













Questo articolo è un estratto dal mio libro TinyML Cookbook, Seconda Edizione. Potete trovare il codice utilizzato nell’articolo qui.
Preparazione
L’applicazione che progeremo in questo articolo mira a registrare continuamente un clip audio di 1 secondo e eseguire l’inferenza del modello, come illustrato nell’immagine seguente:
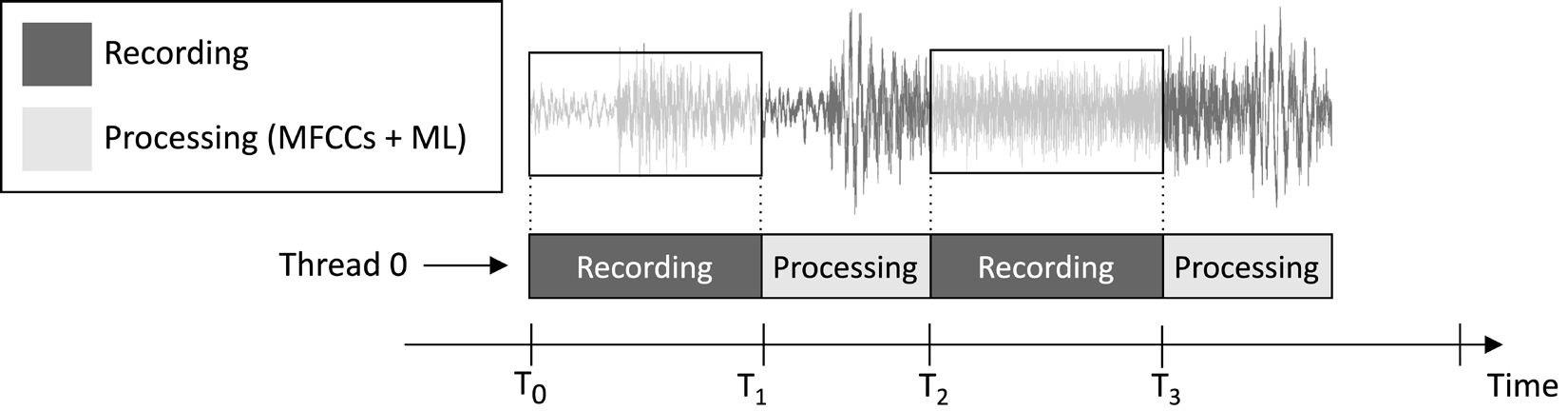
Figura 1: Compiti di registrazione e elaborazione eseguiti in sequenza
Dalla timeline dell’esecuzione delle attività mostrata nell’immagine precedente, si può osservare che l’estrazione delle caratteristiche e l’inferenza del modello vengono sempre eseguite dopo la registrazione audio e non in parallelo. Pertanto, è evidente che non elaboriamo alcuni segmenti del flusso audio live.
A differenza di un’applicazione di individuazione di parole chiave in tempo reale (KWS), che dovrebbe catturare e elaborare tutti i pezzi del flusso audio per non perdere mai alcuna parola parlata, qui, possiamo rilassare questo requisito perché non compromette l’efficacia dell’applicazione.
Come sappiamo, l’input dell’estrazione delle caratteristiche MFCC è l’audio grezzo di 1 secondo in formato Q15. Tuttavia, i campioni acquisiti con il microfono sono rappresentati come valori interi a 16 bit. Quindi, come convertiamo i valori interi a 16 bit in Q15? La soluzione è più semplice di quanto potreste pensare: non è necessario convertire i campioni audio.
Per capire il motivo, considera il formato a punto fisso Q15. Questo formato può rappresentare valori a virgola mobile all’interno dell’intervallo [-1, 1]. La conversione da virgola mobile a Q15 comporta la moltiplicazione dei valori a virgola mobile per 32.768 (2^15). Tuttavia, poiché la rappresentazione a virgola mobile deriva dalla divisione del campione intero a 16 bit per 32.768 (2^15), ciò implica che i valori interi a 16 bit sono intrinsecamente in formato Q15.
Come Fare…
Prendi la breadboard con il microfono collegato al Raspberry Pi Pico. Scollega il cavo dati dal microcontrollore e rimuovi il pulsante e i suoi ponticelli collegati dalla breadboard, poiché non sono necessari per questa ricetta. Figura 2 mostra cosa dovresti avere sulla breadboard:
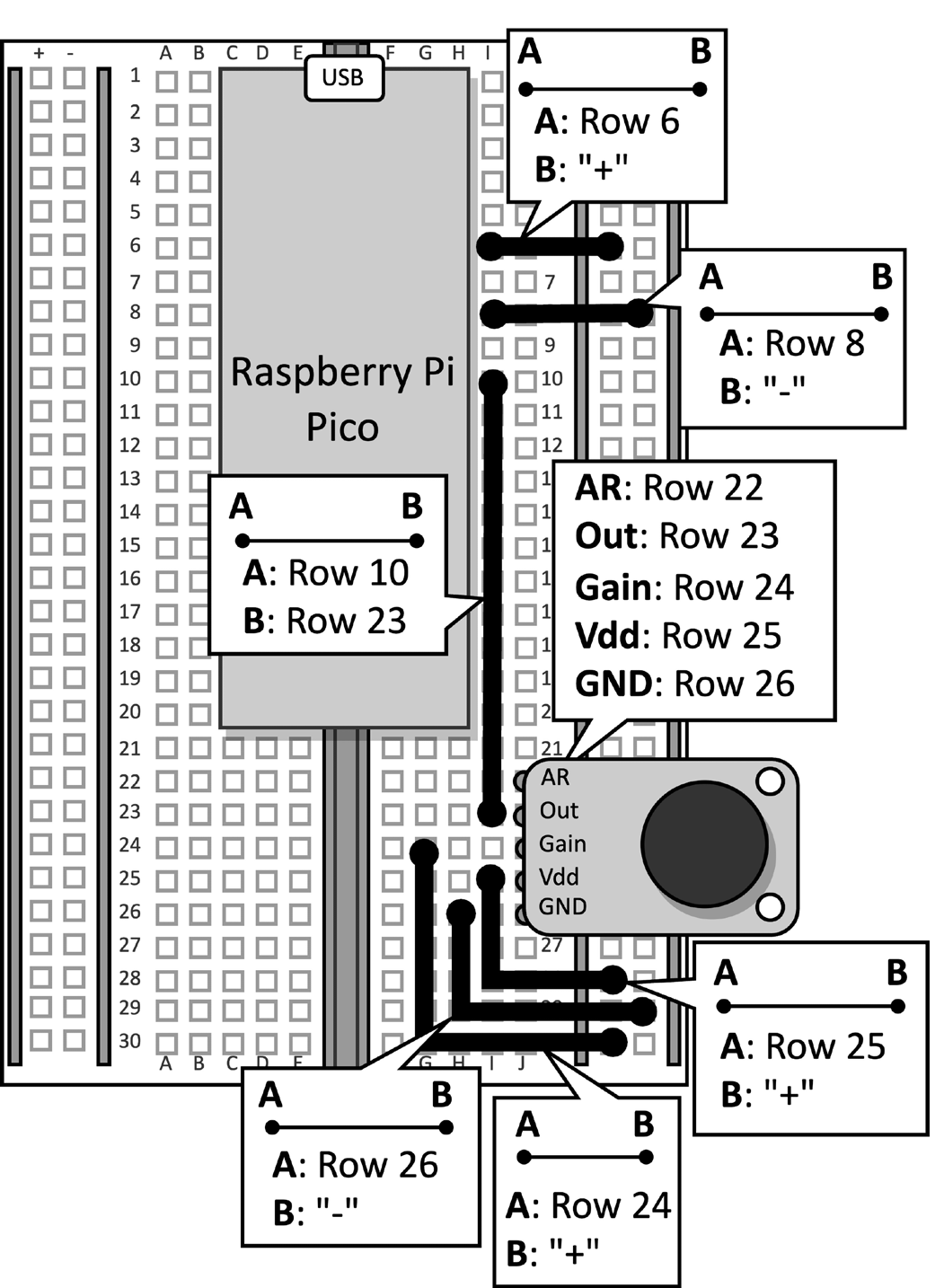
Figura 2: Il circuito elettronico costruito sulla breadboard
Dopo aver rimosso il pulsante dalla breadboard, apri l’IDE di Arduino e crea uno schizzo nuovo.
Ora, segui i seguenti passaggi per sviluppare l’applicazione di riconoscimento del genere musicale sul Raspberry Pi Pico:
Passo 1
Scarica la libreria Arduino TensorFlow Lite dal TinyML-Cookbook_2E repository GitHub repository.
Dopo aver scaricato il file ZIP, importalo nell’IDE Arduino.
Passo 2
Importa tutti i file di intestazione C generati necessari per l’algoritmo di estrazione delle caratteristiche MFCCs nell’IDE Arduino, escludendo test_src.h e test_dst.h.
Passo 3
Copia lo sketch sviluppato in Capitolo 6, Implementazione dell’algoritmo di estrazione delle caratteristiche MFCCs sul Raspberry Pi Pico per implementare l’estrazione delle caratteristiche MFCCs, escludendo le funzioni setup() e loop().
Rimuovi l’inclusione dei file di intestazione test_src.h e test_dst.h. Successivamente, rimuovi l’allocazione dell’array dst, poiché le MFCCs saranno memorizzate direttamente nell’input del modello.
Passo 4
Copia lo sketch sviluppato in Capitolo 5, Riconoscimento dei Generi Musicali con TensorFlow e il Raspberry Pi Pico – Parte 1, per registrare campioni audio con il microfono, escludendo le funzioni setup() e loop().
Una volta importato il codice, rimuovi qualsiasi riferimento all’LED e al pulsante, poiché non sono più necessari. Quindi, modifica la definizione di AUDIO_LENGTH_SEC per registrare audio della durata di 1 secondo:
#define AUDIO_LENGTH_SEC 1Passo 5
Importa il file di intestazione contenente il modello TensorFlow Lite (model.h) nel progetto Arduino.
Una volta importato il file, include il file di intestazione model.h nello sketch:
#include "model.h"
Includi i file di intestazione necessari per tflite-micro:
#include
#include
#include
#include
#include
#include Passo 6
Dichiara le variabili globali per il modello e l’interprete tflite-micro:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
Quindi, dichiara gli oggetti TensorFlow Lite tensor (TfLiteTensor) per accedere ai tensori di input e output del modello:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
Passo 7
Dichiara un buffer (arena tensor) per memorizzare i tensori intermedi utilizzati durante l’esecuzione del modello:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
La dimensione dell’arena tensor è stata determinata attraverso test empirici, poiché la memoria necessaria per i tensori intermedi varia, a seconda di come viene implementato l’operatore LSTM al suo interno. I nostri esperimenti sul Raspberry Pi Pico hanno rilevato che il modello richiede solo 16 KB di RAM per l’inferenza.
Passo 8
Nella funzione setup(), inizializza il periferico seriale con una velocità di 115200 baud:
Serial.begin(115200);
while (!Serial);
Il periferico seriale verrà utilizzato per trasmettere il genere musicale riconosciuto attraverso la comunicazione seriale.
Passo 9
Nella funzione setup(), carica il modello TensorFlow Lite memorizzato nel file di intestazione model.h:
tflu_model = tflite::GetModel(model_tflite);Quindi, registrare tutte le operazioni DNN supportate da tflite-micro e inizializzare l’interprete tflite-micro:
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;Passo 10
Nella funzione setup(), allocare la memoria richiesta per il modello e ottenere il puntatore della memoria dei tensori di input e output:
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
Passo 11
Nella funzione setup(), utilizzare l’SDK Raspberry Pi Pico per inizializzare il periferico ADC:
adc_init();
adc_gpio_init(26);
adc_select_input(0);
Passo 12
Nella funzione loop(), preparare l’input del modello. Per fare ciò, registrare un clip audio di 1 secondo:
// Ripulisci il buffer audio
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();Dopo aver registrato l’audio, estrarre gli MFCC:
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
Come puoi vedere dal frammento di codice precedente, gli MFCC saranno memorizzati direttamente nell’input del modello.
Passo 13
Eseguire l’inferenza del modello e restituire il risultato di classificazione tramite comunicazione seriale:
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);Ora, inserire il cavo dati micro-USB nel Raspberry Pi Pico. Una volta collegato, compilare e caricare lo sketch sul microcontrollore.
Successivamente, aprire il monitor seriale nell’IDE Arduino e posizionare il tuo smartphone vicino al microfono per riprodurre una canzone disco, jazz o metal. L’applicazione dovrebbe ora riconoscere il genere musicale della canzone e visualizzare il risultato di classificazione nel monitor seriale!
Conclusione
In questo articolo, hai imparato come distribuire un modello addestrato per la classificazione di generi musicali sul Raspberry Pi Pico utilizzando tflite-micro.
Source:
https://dzone.com/articles/recognizing-music-genres-with-the-raspberry-pi-pic