













כל ארגון שמבוסס על נתונים מפעיל עומסי עבודה תפעוליים וניתוחיים. גישת "הטוב מבית המומחים" עולה עם מגוון פלטפורמות נתונים, כולל זרימת נתונים, אגם נתונים, מחסן נתונים ופתרונות Lakehouse, ושירותי ענן. מתווה בפורמט טבלה פתוח כמו Apache Iceberg חיוני בארכיטקטורה העסקית כדי להבטיח ניהול נתונים אמין ושיתוף, אבולוציית סכימות בלתי משותפת, טיפול יעיל בסט נתונים בגודל גדול, ואחסון כולל עלות בעוד שמספק תמיכה חזקה בעסקיות ACID ושאילתות נסיעה בזמן.
מאמר זה חוקר מגמות שוק; קבלת עליית מגמת פורמטי טבלה כמו Iceberg, Hudi, Paimon, Delta Lake, ו-XTable; ואת אסטרטגיית המוצר של חלק מספקי הפלטפורמות לנתונים המובילים כמו Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka/Flink), Amazon Athena, ו-Google BigQuery.
מהו פורמט טבלה פתוח לפלטפורמת נתונים?
פורמט טבלה פתוח עוזר בשמירה על תקינות הנתונים, ביצועי שאילתות מקסימליים, ובהבטחה להבנה ברורה של הנתונים שמאוחסנים בתוך הפלטפורמה.
פורמט הטבלה הפתוח לפלטפורמות נתונים כולל בדרך כלל מבנה מוגדר היטב עם רכיבים ספציפיים שמבטיחים ארגון של הנתונים, גישה, ואפשרות לביצוע שאילתות בקלות. פורמט טיפול מכיל שם טבלה, שמות עמודות, סוגי נתונים, מפתחות ראשיים וזרים, אינדקסים, ואילוצים.
זה לא רעיון חדש. מסד הנתונים הישן שלך המועדף — כמו Oracle, IBM DB2 (גם ב-mainframe) או PostgreSQL — משתמש באותם מרכיבים. אך, ה-דרישות והאתגרים השתנו קצת עבור מחסניות נתונים בעננים, אגמים נתונים, ובתי גידול בנושא קידמה, ביצועים, ויכולות שאילתה.
היתרונות של "פורמט טבלת 'Lakehouse'" כמו Apache Iceberg
כל חלק בארגון משתמש בנתונים. התוצאה היא קבוצות נתונים נרחבות, שיתוף נתונים עם מוצרי נתונים בכל מחלקה עסקית, ודרישות חדשות לעיבוד נתונים בזמן אמיתי קרוב.
Apache Iceberg מספקת יתרונות רבים לארכיטקטורת ארגון:
- אחסון יחיד: הנתונים מאוחסנים פעם אחת (מגיעים ממקורות נתונים שונים), מה שמפחית עלויות ומורכבות
- אינטרופרביליות: גישה ללא מאמץ אינטגרציה מכל מנוע אנליטי
- כל הנתונים: איחוד עומסי עבודה אופרטיביים ואנליטיים (מערכות טרנזקציונליות, קבצי לוג של נתונים גדולים/IoT/clickstream, ממשקים ל-API של ניידים, ממשקים B2B גורמי צד שלישי, וכו')
- אי-תלות בספק: עבודה עם כל מנוע אנליטי אהוב (בין אם זה בזמן אמיתי, batch, או מבוסס API)
Apache Hudi ו-Delta Lake מספקים את אותם תכונות. אף על פי כן, Delta Lake בעיקר מופעלת על ידי Databricks כספק יחיד.
פורמט טבלה וממשק קטלוג
חשוב להבין כי שיחות על Apache Iceberg או על מסגרת טבלאית דומה כוללות שני מושגים: פורמט טבלה וממשק קטלוג! כמשתמש סופי בטכנולוגיה, נדרשים שניהם!
פרויקט Apache Iceberg מיישם את הפורמט אך מספק רק תיאור (ולא מימוש) לקטלוג:
- הפורמט של הטבלה מגדיר איך הנתונים מאורגנים, מאוחסנים ומנוהלים בתוך טבלה.
- ממשק הקטלוג נוהל את המטא-נתונים של הטבלאות ומספק שכבת הפשטה לגישה לטבלאות באגם נתונים.
התיעוד של Apache Iceberg חוקר את המושגים בעומק רב יותר, על סמך תרשים זה:
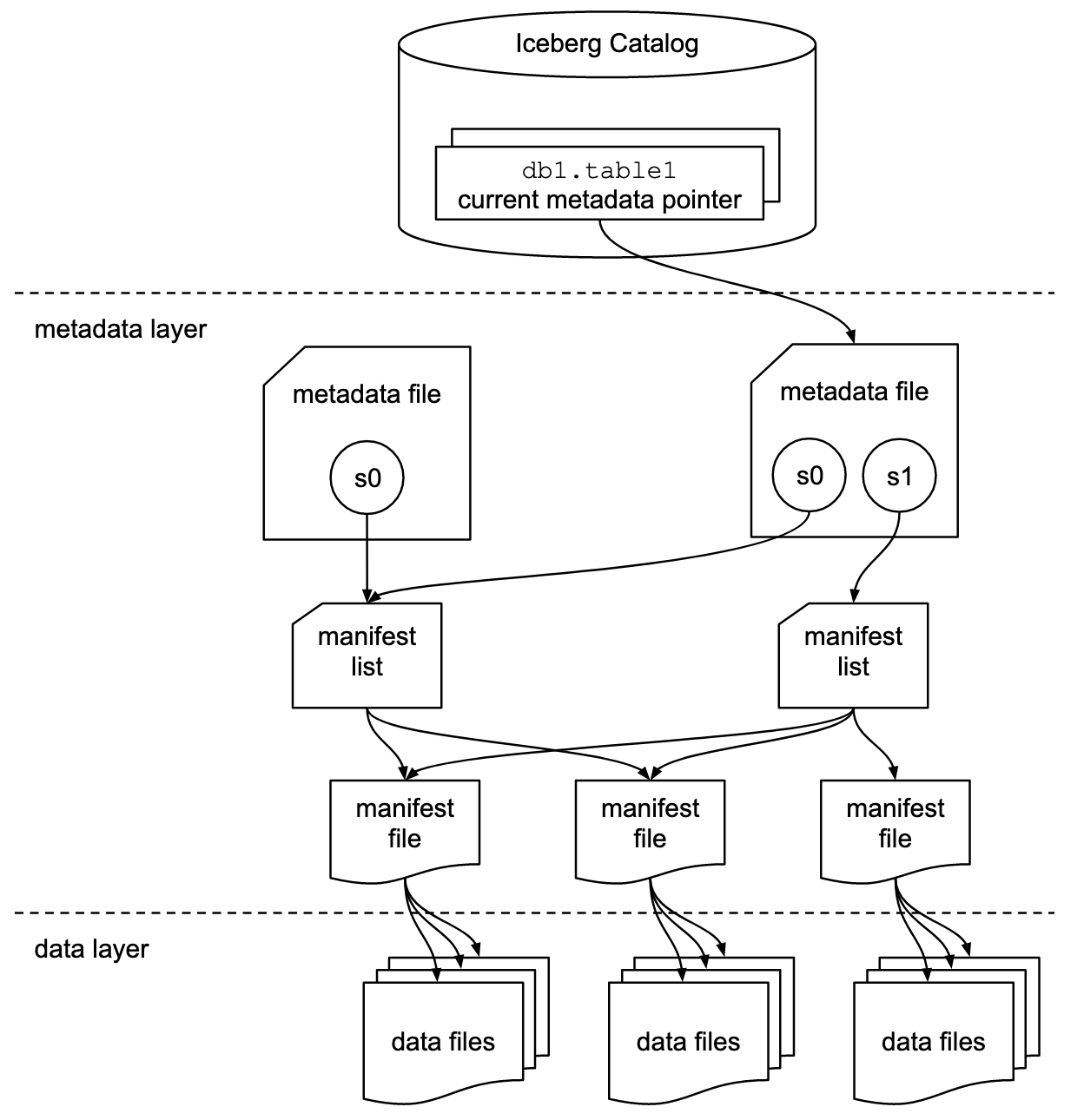
ארגונים משתמשים במימושים שונים לממשק הקטלוג של Iceberg. כל אחד משתלב עם חנויות מטא-נתונים ושירותים שונים. המימושים העיקריים כוללים:
- קטלוג Hadoop: משתמש במערכת הקבצים המבוזרת של Hadoop (HDFS) או במערכות קבצים תואמות אחרות לאחסון מטא-נתונים. מתאים לסביבות המשתמשות כבר ב-Hadoop.
- קטלוג Hive: משתלב עם Hive Metastore של Apache לניהול מטא-נתוני טבלאות. אידיאלי למשתמשים שמשתמשים ב-Hive לניהול המטא-נתונים שלהם.
- קטלוג AWS Glue: משתמש ב-AWS Glue Data Catalog לאחסון מטא-נתונים. מתוכנן למשתמשים שפועלים בתוך אקוסיסטמת AWS.
- קטלוג REST: מספק ממשק RESTful עבור פעולות קטלוג דרך HTTP. מאפשר אינטגרציה עם שירותי מטא-נתונים מותאמים אישית או מצד שלישי.
- קטלוג Nessie: משתמש בפרויקט Nessie, המספק חווית Git לניהול נתונים.
התאוצה והקבלה הגוברת של Apache Iceberg מעוררת רצון רב עם ספקי פלטפורמת נתונים ליישם קטלוג Iceberg משלהם. אני מדבר על מספר אסטרטגיות בקטע הבא על אסטרטגיות של פלטפורמת נתונים וספקי ענן, כולל Polaris של Snowflake, Unity של Databricks ו-Tableflow של Confluent.
תמיכה מקצועית ממדריך אייסברג ראשון לעומת מחבר אייסברג
שימו לב ש-תמיכה ב-Apache Iceberg (או Hudi/Delta Lake) אומרת הרבה יותר מסתפקת בספק מחבר ואינטגרציה עם פורמט הטבלה דרך API. ספקים ושירותי ענן מתפלגים בין התכונות המתקדמות כגון מיפוי אוטומטי בין פורמטי נתונים, SLA חיוניים, נסיעה חזרה בזמן, ממשקי משתמש אינטואיטיביים, וכדומה.
בואו נסתכל על דוגמה: אינטגרציה בין Apache Kafka ו-Iceberg. יישמו כבר מספר מחברי Kafka Connect. מקודם, הנה ה-היתרונות של שימוש באינטגרציה מקצועית עם Iceberg (למשל, Tableflow של Confluent) בהשוואה לשימוש סתם במחבר Kafka Connect:
- ללא תצורת מחבר
- לא צריך לצרף דרך המחבר
- תחזוקה מובנית (קיטוט, איסוף אשפה, ניהול חידושי צילום)
- תפוסת תוכן אוטומטית
- סנכרון עם שירות קטלוג חיצוני
- פעולות פשוטות (בפתרון SaaS ניהול מלא, הוא serverless ואין צורך בכל סוג של התקנה או תפעול על ידי המשתמש הסופי)
היתרונות הדומים חלים גם על פלטפורמות נתונים אחרות ואינטגרציה ראשונית פוטנציאלית בהשוואה לספק חיבורים פשוטים.
פורמט טבלה פתוח עבור אגם נתונים / בית אגם בשימוש ב-Apache Iceberg, Apache Hudi ו-Delta Lake
המטרה הכללית של מסגרת פורמט טבלה כגון Apache Iceberg, Apache Hudi ו-Delta Lake היא לשפר את הפונקציונליות והאמינות של אגמי נתונים על ידי טיפול באתגרים נפוצים הקשורים לניהול נתונים בגדלים גדולים. מסגרות אלה עוזרות ל:
- לשפר את ניהול הנתונים
- לסייע בטיפול קל יותר בספיקת נתונים, אחסון ולקיחתם מהאגמים.
- לאפשר ארגון ואחסון נתונים יעילים, תומכים בביצועים וקידמה טובים יותר.
- להבטיח עדכנות של נתונים
- לספק אמצעים לעסקת ACID, המבטיחים שהנתונים יישארו עדכניים ואמינים גם במהלך פעולות קריאה וכתיבה משותפות.
- לתמוך בבידוד צילומי, מאפשר למשתמשים לראות מצב עדכני של הנתונים בכל נקודת זמן.
- תמוך באבולוציית סכימה
- אפשר שינויים בסכימת הנתונים (כגון הוספת, שינוי שמות או הסרת עמודות) בלי לפרוץ את הנתונים הקיימים או לדרוש העברות מורכבות.
- מיטב ביצועי השאילתא
- יישום אינדוקסים מתקדמים ואסטרטגיות של חלוקה כדי לשפר את מהירות ויעילות שאילתות הנתונים.
- אפשר ניהול מטא-נתונים אפקטיבי כדי להתמודד בצורה יעילה עם סטים גדולים של נתונים ושאילתות מורכבות.
- שפר מנהל נתונים
- ספק כלים למעקב וניהול משפחת נתונים טובים יותר, גרסאות וביקורת, שהם חיוניים לשמירה על איכות הנתונים ועל התאמה לתקנים.
על ידי כתיבת מטרות אלה, פרמטרים כמו Apache Iceberg, Apache Hudi, ו-Delta Lake עוזרים לארגונים לבנות אגם נתונים ואגם בית נתונים עוצמתיים, משתנים ואמינים יותר. מהנדסי נתונים, מדעני נתונים וניתוח עסקי משתמשים בכלים לניתוח, AI/ML, או דיווח/תצוגה על פני הפרמטר כדי לנהל ולנתח כמויות נתונים גדולות.
השוואה בין Apache Iceberg, Hudi, Paimon, ו-Delta Lake
אני לא אעשה השוואה של פרמטרים כמו Apache Iceberg, Apache Hudi, Apache Paimon, ו-Delta Lake כאן. רבים מומחים כתבו כבר על כך. לכל פרמטר יש נקודות חוזק ויתרונות ייחודיים. אך עדכונים דרושים כל חודש בגלל התפתחות וחדשנות מהירה, הוספת שדרוגים חדשים ויכולות בתוך מסגרת אלה.
הנה תקציר של מה שראיתי בפוסטים בבלוגים שונים על ארבעת האפשרויות:
- Apache Iceberg: מתברג בתכנון סכמה ומחלוקת, ניהול מטא-נתונים יעיל, ותאימות רחבה עם מנועי עיבוד נתונים שונים.
- Apache Hudi: מתאים ביותר להזנת נתונים בזמן אמת ועדכונים, עם יכולות חידוש נתונים חזיתיות חזקות וגרסאות של נתונים.
- Apache Paimon: פרמטר אגם שמאפשר בניית ארכיטקטורת בית נתונים בזמן אמת עם Flink ו-Spark לפעולות שטרימינג ואצווה.
- Delta Lake: מספק עסקאות ACID חזקות, אכיפת סכמה, ותכונות שעה-נסיעה, מה שהופך אותו לאידיאלי לשמירה על איכות ועל תקינות הנתונים.
נקודת ההחלטה המרכזית עשויה להיות ש-Delta Lake אינה מופעלת על ידי קהילה רחבה כמו Iceberg ו-Hudi, אלא בעיקר על ידי Databricks כספק יחיד שעומד מאחוריו.
Apache XTable כפריימוורק מתמרבת שתומכת בשיתוף פעולה צלבי בין טבלאות המאגרים של Iceberg, Hudi ו-Delta Lake
למשתמשים יש הרבה בחירות. XTable, הידוע קודם בשם OneTable, הוא פריימוורק טבלאות בשלבי הגידול על פי רישיון הקוד הפתוח של Apache המאפשר שיתוף פעולה חלקי וקל בין Apache Hudi, Delta Lake ו-Apache Iceberg
Apache XTable:
- מספק שיתוף פעולה צלבי ואומנידירקציונלי בין טבלאות המאגרים.
- אינו חדש או פורמט נפרד. Apache XTable מספק מופעים וכלים לתרגום של מטא-נתונים בפורמט טבלאות המאגרים
אולי Apache XTable היא התשובה לספק אפשרויות לפלטפורמות נתונים ספציפיות ולספקי שירותי ענן בעוד הפקת שילוב פשוט ושיתוף פעולה.
אך היזהר: עטיפה מעל טכנולוגיות שונות אינה תרופה קסומה. ראינו זאת לפני שנים כאשר Apache Beam צמח. Apache Beam הוא מודל אחיד וסט של SDKs ספציפיים לשפה להגדרת וביצוע זרימת נתונים ועיבוד נתונים. הוא תומך במגוון של מנועי עיבוד זרימה, כמו Flink, Spark ו-Samza. הדריבר העיקרי מאחורי Apache Beam הוא Google, שמאפשר את תהליכי המיגרציה ב-Google Cloud Dataflow. מצד שני, ההגבלות עצומות, מאחר ועטיפה כזו צריכה למצוא את המחליף המשותף הקטן ביותר של תכונות תמיכה. ורוב היתרונות העיקריים של מסגרת העבודה הם ה-20% שאינם מתאימים לעטיפה כזו. בגלל הסיבות הללו, לדוגמה, Kafka Streams לא תומך במסגרת Apache Beam במתכונת מכיוון שזה היה דורש הרבה מדי הגבלות עיצוב.
אימוץ שוק של מסגרות פורמט טבלה
למעשה, אנחנו עדיין בשלבי ההתחלה. אנחנו עדיין בשלב המעורבות בהיבט של מעגל ההתלהבות של Gartner, מתקרבים לשיא של הציפיות המנופחות. רוב הארגונים עדיין מעריכים אך לא מאמצים את פורמטי הטבלה הללו לייצור בכל הארגון עדיין.
זיכרון לאחור: מלחמת התוכניות של Kubernetes נגד Mesosphere נגד Cloud Foundry
הדיון סביב Apache Iceberg מזכיר לי את מלחמת התוכניות מכמה שנים לפני. המונח "מלחמת התוכניות" מתייחס לתחרות והמרד בין טכנולוגיות ופלטפורמות שונות לתיקונים ולתשתיות בתחום פיתוח תוכנה ותשתיות מחשוביות.
שלושת הטכנולוגיות המתחרותיות היו Kubernetes, Mesosphere ו-Cloud Foundry. הנה איפה זה הלך:

קלאוד פאונדרי ומסוספיר היו בתחילתן, אך קוברנטיס עדיין ניצח בקרב. למה? אף פעם לא הבנתי את כל הפרטים הטכניים וההבדלים. בסופו של דבר, אם המסגרות שלשתן די דומות, הכל נעשה על פי:
- אימוץ על ידי הקהילה
- הזמן הנכון לשחרור תכונות
- שיווק טוב
- מזל
- ועוד מספר גורמים
אך זה טוב לתעשיית התוכנה לקבל מסגרת קוד פתוח מובילה אחת לבניית פתרונות ודפוסי עסקים במקום שלושה מתחרים.
הווה: מלחמת הפורמטים של הטבלה בין אפאצ'י אייסברג להודי לדלתא לייק
ברור, Google Trends אינו ראיית עדיין או מחקר מורכב. אך השתמשתי בו הרבה בעבר ככלי אינטואיטיבי, פשוט וחינמי לניתוח מגמות שוק. לכן, השתמשתי גם בכלי זה כדי לראות האם חיפושי Google מתחפזים עם ניסיונותי האישיים באימוץ השוק של אפאצ'י אייסברג, הודי ודלתא לייק (אפאצ'י XTable קטן יותר כדי להיכלל):
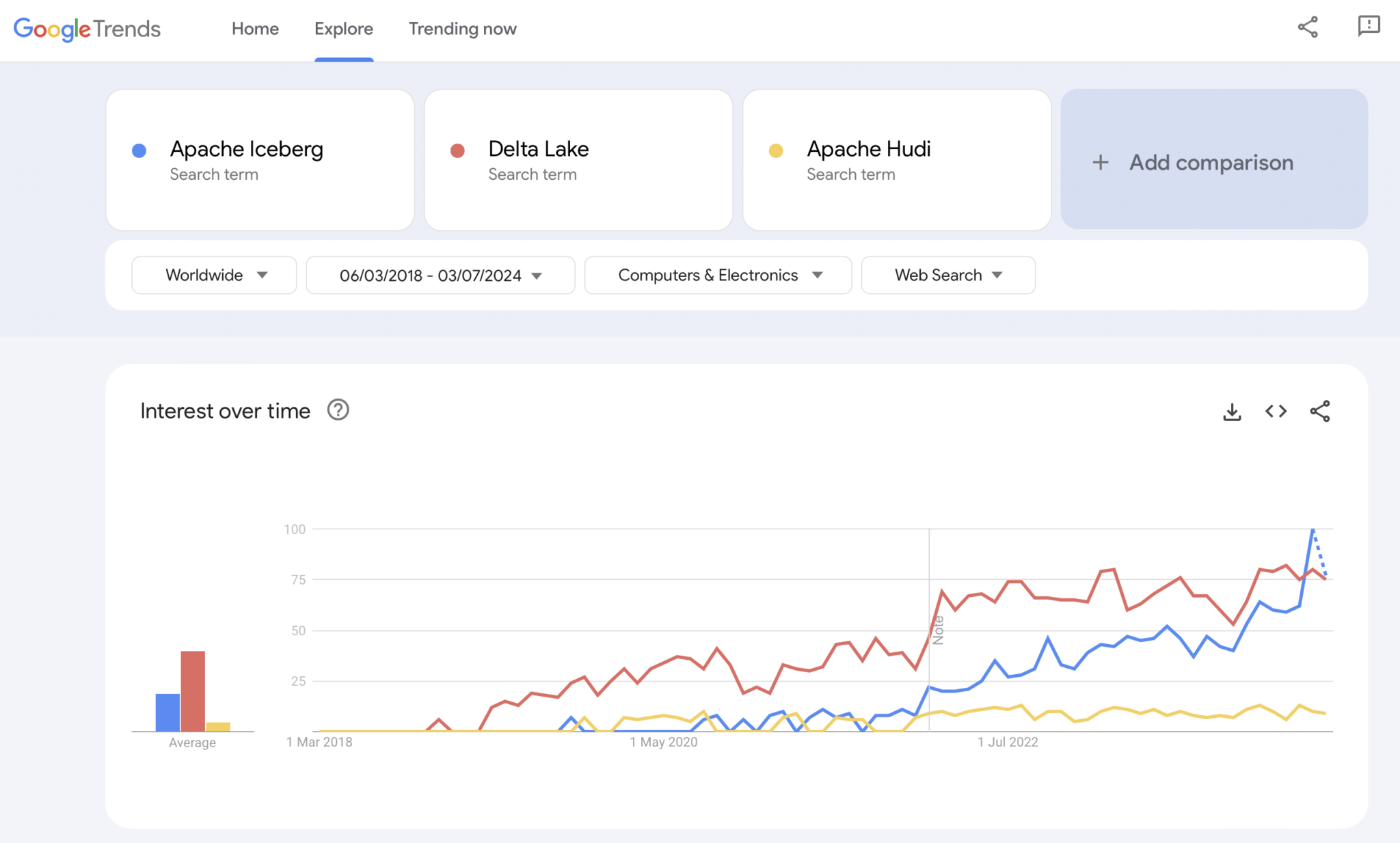
ברור שאנו רואים את אותה תבנית כמו שההילוכים בתוכניות הקונטיינרים הראו לפני מספר שנים. אין לי שום רעיון לאן זה נע. ואם טכנולוגיה אחת תנצח, או אם המסגרות יבדלו מספיק כדי להוכיח שאין כדור כסף, העתיד יראה לנו.
הדעה האישית שלי? אני חושב ש-Apache Iceberg תנצח במרוץ. למה? אני לא יכול להתווכח עם סיבות טכניות. אני רואה פשוט שצרכנים רבים בכל התעשיות מדברים על זה יותר ויותר. וספקים רבים מתחילים לתמוך בזה. אבל נראה. למעשה, אני לא משתנה מי ינצח. אך, דומה למלחמת הקונטיינרים, אני חושב שזה טוב להציב סטנדרט אחד ולספקים להבדיל בתכונות מסביב לזה, דומה למה שקורה עם Kubernetes.
אך עם זאת, בואו נגלוש אל תוך האסטרטגיה הנוכחית של פלטפורמות הנתונים המובילות וספקי הענן לגבי תמיכה בפורמטי טבלאות בפלטפורמות ושירותי הענן שלהם.
אסטרטגיות של פלטפורמות נתונים וספקי ענן לגבי Apache Iceberg
אני לא אעשה כל ספקולציה בסעיף זה. ה-תפתחות של המתישים של פורמטי הטבלאות זזה מהר, ואסטרטגיות של ספקים משתנות במהירות. אנא הפנו אל אתרי הספקים למידע האחרון. אך הנה ה-סטטוס קוו על אסטרטגיות הספקים של פלטפורמות הנתונים ושירותי הענן לגבי תמיכה ואינטגרציה של Apache Iceberg.
- Snowflake:
- תומך ב-Apache Iceberg כבר מהרבה זמן
- מוסיף אינטגרציות טובות ותכונות חדשות באופן קבוע
- אפשרויות אחסון פנימיות וחיצוניות (עם התמרות) כמו אחסון של Snowflake או Amazon S3
- הכריז על Polaris, מימוש קטלוג קוד פתוח ל-Iceberg, עם התמדה לתמוך באינטגרציה דו-כיוונית שנתמכת על ידי הקהילה וספקים
- Databricks:
- מתמקדת ב-Delta Lake כפורמט הטבלה ו-Unity (שנפתח כעת) כקטלוג
- רכשה את Tabular, החברה המובילה מאחורי Apache Iceberg
- אספקת האסטרטגיה העתידית לתמוך בממשק הפתוח של Iceberg (בשני הכיוונים) או רק להזנת נתונים לתוך פלטפורמת ה-Lakehouse שלה וטכנולוגיות כמו Delta Lake ו-Unity Catalog
- Confluent:
- משתלבת עם Apache Iceberg כאזרח ראשון במערכת הזרמת הנתונים שלה (המוצר נקרא Tableflow)
- ממירה של נושא Kafka ומטה-נתוני סכימה קשורים (כלומר, חוזה נתונים) לטבלת Iceberg
- אינטגרציה דו-כיוונית בין עומסי עבודה אופרציונליים ואנליטיים
- ניתוחים עם Flink השרתי ללא שרת ו-API המאוחד שלו לעיבוד עפ"י עקרונות הזרימה או שיתוף נתונים עם מנועי ניתוח צד שלישי כמו Snowflake, Databricks או Amazon Athena
- עוד פלטפורמות נתונים ומנועי ניתוח מקור פתוח:
- רשימת הטכנולוגיות ושירותי הענן שתומכים ב-Iceberg גדלה מדי חודש
- כמה דוגמאות: Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst בשימוש ב- Trino (בעבר PrestoSQL), Cloudera בשימוש ב-Impala, Imply בשימוש ב-Apache Druid, Fivetran
- ספקי שירותי ענן (AWS, Azure, Google Cloud, Alibaba):
- אסטרטגיות ואינטגרציות שונות, אך כל ספקי הענן משפיעים על תמיכתם ב-Iceberg בשירותיהם בימים אלה, לדוגמה:
- אחסון אובייקטים: Amazon S3, אחסון אגם הנתונים של Azure (ALDS), אחסון ענן של Google Cloud
- קטלוגים: ספציפיים לענן כמו AWS Glue Catalog או ספציפיים לספק כמו Project Nessie או קטלוג Hive
- ניתוח: Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
- אסטרטגיות ואינטגרציות שונות, אך כל ספקי הענן משפיעים על תמיכתם ב-Iceberg בשירותיהם בימים אלה, לדוגמה:
ארכיטקטורת ההיסט שמשלבת את Kafka, Flink ו-Iceberg כדי לאחד עומסי עבודה אופרטיביים וניתוחיים
ארכיטקטורת ההיסט מעבירה עיבוד נתונים קרוב יותר למקור הנתונים, תוך השתמשות בטכנולוגיות זרימת נתונים בזמן אמת כמו Apache Kafka ו-Flink כדי לעבד נתונים בתנועה ישירות לאחר הקליטתם. גישה זו מורידה את הלטנציה ומשפרת את העקביות ואיכות הנתונים.
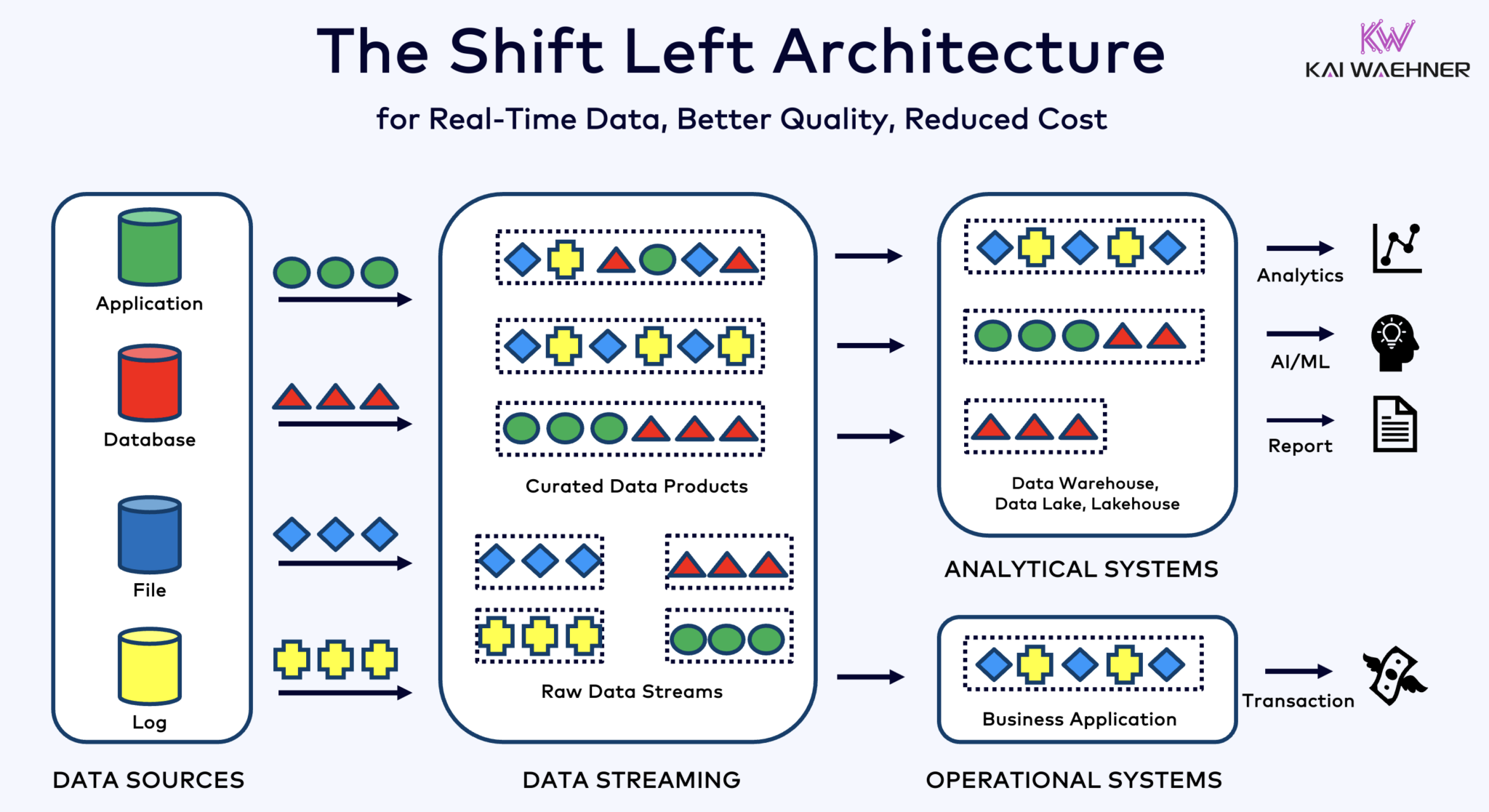
בניגוד ל-ETL ו-ELT, שמשלבים עיבוד באצווה עם הנתונים שמאוחסנים במנוחה, ארכיטקטורת ההיסט מאפשרת כישור בזמן אמת של נתונים ומרתקת. היא מתאימה לעקרון "אפס ETL" על ידי הפיכת הנתונים לשימושיים מיד. אך בניגוד לאפס ETL, העברת עיבוד הנתונים לצד שמאל של ארכיטקטורת הארגון מניעה ארכיטקטורת פסטה מורכבת וקשה לתחזוקה עם מון חיבורי נקודה לנקודה.
ארכיטקטורת ההזזה שמאלה גם יכולה להפחית את הצורך ב- ETL לאחור על ידי הבטיחות שהנתונים ניתנים לפעולה בזמן אמת עבור שני המערכות, הפעלה וניתוח. בגדול, ארכיטקטורה זו משפרת את רעננות הנתונים, מפחיתה עלויות ומאיצה את הזמן לשוק של יישומים המבוססים על נתונים. למידע נוסף על המושג הזה בפוסט בבלוג שלי על "ארכיטקטורת ההזזה שמאלה."
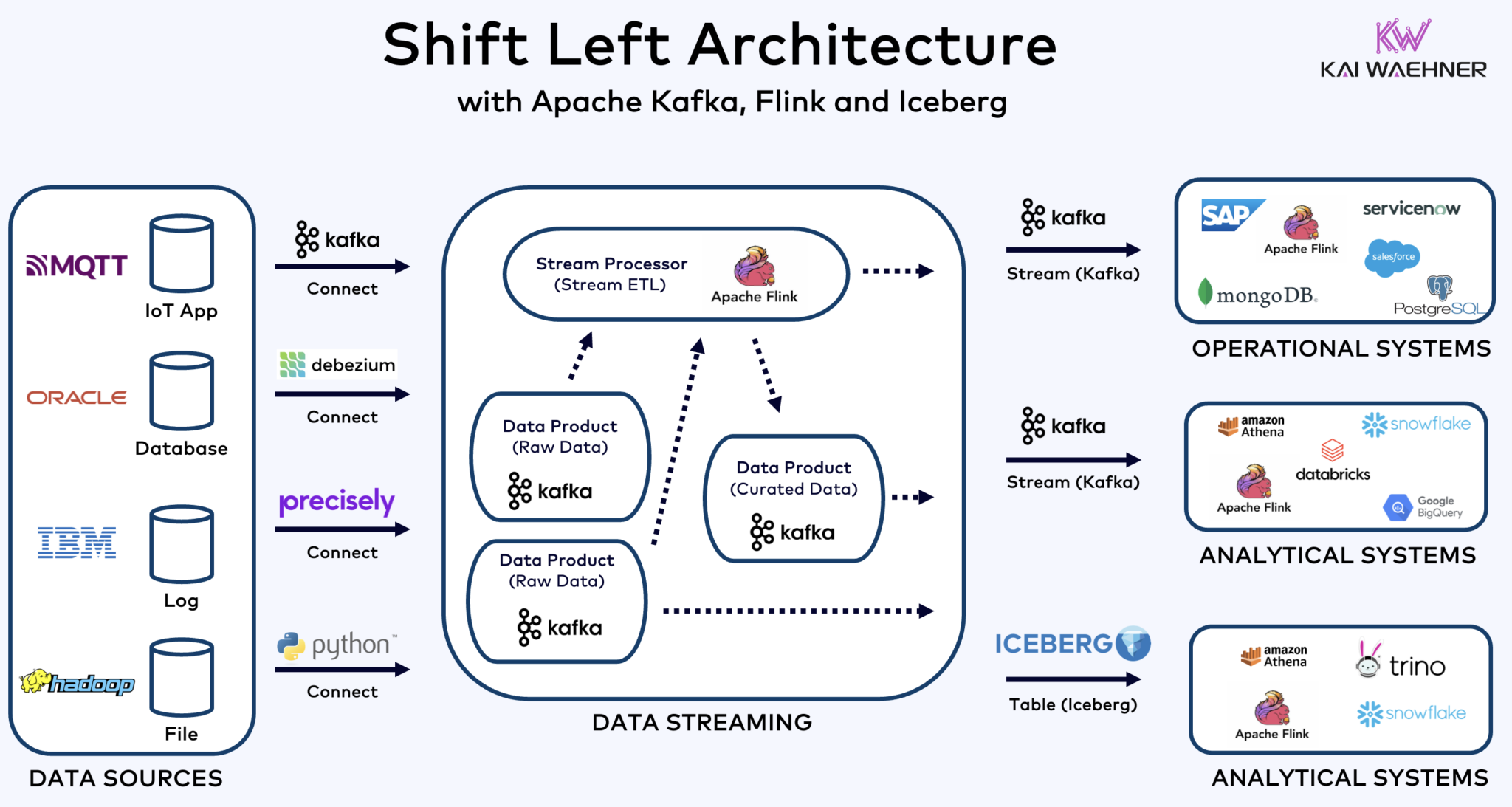
Apache Iceberg כפורמט טבלה פתוח וקטלוג עבור שיתוף נתונים חלקי בין מנועי ניתוח
פורמט טבלה פתוח וקטלוג מכניסים תועלות עצומות לארכיטקטורת הארגון:
- אינטרופרביליטי
- חופש בבחירת מנועי הניתוח
- זמן לשוק מהיר יותר
- הוזלת עלויות
נראה כי Apache Iceberg מתהווה כתקן המובהק בתוך הספקים וספקי ענן. עם זאת, הוא עדיין בשלב מוקדם וטכנולוגיות תחליפיות כמו Apache Hudi, Apache Paimon, Delta Lake ו- Apache XTable מנסות גם הן לקבל תאוצה.
Iceberg ותבניות טבלה פתוחות אחרות אינם רק ניצחון ענק לאחסון יחיד ושילוב עם מספר פלטפורמות לנתונים/ניתוח/AI/ML כמו Snowflake, Databricks, Google BigQuery ועוד, אלא גם לאיחוד של עומסי עבודה אופרטיביים וניתוחיים באמצעות זרימת נתונים עם טכנולוגיות כמו Apache Kafka ו-Flink. ארכיטקטורת ההעברה שמאלה היא יתרון משמעותי להפחתת מאמצים, שיפור איכות ועקביות של הנתונים, ואפשרות לנתונים בזמן אמת במקום אפליקציות ותובנות בצורת צמית.
וסוף סוף, אם עדיין אתה שואל מה ההבדלים בין זרימת נתונים ובין lakehouses (וכיצד הם מתוספים אחד לשני), תצפה בסרטון של עשר דקות זה:
מהי האסטרטגיה שלך לתבנית טבלה? אילו טכנולוגיות ושירותי ענן אתה מחבר? בוא נתתחבר ב-LinkedIn ונדבר על זה!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming