













הקדמה
YOLOv8, שפותח על ידי Ultralytics ב-2023, עלתה כאחד מאלגוריתמי הזיהוי של עצמים הייחודיים בסדרת YOLO ומגיעה עם שדרוגים ארכיטקטוניים וביצועיים משמעותיים מעל הדורות הקודמים שלה, כמו YOLOv5. השדרוגים אלה כוללים גב ה-CSPNet לחילוץ יישות טוב יותר, צוואר ה-FPN+PAN לזיהוי עצמים מרחביים משופר והחלפה לגישה ללא עוגנים. שינויים אלה משפרים באופן משמעותי את דיוק המודל, היעילות והשימושיות שלו לזיהוי עצמים בזמן אמת.
שימוש ב-GPU עם YOLOv8 יכול לשפר באופן משמעותי את הביצועים עבור משימות זיהוי עצמים, ולספק אימון והסקת מהירים יותר. מדריך זה ילווה אותך בהגדרת YOLOv8 לשימוש ב-GPU, כולל הגדרה, פתרון תקלות וטיפים לאופטימיזציה.
YOLOv8
YOLOv8 מבסיס על קודמיו עם עיצוב רשת עצבים מתקדם וטכניקות אימון כדי לשפר ביצועים בזיהוי אובייקטים. הוא מאחד את איתור האובייקטים והסיווג במסגרת אפקטיבית אחת, מאזנת בין מהירות ודיוק. הארכיטקטורה כוללת שלושה רכיבים מרכזיים:
- Backbone: שדרוג עיקרי של עצם CNN מאופטימלי ביישום, אולי מבוסס על CSPDarknet, מחלץ תכונות בר מידה באמצעות שכבות יעילות כמו קונבולוציות ניפרדות לעומק, מבטיח ביצועים גבוהים עם הפחתת עומס חישובי מינימלי.
- Neck: Path Aggregation Network (PANet) משופר משפר ומשלב תכונות בר מידה כדי לזהות אובייקטים בגדלים שונים. מאופטימיזציה ליעילות ושימוש בזיכרון.
- Head: הראש שאינו תלוי בעוגן כולל חזיות גבול, ציוני ביטחון ותווי קלאסה, מפשט תחזיות ומשפר התאמה לצורות וגדלים שונים של אובייקטים.
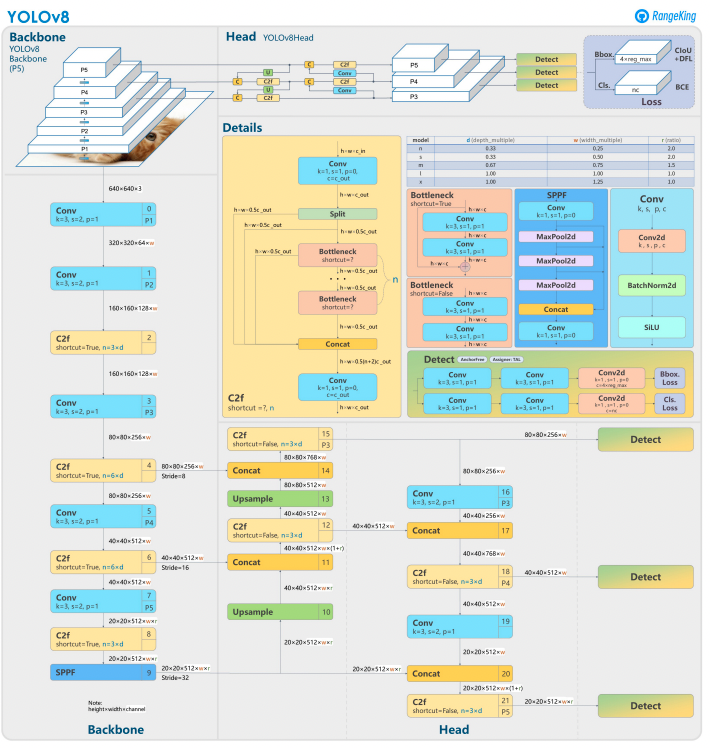
השיפורים הללו הופכים את YOLOv8 למהיר, דיוקני וגמיש למשימות זיהוי אובייקטים מודרניות. בנוסף, YOLOv8 מציג גישה שאינה תלוית עוגן לניבוי תיבות גבול, בזמן שהוא נמקם מגישות המבוססות על עוגן של גרסאות קודמות.
למה להשתמש ב-GPU עם YOLOv8?
YOLOv8 (You Only Look Once, גרסה 8) היא מתון עוצמתי לזיהוי אובייקטים. בעוד שהתוכנה רצה על יחידות מעבד, השימוש ב-GPU מציע מספר יתרונות מרכזיים, כגון:
- מהירות: ה-GPUs מטפלים בחישובים מקביליים בצורה יעילה יותר, מפחיתים את זמני האימון והשערות.
- סקאלביליות: קבוצות נתונים גדולות ומודלים גדולים יכולים להתמודד עם GPUs.
- ביצועים משופרים: הזיהוי בזמן אמת של אובייקטים מתאפשר, מאפשר יישומים כמו רכבים אוטונומיים, שקיפות ועיבוד וידאו חי.

ה-GPUs הם הבחירה הברורה להשגת תוצאות מהירות וטיפול במשימות מורכבות יותר עם YOLOv8.
מעבד vs. GPU
בעבודה עם YOLOv8 או כל מודל זיהוי אובייקטים, הבחירה בין CPU ל-GPU יכולה להשפיע משמעותית על ביצועי המודל הן באימון והן בהסקה. CPUs, כפי שאנו יודעים, טובים למטרות כלליות ויכולים לנהל ביעילות משימות קטנות יותר. עם זאת, CPUs נכשלות כאשר המשימה הופכת ליקרה מבחינה חישובית. משימות כמו זיהוי אובייקטים דורשות מהירות וחישוב מקבילי, ו-GPUs מיועדות להתמודד עם משימות עיבוד מקבילי ברמה גבוהה. לכן, הם אידיאליים להרצת מודלים של למידה עמוקה כמו YOLO. לדוגמה, האימון וההסקה על GPU יכולים להיות 10–50 פעמים מהירים יותר מאשר על CPU, בהתאם לחומרה ולגודל המודל.
| Aspect | CPU | GPU |
|---|---|---|
| זמן הסקה (לכל תמונה) | ~500 ms | ~15 ms |
| מהירות אימון (אפוקים/שעה) | ~2 אפוקים/שעה | ~30 אפוקים/שעה |
| יכולת גודל קבוצה | קטן (2-4 תמונות) | גדול (16-32 תמונות) |
| ביצועים בזמן אמת | לא | כן |
| עיבוד מקבילי | מוגבל | מצוין (אלפי ליבות) |
| יעילות אנרגטית | נמוכה למשימות גדולות | גבוהה לעומסי עבודה מקבילים |
| יעילות עלות | מתאים למשימות קטנות | אידיאלי לכל משימות למידת עמוק |
ההבדל הופך אף יותר מובהק במהלך האימון, שבו כרטיסי ה-GPU מקצרים באופן משמעותי את האפוקים בהשוואה למעבדי ה-CPU. הקידום המהיר הזה מאפשר ל-GPUs לעבד קבוצות נתונים גדולות ולבצע איתור עצמים בזמן אמת בצורה יעילה יותר.
דרישות קדם לשימוש ב-YOLOv8 עם GPU
לפני הגדרת YOLOv8 עבור GPU, וודא שאתה עומד בדרישות הבאות:
1. דרישות חומרה
- כרטיס GPU של NVIDIA: YOLOv8 תלוי ב- CUDA לשיפור ה-GPU, לכן יהיה עליך לצרף כרטיס NVIDIA GPU עם יכולת חישוב CUDA של 6.0 או גבוהה יותר.
- זיכרון: מומלץ לפחות 8GB של זיכרון GPU לקבוצות נתונים בינוניות. לקבוצות נתונים גדולות, 16GB או יותר הם המועדפים.
2. דרישות תוכנה
- פייתון: גרסה 3.8 או מאוחר יותר.
- PyTorch: מותקן עם תמיכה ב-GPU (באמצעות CUDA). מועדף כרטיס מסך NVIDIA.
- ערכי CUDA Toolkit ו-cuDNN: וודא שהם תואמים את גרסת ה-PyTorch שלך.
- YOLOv8: ניתן להתקין ממאגר המידע של Ultralytics.
3. דרישות לנהג
- הורד והתקן את הנהגים האחרונים של NVIDIA מה-אתר של NVIDIA.
- בדוק את זמינות ה-GPU שלך באמצעות
nvidia-smiלאחר התקנת הנהג.
מדריך שלב אחרי שלב להגדרת YOLOv8 עבור GPU
1. התקן את נהגי NVIDIA
כדי להתקין את נהגי NVIDIA:
- זהה את ה-GPU שלך באמצעות הקוד הבא:
- בקר בעמוד ההורדה של נווידיה דרייברים והורד את הדרייבר המתאים.
- עקוף את ההוראות להתקנה עבור מערכת ההפעלה שלך.
- אתחל מחדש את המחשב כדי ליישם את השינויים.
- וודא את ההתקנה על ידי הרצת:
- הפקודה הזו מציגה מידע על GPU ומאשרת פונקציונליות של הדרייבר.
2. התקן את CUDA Toolkit ו-cuDNN
כדי להשתמש ב-YOLOv8, עלינו לבחור בגרסת PyTorch המתאימה, ששוב דורשת גרסת CUDA.
שלבים להתקנת CUDA Toolkit
- הורד את הגרסה המתאימה של CUDA Toolkit מאתר פיתוחי NVIDIA.
- התקן את CUDA Toolkit וקבע משתנים סביבה (לדוגמה,
PATH,LD_LIBRARY_PATH). - וודא את ההתקנה על ידי הרצת:
הבטיחות שיש לך את הגרסה העדכנית ביותר של CUDA יאפשר ל-PyTorch להשתמש ב-GPU ביעילות
שלבים להתקנת cuDNN
- הורד את cuDNN מאתר הפיתוח של NVIDIA.
- חלץ את התוכן והעתק אותו לתיקיות CUDA המתאימות (לדוגמה,
bin,include,lib). - ודא שגרסת ה-cuDNN תואמת את ההתקנה של CUDA שלך.
3. התקן את PyTorch עם תמיכת GPU
כדי להתקין את PyTorch עם תמיכת GPU, בקר בדף ההתחלה של PyTorch ובחר בפקודת התקנה המתאימה. לדוגמה:
4. התקן והרץ את YOLOv8
התקן את YOLOv8 על פי השלבים הבאים:
- התקן את Ultralytics כדי לעבוד עם yolov8 ולייבא את הספריות המתאימות
- דוגמא לסקריפט ב-Python:
- דוגמה לשורת פקודה:
5. אמת את תצורת ה-GPU ב-YOLOv8
השתמש בפקודת הפייתון הבאה כדי לבדוק אם ה-GPU שלך זוהה ו-CUDA מופעל:
6. הכשר או בצע הסקה עם GPU
ציין את המכשיר כ־cuda בפקודות האימון או ההסקה שלך:
דוגמה לשורת פקודה
אמת את המודל המותאם
דוגמה לתסריט של פייתון
למה לבחור ב-Droplets עם GPU של DigitalOcean?
דרופלטים עם GPU של DigitalOcean מיועדים לעיבוד משימות AI ולמידת מכונה בביצועים גבוהים. ה-H100s מספקים ל-Droplets עם GPU אלה מהירות יוצאת דופן ויכולות עיבוד מקבילי, מה שהופך אותם לאידיאליים להכשר והרצת מודלים YOLOv8 ביעילות. בנוסף, הדרופלטים הללו מותקנים מראש עם הגרסה האחרונה של CUDA, מבטיחים שתוכל להתחיל למשוך מהאצת ה-GPU בלי להשקיע זמן בהגדרות ידניות. הסביבה הזו מאפשרת לך להתמקד באופטימיזציה של מודלי YOLOv8 שלך ובהגדלת הפרויקטים שלך בקלות.
פתרות בעיות נפוצות
1. YOLOv8 לא משתמש ב-GPU
- וודא זמינות GPU באמצעות
- בדוק תאימות CUDA ו-PyTorch.
- ודא שאתה מציין
device=0אוdevice='cuda'בפקודות או בסקריפטים. - עדכן את מנהלי ההתקן של NVIDIA והתקן מחדש את CUDA Toolkit אם נדרש.
2. שגיאות CUDA
- ודא שגרסת ערכת הכלים של CUDA מתאימה לדרישות PyTorch.
- וודא התקנת cuDNN על ידי הפעלת סקריפטי אבחון.
- בדוק את משתני הסביבה עבור CUDA (
PATHו־LD_LIBRARY_PATH).
3. ביצועים איטיים
- הפעל אימון בדיוק ערבובי כדי לייעל את שימוש בזיכרון ואת המהירות:
- הפחת גודל קבוצה אם שימוש בזיכרון גבוה מדי.
- ודא שיש לך מערכת מותאמת לביצועי עיבוד מקביל ושיקול דעתך להשתמש בעיבוד קבוצתי בסקריפט הזיה לשפר ביצועים.
שאלות נפוצות
איך להפעיל GPU עבור YOLOv8?
ציין device='cuda' או device=0 (אם משתמשים ב-GPU הראשון) בפקודות או בסקריפטים שלך כאשר טוענים את המודל. זה יאפשר ל-YOLOv8 להשתמש ב-GPU לחישוב מהיר יותר במהלך הסקירה והאימון. ודא שה-GPU שלך מוגדר כראוי וזוהה.
למה YOLOv8 לא משתמש ב-GPU שלי?
YOLOv8 עשוי לא להשתמש ב-GPU אם יש בעיות עם החומרה, הנהגים או ההתקנה.
להתחיל, וודא התקנת CUDA והתאמה עם PyTorch. עדכן את הנהגים אם נדרש. וודא שה-CUDA וה-CuDNN שלך תואמים להתקנת ה-PyTorch שלך.
התקן את torchvision ובדוק את התצורה שמותקנת ומשמשת.
בנוסף, אם PyTorch לא מותקן עם תמיכה ב-GPU (למשל, גרסה ללא CPU), או הפרמטר device בפקודות YOLOv8 שלך עשוי לא להיות מוגדר באופן מפורש ל־cuda. הרצת YOLOv8 על מערכת בלי GPU התואמת ל-CUDA או זיכרון VRAM לא מספיק עשוי לגרום לו לברר באופן ברירת מחדל ל-CPU.
כדי לפתור את הבעיה זו, ודא שה-GPU שלך תואם את CUDA, בדוק את ההתקנה של כל התלויות הנדרשות, בדוק ש־torch.cuda.is_available() מחזיר True, וציין באופן מפורש את הפרמטר device='cuda' בסקריפטים או בפקודות ה־YOLOv8 שלך.
מהם דרישות החומרה עבור YOLOv8 על GPU?
כדי להתקין ולהפעיל ביעילות את YOLOVv8 על GPU, מומלץ Python 3.7 או גרסה גבוהה יותר, ונדרש GPU התואם את CUDA כדי להשתמש בתאוצת GPU.
GPU של NVIDIA מודרני עם לפחות 8GB של זיכרון מומלץ. עבור מערכות נתונים גדולות, זיכרון נוסף הוא מועיל. לביצועים מיטביים, מומלץ להשתמש ב־Python 3.8 או גרסה חדשה יותר, PyTorch 1.10 או גרסה גבוהה יותר, ו-GPU של NVIDIA התואם את CUDA 11.2+. ה-GPU צריך לכל הפחות 8GB של VRAM כדי לעמוד במערכות נתונים בינוניות בצורה יעילה, אף על פי שזיכרון נוסף הוא מועיל עבור מערכות נתונים גדולות ומודלים מורכבים. בנוסף, יש להשקיע לפחות 8GB של RAM ו־50GB של מקום פנוי בדיסק כדי לאחסן מערכות נתונים ולקדם אימוני מודלים. לוודא את הגדרות החומרה והתוכנה אלו יסייע לך להשיג אימון ואינפרנס מהירים יותר עם YOLOv8, במיוחד עבור משימות מחשוביות חישובית.
יש לשים לב: GPU של AMD עשוי שלא לתמוך ב־CUDA, לכן בחירת GPU של NVIDIA לתכנותיות של YOLOv8 היא חיונית.
האם YOLOv8 יכול לרוץ על מספר רב של יחידות עיבוד גרפי (GPU)?
לכדי לאמן את YOLOv8 באמצעות מספר רב של יחידות עיבוד גרפי (GPU), ניתן להשתמש ב־DataParallel של PyTorch או לציין יחידות מרובות ישירות (לדוגמה, cuda:0,1). לאימון מבוזר, YOLOv8 משתמש ב־Multi-GPU DistributedDataParallel (DDP) של PyTorch כברירת מחדל. ודא שיש למערכת שלך מספר רב של יחידות עיבוד גרפי זמינות וציין את היחידות שברצונך להשתמש בהן בסקריפט אימון או בשורת הפקודה. לדוגמה, הגדר --device 0,1,2,3 בשורת הפקודה או device=[0,1,2,3] בפייתון כדי להשתמש ביחידות עיבוד גרפי 0, 1, 2 ו־3. YOLOv8 מטפלת באופן אוטומטי באימון מקבולי על יחידות העיבוד הגרפי המצוינות באופן בלתי פורש בלי לדרוש ארגומנט מסוג data_parallel. בזמן האימון משתמשים בכל יחידות העיבוד הגרפי, אך בדרך כלל שלב האימות רץ על יחידת עיבוד גרפי אחת כברירת מחדל, מאחר שהוא פחות מאמץ משאבים מאשר האימון.
כיצד אני יכול לאופטימז את YOLOv8 עבור הערכת המידע על גרפיקה (GPU)?
אפשר מערכת יישומים מעורבת ולהתאים את גדלי הצטברות כדי לאזן בין זיכרון ומהירות. בהתאם לקבוצת הנתונים שלך, הדרכת YOLOv8 דורשת כמה מחשבות כוח להפעלה יעילה. ניתן להשתמש במודל קטן יותר או בגרסת מידודים (לדוגמה, YOLOv8n או גרסאות מידוד INT8) כדי להפחית את שימוש הזיכרון ואת זמן הניחוש. בתסריט הניחוש שלך, עליך לקבוע באופן ברור את הפרמטר device ל־cuda עבור ביצוע ב-GPU. ניתן להשתמש בטכניקות כמו ניחוש באצווה כדי לעבד תמונות מרובות בו זמנית ולמקסם את שימוש ה-GPU. במידת הצורך, ניתן להשתמש ב־TensorRT כדי לאופטימז את המודל עוד יותר לניחוש מהיר יותר ב-GPU. יש לעקוב באופן קבוע אחר זיכרון ה-GPU וביצועיו כדי לוודא שמשתמשים במשאבים בצורה יעילה.
הקטע הקוד הבא יאפשר לך לעבד תמונות במקביל בתוך גודל הצטברות המוגדר.
במידה ומשתמשים ב-CLI, יש לציין את גודל הצטברות עם -b או –batch-size. ב-Python, יש לוודא שפרמטר הצטברות מוגדר כראוי בעת אתחול המודל שלך או בקריאה לשיטת הניחוש.
כיצד אפשר לפתור בעיות זיכרון CUDA מלאות?
כדי לפתור שגיאות של אין מקום בזיכרון CUDA, עליך להפחית את גודל הצטייד באימות בקובץ התצורה של YOLOv8 שלך, מאחר שצטיידים קטנים דורשים פחות זיכרון ב-GPU. בנוסף, אם יש לך גישה למספר GPUים, שקול לשפר את עיבוד האימות בינתים שלהם באמצעות DistributedDataParallel של PyTorch או פונקציונליות דומה, אם כי זה מחייב ידע מתקדם ב-PyTorch. ניתן גם לנסות לנקות את הזיכרון המטמון באמצעות torch.cuda.empty_cache() בתסריט שלך ולוודא שאין תהליכים לא נחוצים רצים על ה-GPU שלך. שדרוג ל-GPU עם יותר VRAM או אופטימיזציה של המודל והקבוצת נתונים שלך ליעילות בזיכרון הם צעדים נוספים להפחתת בעיות כאלה.
מסקנה
הגדרת YOLOv8 כך שתשתמש ב-GPU היא תהליך פשוט שיכול לשפר באופן משמעותי את הביצועים. על ידי עקיבה אחרי המדריך המפורט הזה, תוכל להאיץ את תהליך האימון וההירמה שלך עבור משימות זיהוי העצמים שלך. אופטימיזציה של ההגדרה שלך, פיתרון בעיות נפוצות, ושחרור הפוטנציאל המלא של YOLOv8 עם האצת GPU.
הפניות
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection