













Las arquitecturas modernas nativas de la nube requieren soluciones de procesamiento de registros robustas, escalables y seguras para monitorear aplicaciones distribuidas. Este estudio presenta una solución híbrida para la recolección, agregación y análisis de registros utilizando Azure Kubernetes Service (AKS) para la generación de registros, Fluent Bit para la recolección de registros, Azure EventHub para la agregación intermedia y Splunk implementado en un clúster de Apache CloudStack local para la indexación y visualización integral de registros.
Detallamos el diseño, la implementación y la evaluación del sistema, demostrando cómo esta arquitectura soporta el procesamiento de registros confiable y escalable para cargas de trabajo nativas de la nube mientras se mantiene el control sobre los datos en las instalaciones.
Introducción
Las soluciones de registro centralizado se han vuelto indispensables. Las aplicaciones modernas, particularmente aquellas construidas sobre arquitecturas de microservicios, generan enormes cantidades de registros, a menudo en formatos diversos y desde múltiples fuentes. Estos registros son la fuente clave para monitorear el rendimiento de la aplicación, diagnosticar problemas y garantizar la fiabilidad general del sistema. Sin embargo, gestionar volúmenes tan altos de datos de registro plantea desafíos significativos, especialmente en entornos de nube híbrida que abarcan tanto infraestructura local como basada en la nube.
Las soluciones de registro tradicionales, aunque efectivas para aplicaciones monolíticas, tienen dificultades para escalar ante las demandas de arquitecturas basadas en microservicios. La naturaleza dinámica de los microservicios, caracterizada por despliegues independientes y actualizaciones frecuentes, produce un flujo continuo de registros, cada uno variando en formato y estructura. Estos registros deben ser ingestados, procesados y analizados en tiempo real para proporcionar información accionable. Además, a medida que las aplicaciones operan cada vez más en entornos híbridos, garantizar la seguridad y los datos de información personal se vuelve primordial, dadas las variadas exigencias de cumplimiento normativo.
Este documento presenta una solución integral que aborda estos desafíos aprovechando las capacidades combinadas de Azure y los recursos de Apache CloudStack. Al integrar la escalabilidad y capacidades analíticas de Azure con la flexibilidad y rentabilidad de la infraestructura local de CloudStack, esta solución ofrece un enfoque unificado y sólido para el registro centralizado.
Revisión de la literatura
La recopilación centralizada de registros en microservicios enfrenta desafíos como la latencia de red, los diversos formatos de datos y la seguridad en múltiples capas. Si bien agentes ligeros como Fluent Bit y FluentD son ampliamente utilizados, el transporte eficiente de registros sigue siendo un desafío.
Soluciones como el stack ELK y Azure Monitor ofrecen procesamiento de registros centralizado, pero típicamente implican implementaciones solo en la nube o solo en las instalaciones, limitando la flexibilidad en los despliegues híbridos. Las soluciones de nube híbrida permiten a las organizaciones aprovechar la escalabilidad de la nube mientras mantienen el control sobre datos sensibles en entornos locales. Los pipelines de procesamiento de registros híbridos, especialmente aquellos que utilizan tecnologías de transmisión de eventos, abordan la necesidad de transporte y agregación de registros escalables.
Arquitectura del Sistema
La arquitectura, ilustrada a continuación, integra Azure EventHub y AKS con Apache CloudStack y Splunk en las instalaciones. Cada componente está optimizado para un procesamiento de registros eficiente y transferencia de datos segura a través de entornos.
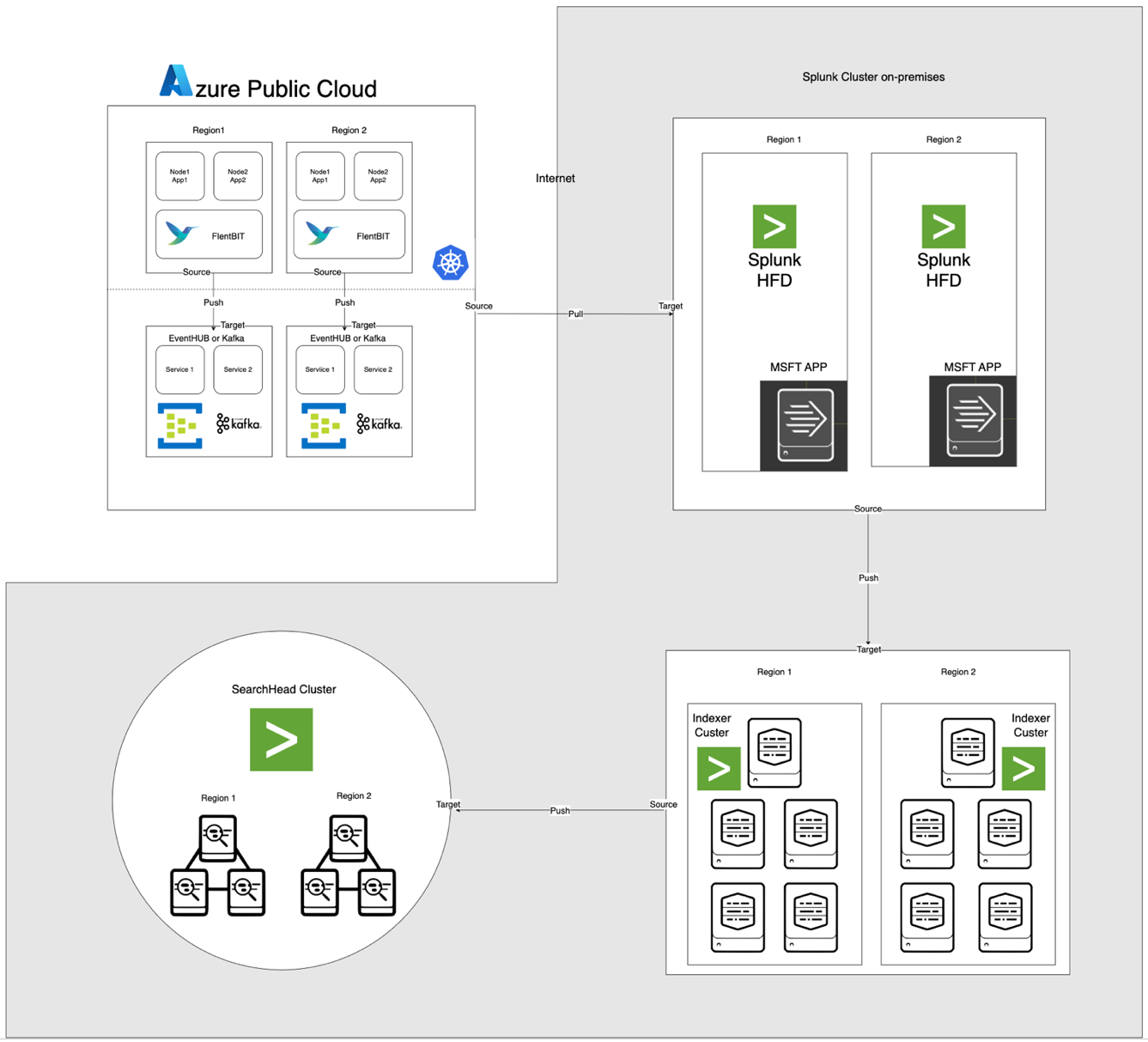
Descripciones de Componentes
- AKS: Aloja aplicaciones en contenedores y genera registros accesibles a través de la capa de agregación de registros de Kubernetes.
- Fluent Bit: Desplegado como un DaemonSet, recopila registros de los nodos de AKS. Cada instancia de Fluent Bit captura registros de /var/log/containers, los filtra y los reenvía en formato JSON a EventHub.
- Azure EventHub: Actúa como un corredor de mensajes de alto rendimiento, agregando registros de Fluent Bit y almacenándolos temporalmente hasta que sean recuperados por el Splunk Heavy Forwarder.
- Apache Kafka: Actúa como un puente confiable entre Fluent Bit y Splunk. Fluent Bit reenvía registros a Kafka utilizando su plugin de salida de Kafka, donde los registros se almacenan y procesan temporalmente. Splunk luego consume los registros de Kafka utilizando conectores como el Kafka Connect Splunk Sink o scripts personalizados, asegurando una arquitectura escalable y desacoplada.
- Splunk Heavy Forwarder (HF): Instalado en Apache CloudStack, el Heavy Forwarder recupera registros de Azure EventHub utilizando el Splunk Add-on for Microsoft Cloud Services. Este complemento proporciona una integración fluida, permitiendo que el Heavy Forwarder se conecte de manera segura a EventHub, recupere registros en casi tiempo real y los transforme según sea necesario antes de reenviarlos al indexador de Splunk para su almacenamiento y procesamiento
- Splunk en Apache CloudStack: Proporciona indexación de registros, búsqueda, visualización y alertas.
Flujo de Datos
- Recolección de registros en AKS: Fluent Bit sigue los archivos de registro en /var/log/containers, filtrando registros innecesarios y etiquetando cada registro con metadatos (por ejemplo, nombre del contenedor, espacio de nombres).
- Reenvío a EventHub: Los registros se envían a EventHub a través de HTTPS utilizando el plugin de salida azure_eventhub de Fluent Bit, asegurando una transmisión de datos segura.
- Apache Kafka: Los registros de AKS son recopilados por Fluent Bit, que se ejecuta como un DaemonSet, el cual los analiza y los envía a Apache Kafka a través de su plugin de salida de Kafka. Kafka actúa como un búfer de alto rendimiento, almacenando y particionando los registros para escalabilidad. Splunk ingiere estos registros desde Kafka utilizando conectores o scripts, permitiendo indexación, análisis y monitoreo en tiempo real.
- Extracción de registros con Splunk Heavy Forwarder: El Forwarder Pesado en Apache CloudStack se conecta a EventHub utilizando el SDK de EventHubs y extrae registros, enviándolos al indexador local de Splunk para almacenamiento y procesamiento.
- Almacenamiento y análisis en Splunk: Los registros son indexados en Splunk, permitiendo búsquedas en tiempo real, visualizaciones de paneles y alertas basadas en patrones de registro.
Metodología
Implementación del DaemonSet de Fluent Bit en AKS
La configuración de Fluent Bit se almacena en un ConfigMap e implementa como un DaemonSet. A continuación se muestra la configuración detallada para el DaemonSet de Fluent Bit:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- Validar el registro entrante
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- Generar una clave única para el reensamblaje basada en el flujo y la etiqueta
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- Manejar fragmentos de registro (logtag == 'P')
if record.logtag == 'P' then
-- Almacenar el fragmento en el estado de reensamblaje
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- Manejar el final de un registro fragmentado
if reassemble_state[reassemble_key] then
-- Combinar fragmentos almacenados con el registro actual
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- Limpiar el estado almacenado para esta clave
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- Si no se necesita reensamblaje, enviar el registro tal cual
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - La sección especifica la recopilación de registros desde el directorio /var/log/containers.
- La sección de filtro enriquece los registros con metadatos de Kubernetes.
- La sección de salida configura Fluent Bit para enviar registros a EventHub en formato JSON.
Configuración de Azure EventHub
EventHub requiere un espacio de nombres, una instancia específica de EventHub y control de acceso a través de políticas de acceso compartido.
- Configuración de espacio de nombres y EventHub: Cree un espacio de nombres e instancia de EventHub en Azure, establezca una política de envío y recupere la cadena de conexión.
- Configuración para alto rendimiento: EventHub se configura con un alto conteo de particiones para soportar escalabilidad, almacenamiento en búfer y flujos de datos concurrentes desde Fluent Bit.
Configuración de Splunk Heavy Forwarder en Apache CloudStack
Splunk Heavy Forwarder recupera registros de EventHub y los envía al indexador de Splunk.
- Complemento para Servicios en la Nube de Microsoft: Instale el complemento para habilitar la conectividad con EventHub. Configure la entrada en
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- Procesamiento por lotes: Establezca el tamaño de lote en 500 e intervalo en 30 segundos para optimizar la ingestión de datos y reducir la frecuencia de llamadas de red.
Indexación y Visualización en Splunk
- Enriquecimiento de datos: Los registros se enriquecen con metadatos adicionales en Splunk mediante extracciones de campos.
- Búsquedas y paneles: Las consultas SPL permiten búsquedas en tiempo real, y los paneles personalizados proporcionan visualización de patrones de registro.
- Alertas: Se configuran alertas para activarse en patrones de registro específicos, como altas tasas de errores o advertencias repetidas de contenedores específicos.
Rendimiento y escalabilidad
Las pruebas muestran que el sistema puede manejar la ingestión de registros a alto rendimiento, con las capacidades de almacenamiento en búfer de EventHub que evitan la pérdida de datos durante interrupciones de red. El uso de recursos de Fluent Bit en nodos de AKS sigue siendo mínimo, y el indexador de Splunk maneja el volumen de registros de manera eficiente con configuraciones adecuadas de indexación y filtrado.
Seguridad
Se utiliza HTTPS para asegurar la comunicación entre AKS y EventHub, mientras que Splunk HF utiliza claves seguras para autenticarse con EventHub. Cada componente en el pipeline implementa mecanismos de reintento para mantener la integridad de los datos.
Utilización de Recursos
- Fluent Bit promedia 100-150 MiB de memoria y 0.2-0.3 CPU en nodos de AKS.
- El uso de recursos de EventHub se ajusta dinámicamente según las configuraciones de partición y rendimiento.
- La carga de Splunk HF se equilibra a través del procesamiento por lotes, optimizando la transferencia de datos sin sobrecargar los recursos de Apache CloudStack.
Confiabilidad y tolerancia a fallos
La solución utiliza el almacenamiento en búfer de EventHub para asegurar la retención de registros en caso de fallos posteriores. EventHub también admite políticas de reintento, mejorando aún más la integridad y confiabilidad de los datos.
Discusión
Ventajas de la Arquitectura de Nube Híbrida
Esta arquitectura proporciona flexibilidad, escalabilidad y seguridad al combinar servicios de Azure con control local. También aprovecha las capacidades de transmisión y almacenamiento en la nube sin comprometer la soberanía de los datos.
Limitaciones
Aunque EventHub ofrece una agregación de datos confiable, los costos aumentan con las unidades de rendimiento, por lo que es esencial optimizar las configuraciones de reenvío de registros. Además, la transferencia de datos entre entornos en la nube y locales introduce posibles latencias.
Aplicaciones Futuras
Esta arquitectura podría ser ampliada integrando aprendizaje automático para la detección de anomalías en registros o añadiendo soporte para múltiples proveedores de nube para escalar aún más el procesamiento de registros y la resiliencia multi-nube.
Conclusión
Este estudio demuestra la efectividad de un pipeline de procesamiento de registros híbrido aprovechando recursos en la nube y locales. Al integrar Azure Kubernetes Service (AKS), Azure EventHub y Splunk en Apache CloudStack, creamos una solución escalable y resiliente para la gestión y análisis centralizados de registros. La arquitectura aborda desafíos clave en el registro distribuido, incluyendo alto rendimiento de datos, seguridad y tolerancia a fallos.
El uso de Fluent Bit como un recolector de registros ligero en AKS garantiza una recopilación eficiente de datos con un mínimo gasto de recursos. Las capacidades de almacenamiento en búfer de Azure EventHub permiten una agregación de registros confiable y almacenamiento temporal, lo que lo hace adecuado para manejar el tráfico variable de registros y mantener la integridad de los datos en caso de problemas de conectividad. El Splunk Heavy Forwarder y la implementación de Splunk en Apache CloudStack permiten a las organizaciones mantener el control sobre el almacenamiento y análisis de registros, al mismo tiempo que se benefician de la escalabilidad y flexibilidad de los recursos en la nube.
Este enfoque ofrece ventajas significativas para las organizaciones que requieren una configuración de nube híbrida, como un mayor control sobre los datos, el cumplimiento de los requisitos de residencia de datos y la flexibilidad para escalar según la demanda. Trabajos futuros pueden explorar la integración del aprendizaje automático para mejorar el análisis de registros, la detección automatizada de anomalías y la expansión a una configuración de múltiples nubes para aumentar la resiliencia y versatilidad. Esta investigación proporciona una arquitectura fundamental adaptable a las necesidades cambiantes de los sistemas modernos y distribuidos en entornos empresariales.
Referencias
Azure Event Hubs y Kafka
Monitoreo y registro híbrido
- Patrones de supervisión de nube híbrida y multi-nube
- Estrategias de supervisión de nube híbrida
Integración de Splunk
- Envío de datos de Azure a Splunk
- Datos de Azure en la plataforma de Splunk
Implementación de AKS
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing