













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
しかし、驚いたことに、テストは失敗しており、要素を見つけることができず、コンソールログでNoSuchElementExceptionが発生しました。私はそのエラーを見て不快に感じました。それはクリックしようとしていた単純なボタンであり、複雑さはありませんでした。
さらに問題を分析し、DOMを展開してルート要素をチェックすると、ボタンのセレクタが#shadow-root(open)ツリーノード内にあることがわかりました。これは、シャドウDOM要素として異なる方法で処理する必要があることを意味します。
このSelenium WebDriverチュートリアルでは、シャドウDOM要素について説明し、Selenium WebDriverでシャドウDOMを自動化する方法を説明します。SeleniumでシャドウDOMを自動化する前に、まずシャドウDOMとは何か、そしてなぜ使用されるのかを理解しましょう。
シャドウDOMとは何か?
シャドウDOMは、ウェブブラウザがメインドキュメントのDOMツリーに配置せずにDOM要素をレンダリングできる機能です。これにより、開発者とブラウザの到達範囲が分離されます。開発者はネストされた要素と同じ方法でシャドウDOMにアクセスすることができず、ブラウザはネストされた要素と同じ方法でそのコードをレンダリングおよび変更できます。
シャドウDOMは、HTMLドキュメント内のカプセル化を実現する方法です。それを実装することで、ドキュメントの一部のスタイルと動作を隠し、同じドキュメントの他のコードから分離し、干渉がないようにすることができます。
シャドウDOMは、通常のDOMツリーの要素に隠れたDOMツリーを添付できる機能です。シャドウDOMツリーはシャドウルートから始まり、その下に通常のDOMと同じ方法で任意の要素を添付できます。
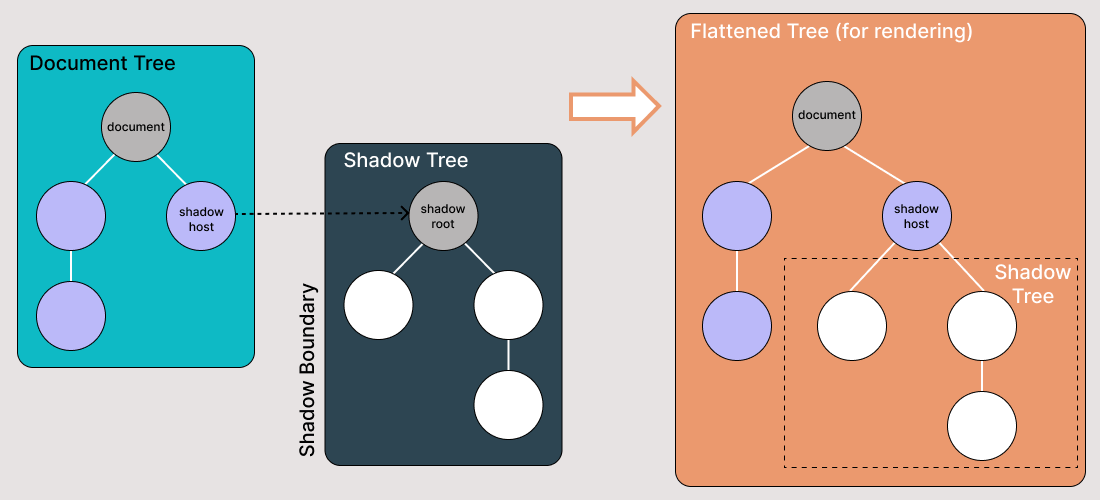
シャドウ DOM の用語について知っておくべきポイントがいくつかあります:
- シャドウホスト: シャドウ DOM が接続されている通常の DOM ノード
- シャドウツリー: シャドウ DOM 内の DOM ツリー
- シャドウ境界は シャドウ DOM が終わり、通常の DOM が始まる場所です。
- シャドウルート: シャドウツリーのルートノード
シャドウ DOM の使用法とは?
シャドウ DOM はカプセル化のために役立ちます。コンポーネントは、メインドキュメントから意図せずアクセスできない独自の「シャドウ」DOM ツリーを持つことができ、ローカルスタイルルールなどを持つことができます。
シャドウ DOM の主要な特性は以下の通りです:
- 独自の ID スペースを持つ
- メインドキュメントの JavaScript セレクターからは見えない、たとえば querySelector
- メインドキュメントからではなく、シャドウツリーからのスタイルのみを使用
Selenium WebDriver を使用してシャドウ DOM 要素を検索する
Selenium のセレクタを使用してシャドウ DOM 要素を検索しようとすると、NoSuchElementException が発生します。これは、DOM に直接アクセスできないためです。
シャドウ DOM のセレクタにアクセスするための以下の戦略を使用します:
- JavaScriptExecutor を使用する。
- Selenium WebDriver の
getShadowDom()メソッドを使用する。
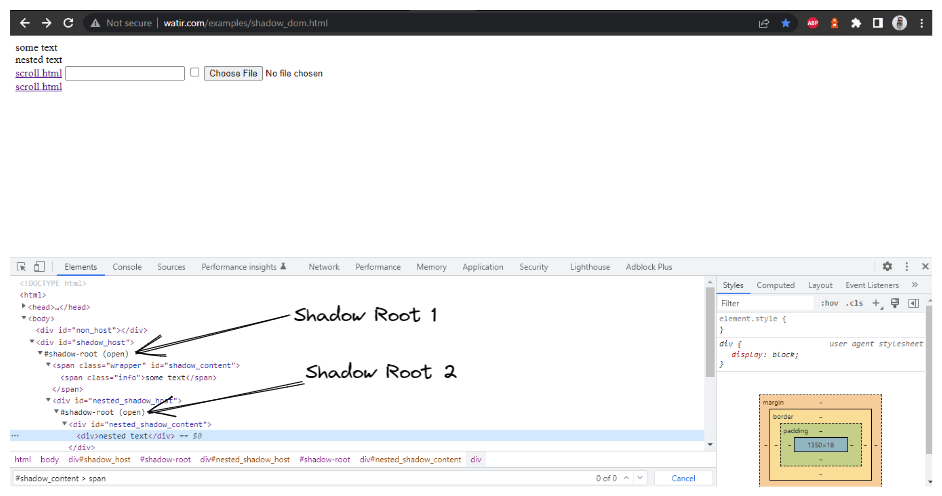
このブログセクションでは、SeleniumでShadow DOMを自動化する方法について説明します。例としてWatir.comのホームページを取り上げ、Selenium WebDriverを使用してshadow domおよびネストされたshadow domのテキストをアサートする方法を説明します。テキスト-> some textに到達する前に、1つのシャドウルート要素があり、テキスト-> nested textに到達する前に2つのシャドウルート要素があります。
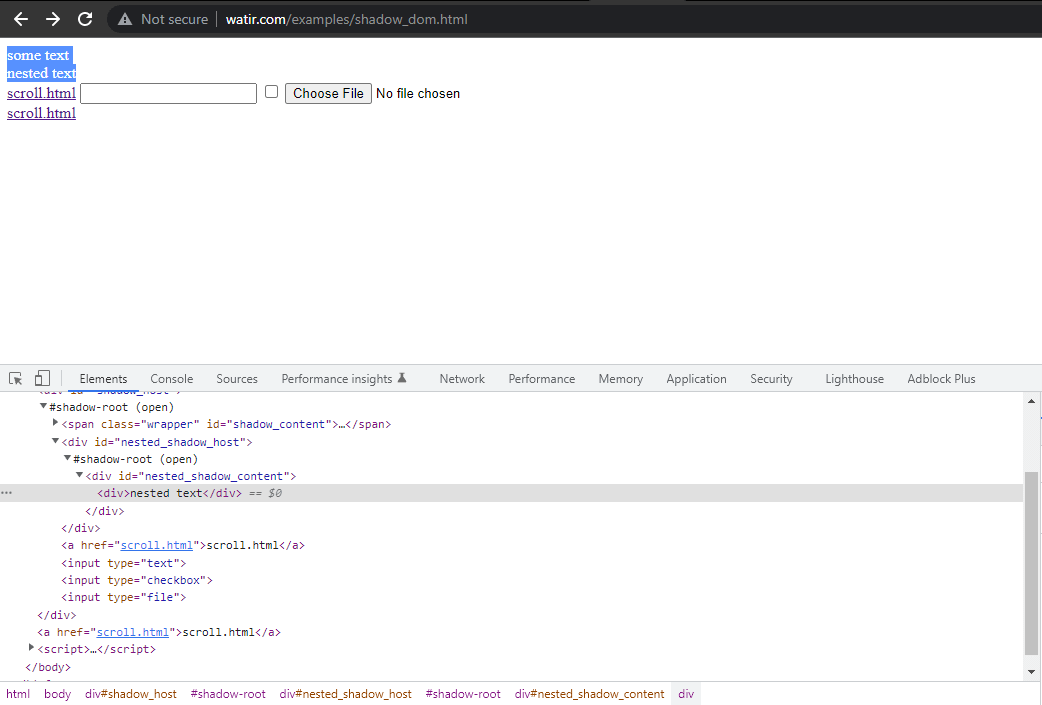
要素をcssSelector("#shadow_content > span")を使用して検索しようとすると、
それが検索されず、Selenium WebDriverはNoSuchElementExceptionをスローします。
これが、cssSelector(“#shadow_content > span”)を使用してテキストを取得しようとするHomepageクラスのコードのスクリーンショットです。

これが、テキスト(“some text”)をアサートしようとするテストのスクリーンショットです。
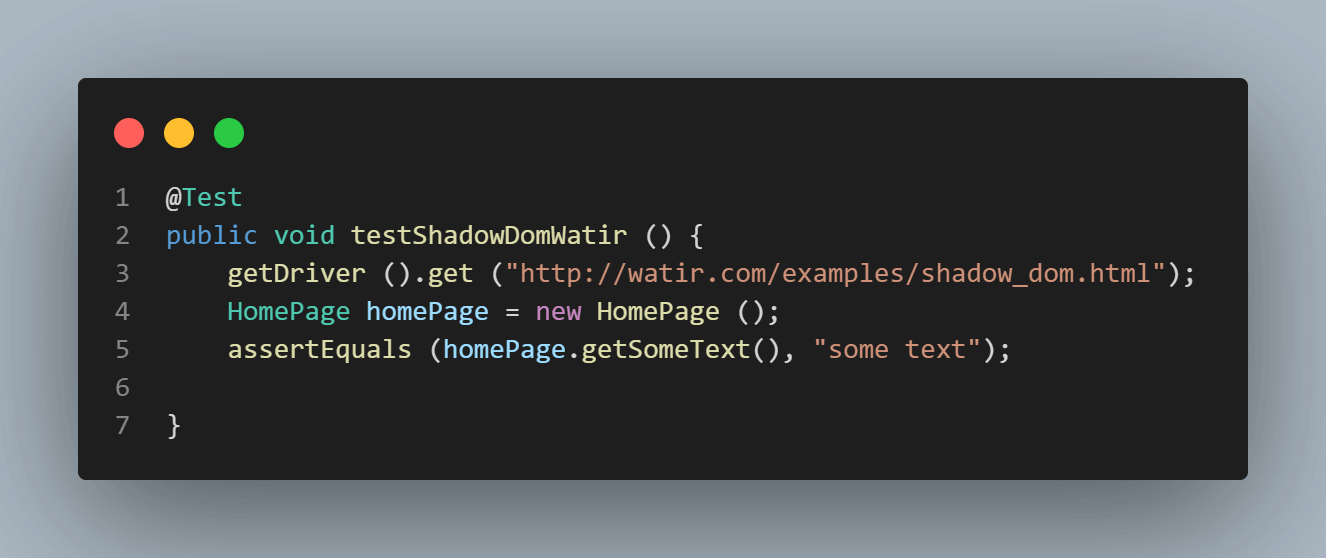
テストを実行するとNoSuchElementExceptionエラーが表示されます
テキストの要素を正しく検索するには、シャドウルート要素を経由する必要があります。そうしないと、ページ上の“some text”と”nested text”を検索できません。
Selenium WebDriverで’getShadowDom’メソッドを使用してShadow DOMを検索する方法
Selenium WebDriverのバージョン4.0.0以上では、getShadowRoot()メソッドが導入され、シャドウルート要素の検索が可能になりました。
ここにgetShadowRoot()メソッドの構文と詳細があります:
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.ドキュメントによると、getShadowRoot()メソッドは、ウェブコンポーネントのシャドウDOMにアクセスするための要素のシャドウルートの表現を返します。
シャドウルートが見つからない場合、NoSuchShadowRootExceptionをスローします。
テストを書き始める前に、コードについて話し合う前に、テストを書き、実行するために使用するツールについて説明しましょう。
以下のプログラミング言語とツールを使用してテストを書き、実行しました。
- プログラミング言語: Java 11
- ウェブオートメーションツール: Selenium WebDriver
- テストランナー: TestNG
- ビルドツール: Maven
- クラウドプラットフォーム: LambdaTest
Selenium WebDriverでシャドウDOMを見つけるためのスタート
以前の議論で述べたように、このSeleniumでのシャドウDOMプロジェクトはMavenで作成されています。TestNGはテストランナーとして使用されています。Mavenについてさらに学びたい場合は、SeleniumテストのためのMavenの始め方に関するこのブログをご覧ください。
プロジェクトが作成されたら、pom.xmlファイルにSelenium WebDriverおよびTestNGの依存関係を追加する必要があります。
依存関係のバージョンは、別のプロパティブロックで設定されています。これは保守性のために行われており、バージョンを更新する必要がある場合、pom.xmlファイル全体で依存関係を検索することなく簡単に行うことができます。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>さて、コードに移りましょう。このプロジェクトでは、コードの重複を減らし、テストケースの保守性を向上させるために、ページオブジェクトモデル(POM)が使用されています。
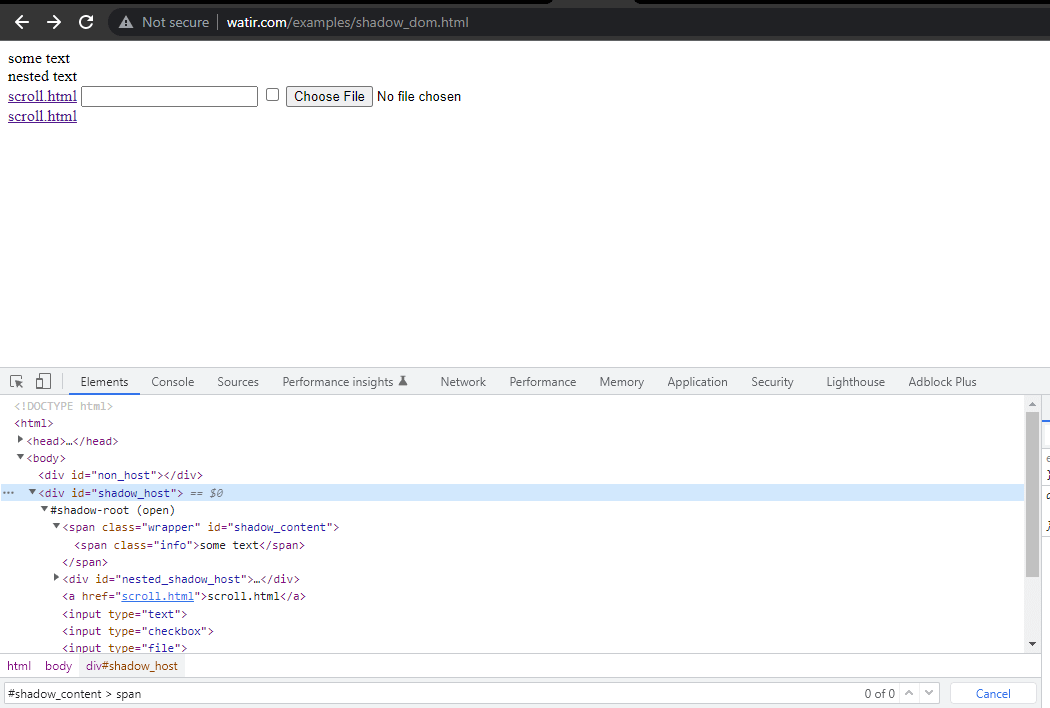
まず、「some text」と「nested text」のセレクタをHomePageで見つけることから始めます。
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}コードの解説
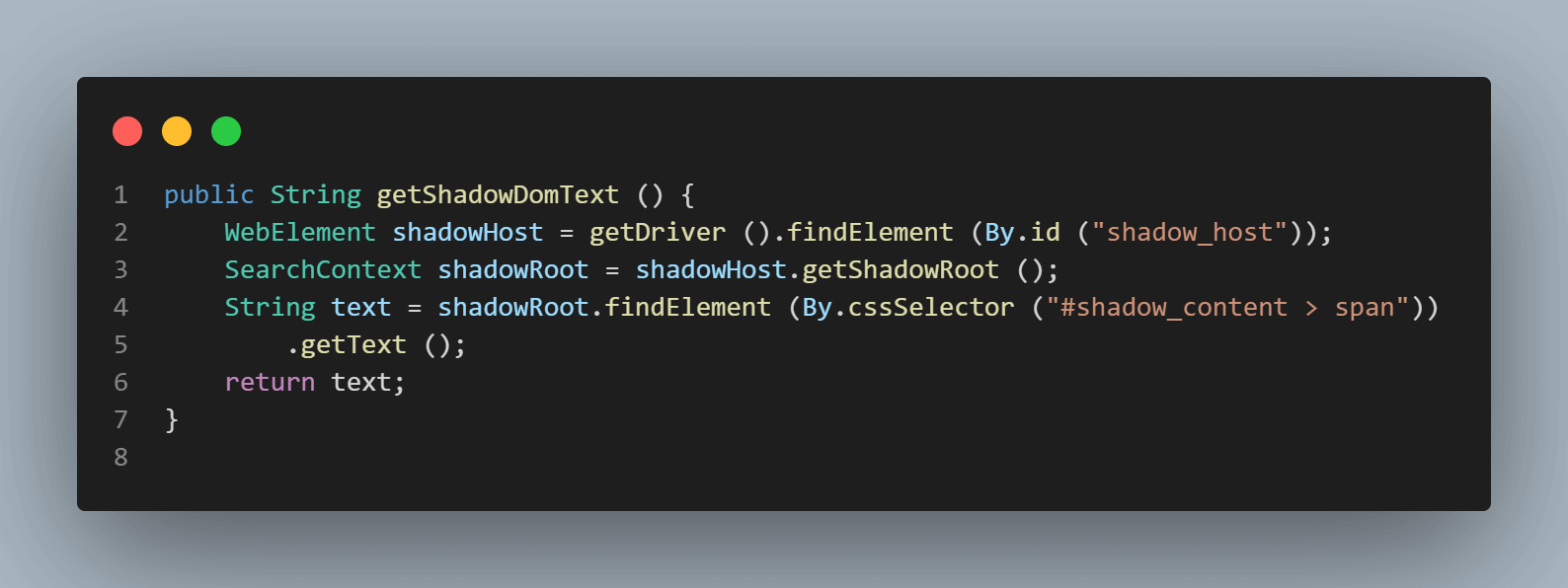
最初に位置づける要素は、セレクタ戦略でidを使用して、< div id = "shadow_host" >です。
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));次に、その隣の最初のシャドウルートをDOM内で検索します。これにはSearchContextインターフェースを使用しました。シャドウルートはgetShadowRoot()メソッドを使用して返されます。上記のスクリーンショットを確認すると、#shadow-root (open)は< div id = "shadow_host" >の隣にあります。
「some text,」というテキストを見つけるためには、通過する必要のあるシャドウDOM要素が1つだけです。
次のコード行がシャドウルート要素を取得するのに役立ちます。
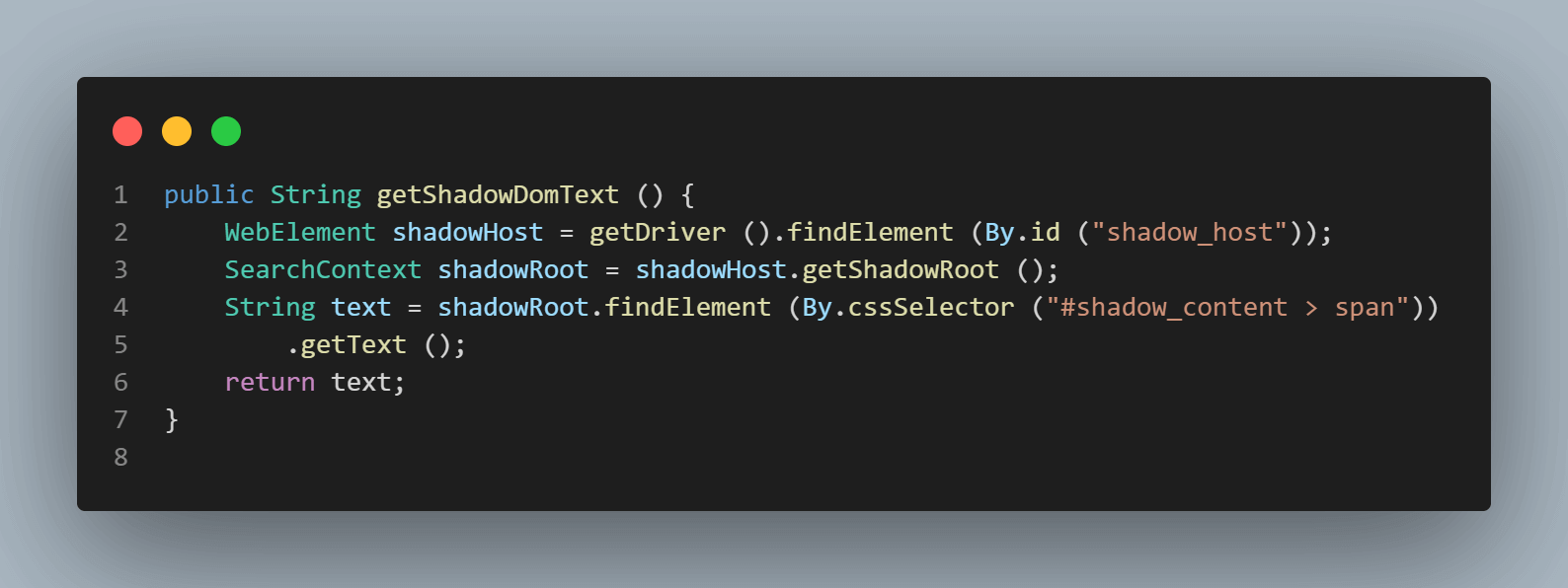
SearchContext shadowRoot = downloadsManager.getShadowRoot();シャドウルートが見つかると、「some text」というテキストを見つける要素を検索できます。次のコード行がテキストを取得するのに役立ちます。
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();次に、「ネストされたテキスト,」のロケータを見つけましょう。これはネストされたシャドウルート要素を持っています。そして、その要素をどのように特定するかを調べましょう。
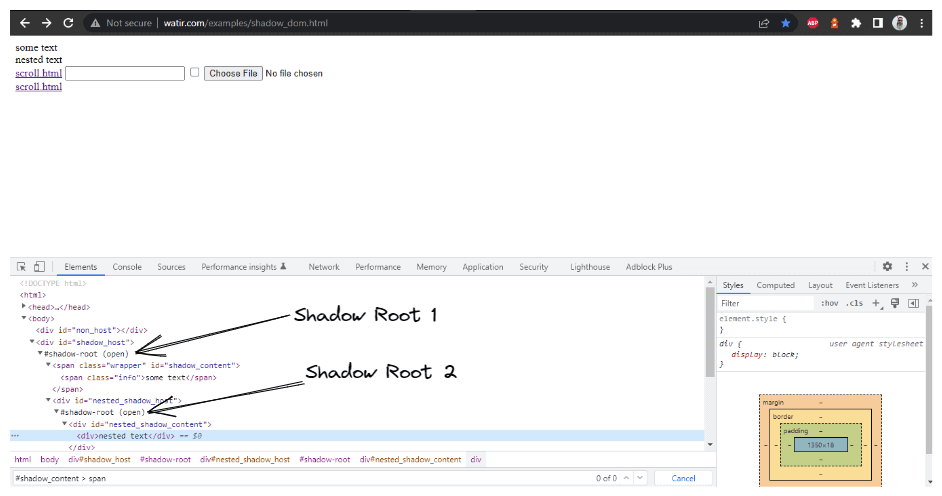
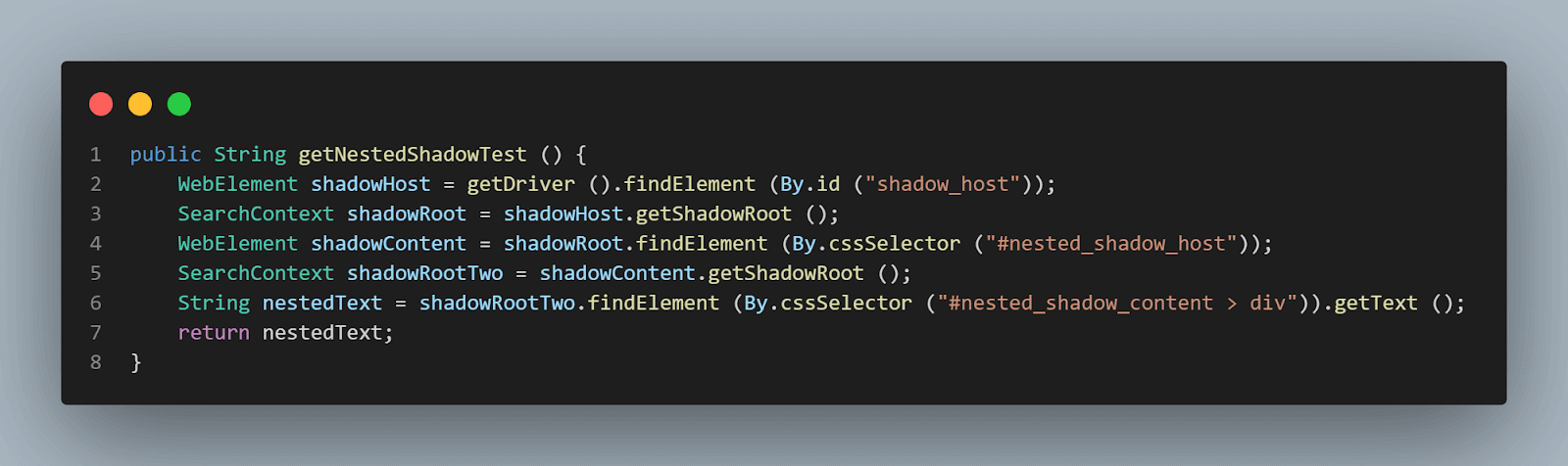
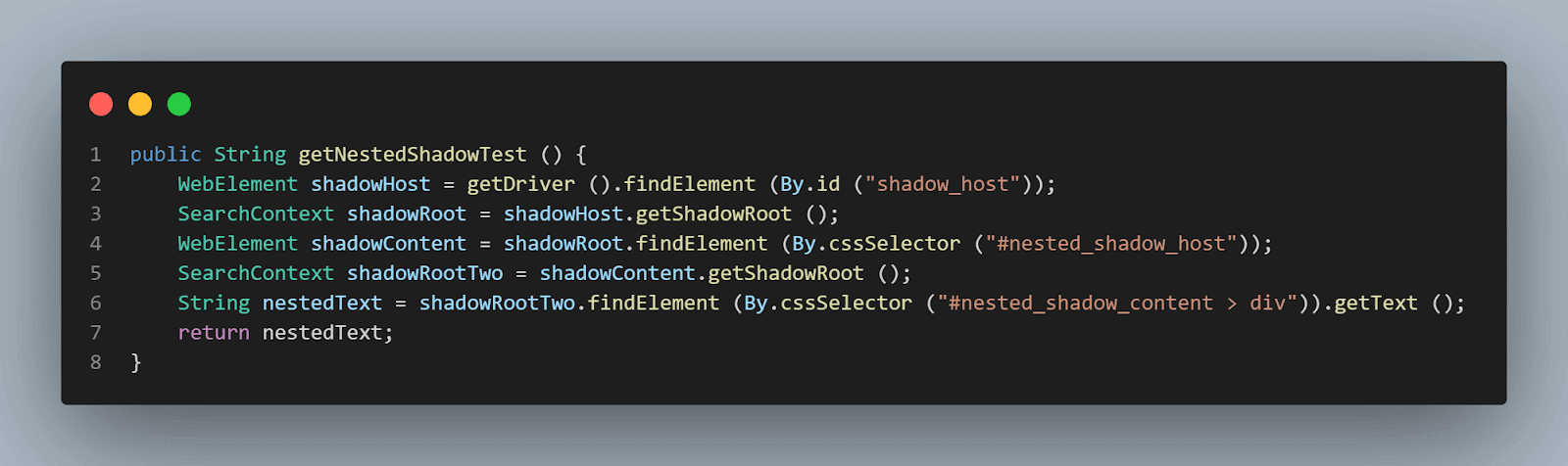
getNestedShadowText() メソッド:
上記のセクションで議論したように、最初に
コード< div id = "shadow_host" >をid検索戦略を使用して特定する必要があります。
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));次に、getShadowRoot()メソッドを使用してシャドウルート要素を見つけます。シャドウルート要素を取得したら、cssSelectorを使用して2番目のシャドウルートを特定するために探し始める必要があります:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));続いて、getShadowRoot()メソッドを使用して2番目のシャドウルート要素を見つけます。最後に、実際の要素を特定してテキスト「ネストされたテキスト」を取得する時が来ました。
以下のコード行は、テキストを特定するのに役立ちます:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"流暢な方法でコードを書く
このブログのシャドウDOM in Seleniumの上記セクションでは、実際の要素を特定するために長い道のりをたどる必要があり、WebElement および SearchContextインターフェースの複数の初期化を行い、単一の要素を特定するために複数行のコードを書く必要がありました。
この全体のコードを流暢な方法で書くこともでき、その方法は以下の通りです。
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}Fluent Interfaceの設計は、メソッドチェーンに大きく依存しています。Fluent Interfaceパターンは、技術的な理解を伴わずにコードを読みやすくすることができるもので、この用語は2005年にEric EvansとMartin Fowlerによって最初に提唱されました。
これは、要素を検索するために実行するメソッドチェーンの方法です。
このコードは、上記のステップで行ったのと同じことを行います。
- まず、idを使用してshadow_host要素を検索し、次に
getShadowRoot()メソッドを使用してShadow Root要素を取得します。 - 次に、CSSセレクタを使用してnested_shadow_host要素を検索し、
getShadowRoot()メソッドを使用してShadow Root要素を取得します。 - 最後に、cssSelector – nested_shadow_content > divを使用して“ネストされたテキスト”を取得します。
JavaScriptExecutorを使用してSeleniumでShadow DOMを検索する方法
上記のコード例では、getShadowRoot()メソッドを使用して要素を検索しました。次に、Selenium WebDriverでJavaScriptExecutorを使用してShadow root要素を検索する方法を見てみましょう。
getNestedTextUsingJSExecutor() メソッドがHomePageクラス内に作成されました。ここでは、パラメータとして渡されたWebElementに基づいてShadow Root要素を展開します。DOM(上記のスクリーンショット参照)で見たように、テキストを取得する実際のコーディネータに到達する前に、2つのShadow Root要素を展開する必要があります – ネストされたテキスト。そのため、expandRootElement()メソッドが作成され、同じJavaScriptエグゼキューターコードを毎回コピー&ペーストする代わりに使用されます。
JavaScriptExecutorを使用してShadow root要素を返すSearchContextインターフェースを実装します。これは、パラメータで渡されたWebElementに基づいています。
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
getNestedTextUsingJSExecutor()メソッド
最初に特定する要素は、< div id = "shadow_host" >で、コーディネータ戦略 – idを使用しています。
次に、検索したshadow_host WebElementに基づいてRoot Elementを展開します。
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);Shadow Rootを展開した後、cssSelectorを使用して次のWebElementを検索します。
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);最後に、テキストを取得する実際の要素 – “ネストされたテキスト” を特定する時が来ました。
次のコード行がテキストの特定を支援します。
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();デモンストレーション
この記事のセクションでは、シャドウ DOM を使用したセレニウムのテストについて説明します。前のステップで見つけたロケータが必要なテキストを提供しているかを確認するために、簡単なテストを作成して実行しましょう。コードで書いたアサーションを実行して、コードが期待どおりに動作しているかを検証できます。
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}これは、期待どおりにテキストが表示されているかをアサートするための単純なテストです。TestNG の assertEquals() アサーションを使用して確認します。
実際の値として、ページからテキストを取得するために書いたメソッドを提供し、期待値として “some text” または “nested text” を渡します。
テストには 4 つの assertEquals ステートメントが含まれています。
- シャドウ DOM 要素を
getShadowRoot()メソッドを使用して確認:
- ネストされたシャドウ DOM 要素を
getShadowRoot()メソッドを使用して確認:
- ネストされたシャドウ DOM 要素を
getShadowRoot()メソッドを使用して流暢に書き込む:
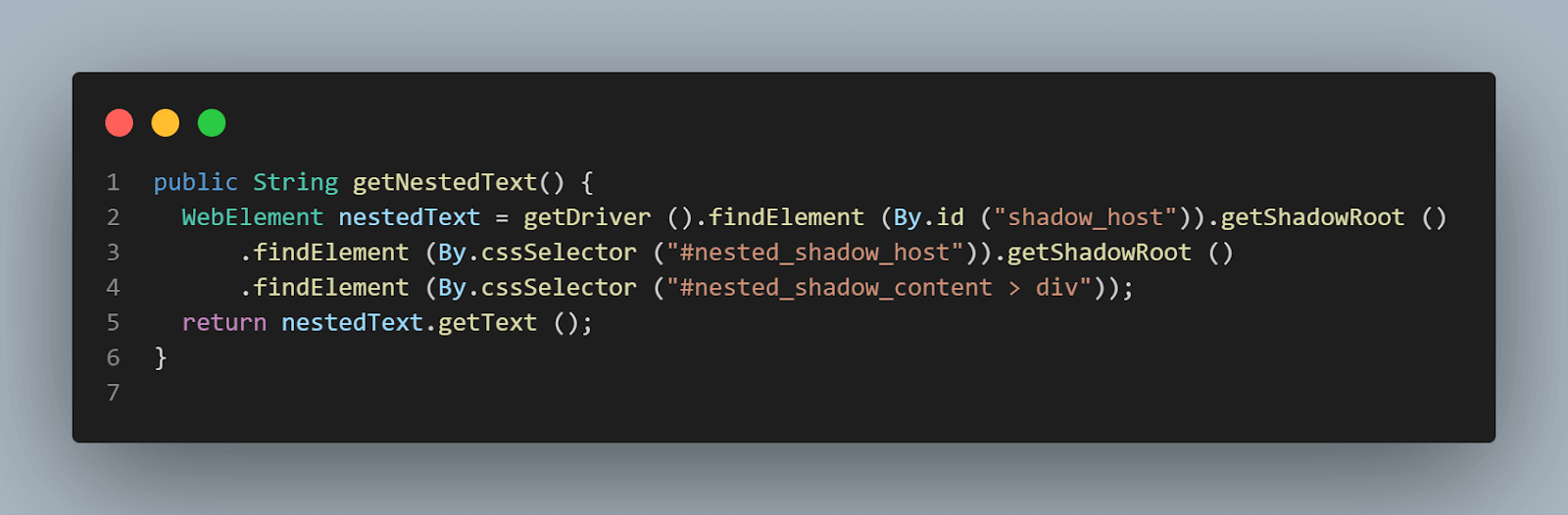
実行
シャドウ DOM を自動化するためのテストを実行する方法は 2 つあります:
- IDE から TestNG を使用
- CLI から Maven を使用
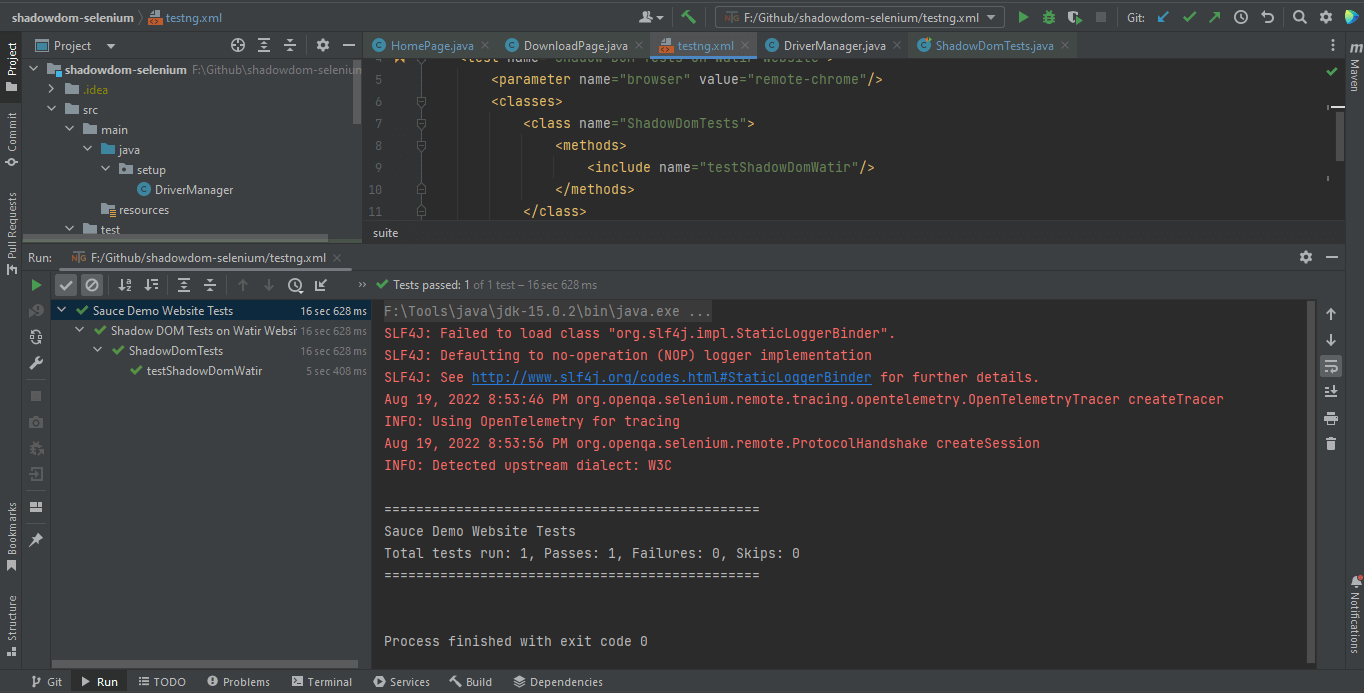
TestNG を使用したセレニウム WebDriver でのシャドウ DOM の自動化
TestNGをテストランナーとして使用しています。そのため、testng.xmlが作成され、それを右クリックして「…\testng.xml」を実行オプションを選択することでテストを実行します。ただし、テストを実行する前に、ユーザー名とアクセスキーをシステムプロパティから読み取っているため、実行設定にLambdaTestのユーザー名とアクセスキーを追加する必要があります。
LambdaTestは、3000以上のリアルブラウザとオペレーティングシステムのオンラインブラウザファームでクロスブラウザテストを提供し、Javaテストをローカルおよび/またはクラウドで実行できるようにします。JavaでSeleniumテストを加速し、並列テストを複数のブラウザとOS構成で実行することで、テスト実行時間を大幅に短縮できます。
- 以下に示すように、実行設定に値を追加してください:
- Dusername =
< LambdaTest username > - DaccessKey =
< LambdaTest access key >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
</suite>こちらは、Intellij IDEを使用してSeleniumでシャドウDOMをローカルで実行したときのスクリーンショットです。
Mavenを使用してSelenium WebDriverでシャドウDOMを自動化
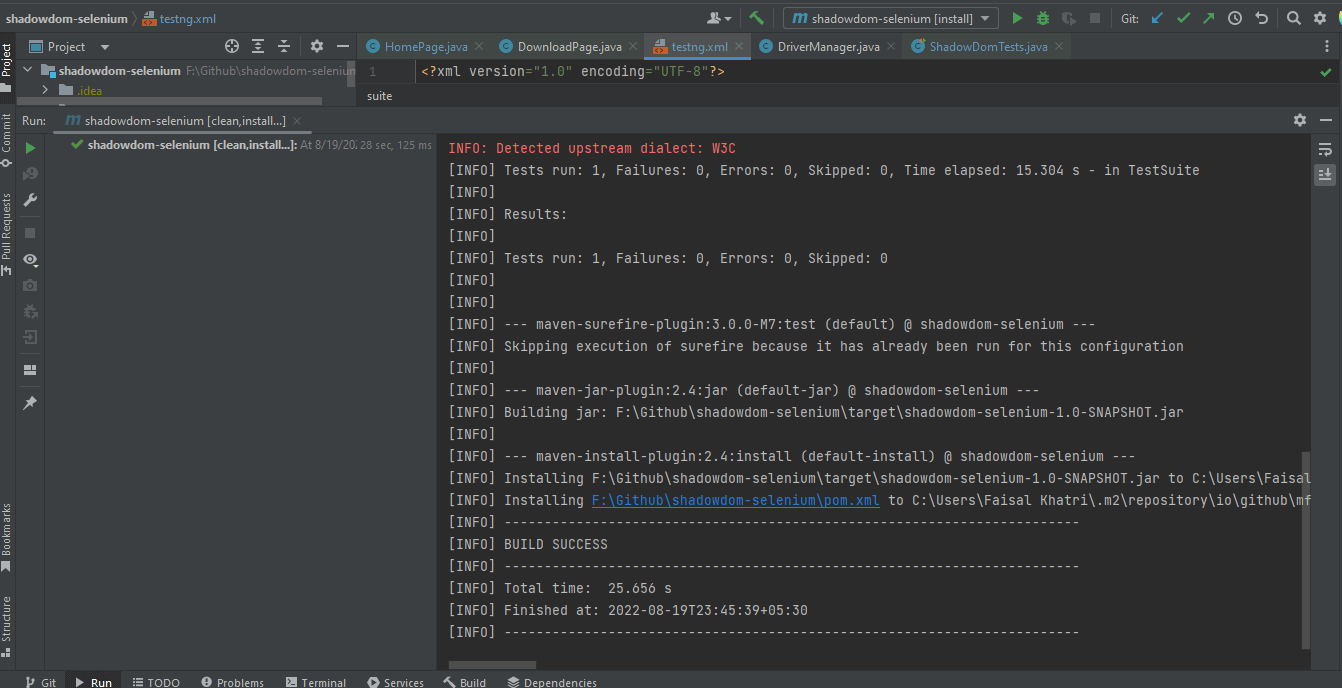
Mavenを使用してテストを実行するには、以下の手順を実行してSeleniumでシャドウDOMを自動化する必要があります。
- コマンドプロンプト/ターミナルを開きます。
- プロジェクトのルートフォルダに移動します。
- コマンドを入力します:
mvn clean install -Dusername=< LambdaTest username > -DaccessKey=< LambdaTest accessKey >.
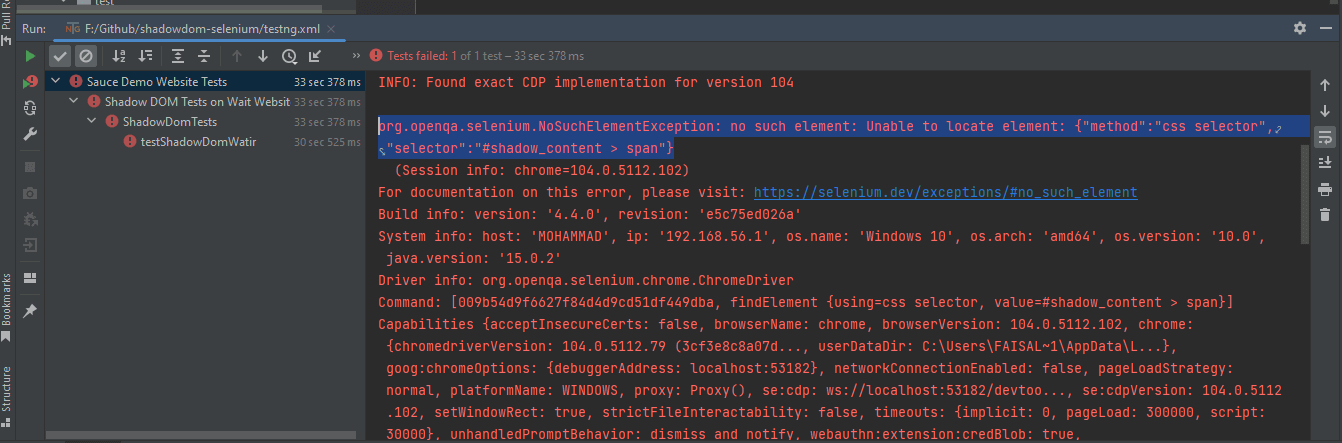
以下は、Mavenを使用してテストの実行状態を示しているIntelliJのスクリーンショットです。
テストが正常に実行されると、LambdaTestダッシュボードを確認して、すべての動画レコーディング、スクリーンショット、デバイスログ、およびテスト実行のステップバイステップの詳細な情報を見ることができます。以下のスクリーンショットをチェックしてください。これは、自動化アプリテストのダッシュボードについてのおおよその理解を与えてくれます。
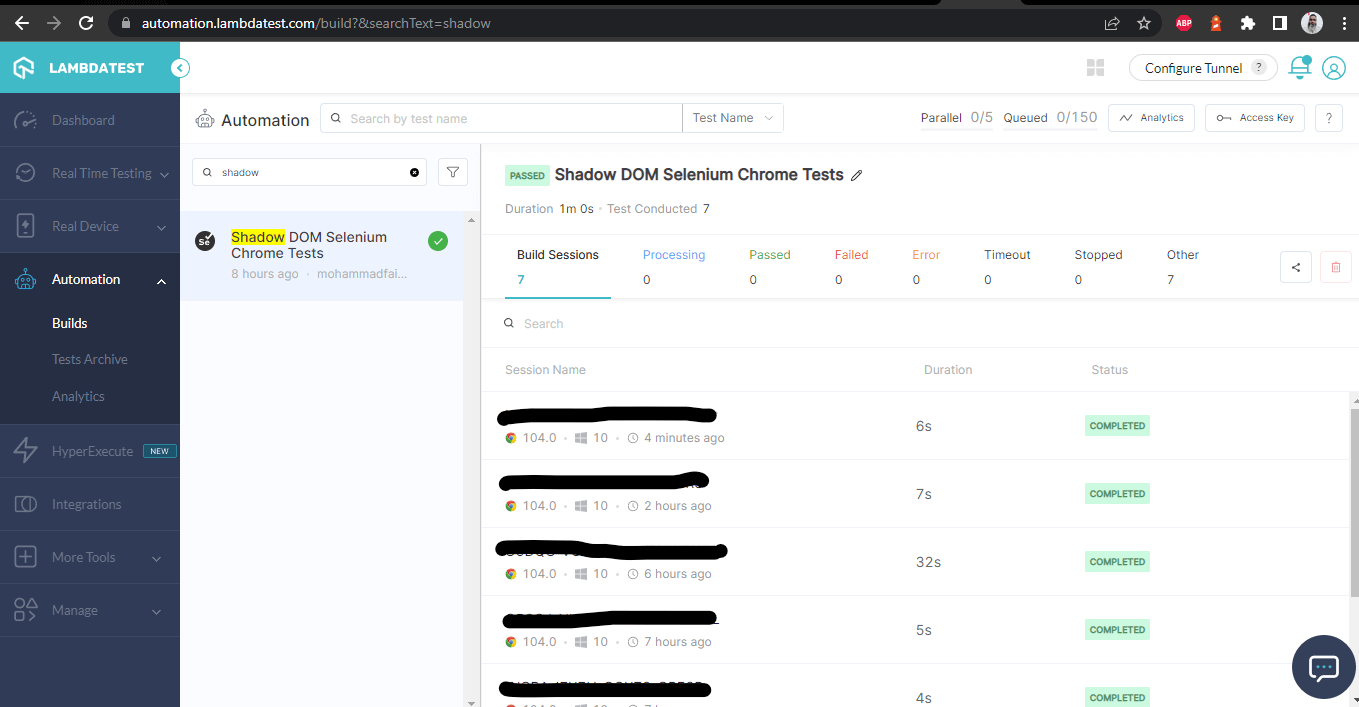 LambdaTestダッシュボード
LambdaTestダッシュボード
以下のスクリーンショットは、SeleniumでShadow DOMを自動化するために実行されたビルドとテストの詳細を示しています。再び、テスト名、ブラウザ名、ブラウザバージョン、OS名、対応するOSバージョン、および画面解像度はすべて、各テストについて正確に表示されています。
また、実行されたテストの動画もあり、デバイス上でテストがどのように実行されたかをより良く理解するために役立ちます。
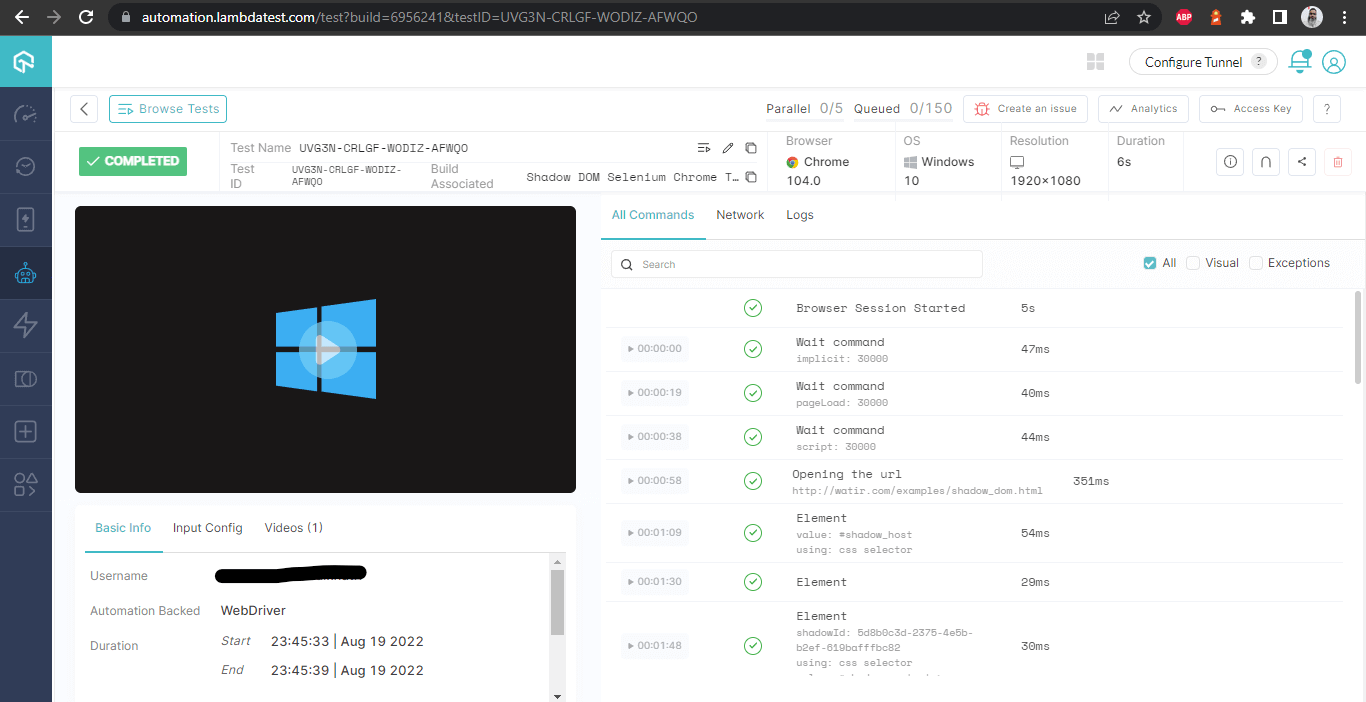 ビルド詳細
ビルド詳細
この画面は、テスターの観点から非常に役立つ詳細なメトリクスをすべて示しており、どのブラウザでどのテストが実行されたかに応じて、SeleniumでShadow DOMを自動化するためのログを表示することができます。
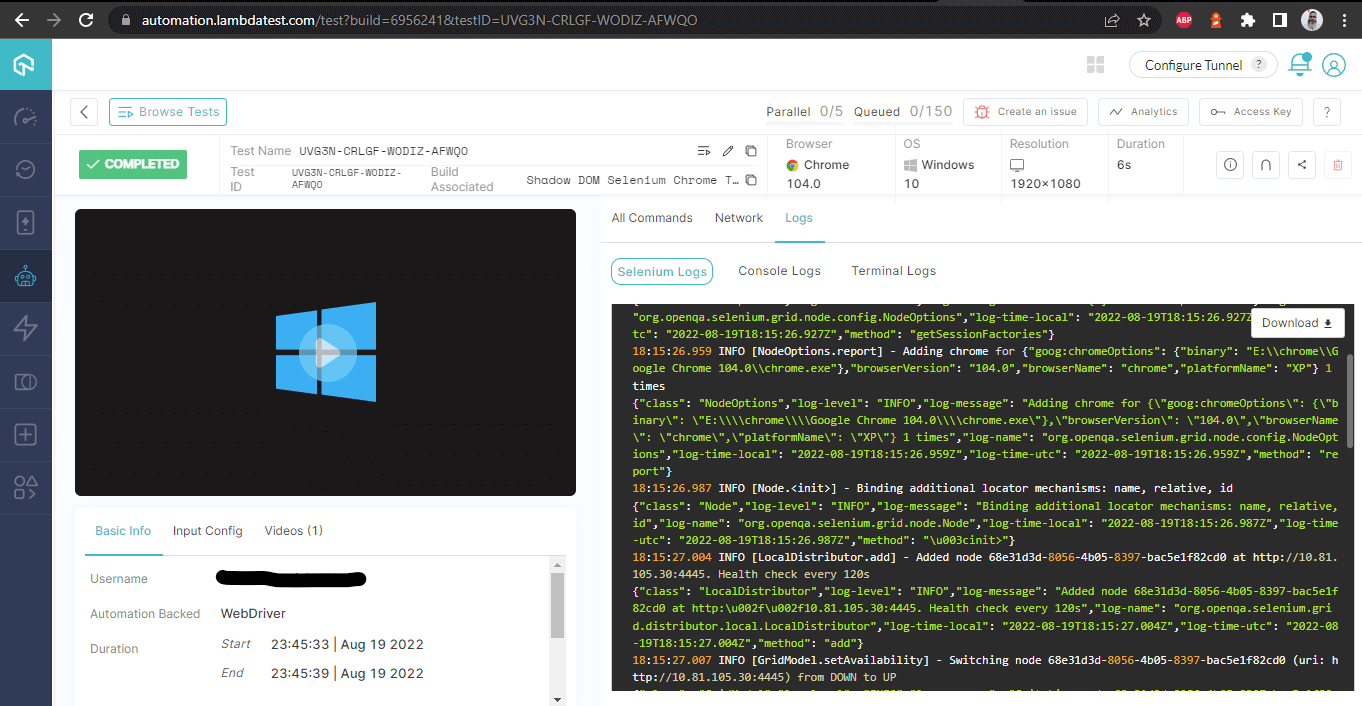 ビルド詳細 – ログ付き
ビルド詳細 – ログ付き
LambdaTest Analytics Dashboardで最新のテスト結果、そのステータス、および合格または不合格したテストの全体的な数にアクセスできます。さらに、テスト概要セクションで最近実行されたテストランのスナップショットを表示できます。
結論
このSeleniumでShadow DOMを自動化するブログでは、Shadow DOM要素を見つけて自動化する方法について説明し、Selenium WebDriverの4.0.0以降のバージョンで導入されたgetShadowRoot()メソッドを使用しました。
また、Selenium WebDriverのJavaScriptExecutorを使用してShadow DOM要素を検索して自動化する方法、およびSelenium WebDriverのログで実行されたテストの粒度の詳細を示すLambdaTestのプラットフォームでテストを実行する方法についても説明しました。
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
楽しいテストを!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver