













Scikit Learn
 Scikit-learn은 Python용 머신 러닝 라이브러리입니다. 이는 SVM, 그라디언트 부스팅, k-평균, 랜덤 포레스트 및 DBSCAN을 포함한 여러 회귀, 분류 및 클러스터링 알고리즘을 제공합니다. 이는 Python Numpy 및 SciPy와 함께 작동하도록 설계되었습니다. Scikit-learn 프로젝트는 scikits.learn으로 알려진 David Cournapeau에 의한 Google Summer of Code(GSoC) 프로젝트로 시작되었습니다. “Scikit”이라는 이름은 SciPy의 별도의 타사 확장에서 유래했습니다.
Scikit-learn은 Python용 머신 러닝 라이브러리입니다. 이는 SVM, 그라디언트 부스팅, k-평균, 랜덤 포레스트 및 DBSCAN을 포함한 여러 회귀, 분류 및 클러스터링 알고리즘을 제공합니다. 이는 Python Numpy 및 SciPy와 함께 작동하도록 설계되었습니다. Scikit-learn 프로젝트는 scikits.learn으로 알려진 David Cournapeau에 의한 Google Summer of Code(GSoC) 프로젝트로 시작되었습니다. “Scikit”이라는 이름은 SciPy의 별도의 타사 확장에서 유래했습니다.
Python Scikit-learn
Scikit은 주로 Python으로 작성되었으며 일부 핵심 알고리즘은 더 나은 성능을 위해 Cython으로 작성되었습니다. Scikit-learn은 모델을 구축하는 데 사용되며 데이터의 읽기, 조작 및 요약에는 목적에 더 적합한 프레임워크가 있으므로 해당 용도에 사용하지 않는 것이 좋습니다. 이는 오픈 소스이며 BSD 라이선스로 배포됩니다.
Scikit Learn 설치
Scikit은 디바이스에 NumPY (1.8.2 이상)와 SciPY (0.13.3 이상) 패키지가 설치된 실행 중인 Python 2.7 이상 플랫폼을 전제로 합니다. 이러한 패키지들이 설치되어 있다고 가정하고 설치를 진행할 수 있습니다. pip를 사용하여 설치하는 경우 터미널에서 다음 명령을 실행하십시오:
pip install scikit-learn
만약 conda를 선호한다면, 다음 명령을 사용하여 conda를 통해 패키지를 설치할 수도 있습니다:
conda install scikit-learn
Scikit-Learn 사용하기
설치가 완료되면, 다음과 같이 scikit-learn을 Python 코드에서 손쉽게 사용할 수 있습니다:
import sklearn
Scikit Learn 데이터셋 불러오기
데이터셋을 불러와서 사용해 보겠습니다. 간단한 데이터셋인 Iris를 로드해 봅시다. 이는 꽃에 관한 데이터셋으로, 꽃의 다양한 측정에 대한 150개의 관측치가 포함되어 있습니다. scikit-learn을 사용하여 데이터셋을 로드하는 방법을 살펴보겠습니다.
# scikit learn 가져오기
from sklearn import datasets
# 데이터 로드
iris= datasets.load_iris()
# 데이터가 로드되었는지 확인하기 위해 데이터 모양 출력
print(iris.data.shape)
편의를 위해 데이터 모양을 출력하고 있습니다. 원한다면 전체 데이터를 출력할 수도 있으며, 코드를 실행하면 다음과 같은 출력이 나타납니다: 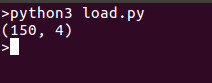
Scikit Learn SVM – 학습 및 예측
이제 데이터를 로드했으니 학습하고 새로운 데이터에 대해 예측해 봅시다. 이를 위해 추정기를 만들고 그 fit 메서드를 호출해야 합니다.
from sklearn import svm
from sklearn import datasets
# 데이터셋 로드
iris = datasets.load_iris()
clf = svm.LinearSVC()
# 데이터에서 학습
clf.fit(iris.data, iris.target)
# 보이지 않는 데이터에 대해 예측
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# 모델 매개변수는 밑줄로 끝나는 속성을 사용하여 변경할 수 있습니다
print(clf.coef_ )
이 스크립트를 실행하면 다음과 같은 결과가 나옵니다: 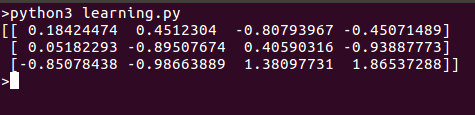
Scikit Learn 선형 회귀
scikit-learn을 사용하여 여러 모델을 만드는 것은 상당히 간단합니다. 간단한 회귀 예제로 시작해 보겠습니다.
#import 모델
from sklearn import linear_model
reg = linear_model.LinearRegression()
# 사용하여 데이터 피팅
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# 피팅된 데이터를 살펴보겠습니다
print(reg.coef_)
모델 실행 시 동일한 선 상에 플로팅할 수 있는 점을 반환해야 합니다: 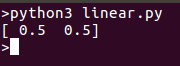
k-Nearest neighbour classifier
간단한 분류 알고리즘을 시도해 봅시다. 이 분류기는 훈련 샘플을 나타내기 위해 볼 트리를 기반으로 한 알고리즘을 사용합니다.
from sklearn import datasets
# 데이터셋 로드
iris = datasets.load_iris()
# 최근접 이웃 분류기 생성 및 피팅
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# 예측 및 결과 출력
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
분류기를 실행하고 결과를 확인해 봅시다. 분류기는 0을 반환해야 합니다. 예제를 시도해 봅시다: 
K-means clustering
이것은 가장 간단한 클러스터링 알고리즘입니다. 세트는 ‘k’ 클러스터로 나뉘며 각 관측값은 클러스터에 할당됩니다. 클러스터가 수렴할 때까지 이를 반복합니다. 다음 프로그램에서 이러한 클러스터링 모델을 만들어 보겠습니다:
from sklearn import cluster, datasets
# 데이터 로드
iris = datasets.load_iris()
# k=3에 대한 클러스터 생성
k=3
k_means = cluster.KMeans(k)
# 데이터 피팅
k_means.fit(iris.data)
# 결과 출력
print( k_means.labels_[::10])
print( iris.target[::10])
프로그램을 실행하면 목록에서 별도의 클러스터가 표시됩니다. 위 코드 스니펫에 대한 출력은 다음과 같습니다: 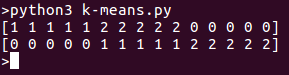
결론
{
“error”: “Upstream error…”
}
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial