













Was bedeutet es, Zeilen in Spalten in SQL zu drehen?
Das Pivoting in SQL bezieht sich auf die Transformation von Daten von einem zeilenbasierten Format in ein spaltenbasiertes Format. Diese Transformation ist nützlich für Berichterstellung und Datenanalyse und ermöglicht eine strukturiertere und kompaktere Datenansicht. Das Umwandeln von Zeilen in Spalten ermöglicht es den Benutzern auch, Daten auf eine Weise zu analysieren und zusammenzufassen, die wichtige Erkenntnisse klarer hervorhebt.
Betrachten wir das folgende Beispiel: Ich habe eine Tabelle mit täglichen Verkaufstransaktionen, und jede Zeile enthält das Datum, den Produktnamen und den Verkaufsbetrag.
| Date | Product | Sales |
|---|---|---|
| 2024-01-01 | Laptop | 100 |
| 2024-01-01 | Maus | 200 |
| 2024-01-02 | Laptop | 150 |
| 2024-01-02 | Maus | 250 |
Indem ich diese Tabelle pivote, kann ich sie umstrukturieren, um jedes Produkt als Spalte darzustellen, mit den Verkaufsdaten für jedes Datum unter der entsprechenden Spalte. Beachten Sie auch, dass eine Aggregation stattfindet.
| Date | Laptop | Mouse |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Traditionell erforderten Pivot-Operationen komplexe SQL-Abfragen mit bedingter Aggregation. Im Laufe der Zeit haben sich SQL-Implementierungen weiterentwickelt, wobei viele moderne Datenbanken jetzt PIVOT– und UNPIVOT-Operatoren enthalten, um effizientere und einfachere Transformationen zu ermöglichen.
Verständnis von SQL Pivot Zeilen zu Spalten
Die SQL-Pivot-Operation verwandelt Daten, indem sie Zeilenwerte in Spalten umwandelt. Folgendes ist die grundlegende Syntax und Struktur von SQL Pivot mit den folgenden Teilen:
-
SELECT: Die
SELECT-Anweisung verweist auf die Spalten, die in der SQL-Pivot-Tabelle zurückgegeben werden sollen. -
Unterabfrage: Die Unterabfrage enthält die Datenquelle oder Tabelle, die in der SQL-Pivot-Tabelle enthalten sein soll.
-
PIVOT: Der
PIVOT-Operator enthält die Aggregationen und Filter, die auf der Pivot-Tabelle angewendet werden sollen.
-- Auswahl statischer Spalten und pivotierter Spalten SELECT <static columns>, [pivoted columns] FROM ( -- Unterabfrage, die die Ausgangsdaten für das Pivoting definiert <subquery that defines data> ) AS source PIVOT ( -- Aggregatfunktion, die auf die Wertspalte angewendet wird und neue Spalten erstellt <aggregation function>(<value column>) FOR <column to pivot> IN ([list of pivoted columns]) ) AS pivot_table;
Schauen wir uns das folgende schrittweise Beispiel an, um zu demonstrieren, wie Zeilen in Spalten in SQL gepivoted werden. Betrachten Sie die untenstehende SalesData-Tabelle.

Beispiel einer Tabelle zur Transformation mit dem SQL PIVOT Operator. Bild von Autor.
Ich möchte diese Daten umwandeln, um die täglichen Verkäufe jedes Produkts zu vergleichen. Ich werde damit beginnen, die Unterabfrage auszuwählen, die den PIVOT Operator strukturieren wird.
-- Unterabfrage definiert Quelldaten für das Pivot SELECT Date, Product, Sales FROM SalesData;
Jetzt werde ich den PIVOT Operator verwenden, um Product Werte in Spalten umzuwandeln und Sales mithilfe des SUM Operators zu aggregieren.
-- Datum auswählen und für jedes Produkt gepivote Spalten SELECT Date, [Laptop], [Mouse] FROM ( -- Unterabfrage, um Datum, Produkt und Umsatzspalten abzurufen SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Umsatz nach Produkt aggregieren, Produktwerte in Spalten umwandeln SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;

Beispiel für die Ausgabetransformation mit SQL Pivot, Zeilen in Spalten. Bild von Autor.
Beim Pivoting von Daten wird die Zusammenfassung von Daten vereinfacht, jedoch hat diese Technik potenzielle Probleme. Die folgenden sind die potenziellen Herausforderungen beim SQL-Pivot und wie man sie angehen kann.
-
Dynamische Spaltennamen: Wenn die zu pivotierenden Werte (z. B. Produkttypen) unbekannt sind, funktioniert das Festcodieren von Spaltennamen nicht. Einige Datenbanken, wie SQL Server, unterstützen dynamisches SQL mit gespeicherten Prozeduren, um dieses Problem zu vermeiden, während andere dies auf der Anwendungsebene behandeln müssen.
-
Umgang mit NULL-Werten: Wenn es keine Daten für eine bestimmte gepivote Spalte gibt, kann das Ergebnis
NULLenthalten. Sie könnenCOALESCEverwenden, umNULL-Werte durch Null oder einen anderen Platzhalter zu ersetzen. -
Kompatibilität über Datenbanken hinweg: Nicht alle Datenbanken unterstützen den
PIVOT-Operator direkt. Wenn Ihr SQL-Dialekt dies nicht unterstützt, können Sie ähnliche Ergebnisse mitCASE-Anweisungen und bedingter Aggregation erzielen.
SQL Pivot Zeilen in Spalten: Beispiele und Anwendungsfälle
Verschiedene Methoden werden verwendet, um Daten in SQL zu pivotieren, abhängig von der verwendeten Datenbank oder anderen Anforderungen. Während der PIVOT-Operator in SQL Server üblich ist, ermöglichen andere Techniken wie die CASE-Anweisungen ähnliche Datenbanktransformationen ohne direkte Unterstützung von PIVOT. Ich werde die beiden gängigen Methoden zur Datenpivottierung in SQL behandeln und über Vor- und Nachteile sprechen.
Verwendung des PIVOT-Operators
Der PIVOT-Operator, verfügbar in SQL Server, bietet eine einfache Möglichkeit, Zeilen in Spalten zu pivotieren, indem eine Aggregatfunktion angegeben und die zu pivotierenden Spalten definiert werden.
Betrachten Sie die folgende Tabelle mit dem Namen sales_data.

Beispiel Orders-Tabelle zur Transformation mithilfe des PIVOT-Operators. Bild von Autor.
Ich werde den PIVOT-Operator verwenden, um die Daten zu aggregieren, sodass die Gesamtsumme der sales_revenue für jedes Jahr in Spalten angezeigt wird.
-- Verwenden von PIVOT zur Aggregation von Umsatzerlösen nach Jahr SELECT * FROM ( -- Auswahl der relevanten Spalten aus der Ausgangstabelle SELECT sale_year, sales_revenue FROM sales_data ) AS src PIVOT ( -- Aggregation der Umsatzerlöse für jedes Jahr SUM(sales_revenue) -- Erstellen von Spalten für jedes Jahr FOR sale_year IN ([2020], [2021], [2022], [2023]) ) AS piv;

Beispielhafte Ausgabentransformation unter Verwendung von SQL PIVOT. Bild von Autor.
Die Verwendung des PIVOT-Operators hat folgende Vorteile und Einschränkungen:
-
Vorteile: Die Methode ist effizient, wenn die Spalten ordnungsgemäß indiziert sind. Sie verfügt außerdem über eine einfache, besser lesbare Syntax.
-
Einschränkungen: Nicht alle Datenbanken unterstützen den
PIVOT-Operator. Es erfordert die vorherige Angabe der Spalten, und dynamisches Pivoting bringt zusätzliche Komplexität mit sich.
Manuelles Pivoting mit CASE-Anweisungen
Sie können auch die CASE-Anweisungen verwenden, um Daten manuell in Datenbanken zu pivotieren, die keine PIVOT-Operatoren unterstützen, wie z.B. MySQL und PostgreSQL. Dieser Ansatz verwendet bedingte Aggregation durch Auswertung jeder Zeile und bedingte Zuweisung von Werten zu neuen Spalten basierend auf spezifischen Kriterien.
Zum Beispiel können wir Daten in derselben sales_data-Tabelle manuell pivotieren mit CASE-Anweisungen.
-- Umsatzerlöse nach Jahr aggregieren mithilfe von CASE-Anweisungen SELECT -- Gesamtumsatzerlöse für jedes Jahr berechnen SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020, SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021, SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022, SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023 FROM sales_data;

Beispiel für die Ausgabetransformation mit dem SQL CASE-Statement. Bild von Autor.
Die Verwendung des CASE-Statements zur Transformation hat folgende Vorteile und Einschränkungen:
-
Vorteile: Die Methode funktioniert in allen SQL-Datenbanken und ist flexibel für die dynamische Generierung neuer Spalten, selbst wenn Produktnamen unbekannt oder häufig geändert werden.
-
Beschränkungen: Abfragen können komplex und langwierig werden, wenn es viele Spalten zu pivotieren gibt. Aufgrund der mehreren bedingten Überprüfungen ist die Methode etwas langsamer als der
PIVOT-Operator.
Leistungsüberlegungen beim Pivotieren von Zeilen zu Spalten
Das Pivotieren von Zeilen zu Spalten in SQL kann Auswirkungen auf die Leistung haben, insbesondere bei der Arbeit mit großen Datensätzen. Hier sind einige Tipps und Best Practices, die Ihnen helfen, effiziente Pivot-Abfragen zu schreiben, deren Leistung zu optimieren und häufige Fallstricke zu vermeiden.
Best Practices
Die folgenden sind die besten Praktiken zur Optimierung Ihrer Abfragen und zur Verbesserung der Leistung.
-
Indexierungsstrategien: Eine ordnungsgemäße Indexierung ist entscheidend für die Optimierung von Pivot-Abfragen, da sie SQL ermöglicht, Daten schneller abzurufen und zu verarbeiten. Indizieren Sie immer die Spalten, die häufig in der
WHERE-Klausel verwendet werden, oder die Spalten, die Sie gruppieren, um die Scan-Zeiten zu reduzieren. -
Vermeiden Sie verschachtelte Pivots: Das Stapeln mehrerer Pivot-Operationen in einer Abfrage kann schwer lesbar und langsamer in der Ausführung sein. Vereinfachen Sie, indem Sie die Abfrage in Teile aufteilen oder eine temporäre Tabelle verwenden.
-
Begrenzen Sie Spalten und Zeilen im Pivot: Nur die Pivot-Spalten sind für die Analyse notwendig, da das Pivotieren vieler Spalten ressourcenintensiv sein kann und große Tabellen erstellt.
Vermeidung häufiger Fehler
Die folgenden sind die häufigen Fehler, die bei Pivot-Abfragen auftreten können, und wie man sie vermeidet.
-
Unnötige Volltabellenscans: Pivot-Abfragen können Volltabellenscans auslösen, insbesondere wenn keine relevanten Indizes verfügbar sind. Vermeiden Sie Volltabellenscans, indem Sie Schlüsselspalten indizieren und Daten filtern, bevor Sie das Pivot anwenden.
-
Verwendung von Dynamic SQL für häufiges Pivoting: Die Verwendung von Dynamic SQL kann die Leistung aufgrund der Abfragekompilierung verlangsamen. Um dieses Problem zu vermeiden, cachen oder begrenzen Sie dynamische Pivots auf bestimmte Szenarien und erwägen Sie, dynamische Spalten in der Anwendungsebene zu behandeln, wenn möglich.
-
Aggregierung großer Datensätze ohne Vorfilterung: Aggregationsfunktionen wie
SUModerCOUNTauf großen Datensätzen können die Leistung der Datenbank verlangsamen. Statt den gesamten Datensatz zu pivotieren, filtern Sie die Daten zuerst mithilfe einerWHERE-Klausel. -
NULL-Werte in gedrehten Spalten: Pivot-Operationen produzieren oft
NULL-Werte, wenn keine Daten für eine bestimmte Spalte vorhanden sind. Diese können Abfragen verlangsamen und die Ergebnisse schwerer interpretierbar machen. Um dieses Problem zu vermeiden, verwenden Sie Funktionen wieCOALESCE, umNULL-Werte durch einen Standardwert zu ersetzen. -
Nur mit Beispieldaten testen: Pivot-Abfragen können sich bei großen Datensätzen aufgrund des erhöhten Speicher- und Verarbeitungsbedarfs anders verhalten. Testen Sie Pivot-Abfragen immer an realen oder repräsentativen Datensamples, um die Leistungsauswirkungen genau zu beurteilen.
Probieren Sie unseren Karriereweg SQL Server Developer aus, der alles von Transaktionen und Fehlerbehandlung bis zur Verbesserung der Abfrageleistung abdeckt.
Datenbankspezifische Implementierungen
Pivot-Operationen unterscheiden sich erheblich zwischen Datenbanken wie SQL Server, MySQL und Oracle. Jede dieser Datenbanken verfügt über spezifische Syntax und Einschränkungen. Ich werde Beispiele für das Pivoting von Daten in den verschiedenen Datenbanken und deren wichtigsten Funktionen behandeln.
SQL Server
SQL Server bietet einen integrierten PIVOT-Operator, der einfach ist, wenn Zeilen in Spalten umgeklappt werden. Der PIVOT-Operator ist einfach zu verwenden und integriert sich mit den leistungsstarken Aggregatfunktionen von SQL Server. Die wichtigsten Funktionen des Pivoting in SQL sind:
-
Direkte Unterstützung für PIVOT und UNPIVOT: Der
PIVOT-Operator von SQL Server ermöglicht eine schnelle Umwandlung von Zeilen in Spalten. DerUNPIVOT-Operator kann diesen Prozess auch umkehren. -
Aggregationsmöglichkeiten: Der
PIVOT-Operator ermöglicht verschiedene Aggregatfunktionen wieSUM,COUNTundAVG.
Die Einschränkung des PIVOT-Operators in SQL Server besteht darin, dass die zu pivotierenden Spaltenwerte im Voraus bekannt sein müssen, was ihn weniger flexibel für sich dynamisch ändernde Daten macht.
In dem folgenden Beispiel konvertiert der PIVOT-Operator Product-Werte in Spalten und aggregiert Sales mithilfe des SUM-Operators.
-- Datum und pivotierte Spalten für jedes Produkt auswählen SELECT Date, [Laptop], [Mouse] FROM ( -- Unterabfrage, um Datum, Produkt und Umsatzspalten abzurufen SELECT Date, Product, Sales FROM SalesData ) AS source PIVOT ( -- Umsatz nach Produkt aggregieren, Produktwerte in Spalten pivotieren SUM(Sales) FOR Product IN ([Laptop], [Mouse]) ) AS pivot_table;
Ich empfehle den Kurs Einführung in SQL Server von DataCamp, um die Grundlagen von SQL Server für die Datenanalyse zu beherrschen.
MySQL
MySQL unterstützt den PIVOT-Operator nicht nativ. Sie können jedoch die CASE-Anweisung verwenden, um Zeilen manuell in Spalten zu pivotieren und andere Aggregatfunktionen wie SUM, AVG und COUNT zu kombinieren. Obwohl diese Methode flexibel ist, kann sie komplex werden, wenn Sie viele Spalten zu pivotieren haben.
Die Abfrage unten erreicht die gleiche Ausgabe wie das SQL Server PIVOT Beispiel, indem sie den Verkauf für jedes Produkt bedingt aggregiert und den CASE Operator verwendet.
-- Wählen Sie Datum und die gedrehten Spalten für jedes Produkt aus SELECT Date, -- Verwenden SieCASE, um eine Spalte für Laptop- und Mäuseverkäufe zu erstellen SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop, SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse FROM SalesData GROUP BY Date;
Oracle
Oracle unterstützt den PIVOT Operator, der die einfache Umwandlung von Zeilen in Spalten ermöglicht. Genauso wie SQL Server müssen Sie die Spalten für die Transformation explizit angeben.
In der folgenden Abfrage wandelt der PIVOT Operator die ProductName Werte in Spalten um und aggregiert SalesAmount mit dem SUM Operator.
SELECT * FROM ( -- Auswahl der Ausgangsdaten SELECT SaleDate, ProductName, SaleAmount FROM SalesData ) PIVOT ( -- Verkauf nach Produkt aggregieren und gedrehte Spalten erstellen SUM(SaleAmount) FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse) );

Beispiel für die Ausgabetransformation mit dem SQL PIVOT-Operator in Oracle. Bild von Autor.
Fortgeschrittene Techniken zum Umwandeln von Zeilen in Spalten in SQL
Fortgeschrittene Techniken zum Umwandeln von Zeilen in Spalten sind nützlich, wenn Sie Flexibilität beim Umgang mit komplexen Daten benötigen. Dynamische Techniken und das gleichzeitige Bearbeiten mehrerer Spalten ermöglichen es Ihnen, Daten in Szenarien zu transformieren, in denen statisches Pivoting begrenzt ist. Lassen Sie uns diese beiden Methoden im Detail erkunden.
Dynamische Pivots
Dynamische Pivots ermöglichen es Ihnen, Pivot-Abfragen zu erstellen, die sich automatisch an Änderungen in den Daten anpassen. Diese Technik ist besonders nützlich, wenn Sie Spalten haben, die sich häufig ändern, wie Produkt- oder Kategorienamen, und Sie möchten, dass Ihre Abfrage neue Einträge automatisch einschließt, ohne sie manuell aktualisieren zu müssen.
Angenommen, wir haben eine SalesData-Tabelle und können ein dynamisches Pivot erstellen, das sich anpasst, wenn neue Produkte hinzugefügt werden. In der folgenden Abfrage baut @columns dynamisch die Liste der pivotierten Spalten auf, und sp_executesql führt das generierte SQL aus.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX); -- Schritt 1: Generieren Sie eine Liste von distinct Produkten für das Pivot SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ') FROM (SELECT DISTINCT Product FROM SalesData) AS products; -- Schritt 2: Erstellen Sie die dynamische SQL-Abfrage SET @sql = N' SELECT Date, ' + @columns + ' FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT ( SUM(Sales) FOR Product IN (' + @columns + ') ) AS pivot_table;'; -- Schritt 3: Führen Sie die dynamische SQL-Abfrage aus EXEC sp_executesql @sql;
Umgang mit mehreren Spalten
In Szenarien, in denen Sie mehrere Spalten gleichzeitig pivotieren müssen, verwenden Sie den PIVOT-Operator und zusätzliche Aggregationstechniken, um mehrere Spalten in derselben Abfrage zu erstellen.
Im folgenden Beispiel habe ich die Spalten Sales und Quantity nach Product pivotiert.
-- Pivot-Verkäufe und Menge für Laptop und Maus nach Datum SELECT p1.Date, p1.[Laptop] AS Laptop_Sales, p2.[Laptop] AS Laptop_Quantity, p1.[Mouse] AS Mouse_Sales, p2.[Mouse] AS Mouse_Quantity FROM ( -- Pivot für Verkäufe SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Sales FROM SalesData) AS source PIVOT (SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales ) p1 JOIN ( -- Pivot für Menge SELECT Date, [Laptop], [Mouse] FROM (SELECT Date, Product, Quantity FROM SalesData) AS source PIVOT (SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity ) p2 ON p1.Date = p2.Date;
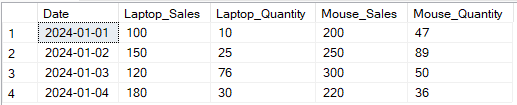
Beispielausgabe der Transformation mehrerer Spalten mit dem SQL PIVOT-Operator. Bild vom Autor.
Das Pivotieren mehrerer Spalten ermöglicht detailliertere Berichte, indem mehrere Attribute pro Artikel pivotiert werden, was reichhaltigere Einblicke ermöglicht. Die Syntax kann jedoch komplex sein, insbesondere wenn viele Spalten vorhanden sind. Hardcoding kann erforderlich sein, es sei denn, es wird mit dynamischen Pivot-Techniken kombiniert, was die Komplexität weiter erhöht.
Fazit
Das Pivotieren von Zeilen zu Spalten ist eine SQL-Technik, die es wert ist, erlernt zu werden. Ich habe gesehen, dass SQL-Pivot-Techniken verwendet werden, um eine Kohorten-Retentionstabelle zu erstellen, in der die Benutzerbindung über die Zeit verfolgt wird. Ich habe auch gesehen, dass SQL-Pivot-Techniken bei der Analyse von Umfragedaten verwendet werden, bei denen jede Zeile einen Befragten darstellt und jede Frage in ihre Spalte pivotiert werden kann.
Unser Reporting in SQL Kurs ist eine großartige Option, wenn Sie mehr über die Zusammenfassung und Aufbereitung von Daten für Präsentationen und/oder den Aufbau von Dashboards lernen möchten. Unsere Associate Data Analyst in SQL und Associate Data Engineer in SQL Karrierepfade sind eine weitere großartige Idee und bereichern jeden Lebenslauf, also melden Sie sich noch heute an.
Source:
https://www.datacamp.com/tutorial/sql-pivot-rows-to-columns