













Einrichten der AWS CLI und AWS S3
Bevor Sie sich mit dem Befehl aws s3 cp befassen, müssen Sie AWS CLI auf Ihrem System installiert und ordnungsgemäß konfiguriert haben. Machen Sie sich keine Sorgen, wenn Sie noch nie mit AWS gearbeitet haben – der Einrichtungsprozess ist einfach und sollte weniger als 10 Minuten dauern.
Ich werde dies in drei einfache Phasen aufteilen: Installation des AWS CLI-Tools, Konfigurieren Ihrer Anmeldeinformationen und Erstellen Ihres ersten S3-Buckets für die Speicherung.
Installation der AWS CLI
Der Installationsprozess unterscheidet sich je nach verwendetem Betriebssystem leicht.
Für Windows-Systeme:
- Gehe zur offiziellen AWS CLI Dokumentationsseite
- Lade den 64-Bit Windows Installer
- Herunter und starte die heruntergeladene Datei, um dem Installationsassistenten zu folgen
Für Linux-Systeme:
Führe die folgenden drei Befehle im Terminal aus:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
Für macOS-Systeme:
Angenommen, du hast Homebrew installiert, führe diese Zeile im Terminal aus:
brew install awscli
Wenn du Homebrew nicht hast, verwende stattdessen diese beiden Befehle:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /
Zur Bestätigung einer erfolgreichen Installation führe aws --version in deinem Terminal aus. Du solltest etwas ähnliches wie dies sehen:
Bild 1 – AWS CLI Version
Konfigurieren der AWS CLI
Mit der CLI installiert, ist es Zeit, deine AWS-Anmeldeinformationen für die Authentifizierung einzurichten.
Zugriff auf dein AWS-Konto und navigiere zum Dashboard des IAM-Dienstes. Erstelle einen neuen Benutzer mit programmatischem Zugriff und hänge die entsprechende S3-Berechtigungsrichtlinie an:
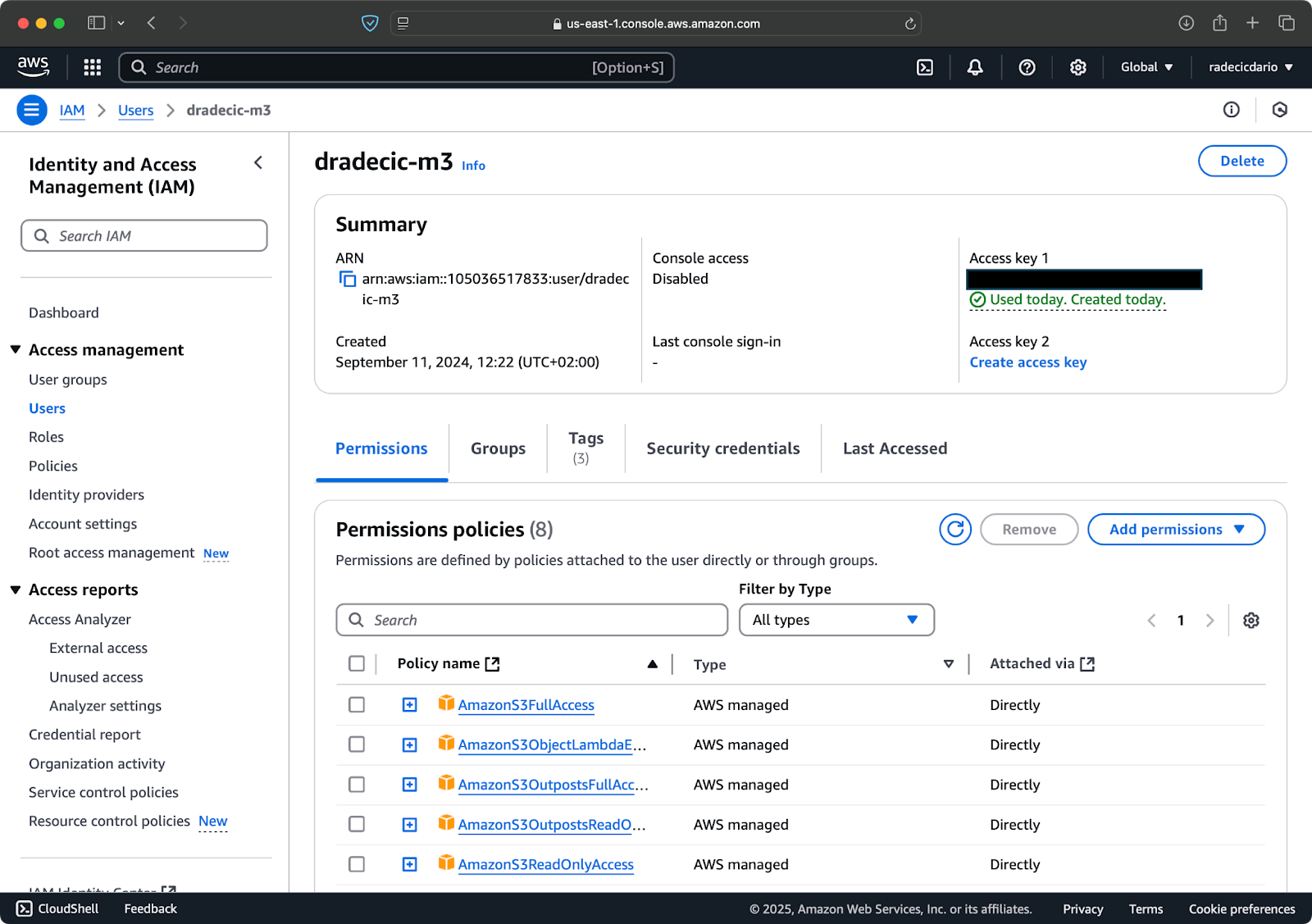
Bild 2 – AWS IAM Benutzer
Besuche als Nächstes den Tab „Sicherheitsanmeldeinformationen“ und generiere ein neues Zugriffsschlüsselpaar. Stelle sicher, dass du sowohl die Zugriffschlüssel-ID als auch den geheimen Zugriffsschlüssel an einem sicheren Ort speicherst – Amazon wird dir den geheimen Schlüssel nach diesem Bildschirm nicht mehr anzeigen:
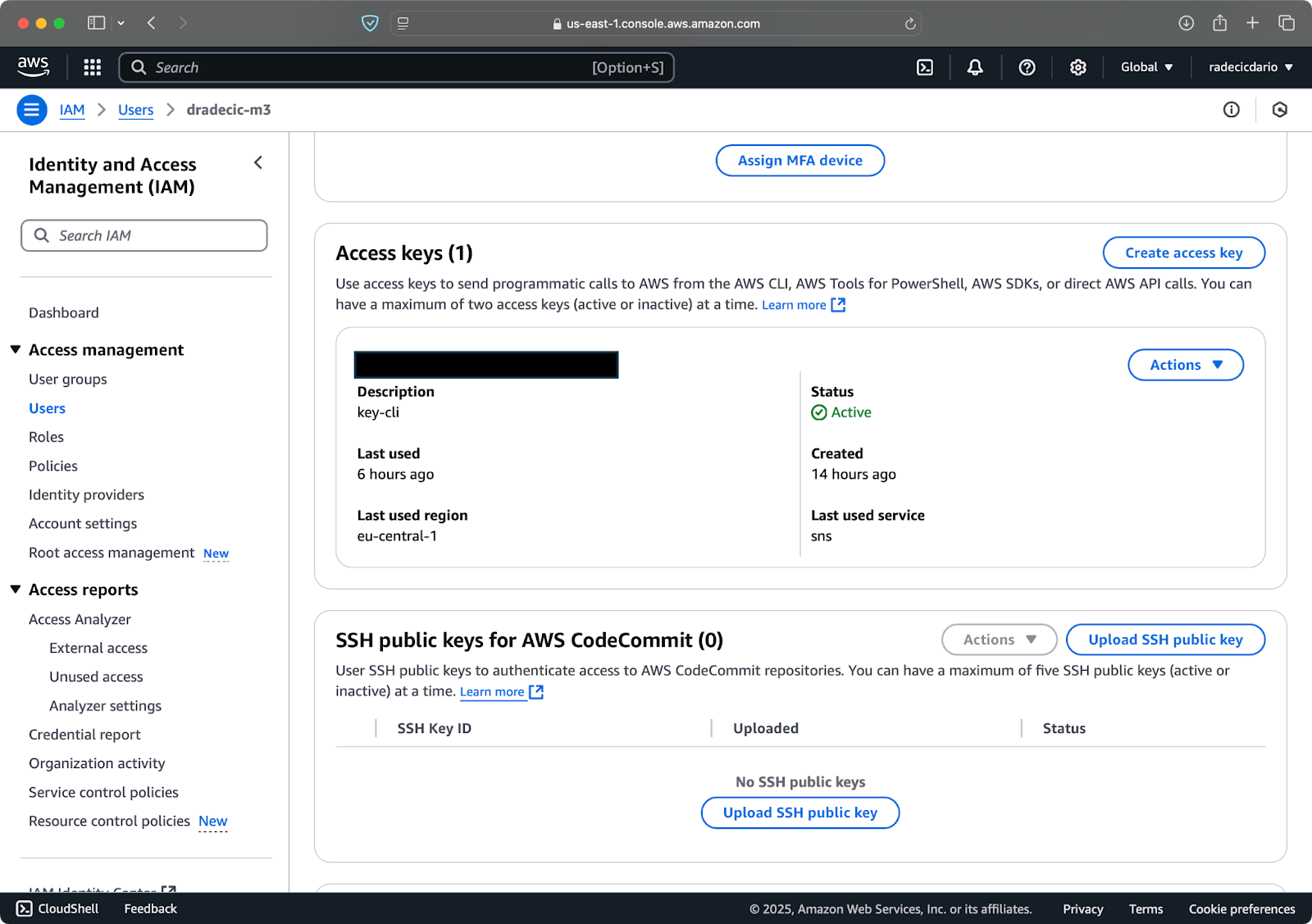
Bild 3 – AWS IAM Benutzeranmeldeinformationen
Öffnen Sie jetzt Ihr Terminal und führen Sie den Befehl aws configure aus. Sie werden nach vier Informationen gefragt: Ihre Zugriffsschlüssel-ID, geheimer Zugriffsschlüssel, Standardregion (ich verwende eu-central-1) und bevorzugtes Ausgabeformat (typischerweise json):
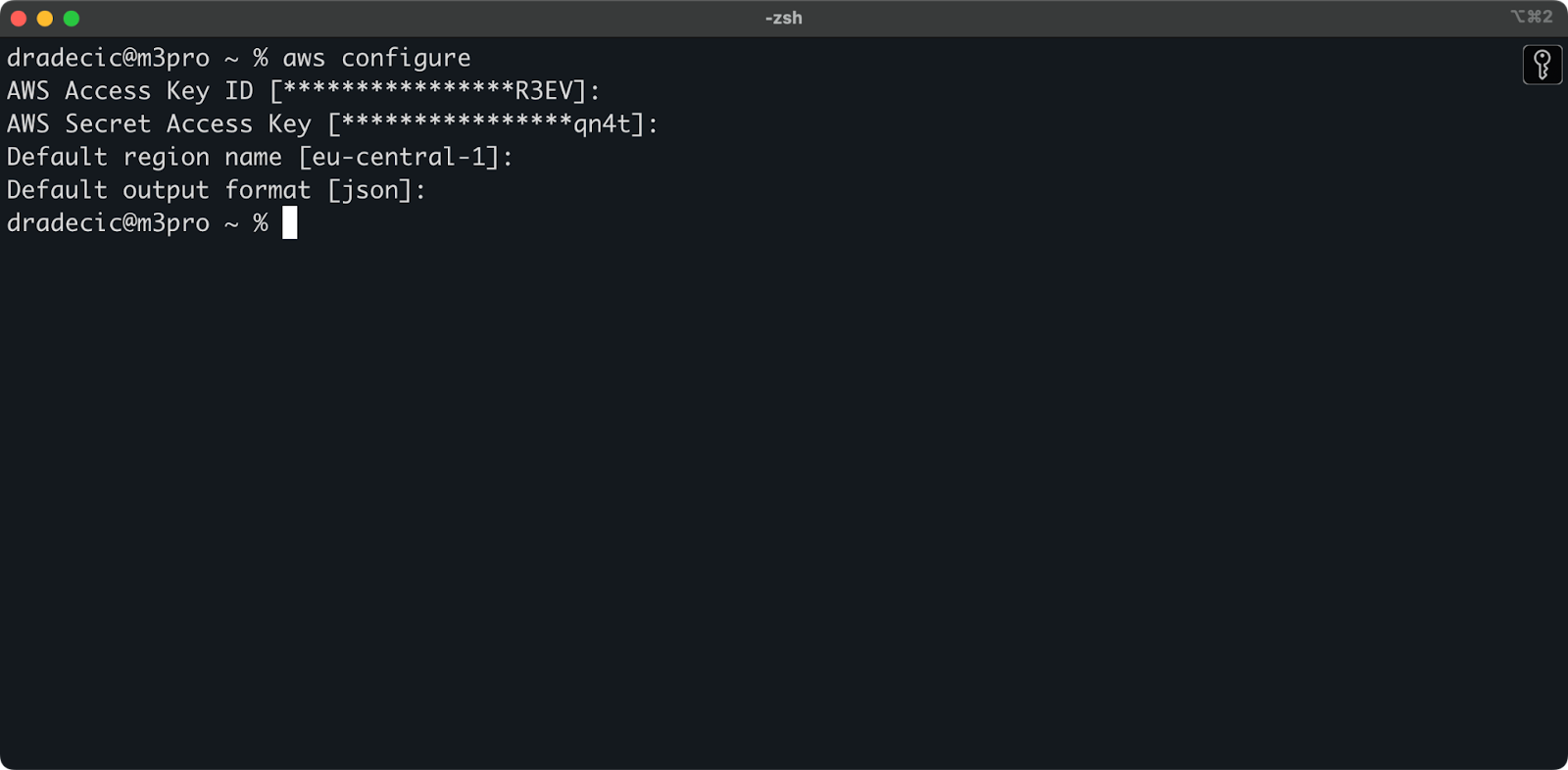
Bild 4 – AWS CLI-Konfiguration
Um sicherzustellen, dass alles ordnungsgemäß verbunden ist, überprüfen Sie Ihre Identität mit folgendem Befehl:
aws sts get-caller-identity
Wenn alles korrekt konfiguriert ist, sehen Sie Ihre Kontodetails:
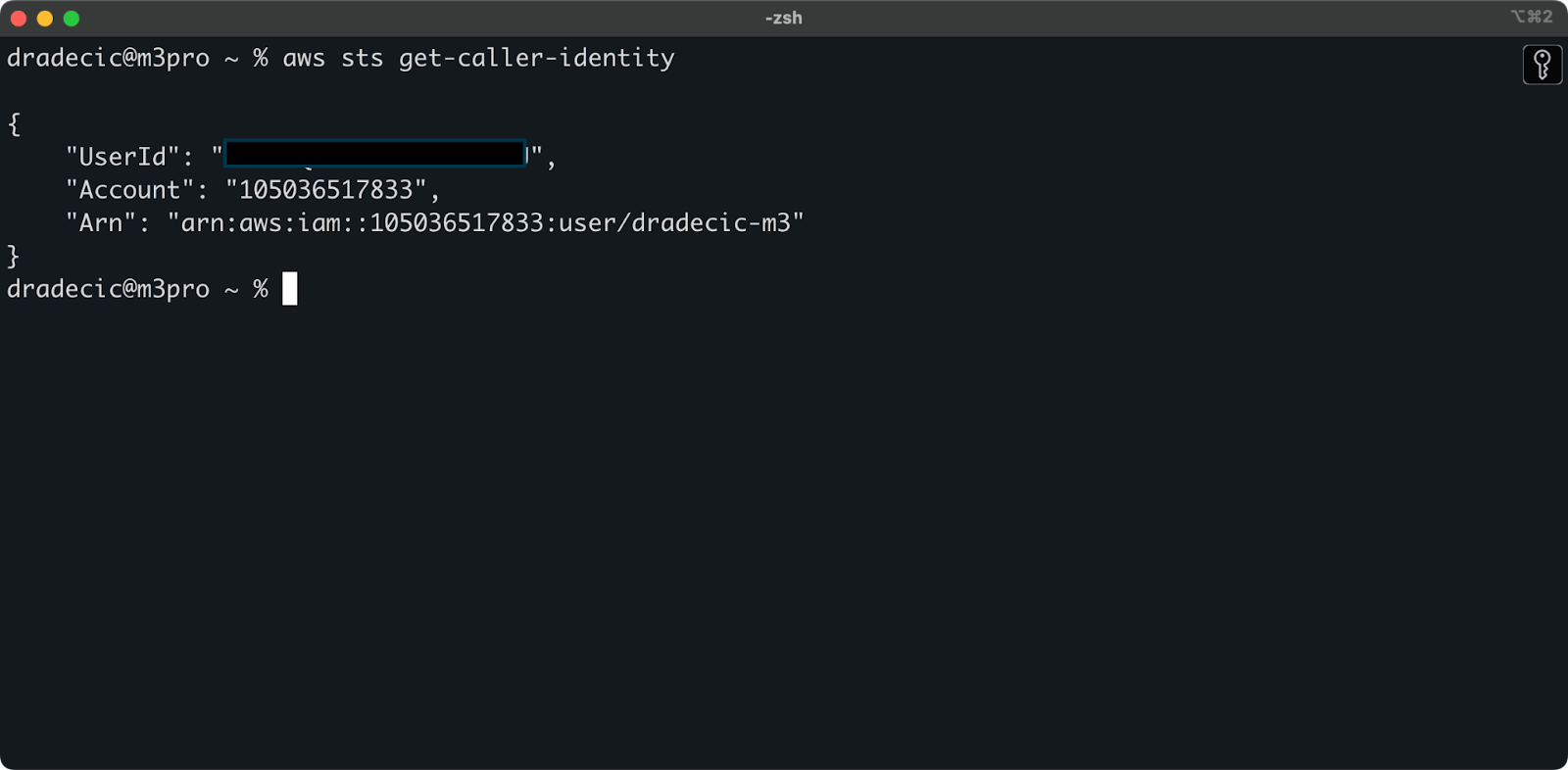
Bild 5 – AWS CLI Testverbindungsbefehl
Erstellen eines S3-Buckets
Sie müssen schließlich einen S3-Bucket erstellen, um die Dateien zu speichern, die Sie kopieren werden.
Wechseln Sie zum S3-Dienstbereich in Ihrer AWS-Konsole und klicken Sie auf „Bucket erstellen“. Denken Sie daran, dass Bucket-Namen global eindeutig über alle AWS sein müssen. Wählen Sie einen eindeutigen Namen, lassen Sie die Standardeinstellungen vorerst unverändert und klicken Sie auf „Erstellen“:
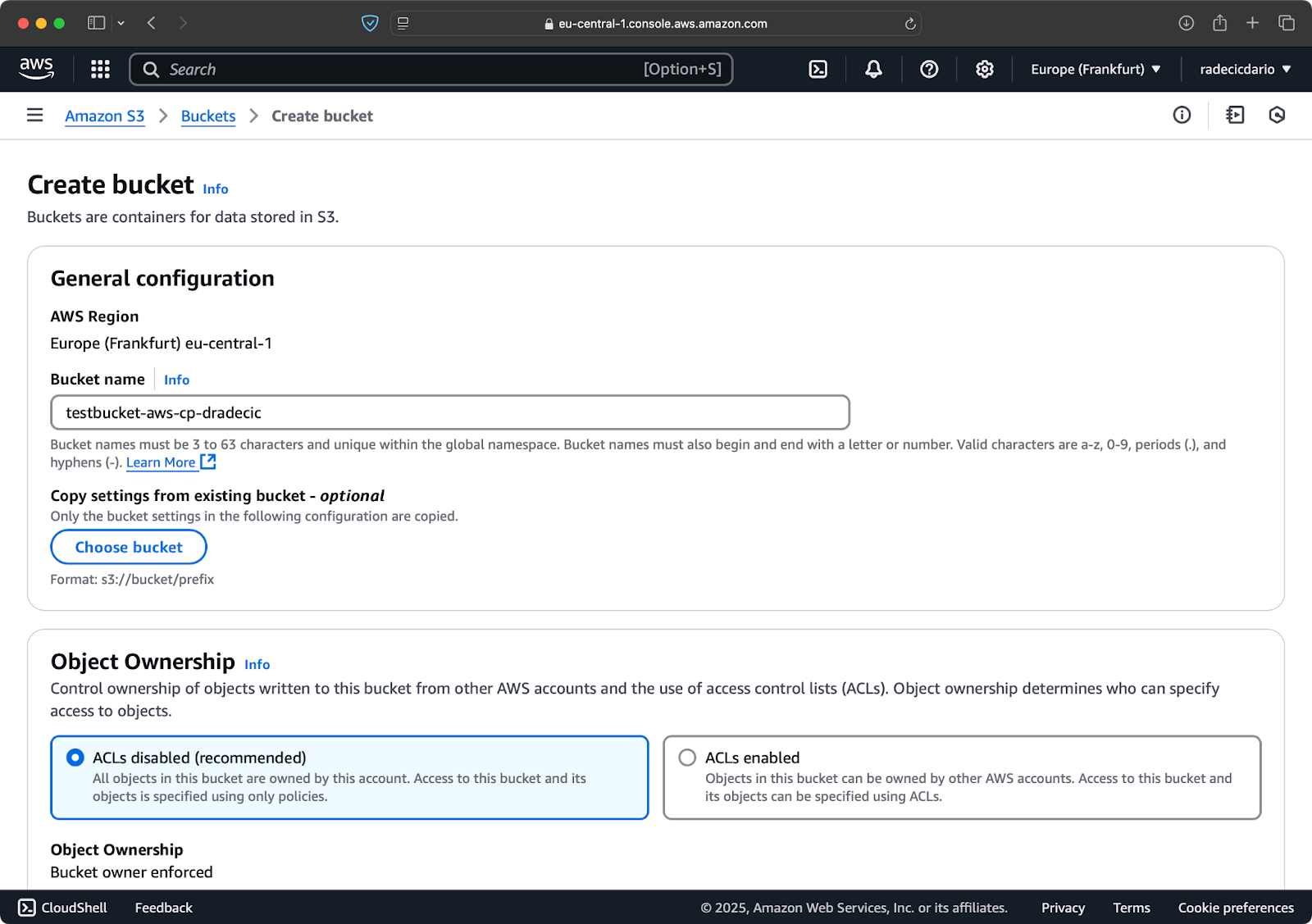
Bild 6 – AWS Bucket-Erstellung
Nach der Erstellung wird Ihr neuer Bucket in der Konsole angezeigt. Sie können auch dessen Existenz über die Befehlszeile bestätigen:
aws s3 ls
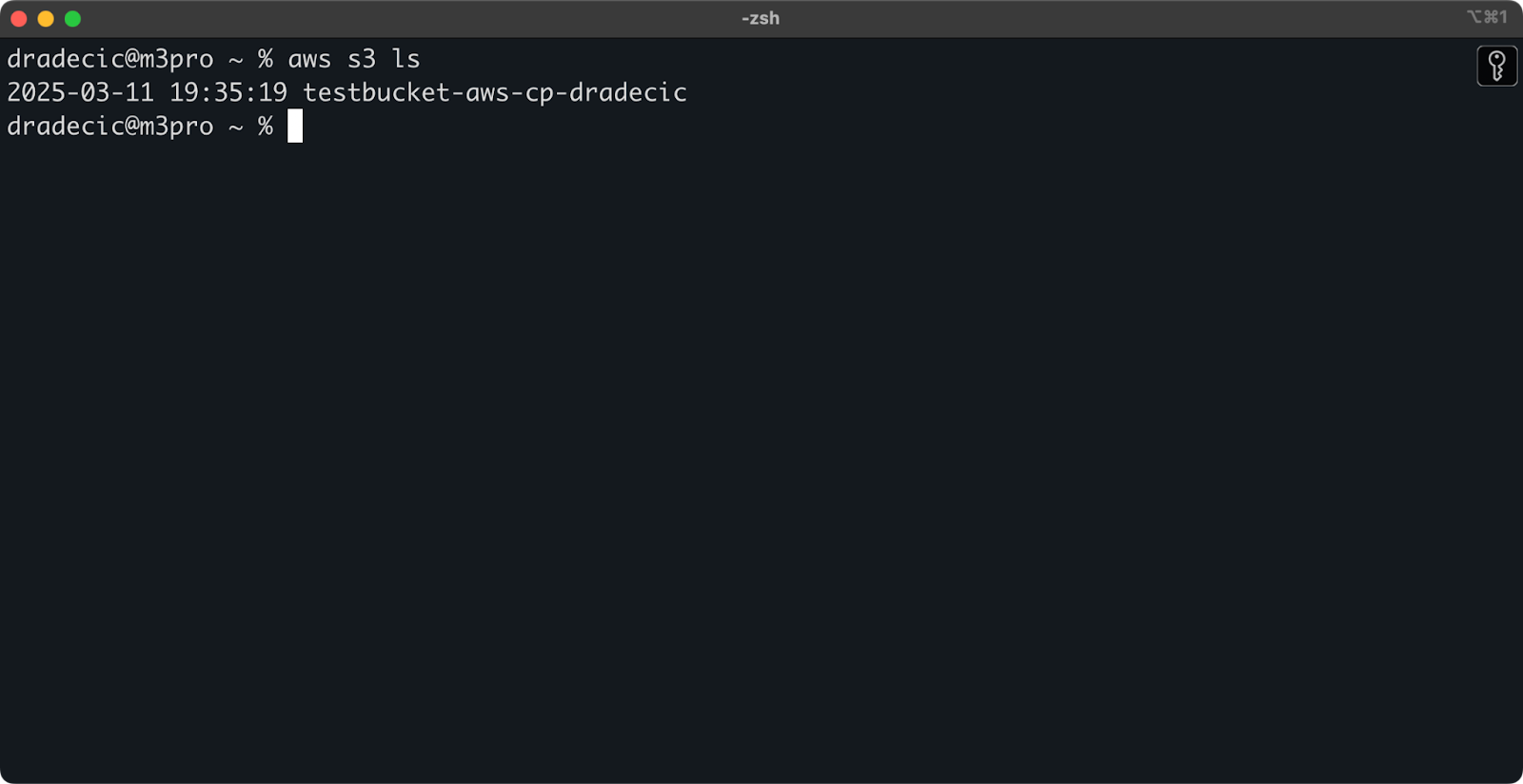
Bild 7 – Alle verfügbaren S3-Buckets
Alle S3-Buckets sind standardmäßig als privat konfiguriert, also denken Sie daran. Wenn Sie diesen Bucket für öffentlich zugängliche Dateien verwenden möchten, müssen Sie die Bucket-Richtlinien entsprechend anpassen.
Sie sind jetzt vollständig ausgestattet, um mit dem Befehl aws s3 cp Dateien zu übertragen. Lassen Sie uns als nächstes mit den Grundlagen beginnen.
Grundlegende AWS S3 cp-Befehlssyntax
Nun, da alles konfiguriert ist, lassen Sie uns in die grundlegende Verwendung des Befehls aws s3 cp eintauchen. Wie gewohnt bei AWS liegt die Schönheit in der Einfachheit, obwohl der Befehl verschiedene Szenarien für Dateiübertragungen handhaben kann.
In seiner einfachsten Form folgt der Befehl aws s3 cp dieser Syntax:
aws s3 cp <source> <destination> [options]
Wo <source> und <destination> lokale Dateipfade oder S3-URIs (die mit s3:// beginnen) sein können. Lassen Sie uns die drei häufigsten Anwendungsfälle erkunden.
Kopieren einer Datei von lokal nach S3
Um eine Datei von Ihrem lokalen System in einen S3-Bucket zu kopieren, ist die Quelle ein lokaler Pfad und das Ziel ein S3-URI:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txt
Dieser Befehl lädt die Datei test_file.txt aus dem angegebenen Verzeichnis in den angegebenen S3-Bucket hoch. Wenn die Operation erfolgreich ist, sehen Sie eine Konsolenausgabe wie diese:
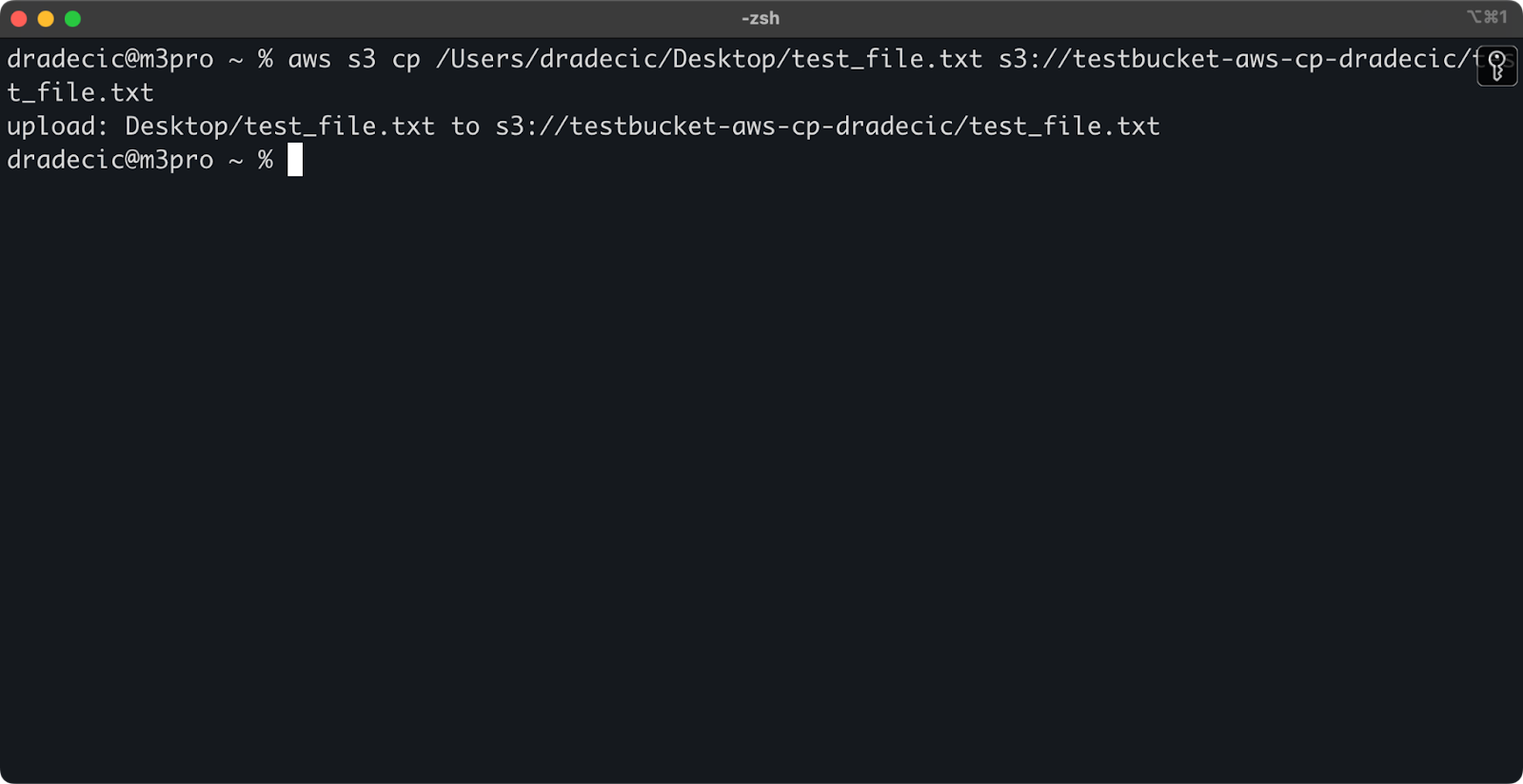
Bild 8 – Konsolenausgabe nach dem Kopieren der lokalen Datei
Und auf der AWS-Managementkonsole sehen Sie Ihre hochgeladene Datei:
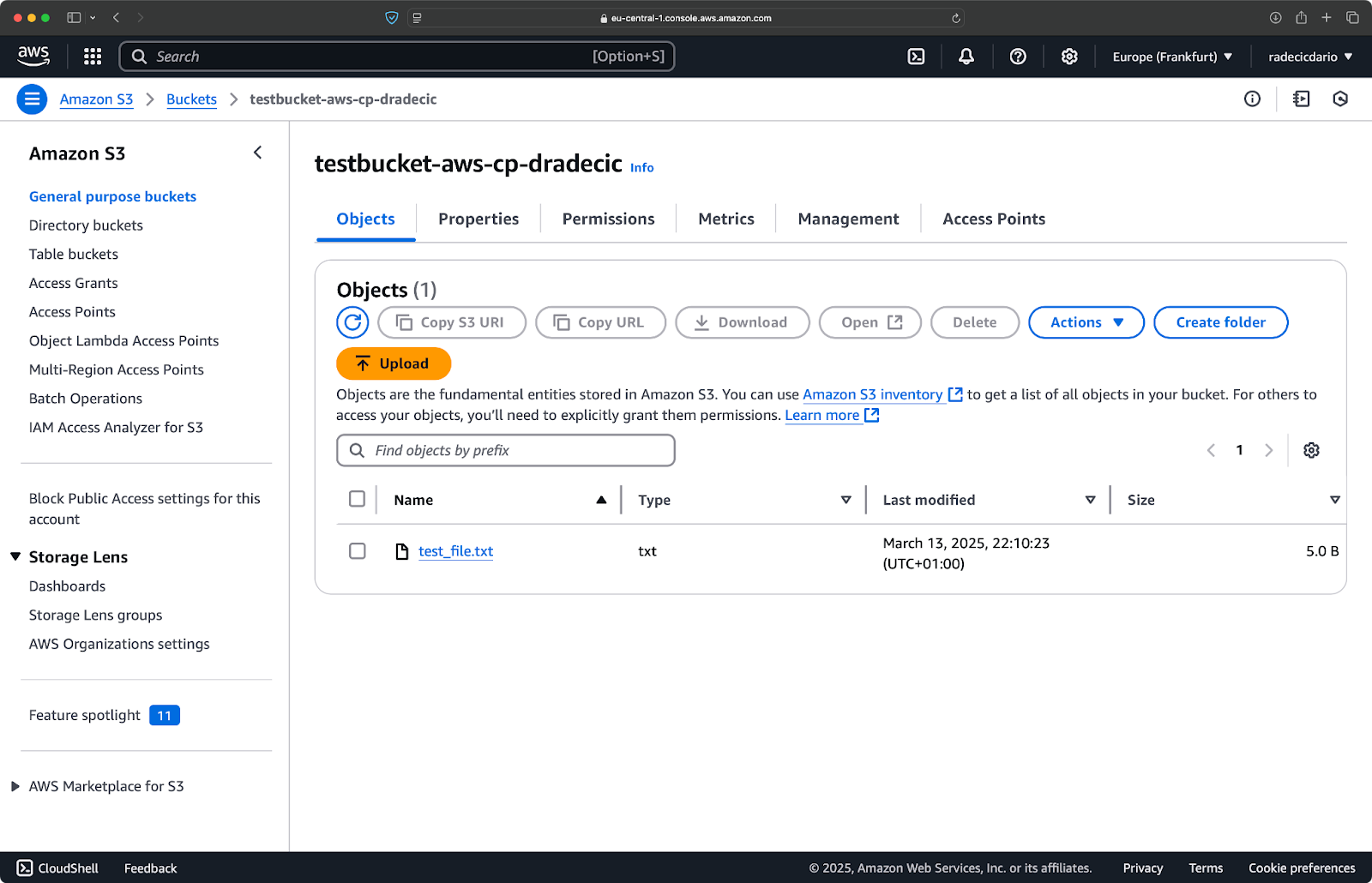
Bild 9 – Inhalte des S3-Buckets
Ebenso, wenn Sie einen lokalen Ordner in Ihren S3-Bucket kopieren und ihn beispielsweise in einem anderen verschachtelten Ordner platzieren möchten, führen Sie einen ähnlichen Befehl wie diesen aus:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive
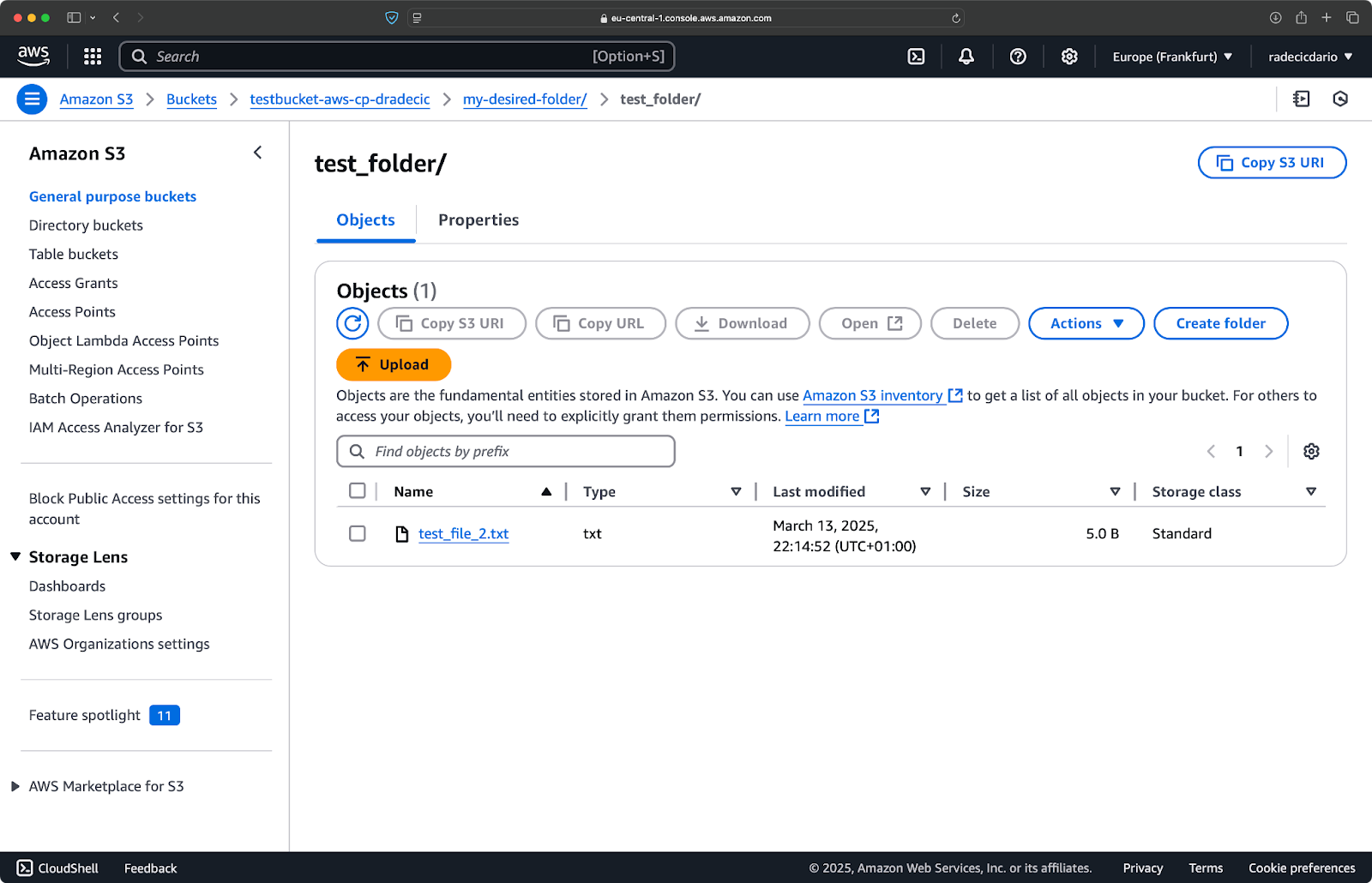
Bild 10 – Inhalte des S3-Buckets nach dem Hochladen eines Ordners
Der --recursive-Schalter stellt sicher, dass alle Dateien und Unterordner innerhalb des Ordners kopiert werden.
Denken Sie daran – S3 hat tatsächlich keine Ordner – die Pfadstruktur ist nur Teil des Objektschlüssels, aber es funktioniert konzeptionell wie Ordner.
Kopieren einer Datei von S3 auf lokal
Um eine Datei von S3 auf Ihr lokales System zu kopieren, kehren Sie einfach die Reihenfolge um – die Quelle wird zur S3-URI und das Ziel ist Ihr lokaler Pfad:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txt
Dieser Befehl lädt test_file.txt aus Ihrem S3-Bucket herunter und speichert es als downloaded_test_file.txt im angegebenen Verzeichnis. Sie werden es sofort auf Ihrem lokalen System sehen:
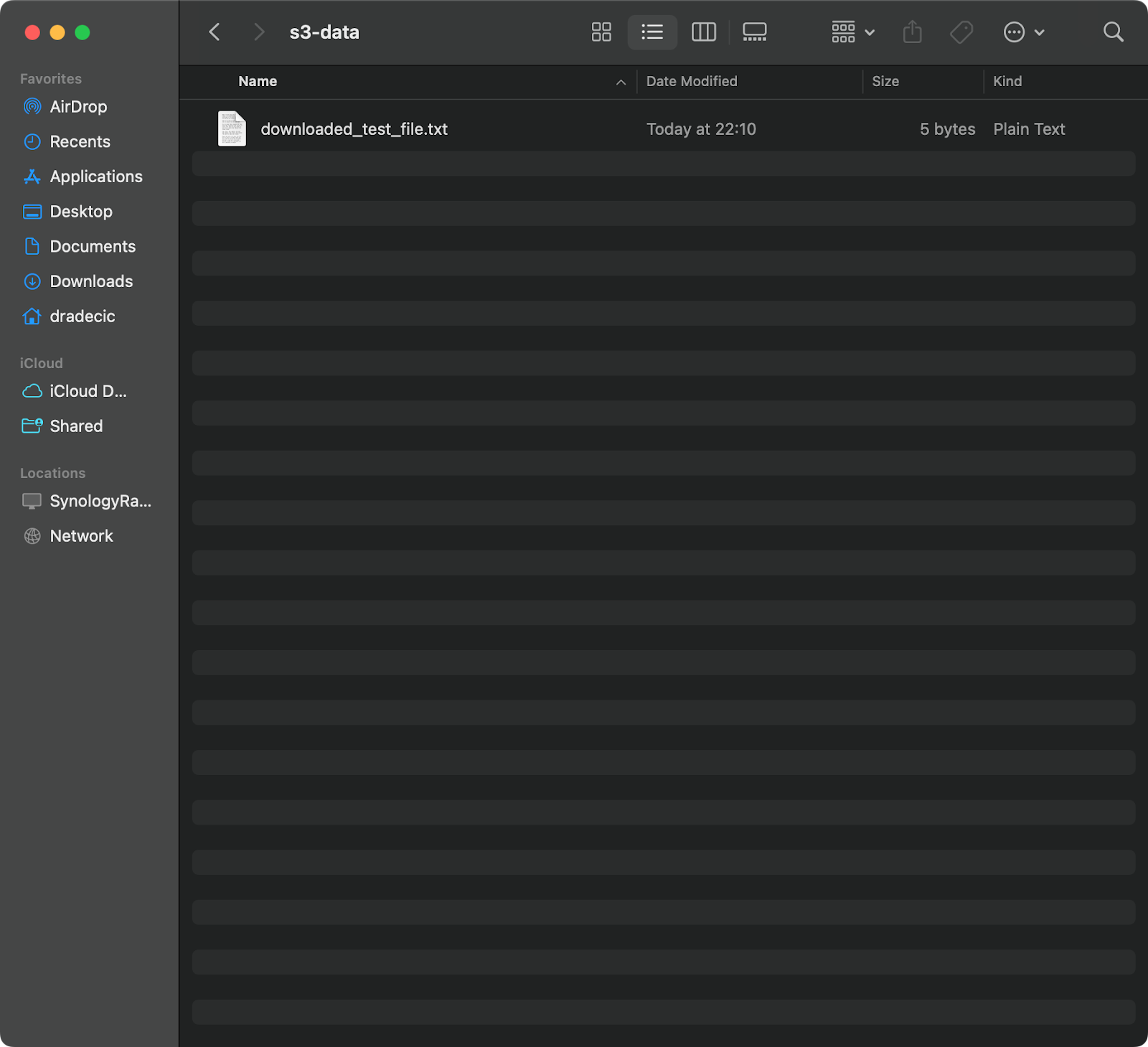
Abbildung 11 – Herunterladen einer einzelnen Datei von S3
Wenn Sie den Dateinamen des Ziels weglassen, wird der Befehl den Originaldateinamen verwenden:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .
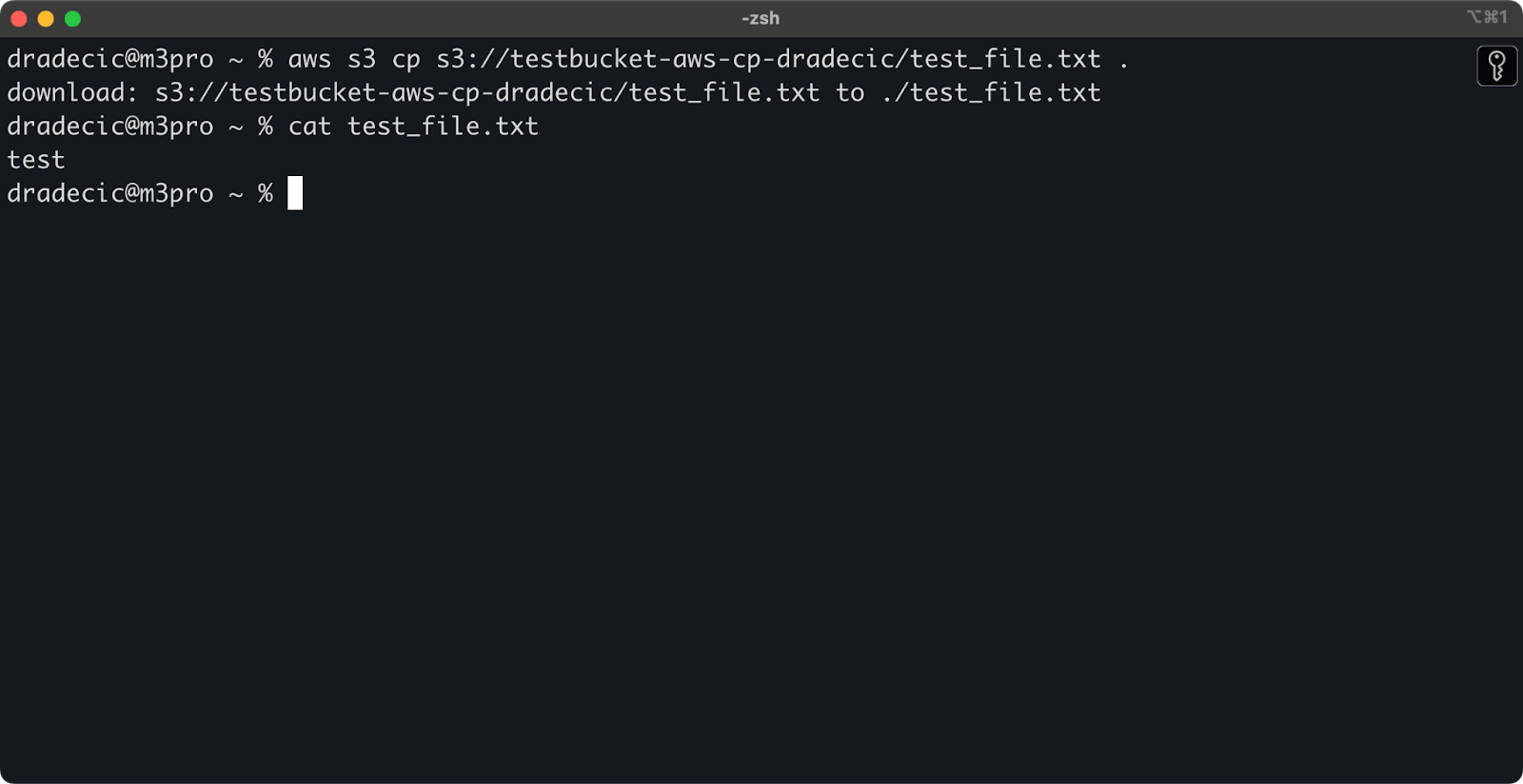
Abbildung 12 – Inhalt der heruntergeladenen Datei
Der Punkt (.) repräsentiert Ihr aktuelles Verzeichnis, sodass dies test_file.txt an Ihren aktuellen Speicherort herunterlädt.
Und schließlich, um ein ganzes Verzeichnis herunterzuladen, können Sie einen Befehl ähnlich diesem verwenden:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive
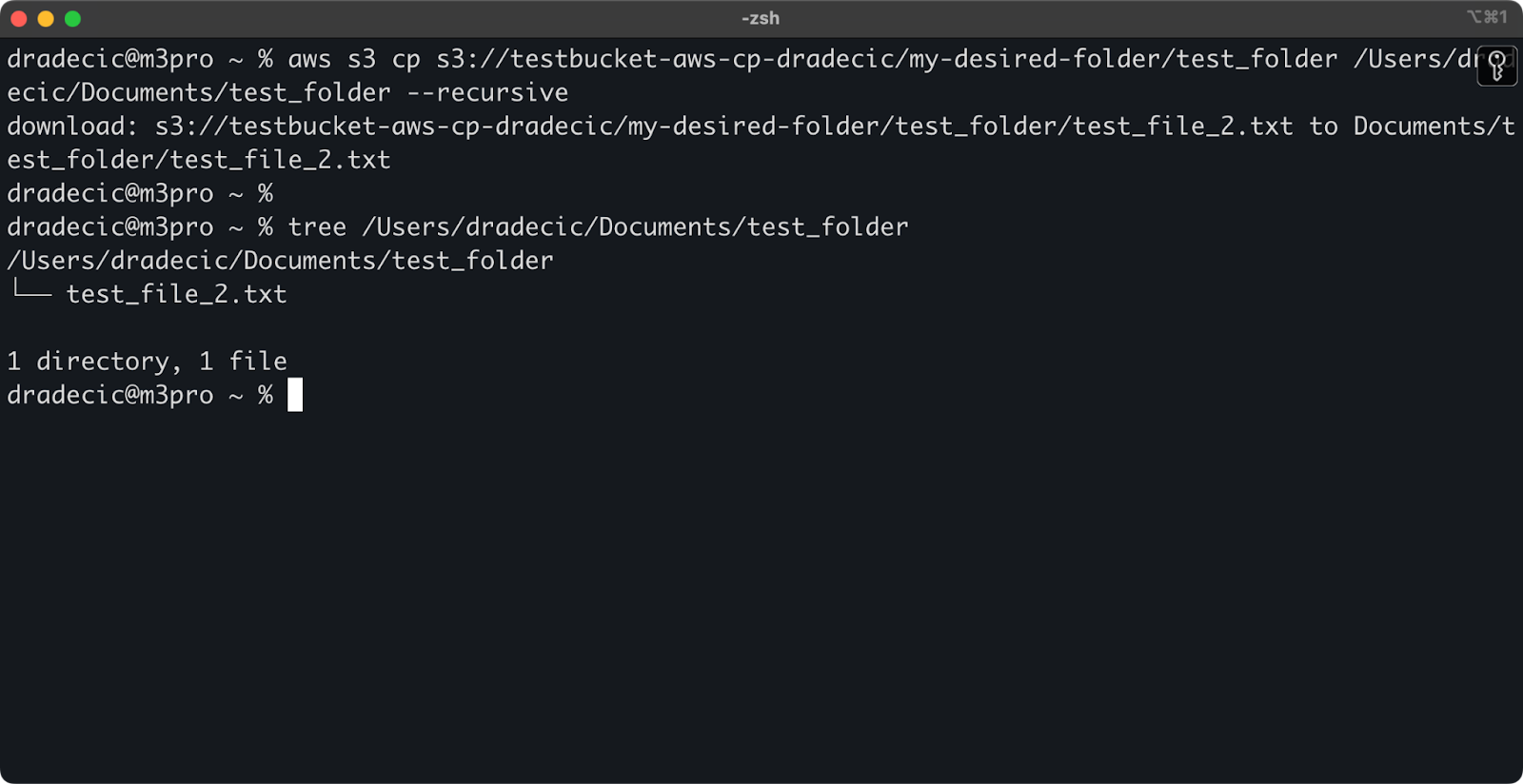
Abbildung 13 – Inhalt des heruntergeladenen Ordners
Beachten Sie, dass die Verwendung des --recursive-Flags unerlässlich ist, wenn Sie mit mehreren Dateien arbeiten – ohne dieses Flag schlägt der Befehl fehl, wenn die Quelle ein Verzeichnis ist.
Mit diesen grundlegenden Befehlen können Sie bereits die meisten der Dateiübertragungsaufgaben erledigen, die Sie benötigen werden. In der nächsten Sektion lernen Sie jedoch fortgeschrittenere Optionen kennen, die Ihnen eine bessere Kontrolle über den Kopiervorgang geben werden.
Erweiterte AWS S3 cp-Optionen und Funktionen
AWS bietet einige fortgeschrittene Optionen, die es Ihnen ermöglichen, Dateikopieroperationen zu maximieren. In diesem Abschnitt zeige ich Ihnen einige der nützlichsten Flags und Parameter, die Ihnen bei Ihren täglichen Aufgaben helfen werden.
Verwendung der –exclude und –include-Flags
Manchmal möchten Sie nur bestimmte Dateien kopieren, die bestimmten Mustern entsprechen. Die --exclude und --include Flags ermöglichen es Ihnen, Dateien anhand von Mustern zu filtern, und sie geben Ihnen genaue Kontrolle darüber, was kopiert wird.
Nur um den Rahmen zu setzen, dies ist die Verzeichnisstruktur, mit der ich arbeite:
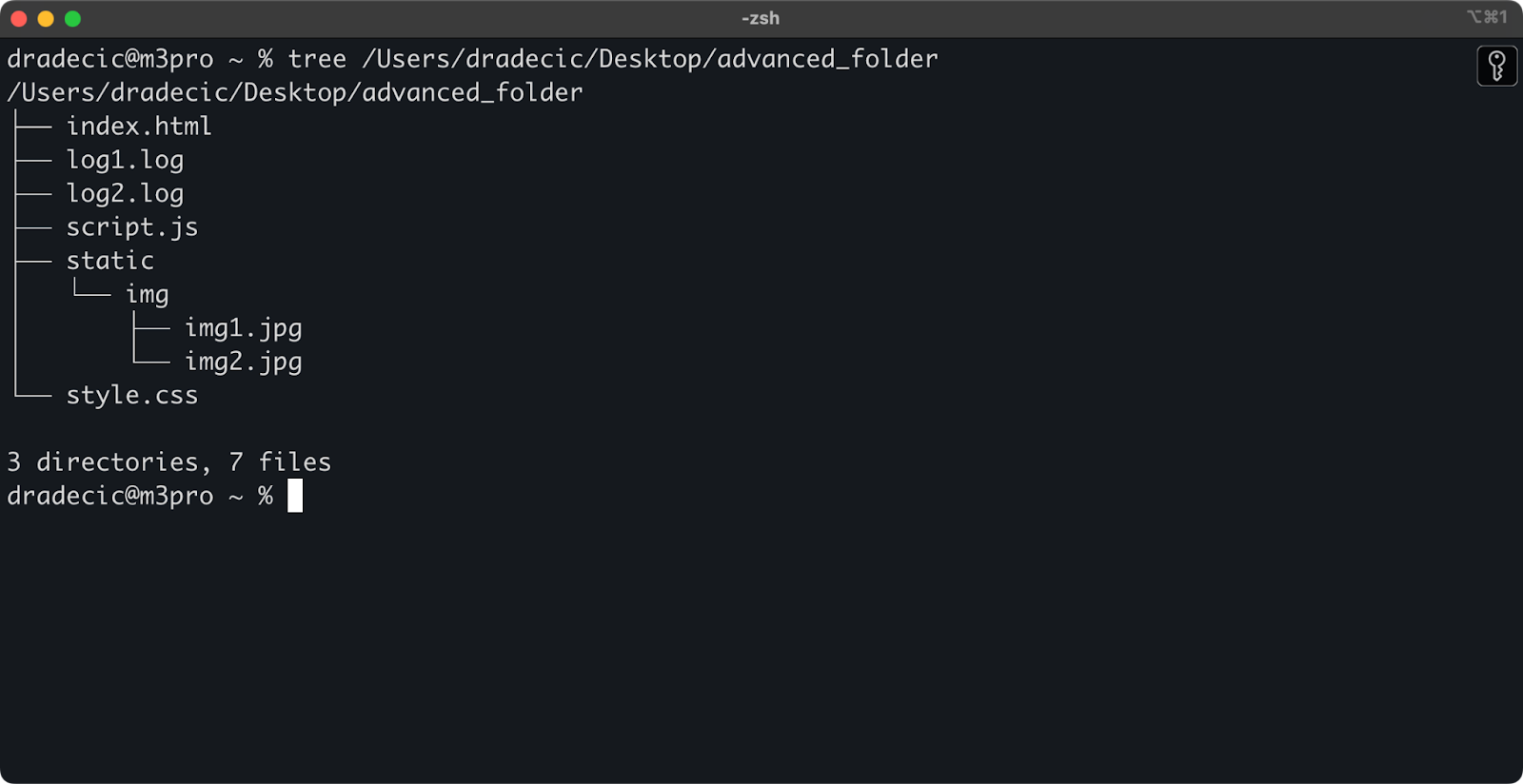
Bild 14 – Verzeichnisstruktur
Angenommen, Sie möchten alle Dateien aus dem Verzeichnis kopieren, außer den .log Dateien:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"
Mit diesem Befehl werden alle Dateien aus dem Verzeichnis advanced_folder nach S3 kopiert, wobei alle Dateien mit der Erweiterung .log ausgeschlossen werden:
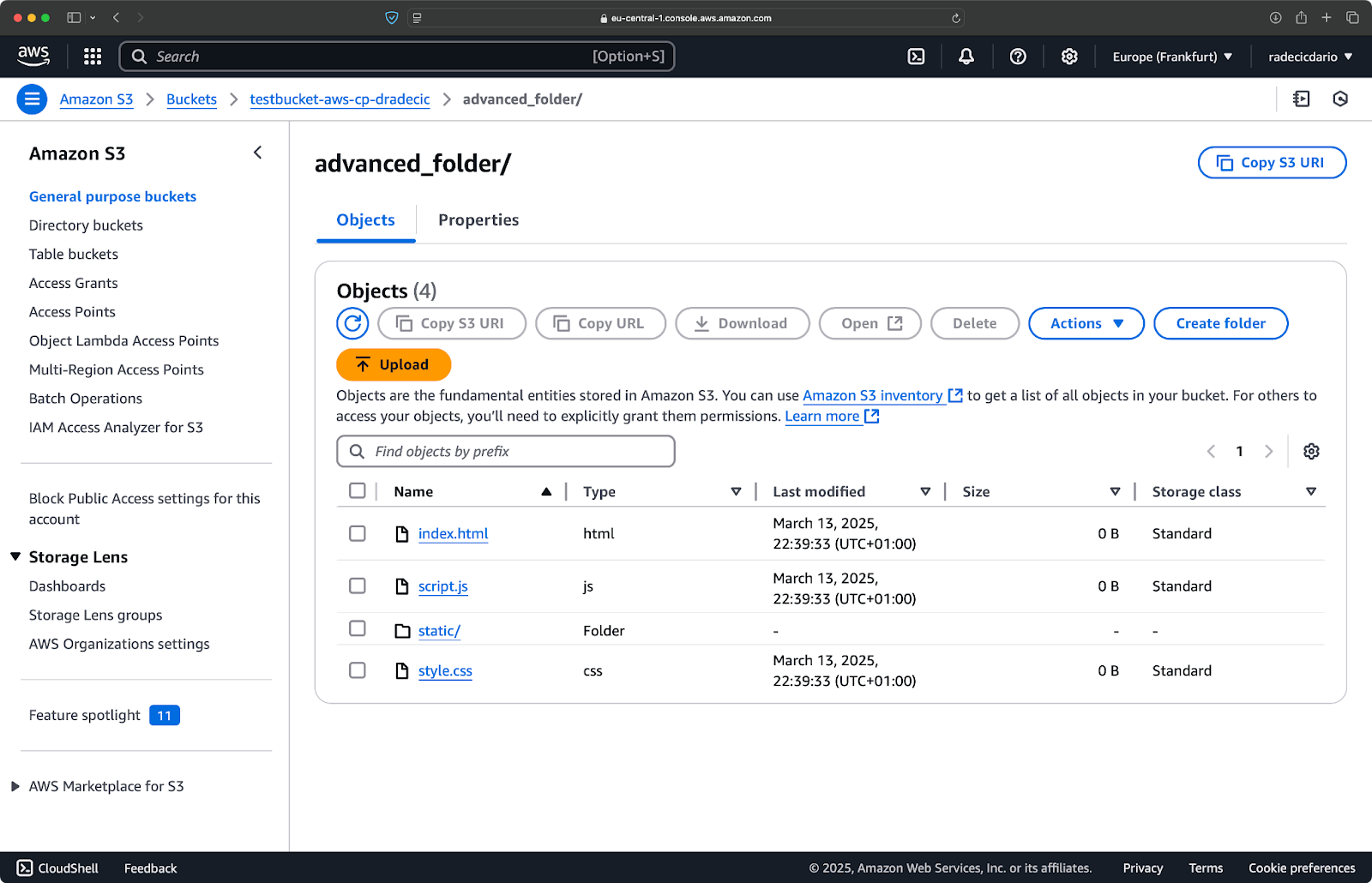
Bild 15 – Ergebnisse des Kopiervorgangs
Sie können auch mehrere Muster kombinieren. Angenommen, Sie möchten nur die HTML- und CSS-Dateien aus dem Projektordner kopieren:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"
Dieser Befehl schließt zunächst alles aus (--exclude "*"), und schließt dann nur Dateien mit den Erweiterungen .html und .css ein. Das Ergebnis sieht so aus:
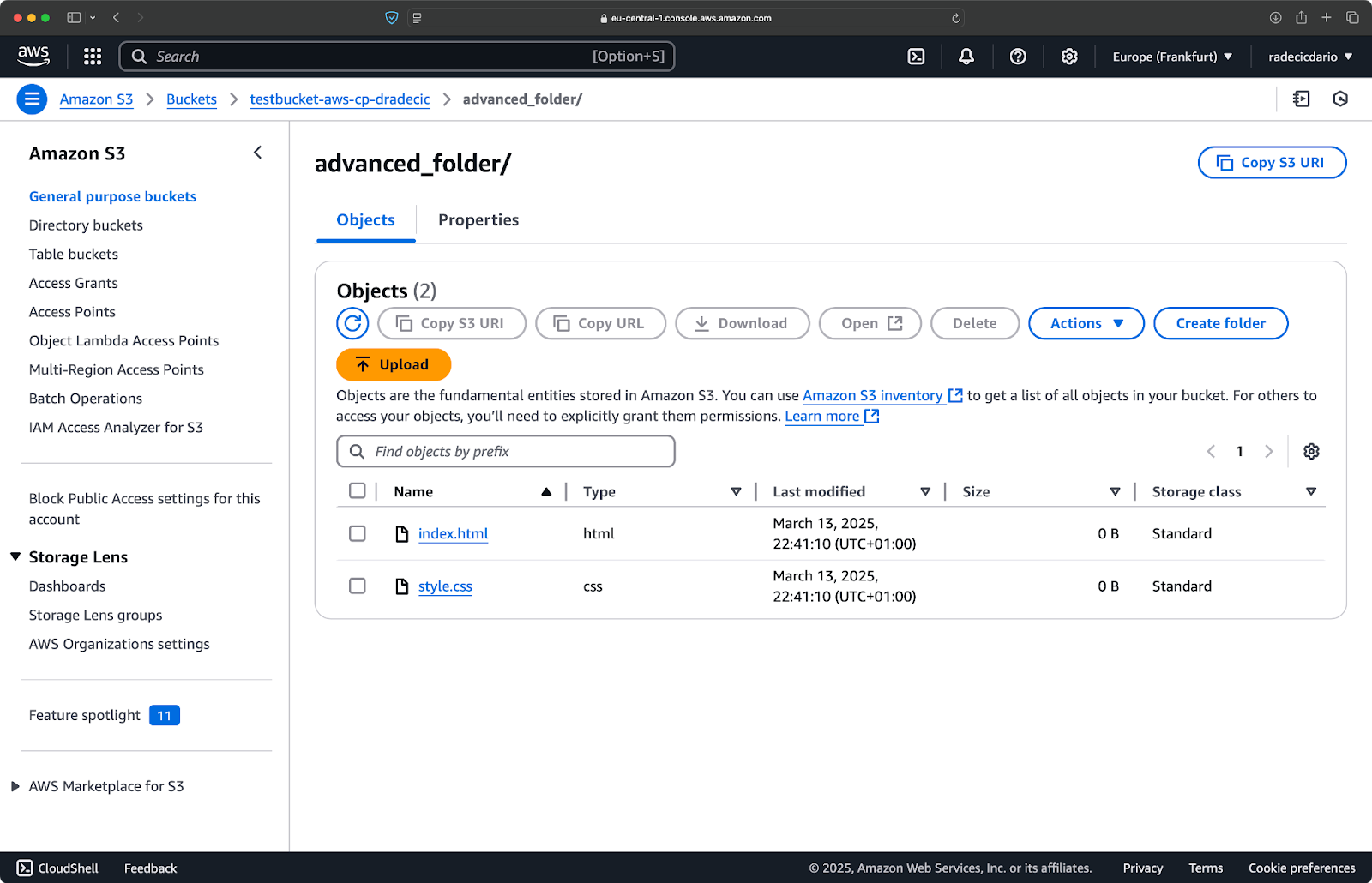
Bild 16 – Ergebnisse des Kopiervorgangs (2)
Denken Sie daran, dass die Reihenfolge der Flags wichtig ist – AWS CLI verarbeitet diese Flags sequentiell, also wenn Sie --include vor --exclude setzen, erhalten Sie unterschiedliche Ergebnisse:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"
Diesmal wurde nichts in den Eimer kopiert:
Bild 17 – Ergebnisse des Kopiervorgangs (3)
Spezifizierung der S3-Speicherklassen
Amazon S3 bietet verschiedene Speicherklassen, jede mit unterschiedlichen Kosten und Abrufmerkmalen. Standardmäßig lädt aws s3 cp Dateien in die Standard-Speicherklasse hoch, aber Sie können eine andere Klasse mit dem --storage-class-Flag angeben:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIER
Dieser Befehl lädt large-archive.zip in die Glacier-Speicherklasse hoch, die deutlich günstiger ist, aber höhere Abrufkosten und längere Abrufzeiten hat:
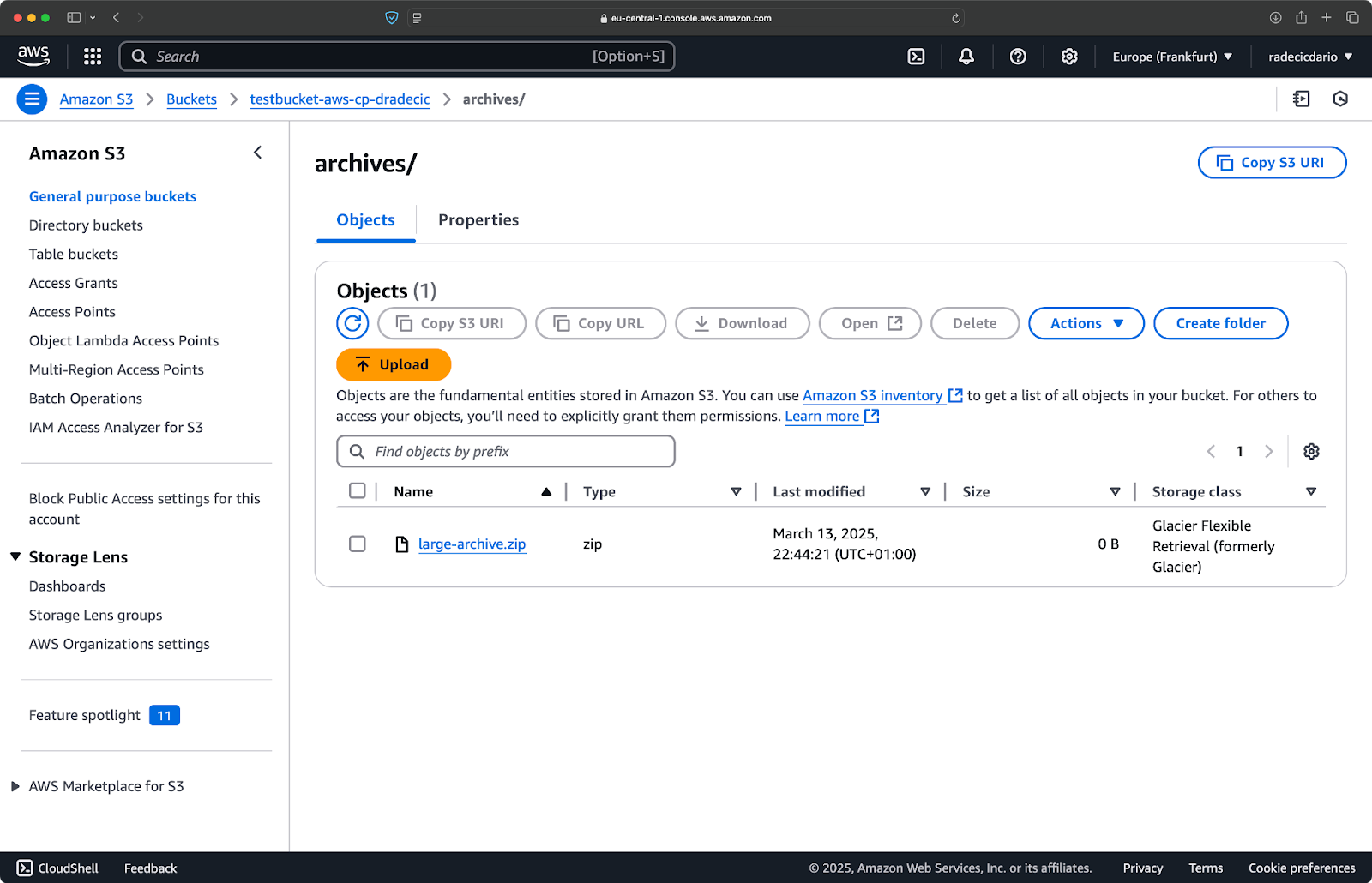
Bild 18 – Kopieren von Dateien in S3 mit verschiedenen Speicherklassen
Die verfügbaren Speicherklassen sind:
STANDARD(Standard): Allzweck-Speicher mit hoher Haltbarkeit und Verfügbarkeit.REDUCED_REDUNDANCY(nicht mehr empfohlen): Geringere Haltbarkeit, kostensparende Option, jetzt veraltet.STANDARD_IA(Seltener Zugriff): Günstigerer Speicher für seltener abgerufene Daten.ONEZONE_IA(Seltener Zugriff in einer Zone): Günstiger, seltener abgerufener Speicher in einer AWS-Verfügbarkeitszone.INTELLIGENT_TIERING: Verschiebt automatisch Daten zwischen Speichertiers basierend auf den Zugriffsmustern.GLACIER: Günstiger Archivspeicher für langfristige Aufbewahrung, Abruf innerhalb von Minuten bis Stunden.DEEP_ARCHIVE: Günstigster Archivspeicher, Abruf innerhalb von Stunden, ideal für langfristige Sicherungskopien.
Wenn Sie Dateien sichern, auf die Sie keinen sofortigen Zugriff benötigen, können Sie durch die Verwendung von GLACIER oder DEEP_ARCHIVE erhebliche Speicherkosten sparen.
Das Synchronisieren von Dateien mit dem –exact-timestamps-Flag
Wenn Sie Dateien in S3 aktualisieren, die bereits vorhanden sind, möchten Sie möglicherweise nur Dateien kopieren, die sich geändert haben. Das --exact-timestamps-Flag hilft dabei, indem es die Zeitstempel zwischen Quelle und Ziel vergleicht.
Hier ist ein Beispiel:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestamps
Mit diesem Flag kopiert der Befehl nur Dateien, wenn sich ihre Zeitstempel von den Dateien unterscheiden, die bereits in S3 vorhanden sind. Dies kann die Übertragungszeit und die Bandbreitennutzung reduzieren, wenn Sie regelmäßig eine große Menge an Dateien aktualisieren.
Also, warum ist das nützlich? Stellen Sie sich einfach Bereitstellungsszenarien vor, in denen Sie Ihre Anwendungsdateien aktualisieren möchten, ohne unveränderte Assets unnötig zu übertragen.
Während --exact-timestamps nützlich ist, um eine Art von Synchronisation durchzuführen, wenn Sie eine ausgefeiltere Lösung benötigen, sollten Sie in Betracht ziehen, stattdessen aws s3 sync anstelle von aws s3 cp zu verwenden. Der Befehl sync wurde speziell entwickelt, um Verzeichnisse synchron zu halten und verfügt über zusätzliche Funktionen zu diesem Zweck. Ich habe alles über den Sync-Befehl im AWS S3 Sync Tutorial geschrieben.
Mit diesen erweiterten Optionen haben Sie nun eine viel feinere Kontrolle über Ihre S3-Dateioperationen. Sie können spezifische Dateien auswählen, Speicherkosten optimieren und Ihre Dateien effizient aktualisieren. Im nächsten Abschnitt lernen Sie, diese Operationen mithilfe von Skripten und geplanten Aufgaben zu automatisieren.
Automatisierung von Dateiübertragungen mit AWS S3 cp
Bisher haben Sie gelernt, wie Sie Dateien manuell mit der Befehlszeile von und nach S3 kopieren können. Einer der größten Vorteile der Verwendung von aws s3 cp ist, dass Sie diese Übertragungen einfach automatisieren können, was Ihnen eine Menge Zeit spart.
Lassen Sie uns erkunden, wie Sie den Befehl aws s3 cp in Skripte und geplante Aufgaben zur automatischen Dateiübertragung integrieren können.
Verwendung von AWS S3 cp in Skripten
Hier ist ein einfaches Bash-Skriptbeispiel, das ein Verzeichnis in S3 sichert, einen Zeitstempel zum Backup hinzufügt und Fehlerbehandlung und Protokollierung in eine Datei implementiert:
#!/bin/bash # Variablen festlegen SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder" BUCKET="s3://testbucket-aws-cp-dradecic/backups" DATE=$(date +%Y-%m-%d-%H-%M) BACKUP_NAME="backup-$DATE" LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log" # Stellen Sie sicher, dass das Protokollverzeichnis vorhanden ist mkdir -p "$(dirname "$LOG_FILE")" # Erstellen Sie das Backup und protokollieren Sie die Ausgabe echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE # Überprüfen, ob das Backup erfolgreich war if [ $? -eq 0 ]; then echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE else echo "Backup failed on $DATE" | tee -a $LOG_FILE fi
Speichern Sie dies als backup.sh, machen Sie es mit chmod +x backup.sh ausführbar und Sie haben ein wiederverwendbares Backup-Skript!
Sie können es dann mit dem folgenden Befehl ausführen:
./backup.sh
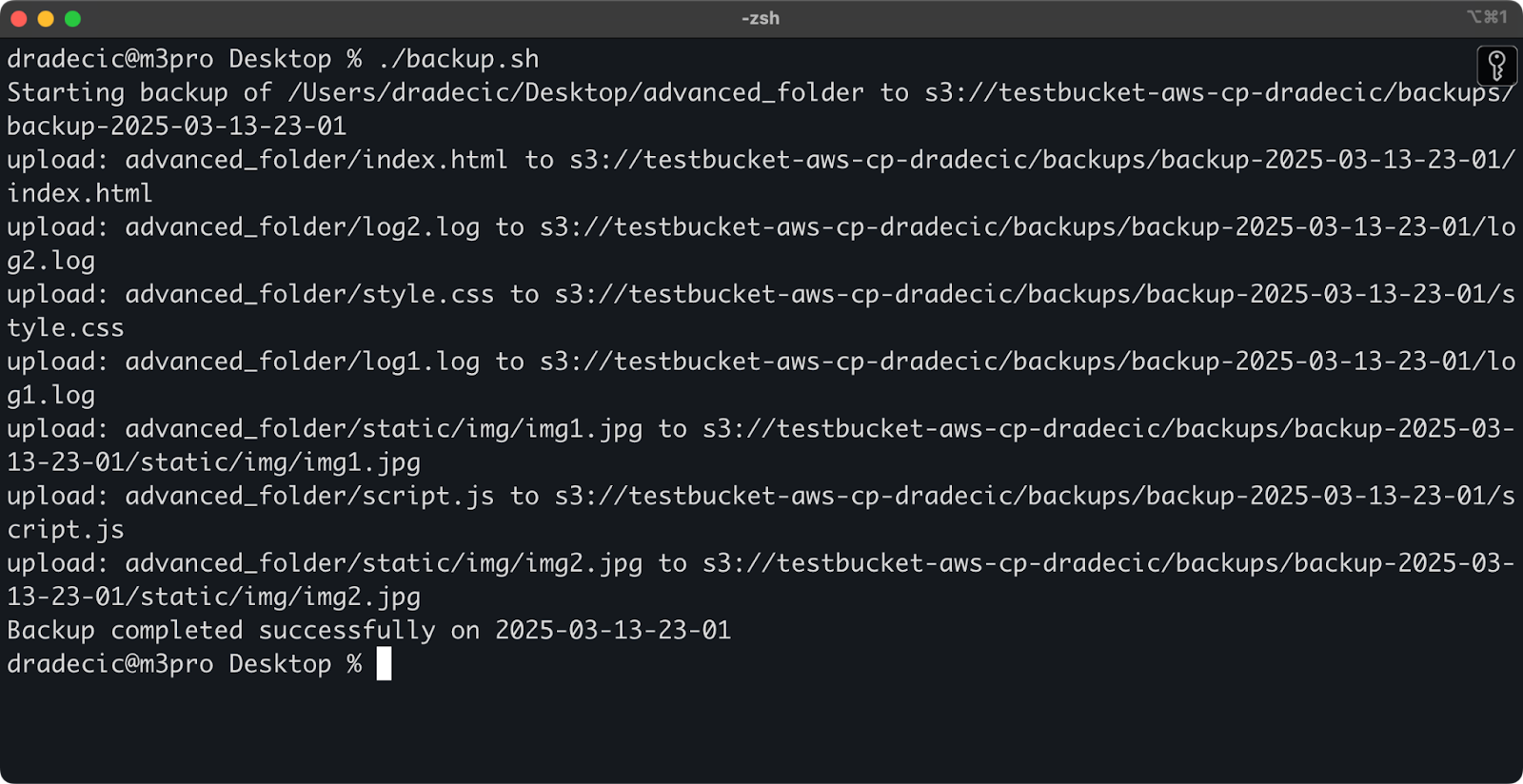
Bild 19 – Skriptausführung im Terminal
Direkt danach wird der Ordner backups im Bucket bevölkert sein:
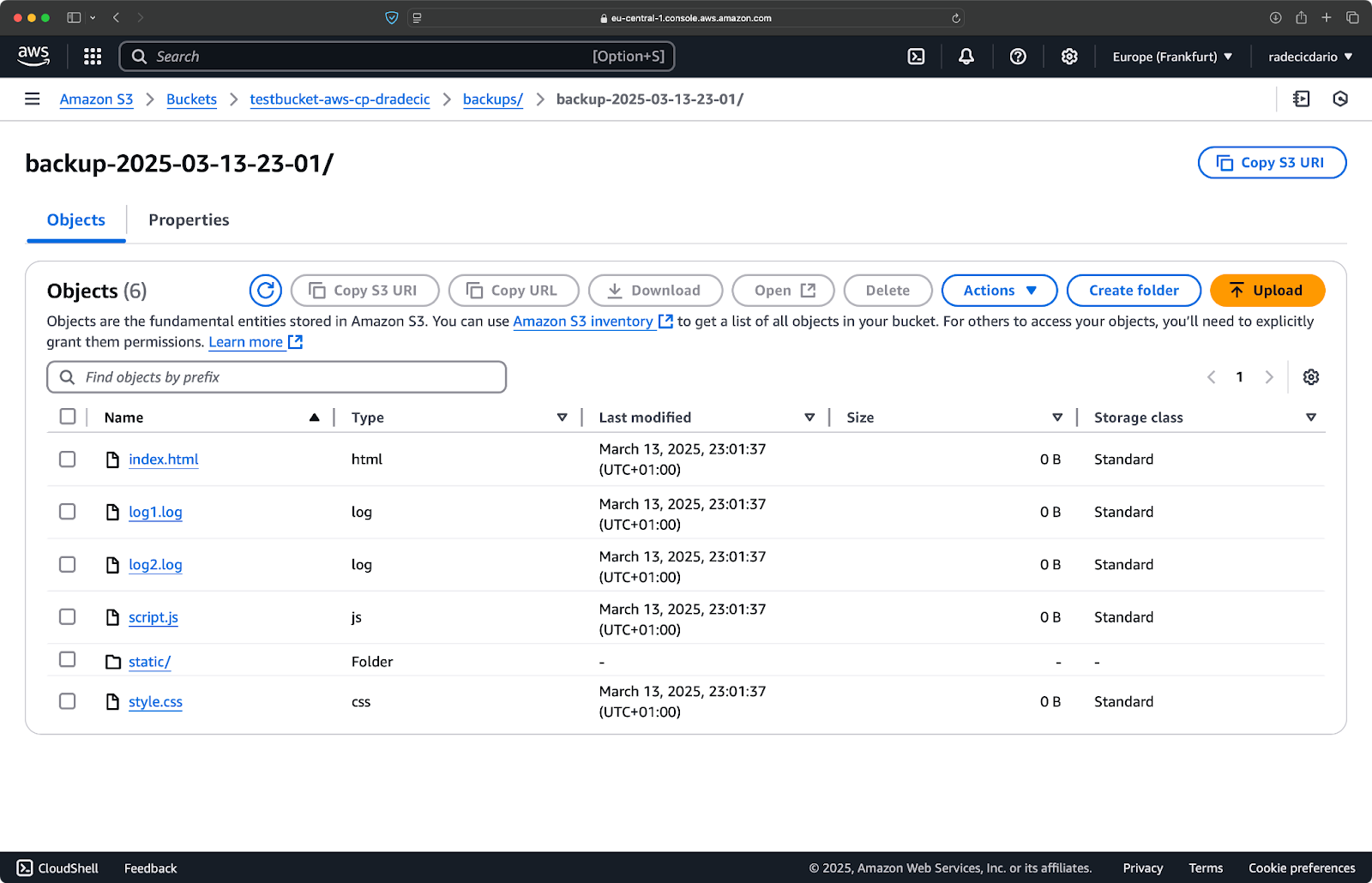
Bild 20 – Backup im S3-Bucket gespeichert
Lassen Sie uns dies auf die nächste Stufe heben, indem wir das Skript nach einem Zeitplan ausführen.
Dateiübertragungen mit Cron-Jobs planen
Jetzt, da Sie ein Skript haben, ist der nächste Schritt, es zu bestimmten Zeiten automatisch auszuführen.
Wenn Sie Linux oder macOS verwenden, können Sie cron verwenden, um Ihre Backups zu planen. So richten Sie einen Cron-Job ein, um Ihr Backup-Skript jeden Tag um Mitternacht auszuführen:
1. Öffnen Sie Ihre Crontab zum Bearbeiten:
crontab -e
2. Fügen Sie die folgende Zeile hinzu, um Ihr Skript täglich um Mitternacht auszuführen:
0 0 * * * /path/to/your/backup.sh
Image 21 – Cron-Job zum täglichen Ausführen des Skripts
Das Format für Cron-Jobs ist Minute Stunde Tag-des-Monats Monat Wochentag Befehl. Hier sind ein paar weitere Beispiele:
- Jede Stunde ausführen:
0 * * * * /pfad/zu/deinem/backup.sh - Jeden Montag um 9 Uhr ausführen:
0 9 * * 1 /pfad/zu/deinem/backup.sh - Am 1. jedes Monats ausführen:
0 0 1 * * /pfad/zu/deinem/backup.sh
Und das war’s! Das Skript backup.sh wird nun im festgelegten Intervall ausgeführt.
Die Automatisierung Ihrer S3-Dateiübertragungen ist eine gute Idee. Besonders nützlich ist dies für Szenarien wie:
- Tägliche Backups wichtiger Daten
- Synchronisierung von Produktbildern auf einer Website
- Verschieben von Protokolldateien in Langzeitspeicherung
- Bereitstellen von aktualisierten Website-Dateien
Automatisierungstechniken wie diese helfen Ihnen, ein zuverlässiges System einzurichten, das Dateiübertragungen ohne manuelle Eingriffe bewältigt. Sie müssen es nur einmal schreiben, und dann können Sie es vergessen.
Im nächsten Abschnitt werde ich einige bewährte Methoden vorstellen, um Ihre aws s3 cp-Operationen sicherer und effizienter zu gestalten.
Best Practices für die Verwendung von AWS S3 cp
Während der aws s3 cp Befehl einfach zu verwenden ist, können Dinge schiefgehen.
Wenn Sie bewährte Verfahren befolgen, vermeiden Sie häufige Fallstricke, optimieren die Leistung und halten Ihre Daten sicher. Lassen Sie uns diese Praktiken erkunden, um Ihre Dateiübertragungsoperationen effizienter zu gestalten.
Effizientes Dateimanagement
Bei der Arbeit mit S3 sparen Sie Zeit und Nerven, wenn Sie Ihre Dateien logisch organisieren.
Zunächst einmal sollten Sie eine konsistente Eimer- und Präfixbenennungskonvention festlegen. Zum Beispiel können Sie Ihre Daten nach Umgebung, Anwendung oder Datum trennen:
s3://company-backups/production/database/2023-03-13/ s3://company-backups/staging/uploads/2023-03/
Diese Art von Organisation erleichtert es:
- Spezifische Dateien zu finden, wenn Sie sie benötigen.
- Eimer-Richtlinien und Berechtigungen auf der richtigen Ebene anzuwenden.
- Lifecycle-Regeln für das Archivieren oder Löschen alter Daten einzurichten.
Ein weiterer Tipp: Beim Übertragen großer Dateisätze sollten Sie in Betracht ziehen, zuerst kleine Dateien zusammenzufassen (mit zip oder tar) bevor Sie sie hochladen. Dies reduziert die Anzahl der API-Aufrufe an S3, was die Kosten senken und die Übertragungsgeschwindigkeit erhöhen kann.
# Anstatt Tausende kleiner Protokolldateien zu kopieren # packen Sie sie zuerst mit tar und laden sie dann hoch tar -czf example-logs-2025-03.tar.gz /var/log/application/ aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/
Umgang mit großen Datentransfers
Wenn Sie große Dateien oder viele Dateien gleichzeitig kopieren, gibt es einige Techniken, um den Prozess zuverlässiger und effizienter zu gestalten.
Sie können die --quiet-Flag verwenden, um die Ausgabe zu reduzieren beim Ausführen in Skripten:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quiet
Dadurch wird die Fortschrittsinformation für jede Datei unterdrückt, was die Protokolle handlicher macht. Es verbessert auch die Leistung etwas.
Für sehr große Dateien sollten Sie in Betracht ziehen, Multipart-Uploads mit dem Flag --multipart-threshold zu verwenden:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MB
Die obige Einstellung teilt AWS CLI mit, Dateien größer als 100 MB in mehrere Teile für den Upload aufzuteilen. Dies bringt einige Vorteile mit sich:
- Wenn die Verbindung abbricht, muss nur der betroffene Teil erneut übertragen werden.
- Teile können parallel hochgeladen werden, was potenziell die Durchsatzrate erhöht.
- Sie können große Uploads pausieren und fortsetzen.
Beim Datenübertragung zwischen Regionen sollten Sie in Betracht ziehen, S3 Transfer Acceleration für schnellere Uploads zu verwenden:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.com
Dies leitet Ihren Transfer über das Edge-Netzwerk von Amazon um, was die Übertragung zwischen Regionen erheblich beschleunigen kann.
Die Sicherheit gewährleisten
Sicherheit sollte immer oberste Priorität haben, wenn Sie mit Ihren Daten in der Cloud arbeiten.
Stellen Sie zunächst sicher, dass Ihre IAM-Berechtigungen dem Prinzip der minimalen Rechte folgen.Vergib nur die spezifischen Berechtigungen, die für jede Aufgabe benötigt werden.
Hier ist ein Beispiel für eine Richtlinie, die Sie dem Benutzer zuweisen können:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*" } ] }
Diese Richtlinie erlaubt das Kopieren von Dateien nur aus dem Präfix „backups“ in „meinem Eimer“.
Ein weiterer Weg, um die Sicherheit zu erhöhen, besteht darin, die Verschlüsselung zu aktivieren für sensible Daten. Sie können die serverseitige Verschlüsselung beim Hochladen angeben:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256
Oder verwenden Sie für mehr Sicherheit den AWS Key Management Service (KMS):
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyId
Allerdings sollten Sie für besonders sensible Operationen in Betracht ziehen, VPC-Endpunkte für S3. Dadurch bleibt Ihr Datenverkehr innerhalb des AWS-Netzwerks und umgeht das öffentliche Internet vollständig.
In dem nächsten Abschnitt erfahren Sie, wie Sie häufige Probleme beheben können, die beim Arbeiten mit diesem Befehl auftreten können.
Fehlerbehebung bei AWS S3 cp Fehlern
Eines ist sicher – Sie werden gelegentlich auf Probleme stoßen, wenn Sie mit aws s3 cp arbeiten. Durch das Verständnis häufiger Fehler und ihrer Lösungen sparen Sie Zeit und Frustration, wenn die Dinge nicht wie geplant verlaufen.
In diesem Abschnitt zeige ich Ihnen die häufigsten Probleme und wie Sie sie beheben können.
Übliche Fehler und Lösungen
Fehler: „Zugriff verweigert“
Dies ist wahrscheinlich der häufigste Fehler, dem Sie begegnen werden:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
Dies bedeutet in der Regel eine der drei folgenden Möglichkeiten:
- Ihr IAM-Benutzer hat nicht ausreichende Berechtigungen, um die Operation auszuführen.
- Die Eimer-Richtlinie beschränkt den Zugriff.
- Ihre AWS-Anmeldeinformationen sind abgelaufen.
Zur Fehlerbehebung:
- Überprüfen Sie Ihre IAM-Berechtigungen, um sicherzustellen, dass Sie die erforderlichen
s3:PutObject(für Uploads) oders3:GetObject(für Downloads) Berechtigungen haben. - Überprüfen Sie, ob die Eimer-Richtlinie Ihre Aktionen einschränkt.
- Führen Sie
aws configureaus, um Ihre Anmeldeinformationen zu aktualisieren, wenn sie abgelaufen sind.
Fehler: „Keine solche Datei oder Verzeichnis“
Dieser Fehler tritt auf, wenn die lokale Datei oder das Verzeichnis, das Sie kopieren möchten, nicht vorhanden ist:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not Found
Die Lösung ist einfach – überprüfen Sie Ihre Dateipfade sorgfältig. Pfade sind Groß- und Kleinschreibung beachten. Stellen Sie außerdem sicher, dass Sie sich im richtigen Verzeichnis befinden, wenn Sie relative Pfade verwenden.
Fehler: „Der angegebene Eimer existiert nicht“
Wenn Sie diesen Fehler sehen:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
Überprüfen Sie:
- Tippfehler in Ihrem Eimernamen.
- Überprüfen Sie, ob Sie die richtige AWS-Region verwenden.
- Überprüfen Sie, ob der Eimer tatsächlich existiert (es könnte gelöscht worden sein).
Sie können alle Ihre Eimer mit aws s3 ls auflisten, um den richtigen Namen zu bestätigen.
Fehler: „Verbindungstimeout“
Netzwerkprobleme können Verbindungsabbrüche verursachen:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeout
Um dies zu lösen:
- Überprüfen Sie Ihre Internetverbindung.
- Versuchen Sie, kleinere Dateien zu verwenden oder die Mehrfachuploads für große Dateien zu aktivieren.
- Erwägen Sie die Verwendung von AWS Transfer Acceleration für bessere Leistung.
Umgang mit Upload-Fehlern
Fehler treten häufiger auf, wenn große Dateien übertragen werden. In solchen Fällen sollten Sie versuchen, Fehler angemessen zu behandeln.
Zum Beispiel können Sie die --only-show-errors-Flag verwenden, um die Fehlerdiagnose in Skripten zu erleichtern:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errors
Dies unterdrückt erfolgreiche Übertragungsmeldungen und zeigt nur Fehler an, was die Fehlersuche bei großen Übertragungen erheblich erleichtert.
Zur Behandlung unterbrochener Übertragungen überspringt der Befehl --recursive automatisch Dateien, die bereits mit der gleichen Größe im Ziel vorhanden sind. Um jedoch gründlicher vorzugehen, können Sie die integrierten Wiederholungen des AWS CLI für Netzwerkprobleme verwenden, indem Sie diese Umgebungsvariablen setzen:
export AWS_RETRY_MODE=standard export AWS_MAX_ATTEMPTS=5 aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/
Dies teilt dem AWS CLI mit, fehlgeschlagene Operationen automatisch bis zu 5 Mal zu wiederholen.
Bei sehr großen Datensätzen empfiehlt es sich jedoch, anstelle von cp aws s3 sync zu verwenden, da es besser für Unterbrechungen geeignet ist:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/
Der Befehl sync überträgt nur Dateien, die sich von dem unterscheiden, was bereits im Zielort vorhanden ist, was ihn perfekt für das Wiederaufnehmen unterbrochener großer Übertragungen macht.
Wenn Sie diese häufigen Fehler verstehen und eine ordnungsgemäße Fehlerbehandlung in Ihren Skripten implementieren, machen Sie Ihre S3-Kopieroperationen viel robuster und zuverlässiger.
Zusammenfassend AWS S3 cp
Zusammenfassend ist der Befehl aws s3 cp eine All-in-One-Lösung zum Kopieren lokaler Dateien nach S3 und umgekehrt.
Sie haben in diesem Artikel alles darüber gelernt. Sie haben mit den Grundlagen und der Umgebungskonfiguration begonnen und sind dazu übergegangen, geplante und automatisierte Skripte zum Kopieren von Dateien zu schreiben. Sie haben auch gelernt, wie Sie einige häufige Fehler und Herausforderungen beim Verschieben von Dateien, insbesondere großen Dateien, bewältigen können.
Wenn Sie also ein Entwickler, Datenfachmann oder Systemadministrator sind, denke ich, dass Sie diesen Befehl nützlich finden werden. Der beste Weg, sich damit wohlzufühlen, besteht darin, ihn regelmäßig zu verwenden. Stellen Sie sicher, dass Sie die Grundlagen verstehen, und verbringen Sie dann etwas Zeit damit, lästige Teile Ihrer Arbeit zu automatisieren.
Um mehr über AWS zu erfahren, folgen Sie diesen Kursen von DataCamp:
Sie können sogar DataCamp verwenden, um sich auf AWS-Zertifizierungsprüfungen vorzubereiten – AWS Cloud Practitioner (CLF-C02).