













Ogni organizzazione guidata dai dati ha carichi di lavoro operativi e analitici. Un approccio best-of-breed emerge con diverse piattaforme dati, tra cui data streaming, data lake, data warehouse e soluzioni lakehouse, e servizi cloud. Un framework di formato tabella aperto come Apache Iceberg è essenziale nell’architettura enterprise per garantire una gestione e condivisione dei dati affidabile, una transizione senza interruzioni degli schemi, una gestione efficiente di dataset su larga scala e un’archiviazione efficiente dal punto di vista dei costi, fornendo al contempo un forte supporto per le transazioni ACID e le query di viaggio nel tempo.
Questo articolo esplora le tendenze di mercato; l’adozione di framework di formato tabella come Iceberg, Hudi, Paimon, Delta Lake e XTable; e la strategia di prodotto di alcuni dei principali fornitori di piattaforme dati come Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka/Flink), Amazon Athena e Google BigQuery.
Cos’è un Formato Tabella Aperto per una Piattaforma Dati?
Un formato tabella aperto aiuta a mantenere l’integrità dei dati, ottimizzare le prestazioni delle query e garantire una chiara comprensione dei dati memorizzati all’interno della piattaforma.
Il formato tabella aperto per le piattaforme dati include tipicamente una struttura ben definita con componenti specifici che garantiscono che i dati siano organizzati, accessibili e facilmente interrogabili. Un formato tabella tipico contiene il nome della tabella, i nomi delle colonne, i tipi di dati, le chiavi primarie e esterne, gli indici e le constraint.
Questo non è un concetto nuovo. Il tuo database preferito da decenni – come Oracle, IBM DB2 (addirittura su mainframe) o PostgreSQL – utilizza gli stessi principi. Tuttavia, i requisiti e le sfide sono cambiati un po’ per i data warehouse cloud, i data lake e i lakehouse riguardo alla scalabilità, le prestazioni e le capacità di query.
Vantaggi di un “Formato di Tabella Lakehouse” come Apache Iceberg
Ogni parte di un’organizzazione diventa guidata dai dati. La conseguenza è un insieme esteso di dati, la condivisione dei dati con prodotti di dati tra le unità aziendali e nuove richieste per l’elaborazione dei dati in quasi tempo reale.
Apache Iceberg fornisce molti vantaggi per l’architettura aziendale:
- Single storage: I dati sono memorizzati una volta (provenienti da diverse fonti di dati), riducendo costi e complessità
- Interoperabilità: Accesso senza sforzi di integrazione da parte di qualsiasi motore analitico
- Tutti i dati: Unifica i carichi di lavoro operativi e analitici (sistemi transazionali, big data logs/IoT/clickstream, API mobili, interfacce B2B terze parti, ecc.)
- Indipendenza dal fornitore: Lavora con qualsiasi motore di analisi preferito (indipendentemente se è in quasi tempo reale, batch o basato su API)
Apache Hudi e Delta Lake forniscono le stesse caratteristiche. Tuttavia, Delta Lake è principalmente guidato da Databricks come singolo fornitore.
Formato di Tabella e Interfaccia di Catalogo
È importante comprendere che le discussioni su Apache Iceberg o framework di formato tabella simili includono due concetti: il formato della tabella e l’interfaccia del catalogo! Come utente finale della tecnologia, hai bisogno di entrambi!
Il progetto Apache Iceberg implementa il formato ma fornisce solo una specifica (ma non un’implementazione) per il catalogo:
- Il formato della tabella definisce come i dati sono organizzati, memorizzati e gestiti all’interno di una tabella.
- L’interfaccia del catalogo gestisce i metadati delle tabelle e fornisce uno strato di astrazione per accedere alle tabelle in un data lake.
La documentazione di Apache Iceberg esplora i concetti in modo molto più dettagliato, basandosi su questo diagramma:
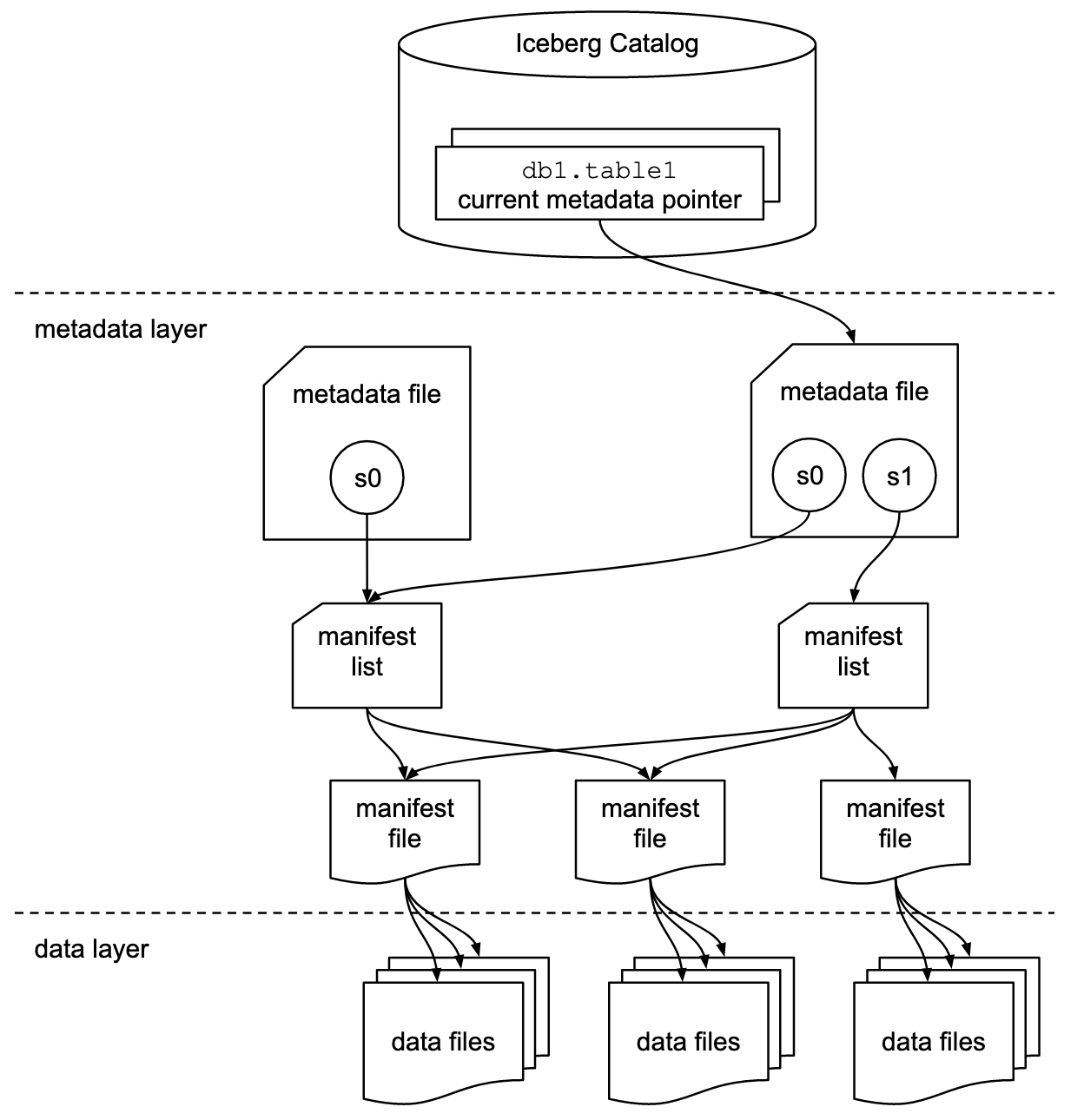
Le organizzazioni utilizzano varie implementazioni per l’interfaccia del catalogo di Iceberg. Ognuna si integra con diversi archivi dei metadati e servizi. Le principali implementazioni includono:
- Catalogo Hadoop: Utilizza il File System Distribuito di Hadoop (HDFS) o altri file system compatibili per memorizzare i metadati. Adatto per ambienti che utilizzano già Hadoop.
- Catalogo Hive: Si integra con Apache Hive Metastore per gestire i metadati delle tabelle. Ideale per gli utenti che sfruttano Hive per la gestione dei metadati.
- Catalogo AWS Glue: Utilizza AWS Glue Data Catalog per lo storage dei metadati. Progettato per gli utenti che operano all’interno dell’ecosistema AWS.
- Catalogo REST: Fornisce un’interfaccia RESTful per le operazioni di catalogo tramite HTTP. Permette l’integrazione con servizi di metadati personalizzati o di terze parti.
- Catalogo Nessie: Utilizza il Progetto Nessie, che offre un’esperienza simile a Git per la gestione dei dati.
La momentum e l’adozione crescente di Apache Iceberg motivano molti fornitori di piattaforme dati a implementare il proprio catalogo Iceberg. Discussione di alcune strategie nella sezione seguente riguardante le strategie dei fornitori di piattaforme dati e cloud, inclusi Polaris di Snowflake, Unity di Databricks e Tableflow di Confluent.
Supporto di Primo Livello per Iceberg vs. Connettore Iceberg
Si prega di notare che supportare Apache Iceberg (o Hudi/Delta Lake) significa molto di più che fornire un connettore e l’integrazione con il formato di tabella tramite API. I fornitori e i servizi cloud si differenziano per funzionalità avanzate come la mappatura automatica tra formati di dati, SLA critici, il viaggio indietro nel tempo, interfacce utente intuitive e così via.
Mettiamo un esempio: l’integrazione tra Apache Kafka e Iceberg. Sono stati già implementati vari connettori Kafka Connect. Tuttavia, ecco i vantaggi dell’uso di un’integrazione di primo livello con Iceberg (ad esempio, Tableflow di Confluent) rispetto all’uso di un semplice connettore Kafka Connect:
- Nessuna configurazione del connettore
- Nessun consumo tramite connettore
- Mantenimento integrato (compattazione, raccolta dei rifiuti, gestione degli snapshot)
- Evoluzione automatica dello schema
- Sincronizzazione del servizio di catalogo esterno
- Operazioni più semplici (in una soluzione SaaS completamente gestita, è serverless e non richiede alcuna scalatura o operazioni da parte dell’utente finale)
Benefici simili si applicano anche ad altre piattaforme dati e a una potenziale integrazione di primo livello rispetto alla fornitura di semplici connettori.
Formato aperto di tabella per un Data Lake/Lakehouse utilizzando Apache Iceberg, Apache Hudi e Delta Lake
L’obiettivo generale dei framework di formato di tabella come Apache Iceberg, Apache Hudi e Delta Lake è di rafforzare la funzionalità e l’affidabilità dei data lakes affrontando le sfide comuni associate alla gestione di dati su larga scala. Questi framework aiutano a:
- Migliorare la gestione dei dati
- Facilitare una gestione più semplice dell’ingestione, dello storage e del recupero dei dati nei data lakes.
- Permettere un’organizzazione e uno storage dei dati efficienti, sostenendo una migliore performance e scalabilità.
- Garantire la coerenza dei dati
- Fornire meccanismi per transazioni ACID, garantendo che i dati rimangano consistenti e affidabili anche durante operazioni di lettura e scrittura concorrenti.
- Supportare l’isolamento degli snapshot, permettendo agli utenti di visualizzare uno stato consistente dei dati in qualsiasi momento.
- Supporto per l’evoluzione dello schema
- Permette modifiche allo schema dei dati (come l’aggiunta, la rinomina o la rimozione di colonne) senza interrompere i dati esistenti o richiedere migrazioni complesse.
- Ottimizzazione delle prestazioni delle query
- Implementa strategie avanzate di indexing e partizione per migliorare la velocità e l’efficienza delle query sui dati.
- Abilita una gestione efficiente dei metadati per gestire grandi set di dati e query complesse in modo efficace.
- Miglioramento della governance dei dati
- Fornisce strumenti per un miglior tracciamento e gestione della lineage dei dati, della versioning e dell’auditing, che sono fondamentali per mantenere la qualità e la conformità dei dati.
Per affrontare questi obiettivi, framework di formato tabella come Apache Iceberg, Apache Hudi e Delta Lake aiutano le organizzazioni a costruire data lake e lakehouse più robusti, scalabili e affidabili. Gli ingegneri dei dati, gli scienziati dei dati e gli analisti aziendali utilizzano strumenti di analisi, AI/ML o reportistica/visualizzazione sopra il formato tabella per gestire e analizzare grandi volumi di dati.
Confronto tra Apache Iceberg, Hudi, Paimon e Delta Lake
Non farò un confronto tra i framework di formato tabella Apache Iceberg, Apache Hudi, Apache Paimon e Delta Lake qui. Molti esperti hanno già scritto su questo argomento. Ogni framework di formato tabella ha forza e vantaggi unici. Ma gli aggiornamenti sono necessari ogni mese a causa dell’evoluzione e dell’innovazione rapida, aggiungendo nuove migliorie e capacità all’interno di questi framework.
Ecco un riassunto di ciò che vedo in vari articoli di blog sulle quattro opzioni:
- Apache Iceberg: Si distingue nella evoluizione dello schema e della partizione, nella gestione efficiente dei metadati e nella ampia compatibilità con vari motori dielaborazione dei dati.
- Apache Hudi: Adatto meglio per l’ingestione di dati in tempo reale e gli upsert, con forti capacità di cattura dei dati di cambiamento e versioning dei dati.
- Apache Paimon: Un formato di lake che permette di costruire un’architettura di lakehouse in tempo reale con Flink e Spark per operazioni sia in streaming che batch.
- Delta Lake: Fornisce transazioni ACID robuste, applicazione dello schema e funzionalità di time travel, rendendolo ideale per mantenere la qualità e l’integrità dei dati.
Un punto decisionale chiave potrebbe essere che Delta Lake non è guidato da una vasta comunità come Iceberg e Hudi, ma principalmente da Databricks come singolo fornitore dietro di esso.
Apache XTable come Framework di interoperabilità Cross-Table che supporta Iceberg, Hudi e Delta Lake
I utenti hanno molte scelte. XTable, precedentemente noto come OneTable, è un altro framework di tabelle in incubazione sotto la licenza open-source Apache progettato per interagire senza interruzioni tra Apache Hudi, Delta Lake e Apache Iceberg.
Apache XTable:
- Fornisce interoperabilità omnidirezionale cross-table tra i formati di tabella del lakehouse.
- Non è un nuovo o separato formato. Apache XTable fornisce astrazioni e strumenti per la traduzione della metadata delle tabelle del lakehouse.
Forse Apache XTable è la risposta per fornire opzioni per piattaforme di dati specifiche e fornitori di cloud mantenendo al contempo una semplice integrazione e interoperabilità.
Ma attenzione: Un wrapper sopra diverse tecnologie non è una pallottola d’argento. Lo abbiamo visto anni fa quando è emerso Apache Beam. Apache Beam è un modello unificato open-source e un set di SDK specifici per linguaggi per definire ed eseguire flussi di lavoro di ingestion e processing dei dati. Supporta una varietà di motori di elaborazione in streaming, come Flink, Spark e Samza. Il driver principale di Apache Beam è Google, che permette la migrazione dei flussi di lavoro in Google Cloud Dataflow. Tuttavia, le limitazioni sono enormi, poiché un tale wrapper deve trovare il minimo comune multiplo delle funzionalità supportate. E il vantaggio chiave della maggior parte dei framework è il 20% che non si adatta a tale wrapper. Per questi motivi, ad esempio, Kafka Streams non supporta Apache Beam perché avrebbe richiesto troppe limitazioni di design.non supporta Apache Beam perché avrebbe richiesto troppe limitazioni di progettazione.
Adozione di Format Frameworks
Prime di tutto, siamo ancora nelle fasi iniziali. Siamo ancora nelle prime fasi. La maggior parte delle organizzazioni sta ancora valutando ma non le ha adottato in produzione in tutta l’organizzazione.
Flashback: Le Guerre dei Contenitori di Kubernetes contro Mesosphere contro Cloud Foundry
Il dibattito su Apache Iceberg mi ricorda delle guerre dei contenitori few years ago. Il termine “Guerra dei contenitori” si riferisce alla concorrenza delle tecnologie e piattaforme nella software development e IT infrastructure.
The three competing technologies were Kubernetes, Mesosphere, and Cloud Foundry. Here is where it went:

Cloud Foundry e Mesosphere erano precursori, ma Kubernetes ha comunque vinto la battaglia. Perché? Non ho mai capito tutte le dettagli tecnici e le differenze. Alla fine, se i tre framework sono abbastanza simili, tutto si riduce a:
- Adozione della comunità
- Tempistica corretta del rilascio delle funzionalità
- Marketing efficace
- Fortuna
- E alcuni altri fattori
Ma è utile per l’industria del software avere un framework open-source leader su cui costruire soluzioni e modelli di business invece di tre in competizione.
Presente: La guerra dei formati tabellari di Apache Iceberg vs. Hudi vs. Delta Lake
Ovviamente, Google Trends non è una prova statistica o una ricerca sofisticata. Ma l’ho utilizzato molto in passato come uno strumento intuitivo, semplice e gratuito per analizzare le tendenze di mercato. Pertanto, ho anche usato questo strumento per vedere se le ricerche su Google coincidono con la mia esperienza personale dell’adozione di mercato di Apache Iceberg, Hudi e Delta Lake (Apache XTable è ancora troppo piccolo per essere aggiunto):
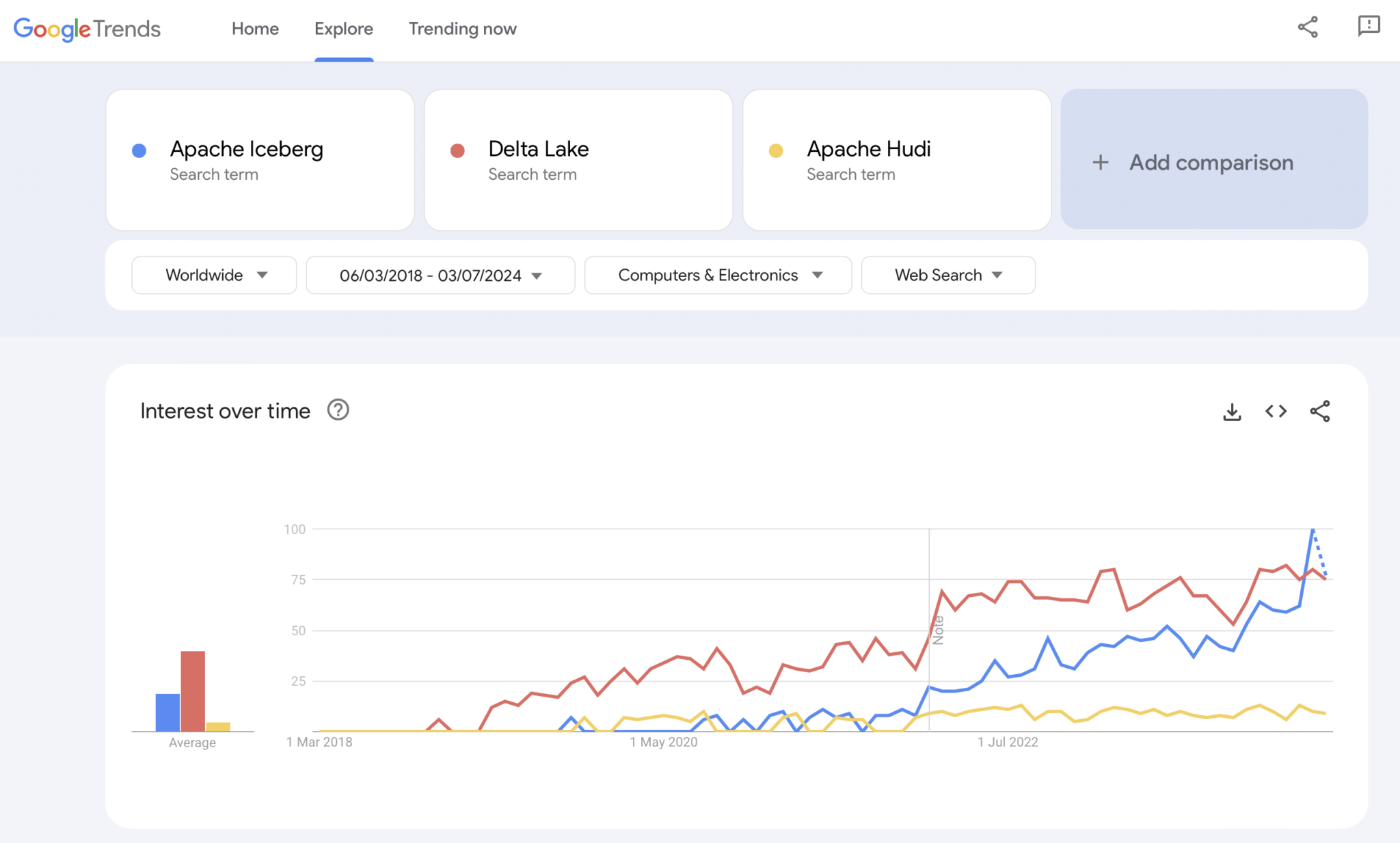
Notiamo chiaramente un pattern simile a quello delle guerre dei container mostrato qualche anno fa. Non ho idea di dove tutto questo sta andando. E se una tecnologia vincerà, o se i framework si differenzieranno abbastanza per dimostrare che non esiste una soluzione unica, il futuro ce lo mostrerà.
La mia opinione personale? Penso che Apache Iceberg vincerà la gara. Perché? Non posso discutere per nessun motivo tecnico. simply vedo molti clienti in tutte le industrie parlare sempre di più di esso. E sempre più fornitori iniziano a supportarlo. Ma vedremo. In realtà, non mi importa chi vince. Tuttavia, simile alle guerre dei container, penso che sia bene avere uno standard unico e fornitori che si differenziano con funzionalità intorno ad esso, come avviene con Kubernetes.
Ma con questo in mente, esploriamo la strategia attuale delle piattaforme di dati leader e dei fornitori di servizi cloud riguardo al supporto del formato di tabella nelle loro piattaforme e servizi cloud.
Strategie dei Fornitori di Piattaforme di Dati e Cloud per Apache Iceberg
Non farò alcuna speculazione in questa sezione. La evoluzione dei framework di formato delle tabelle si muove rapidamente, e le strategie dei fornitori cambiano rapidamente. Fare riferimento ai siti web dei fornitori per le informazioni più recenti. Ma ecco il status quo riguardo alle strategie delle piattaforme di dati e dei fornitori di servizi cloud riguardo al supporto e integrazione di Apache Iceberg.
- Snowflake:
- Supporta Apache Iceberg da un pezzo
- Aggiunge meglio le integrazioni e nuove funzionalità regolarmente
- Opzioni di archiviazione interna ed esterna (con compromessi) come l’archiviazione di Snowflake o Amazon S3
- Ha annunciato Polaris, un’implementazione di catalogo open-source per Iceberg, con impegno a supportare l’integrazione bidirezionale comunitaria, agnostica ai fornitori
- Databricks:
-
Si concentra su Delta Lake come formato di tabella e (ora open sourced) Unity come catalogo
Ha acquisito Tabular, la principale azienda dietro Apache Iceberg
Strategia futura incerta di supporto all’interfaccia Iceberg aperta (in entrambi i sensi) o solo per alimentare dati nella sua piattaforma lakehouse e tecnologie come Delta Lake e Unity Catalog - Confluent:
-
Integra Apache Iceberg come cittadino di primo piano nella sua piattaforma di streaming dati (il prodotto si chiama Tableflow)
Converti un Topic Kafka e le relative metadati di schema (ovvero, contratto di dati) in una tabella Iceberg
- Piattaforme di dati e motori di analisi open-source aggiuntivi:
- L’elenco delle tecnologie e dei servizi cloud che supportano Iceberg cresce ogni mese
- Alcuni esempi: Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst utilizzando Trino (precedentemente PrestoSQL), Cloudera utilizzando Impala, Imply utilizzando Apache Druid, Fivetran
- Fornitori di servizi cloud (AWS, Azure, Google Cloud, Alibaba):
- Strategie e integrazioni diverse, ma tutti i fornitori di cloud stanno aumentando il supporto per Iceberg attraverso i loro servizi in questi giorni, ad esempio:
- Storage Oggetti: Amazon S3, Azure Data Lake Storage (ALDS), Google Cloud Storage
- Cataloghi: Specifici del cloud come AWS Glue Catalog o indipendenti dal fornitore come Project Nessie o Hive Catalog
- Analisi: Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
- Strategie e integrazioni diverse, ma tutti i fornitori di cloud stanno aumentando il supporto per Iceberg attraverso i loro servizi in questi giorni, ad esempio:
Architettura Shift Left con Kafka, Flink e Iceberg per unificare i carichi di lavoro operativi e analitici
L’architettura shift left sposta l’elaborazione dei dati più vicino alla fonte dei dati, sfruttando tecnologie di streaming di dati in tempo reale come Apache Kafka e Flink per elaborare i dati in movimento direttamente dopo che sono stati acquisiti. Questo approccio riduce la latenza e migliora la coerenza e la qualità dei dati.
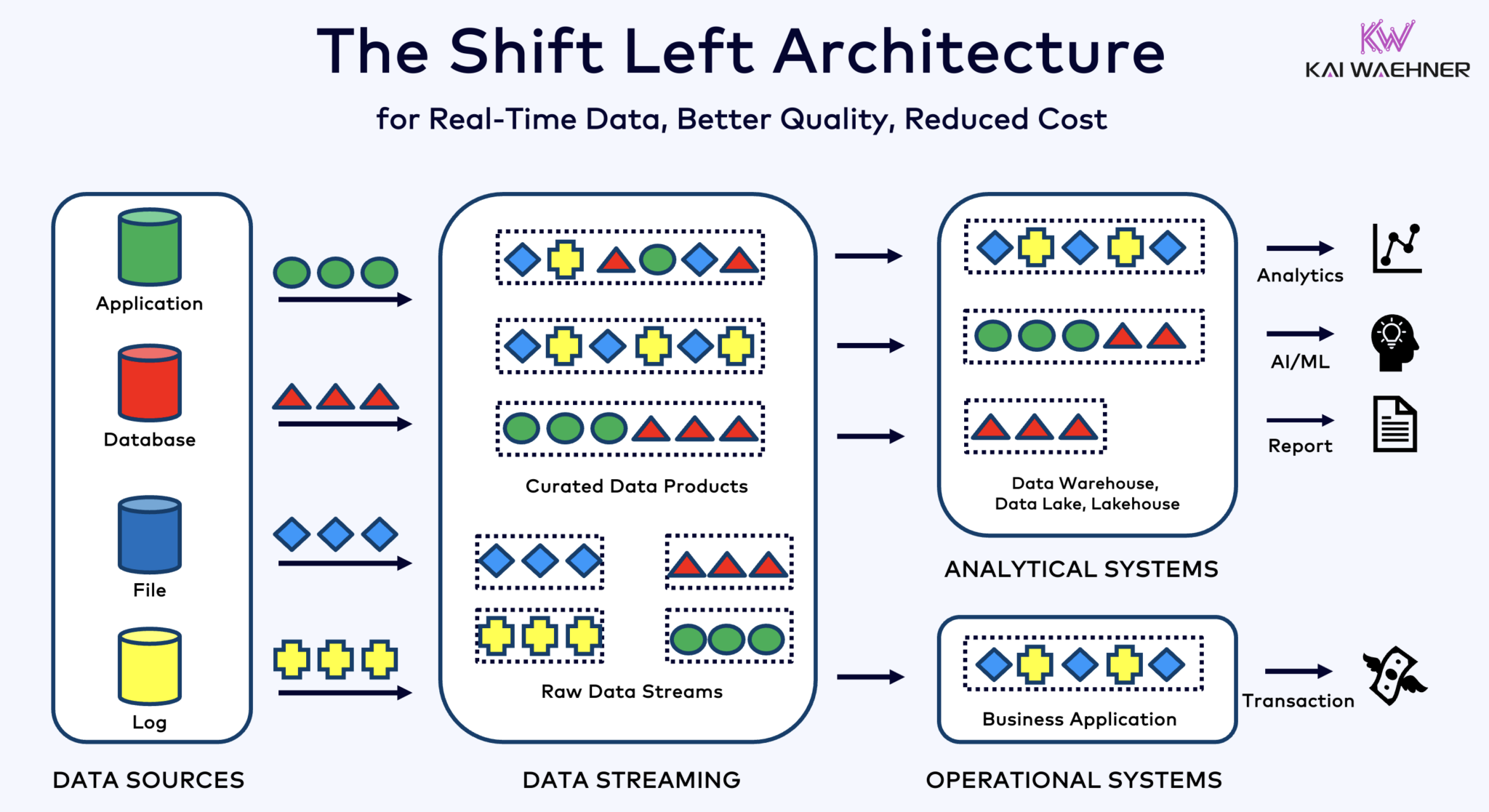
Contrariamente a ETL ed ELT, che coinvolgono l’elaborazione in batch con i dati archiviati a riposo, l’architettura shift left consente la cattura e la trasformazione dei dati in tempo reale. Si allinea con il concetto di zero-ETL rendendo i dati immediatamente utilizzabili. Ma a differenza di zero-ETL, spostare l’elaborazione dei dati verso il lato sinistro dell’architettura aziendale evita un’architettura a spaghetti complessa e difficile da mantenere con molte connessioni punto a punto.
L’architettura shift left riduce anche la necessità di reverse ETL garantendo che i dati siano azionabili in tempo reale per entrambi i sistemi operativi e analitici. Nel complesso, questa architettura migliora la freschezza dei dati, riduce i costi e accelera il tempo di mercato per le applicazioni guidate dai dati. Scopri di più su questo concetto nel mio post di blog su “L’architettura Shift Left.”
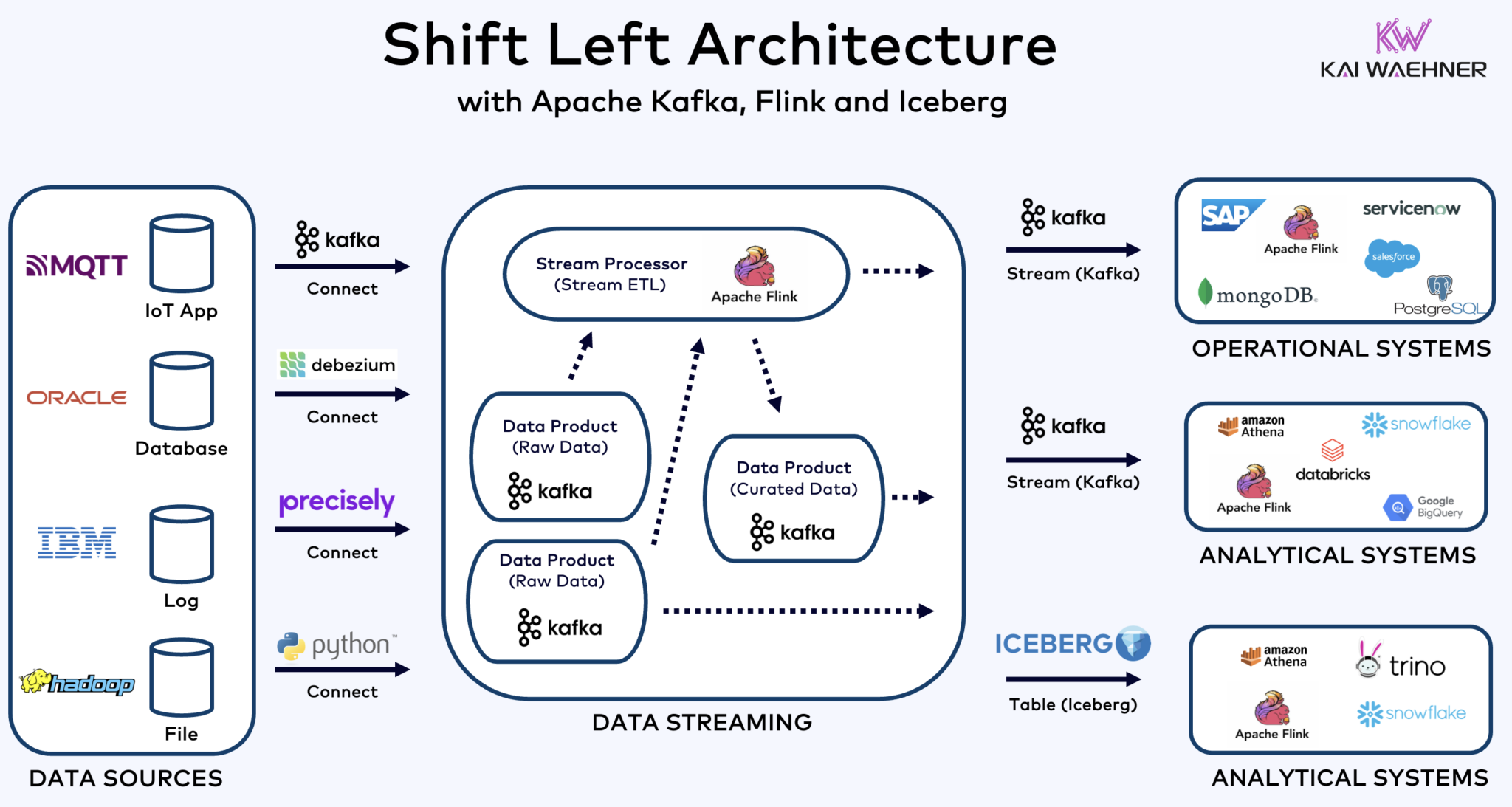
Apache Iceberg come Format di Tabella e Catalogo Aperto per la Condivisione Semplice dei Dati Across Analytics Engines
Un format di tabella e catalogo aperto introduce enormi benefici nell’architettura aziendale:
- Interoperabilità
- Libertà di scelta degli analytics engines
- Tempo di mercato più rapido
- Riduzione dei costi
Apache Iceberg sembra diventare lo standard di fatto tra i fornitori e i provider cloud. Tuttavia, è ancora in una fase iniziale e le tecnologie concorrenti e wrapper come Apache Hudi, Apache Paimon, Delta Lake e Apache XTable stanno cercando di ottenere momentum, troppo.
Ghiacciaio e altri formati di tavola aperta non sono solo una grande vittoria per lo storage singolo e l’integrazione con più piattaforme di analisi/dati/AI/ML come Snowflake, Databricks, Google BigQuery, et al., ma anche per la unificazione dei carichi di lavoro operativi e analitici utilizzando lo streaming di dati con tecnologie come Apache Kafka e Flink. L’architettura shift left è un vantaggio significativo per ridurre gli sforzi, migliorare la qualità e la coerenza dei dati, e abilitare applicazioni e insight in tempo reale invece che batch.
Infine, se ti chiedi ancora quali sono le differenze tra lo streaming di dati e i data lakehouse (e come si completano a vicenda), dai un’occhiata a questo video di dieci minuti:
Qual è la tua strategia di formato di tabella? Quali tecnologie e servizi cloud connetti? Insieme collegiamoci su LinkedIn e ne discutiamo!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming