













Moderne cloud-native Architekturen erfordern robuste, skalierbare und sichere Protokollverarbeitungslösungen zur Überwachung verteilter Anwendungen. Diese Studie präsentiert eine hybride Lösung zur Protokollsammlung, -aggregation und -analyse unter Verwendung von Azure Kubernetes Service (AKS) zur Protokollgenerierung, Fluent Bit zur Protokollsammlung, Azure EventHub zur Zwischenaggregation und Splunk, das auf einem lokalen Apache CloudStack-Cluster für umfassendes Protokoll-Indexing und -Visualisierung bereitgestellt wird.
Wir erläutern das Design, die Implementierung und die Evaluierung des Systems und zeigen, wie diese Architektur eine zuverlässige und skalierbare Protokollverarbeitung für cloud-native Arbeitslasten unterstützt, während die Kontrolle über die Daten vor Ort erhalten bleibt.
Einführung
Zentralisierte Protokollierung Lösungen sind unverzichtbar geworden. Moderne Anwendungen, insbesondere solche, die auf Microservices-Architekturen basieren, erzeugen riesige Mengen an Protokollen, oft in unterschiedlichen Formaten und aus mehreren Quellen. Diese Protokolle sind die wichtigste Quelle zur Überwachung der Anwendungsleistung, zur Diagnose von Problemen und zur Sicherstellung der Gesamtzuverlässigkeit des Systems. Die Verwaltung solcher hohen Volumina an Protokolldaten stellt jedoch erhebliche Herausforderungen dar, insbesondere in hybriden Cloud-Umgebungen, die sowohl lokale als auch cloudbasierte Infrastrukturen umfassen.
Traditionelle Protokollierungslösungen, die für monolithische Anwendungen effektiv sind, haben Schwierigkeiten, unter den Anforderungen von architekturen, die auf Mikroservices basieren, zu skalieren. Die dynamische Natur von Mikroservices, gekennzeichnet durch unabhängige Bereitstellungen und häufige Updates, erzeugt einen kontinuierlichen Strom von Protokollen, die jeweils in Format und Struktur variieren. Diese Protokolle müssen in Echtzeit aufgenommen, verarbeitet und analysiert werden, um handlungsrelevante Erkenntnisse zu liefern. Darüber hinaus wird die Sicherheit und der Datenschutz immer wichtiger, da Anwendungen zunehmend in hybriden Umgebungen arbeiten, was angesichts der vielfältigen Compliance- und regulatorischen Anforderungen entscheidend ist.
Dieses Papier stellt eine umfassende Lösung vor, die diese Herausforderungen durch die Nutzung der kombinierten Fähigkeiten der Ressourcen von Azure und Apache CloudStack angeht. Durch die Integration der Skalierbarkeit und Analysefähigkeiten von Azure mit der Flexibilität und Kosteneffizienz der lokal gehosteten Infrastruktur von CloudStack bietet diese Lösung einen robusten, vereinheitlichten Ansatz für die zentrale Protokollierung.
Literaturüberblick
Die zentrale Protokollsammlung in Mikroservices steht vor Herausforderungen wie Netzwerklatenz, verschiedenen Datenformaten und Sicherheit über mehrere Ebenen hinweg. Während leichte Agenten wie Fluent Bit und FluentD weit verbreitet sind, bleibt der effiziente Protokolltransport eine Herausforderung.
Lösungen wie das ELK-Stack und Azure Monitor bieten eine zentrale Protokollverarbeitung, die jedoch in der Regel nur Cloud- oder nur On-Premises-Implementierungen umfasst, was die Flexibilität in Hybridbereitstellungen einschränkt. Hybrid-Cloud-Lösungen ermöglichen es Organisationen, die Skalierbarkeit der Cloud zu nutzen, während sie die Kontrolle über sensible Daten in On-Premises-Umgebungen behalten. Hybrid-Protokollverarbeitungspipelines, insbesondere solche, die Event-Streaming-Technologien verwenden, adressieren den Bedarf an skalierbarem Protokolltransport und Aggregation.
Systemarchitektur
Die unten dargestellte Architektur integriert Azure EventHub und AKS mit On-Premises Apache CloudStack und Splunk. Jede Komponente ist für eine effiziente Protokollverarbeitung und sicheren Datentransfer über Umgebungen optimiert.
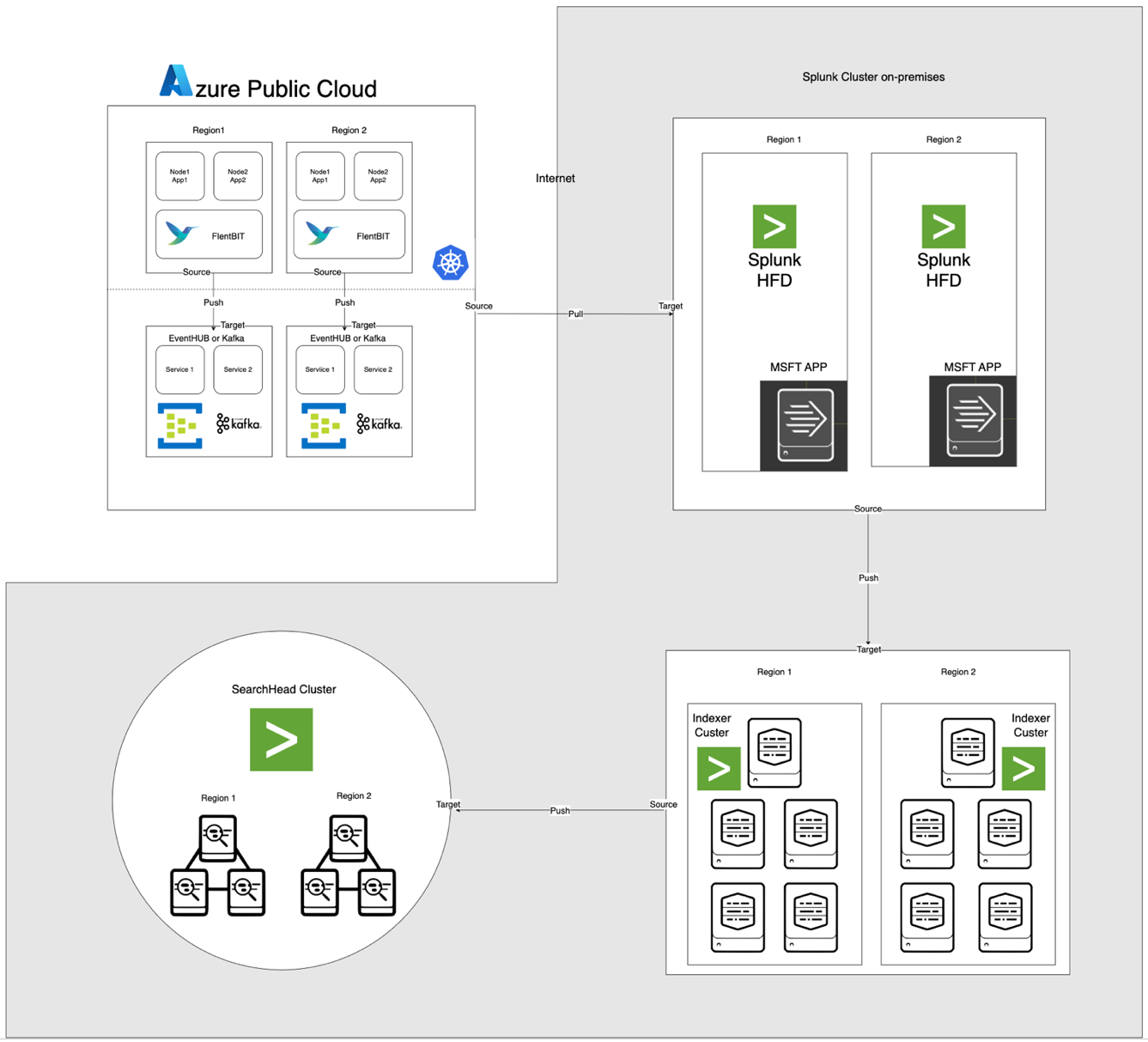
Komponentenbeschreibungen
- AKS: Hostet containerisierte Anwendungen und generiert Protokolle, die über die Protokollaggregationsschicht von Kubernetes zugänglich sind.
- Fluent Bit: Wird als DaemonSet bereitgestellt, sammelt Protokolle von AKS-Nodes. Jede Fluent Bit-Instanz erfasst Protokolle von /var/log/containers, filtert sie und leitet sie im JSON-Format an EventHub weiter.
- Azure EventHub: Dient als Hochdurchsatz-Nachrichtenbroker, der Protokolle von Fluent Bit aggregiert und sie vorübergehend speichert, bis sie vom Splunk Heavy Forwarder abgerufen werden.
- Apache Kafka: Dient als zuverlässige Brücke zwischen Fluent Bit und Splunk. Fluent Bit leitet Protokolle mithilfe seines Kafka-Ausgabe-Plugins an Kafka weiter, wo die Protokolle vorübergehend gespeichert und verarbeitet werden. Splunk greift dann mithilfe von Connectors wie dem Kafka Connect Splunk Sink oder benutzerdefinierten Skripten auf die Protokolle in Kafka zu, was eine skalierbare und entkoppelte Architektur gewährleistet.
- Splunk Heavy Forwarder (HF): Wird in Apache CloudStack installiert, um Protokolle aus Azure EventHub mithilfe des Splunk Add-on for Microsoft Cloud Services abzurufen. Dieses Add-on bietet eine nahtlose Integration, die es dem Heavy Forwarder ermöglicht, sicher mit EventHub zu verbinden, Protokolle nahezu in Echtzeit abzurufen und sie bei Bedarf vor der Weiterleitung an Splunks Indexer für Speicherung und Verarbeitung zu transformieren
- Splunk auf Apache CloudStack: Bietet Protokollindexierung, Suche, Visualisierung und Alarmierung.
Datenfluss
- Protokollsammlung in AKS: Fluent Bit überwacht Protokolldateien in /var/log/containers, filtert unnötige Protokolle heraus und versieht jedes Protokoll mit Metadaten (z. B. Containername, Namensraum).
- Weiterleitung an EventHub: Protokolle werden über HTTPS mithilfe des Fluent Bit-Ausgabe-Plugins azure_eventhub an EventHub gesendet, um eine sichere Datenübertragung zu gewährleisten.
- Apache Kafka: Logs von AKS werden von Fluent Bit gesammelt, das als DaemonSet läuft, analysiert und über sein Kafka-Ausgabemodul an Apache Kafka weiterleitet. Kafka fungiert als Hochdurchsatzpuffer, der Logs zur Skalierbarkeit speichert und partitioniert. Splunk nimmt diese Logs von Kafka mit Connectors oder Skripten auf, ermöglicht Indexierung, Analyse und Echtzeitüberwachung.
- Logs abrufen mit Splunk Heavy Forwarder: Der Heavy Forwarder in Apache CloudStack verbindet sich mit EventHub mithilfe des EventHubs SDK und ruft Logs ab, leitet sie an den lokalen Splunk-Indexer zur Speicherung und Verarbeitung weiter.
- Speicherung und Analyse in Splunk: Logs sind in Splunk indiziert, was Echtzeitsuchen, Dashboard-Visualisierungen und Alarme basierend auf Logmustern ermöglicht.
Methodik
Fluent Bit DaemonSet-Bereitstellung in AKS
Die Konfiguration von Fluent Bit wird in einem ConfigMap gespeichert und als DaemonSet bereitgestellt. Hier ist die erweiterte Konfiguration für das Fluent Bit DaemonSet:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations:
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- Validierung des eingehenden Datensatzes
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- Generierung eines eindeutigen Schlüssels zur Neuordnung basierend auf Stream und Tag
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- Behandlung von Logfragmente (logtag == 'P')
if record.logtag == 'P' then
-- Speichern des Fragments im Neuordnungszustand
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- Behandlung des Endes eines fragmentierten Logs
if reassemble_state[reassemble_key] then
-- Kombinieren gespeicherter Fragmente mit dem aktuellen Log
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- Löschen des gespeicherten Zustands für diesen Schlüssel
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- Wenn keine Neuordnung erforderlich ist, leite das Log wie erhalten weiter
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(? - [EINGABE] Abschnitt spezifiziert die Protokollsammlung aus dem Verzeichnis /var/log/containers.
- [FILTER] Abschnitt enriches Logs mit Kubernetes Metadaten.
- [AUSGABE] Abschnitt konfiguriert Fluent Bit, um Protokolle im JSON-Format an EventHub weiterzuleiten.
Azure EventHub Konfiguration
EventHub erfordert einen Namensraum, eine spezifische EventHub-Instanz und Zugriffssteuerung über Shared-Access-Richtlinien.
- Namensraum und EventHub Einrichtung: Erstellen Sie einen Namensraum und eine EventHub-Instanz in Azure, legen Sie eine Send-Richtlinie fest und rufen Sie die Verbindungszeichenfolge ab.
- Konfiguration für hohe Durchsatzrate: EventHub ist mit einer hohen Partitionszahl konfiguriert, um Skalierbarkeit, Pufferung und gleichzeitige Datenströme von Fluent Bit zu unterstützen.
Splunk Heavy Forwarder Konfiguration in Apache CloudStack
Splunk Heavy Forwarder ruft Protokolle von EventHub ab und leitet sie an den Indexer von Splunk weiter.
- Add-on für Microsoft Cloud Services: Installieren Sie das Add-on, um die EventHub-Konnektivität zu aktivieren. Konfigurieren Sie den Input in
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- Batch-Verarbeitung: Legen Sie batch_size auf 500 und interval auf 30 Sekunden fest, um die Datenübernahme zu optimieren und die Häufigkeit von Netzwerkanfrufen zu reduzieren.
Splunk Indexierung und Visualisierung
- Datenanreicherung: Protokolle werden in Splunk mithilfe von Feldextraktionen mit zusätzlichen Metadaten angereichert.
- Suchen und Dashboards: SPL-Abfragen ermöglichen Echtzeitsuchen, und benutzerdefinierte Dashboards visualisieren Log-Muster.
- Alarmierung: Alarme werden konfiguriert, um bei bestimmten Log-Mustern ausgelöst zu werden, wie z.B. hohe Fehlerquoten oder wiederholte Warnungen aus bestimmten Containern.
Leistung und Skalierbarkeit
Tests zeigen, dass das System eine hohe Durchsatzrate für die Protokollaufnahme bewältigen kann, wobei die Pufferungsfunktionen von EventHub Datenverlust während Netzwerkunterbrechungen verhindern. Der Ressourcenverbrauch von Fluent Bit auf AKS-Nodes bleibt minimal, und der Indexer von Splunk verarbeitet das Log-Volumen effizient mit geeigneten Indexierungs- und Filterkonfigurationen.
Sicherheit
HTTPS wird zur Sicherung der Kommunikation zwischen AKS und EventHub verwendet, während Splunk HF sichere Schlüssel zur Authentifizierung mit EventHub verwendet. Jedes Komponente in der Pipeline implementiert Wiederholungsmechanismen, um die Datenintegrität aufrechtzuerhalten.
Ressourcennutzung
- Fluent Bit benötigt durchschnittlich 100-150 MiB Arbeitsspeicher und 0,2-0,3 CPU auf AKS-Nodes.
- Die Ressourcennutzung von EventHub wird dynamisch anhand von Partition und Durchsatzkonfigurationen angepasst.
- Die Last von Splunk HF wird durch Stapelverarbeitung ausgeglichen, um den Datentransfer zu optimieren, ohne die Ressourcen von Apache CloudStack zu überlasten.
Zuverlässigkeit und Fehlertoleranz
Die Lösung verwendet die Pufferung von EventHub, um die Protokollaufbewahrung im Falle von Ausfällen nachgelagerter Systeme sicherzustellen. EventHub unterstützt zudem Wiederholungsrichtlinien, die die Datenintegrität und Zuverlässigkeit weiter verbessern.
Diskussion
Vorteile der Hybrid-Cloud-Architektur
Diese Architektur bietet Flexibilität, Skalierbarkeit und Sicherheit durch die Kombination von Azure-Diensten mit der Kontrolle vor Ort. Sie nutzt auch cloudbasierte Streaming- und Pufferungsfunktionen, ohne die Datenhoheit zu beeinträchtigen.
Einschränkungen
Obwohl EventHub eine zuverlässige Datensammlung bietet, steigen die Kosten mit den Durchsatz-Einheiten, was es notwendig macht, die Konfigurationen für die Weiterleitung von Protokollen zu optimieren. Darüber hinaus kann die Datenübertragung zwischen Cloud- und lokalen Umgebungen zu potenzieller Latenz führen.
Zukünftige Anwendungen
Diese Architektur könnte durch die Integration von maschinellem Lernen zur Anomalieerkennung in Protokollen erweitert werden oder durch die Unterstützung mehrerer Cloud-Anbieter, um die Protokollverarbeitung und Multi-Cloud-Resilienz weiter zu skalieren.
Fazit
Diese Studie zeigt die Wirksamkeit einer hybriden Protokollverarbeitungspipeline, die Cloud- und lokale Ressourcen nutzt. Durch die Integration von Azure Kubernetes Service (AKS), Azure EventHub und Splunk auf Apache CloudStack schaffen wir eine skalierbare und widerstandsfähige Lösung für zentrales Protokollmanagement und -analyse. Die Architektur adressiert Schlüsselherausforderungen bei der verteilten Protokollierung, einschließlich hoher Daten-Durchsatzraten, Sicherheit und Fehlertoleranz.
Die Verwendung von Fluent Bit als leichtgewichtiger Protokollsammler in AKS gewährleistet eine effiziente Datensammlung mit minimalem Ressourcenoverhead. Die Pufferungsfunktionen von Azure EventHub ermöglichen zuverlässige Protokollaggregation und temporären Speicher, was es gut geeignet macht, um variable Protokoll-Traffic zu handhaben und die Datenintegrität im Falle von Konnektivitätsproblemen aufrechtzuerhalten. Der Splunk Heavy Forwarder und Splunk-Bereitstellung in Apache CloudStack ermöglichen es Organisationen, die Kontrolle über die Protokollspeicherung und -analyse zu behalten und gleichzeitig von der Skalierbarkeit und Flexibilität der Cloud-Ressourcen zu profitieren.
Dieser Ansatz bietet signifikante Vorteile für Organisationen, die eine hybride Cloud-Umgebung benötigen, wie z.B. verbesserte Kontrolle über Daten, Einhaltung von Anforderungen an den Datenstandort und die Flexibilität, sich der Nachfrage entsprechend zu skalieren. Zukünftige Arbeiten können die Integration von maschinellem Lernen zur Verbesserung der Protokollanalyse, automatisierte Anomalieerkennung und die Erweiterung auf eine Multi-Cloud-Umgebung zur Steigerung der Widerstandsfähigkeit und Vielseitigkeit erforschen. Diese Forschung bietet eine fundamentale Architektur, die den sich entwickelnden Anforderungen moderner, verteilter Systeme in Unternehmensumgebungen anpassbar ist.
Referenzen
Azure Event Hubs und Kafka
Hybrides Monitoring und Protokollierung
- Hybride und Multi-Cloud-Überwachungsmuster
- Strategien für die Überwachung von Hybrid Cloud
Splunk-Integration
- Azure Event Hubs in Splunk einbinden
- Azure-Daten in die Splunk-Plattform
AKS-Bereitstellung
Source:
https://dzone.com/articles/bridging-cloud-and-on-premises-log-processing