













Einführung
YOLOv8, entwickelt von Ultralytics im Jahr 2023, hat sich als einer der einzigartigen Objekterkennungsalgorithmen in der YOLO-Serie herausgestellt und bietet signifikante architektonische und Leistungsverbesserungen gegenüber seinen Vorgängern wie YOLOv5. Diese Verbesserungen umfassen ein CSPNet-Backbone für eine bessere Merkmalsextraktion, einen FPN+PAN-Hals für eine verbesserte Multi-Scale-Objekterkennung und einen Wechsel zu einem anchor-freien Ansatz. Diese Änderungen verbessern signifikant die Genauigkeit, Effizienz und Benutzerfreundlichkeit des Modells für die Echtzeit-Objekterkennung.
Die Verwendung einer GPU mit YOLOv8 kann die Leistung bei Objekterkennungsaufgaben erheblich steigern, indem das Training und die Inferenz beschleunigt werden. Dieser Leitfaden führt Sie durch die Einrichtung von YOLOv8 für die GPU-Nutzung, einschließlich Konfiguration, Fehlerbehebung und Optimierungstipps.
YOLOv8
YOLOv8 baut auf seinen Vorgängern auf, indem es fortgeschrittene neuronale Netzwerkdesigns und Trainingstechniken zur Verbesserung der Leistung bei der Objekterkennung verwendet. Es vereint die Objektlokalisierung und Klassifizierung in einem einzigen, effizienten Framework, das Geschwindigkeit und Genauigkeit ausbalanciert. Die Architektur besteht aus drei Schlüsselkomponenten:
- Backbone: Ein hochgradig optimierter CNN-Backbone, möglicherweise basierend auf CSPDarknet, extrahiert mehrskalige Merkmale mithilfe effizienter Schichten wie Tiefen-trennbaren Faltungen und gewährleistet hohe Leistung bei minimalem Rechenaufwand.
- Neck: Ein verbessertes Path Aggregation Network (PANet) verfeinert und integriert mehrskalige Merkmale, um Objekte unterschiedlicher Größen besser zu erkennen. Es ist auf Effizienz und Speichernutzung optimiert.
- Head: Der anchorfreie Head sagt Begrenzungsrahmen, Vertrauenswerte und Klassenbezeichnungen vorher, vereinfacht Vorhersagen und verbessert die Anpassungsfähigkeit an verschiedene Objektformen und -größen.
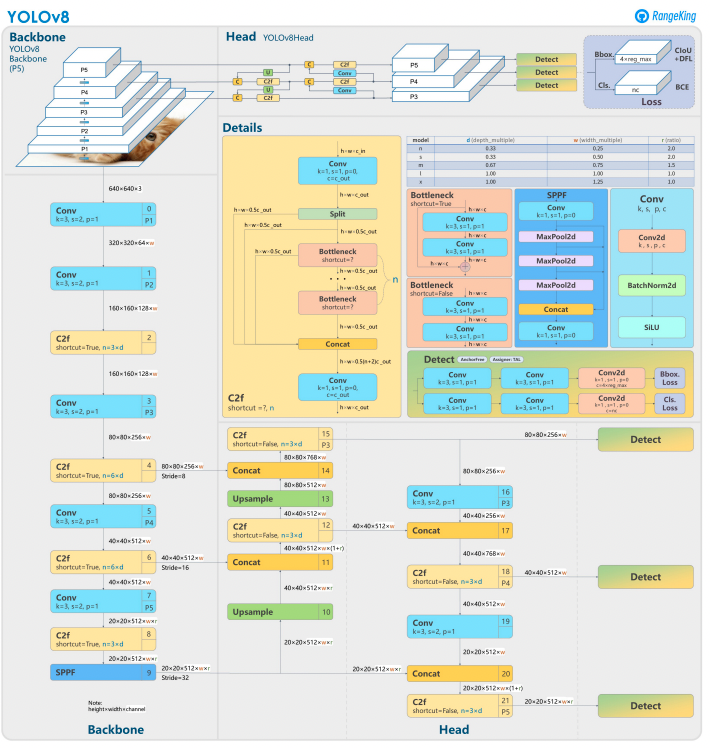
Diese Innovationen machen YOLOv8 schneller, genauer und vielseitiger für moderne Objekterkennungsaufgaben. Darüber hinaus führt YOLOv8 einen anchorfreien Ansatz zur Vorhersage von Begrenzungsrahmen ein und entfernt sich von den ankerbasierten Methoden früherer Versionen.
Warum eine GPU mit YOLOv8 verwenden?
YOLOv8 (You Only Look Once, Version 8) ist ein leistungsstarkes Framework für die Objekterkennung. Obwohl es auf CPUs läuft, bietet die Nutzung einer GPU einige entscheidende Vorteile, wie:
- Geschwindigkeit: GPUs verarbeiten parallele Berechnungen effizienter, wodurch Trainings- und Inferenzzeiten reduziert werden.
- Skalierbarkeit: Größere Datensätze und Modelle sind mit GPUs besser handhabbar.
- Verbesserte Leistung: Echtzeit-Objekterkennung wird möglich, was Anwendungen wie autonome Fahrzeuge, Überwachung und die Verarbeitung von Live-Videos ermöglicht.

GPUs sind die klare Wahl für schnellere Ergebnisse und die Bewältigung komplexerer Aufgaben mit YOLOv8.
CPUs vs. GPUs
Bei der Arbeit mit YOLOv8 oder einem beliebigen Objekterkennungsmodell kann die Auswahl zwischen CPU und GPU die Leistung des Modells sowohl beim Training als auch bei der Inferenz erheblich beeinflussen. CPUs sind bekanntlich großartig für allgemeine Zwecke und können kleinere Aufgaben effizient bewältigen. CPUs versagen jedoch, wenn die Aufgabe rechenintensiv wird. Aufgaben wie die Objekterkennung erfordern Geschwindigkeit und paralleles Computing, und GPUs sind darauf ausgelegt, hochleistungsfähige parallele Verarbeitungsaufgaben zu bewältigen. Daher sind sie ideal für das Ausführen von Deep-Learning-Modellen wie YOLO. Beispielsweise können Training und Inferenz auf einer GPU 10–50 Mal schneller sein als auf einer CPU, abhängig von der Hardware und der Modellgröße.
| Aspect | CPU | GPU |
|---|---|---|
| Inferenzzeit (pro Bild) | ~500 ms | ~15 ms |
| Traininggeschwindigkeit (Epochen/Stunde) | ~2 Epochen/Stunde | ~30 Epochen/Stunde |
| Batch-Größenkapazität | Klein (2-4 Bilder) | Groß (16-32 Bilder) |
| Echtzeit-Performance | Nein | Ja |
| Parallele Verarbeitung | Begrenzt | Hervorragend (Tausende von Kernen) |
| Energieeffizienz | Niedriger für große Aufgaben | Höher für parallele Arbeitslasten |
| Kosteneffizienz | Geeignet für kleine Aufgaben | Ideal für jede Deep-Learning-Aufgabe |
Der Unterschied wird während des Trainings noch deutlicher, wo GPUs im Vergleich zu CPUs die Epochen dramatisch verkürzen. Dieser Geschwindigkeitsvorteil ermöglicht es GPUs, größere Datensätze zu verarbeiten und eine Echtzeitobjekterkennung effizienter durchzuführen.
Voraussetzungen für die Verwendung von YOLOv8 mit GPU
Vor der Konfiguration von YOLOv8 für die GPU stellen Sie sicher, dass Sie die folgenden Anforderungen erfüllen:
1. Hardware-Anforderungen
- NVIDIA GPU: YOLOv8 basiert auf CUDA für die GPU-Beschleunigung, daher benötigen Sie eine NVIDIA GPU mit einer CUDA-Compute-Fähigkeit von 6.0 oder höher.
- Speicher: Mindestens 8GB GPU-Speicher werden für moderate Datensätze empfohlen. Für größere Datensätze sind 16GB oder mehr bevorzugt.
2. Software-Anforderungen
- Python: Version 3.8 oder höher.
- PyTorch: Installiert mit GPU-Unterstützung (über CUDA). Bevorzugt NVIDIA GPU.
- CUDA Toolkit und cuDNN: Stellen Sie sicher, dass diese mit Ihrer PyTorch-Version kompatibel sind.
- YOLOv8: Installierbar aus dem Ultralytics-Repository.
3. Treiberanforderungen
- Laden Sie die neuesten NVIDIA-Treiber von der NVIDIA-Website herunter und installieren Sie sie.
- Überprüfen Sie nach der Treiberinstallation die Verfügbarkeit Ihrer GPU mit
nvidia-smi.
Schritt-für-Schritt-Anleitung zur Konfiguration von YOLOv8 für GPU
1. NVIDIA-Treiber installieren
Um NVIDIA-Treiber zu installieren:
- Identifizieren Sie Ihre GPU mit dem folgenden Code:
- Besuchen Sie die NVIDIA Treiber-Downloadseite und laden Sie den entsprechenden Treiber herunter.
- Folgen Sie den Installationsanweisungen für Ihr Betriebssystem.
- Starten Sie Ihren Computer neu, um die Änderungen anzuwenden.
- Überprüfen Sie die Installation, indem Sie Folgendes ausführen:
- Dieser Befehl zeigt Informationen zur GPU an und bestätigt die Funktionalität des Treibers.
2. Installieren Sie das CUDA Toolkit und cuDNN
Um YOLOv8 zu verwenden, müssen wir die geeignete PyTorch-Version auswählen, die wiederum eine CUDA-Version erfordert.
Schritte zur Installation des CUDA Toolkits
- Laden Sie die entsprechende Version des CUDA Toolkits von der NVIDIA Entwicklerseite herunter.
- Installieren Sie das CUDA Toolkit und setzen Sie die Umgebungsvariablen (z.B.
PATH,LD_LIBRARY_PATH). - Überprüfen Sie die Installation, indem Sie Folgendes ausführen:
Die Sicherstellung, dass Sie die neueste Version von CUDA haben, ermöglicht es PyTorch, die GPU effektiv zu nutzen
Schritte zur Installation von cuDNN
- Laden Sie cuDNN von der NVIDIA Developer-Website herunter.
- Extrahieren Sie die Inhalte und kopieren Sie sie in die entsprechenden CUDA-Verzeichnisse (z. B.
bin,include,lib). - Stellen Sie sicher, dass die cuDNN-Version mit Ihrer CUDA-Installation übereinstimmt.
3. Installieren Sie PyTorch mit GPU-Unterstützung
Um PyTorch mit GPU-Unterstützung zu installieren, besuchen Sie die PyTorch-Get-Started-Seite und wählen Sie den entsprechenden Installationsbefehl aus. Zum Beispiel:
4. Installieren und Ausführen von YOLOv8
Installieren Sie YOLOv8, indem Sie diese Schritte befolgen:
- Installieren Sie Ultralytics, um mit YOLOv8 zu arbeiten, und importieren Sie die erforderlichen Bibliotheken
- Beispiel für Python-Skript:
- Beispiel für die Befehlszeile:
5. Überprüfen der GPU-Konfiguration in YOLOv8
Verwenden Sie den folgenden Python-Befehl, um zu überprüfen, ob Ihre GPU erkannt wird und CUDA aktiviert ist:
6. Trainieren oder Inferenz mit GPU
Geben Sie das Gerät in Ihren Trainings- oder Inferenzbefehlen als cuda an:
Befehlszeilenbeispiel
Validieren des benutzerdefinierten Modells
Python-Skriptbeispiel
Warum DigitalOcean GPU-Droplets?
Die DigitalOcean GPU-Droplets sind für die Bewältigung von leistungsstarken KI- und maschinellen Lernaufgaben konzipiert. Die H100s in diesen GPU-Droplets sorgen für außergewöhnliche Geschwindigkeit und parallele Verarbeitungsfähigkeiten, die sie ideal für das effiziente Training und die Ausführung von YOLOv8-Modellen machen. Darüber hinaus sind diese Droplets mit der neuesten Version von CUDA vorinstalliert, um sicherzustellen, dass Sie die GPU-Beschleunigung sofort nutzen können, ohne Zeit für manuelle Konfigurationen aufwenden zu müssen. Diese optimierte Umgebung ermöglicht es Ihnen, sich vollständig auf die Optimierung Ihrer YOLOv8-Modelle und das mühelose Skalieren Ihrer Projekte zu konzentrieren.
Beheben von häufigen Problemen
1. YOLOv8 verwendet die GPU nicht
- Überprüfen Sie die GPU-Verfügbarkeit mit
- Überprüfen Sie die CUDA- und PyTorch-Kompatibilität.
- Stellen Sie sicher, dass Sie
device=0oderdevice='cuda'in Befehlen oder Skripten angeben. - Aktualisieren Sie die NVIDIA-Treiber und installieren Sie das CUDA Toolkit neu, falls erforderlich.
2. CUDA-Fehler
- Stellen Sie sicher, dass die CUDA Toolkit-Version den Anforderungen von PyTorch entspricht.
- Überprüfen Sie die cuDNN-Installation, indem Sie Diagnoseskripte ausführen.
- Überprüfen Sie die Umgebungsvariablen für CUDA (
PATHundLD_LIBRARY_PATH).
3. Langsame Leistung
- Aktivieren Sie das Training mit gemischter Präzision, um Speichernutzung und Geschwindigkeit zu optimieren:
- Reduzieren Sie die Batch-Größe, wenn der Speicherverbrauch zu hoch ist.
- Stellen Sie sicher, dass Sie ein optimiertes System für die parallele Verarbeitung haben, und erwägen Sie die Verwendung von Batch-Verarbeitung in Ihrem Detektionsskript, um die Leistung zu verbessern.
FAQs
Wie aktiviere ich die GPU für YOLOv8?
Geben Sie device='cuda' oder device=0 (falls die erste GPU verwendet wird) in Ihren Befehlen oder Skripten an, wenn Sie das Modell laden. Dadurch kann YOLOv8 die GPU zur schnelleren Berechnung während der Inferenz und des Trainings nutzen. Stellen Sie sicher, dass Ihre GPU ordnungsgemäß eingerichtet und erkannt ist.
Warum verwendet YOLOv8 nicht meine GPU?
YOLOv8 verwendet möglicherweise die GPU nicht, wenn es Probleme mit der Hardware, den Treibern oder der Einrichtung gibt.
Überprüfen Sie zunächst die CUDA-Installation und die Kompatibilität mit PyTorch. Aktualisieren Sie bei Bedarf die Treiber. Stellen Sie sicher, dass Ihre CUDA und CuDNN mit Ihrer PyTorch-Installation kompatibel sind.
Installieren Sie torchvision und überprüfen Sie die Konfiguration, die installiert und verwendet wird.
Zusätzlich kann es sein, dass PyTorch nicht mit GPU-Unterstützung installiert ist (z. B. eine reine CPU-Version), oder der device-Parameter in Ihren YOLOv8-Befehlen nicht explizit auf cuda gesetzt ist. Das Ausführen von YOLOv8 auf einem System ohne eine CUDA-kompatible GPU oder mit unzureichendem VRAM kann dazu führen, dass es standardmäßig auf die CPU zurückgreift.
Um dies zu lösen, stellen Sie sicher, dass Ihre GPU CUDA-kompatibel ist, überprüfen Sie die Installation aller erforderlichen Abhängigkeiten, stellen Sie sicher, dass torch.cuda.is_available() True zurückgibt, und geben Sie explizit den Parameter device='cuda' in Ihren YOLOv8-Skripten oder -Befehlen an.
Was sind die Hardwareanforderungen für YOLOv8 auf GPU?
Um YOLOv8 effektiv auf einer GPU zu installieren und auszuführen, wird Python 3.7 oder höher empfohlen, und eine CUDA-kompatible GPU ist erforderlich, um die GPU-Beschleunigung zu nutzen.
Eine moderne NVIDIA-GPU mit mindestens 8 GB Speicher wird empfohlen. Bei großen Datensätzen ist mehr Speicher vorteilhaft. Für optimale Leistung wird empfohlen, Python 3.8 oder neuer, PyTorch 1.10 oder höher und eine NVIDIA-GPU, die mit CUDA 11.2+ kompatibel ist, zu verwenden. Die GPU sollte idealerweise mindestens 8 GB VRAM haben, um moderate Datensätze effizient zu verarbeiten, obwohl mehr VRAM für größere Datensätze und komplexe Modelle vorteilhaft ist. Darüber hinaus sollte Ihr System mindestens 8 GB RAM und 50 GB freien Speicherplatz haben, um Datensätze zu speichern und das Modelltraining zu erleichtern. Die Sicherstellung dieser Hardware- und Softwarekonfigurationen wird Ihnen helfen, schnellere Trainings- und Inferenzzeiten mit YOLOv8 zu erreichen, insbesondere bei rechenintensiven Aufgaben.
Bitte beachten Sie: AMD-GPUs unterstützen möglicherweise kein CUDA, daher ist die Auswahl einer NVIDIA-GPU für die Kompatibilität mit YOLOv8 entscheidend.
Kann YOLOv8 auf mehreren GPUs ausgeführt werden?
Um YOLOv8 mit mehreren GPUs zu trainieren, können Sie PyTorchs DataParallel verwenden oder mehrere Geräte direkt angeben (z. B. cuda:0,1). Für das verteilte Training verwendet YOLOv8 standardmäßig PyTorchs Multi-GPU DistributedDataParallel (DDP). Stellen Sie sicher, dass Ihr System über mehrere verfügbare GPUs verfügt und geben Sie die GPUs, die Sie im Training verwenden möchten, im Skript oder in der Befehlszeile an. Legen Sie beispielsweise --device 0,1,2,3 in der Befehlszeile fest oder device=[0,1,2,3] in Python, um die GPUs 0, 1, 2 und 3 zu nutzen. YOLOv8 behandelt automatisch das parallele Training über die angegebenen GPUs, ohne dass ein explizites data_parallel-Argument erforderlich ist. Während alle GPUs während des Trainings genutzt werden, läuft die Validierungsphase standardmäßig auf einer einzelnen GPU, da sie weniger ressourcenintensiv ist als das Training.
Wie optimiere ich YOLOv8 für die Inferenz auf der GPU?
Aktivieren Sie gemischte Präzision und passen Sie die Batch-Größen an, um Speicher und Geschwindigkeit auszugleichen. Je nach Ihrem Datensatz erfordert das Training von YOLOv8 ziemlich viel Rechenleistung, um effizient ausgeführt zu werden. Verwenden Sie eine kleinere oder quantisierte Modellvariante (z. B. YOLOv8n oder INT8-quantisierte Versionen), um den Speicherverbrauch und die Inferenzzeit zu reduzieren. Legen Sie in Ihrem Inferenzskript den device-Parameter explizit auf cuda für die GPU-Ausführung fest. Verwenden Sie Techniken wie Batch-Inferenz, um mehrere Bilder gleichzeitig zu verarbeiten und die GPU-Auslastung zu maximieren. Nutzen Sie bei Bedarf TensorRT, um das Modell weiter zu optimieren und die GPU-Inferenz zu beschleunigen. Überwachen Sie regelmäßig den GPU-Speicher und die Leistung, um eine effiziente Ressourcennutzung sicherzustellen.
Der folgende Code-Schnipsel ermöglicht es Ihnen, Bilder parallel innerhalb der definierten Batch-Größe zu verarbeiten.
Wenn Sie die CLI verwenden, geben Sie die Batch-Größe mit -b oder –batch-size an. Mit Python stellen Sie sicher, dass das Batch-Argument korrekt festgelegt ist, wenn Sie Ihr Modell initialisieren oder die Vorhersagemethode aufrufen.
Wie löse ich CUDA Out-of-memory Probleme?
Um CUDA-Speicherfehler zu beheben, reduzieren Sie die Validierungsbatchgröße in Ihrer YOLOv8-Konfigurationsdatei, da kleinere Batches weniger GPU-Speicher benötigen. Wenn Sie Zugriff auf mehrere GPUs haben, erwägen Sie die Verteilung der Validierungsarbeit auf sie mithilfe von PyTorch’s DistributedDataParallel oder ähnlicher Funktionalität, obwohl dies fortgeschrittene Kenntnisse von PyTorch erfordert. Sie können auch versuchen, den zwischengespeicherten Speicher mit torch.cuda.empty_cache() in Ihrem Skript zu löschen und sicherstellen, dass keine unnötigen Prozesse auf Ihrer GPU laufen. Das Aufrüsten auf eine GPU mit mehr VRAM oder das Optimieren Ihres Modells und Datensatzes für eine effiziente Speichernutzung sind weitere Schritte, um solche Probleme zu mildern.
Fazit
Die Konfiguration von YOLOv8 zur Nutzung einer GPU ist ein unkomplizierter Prozess, der die Leistung erheblich steigern kann. Durch Befolgen dieses detaillierten Leitfadens können Sie das Training und die Inferenz für Ihre Objekterkennungsaufgaben beschleunigen. Optimieren Sie Ihr Setup, beheben Sie häufige Probleme und schöpfen Sie das volle Potenzial von YOLOv8 mit GPU-Beschleunigung aus.
Referenzen
Source:
https://www.digitalocean.com/community/tutorials/yolov8-for-gpu-accelerate-object-detection