













あなたの組織の運営時間中に、重要な仮想マシンとそれら上で実行されている重要なサービスの可用性を確保する必要があります。高可用性を実現する方法の1つは、クラスターを使用してサービスやアプリケーションの連続実行を保証することです。
VMware vSphere仮想化プラットフォームを使用すると、仮想マシン(VM)を実行するためのクラスターを使用し、vSphere High Availability(HA)を使用できます。このブログ投稿では、VMware vSphere HA構成について説明し、構成するパラメータについてご紹介します。
VMware vSphereのHAとは何ですか?
VMware High Availability(HA)は、VMware vSphere仮想マシン、およびVM上で実行されているアプリケーションやサービスの最適な可用性を提供し、障害が発生した場合のダウンタイムを最小限に抑える機能です。高可用性(HA)、またはホスト障害に耐える仮想環境の能力は、VMware vCenterとクラスターを展開することを選択する重要な理由の1つであり、スタンドアロンVMware ESXiホストとは対照的です。
HAがVMwareクラスターで実行されている場合、クラスターに参加している各ホストにエージェントがインストールされます。各ホストエージェントは他のホストと通信し、ハートビートを介してクラスター内のホストの到達可能性を監視します。特定のホストからのハートビートの受信がない状態が15秒間続くと、そのホストへのピングも失敗すると、そのホストは障害として宣言されます。障害のあるホストのコンピューティング/メモリリソースで実行されているVMは、健全なホストにフェールオーバーされ、そのホストで再起動されます。
vSphereのHAは、ホストのハードウェアの健康状態を監視して、ハードウェアの問題を持つホストからVMを積極的に移動します。HAには再起動の優先順位やオーケストレーションも組み込まれており、その結果、フェールオーバーの際に指定されたVMが他のVMよりも先にオンラインになります。これらの機能は、VMware vSphere 6.7およびvSphere 7のバージョンで利用可能です。
VMwareクラスターの要件
VMwareは、HAが有効になっているVMwareクラスターを作成するためのいくつかの要件を定めています。これらの要件には、次のものが含まれます。
- HAクラスターのホストはvSphere HAのためにライセンスが必要です。VMware vSphere StandardまたはEnterprise Plus、およびvCenter Standardライセンスが適用されている必要があります。
- HAを有効にするには、2つのホストが必要です。3つ以上のホストが推奨されています。
- 各ホストに設定された静的IPアドレスは最善の方法です。
- ホスト全体で共通の管理ネットワークが少なくとも1つ必要です。
- クラスタ内の異なるホストに移動された場合、VMがすべてのホストで実行されるようにするには、ホストに同じネットワークとデータストアが設定されている必要があります。
- HAには共有ストレージが必要です。
- VMware ToolsはHAで監視されているVMで実行される必要があります。
VMware HA構成ステップバイステップ
クラスタを作成する際または既にクラスタを作成した場合にVMware HAを有効にできます。このvSphere HA構成の手順では、高可用性の構成に焦点を当て、すでに作成されたクラスタを使用します。VMware HA構成の手順をステップバイステップで説明するためにVMware vSphere 7を使用します。
VMware vSphereでHAを有効にする方法
既存のクラスタでVMware vSphereでHAを有効にするには、以下の手順を実行してください:
- WebブラウザでVMware vSphere Clientを開きます。
- ホストとクラスタに移動し、クラスタに移動します。
- ナビゲータペインでクラスタ名を右クリックします。
- 設定をクリックしてください。
- クラスターのサービスセクションでvSphere可用性を構成ページで選択してください。
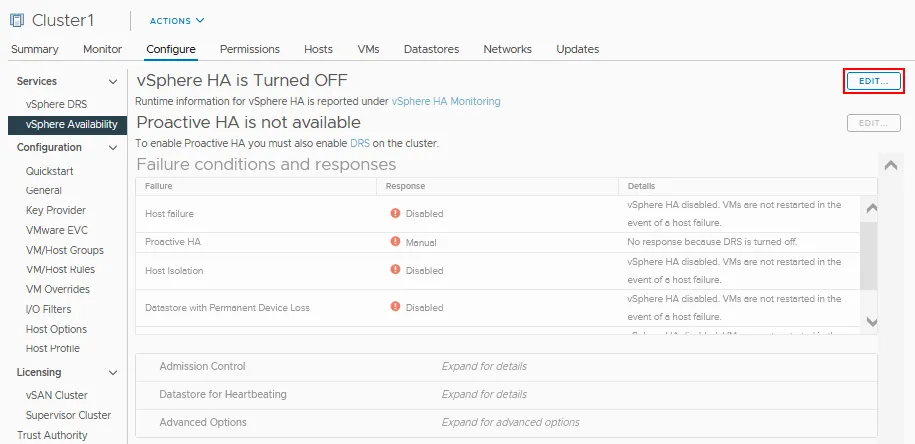
- 私たちの場合、オフになっているvSphere HAの近くにある編集をクリックしてください。
- vSphere HAスイッチャーをクリックして、ハイ・アベイラビリティを有効にしてください。
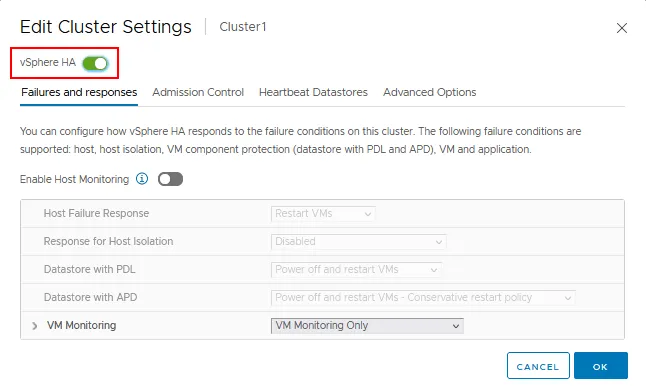
vSphere HA設定には4つのタブがあります:
- 障害と応答
- アドミッション・コントロール
- ハートビート・データストア
- 高度なオプション
これらのタブの設定を編集して行うことができるvSphere HA構成を見てみましょう。
障害と応答タブ
障害と応答タブはHAクラスターの動作をカスタマイズし、異なる状況でVMの動作を設定するために使用されます。
ホスト監視を有効にする。このオプションを有効にして、ESXiホストがクラスター内でハートビートを交換できるようにしてください。VMware vSphere HAクラスターは、クラスターのコンポーネントが利用できないときを検出するためにハートビートを使用します。ネットワークメンテナンスを実行する際には、VMの移行やフェイルオーバーを避けるためにこのオプションを無効にしてください。
障害と応答タブのすべての設定を見直しましょう。
ホスト障害応答
- 失敗応答。このクラスタの障害条件に対するHAクラスタの応答方法を設定するには、次の設定を使用します。2つのモードが利用可能です:
- 無効 – ESXiホストの監視がオフになります。
- VMの再起動 – ホスト障害時にVMが決定された順序で再起動されます。
- デフォルトのVM再起動優先度。この設定は、最初に再起動すべきVMグループを決定するために使用されます。5つの値があります:最低、低、中、高、および最高。VMは優先順位に従って、1つのグループずつ順番に再起動されます。
- VM依存性再起動条件。VMが正常に再起動されたとクラスタが検出する条件を選択し、次のバッチのVMを再起動できるようにします。4つの条件があります:
- 割り当てられたリソース
- 電源オン
- ゲストハートビートが検出されました
- アプリハートビートが検出されました
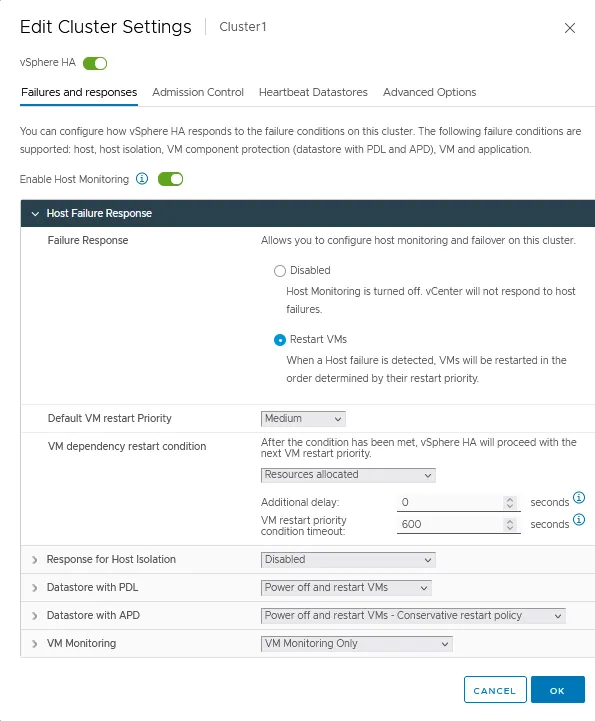
ホスト分離への応答
ホスト分離応答オプションは、ESXiホストが動作を続けているが管理ネットワーク接続を失った場合のHAクラスタの動作を設定できます:
- 無効
- VMの電源をオフにして再起動します
- VMをシャットダウンして再起動

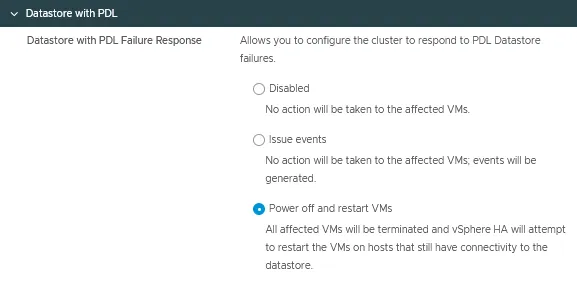
PDLを持つデータストア
永続デバイス損失(PDL)障害応答は、ESXiホストによるデータストアのアクセス不能を検出し、影響を受けるVMの自動フェイルオーバーを開始するように構成できます。
このvSphere HA構成オプションには3つのモードがあります。
- 無効
- イベントの発行
- VMの電源を切って再起動
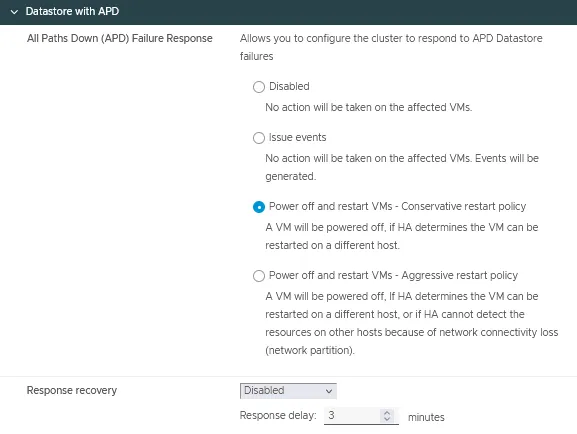
APDを持つデータストア
- すべてのパスダウン(APD)障害応答は、すべてのパスがダウンしており、これが一時的なものか永続的なデバイス損失かを示す手がかりがない場合にクラスタが応答する条件です。
この設定には4つのオプションがあります。- 無効
- イベントの発行
- VMの電源を切って再起動 – 保守的な再起動ポリシー
- VMの電源を切って再起動 – 積極的な再起動ポリシー
- 応答回復には2つのオプションがあります。
- 無効
- VMのリセット
応答の遅延を分単位で設定できます。
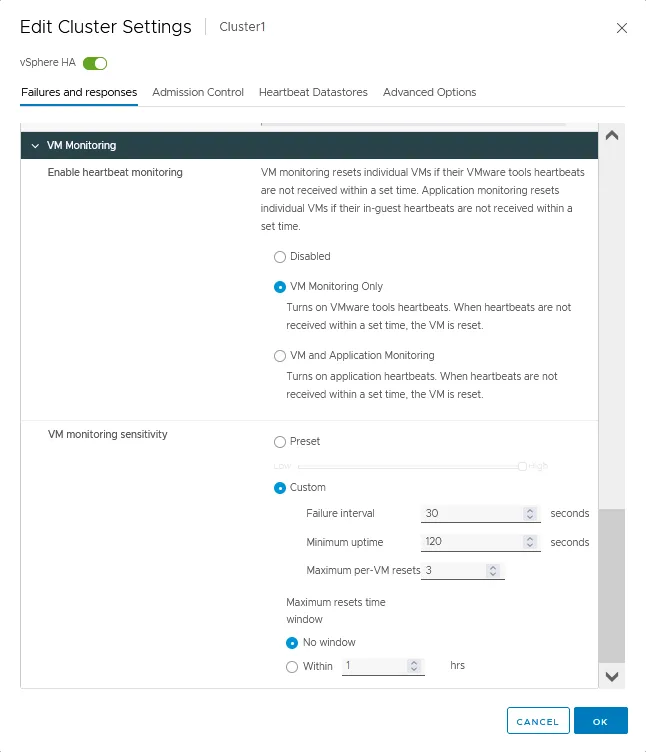
VMモニタリング
- 仮想マシンのハートビート監視を有効にするには、それらの上で実行されているVMware Toolsを使用します。また、これらの機能を使用してアプリケーションの監視を構成することもできます。VMのハートビートがタイムリーに受信されない場合、VMの再起動が開始されます。VMwareクラスタ構成には、この設定に対する3つのオプションがあります:
- 無効
- VM監視のみ
- VMおよびアプリケーションの監視
- VM監視の感度は、VMが利用できないと分類され、HAクラスタがVMの再起動を開始できるまでの時間を設定するために使用されます。
- プリセット。スイッチャを低い値から高い値に移動できます。
- カスタム。障害間隔、最大稼働時間、およびVMごとの最大リセット数などのカスタム感度パラメータを設定できます。最大リセット時間ウィンドウは、時間でのカスタム値に設定できます。
注意:クラスタにないVMの障害および問題を検出するためにVM監視ソリューションを使用することもできます。
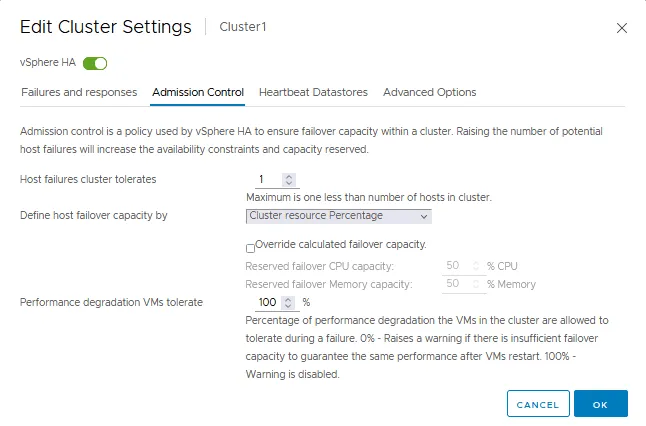
アドミッション制御タブ
アドミッションコントロールは、VMware HAクラスタ内の仮想マシンがフェイルオーバーの際に十分なリソースが確保されることを保証するためのポリシーです。アドミッションコントロールの設定は、フェイルオーバー容量を確保します。アクションがアドミッションコントロールの設定に違反する場合、そのアクションは許可されません。これらの許可されないアクションには、VMの起動、VMのマイグレーション、VMのCPUおよびメモリ設定の増加が含まれます。
- アドミッションコントロールは、HAクラスタがどれだけの障害に耐えられるかを定義し、VMのフェイルオーバーが可能な状態を維持する(VMのフェイルオーバーを保証する)ことができます。
- ホストのフェイルオーバー容量を定義する方法は次の通りです。
- クラスタリソースのパーセンテージ
- 専用のフェイルオーバーホスト
- スロットポリシー
アドミッションコントロールを無効にすると、フェイルオーバーが発生した場合にHAクラスタ内で予想される数のVMが再起動されることを保証できなくなります。
- クラスタが許容するパフォーマンスの低下は、クラスタが許容できるパフォーマンス低下の割合を定義する設定です。0%は、VMのフェイルオーバー/再起動後に同じレベルのVMパフォーマンスが保証されなければならないことを意味します。そうでなければ、警告が表示されます。100%は、警告が無効になり、クラスタはVMを再起動しようとします。
ハートビートデータストアタブ
Heartbeatデータストアは、ESXiホストの可用性を監視するためのセカンダリの方法を提供し、ESXiホストへのネットワーク接続が利用できない場合や管理ネットワークが障害を受けた場合に、データストアを使用します。このアプローチにより、vSphereはホストの障害とネットワーク経由でのホストの利用不可を区別できます。VMware HA構成でハートビートデータストアを使用して、HAネットワークが障害を受けた場合にホストを監視します。
ハートビートデータストアの選択ポリシーには、3つのオプションがあります:
- ホストからアクセス可能なデータストアを自動的に選択
- 指定されたリストからのみデータストアを使用
- 必要に応じて指定されたリストからデータストアを使用し、自動的に補完

詳細オプションタブ
詳細オプションタブを使用して、各文字列にオプションと値を手動で入力してvSphere HAを構成できます。VMware vSphere ClientのGUIで利用可能な標準設定でHAクラスタを調整できない場合に詳細オプションを使用できます。
VMware Distributed Resource Scheduler (DRS)と同様に、OKをクリックすると、上記で構成されたHA設定に再構成されたVMwareクラスタが再構成されます。
VMware vSphere Proactive HA
Proactive HAは、ESXiホストおよびそのホストに存在するすべてのVMの障害が発生する前に、クラスタが問題に反応する機能です。ESXiサーバーのさまざまなコンポーネントで問題が発生する可能性があり、vSphere Proactive HAはサーバーのハードウェア状態を検出できます。
例えば、Proactive HA は ESXi サーバーの電源供給に問題があることを通知できます。このサーバー上で VM は引き続き実行されますが、この問題がサーバーの障害につながる可能性があります。VM の障害を防ぐために、vSphere Proactive HA はクラスターの他の ESXi ホストに VM を移行することができます。Proactive HA は、電源供給、ファン、ストレージ、メモリ、ネットワークに関連する問題に反応することをサポートしています。
Proactive HA を有効にする前に、vSphere クラスターで Distributed Resource Scheduler(DRS)を有効にして設定する必要があります。クラスターに対して vSphere HA と DRS を一緒に構成することができます。
締めくくり
VMware vSphere ESXi プラットフォームの真の力、回復力、拡張性は、vCenter Server がプロビジョニングされ、ESXi ホストが vSphere ESXi クラスターに追加された後に解除されます。VM のホスト障害に対する保護を効果的に提供し、VM のリソースのバランスとスケジュールを行うために、vSphere HA と DRS を構成してください。vSphere 6.5 以降、VMware はよりプロアクティブでインテリジェントな監視と洞察を両方のクラスター機能に追加したため、DRS や HA はさらに強力になり、アジャイルでプロアクティブになりました。
VM がクラスターで実行されている場合でも、データ損失を防ぐために VMware VM バックアップを実行するのを忘れないでください。
Source:
https://www.nakivo.com/blog/vmware-cluster-ha-configuration/