













AWS CLIとAWS S3の設定
aws s3 cpコマンドに取り組む前に、AWS CLIをシステムにインストールして適切に設定する必要があります。AWSを使ったことがなくても心配しないでください – セットアッププロセスは簡単で、10分未満で完了します。
これを3つのシンプルなフェーズに分解します:AWS CLIツールのインストール、資格情報の設定、および最初のS3バケットの作成。
AWS CLIのインストール
インストールプロセスは、使用しているオペレーティングシステムによってわずかに異なります。
Windowsシステムの場合:
- 公式のAWS CLIドキュメントページに移動してください。
- 64ビットWindowsインストーラーをダウンロードしてください。
- ダウンロードしたファイルを起動し、インストールウィザードに従ってください。
Linuxシステムの場合:
ターミナルを介して以下の3つのコマンドを実行してください。
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
macOSシステムの場合:
Homebrewがインストールされていると仮定して、ターミナルからこの1行を実行してください。
brew install awscli
Homebrewがインストールされていない場合は、代わりにこれらの2つのコマンドを使用してください。
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
インストールが成功したか確認するには、ターミナルでaws --versionを実行してください。次のようなものが表示されるはずです。
画像1 – AWS CLIバージョン
AWS CLIの設定
CLIがインストールされたら、認証のためにAWS資格情報を設定する時がきました。
まず、AWSアカウントにアクセスしてIAMサービスダッシュボードに移動してください。プログラムによるアクセス権限を持つ新しいユーザーを作成し、適切なS3権限ポリシーをアタッチしてください。
画像2 – AWS IAMユーザー
次に、”セキュリティ資格情報”タブに移動して新しいアクセスキーを生成してください。アクセスキーIDとシークレットアクセスキーの両方を安全な場所に保存してください。この画面以降、Amazonは再びシークレットキーを表示しません。
画像3 – AWS IAMユーザー資格情報
今、ターミナルを開いてaws configureコマンドを実行してください。アクセスキーID、シークレットアクセスキー、デフォルトリージョン(私はeu-central-1を使用しています)、および希望の出力形式(通常はjson)を求められます。
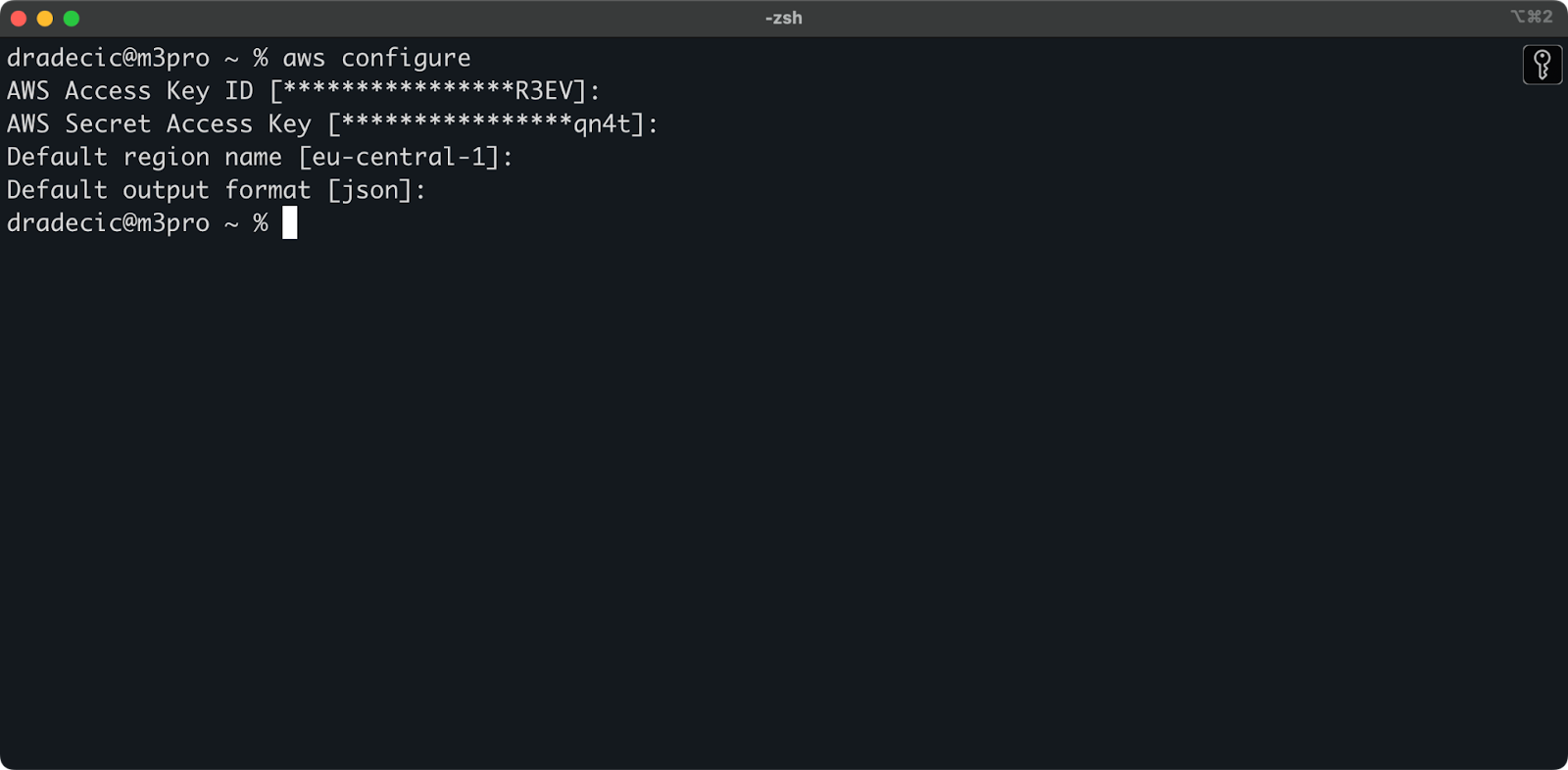
画像4 – AWS CLI構成
すべてが正しく接続されていることを確認するために、次のコマンドでアイデンティティを検証してください:
aws sts get-caller-identity
正しく構成されている場合、アカウントの詳細が表示されます:
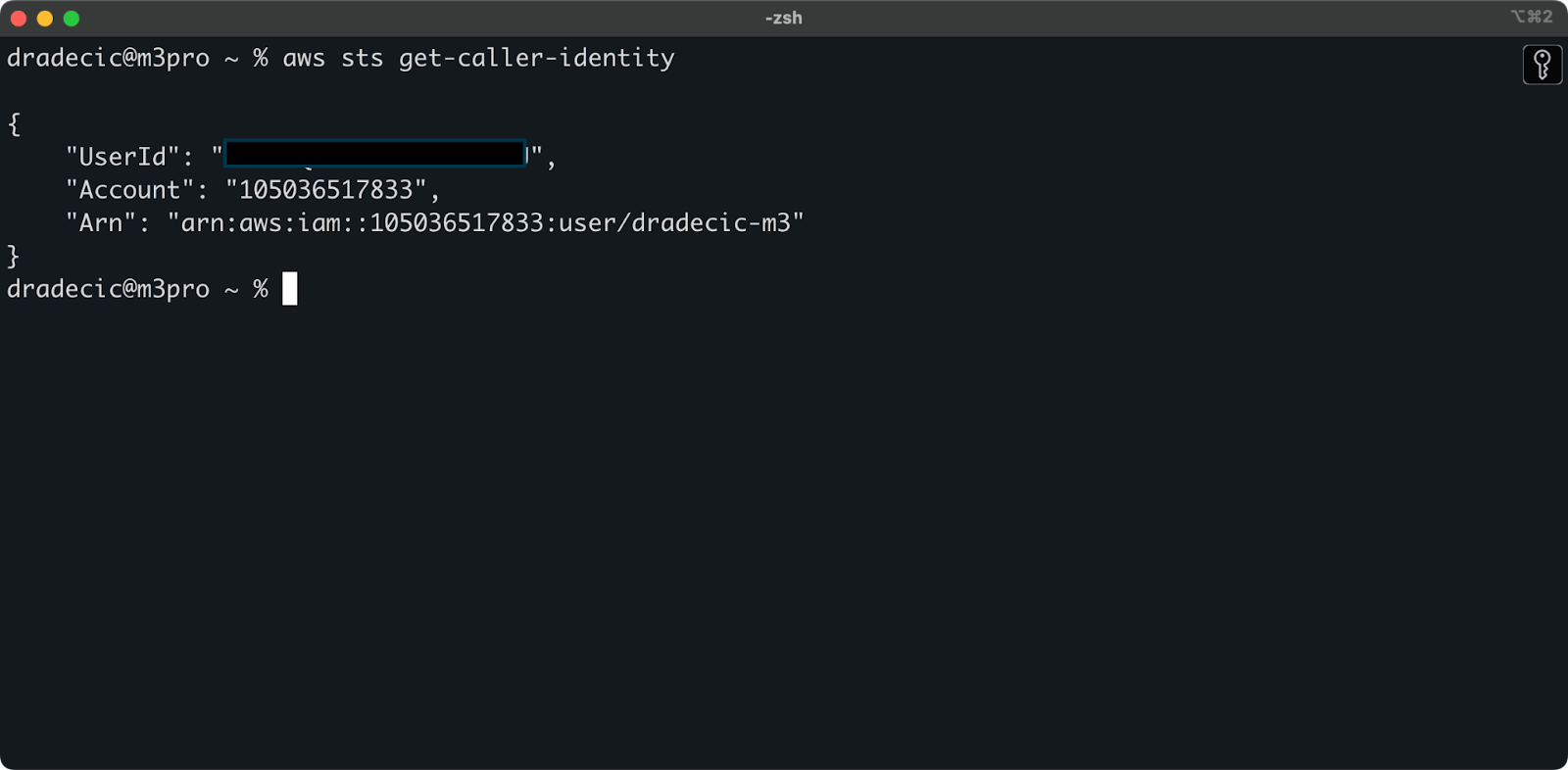
画像5 – AWS CLIテスト接続コマンド
S3バケットの作成
最後に、コピーするファイルを保存するためのS3バケットを作成する必要があります。
AWSコンソールのS3サービスセクションに移動し、「バケットの作成」をクリックしてください。バケット名はAWS全体で一意である必要があることを念頭に置いてください。特徴的な名前を選択し、現時点ではデフォルト設定を残し、「作成」をクリックしてください:
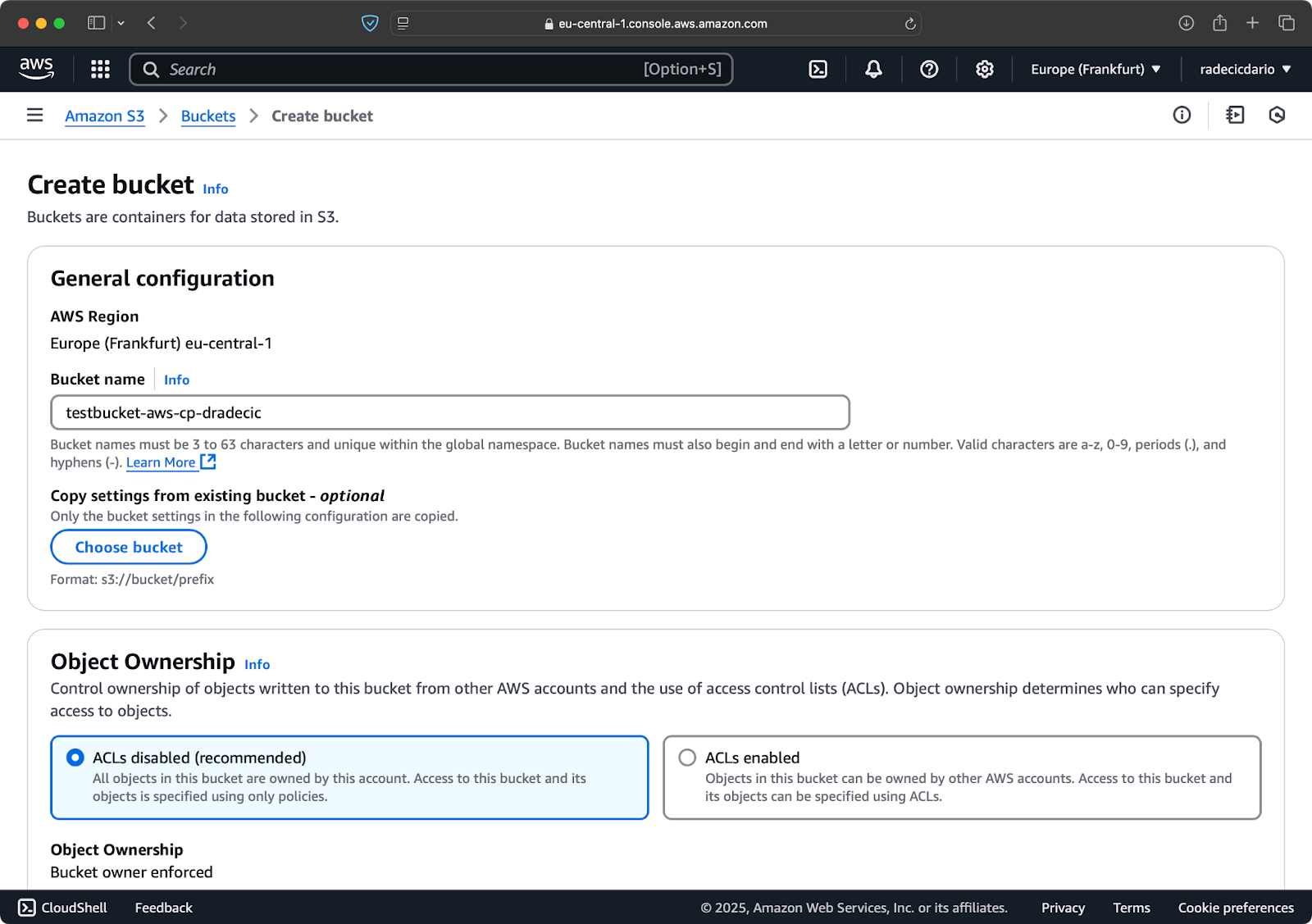
画像6 – AWSバケットの作成
作成されると、新しいバケットがコンソールに表示されます。存在を確認するためにもコマンドラインを使用することができます:
aws s3 ls
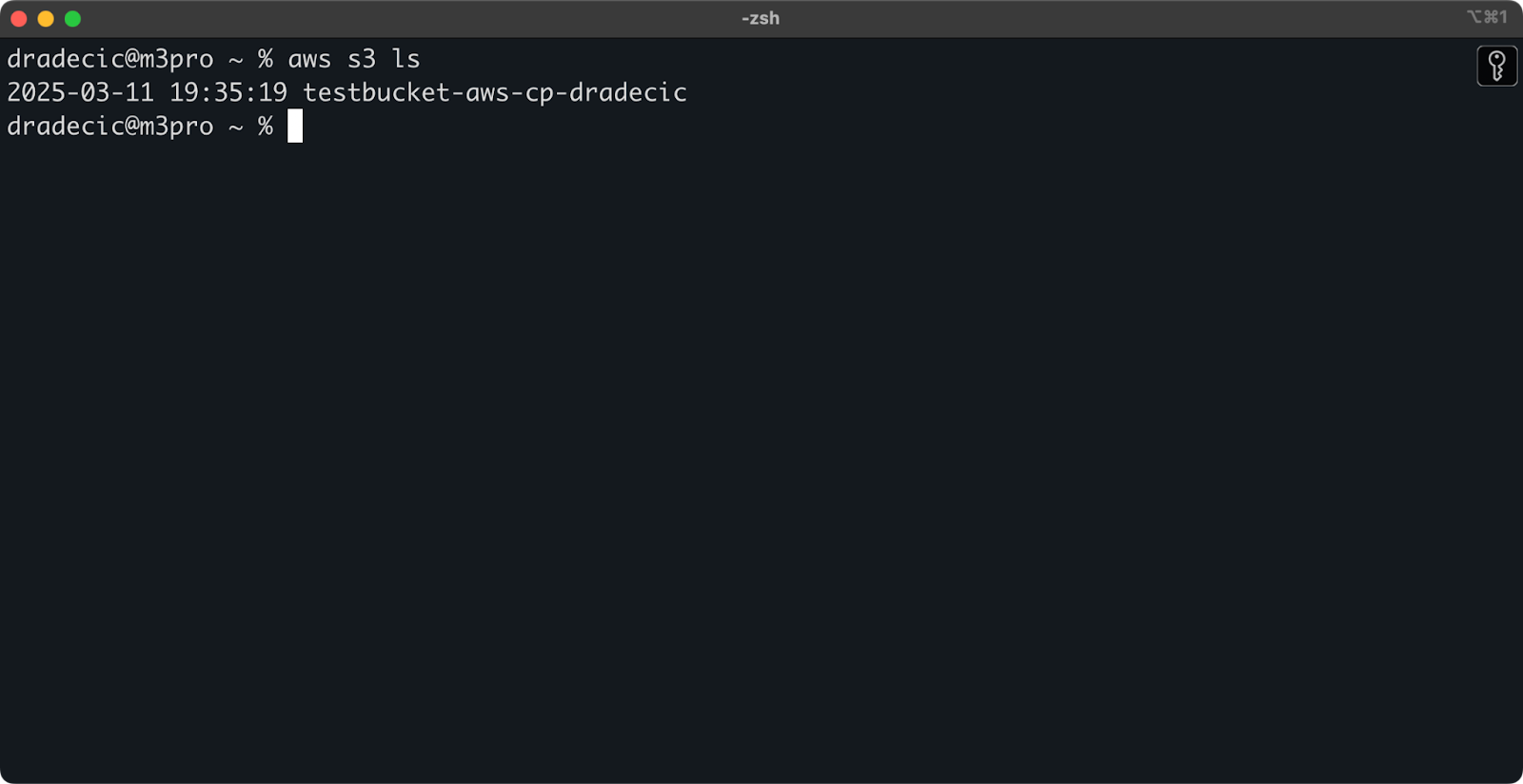
画像7 – 利用可能なすべてのS3バケット
すべてのS3バケットはデフォルトでプライベートに構成されているため、これを考慮してください。このバケットを公開可能なファイルに使用する場合は、バケットポリシーを適切に変更する必要があります。
これで、ファイルを転送するためにaws s3 cpコマンドを使用する準備が整いました。次に基本を始めましょう。
基本的なAWS S3 cpコマンドの構文
設定が完了したので、aws s3 cpコマンドの基本的な使用方法について学んでみましょう。AWSではいつものように、その美しさはシンプルさにあります。このコマンドは異なるファイル転送シナリオを処理できます。
最も基本的な形では、aws s3 cpコマンドは次の構文に従います:
aws s3 cp <source> <destination> [options]
<source>と<destination>は、ローカルファイルパスまたはs3://で始まるS3 URIであることができます。3つの最も一般的な使用ケースを探ってみましょう。
ローカルからS3へのファイルのコピー
ローカルシステムからS3バケットにファイルをコピーするには、ソースはローカルパスであり、宛先はS3 URIとなります:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
このコマンドは、指定したディレクトリからファイルtest_file.txtを指定されたS3バケットにアップロードします。操作が成功した場合、以下のようなコンソール出力が表示されます:
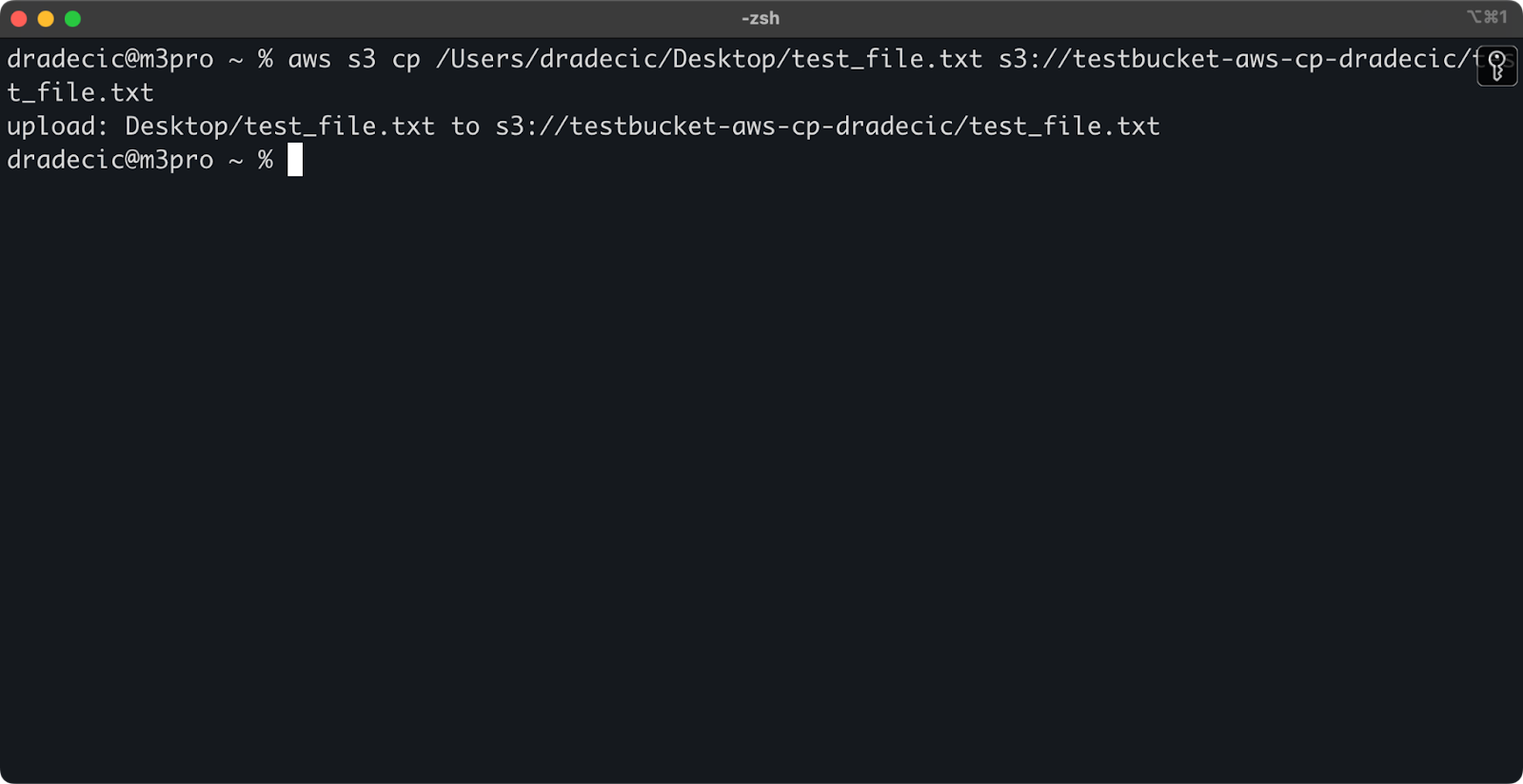
画像8 – ローカルファイルをコピーした後のコンソール出力
また、AWS管理コンソールでは、ファイルがアップロードされたのが見られます:
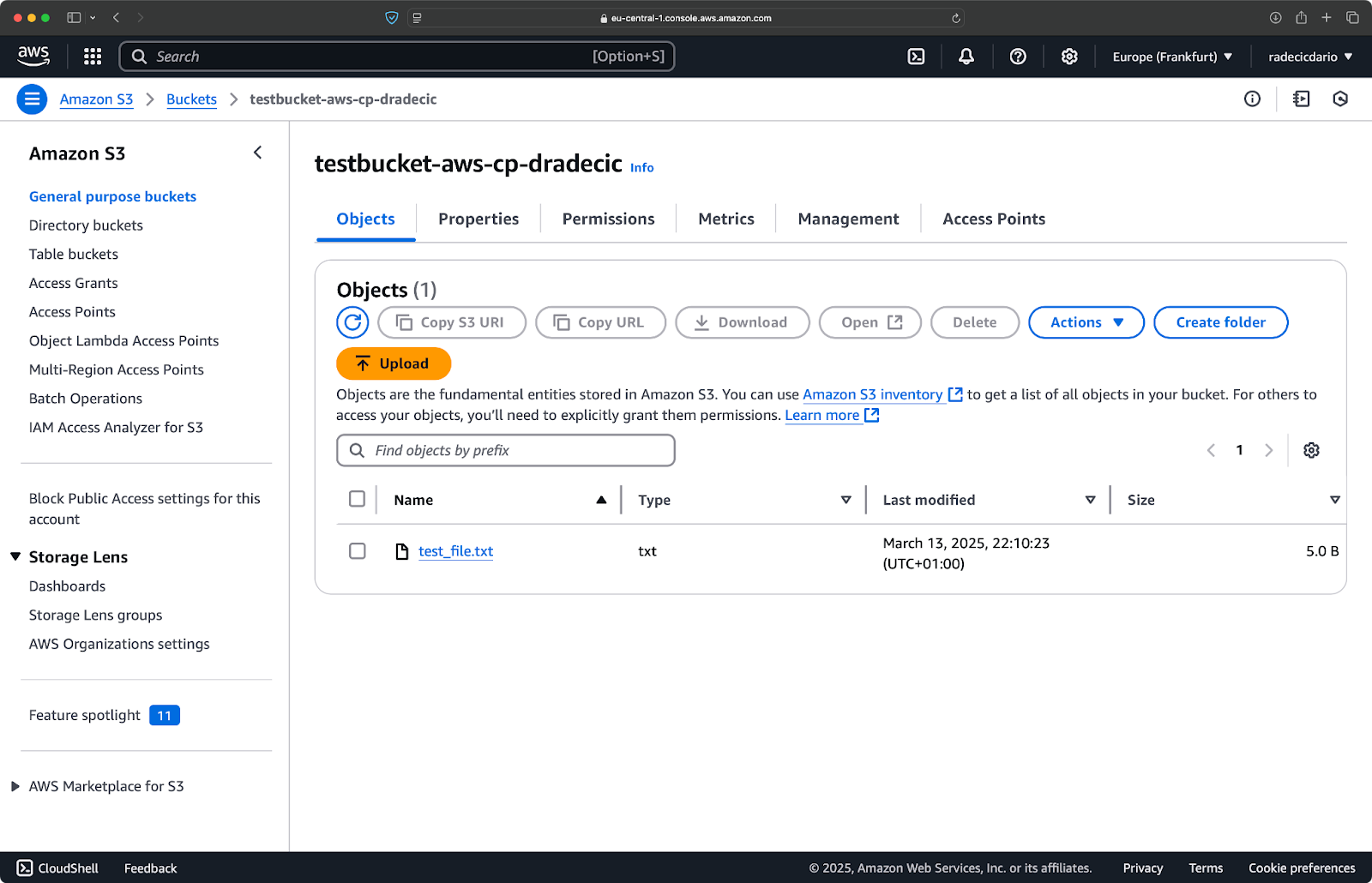
画像9 – S3バケットの内容
同様に、ローカルフォルダをS3バケットにコピーして、別のネストされたフォルダに配置したい場合は、次のようなコマンドを実行します:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
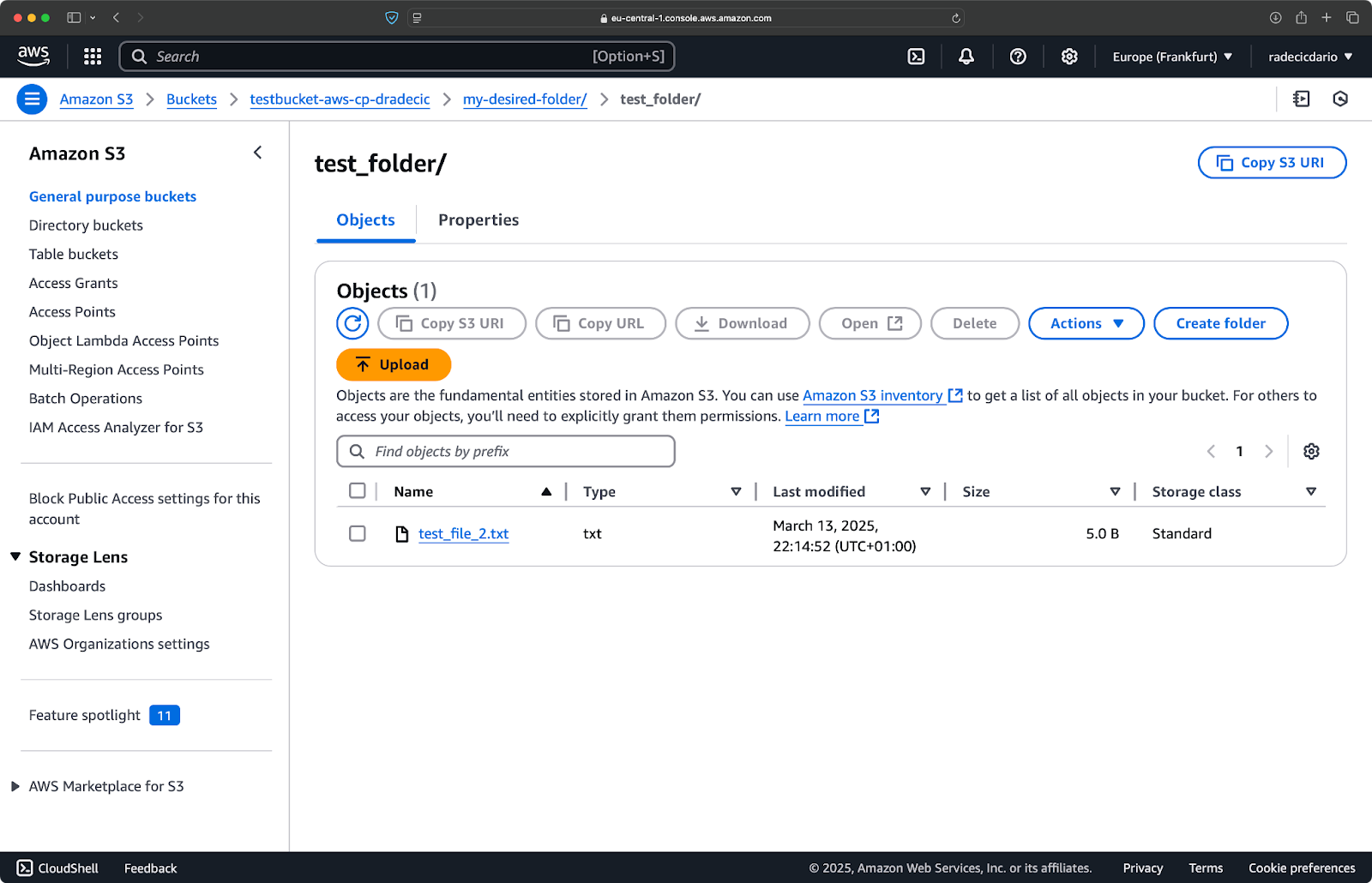
画像10 – フォルダをアップロードした後のS3バケットの内容
--recursiveフラグは、フォルダ内のすべてのファイルとサブフォルダがコピーされることを確認します。
ただし、覚えておくこと – S3には実際にフォルダはありません – パス構造はオブジェクトのキーの一部ですが、概念的にはフォルダのように機能します。
S3からローカルへのファイルのコピー
S3からファイルをローカルシステムにコピーするには、単純に順序を逆にします-ソースはS3 URIとなり、宛先はローカルパスになります:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
このコマンドは、S3バケットからtest_file.txtをダウンロードし、指定したディレクトリにdownloaded_test_file.txtとして保存します。ローカルシステムで即座に確認できます:
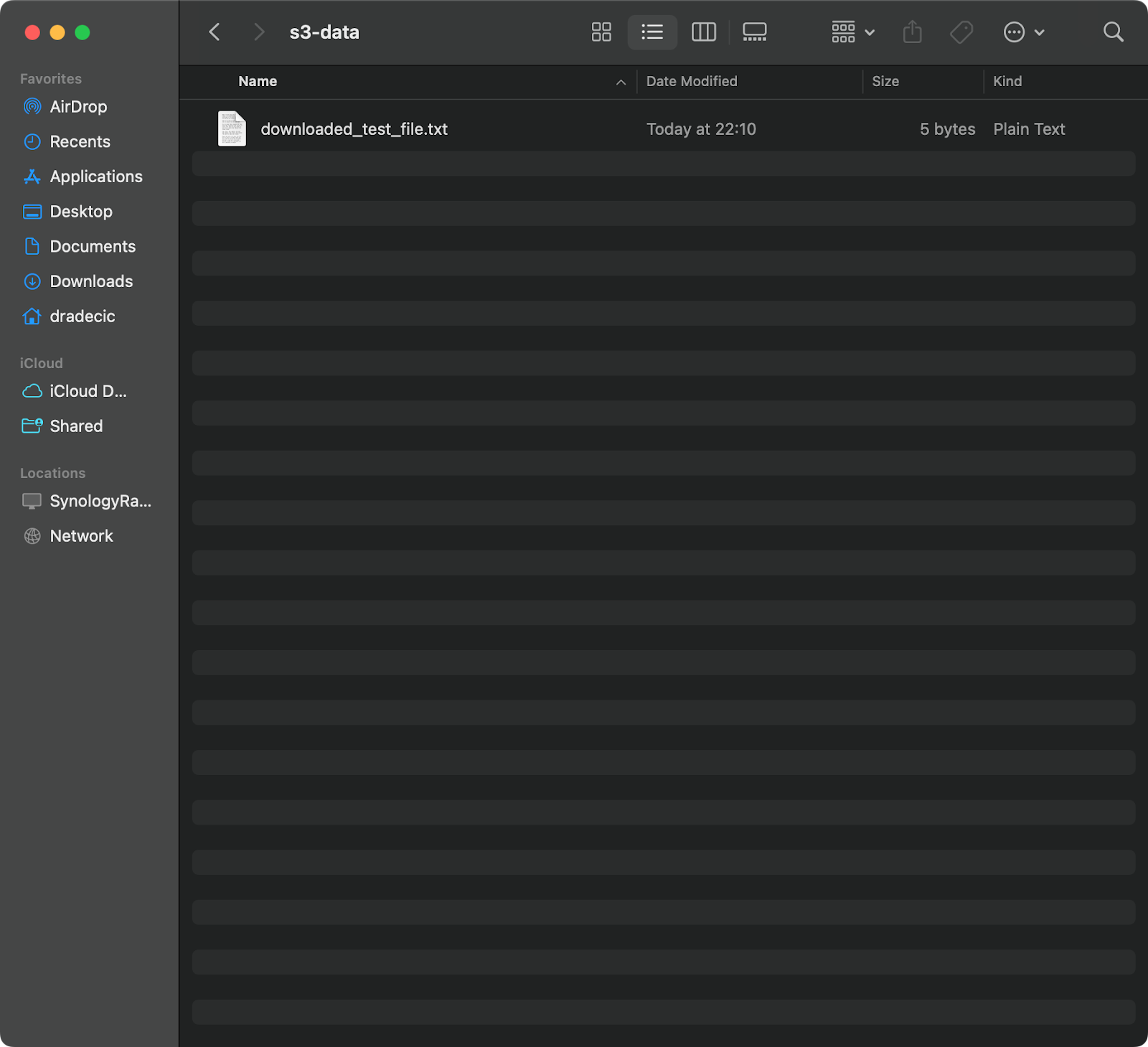
イメージ11 – S3から単一のファイルをダウンロード
宛先ファイル名を省略すると、元のファイル名が使用されます:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
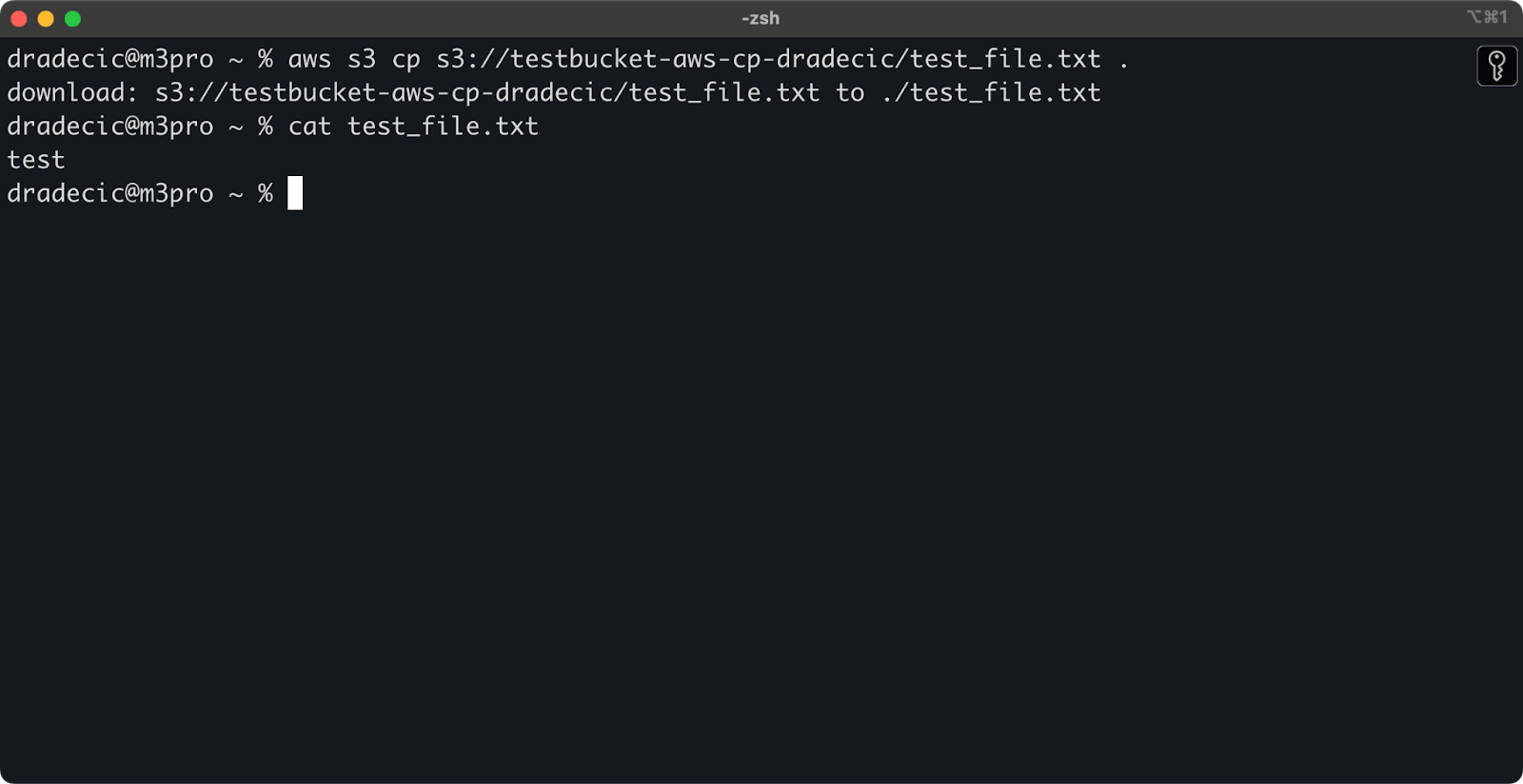
イメージ12 – ダウンロードしたファイルの内容
ピリオド(.)は現在のディレクトリを表し、したがって、test_file.txtを現在の場所にダウンロードします。
最後に、ディレクトリ全体をダウンロードするには、次のようなコマンドを使用できます:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
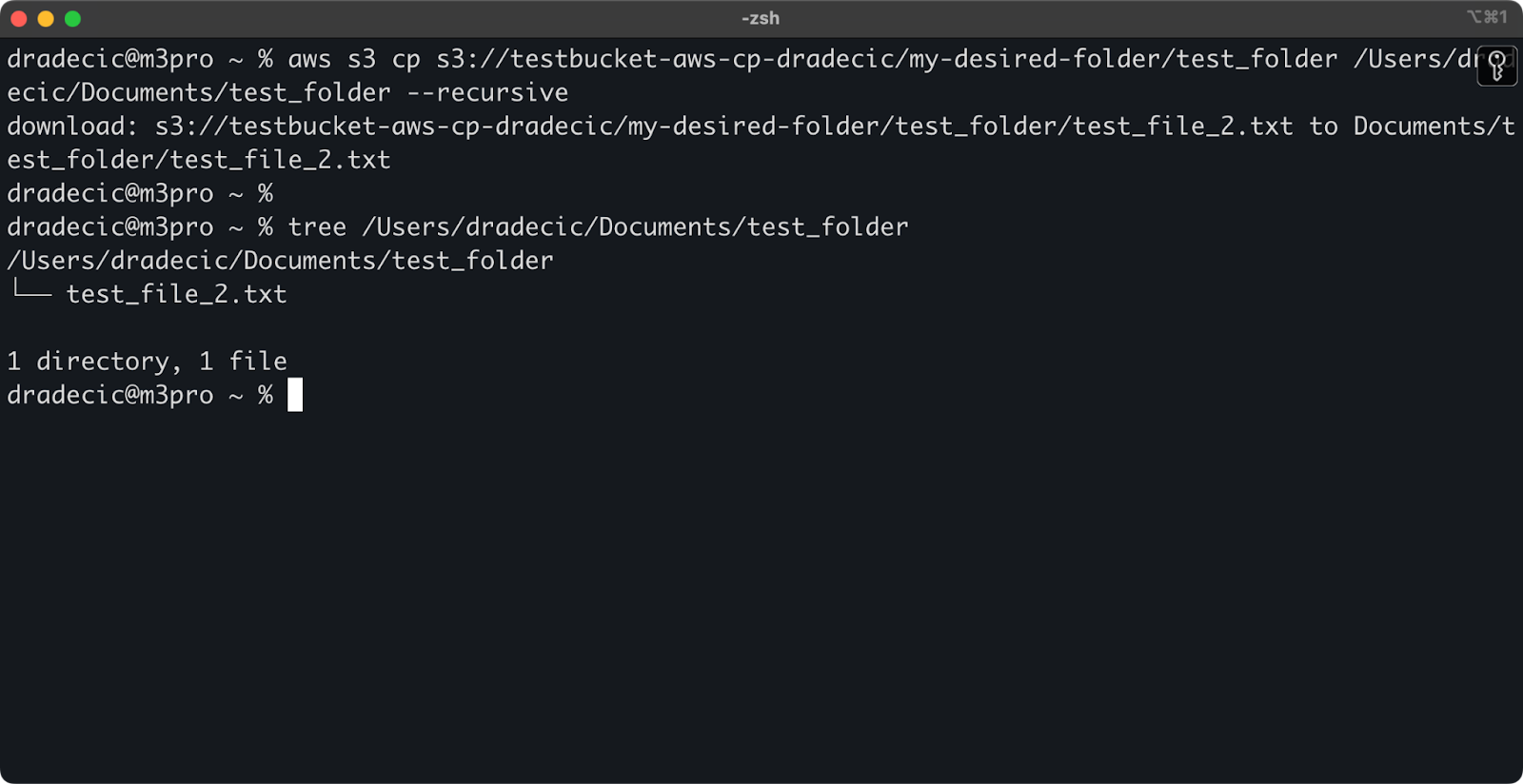
イメージ13 – ダウンロードしたフォルダの内容
複数のファイルを扱う際には、--recursiveフラグが不可欠です-それなしでは、ソースがディレクトリの場合にコマンドが失敗します。
これらの基本的なコマンドを使用すると、必要なほとんどのファイル転送タスクをすでに達成できます。ただし、次のセクションでは、コピー処理をより細かく制御するための高度なオプションについて詳しく説明します。
高度なAWS S3 cpオプションと機能
AWSには、ファイルコピー操作を最大限に活用できるいくつかの高度なオプションがあります。このセクションでは、日常的なタスクに役立ついくつかの最も有用なフラグとパラメータを紹介します。
–excludeおよび–includeフラグの使用
特定のパターンと一致するファイルのみをコピーしたい場合があります。 --exclude と --include フラグを使用すると、パターンに基づいてファイルをフィルタリングし、コピーされるファイルを正確に制御できます。
まず、作業しているディレクトリ構造は次のようになります:
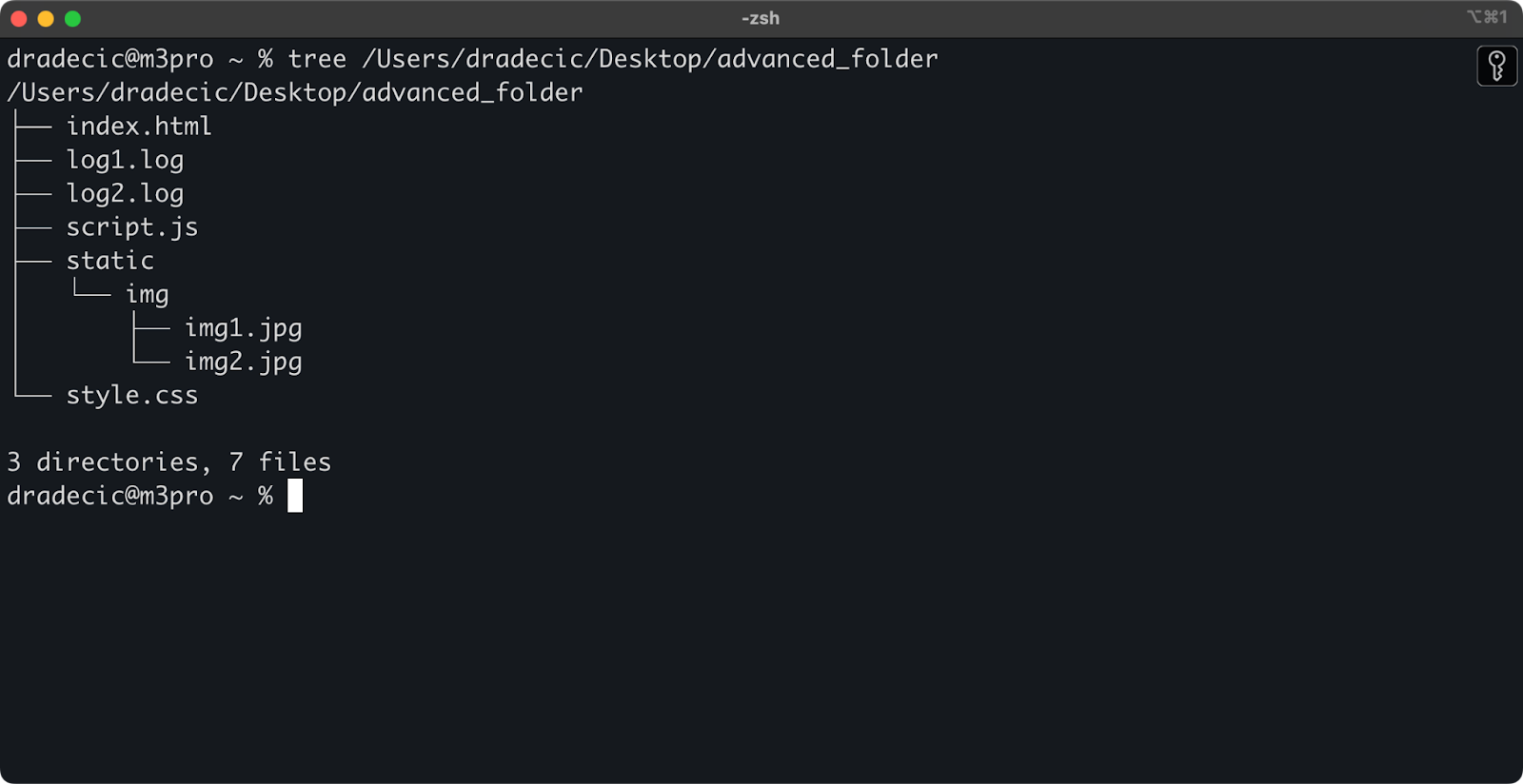
Image 14 – ディレクトリ構造
では、例えばディレクトリからすべてのファイルをコピーしたいが、.log ファイルは除外したいとします。
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
このコマンドは、.log 拡張子のファイルを除外して、advanced_folder ディレクトリからすべてのファイルを S3 にコピーします:
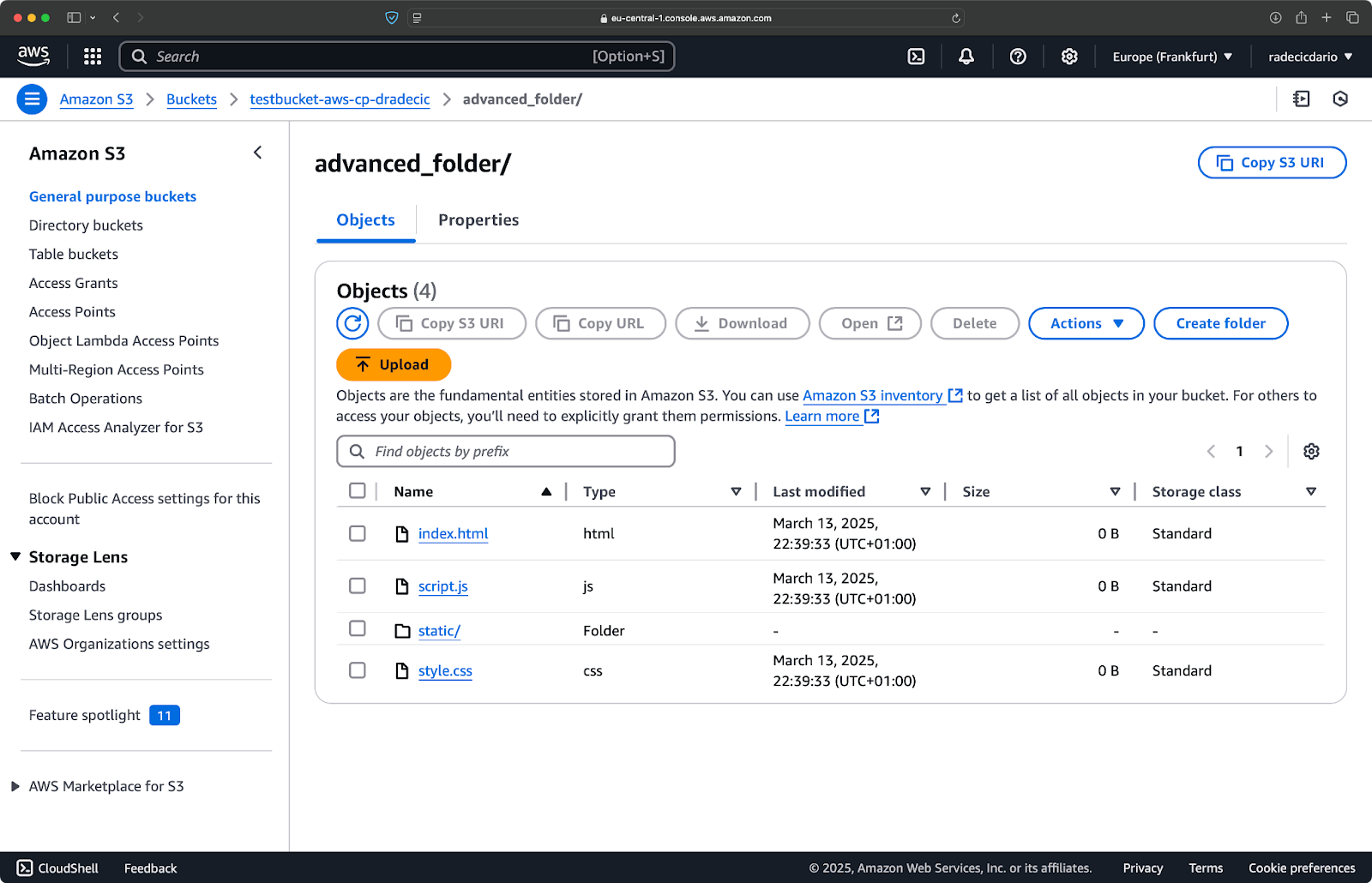
Image 15 – フォルダコピーの結果
複数のパターンを組み合わせることもできます。たとえば、プロジェクトフォルダから HTML ファイルと CSS ファイルのみをコピーしたい場合:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
このコマンドでは、まずすべてを除外し (--exclude "*")、その後 .html と .css 拡張子を持つファイルのみを含めます。結果は次のようになります:
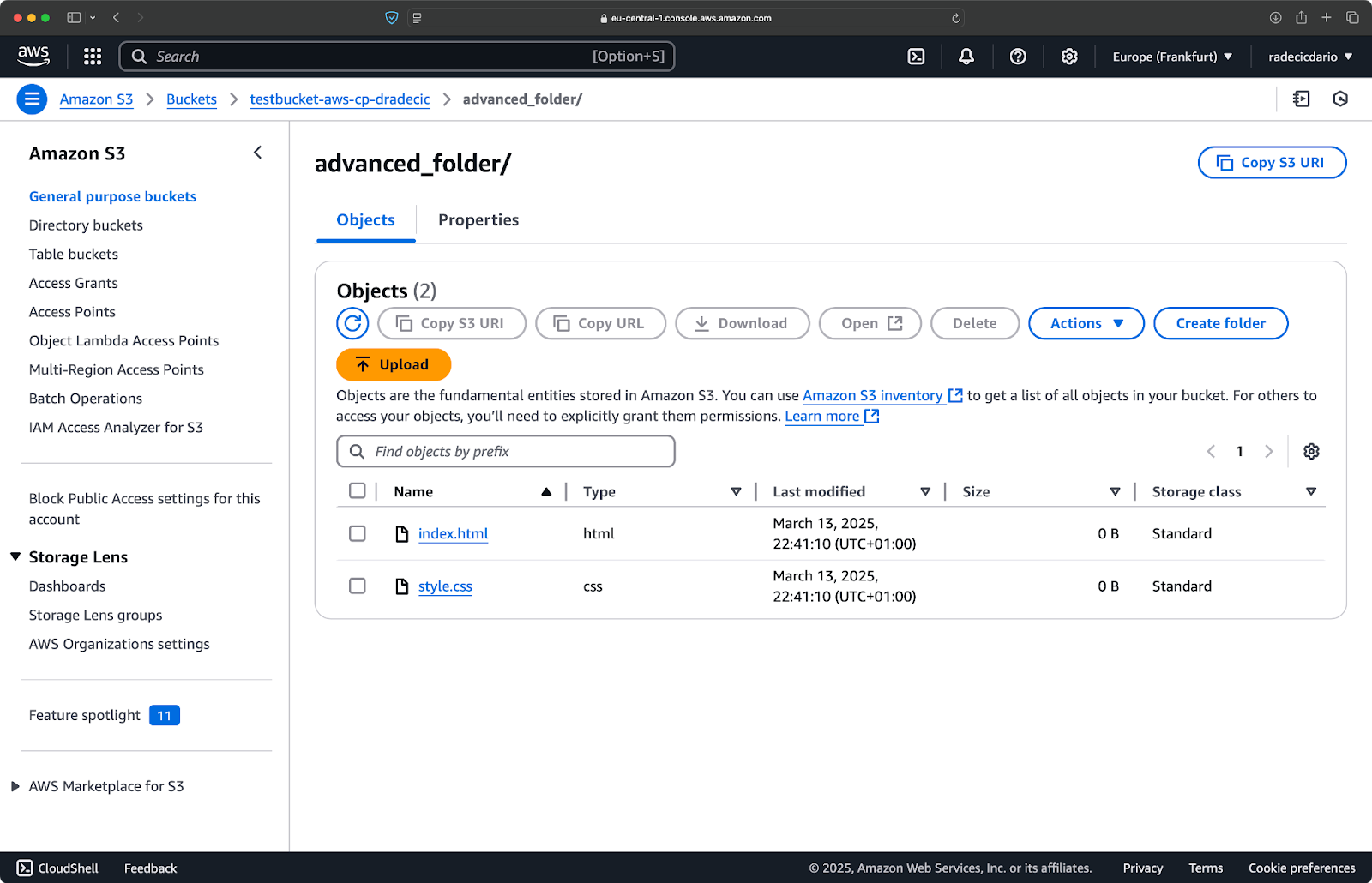
Image 16 – フォルダコピーの結果 (2)
フラグの順序が重要であることに注意してください。AWS CLI はこれらのフラグを連続して処理するため、--include を --exclude の前に配置すると異なる結果が得られます:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
今回は、何もバケットにコピーされませんでした:
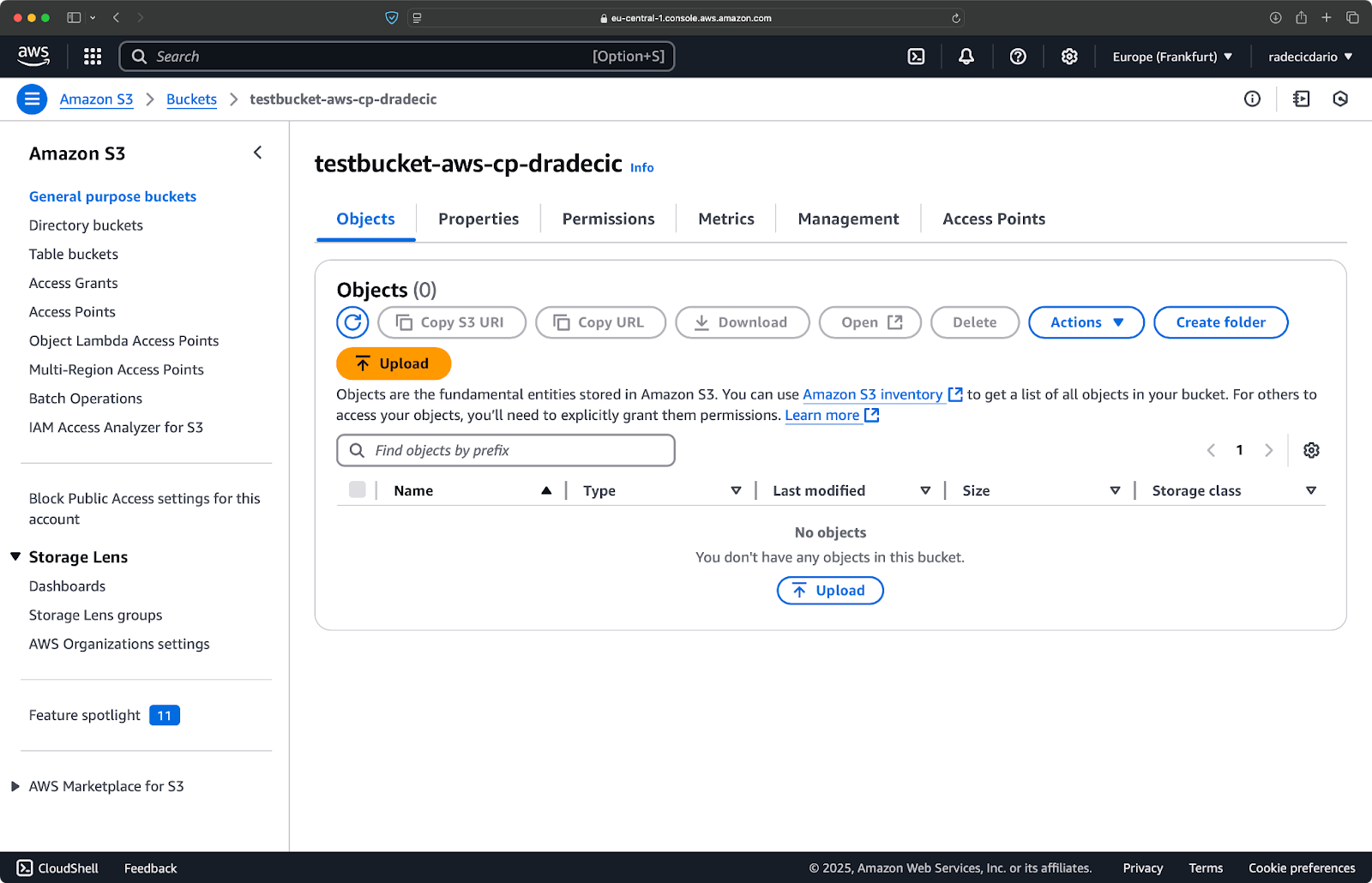
Image 17 – フォルダコピーの結果 (3)
S3 ストレージクラスの指定
Amazon S3では、異なるストレージクラスが提供されており、それぞれ異なるコストとリトリーバル特性を持っています。デフォルトでは、aws s3 cpはファイルを標準ストレージクラスにアップロードしますが、--storage-classフラグを使用して異なるクラスを指定することができます。
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
このコマンドはlarge-archive.zipをGlacierストレージクラスにアップロードし、価格は格段に安いですが、リトリーバルコストが高く、リトリーバル時間が長いです:
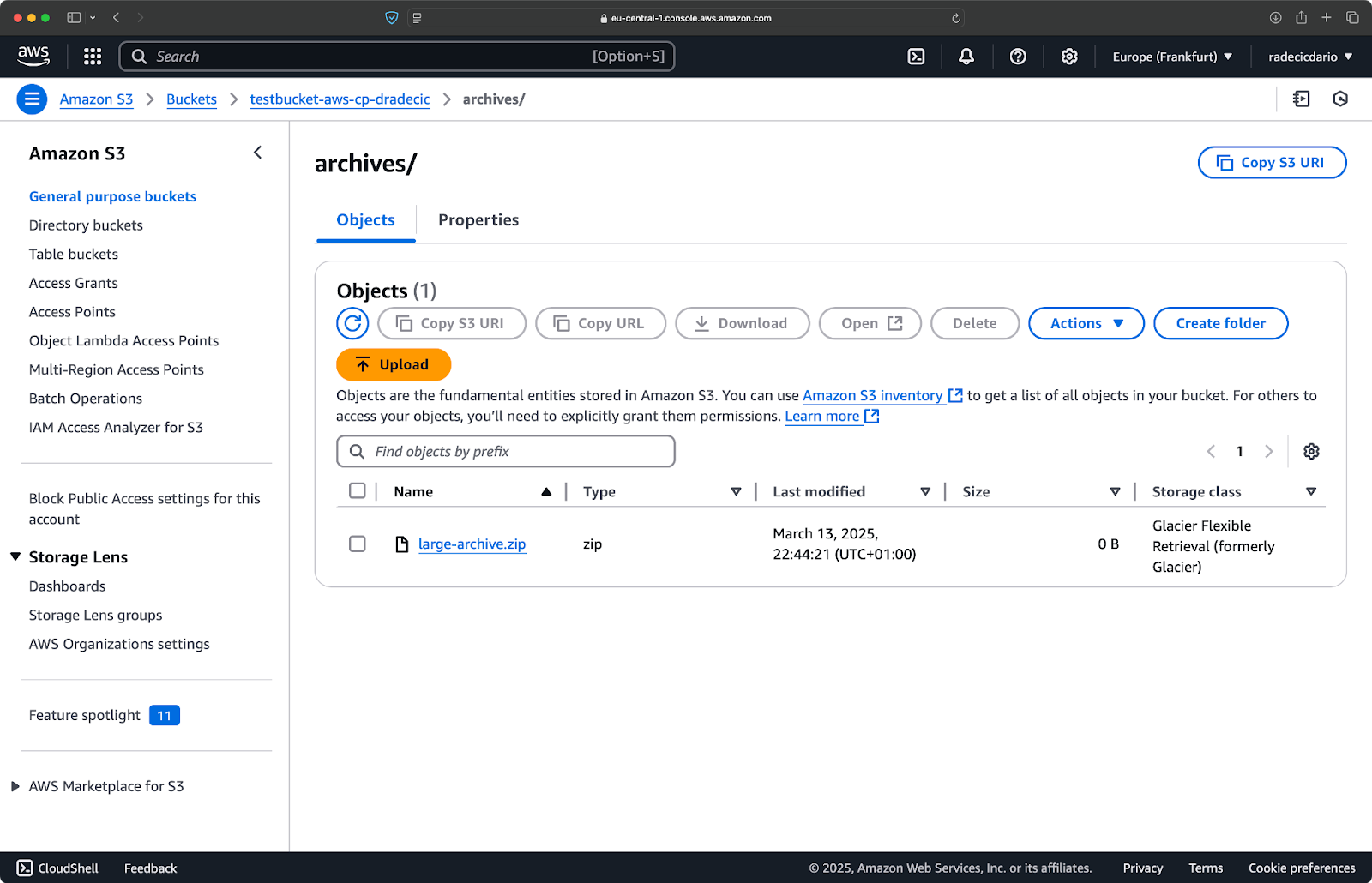
Image 18 – 異なるストレージクラスへのファイルのコピーS3
利用可能なストレージクラスは以下を含みます:
STANDARD(デフォルト): 高い耐久性と可用性を持つ汎用ストレージ。REDUCED_REDUNDANCY(推奨されない): 低い耐久性、コスト節約のオプション、現在は非推奨。STANDARD_IA(まれにアクセス): より頻繁にアクセスされないデータ用の低コストストレージ。ONEZONE_IA(単一ゾーンまれにアクセス): 単一のAWSアベイラビリティゾーン内での低コスト、まれにアクセスされるストレージ。INTELLIGENT_TIERING: アクセスパターンに基づいてデータをストレージティア間で自動的に移動。GLACIER: 長期保存用の低コストアーカイブストレージ、リトリーバルは数分から数時間で可能。DEEP_ARCHIVE: 最も安いアーカイブストレージ、数時間でのリトリーバル、長期バックアップに最適。
直ちにアクセスが必要でないファイルをバックアップする場合は、GLACIERやDEEP_ARCHIVEを使用することで膨大なストレージコストを節約できます。
–exact-timestampsフラグを使用してファイルを同期
S3で既に存在するファイルを更新する際、変更されたファイルのみをコピーしたい場合があります。 --exact-timestamps フラグは、ソースと宛先のタイムスタンプを比較することでこれをサポートします。
以下に例を示します:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
このフラグを使用すると、コマンドはS3にすでにあるファイルとタイムスタンプが異なる場合のみファイルをコピーします。これにより、大量のファイルを定期的に更新する際の転送時間と帯域幅の使用量を削減できます。
では、なぜこれが役立つのでしょうか?変更されていないアセットを転送せずにアプリケーションファイルを更新したい展開シナリオを想像してみてください。
--exact-timestamps は同期を行うのに役立ちますが、より洗練されたソリューションが必要な場合は、aws s3 cp の代わりに aws s3 sync を使用することを検討してください。 sync コマンドは、ディレクトリを同期させるために特別に設計されており、この目的のための追加機能を備えています。私は AWS S3 Sync チュートリアル で sync コマンドについて詳しく説明しています。
これらの高度なオプションを使用すると、S3ファイル操作に対してより細かい制御が可能になります。特定のファイルを対象にでき、ストレージコストを最適化し、効率的にファイルを更新できます。次のセクションでは、これらの操作をスクリプトやスケジュールされたタスクを使用して自動化する方法を学びます。
AWS S3 cpを使用したファイル転送の自動化
これまでに、コマンドラインを使用してS3にファイルを手動でコピーおよびコピー元S3から取得する方法を学びました。 aws s3 cpを使用する最大の利点の1つは、これらの転送を簡単に自動化できることです。これにより、大量の時間が節約されます。
手をかけずにファイル転送を行うために、aws s3 cpコマンドをスクリプトや定期ジョブに統合する方法を探ってみましょう。
スクリプトでAWS S3 cpを使用する
次に示すシンプルなbashスクリプト例は、ディレクトリをS3にバックアップし、バックアップにタイムスタンプを追加し、エラーハンドリングとログをファイルに実装します:
#!/bin/bash # 変数を設定 SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # ログディレクトリが存在することを確認 mkdir -p "$(dirname "$LOG_FILE")" # バックアップを作成し、出力をログに記録 echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # バックアップが成功したかどうかをチェック if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
これをbackup.shとして保存し、chmod +x backup.shで実行可能にして、再利用可能なバックアップスクリプトを作成します!
次のコマンドで実行できます:
./backup.sh
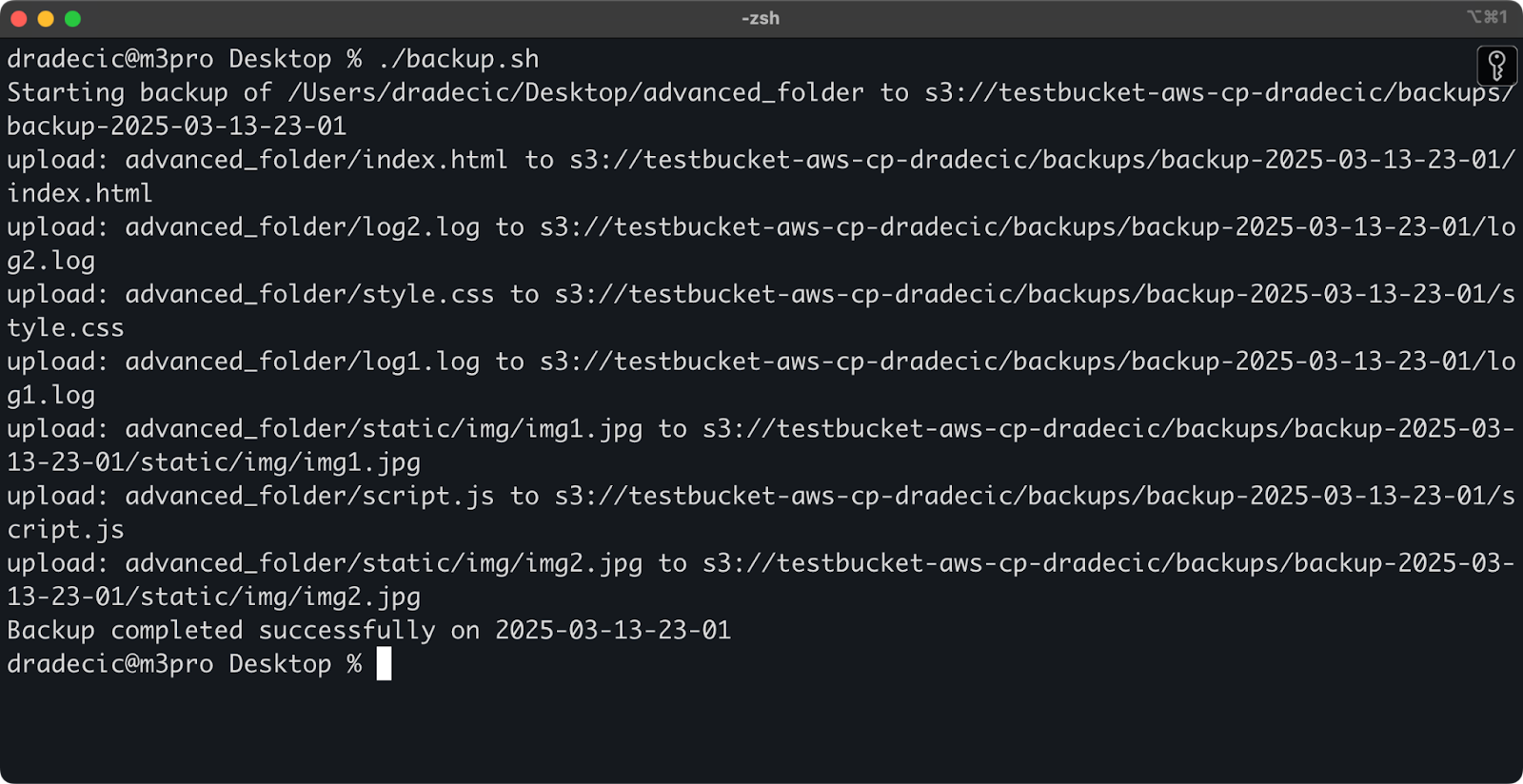
イメージ19 – ターミナルでスクリプトが実行されています
直後に、バケット上のbackupsフォルダがデータで埋められます:
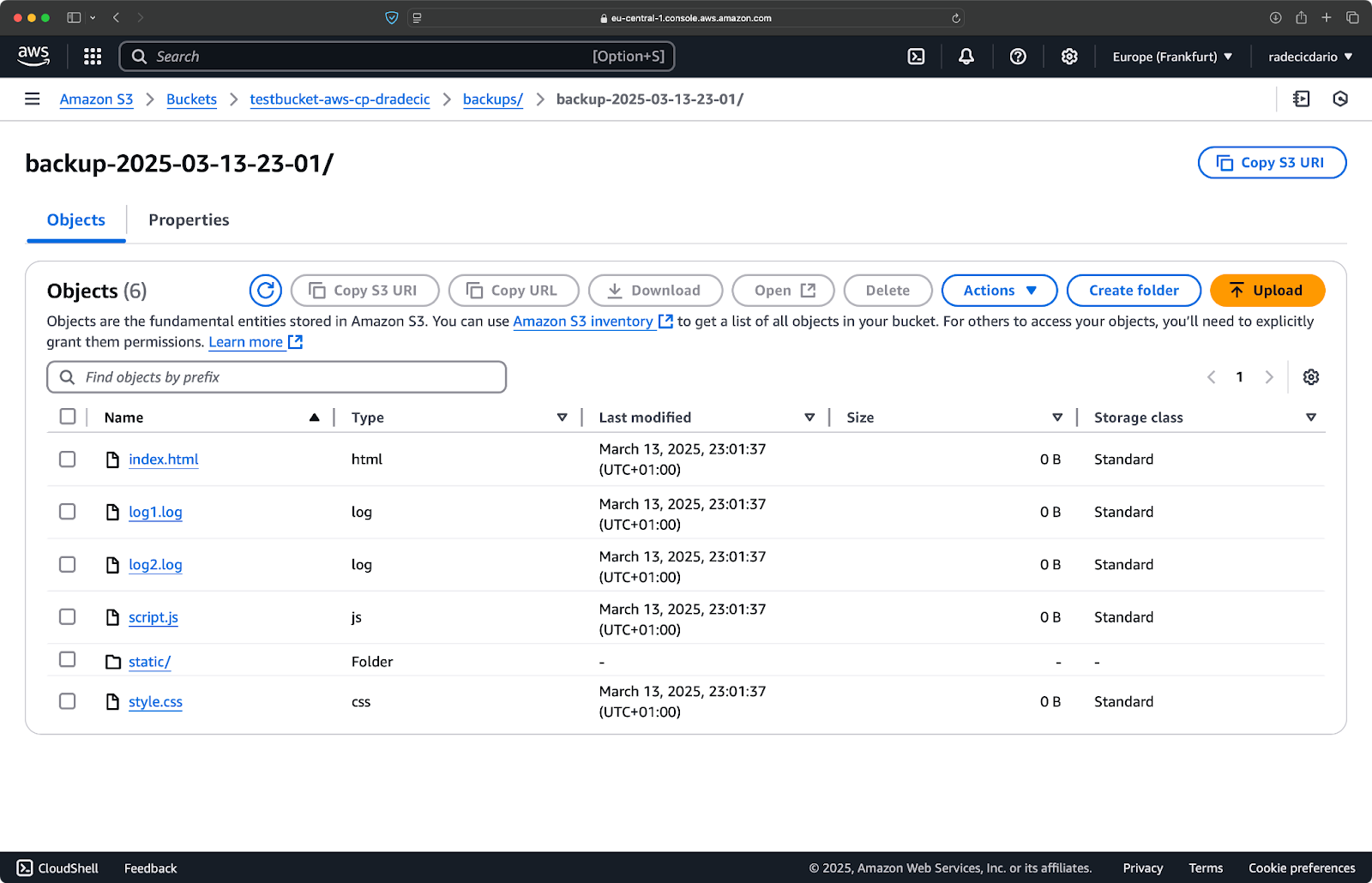
イメージ20 – S3バケットに保存されたバックアップ
次のステップは、スクリプトをスケジュールに従って自動的に実行することです。
cronジョブでファイル転送をスケジュールする
スクリプトができたので、次のステップは、特定の時間に自動的に実行されるようにスケジュールすることです。
LinuxまたはmacOSを使用している場合、cronを使用してバックアップをスケジュールできます。毎日深夜にバックアップスクリプトを実行するcronジョブを設定する方法は次の通りです:
1. crontabを編集するために開いてください:
crontab -e
2. 毎日深夜にスクリプトを実行するための以下の行を追加してください:
0 0 * * * /path/to/your/backup.sh
イメージ21 – 毎日スクリプトを実行するためのCronジョブ
クロンジョブのフォーマットはminute hour day-of-month month day-of-week commandです。以下にいくつかの例を示します:
- 毎時実行:
0 * * * * /path/to/your/backup.sh - 毎週月曜日の午前9時に実行:
0 9 * * 1 /path/to/your/backup.sh - 毎月1日に実行:
0 0 1 * * /path/to/your/backup.sh
以上で終わりです!backup.shスクリプトは今後、スケジュールされた間隔で実行されます。
S3ファイル転送を自動化することは有効な方法です。特に、次のようなシナリオで特に便利です:
- 重要なデータの日次バックアップ
- 製品画像をウェブサイトに同期する
- ログファイルを長期保存用ストレージに移動する
- 更新されたウェブサイトファイルの展開
これらの自動化技術を使用すると、手動介入なしでファイル転送を処理する信頼性のあるシステムを構築できます。一度書いてしまえば、その後は忘れてしまえます。
次のセクションでは、aws s3 cp操作をより安全かつ効率的に行うためのベストプラクティスについて説明します。
Amazon S3 の cp 使用のベストプラクティス
aws s3 cpコマンドは使いやすいですが、問題が発生する可能性があります。
ベストプラクティスに従うと、一般的な落とし穴を回避し、パフォーマンスを最適化し、データを安全に保つことができます。これらのプラクティスを探って、ファイル転送操作を効率的に行いましょう。
効率的なファイル管理
S3を使用する際は、ファイルを論理的に整理することで将来の時間と頭痛を節約できます。
まず、一貫したバケットとプレフィックスの命名規則を確立してください。たとえば、環境、アプリケーション、または日付でデータを分けることができます:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
この種の組織は、次の点で便利です:
- 必要なときに特定のファイルを見つける。
- 適切なレベルでバケットポリシーとアクセス許可を適用する。
- 古いデータをアーカイブしたり削除したりするライフサイクルルールを設定する。
もう1つのヒント:大量のファイルを転送する場合は、まず小さなファイルをまとめて(zipやtarを使用して)アップロードすることを検討してください。これにより、S3へのAPIコールの数が減少し、コストが下がり、転送が高速化されます。
# 数千の小さなログファイルをコピーする代わりに # まずそれらをtarにまとめてからアップロードする tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
大容量データ転送の処理
大きなファイルまたは多数のファイルをコピーする場合、プロセスを信頼性が高く効率的にするためのいくつかのテクニックがあります。
スクリプトで実行する際に --quiet フラグを使用して出力を抑制できます:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
これにより各ファイルの進行状況情報が抑制され、ログがより管理しやすくなります。また、わずかにパフォーマンスが向上します。
非常に大きなファイルの場合は、マルチパートアップロードを使用することを検討してください。--multipart-thresholdフラグを使用します:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
上記の設定は、AWS CLIに対して、100MBを超えるファイルをアップロードのために複数のパートに分割するよう指示します。これにより、いくつかの利点があります:
- 接続が切断された場合、影響を受けたパートのみを再試行すればよいです。
- パーツを並行してアップロードすることで、スループットを向上させる可能性があります。
- 大容量アップロードを一時停止して再開することができます。
データをリージョン間で転送する際には、アップロードを高速化するためにS3トランスファーアクセラレーションの利用を検討してください:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
これにより、Amazonのエッジネットワークを経由して転送が行われ、リージョン間の転送速度が大幅に向上する可能性があります。
セキュリティの確保
クラウドでデータを扱う際には、セキュリティを常に最優先事項としてください。
まず、IAMのアクセス許可が最小特権の原則に従っていることを確認してください。各タスクに必要な特定のアクセス許可のみを付与してください。
以下は、ユーザーに割り当てることができるポリシーの例です:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
このポリシーは、”my-bucket”内の”backups”プレフィックスにのみファイルのコピーを許可します。
セキュリティを強化する別の方法は、機密データの暗号化を有効にすることです。アップロード時にサーバーサイドで暗号化を指定できます:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
または、さらにセキュリティを強化するために、AWS Key Management Service (KMS) を使用します:
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
ただし、非常に機密性の高い操作の場合は、VPC エンドポイントを使用して S3を検討してください。これにより、トラフィックがAWSネットワーク内に保持され、公共インターネットを完全に回避できます。
次のセクションでは、このコマンドを使用しているときに遭遇する可能性のある一般的な問題のトラブルシューティング方法を学びます。
AWS S3 cp エラーのトラブルシューティング
確かなことは、aws s3 cpを使用しているときに時々問題に直面することがあるということです。しかし、一般的なエラーとその解決策を理解することで、物事が計画通りに進まないときに時間とイライラを節約できます。
このセクションでは、最も頻繁に発生する問題とその修正方法を示します。
一般的なエラーと修正
エラー: “アクセス拒否”
これはおそらく、遭遇する最も一般的なエラーです:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
これは通常、次の3つのうちのいずれかを意味します:
- 操作を実行するための十分な権限が IAM ユーザーにありません。
- バケットポリシーがアクセスを制限しています。
- AWS 資格情報の有効期限が切れています。
トラブルシューティング方法:
- 必要な
s3:PutObject(アップロード用)またはs3:GetObject(ダウンロード用)アクセス許可を持っていることを確認するために IAM の権限を確認してください。 - バケットポリシーがアクションを制限していないことを確認してください。
- 有効期限が切れている場合は、
aws configureを実行して資格情報を更新してください。
Error: “No such file or directory”
このエラーは、コピーしようとしているローカルファイルやディレクトリが存在しない場合に発生します:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
解決策は簡単です – ファイルパスを注意深く確認してください。パスは大文字と小文字を区別するので、それを考慮してください。また、相対パスを使用する際には正しいディレクトリにいることを確認してください。
Error: “The specified bucket does not exist”
このエラーが表示される場合:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
以下を確認してください:
- バケット名に誤植がないかどうか。
- 適切なAWSリージョンを使用しているかどうか。
- バケットが実際に存在しているか(削除されている可能性があります)。
正しい名前を確認するためにaws s3 lsを使用してすべてのバケットをリストできます。
エラー: “接続タイムアウト”
ネットワークの問題が接続タイムアウトを引き起こす可能性があります:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
これを解決するには:
- インターネット接続を確認してください。
- 大きなファイルを使用するか、大きなファイルの場合はマルチパートアップロードを有効にしてみてください。
- パフォーマンスの向上のためにAWS Transfer Accelerationを使用することを検討してください。
アップロードの失敗の処理
大きなファイルを転送する際にエラーが発生する可能性が高いです。その場合は、エラーを適切に処理するようにしてください。
例えば、スクリプトでエラーの診断を容易にするために--only-show-errorsフラグを使用できます:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
これにより、成功した転送メッセージは抑制され、エラーのみが表示されるため、大きな転送のトラブルシューティングが容易になります。
中断された転送を処理するために、--recursive コマンドは、宛先に同じサイズのファイルが既に存在する場合、自動的にスキップします。ただし、より徹底的にするために、あなたはAWS CLI の組み込みのリトライ機能を使用できます、これらの環境変数を設定することでネットワークの問題に対応します:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
これは、AWS CLI に失敗した操作を最大 5 回まで自動的にリトライするよう指示します。
しかし、非常に大きなデータセットの場合は、cp の代わりに aws s3 sync を使用することを検討してください。これは中断の処理に優れています:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
「sync」コマンドは、既に宛先にあるものと異なるファイルのみを転送し、中断された大容量転送を再開するのに最適です。
これらの一般的なエラーを理解し、スクリプトで適切なエラーハンドリングを実装すれば、S3コピー操作ははるかに堅牢で信頼性の高いものになります。
AWS S3 cpをまとめる
最後に、aws s3 cpコマンドは、ローカルファイルをS3にコピーしたりその逆を行うための簡単な方法です。
この記事で全てを学びました。基本から環境構築までを学び、ファイルをコピーするためのスケジュール化された自動スクリプトを作成しました。大きなファイルを移動する際の一般的なエラーや課題にどう対処するかも学びました。
開発者、データプロフェッショナル、またはシステム管理者の場合、このコマンドは役立つと思います。それに慣れる一番の方法は、定期的に使用することです。基本を理解し、その後は仕事の煩わしい部分を自動化するために時間を費やしてください。
AWSについてさらに学ぶには、DataCampの以下のコースをフォローしてください:
DataCampを使用してAWS認定試験に備えることもできます – AWS Cloud Practitioner (CLF-C02)。