













Introduzione
YOLOv8, sviluppato da Ultralytics nel 2023, è emerso come uno degli algoritmi di rilevamento degli oggetti unici nella serie YOLO e presenta significativi miglioramenti architetturali e prestazionali rispetto ai suoi predecessori, come YOLOv5. Questi miglioramenti includono una spina dorsale CSPNet per una migliore estrazione delle caratteristiche, un collo FPN+PAN per un miglior rilevamento degli oggetti multiscala e un passaggio a un approccio senza ancoraggio. Questi cambiamenti migliorano significativamente l’accuratezza, l’efficienza e l’usabilità del modello per il rilevamento degli oggetti in tempo reale.
Utilizzare una GPU con YOLOv8 può migliorare significativamente le prestazioni per compiti di rilevamento degli oggetti, garantendo una formazione e un’inferenza più veloci. Questa guida ti guiderà nella configurazione di YOLOv8 per l’uso con GPU, inclusa la configurazione, la risoluzione dei problemi e suggerimenti di ottimizzazione.
YOLOv8
YOLOv8 si basa sui suoi predecessori con un design avanzato della rete neurale e tecniche di addestramento per migliorare le prestazioni nel rilevamento degli oggetti. Unifica la localizzazione e la classificazione degli oggetti in un unico framework efficiente, bilanciando velocità e precisione. L’architettura comprende tre componenti chiave:
- Backbone: una backbone CNN altamente ottimizzata, potenzialmente basata su CSPDarknet, estrae caratteristiche multi-scala utilizzando strati efficienti come le convoluzioni separabili in profondità, garantendo alte prestazioni con un sovraccarico computazionale minimo.
- Neck: una Path Aggregation Network (PANet) migliorata affina e integra le caratteristiche multi-scala per rilevare meglio gli oggetti di diverse dimensioni. È ottimizzata per l’efficienza e l’uso della memoria.
- Head: la testa senza ancore prevede le bounding box, i punteggi di confidenza e le etichette di classe, semplificando le previsioni e migliorando l’adattabilità a forme e scale degli oggetti diverse.
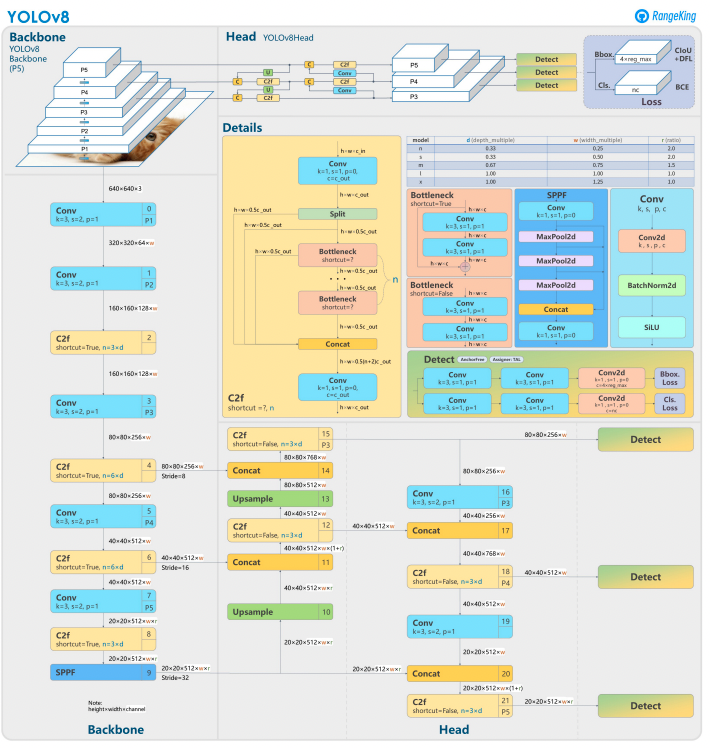
Queste innovazioni rendono YOLOv8 più veloce, più preciso e versatile per i compiti moderni di rilevamento degli oggetti. Inoltre, YOLOv8 introduce un approccio senza ancore per la previsione delle bounding box, allontanandosi dai metodi basati su ancore delle versioni precedenti.
Perché utilizzare una GPU con YOLOv8?
YOLOv8 (You Only Look Once, Versione 8) è un potente framework per il rilevamento degli oggetti. Sebbene possa funzionare su CPU, l’utilizzo di una GPU offre alcuni vantaggi chiave, come:
- Velocità: le GPU gestiscono i calcoli paralleli in modo più efficiente, riducendo i tempi di addestramento e inferenza.
- Scalabilità: dataset e modelli più grandi sono gestibili con le GPU.
- Prestazioni migliorate: il rilevamento degli oggetti in tempo reale diventa fattibile, consentendo applicazioni come veicoli autonomi, sorveglianza e elaborazione video in diretta.

Le GPU sono la scelta migliore per ottenere risultati più rapidi e gestire compiti più complessi con YOLOv8.
CPU vs.GPU
Mentre si lavora con YOLOv8 o qualsiasi modello di rilevamento degli oggetti, la scelta tra CPU e GPU può influire significativamente sulle prestazioni del modello sia per l’addestramento che per l’inferenza. Le CPU, come sappiamo, sono ottime per scopi generali e possono gestire efficacemente compiti più piccoli. Tuttavia, le CPU non riescono quando il compito diventa computazionalmente costoso. Compiti come il rilevamento degli oggetti richiedono velocità e calcolo parallelo, e le GPU sono progettate per gestire compiti di elaborazione parallela ad alte prestazioni. Pertanto, sono ideali per eseguire modelli di deep learning come YOLO. Ad esempio, l’addestramento e l’inferenza su una GPU possono essere 10–50 volte più veloci rispetto a una CPU, a seconda dell’hardware e delle dimensioni del modello.
| Aspect | CPU | GPU |
|---|---|---|
| Tempo di inferenza (per immagine) | ~500 ms | ~15 ms |
| Velocità di addestramento (epoche/ora) | ~2 epoche/ora | ~30 epoche/ora |
| Capacità di dimensione batch | Piccola (2-4 immagini) | Grande (16-32 immagini) |
| Prestazioni in tempo reale | No | Sì |
| Elaborazione parallela | Limitata | Eccellente (migliaia di core) |
| Efficienza energetica | Inferiore per compiti grandi | Superiore per carichi di lavoro paralleli |
| Efficienza dei costi | Adatto per piccoli compiti | Ideale per qualsiasi compito di deep learning |
La differenza diventa ancora più pronunciata durante l’addestramento, dove le GPU riducono drasticamente il numero di epoche rispetto alle CPU. Questo aumento di velocità consente alle GPU di elaborare set di dati più grandi e di eseguire il rilevamento di oggetti in tempo reale in modo più efficiente.
Prerequisiti per l’uso di YOLOv8 con GPU
Prima di configurare YOLOv8 per GPU, assicurati di soddisfare i seguenti requisiti:
1. Requisiti hardware
- GPU NVIDIA: YOLOv8 si basa su CUDA per l’accelerazione GPU, quindi avrai bisogno di una GPU NVIDIA con una capacità di calcolo CUDA di 6.0 o superiore.
- Memoria: Si consiglia almeno 8 GB di memoria GPU per set di dati moderati. Per set di dati più grandi, è preferibile avere 16 GB o più.
2. Requisiti software
- Python: Versione 3.8 o successiva.
- PyTorch: Installato con supporto GPU (tramite CUDA). Preferibilmente GPU NVIDIA.
- CUDA Toolkit e cuDNN: Assicurati che siano compatibili con la tua versione di PyTorch.
- YOLOv8: Installabile dal repository Ultralytics.
3. Requisiti del driver
- Scarica e installa i driver NVIDIA più recenti dal sito web NVIDIA.
- Controlla la disponibilità della tua GPU utilizzando
nvidia-smidopo l’installazione del driver.
Guida passo-passo per configurare YOLOv8 per GPU
1. Installa i driver NVIDIA
Per installare i driver NVIDIA:
- Identifica la tua GPU utilizzando il codice sottostante:
- Visita la pagina di download dei driver NVIDIA e scarica il driver appropriato.
- Segui le istruzioni di installazione per il tuo sistema operativo.
- Riavvia il computer per applicare le modifiche.
- Verifica l’installazione eseguendo:
- Questo comando visualizza le informazioni sulla GPU e conferma la funzionalità del driver.
2. Installa CUDA Toolkit e cuDNN
Per utilizzare YOLOv8, è necessario selezionare la versione appropriata di PyTorch, che a sua volta richiede una versione di CUDA.
Passaggi per installare il CUDA Toolkit
- Scarica la versione appropriata del CUDA Toolkit dal sito sviluppatori NVIDIA.
- Installa il CUDA Toolkit e imposta le variabili d’ambiente (ad es.
PATH,LD_LIBRARY_PATH). - Verifica l’installazione eseguendo:
Assicurati di avere l’ultima versione di CUDA per consentire a PyTorch di utilizzare efficacemente la GPU
Passaggi per installare cuDNN
- Scarica cuDNN dal sito sviluppatori NVIDIA.
- Estrai i contenuti e copiali nelle cartelle CUDA corrispondenti (ad esempio,
bin,include,lib). - Assicurati che la versione di cuDNN corrisponda all’installazione di CUDA.
3. Installa PyTorch con il Supporto GPU
Per installare PyTorch con il supporto GPU, visita la pagina Get Started di PyTorch e seleziona il comando di installazione appropriato. Per esempio:
4. Installa ed Esegui YOLOv8
Installa YOLOv8 seguendo questi passaggi:
- Installa Ultralytics per lavorare con yolov8 e importare le librerie necessarie
- Esempio di Script in Python:
- Esempio per la riga di comando:
5. Verifica la configurazione della GPU in YOLOv8
Usa il seguente comando Python per controllare se la tua GPU è rilevata e se CUDA è abilitato:
6. Addestra o esegui inferenza con GPU
Specifica il dispositivo come cuda nei tuoi comandi di addestramento o inferenza:
Esempio di riga di comando
Valida il modello personalizzato
Esempio di script Python
Perché i Droplet GPU di DigitalOcean?
I droplet GPU di DigitalOcean sono progettati per gestire compiti di AI e machine learning ad alte prestazioni. Gli H100 alimentano questi Droplet GPU per offrire velocità eccezionali e capacità di elaborazione parallela, rendendoli ideali per addestrare ed eseguire modelli YOLOv8 in modo efficiente. Inoltre, questi droplet sono preinstallati con l’ultima versione di CUDA, garantendo che tu possa iniziare a sfruttare l’accelerazione GPU senza perdere tempo in configurazioni manuali. Questo ambiente semplificato ti consente di concentrarti completamente sull’ottimizzazione dei tuoi modelli YOLOv8 e sull’espansione dei tuoi progetti senza sforzo.
Risoluzione dei problemi comuni
1. YOLOv8 non utilizza la GPU
- Verifica la disponibilità della GPU usando
- Controlla la compatibilità di CUDA e PyTorch.
- Assicurati di specificare
device=0odevice='cuda'nei comandi o negli script. - Aggiorna i driver NVIDIA e reinstalla il CUDA Toolkit se necessario.
2. Errori di CUDA
- Assicurati che la versione del CUDA Toolkit corrisponda ai requisiti di PyTorch.
- Verifica l’installazione di cuDNN eseguendo script di diagnostica.
- Controlla le variabili d’ambiente per CUDA (
PATHeLD_LIBRARY_PATH).
3. Prestazioni scadenti
- Abilita l’addestramento a precisione mista per ottimizzare l’uso della memoria e la velocità:
- Riduci le dimensioni del batch se l’uso della memoria è troppo elevato.
- Assicurati di avere un sistema ottimizzato per l’esecuzione del processing parallelo e considera l’utilizzo del processing a batch nel tuo script di rilevamento per migliorare le prestazioni.
Domande frequenti
Come abilitare la GPU per YOLOv8?
Specificare device='cuda' o device=0 (se si utilizza la prima GPU) nei comandi o script durante il caricamento del modello. Questo abiliterà YOLOv8 a utilizzare la GPU per una computazione più veloce durante l’elaborazione e l’addestramento. Assicurarsi che la GPU sia correttamente configurata e rilevata.
Perché YOLOv8 non sta utilizzando la mia GPU?
YOLOv8 potrebbe non utilizzare la GPU se ci sono problemi con l’hardware, i driver o la configurazione. Per cominciare, verificare l’installazione di CUDA e la compatibilità con PyTorch. Aggiornare i driver se necessario. Assicurarsi che CUDA e CuDNN siano compatibili con l’installazione di PyTorch. Installare torchvision e controllare la configurazione che viene installata e utilizzata.
Inoltre, se PyTorch non è installato con il supporto GPU (ad esempio, una versione solo CPU), oppure il parametro device nei comandi di YOLOv8 potrebbe non essere esplicitamente impostato su cuda. Eseguire YOLOv8 su un sistema senza una GPU compatibile con CUDA o con una VRAM insufficiente può far sì che utilizzi di default la CPU.
Per risolvere questo problema, assicurati che la tua GPU sia compatibile con CUDA, verifica l’installazione di tutte le dipendenze necessarie, controlla che torch.cuda.is_available() restituisca True e specifica esplicitamente il parametro device='cuda' nei tuoi script o comandi YOLOv8.
Quali sono i requisiti hardware per YOLOv8 su GPU?
Per installare e eseguire efficacemente YOLOv8 su una GPU, si consiglia Python 3.7 o superiore, ed è necessaria una GPU compatibile con CUDA per utilizzare l’accelerazione GPU.
Si raccomanda una GPU NVIDIA moderna con almeno 8GB di memoria. Per set di dati di grandi dimensioni, è utile avere più memoria. Per prestazioni ottimali, si consiglia di utilizzare Python 3.8 o versioni successive, PyTorch 1.10 o superiore, e una GPU NVIDIA compatibile con CUDA 11.2+. La GPU dovrebbe idealmente avere almeno 8GB di VRAM per gestire set di dati moderati in modo efficiente, anche se più VRAM è vantaggiosa per set di dati più grandi e modelli complessi. Inoltre, il tuo sistema dovrebbe avere almeno 8GB di RAM e 50GB di spazio libero su disco per memorizzare i set di dati e facilitare l’addestramento del modello. Assicurarsi che queste configurazioni hardware e software siano corrette ti aiuterà a ottenere un addestramento e un’inferenza più rapidi con YOLOv8, specialmente per compiti computazionalmente intensivi.
Si prega di notare: le GPU AMD potrebbero non supportare CUDA, quindi scegliere una GPU NVIDIA per la compatibilità con YOLOv8 è essenziale.
Possono YOLOv8 funzionare su più GPU?
Per addestrare YOLOv8 utilizzando più GPU, è possibile utilizzare DataParallel di PyTorch o specificare direttamente più dispositivi (ad esempio, cuda:0,1). Per l’addestramento distribuito, YOLOv8 utilizza per impostazione predefinita il DistributedDataParallel (DDP) multi-GPU di PyTorch. Assicurati che il tuo sistema disponga di più GPU disponibili e specifica le GPU che desideri utilizzare nello script di addestramento o sulla riga di comando. Ad esempio, imposta --device 0,1,2,3 nella CLI o device=[0,1,2,3] in Python per utilizzare le GPU 0, 1, 2 e 3. YOLOv8 gestisce automaticamente l’addestramento parallelo sulle GPU specificate senza richiedere un argomento data_parallel esplicito. Mentre tutte le GPU vengono utilizzate durante l’addestramento, la fase di convalida di solito viene eseguita su una singola GPU per impostazione predefinita, poiché è meno intensiva in termini di risorse rispetto all’addestramento.
Come posso ottimizzare YOLOv8 per l’inferenza sulla GPU?
Abilita la precisione mista e regola le dimensioni dei batch per bilanciare memoria e velocità. A seconda del tuo dataset, addestrare YOLOv8 richiede una notevole potenza di calcolo per funzionare in modo efficiente. Usa una variante di modello più piccola o quantizzata (ad es., YOLOv8n o versioni quantizzate INT8) per ridurre l’uso della memoria e il tempo di inferenza. Nel tuo script di inferenza, imposta esplicitamente il parametro device su cuda per l’esecuzione su GPU. Utilizza tecniche come l’inferenza batch per elaborare più immagini simultaneamente e massimizzare l’utilizzo della GPU. Se applicabile, utilizza TensorRT per ottimizzare ulteriormente il modello per un’inferenza GPU più veloce. Monitora regolarmente la memoria della GPU e le prestazioni per garantire un uso efficiente delle risorse.
Il seguente frammento di codice ti permetterà di elaborare immagini in parallelo all’interno della dimensione del batch definita.
Se utilizzi la CLI, specifica la dimensione del batch con -b o –batch-size. Con Python, assicurati che l’argomento batch sia impostato correttamente quando inizializzi il tuo modello o chiami il metodo di previsione.
Come risolvo i problemi di memoria esaurita di CUDA?
Per risolvere gli errori di memoria esaurita di CUDA, riduci la dimensione del batch di validazione nel tuo file di configurazione YOLOv8, poiché batch più piccoli richiedono meno memoria GPU. Inoltre, se hai accesso a più GPU, considera di distribuire il carico di lavoro di validazione tra di esse utilizzando DistributedDataParallel di PyTorch o funzionalità simili, anche se ciò richiede conoscenze avanzate di PyTorch. Puoi anche provare a liberare la memoria cache utilizzando torch.cuda.empty_cache() nel tuo script e assicurarti che non ci siano processi non necessari in esecuzione sulla tua GPU. Aggiornare a una GPU con più VRAM o ottimizzare il tuo modello e il tuo dataset per l’efficienza della memoria sono ulteriori passi per mitigare tali problemi.
Conclusione
Configurare YOLOv8 per utilizzare una GPU è un processo semplice che può migliorare significativamente le prestazioni. Seguendo questa guida dettagliata, puoi accelerare l’addestramento e l’inferenza per i tuoi compiti di rilevamento degli oggetti. Ottimizza la tua configurazione, risolvi i problemi comuni e sblocca il pieno potenziale di YOLOv8 con l’accelerazione GPU.
Riferimenti
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection