













Chaque organisation pilotée par les données a des charges de travail opérationnelles et analytiques. Une approche du meilleur de chaque catégorie émerge avec diverses plateformes de données, y compris les flux de données, les lacs de données, les entrepôts de données et les solutions lakehouse, ainsi que les services cloud. Un framework de format de table ouvert comme Apache Iceberg est essentiel dans l’architecture de l’entreprise pour garantir une gestion et un partage de données fiables, une évolution transparente des schémas, une gestion efficace des jeux de données à grande échelle, un stockage rentable tout en offrant un solide soutien aux transactions ACID et aux requêtes de voyage dans le temps.
Cet article explore les tendances du marché ; l’adoption de frameworks de format de table comme Iceberg, Hudi, Paimon, Delta Lake, et XTable ; et la stratégie de produit de certains des principaux fournisseurs de plateformes de données tels que Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka/Flink), Amazon Athena, et Google BigQuery.
Qu’est-ce qu’un Format de Table Ouvert pour une Plateforme de Données ?
Un format de table ouvert aide à maintenir l’intégrité des données, à optimiser les performances des requêtes et à garantir une compréhension claire des données stockées au sein de la plateforme.
Le format de table ouvert pour les plateformes de données inclut généralement une structure bien définie avec des composants spécifiques qui assurent que les données sont organisées, accessibles et faciles à interroger. Un format de table typique contient un nom de table, des noms de colonnes, des types de données, des clés primaires et étrangères, des indexes et des contraintes.
Ce n’est pas un concept nouveau. Votre base de données préférée vieille de plusieurs décennies — comme Oracle, IBM DB2 (même sur le mainframe) ou PostgreSQL — utilise les mêmes principes. Cependant, les exigences et défis ont un peu changé pour les entrepôts de données cloud, les data lakes et les lakehouses en termes d’évolutivité, de performance et de capacités de requête.
Avantages d’un « Format de Table Lakehouse » comme Apache Iceberg
Chaque partie d’une organisation devient orientée données. La conséquence est des ensembles de données étendus, un partage des données avec des produits de données entre les unités commerciales et de nouvelles exigences pour le traitement des données en quasi temps réel.
Apache Iceberg offre de nombreux avantages pour l’architecture des entreprises :
- Stockage unique : Les données sont stockées une seule fois (venant de diverses sources de données), ce qui réduit les coûts et la complexité
- Interopérabilité : Accès sans efforts d’intégration depuis n’importe quel moteur analytique
- Toutes les données : Unifier les charges de travail opérationnelles et analytiques (systèmes transactionnels, journaux de big data/IoT/clickstream, APIs mobiles, interfaces B2B tierces, etc.)
- Indépendance des fournisseurs : Travailler avec n’importe quel moteur d’analyse préféré (que ce soit en quasi temps réel, en lot ou basé sur une API)
Apache Hudi et Delta Lake offrent les mêmes caractéristiques. Cependant, Delta Lake est principalement développé par Databricks en tant que fournisseur unique.
Format de Table et Interface de Catalogue
Il est important de comprendre que les discussions sur Apache Iceberg ou des frameworks de format de table similaires incluent deux concepts : le format de table et l’interface de catalogue ! En tant qu’utilisateur final de la technologie, vous en avez besoin des deux !
Le projet Apache Iceberg implémente le format mais n’offre qu’une spécification (et non une implémentation) pour le catalogue :
- Le format de table définit comment les données sont organisées, stockées et gérées au sein d’une table.
- L’interface de catalogue gère les métadonnées des tables et fournit une couche d’abstraction pour accéder aux tables dans un lac de données.
La documentation Apache Iceberg explore ces concepts en bien plus de détails, basée sur ce diagramme :
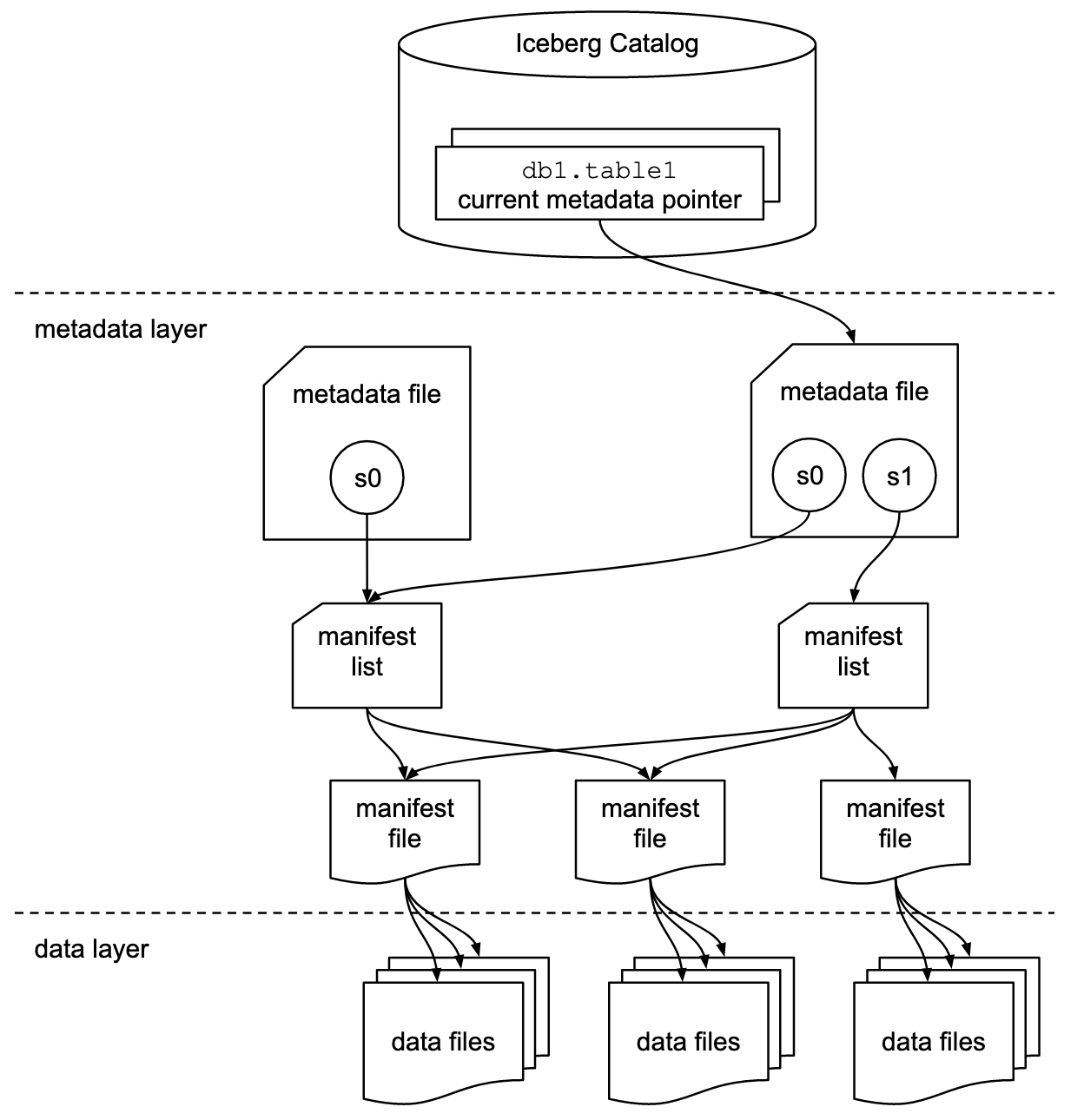
Les organisations utilisent diverses implémentations pour l’interface de catalogue Iceberg. Chacune s’intègre avec différents magasins de métadonnées et services. Les implémentations clés incluent :
- Catalogue Hadoop : Utilise le Hadoop Distributed File System (HDFS) ou d’autres systèmes de fichiers compatibles pour stocker les métadonnées. Adapté pour les environnements utilisant déjà Hadoop.
- Catalogue Hive : S’intègre avec le Apache Hive Metastore pour gérer les métadonnées des tables. Idéal pour les utilisateurs qui exploitent Hive pour la gestion de leurs métadonnées.
- Catalogue AWS Glue : Utilise le AWS Glue Data Catalog pour le stockage des métadonnées. Conçu pour les utilisateurs opérant dans l’écosystème AWS.
- Catalogue REST : Fournit une interface RESTful pour les opérations de catalogue via HTTP. Permet l’intégration avec des services de métadonnées personnalisés ou tiers.
- Catalogue Nessie : Utilise le projet Nessie, qui offre une expérience similaire à Git pour la gestion des données.
La dynamique et l’adoption croissante d’Apache Iceberg motivent de nombreux fournisseurs de plates-formes de données à implémenter leur propre catalogue Iceberg. Je discuss quelques stratégies dans la section ci-dessous concernant les stratégies des fournisseurs de plates-formes de données et de services cloud, y compris Polaris de Snowflake, Unity de Databricks et Tableflow de Confluent.
Support de premier plan pour Iceberg vs. Connecteur Iceberg
Veuillez noter que supporter Apache Iceberg (ou Hudi/Delta Lake) signifie bien plus que simplement fournir un connecteur et une intégration avec le format de table via API. Les fournisseurs et les services cloud se distinguent par des fonctionnalités avancées comme le mappage automatique entre les formats de données, des SLAs critiques, la capacité de voyager dans le temps, des interfaces utilisateur intuitives, et ainsi de suite.
Voyons un exemple : L’intégration entre Apache Kafka et Iceberg. Divers connecteurs Kafka Connect ont déjà été implémentés. Cependant, voici les avantages de l’utilisation d’une intégration de premier plan avec Iceberg (par exemple, Tableflow de Confluent) par rapport à l’utilisation d’un simple connecteur Kafka Connect :
- Pas de configuration de connecteur
- Pas de consommation via connecteur
- Entretien intégré (compaction, collecte des ordures, gestion des instantanés)
- Évolution automatique du schéma
- Synchronisation du service de catalogue externe
- Des opérations plus simples (dans une solution SaaS entièrement gérée, elle est sans serveur et ne nécessite aucune mise à l’échelle ou opérations par l’utilisateur final)
Les mêmes avantages s’appliquent également aux autres plateformes de données et à une intégration potentielle de premier ordre par rapport à la fourniture de simples connecteurs.
Format de table ouverte pour un lac de données/lachouse en utilisant Apache Iceberg, Apache Hudi et Delta Lake
L’objectif général des cadres de format de table tels qu’Apache Iceberg, Apache Hudi et Delta Lake est de améliorer la fonctionnalité et la fiabilité des lacs de données en abordant les défis courants associés à la gestion de données à grande échelle. Ces cadres aident à :
- Améliorer la gestion des données
- Faciliter une gestion plus simple de l’ingestion, du stockage et de la récupération des données dans les lacs de données.
- Permettre une organisation et un stockage des données efficaces, soutenant une meilleure performance et une scalable.
- Assurer la cohérence des données
- Fournir des mécanismes pour les transactions ACID, garantissant que les données restent cohérentes et fiables même pendant les opérations de lecture et d’écriture concurrentes.
- Supporter l’isolement des instantanés, permettant aux utilisateurs de voir un état cohérent des données à tout moment.
- Prend en charge l’évolution du schéma
- Permettre des modifications dans le schéma des données (comme ajouter, renommer ou supprimer des colonnes) sans perturber les données existantes ou nécessiter des migrations complexes.
- Optimiser les performances des requêtes
- Mettre en œuvre des stratégies avancées d’indexation et de partitionnement pour améliorer la vitesse et l’efficacité des requêtes sur les données.
- Permettre une gestion efficace des métadonnées pour gérer de grands ensembles de données et des requêtes complexes de manière efficace.
- Améliorer la gouvernance des données
- Fournir des outils pour un meilleur suivi et gestion de la lignée des données, de la versionning et de l’audit, ce qui est crucial pour maintenir la qualité des données et la conformité.
En abordant ces objectifs, les cadres de format de table tels que Apache Iceberg, Apache Hudi et Delta Lake aident les organisations à construire des lacs de données et des maisons de lac plus robustes, évolutifs et fiables. Les ingénieurs de données, les data scientists et les analystes métier utilisent des outils d’analyse, d’IA/ML ou de reporting/visualisation sur le format de table pour gérer et analyser de gros volumes de données.
Comparaison d’Apache Iceberg, Hudi, Paimon et Delta Lake
Je ne ferai pas ici de comparaison des cadres de format de table Apache Iceberg, Apache Hudi, Apache Paimon et Delta Lake. De nombreux experts ont déjà écrit à ce sujet. Chaque cadre de format de table a des forces et des avantages uniques. Mais des mises à jour sont nécessaires chaque mois en raison de l’évolution rapide et de l’innovation, ajoutant de nouvelles améliorations et capacités au sein de ces cadres.
Voici un résumé de ce que je vois dans divers articles de blog sur les quatre options :
- Apache Iceberg : Excellente évolution de schéma et de partition, gestion efficace des métadonnées et large compatibilité avec divers moteurs de traitement de données.
- Apache Hudi : Mieux adapté pour l’ingestion de données en temps réel et les upserts, avec de solides capacités de capture des modifications et de versionnage des données.
- Apache Paimon : Un format de lac qui permet de construire une architecture de lac en temps réel avec Flink et Spark pour les opérations de streaming et par lots.
- Delta Lake : Fournit des transactions ACID robustes, une application de schéma et des fonctionnalités de voyage dans le temps, ce qui en fait idéal pour maintenir la qualité et l’intégrité des données.
Un point de décision clé pourrait être que Delta Lake n’est pas piloté par une large communauté comme Iceberg et Hudi, mais principalement par Databricks en tant que seul fournisseur derrière.
Apache XTable en tant que framework interopérable entre tables cross-plateformes prenant en charge Iceberg, Hudi, et Delta Lake
Les utilisateurs ont beaucoup de choix. XTable, anciennement connu sous le nom de OneTable, est une autre structure de table en incubation sous licence open-source Apache pour interopérer sans couture entre les tables Apache Hudi, Delta Lake, et Apache Iceberg.
Apache XTable:
- Fournit une interopérabilité omnidirectionnelle entre tables de formats de lakehouse.
- Est pas un nouveau format ou une structure distincte. Apache XTable fournit des abstractions et des outils pour la traduction des métadonnées de format de table de lakehouse.
Peut-être qu’Apache XTable est la réponse pour offrir des options pour des plateformes de données spécifiques et des fournisseurs de cloud tout en offrant une intégration et une interopérabilité simples.
Mais attention : Un wrapper au-dessus de différentes technologies n’est pas une solution miracle. Nous avons vu cela il y a quelques années lorsque Apache Beam est apparu. Apache Beam est un modèle unifié open source et un ensemble de SDK spécifiques aux langages pour définir et exécuter des workflows d’ingestion de données et de traitement des données. Il prend en charge une variété de moteurs de traitement de flux, tels que Flink, Spark et Samza. Le principal moteur derrière Apache Beam est Google, qui permet la migration des workflows dans Google Cloud Dataflow. Cependant, les limitations sont énormes, car un tel wrapper doit trouver le plus petit commun multiple des fonctionnalités prises en charge. Et le principal avantage de la plupart des frameworks est le 20% qui ne s’insère pas dans un tel wrapper. Pour ces raisons, par exemple, Kafka Streams ne prend pas en charge Apache Beam car cela aurait nécessité trop de limitations de conception.
Adoption sur le marché des frameworks de format de table
tout d’abord, nous sommes encore dans les premières étapes. Nous sommes toujours au déclencheur de l’innovation en termes de cycle de hype de Gartner, en direction du sommet des attentes inflationnistes. La plupart des organisations sont encore en train d’évaluer mais n’ont pas encore adopté ces formats de table en production à travers l’organisation.
Rétrospective : La guerre des conteneurs entre Kubernetes, Mesosphere et Cloud Foundry
Le débat autour d’Apache Iceberg me rappelle la guerre des conteneurs il y a quelques années. Le terme « Guerre des conteneurs » fait référence à la concurrence et à la rivalité entre différentes technologies et plateformes de conteneurisation dans le domaine du développement logiciel et des infrastructures IT.
Les trois technologies concurrentes étaient Kubernetes, Mesosphere et Cloud Foundry. Voici où cela en est arrivé :

Cloud Foundry et Mesosphere étaient précoces, mais Kubernetes a quand même gagné la bataille. Pourquoi ? Je n’ai jamais compris toutes les détails techniques et les différences. À la fin, si les trois frameworks sont plutôt similaires, c’est tout une question de :
- Adoption communautaire
- Bon timing des releases de fonctionnalités
- Bon marketing
- Chance
- Et quelques autres facteurs
Mais c’est bon pour l’industrie du logiciel d’avoir un framework open-source leader pour construire des solutions et des modèles commerciaux au lieu de trois concurrents.
Présent : Les guerres de format de table entre Apache Iceberg vs. Hudi vs. Delta Lake
Évidemment, Google Trends n’est pas une preuve statistique ou une recherche sophistiquée. Mais j’ai souvent utilisé cet outil par le passé comme un outil intuitif, simple et gratuit pour analyser les tendances du marché. Ainsi, j’ai aussi utilisé cet outil pour voir si les recherches Google chevauchent mon expérience personnelle de l’adoption sur le marché d’Apache Iceberg, Hudi et Delta Lake (Apache XTable est encore trop petit pour être ajouté) :
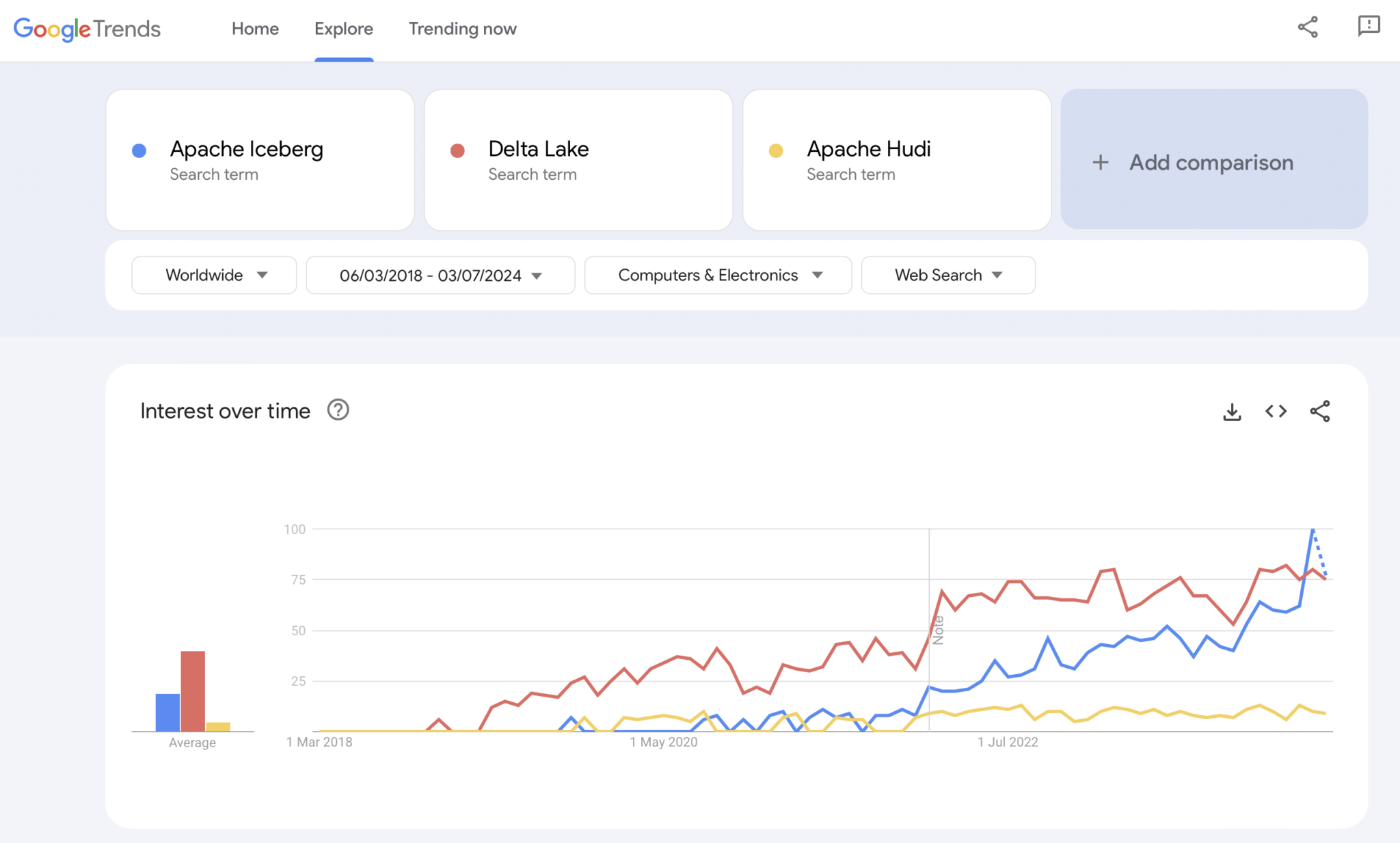
Nous voyons évidemment un schéma similaire à celui que les guerres des conteneurs ont montré il y a quelques années. Je n’ai aucune idée de où cela va. Et si une technologie gagne, ou si les frameworks se différencient suffisamment pour prouver qu’il n’y a pas de solution miracle, l’avenir nous le montrera.
Mon opinion personnelle ? Je pense qu’Apache Iceberg va gagner la course. Pourquoi ? Je ne peux pas contester des raisons techniques. Je vois simplement de plus en plus de clients dans toutes les industries en parler de plus en plus. Et de plus en plus de fournisseurs commencent à le prendre en charge. Mais nous verrons. En réalité, je ne m’en souciais pas qui gagne. Cependant, comme pour la guerre des conteneurs, je pense qu’il est bon d’avoir une norme unique et que les fournisseurs se distinguent par des fonctionnalités autour de celle-ci, comme c’est le cas avec Kubernetes.
Mais avec cela à l’esprit, explorons la stratégie actuelle des principales plateformes de données et des fournisseurs de services cloud concernant le support du format de table dans leurs plateformes et services cloud.
Stratégies des Plateformes de Données et Fournisseurs Cloud pour Apache Iceberg
Je ne ferai aucune spéculation dans cette section. L’évolution des frameworks de format de table est rapide, et les stratégies des fournisseurs changent rapidement. Veuillez vous référer aux sites web des fournisseurs pour obtenir les informations les plus récentes. Mais voici le statu quo concernant les stratégies des plateformes de données et des fournisseurs cloud concernant le support et l’intégration d’Apache Iceberg.
- Snowflake :
- Supporte Apache Iceberg depuis déjà un certain temps
- Ajoute régulièrement de meilleures intégrations et nouvelles fonctionnalités
- Options de stockage interne et externe (avec des compromis) comme le stockage de Snowflake ou Amazon S3
- Annonce Polaris, une implémentation de catalogue open-source pour Iceberg, avec un engagement à soutenir une intégration bidirectionnelle communautaire et agnostique aux fournisseurs
- Databricks :
- Se concentre sur Delta Lake comme format de table et (maintenant open source) Unity comme catalogue
- Aquérit Tabular, la société leader derrière Apache Iceberg
- Stratégie future incertaine de prise en charge de l’interface ouverte Iceberg (dans les deux sens) ou uniquement pour nourrir les données dans sa plateforme lakehouse et des technologies comme Delta Lake et Unity Catalog
- Confluent :
- Intègre Apache Iceberg en tant que citoyen de premier plan dans sa plateforme de streaming de données (le produit est appelé Tableflow)
- Convertis un sujet Kafka et les métadonnées associées de schéma (c’est-à-dire, contrat de données) en une table Iceberg
- Intégration bidirectionnelle entre les charges de travail opérationnelles et analytiques
- Analyses avec un serveurless Flink intégré et son API unifiée batch et streaming ou partage de données avec des moteurs d’analyse tiers comme Snowflake, Databricks, ou Amazon Athena
- Plus de plateformes de données et de moteurs d’analyse open-source :
- La liste des technologies et services cloud prenant en charge Iceberg s’allonge chaque mois
- Quelques exemples : Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst utilisant Trino (anciennement PrestoSQL), Cloudera utilisant Impala, Imply utilisant Apache Druid, Fivetran
- Fournisseurs de services cloud (AWS, Azure, Google Cloud, Alibaba) :
- Differentes stratégies et intégrations, mais tous les fournisseurs de cloud augmentent la prise en charge d’Iceberg à travers leurs services en ce moment, par exemple :
- Stockage d’objets : Amazon S3, Azure Data Lake Storage (ALDS), Google Cloud Storage
- Catalogues : Spécifiques au cloud comme le AWS Glue Catalog ou indépendants du fournisseur comme Project Nessie ou Hive Catalog
- Analytics : Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
- Differentes stratégies et intégrations, mais tous les fournisseurs de cloud augmentent la prise en charge d’Iceberg à travers leurs services en ce moment, par exemple :
Architecture de décalage à gauche avec Kafka, Flink, et Iceberg pour unifier les charges de travail opérationnelles et analytiques
Le shift left architecture déplace le traitement des données plus près de la source des données, en utilisant des technologies de streaming de données en temps réel comme Apache Kafka et Flink pour traiter les données en mouvement directement après leur ingestion. Cette approche réduit la latence et améliore la cohérence des données et la qualité des données.
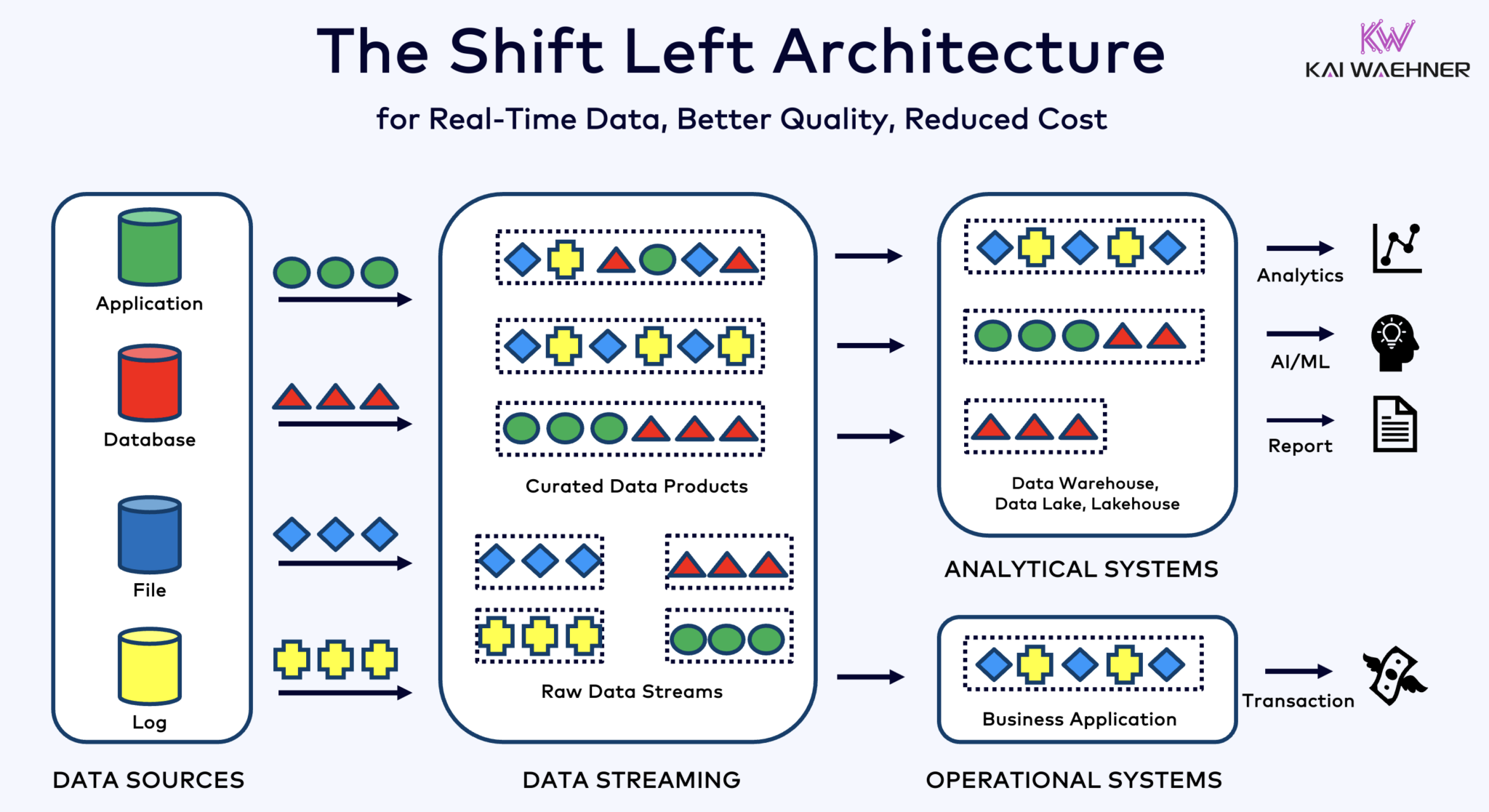
Contrairement aux ETL et ELT, qui impliquent un traitement par lots des données stockées au repos, l’architecture de décalage à gauche permet la capture et la transformation des données en temps réel. Elle s’aligne avec le concept de zero-ETL en rendant les données immédiatement utilisables. Mais contrairement à zero-ETL, décaler le traitement des données vers le côté gauche de l’architecture de l’entreprise évite une architecture complexe et difficile à entretenir avec de nombreuses connexions point à point.
L’architecture Shift Left réduit également le besoin de reverse ETL en assurant que les données sont actionnables en temps réel pour les systèmes opérationnels et analytiques. Dans l’ensemble, cette architecture améliore la fraîcheur des données, réduit les coûts et accélère le temps de mise sur le marché des applications basées sur les données. En savoir plus sur ce concept dans mon article de blog intitulé « L’Architecture Shift Left. »
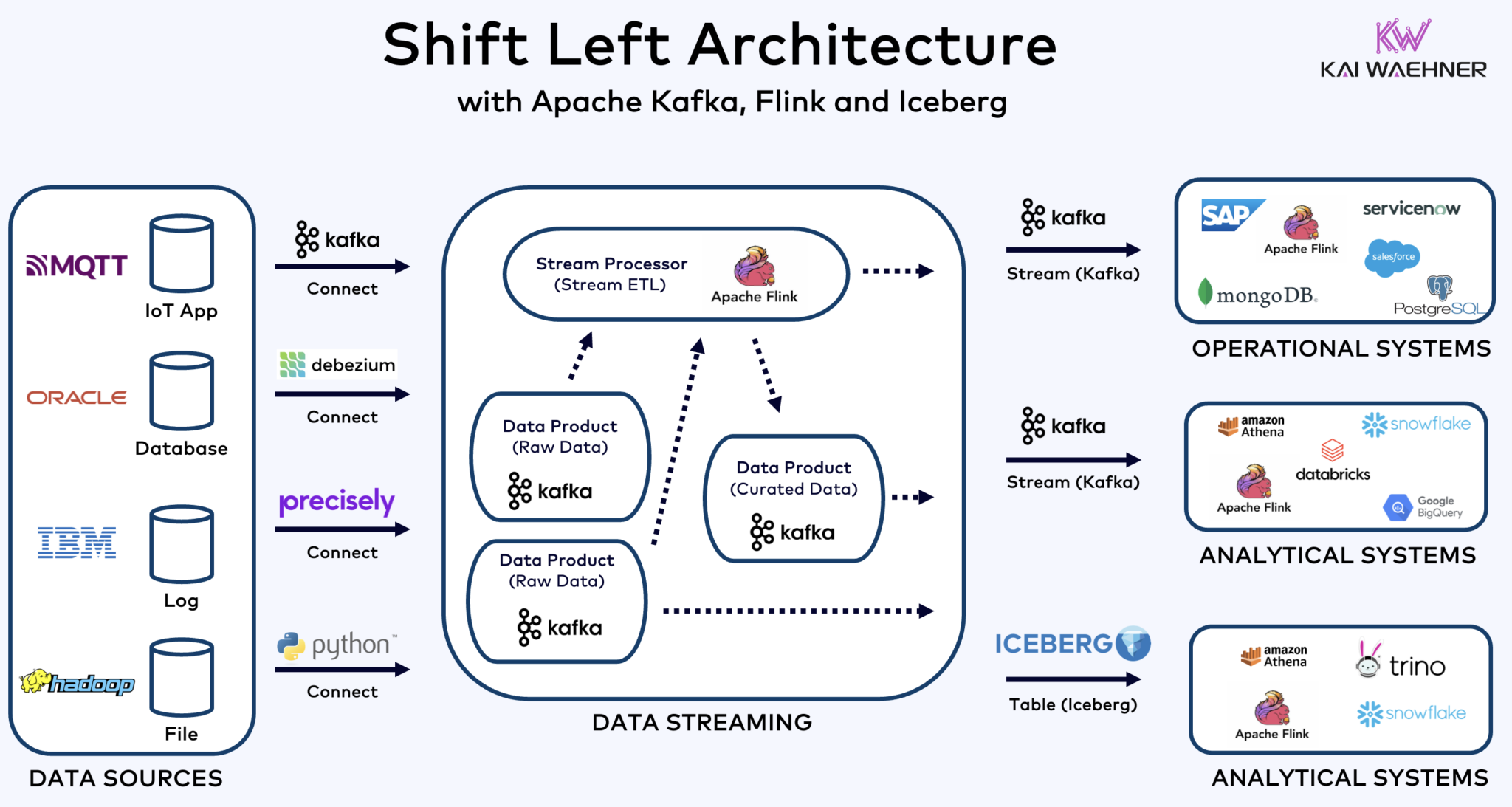
Apache Iceberg en tant que Format de Table et Catalogue Ouverts pour un Partage Transparent des Données Across Analytics Engines
Un format de table et catalogue ouverts apportent d’énormes avantages à l’architecture de l’entreprise :
- Interopérabilité
- Liberté de choix des moteurs analytiques
- Temps de mise sur le marché plus rapide
- Réduction des coûts
Apache Iceberg semble devenir la norme de facto parmi les fournisseurs et les prestataires de services cloud. Cependant, il est toujours à un stade précoce et des technologies concurrentes et enveloppantes comme Apache Hudi, Apache Paimon, Delta Lake, et Apache XTable tentent également de gagner du momentum.
L’iceberg et d’autres formats de tables ouvertes ne représentent pas seulement un énorme avantage pour le stockage unique et l’intégration avec plusieurs plateformes d’analyse/données/AI/ML telles que Snowflake, Databricks, Google BigQuery, et autres, mais aussi pour la unification des charges de travail opérationnelles et analytiques en utilisant le streaming de données avec des technologies telles qu’Apache Kafka et Flink. L’architecture de décalage à gauche offre un avantage significatif pour réduire les efforts, améliorer la qualité et la cohérence des données, et permettre des applications et des insights en temps réel plutôt qu’en lots.
Finalement, si vous vous demandez toujours quelles sont les différences entre le streaming de données et les lakehouses (et comment ils se complètent), jetez un œil à cette vidéo de dix minutes :
Quelle est votre stratégie de format de table ? Quelles technologies et services cloud utilisez-vous ? Connectons-nous sur LinkedIn et discutons-en !
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming