













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
Ma, a mia sorpresa, il test fallì poiché non riuscì a individuare l’elemento e ricevetti NoSuchElementException nei log della console. Non ero contento di vedere quell’errore, poiché si trattava di un semplice pulsante che stavo cercando di cliccare, e non c’era alcuna complessità.
Analizzando ulteriormente il problema, espandendo il DOM e controllando gli elementi radice, scoprii che il selettore del pulsante era all’interno del nodo #shadow-root(open), il che mi fece capire che necessitava di un trattamento diverso poiché si trattava di un elemento Shadow DOM.
In questa lezione sul Selenium WebDriver, discuteremo degli elementi Shadow DOM e come automatizzare l’Shadow DOM in Selenium WebDriver. Prima di passare all’automatizzazione dell’Shadow DOM in Selenium, capiamo prima cosa sia l’Shadow DOM e perché viene utilizzato.
Che cos’è l’Shadow DOM?
L’Shadow DOM è una funzionalità che permette al browser web di rendere gli elementi DOM senza inserirli nell’albero DOM principale del documento. Questo crea una barriera tra ciò che il developer e il browser possono raggiungere; il developer non può accedere all’Shadow DOM allo stesso modo in cui accede agli elementi nidificati, mentre il browser può rendere e modificare quel codice allo stesso modo in cui lo farebbe con gli elementi nidificati.
L’Shadow DOM è un modo per raggiungere l’incapsulamento nel documento HTML. Implementandolo, puoi mantenere lo stile e il comportamento di una parte del documento nascosti e separati dal resto del codice del documento, evitando così interferenze.
L’Shadow DOM permette di collegare alberi DOM nascosti a elementi nell’albero DOM regolare – l’albero Shadow DOM inizia con una radice Shadow, sotto la quale puoi collegare qualsiasi elemento allo stesso modo dell’albero DOM normale.
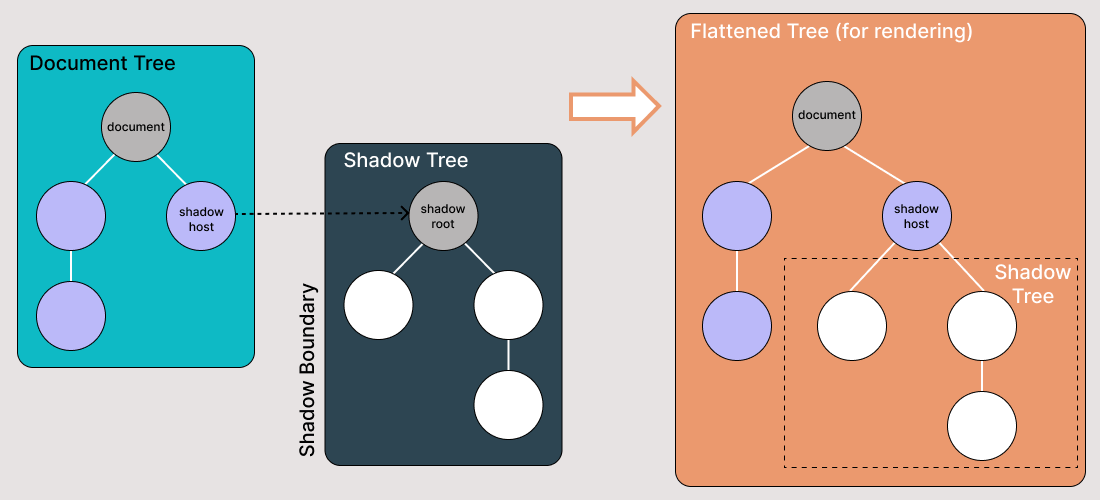
Ci sono alcuni concetti chiave di Shadow DOM di cui tenere conto:
- Host ombra: Il nodo DOM normale a cui il Shadow DOM è collegato
- Albero ombra: L’albero DOM all’interno del Shadow DOM
- Il confine ombra è dove il Shadow DOM termina e il DOM normale inizia.
- Root ombra: Il nodo root dell’albero ombra
Qual è l’utilizzo del Shadow DOM?
Shadow DOM serve per l’incapsulamento. Permette a un componente di avere il proprio “ombra” albero DOM che non può essere accidentalmente accessibile dal documento principale, può avere regole di stile locali e altro ancora.
Ecco alcune delle proprietà essenziali del Shadow DOM:
- Hanno il proprio spazio di id
- Invisibile ai selettori JavaScript dal documento principale, come querySelector
- Usa stili solo dall’albero ombra, non dal documento principale
Trovare elementi Shadow DOM utilizzando Selenium WebDriver
Quando cerchiamo di trovare gli elementi Shadow DOM utilizzando i localizzatori di Selenium, otteniamo NoSuchElementException poiché non è direttamente accessibile al DOM.
Adoperemmo la seguente strategia per accedere ai localizzatori Shadow DOM:
- Utilizzando JavaScriptExecutor.
- Utilizzando il metodo
getShadowDom()di Selenium WebDriver.
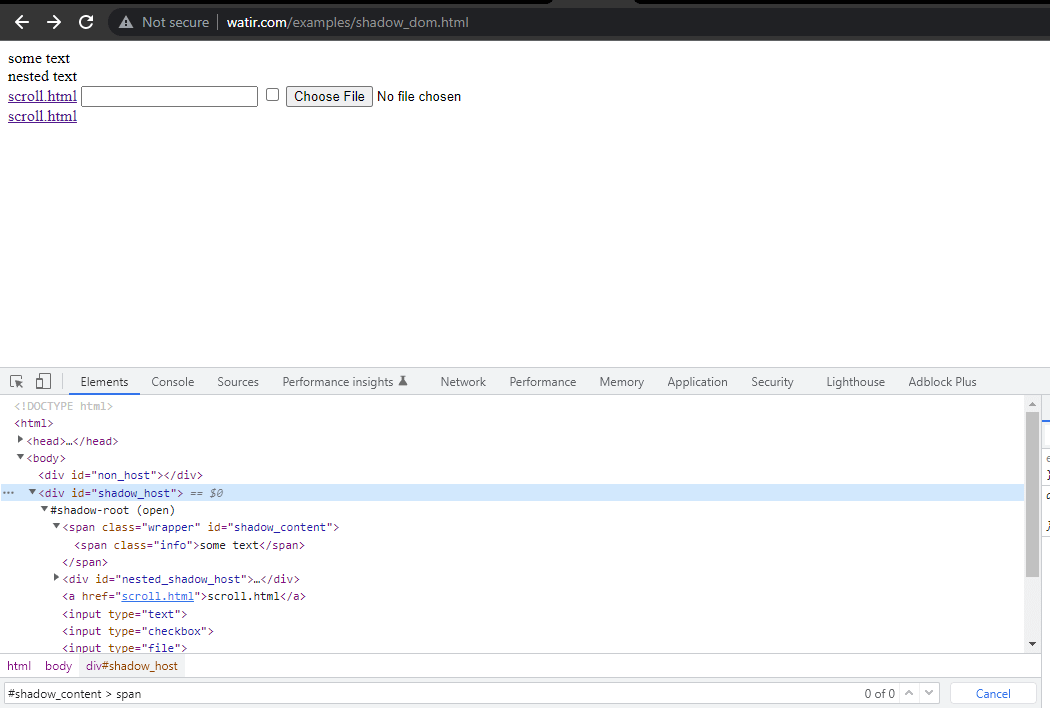
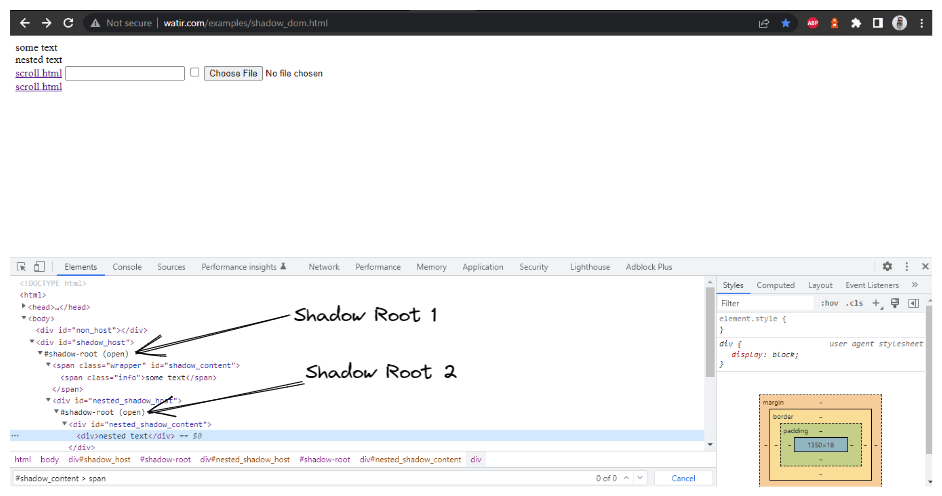
In questa sezione del blog sull’automazione del Shadow DOM in Selenium, prendiamo come esempio la Homepage di Watir.com e cerchiamo di verificare il testo del shadow DOM e del shadow DOM annidato con Selenium WebDriver. Si noti che ha un elemento radice shadow prima di raggiungere il testo -> alcuni testo, e ci sono due elementi radice shadow prima di raggiungere il testo -> testo annidato.
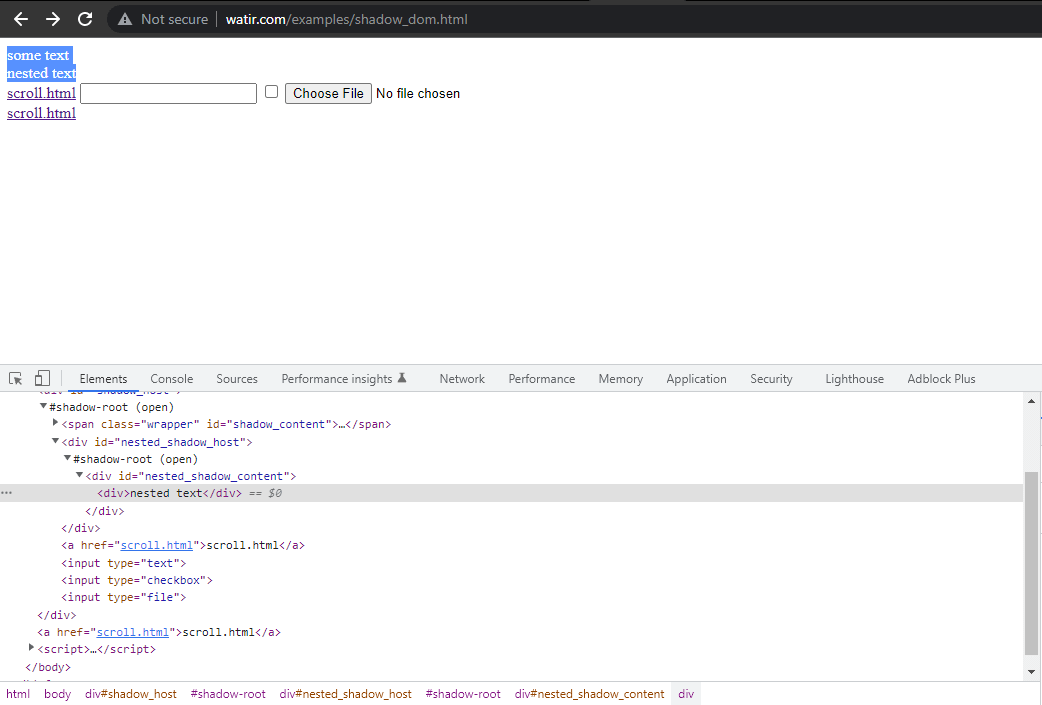
Ora, se proviamo a individuare l’elemento utilizzando il cssSelector("#shadow_content > span"), non viene individuato e Selenium WebDriver genererà NoSuchElementException.
Ecco lo screenshot della classe Homepage, che contiene il codice che cerca di ottenere il testo utilizzando
cssSelector(“#shadow_content > span”).

Ecco lo screenshot dei test in cui cerchiamo di verificare il testo (“alcuni testo”).
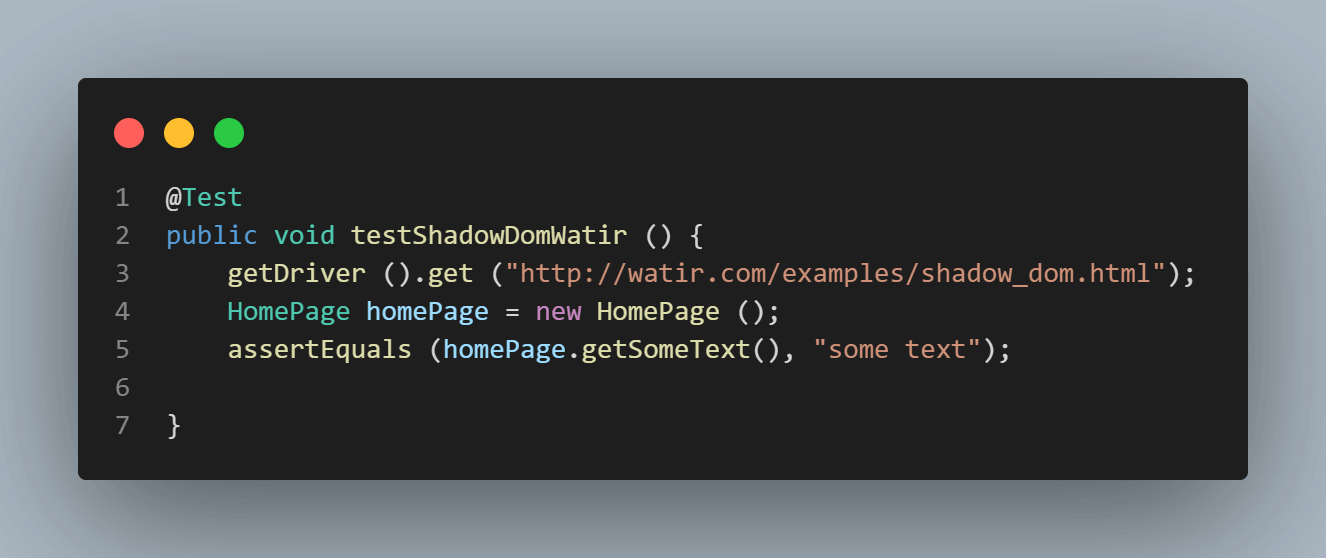
Errore durante l’esecuzione dei test mostra NoSuchElementException
Per individuare correttamente l’elemento per il testo, dobbiamo passare attraverso gli elementi radice shadow. Solo allora saremo in grado di individuare “alcuni testo” e “testo annidato” nella pagina?
Come Trovare il Shadow DOM in Selenium WebDriver Utilizzando il Metodo ‘getShadowDom’
Con la release di Selenium WebDriver versione 4.0.0 e superiori, è stato introdotto il getShadowRoot() metodo che ha facilitato l’individuazione degli elementi radice shadow.
Ecco la sintassi e i dettagli del metodo getShadowRoot():
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.Secondo la documentazione, il metodo getShadowRoot() restituisce una rappresentazione della root dell’ombra di un elemento per accedere al DOM dell’ombra di un componente web.
Nel caso in cui la root dell’ombra non venga trovata, verrà lanciata un’eccezione NoSuchShadowRootException.
Prima di iniziare a scrivere i test e discutere il codice, lasciami parlare dei tool che useremo per scrivere e eseguire i test:
Sono stati utilizzati i seguenti linguaggio di programmazione e strumenti per scrivere ed eseguire i test:
- Linguaggio di Programmazione: Java 11
- Strumento di Automazione Web: Selenium WebDriver
- Test Runner: TestNG
- Tool di Costruzione: Maven
- Piattaforma Cloud: LambdaTest
Iniziare con il Trovare Shadow DOM in Selenium WebDriver
Come discusso in precedenza, questo progetto sul Shadow DOM in Selenium è stato creato utilizzando Maven. TestNG è utilizzato come runner di test. Per saperne di più su Maven, puoi leggere questo blog su iniziare con Maven per i test Selenium.
Una volta creato il progetto, dobbiamo aggiungere la dipendenza per Selenium WebDriver e TestNG nel file pom.xml.
Le versioni delle dipendenze sono impostate in un blocco di proprietà separato. Questo viene fatto per la manutenibilità, in modo che se abbiamo bisogno di aggiornare le versioni, possiamo farlo facilmente senza cercare la dipendenza in tutto il file pom.xml.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>Passiamo ora al codice; il Page Object Model (POM) è stato utilizzato in questo progetto poiché è utile per ridurre la duplicazione del codice e migliorare la manutenzione dei casi di test.
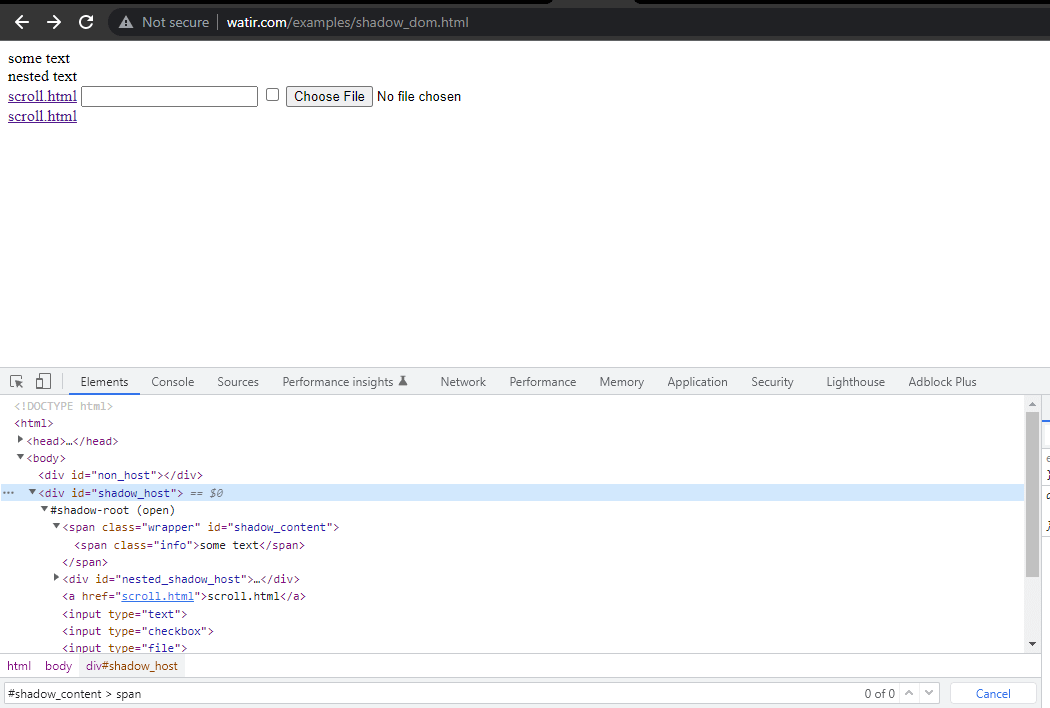
In primo luogo, troveremo il selettore per ” alcuni testo” e ” testo nidificato” sulla HomePage.
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}Code Walkthrough
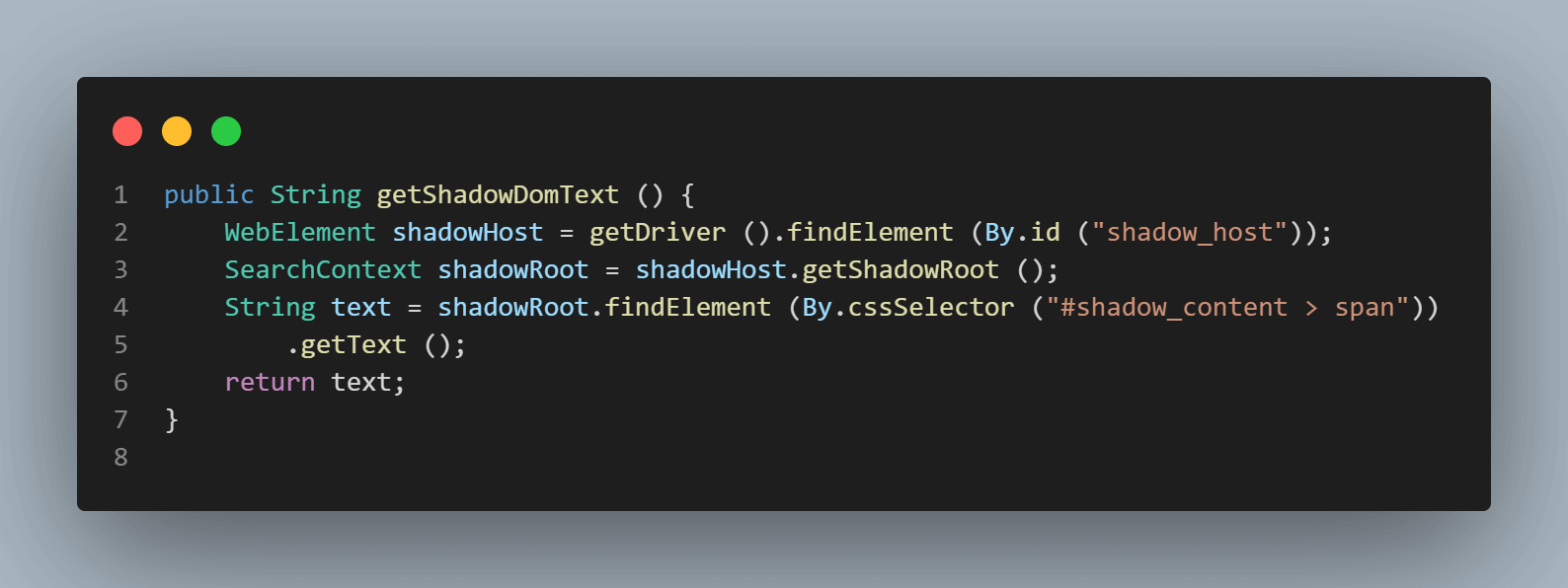
Il primo elemento che localizzeremo nel < div id = "shadow_host" > utilizzando la strategia di localizzazione – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Successivamente, cerchiamo il primo Shadow Root nel DOM accanto ad esso. Per questo, abbiamo utilizzato l’interfaccia SearchContext. Il Shadow Root viene restituito utilizzando il getShadowRoot() metodo. Se controlli lo screenshot sopra, #shadow-root (open) è accanto al < div id = "shadow_host" >.
Per individuare il testo – “alcuni testo,“, c’è solo un elemento Shadow DOM attraverso cui dobbiamo passare.
Il seguente codice ci aiuta a ottenere l’elemento radice dell’ombra.
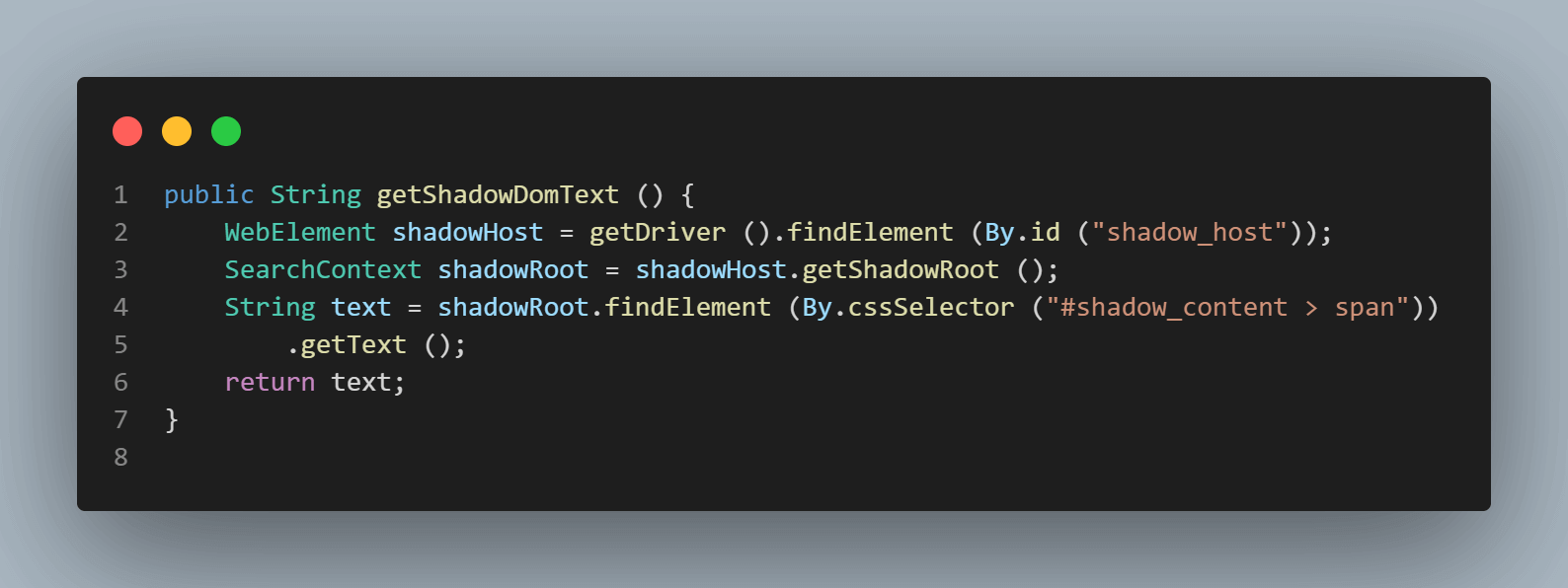
SearchContext shadowRoot = downloadsManager.getShadowRoot();Una volta trovato Shadow Root, possiamo cercare l’elemento per individuare il testo – “alcuni testo“. Il seguente codice ci aiuta a ottenere il testo:
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();Successivamente, cerchiamo il localizzatore di “testo nidificato,” che ha un elemento Shadow root nidificato, e scopriamo come individuare il suo elemento.
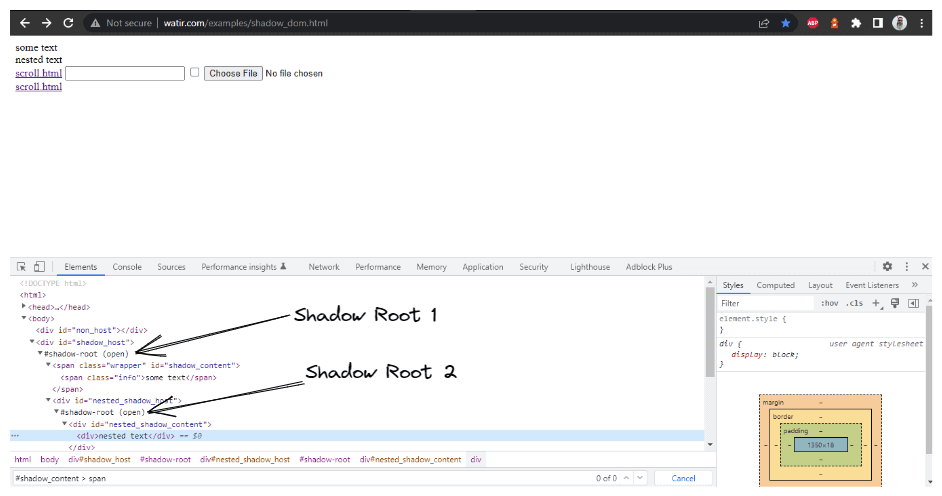
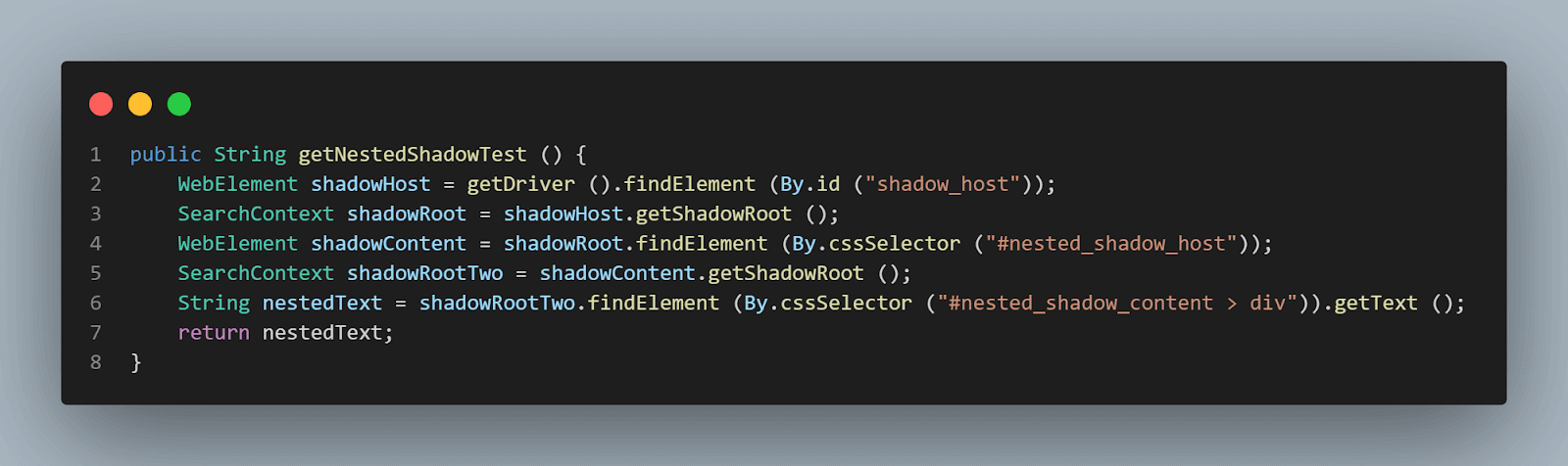
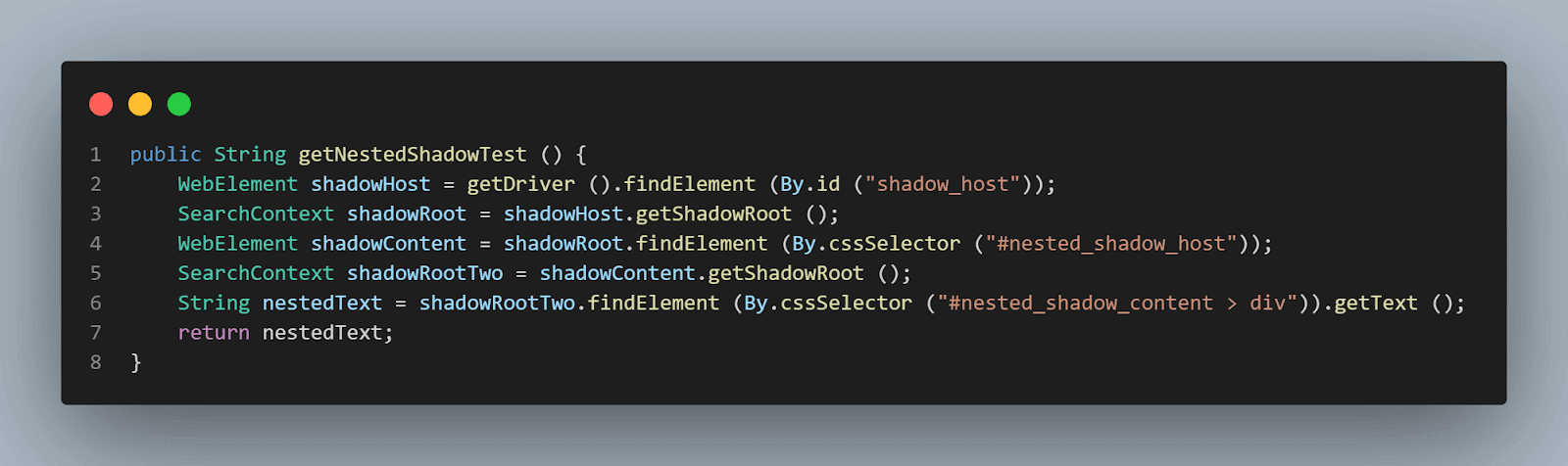
metodo getNestedShadowText():
A partire dall’inizio, come discusso nella sezione precedente, abbiamo bisogno di individuare < div id = "shadow_host" > utilizzando la strategia di localizzazione – id.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Dopodiché, dobbiamo trovare l’elemento Shadow Root utilizzando il getShadowRoot() metodo; una volta ottenuto l’elemento Shadow root, dovremo procedere alla ricerca del secondo Shadow root utilizzando cssSelector per individuare:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));Successivamente, dobbiamo trovare il secondo elemento Shadow Root utilizzando il getShadowRoot() metodo. Infine, è il momento di individuare l’elemento effettivo per ottenere il testo – “testo nidificato.”
La seguente riga di codice ci aiuterà nell’individuazione del testo:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"Scrittura del Codice in modo Fluente
Nella sezione precedente di questo blog sul Shadow DOM in Selenium, abbiamo visto un percorso lungo da dove dobbiamo individuare l’elemento effettivo con cui vogliamo lavorare, e dobbiamo effettuare molte inizializzazioni di WebElement e SearchContext interfacce e scrivere molte righe di codice per individuare un singolo elemento con cui lavorare.
Possiamo anche scrivere tutto questo codice in modo fluente, ed ecco come puoi farlo:
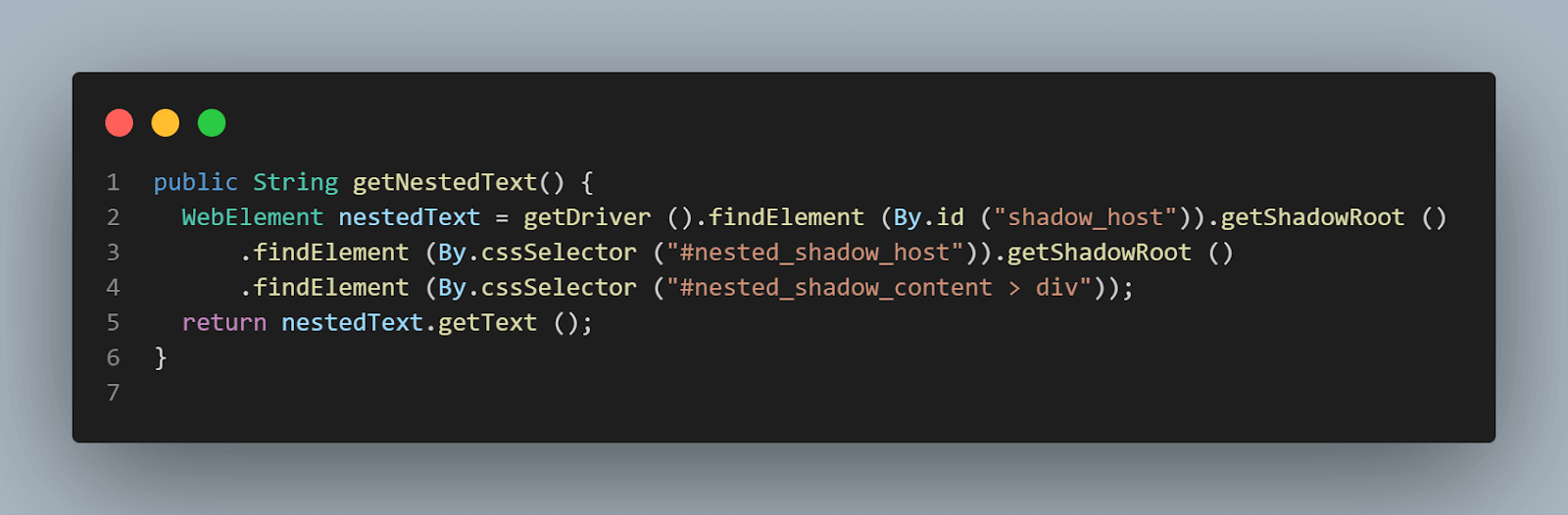
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}Il design dell’interfaccia fluida si basa in modo estensivo sulla catena di metodi. Il pattern dell’interfaccia fluida ci aiuta a scrivere codice facilmente leggibile che può essere compreso senza dover fare uno sforzo tecnico per capire il codice. Questo termine fu coniato per la prima volta nel 2005 da Eric Evans e Martin Fowler.
Questo è il metodo di concatenazione che eseguiremmo per individuare l’elemento.
Questo codice fa la stessa cosa che abbiamo fatto nei passaggi precedenti.
- In primo luogo, locateremo l’elemento shadow_host utilizzando il suo id, dopo di che otterremo l’elemento Shadow Root utilizzando il metodo
getShadowRoot(). - Successivamente, cercheremo l’elemento nested_shadow_host utilizzando il selettore CSS e otterremo l’elemento Shadow Root utilizzando il metodo
getShadowRoot(). - Infine, otterremo il testo “testo nidificato” utilizzando il selettore CSS – nested_shadow_content > div.
Come Trovare Shadow DOM in Selenium Utilizzando JavaScriptExecutor
Nei precedenti esempi di codice, abbiamo individuato elementi utilizzando il metodo getShadowRoot(). Vediamo ora come possiamo individuare gli elementi root Shadow utilizzando JavaScriptExecutor in Selenium WebDriver.
Il metodo getNestedTextUsingJSExecutor() è stato creato all’interno della classe HomePage, dove espanderemo l’elemento Shadow Root basato sul WebElement che passiamo come parametro. Nel DOM (come mostrato nella schermata sopra), abbiamo visto che ci sono due elementi Shadow Root che dobbiamo espandere prima di arrivare al vero e proprio selettore per ottenere il testo – testo nidificato. Pertanto, è stato creato il metodo expandRootElement() invece di copiare e incollare lo stesso codice JavaScript Executor ogni volta.
Implementeremo l’interfaccia SearchContext, che ci aiuterà con il JavaScriptExecutor e restituirà l’elemento Shadow root basato sul WebElement che passiamo come parametro.
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
metodo getNestedTextUsingJSExecutor()
Il primo elemento che cercheremo sarà il <div id="shadow_host"> utilizzando la strategia di localizzazione – id.
Successivamente, espanderemo l’elemento Root basato sul WebElement shadow_host che abbiamo cercato.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);Dopo aver espanso il primo Shadow Root, possiamo cercare un altro WebElement utilizzando cssSelector per individuare:
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);Finalmente, è giunto il momento di individuare l’elemento effettivo per ottenere il testo – “testo nidificato.”
Il seguente codice ci aiuterà a individuare il testo:
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();Dimostrazione
In questa sezione dell’articolo su Shadow DOM in Selenium, scriviamo rapidamente un test per verificare che i localizzatori individuati nei passaggi precedenti ci forniscono il testo richiesto. Possiamo eseguire asserzioni sul codice che abbiamo scritto per verificare che ciò che ci aspettiamo dal codice funzioni.
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}Questo è solo un semplice test per asserire che i testi siano visualizzati correttamente come previsto. Verificheremo che utilizzando l’asserzione assertEquals() in TestNG.
Nel valore effettivo, forniremmo il metodo appena scritto per ottenere il testo dalla pagina, e nel valore atteso, passeremmo il testo “some text” o “nested text,” a seconda delle asserzioni che eseguiremmo.
Sono fornite quattro istruzioni assertEquals nel test.
- Verifica dell’elemento Shadow DOM utilizzando il metodo
getShadowRoot():
- Verifica dell’elemento Shadow DOM nidificato utilizzando il metodo
getShadowRoot():
- Verifica dell’elemento Shadow DOM nidificato utilizzando il metodo
getShadowRoot()e scrivendo in modo fluente:
Esecuzione
Ci sono due modi per eseguire i test per automatizzare Shadow DOM in Selenium:
- Dall’IDE utilizzando TestNG
- Dalla CLI utilizzando Maven
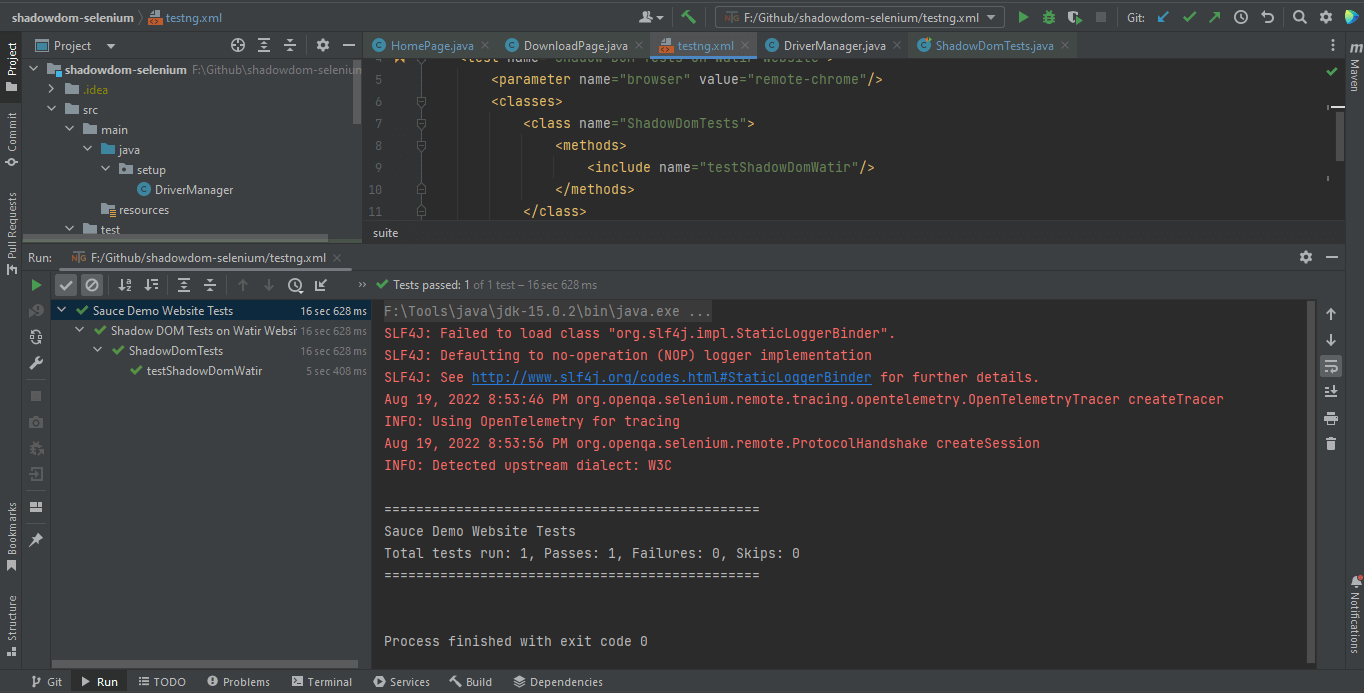
Automatizzare Shadow DOM in Selenium WebDriver Utilizzando TestNG
TestNG viene utilizzato come runner di test. Di conseguenza, è stato creato testng.xml, utilizzando il quale eseguiremo i test facendo clic destro sul file e selezionando l’opzione Esegui ‘…\testng.xml’. Ma prima di eseguire i test, dobbiamo aggiungere il nome utente e la chiave di accesso di LambdaTest nelle Configurazioni di esecuzione poiché stiamo leggendo il nome utente e la chiave di accesso dalla proprietà del sistema.
LambdaTest offre test di cross-browser su una fattoria di browser online con oltre 3000 browser reali e sistemi operativi per aiutarti a eseguire test Java sia localmente che/o nel cloud. Puoi accelerare i tuoi test Selenium con Java e ridurre il tempo di esecuzione dei test di moltiplicare eseguendo test in parallelo su vari browser e configurazioni di sistemi operativi.
- Aggiungi i valori nelle Configurazioni di esecuzione come descritto di seguito:
- Dusername =
< Nome utente LambdaTest > - DaccessKey =
< Chiave di accesso LambdaTest >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
</suite>Ecco lo screenshot dell’esecuzione del test localmente per Shadow DOM in Selenium utilizzando Intellij IDE.
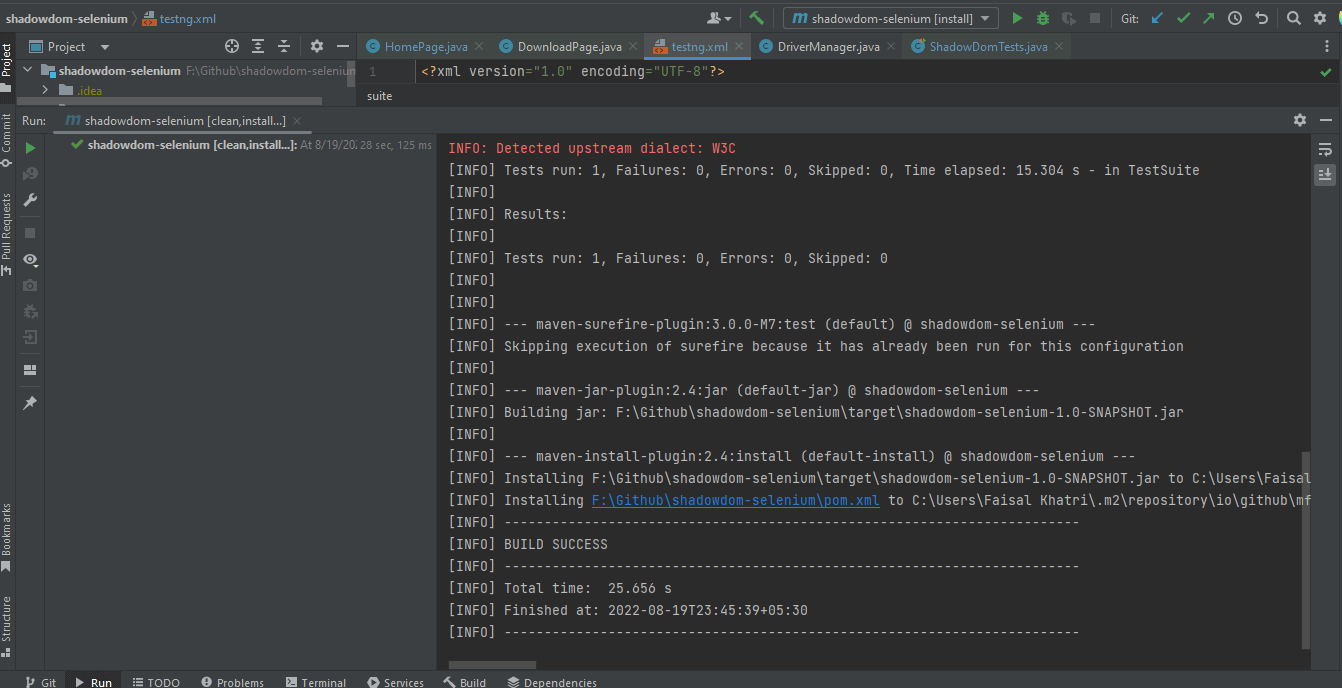
Automatizzare Shadow DOM in Selenium WebDriver Utilizzando Maven
Per eseguire i test utilizzando Maven, è necessario eseguire i seguenti passaggi per automatizzare Shadow DOM in Selenium:
- Apri il Prompt dei comandi/Terminale.
- Naviga alla cartella root del progetto.
- Digita il comando:
mvn clean install -Dusername=< Nome utente LambdaTest > -DaccessKey=< Chiave di accesso LambdaTest >.
Ecco uno screenshot da IntelliJ che mostra lo stato di esecuzione dei test utilizzando Maven:
Una volta che i test sono stati eseguiti con successo, possiamo controllare il Dashboard di LambdaTest e visualizzare tutti i video registrati, screenshot, log dei dispositivi e dettagli granulari passo passo dell’esecuzione del test. Dai un’occhiata agli screenshot qui sotto, che ti daranno un’idea abbastanza chiara del dashboard per i test automatizzati dell’app.
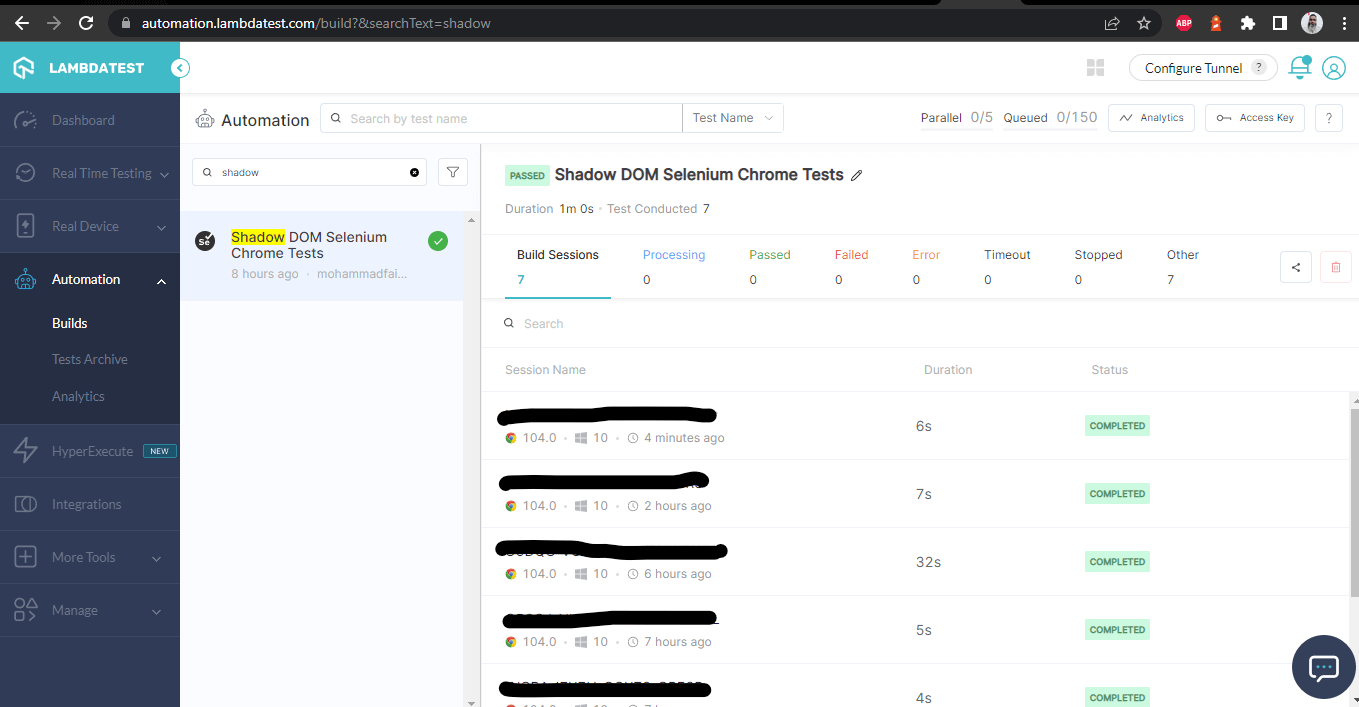 Dashboard LambdaTest
Dashboard LambdaTest
Gli screenshot seguenti mostrano i dettagli della build e dei test eseguiti per automatizzare Shadow DOM in Selenium. Ancora una volta, il nome del test, il nome del browser, la versione del browser, il nome dell’OS, la versione corrispondente dell’OS e la risoluzione dello schermo sono tutti visibili correttamente per ogni test.
Contiene anche il video del test eseguito, dando un’idea migliore di come i test sono stati eseguiti sul dispositivo.
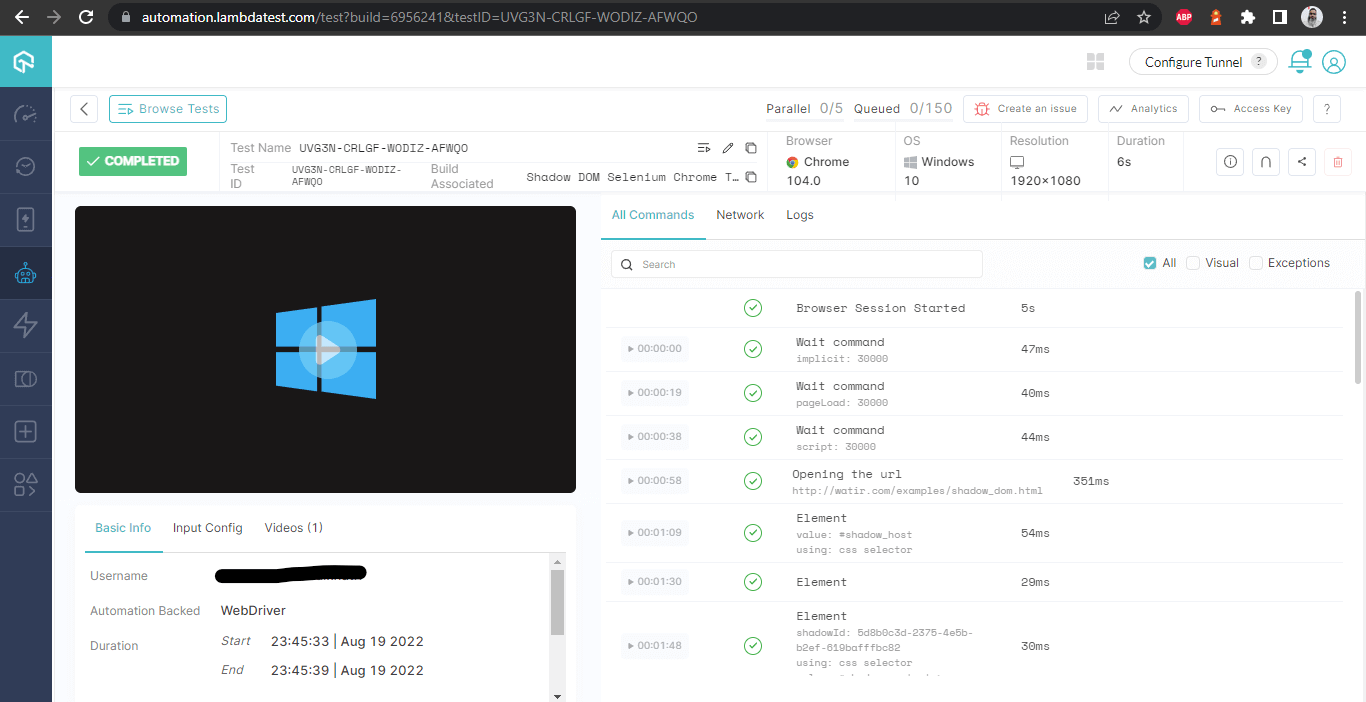 Dettagli Build
Dettagli Build
Questa schermata mostra tutti i metri in dettaglio, che sono molto utili dal punto di vista del tester per verificare quale test è stato eseguito su quale browser e di conseguenza visualizzare i log per automatizzare Shadow DOM in Selenium.
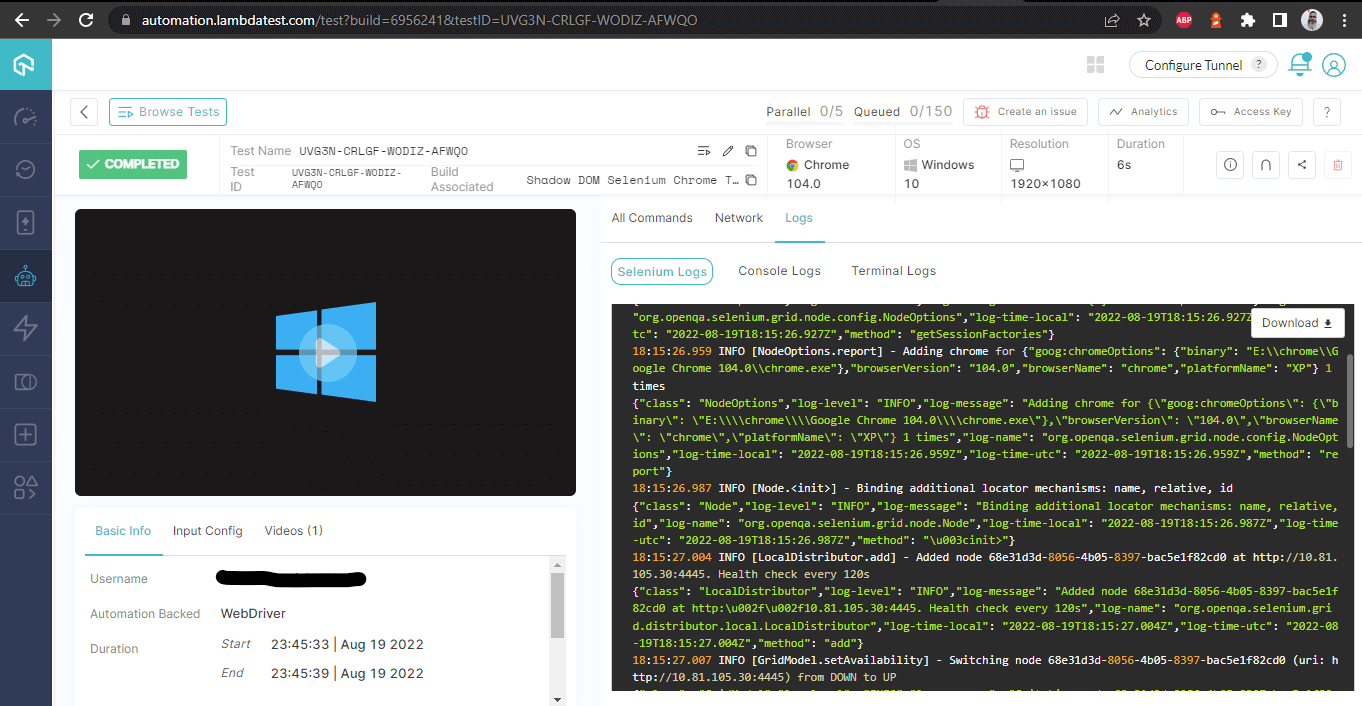 Dettagli della Build – con log
Dettagli della Build – con log
È possibile accedere ai risultati dei test più recenti, al loro stato e al numero complessivo di test superati o falliti nel Dashboard di Analisi di LambdaTest. Inoltre, potete vedere le anteprime delle esecuzioni di test recentemente eseguite nella sezione Panoramica dei Test.
Conclusione
In questo blog sull’automazione del Shadow DOM in Selenium, abbiamo discusso come trovare gli elementi del Shadow DOM e automatizzarli utilizzando il metodo getShadowRoot() introdotto nella versione 4.0.0 e successive di Selenium WebDriver.
Abbiamo anche discusso il posizionamento e l’automazione degli elementi Shadow DOM utilizzando JavaScriptExecutor in Selenium WebDriver e l’esecuzione dei test sul Piattaforma di LambdaTest, che mostra dettagli granulari dei test eseguiti con log di Selenium WebDriver.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
Buon testing!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver