













每個數據驅動的組織都有運營和分析工作負荷。一種優秀的選擇方法伴隨著各種數據平臺的出現,包括數據流、數據湖、數據倉庫和湖倉解決方案,以及雲服務。像Apache Iceberg 這樣的開放表格式框架在企業架構中至關重要,確保可靠數據管理和共享,無縫模式演變,高效處理大規模數據集,並提供節省成本的存儲,同時為ACID交易和時間旅行查詢提供強大的支持。
本文探討市場趨勢;表格式框架如Iceberg、Hudi、Paimon、Delta Lake和XTable的採用;以及一些數據平臺領先供應商如Snowflake、Databricks(Apache Spark)、Confluent(Apache Kafka/Flink)、Amazon Athena和Google BigQuery產品策略。
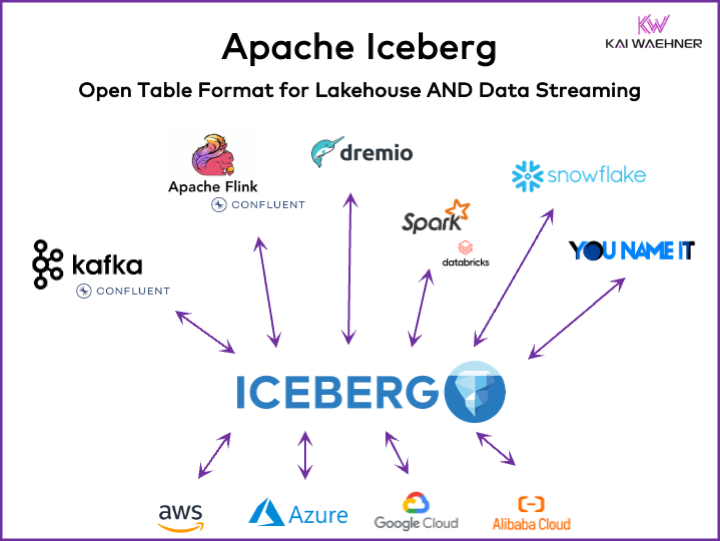
數據平臺的開放表格式是什麼?
一個開放表格式有助於維護數據完整性,優化查詢性能,並確保對平台中存儲的數據有清晰的了解。
數據平臺的開放表格式通常包括定義良好的結構,具有確保數據組織、可訪問和容易查詢的特定組件。典型的表格式包含表名、列名、數據類型、主鍵和外鍵、索引和約束。
這不是一個新的概念。您最喜歡的數十年舊數據庫 — 如Oracle、IBM DB2(甚至是在大型機上)或PostgreSQL — 使用的是同樣的原則。然而,針對雲數據倉庫、數據湖和湖倉在可擴展性、性能和查詢能力方面,需求與挑戰有所改變。
「湖倉表格式」的優點,如Apache Iceberg
組織的每一個部分都變得數據驅動。其結果是大量數據集、跨業務單位與數據產品共享數據,以及對近實時數據處理的新需求。
Apache Iceberg為企業架構提供了許多優點:
- 單一存儲:數據只存儲一次(來自各種數據源),從而減少了成本和複雜性
- 互操作性:從任何分析引擎訪問,無需整合努力
- 所有數據:統一運營和分析工作負荷(交易系統、大數據日誌/IoT/點擊流、移動API、第三方B2B接口等)
- 供應商獨立性:與任何喜歡的分析引擎一起工作(無論它是近實時、批處理還是基於API的)
Apache Hudi和Delta Lake提供了同樣的特點。儘管如此,Delta Lake主要由Databricks作為單一供應商推動。
表格式和目錄接口
了解Apache Iceberg或類似表格格式框架的討論包括兩個概念:表格格式和目錄接口! 作為這項技術的終端用戶,你需要這兩者!
Apache Iceberg項目實作了這種格式,但僅提供目錄的規範(而非實作):
- 表格格式定義了數據在表內如何組織、儲存和管理。
- 目錄接口管理表的元數據,並為數據湖中訪問表提供了一個抽象層。
Apache Iceberg文件詳盡地探討了這些概念,基於以下這張圖:
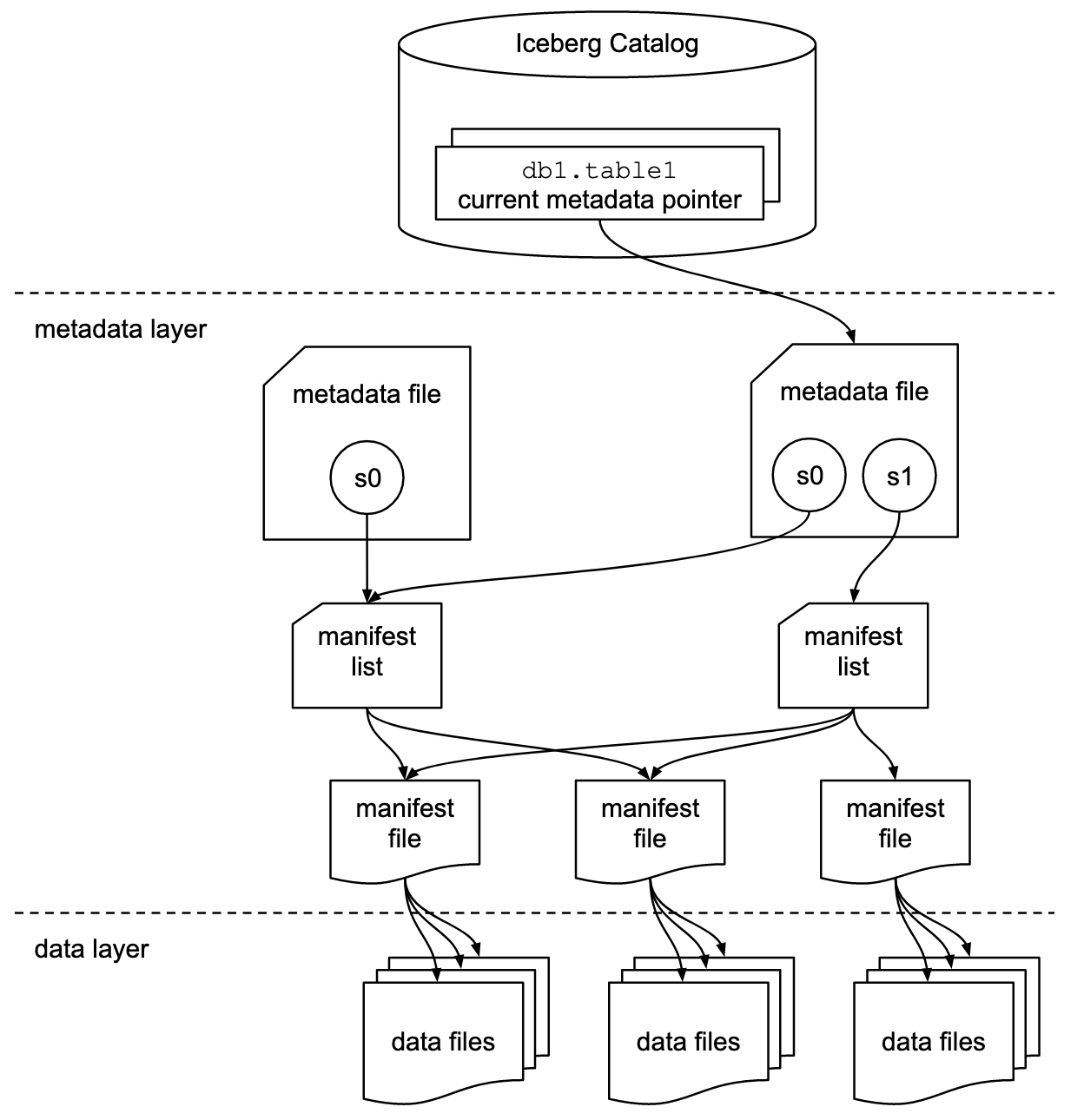
組織使用各種實作來實現Iceberg的目錄接口。每一個都與不同的元數據存儲和服務整合。关键的實作包括:
- Hadoop目錄:使用Hadoop分布式文件系統(HDFS)或其他兼容的文件系統來存儲元數據。適合已經使用Hadoop的環境。
- Hive目錄:與Apache Hive Metastore整合來管理表元數據。對於使用Hive進行元數據管理的用戶來說是理想的。
- AWS Glue目錄:使用AWS Glue Data Catalog來存儲元數據。為在AWS生態系統中運作的用戶設計。
- >REST目錄:通過HTTP提供RESTful介面以進行目錄操作。能夠與自定義或第三方元數據服務進行集成。
- Nessie目錄:使用Project Nessie,為管理數據提供類似Git的體驗。
Apache Iceberg的動力和日益增多的採用,激勵許多數據平臺供應商實現他們自己的Iceberg目錄。我將在下面的數據平臺和云供應商策略部分中討論幾種策略,包括Snowflake的Polaris、Databricks的Unity和Confluent的Tableflow。
一等Iceberg支援與Iceberg連接器
請注意,支援Apache Iceberg(或Hudi/Delta Lake)意味著遠遠不僅僅是提供一個連接器和通過API與表格式進行集成。供應商和云服務通過先進功能如數據格式之間的自动映射、關鍵SLA、時間旅行、直觀用戶界面等進行區分。
讓我們看看一個例子:Apache Kafka與Iceberg的集成。已經實現了各種Kafka Connect連接器。然而,在這裡,使用一等Iceberg集成(例如,Confluent的Tableflow)與僅使用Kafka Connect連接器相比有以下好處:
- 無連接器配置
- 無通過連接器消費
- 內置維護(壓縮、垃圾回收、快照管理)
- 自动模式演變
- 外部目錄服務同步
- 更簡單的操作(在完全管理的SaaS解決方案中,它是無服務器的,用戶無需進行任何規模或操作)
類似的好處也適用於其他數據平台以及與提供簡單連接器相比的潛在一流整合。
使用Apache Iceberg、Apache Hudi和Delta Lake的數據湖/湖倉開放表格式
Apache Iceberg、Apache Hudi和Delta Lake等表格式框架的普遍目標是通過解決管理大規模數據的常見挑戰來增強數據湖的功能和可靠性。這些框架有助於:
- 改善數據管理
- 方便數據湖中的數據吸入、存儲和检索。
- 支持有效的數據組織和存儲,支持更好的性能和可擴展性。
- 確保數據一致性
- 提供ACID交易的機制,確保即使在使用並發讀寫操作時,數據也能保持一致和可靠。
- 支持快照隔離,使用戶能夠在任何時間點查看數據的一致性狀態。
- 支援模式演變
- 允許在不中斷現有數據或不需複雜遷移的情況下,變更數據模式(例如添加、重命名或刪除列)。
- 優化查詢性能
- 實現先進的索引和分區策略以提升數據查詢的速度和效率。
- 啟用高效的事務元數據管理以有效處理大量數據集和複雜查詢。
- 增強數據治理
- 提供工具以更好地追蹤和管理數據血統、版本控制和審計,這些對於維護數據品質和合規性至關重要。
透過解決這些目標,像Apache Iceberg、Apache Hudi和Delta Lake這樣的表格格式框架有助於組織構建更健壯、可擴展且可靠數據湖和數據湖倉。數據工程師、數據科學家和商業分析師可以利用表格格式上的分析、AI/ML或報告/視覺化工具來管理和分析大量數據。
Apache Iceberg、Hudi、Paimon與Delta Lake的比較
在這裡我不會對Apache Iceberg、Apache Hudi、Apache Paimon和Delta Lake這些表格格式框架進行比較。已經有許多專家寫過這方面的內容。每個表格格式框架都有其獨特的優勢和好處。但每月都需要更新,因為這些框架的快速演化和創新,在不斷增加新的改進和能力。
以下是我從各種博客文章中看到的這四種選項的總結:
- Apache Iceberg:在模式及分区演變、高效元數據管理和與各種數據處理引擎的廣泛兼容性方面表現出色。
- Apache Hudi:最適合實時數據吸入和更新,具有強大的變更數據捕獲能力和數據版本控制。
- Apache Paimon:一種數據湖格式,能夠利用Flink和Spark構建實時數據湖倉架構,同時支持流處理和批處理操作。
- Delta Lake:提供堅固的ACID交易、模式執行和時間旅行功能,使其成為維護數據質量和完整性的理想選擇。
一個關鍵決策點可能是Delta Lake不是由像Iceberg和Hudi那樣廣泛的社群驅動,而是主要由Databricks作為背後的唯一供應商。
Apache XTable作為支持Iceberg、Hudi和Delta Lake的互通跨表框架
用戶有許多選擇。 XTable,此前稱為OneTable,是另一個在Apache開源許可下孵化中的表框架,用以無縫實現Apache Hudi、Delta Lake和Apache Iceberg之間的跨表互通。
Apache XTable:
- 提供跨表全方位互通,涵蓋數據湖倉表格式。
- 是不是一個新的或獨立的格式。Apache XTable提供抽象化和工具,用以轉換數據湖倉表格式的元數據。
也許Apache XTable就是答案,它在為特定數據平台和雲供應商提供選項的同時,仍然能夠提供簡單的集成和互通。
但請小心:在不同的技術之上增加一個包装並非萬靈丹。我們多年前在Apache Beam問世時就看到了這一點。Apache Beam是一個開源統一模型,以及一套特定於語言的SDK,用以定義和執行數據引入和數據處理工作流。它支持多種流處理引擎,如Flink、Spark和Samza。Apache Beam的主要推動者是Google,它允許在Google Cloud Dataflow中遷移工作流。然而,這樣的包装的局限性非常大,因為它需要找到支持功能的最小公倍數。而大多數框架的主要優勢在於那20%不符合這種包装的部分。因此,例如,Kafka Streams故意不支持Apache Beam,因為這將要求太多設計上的限制。
市場對表格式框架的採用
首先,我們仍處於早期階段。在Gartner Hype Cycle上,我們仍然處於創新觸發階段,即將達到過高期望的頂峰。大多數組織仍在評估這些表格式,但在整個組織內部的生產環境中尚未採用。
回顧:容器大戰:Kubernetes與Mesosphere對Cloud Foundry的競爭
Apache Iceberg的辯論讓我想到幾年前的容器大戰。所謂“容器大戰”是指軟件開發和IT基礎設施領域中,不同容器化技術和平台之間的競爭和對抗。
當時有三種競爭技術:Kubernetes、Mesosphere和Cloud Foundry。以下是其發展趨勢:

Cloud Foundry 與 Mesosphere 提早出場,但 Kubernetes 還是贏得了這場戰鬥。為什麼?我從未完全理解所有技術細節和差異。最終,如果這三個框架相當類似,那就關乎於:
- 社群接受度
- 功能發布的恰當時機
- 良好的市場營銷
- 運氣
- 以及一些其他因素
但對於軟件行業來說,能夠有一個領先的開源框架來建立解決方案和商業模式,而不是三個競爭的框架,這是好事。
當前:Apache Iceberg 與 Hudi 與 Delta Lake 的表格格式戰爭
顯然,Google Trends 不是統計證據或精密研究。但過去我經常把它當作一個直觀、簡單、免費的工具來分析市場趨勢。因此,我還是使用這個工具來看看 Google 搜索是否與我個人對 Apache Iceberg、Hudi 和 Delta Lake(Apache XTable 還太小,尚未加入)的市場接受度相吻合:
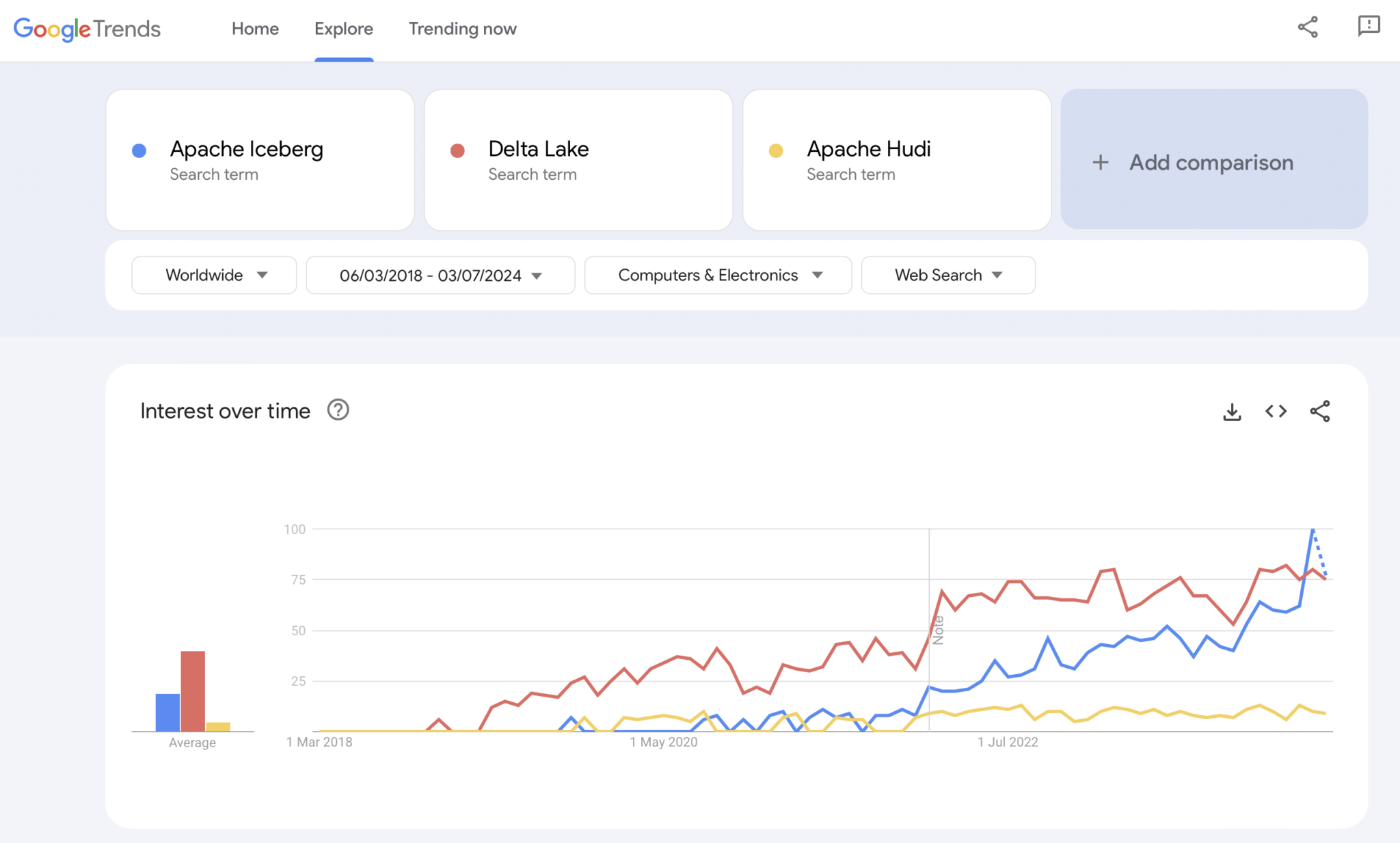
我們明顯看到與幾年前容器戰爭相似的模式。我不知這會走向何方。如果有一項技術獲勝,或者框架之間的差異足夠大以證明沒有萬應良藥,未來將會告訴我們答案。
我個人的看法?我認為Apache Iceberg會在比賽中獲勝。為什麼?我無法爭辯任何技術原因。我只是看到各個行業中的許多客戶越來越多地談論它。而且越來越多的廠商開始支持它。但我們會看到的。其實我不在乎誰會獲勝。然而,類似於容器之戰,我認為有一個單一標準並且廠商在它周圍的功能上進行差異化是好的,就像Kubernetes一樣。
但帶著這種想法,讓我們探討一下當前數據平台和雲服務供應商對於他們平台和雲服務中表格式支持的策略。
Apache Iceberg的數據平台和雲廠商策略
在這一部分,我不會做任何猜測。表格式框架的演變很快,廠商策略也會快速變化。請參考廠商的網站以獲取最新信息。但這裡是關於數據平台和雲服務供應商對於支持與整合Apache Iceberg的現狀。
- Snowflake:
- 已經支持Apache Iceberg一段時間
- 定期添加更好的整合和新的功能
- 內部和外部存儲選項(有著权衡)如Snowflake的存儲或Amazon S3
- 宣布了Polaris,一個開源的分類法實現,用于Iceberg,承諾支持由社群驅動的、廠商中立的雙向整合
- Databricks:
-
專注於Delta Lake作為表格式以及(現在已開源)Unity作為目錄
收購了Tabular,這家公司在Apache Iceberg背後是領先的
支持開放Iceberg接口(雙向)的不明確未來策略,或者只將數據餵入其lakehouse平台和技術,如Delta Lake和Unity目錄 - Confluent:
-
將Apache Iceberg作為一等公民嵌入其數據流平台(產品名為Tableflow)
將Kafka主題和相關模式元數據(即數據合同)轉換為Iceberg表
運營和分析工作負荷之間的雙向整合
使用嵌入式無服務器Flink及其統一批處理和流式API進行分析,或與第三方分析引擎如Snowflake、Databricks或Amazon Athena進行數據共享 - 更多的數據平臺和開源分析引擎:
- 支持Iceberg的技術和雲服務名單每月都在增加
- 一些例子:Apache Spark、Apache Flink、ClickHouse、Dremio、使用Trino(前稱PrestoSQL)的Starburst、使用Impala的Cloudera、使用Apache Druid的Imply、Fivetran
- 雲服務供應商(AWS、Azure、Google Cloud、Alibaba):
- 有不同的策略和整合方式,但現在所有雲服務供應商都在增加他們服務中對Iceberg的支持,例如:
- 對象存儲:Amazon S3、Azure Data Lake Storage (ALDS)、Google Cloud Storage
- 目錄:特定於雲的如AWS Glue目錄或跨供應商的如Project Nessie或Hive目錄
- 分析:Amazon Athena、Azure Synapse Analytics、Microsoft Fabric、Google BigQuery
- 有不同的策略和整合方式,但現在所有雲服務供應商都在增加他們服務中對Iceberg的支持,例如:
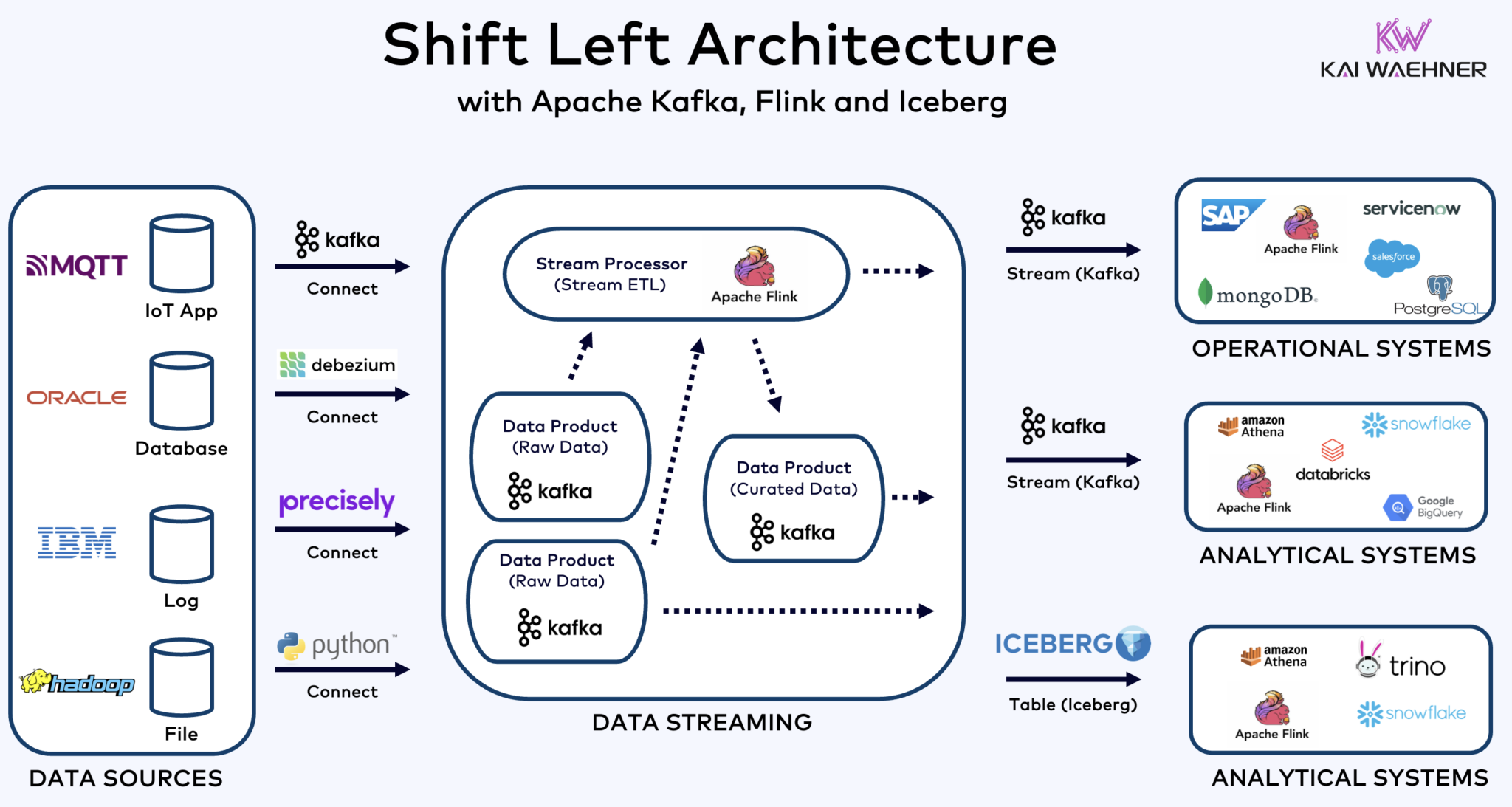
使用Kafka、Flink和Iceberg統一運營和分析工作負荷的左移架構
左移架構(shift left architecture)將數據處理更靠近數據源,利用實時數據流技術如Apache Kafka和Flink在數據被吸入後直接處理數據流。這種方法減少了延遲並提高了數據一致性與數據品質。
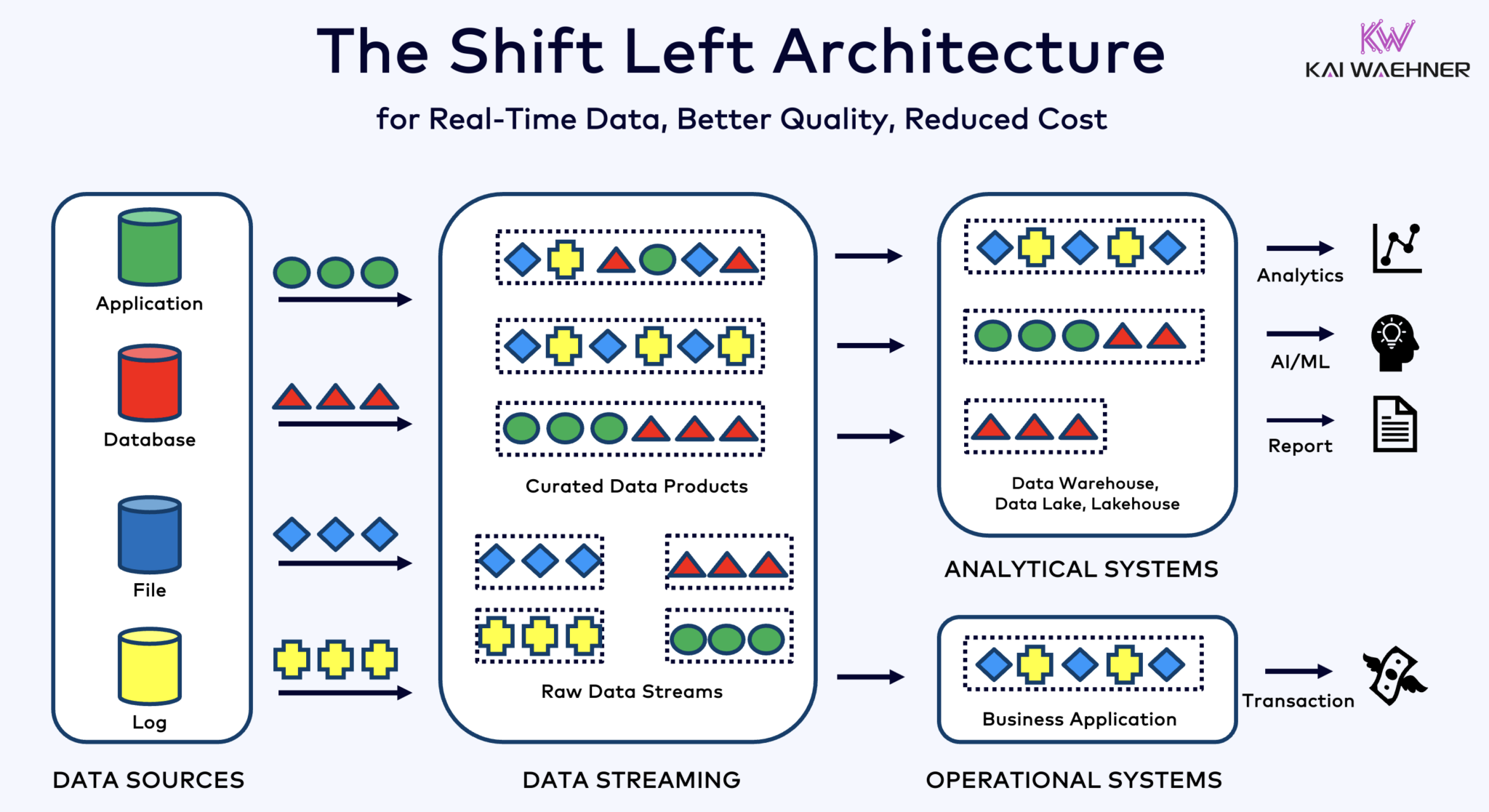
與ETL和ELT這種涉及批量處理和靜止數據的技術不同,左移架構能夠實現實時數據捕獲和轉換。它符合零ETL概念,使數據立即可用。但與零ETL相比,將數據處理向企業架構的左側移動避免了複雜且難以維護的意大利麵狀架構,這種架構有許多點對點的連接。
Shift left 構架也減少了對反向 ETL 的需求,通過確保數據能夠在實時中發揮作用 對於運營和 分析系統。總的來說,這種構架增強了數據的新鮮度,降低了成本,並加快了數據驅動應用的上市時間。在 我的博客文章”Shift Left 構架“中了解更多這個概念。
Apache Iceberg 作為開放表格式和目錄,實現了在分析引擎之間無縫數據共享
一個開放的表格式和目錄為企業架構帶來了巨大的好處:
- 互操作性
- 選擇分析引擎的自由度
- 更快的上市時間
- 降低成本
Apache Iceberg 似乎已成為跨供應商和雲服務提供商的實質性標準。然而,它仍處於早期階段,競爭和包絡技術如 Apache Hudi、Apache Paimon、Delta Lake 和 Apache XTable 也正在努力獲得動力。
冰山和其他開放式表格格式不僅對單一存儲以及與Snowflake、Databricks、Google BigQuery等多元分析/數據/AI/ML平台的整合有巨大優勢,還能夠通過使用Apache Kafka和Flink等數據流技術,實現統一 運營和分析工作負荷。左移架構能夠顯著降低努力,提高數據質量和一致性,並實現實時應用程序和洞見,而不是批量應用程序和洞見。
最後,如果你還在好奇數據流和數據湖倉之間的差異 (以及它們如何互相補充),請觀看這個十分钟的视频:
你的表格格式策略是什麼?你連接哪些技術和雲服務?讓我們在LinkedIn上聯繫並討論這個問題!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming