있으며, loss가 너무 작은 것(our case에서)을 보면 overfitting을 나타냅니다. 그것을 해결하는 다양한 方法이 있습니다. 例如, regularization, data augmentation 等等 하지만, 이 글에서는 그것들에 대해 들어가지 않을 것입니다. 이제, 우리의 model을 테스트하여 그것이 어떻게 perform하는지 보겠습니다.
Model Testing
이제, 우리의 model을 테스트하자:
# 테스트 모델
# 테스트 단계에서는 그라디언트를 계산할 필요가 없습니다 (메모리 효율성을 위해)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
보시다시피, 코드는 훈련 때 사용했던 것과 크게 다르지 않습니다. 유일한 차이점은 그라디언트를 계산하지 않고 있으며 (with torch.no_grad()를 사용하여), 손실을 계산하지도 않는 것입니다. 여기서 역전파를 하지 않아서요. 모델의 결과적인 정확도를 계산하려면, 이미지 전체 수에 대한 올바른 예측의 총 수를 간단하게 계산할 수 있습니다.
이 모델을 사용하면 약 98.8%의 정확도를 얻을 수 있어서 꽤 좋습니다:

테스트 정확도
MNIST 데이터셋은 현재의 표준에 비해 상당히 기본적이고 작습니다. 비슷한 결과를 다른 데이터셋에서 얻기는 어렵습니다. 그러나, 딥러닝과 CNN을 배울 때 좋은 시작점입니다.
결론
이 글에서 우리가 했던 것을 요약해봅시다:
- LeNet5의 아키텍처와 그 안의 다양한 종류의 레이어를 배우기 시작했습니다.
- 그 다음, MNIST 데이터셋을 탐색하고
torchvision을 사용하여 데이터를 로드했습니다. - 그리고, 모델의 하이퍼파라미터를 정의하면서 LeNet5를 처음부터 빌드했습니다.
- 결국, MNSIT 데이터셋에 我们的 모델을 训练 및 시험하였고, 모델은 시험 데이터셋에서 좋은 성능을 보였다.
未来的工作
이것은 PyTorch에서 深层学习의 실� 인TR을 보는 것 같은 것 뿐만 아니라, 이 작업을 확장하여 더 많은 것을 배울 수 있습니다.:
- 다른 데이터셋을 시도하는 것을 시도할 수 있지만, 이 모델에서는 그레이 스케일 데이터셋이 필요합니다. 이러한 데이터셋 중 하나는 FashionMNIST입니다.
- 다른 하이퍼 파라미터를 실험하여 이 모델에 대해 가장 좋은 조합을 보기 위해서는 할 수 있습니다.
- 결국, 이 데이터셋에서 层层를 추가하거나 제거하여 그들이 모델의 능력에 영향을 미칠 것을 확인할 수 있습니다.
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python