













I came across one of the test cases in my previous projects where I had to click on a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests hoping it would click the button and navigate to the next page.
Aber zu meiner Überraschung ist der Test gescheitert, weil er das Element nicht finden konnte, und ich habe NoSuchElementException in den Konsolenprotokollen erhalten. Das war nicht das, was ich sehen wollte, da es sich um einen einfachen Button handelte, den ich zu klicken versuchte, und es keine Komplexität gab.
Bei weiterer Analyse des Problems, Erweiterung des DOM und Überprüfung der Stammelemente, stellte ich fest, dass der Button-Locator innerhalb des #shadow-root(open) Knotens der Baumstruktur lag, was mich dazu brachte, zu erkennen, dass es anders behandelt werden muss, da es sich um ein Shadow DOM-Element handelt.
In diesem Selenium WebDriver-Tutorial werden wir Shadow DOM-Elemente diskutieren und erfahren, wie man Shadow DOM in Selenium WebDriver automatisieren kann. Bevor wir jedoch zur Automatisierung von Shadow DOM in Selenium übergehen, lassen Sie uns zunächst verstehen, was Shadow DOM ist. Und warum wird es verwendet?
Was ist Shadow DOM?
Shadow DOM ist eine Funktionalität, die es dem Webbrowser ermöglicht, DOM-Elemente ohne sie in den Hauptdokument-DOM-Baum einzubetten, zu rendern. Dies schafft eine Barriere zwischen dem, was der Entwickler und der Browser erreichen können; der Entwickler kann den Shadow DOM nicht auf die gleiche Weise erreichen, wie er es bei eingebetteten Elementen tun würde, während der Browser diesen Code auf die gleiche Weise rendern und ändern kann, wie er es bei eingebetteten Elementen tun würde.
Shadow DOM ist eine Möglichkeit zur Erreichung der Kapselung im HTML-Dokument. Durch die Implementierung können Sie den Stil und das Verhalten eines Teils des Dokuments verbergen und von dem anderen Code desselben Dokuments trennen, sodass keine Störung auftritt.
Shadow DOM ermöglicht es, versteckte DOM-Bäume an Elemente im regulären DOM-Baum anzuhängen – der Shadow DOM-Baum beginnt mit einem Shadow-Stamm, unter dem Sie Elemente auf die gleiche Weise wie im normalen DOM anhängen können.
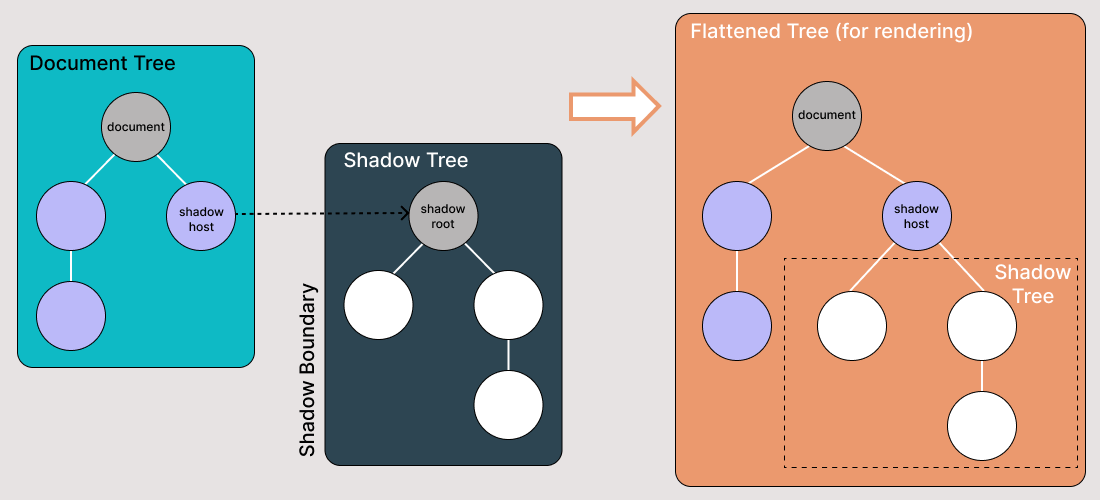
Es gibt einige Begriffe aus dem Bereich des Shadow DOM, die man kennen sollte:
- Shadow host: Der reguläre DOM-Knoten, an den das Shadow DOM angehängt ist
- Shadow tree: Der DOM-Baum innerhalb des Shadow DOM
- Die Schattenbegrenzung ist der Punkt, an dem das Shadow DOM endet und der reguläre DOM beginnt.
- Shadow root: Der Stammknoten des Shadow-Baums
Wofür wird das Shadow DOM verwendet?
Das Shadow DOM dient der Encapsulation. Es ermöglicht einem Komponenten, seinen eigenen „Schatten“-DOM-Baum zu haben, der nicht versehentlich vom Haupt-Dokument aus zugegriffen werden kann, lokale Stilregeln haben kann und mehr.
Hier sind einige der wichtigsten Eigenschaften des Shadow DOM:
- Haben ihre eigene ID-Raum
- Unsichtbar für JavaScript-Selektoren aus dem Haupt-Dokument, wie querySelector
- Verwenden Stile nur aus dem Schattenbaum, nicht aus dem Haupt-Dokument
Finden von Shadow DOM-Elementen mit Selenium WebDriver
Wenn wir versuchen, die Shadow DOM-Elemente mit Selenium Locatoren zu finden, erhalten wir NoSuchElementException, da es nicht direkt zugänglich für den DOM ist.
Wir würden die folgende Strategie verwenden, um auf die Shadow DOM-Locatoren zuzugreifen:
- Verwendung von JavaScriptExecutor.
- Verwendung der Methode
getShadowDom()von Selenium WebDriver.
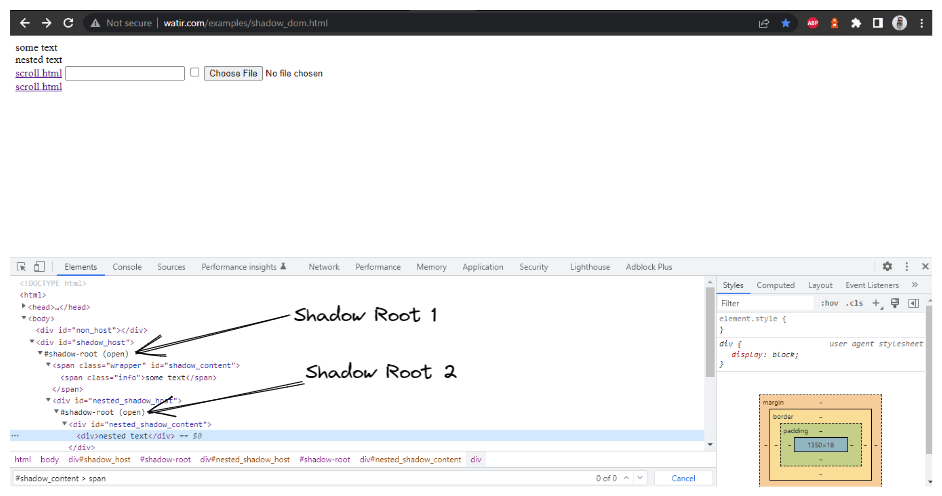
In diesem Blog-Abschnitt zur Automatisierung des Shadow DOM in Selenium nehmen wir als Beispiel die Startseite von Watir.com und versuchen, das Shadow DOM und das verschachtelte Shadow DOM-Text mit Selenium WebDriver zu überprüfen. Beachten Sie, dass es vor dem Erreichen des Textes -> einige Text ein Shadow-Root-Element gibt, und es sind zwei Shadow-Root-Elemente, bevor wir den Text -> verschachtelter Text erreichen.
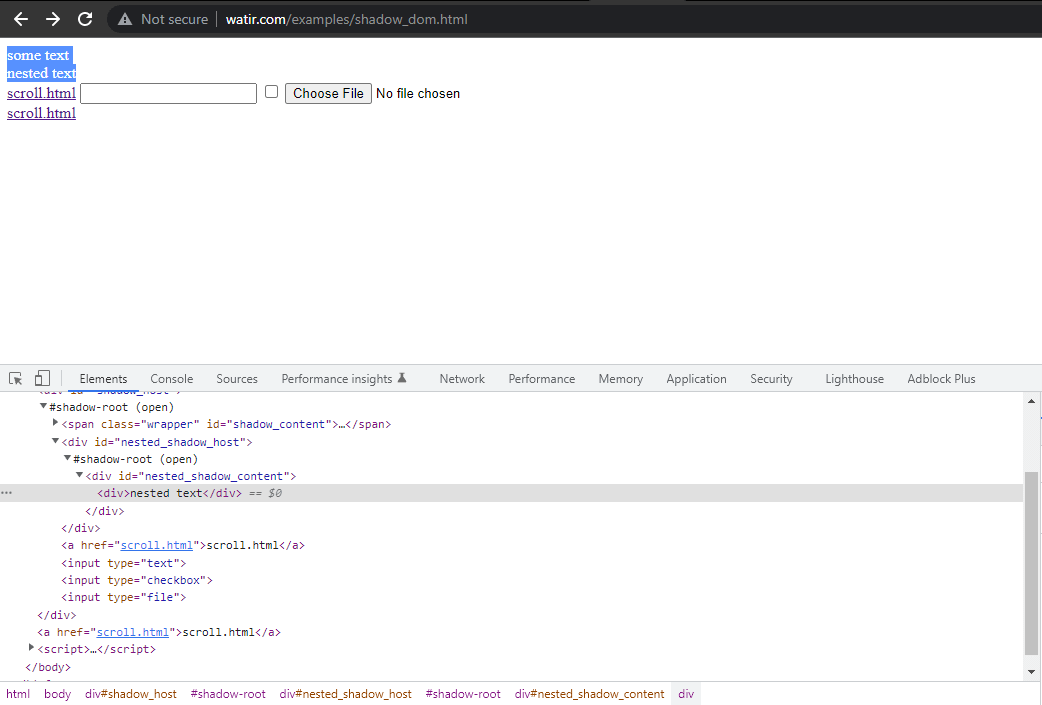
Wenn wir nun versuchen, das Element mithilfe des cssSelector("#shadow_content > span") zu lokalisieren, wird es
nicht gefunden, und Selenium WebDriver wird eine NoSuchElementException auslösen.
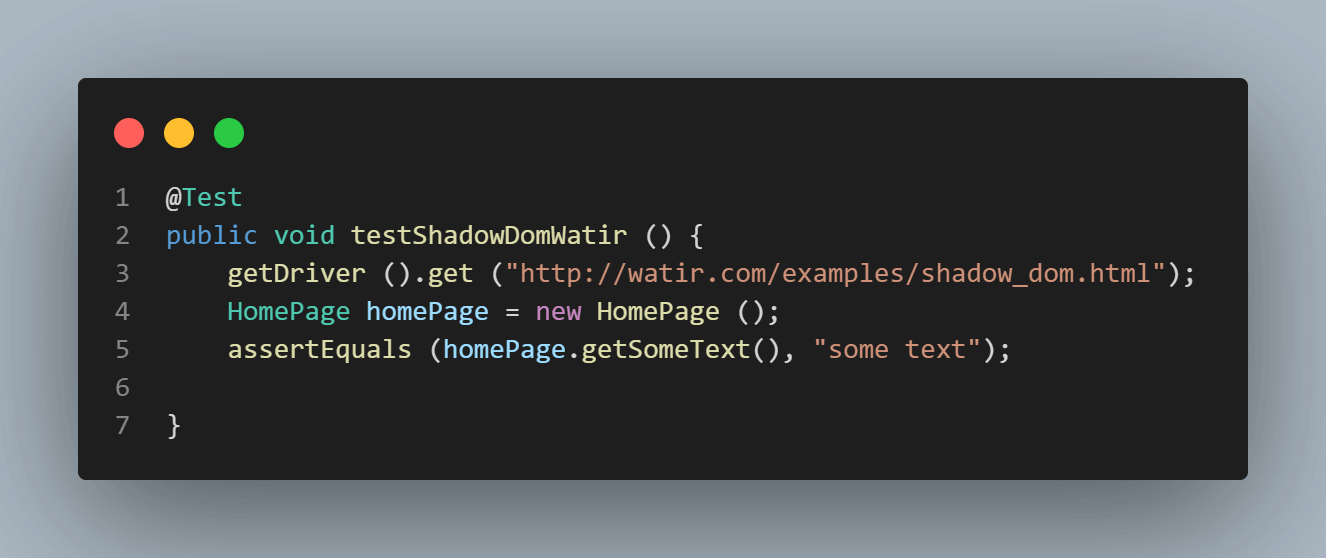
Hier ist ein Screenshot der Homepage-Klasse, die versucht, Text mithilfe von
cssSelector(„#shadow_content > span“) zu erhalten.

Hier ist ein Screenshot der Tests, bei denen wir versuchen, den Text(„einige Text“) zu überprüfen.
Fehler beim Ausführen der Tests zeigt NoSuchElementException
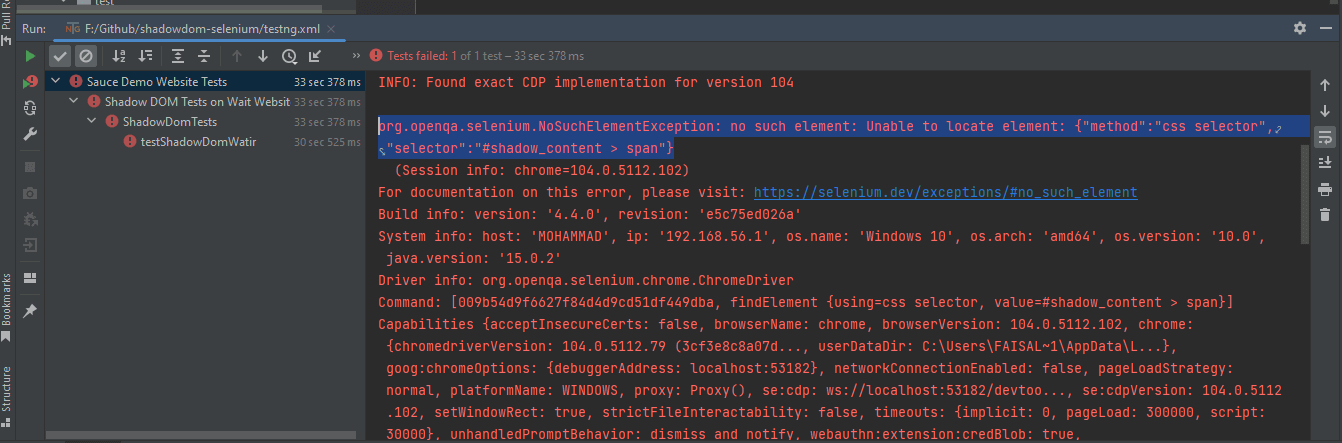
Um das Element für den Text korrekt zu lokalisieren, müssen wir durch die Shadow-Root-Elemente gehen. Erst dann können wir „einige Text“ und „verschachtelter Text“ auf der Seite lokalisieren?
So finden Sie das Shadow DOM in Selenium WebDriver mit der Methode ‘getShadowDom’
Mit der Veröffentlichung von Selenium WebDriver-Version 4.0.0 und höher wurde die getShadowRoot() Methode eingeführt und half dabei, Shadow-Root-Elemente zu lokalisieren.
Hier sind die Syntax und Details der Methode getShadowRoot():
default SearchContext getShadowRoot()
Returns:
The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component.
Throws:
NoSuchShadowRootException - If shadow root is not found.Laut der Dokumentation gibt die Methode getShadowRoot() eine Darstellung des Schatten-Stamms eines Elements zurück, um den Shadow DOM eines Web-Komponenten zugreifen zu können.
Falls der Schatten-Stamm nicht gefunden wird, wird eine NoSuchShadowRootException ausgelöst.
Bevor wir anfangen, die Tests zu schreiben und den Code zu diskutieren, lass mich dir die Werkzeuge erklären, die wir zum Schreiben und Ausführen der Tests verwenden werden:
Die folgenden Programmiersprachen und Werkzeuge wurden zum Schreiben und Ausführen der Tests verwendet:
- Programmiersprache: Java 11
- Web-Automatisierungstool: Selenium WebDriver
- Testrunner: TestNG
- Build-Tool: Maven
- Cloud-Plattform: LambdaTest
Erste Schritte mit dem Finden des Shadow DOM in Selenium WebDriver
Wie zuvor besprochen, wurde dieses Projekt zum Shadow DOM in Selenium mit Maven erstellt. TestNG wird als Testrunner verwendet. Um mehr über Maven zu erfahren, können Sie diesen Blogbeitrag über den Einstieg in Maven für Selenium-Tests lesen.
Sobald das Projekt erstellt ist, müssen wir die Abhängigkeiten für Selenium WebDriver und TestNG im pom.xml-Datei hinzufügen.
Versionen der Abhängigkeiten sind in einem separaten Eigenschaftenblock festgelegt. Dies wird zur Wartbarkeit getan, damit wir die Versionen leicht aktualisieren können, ohne die Abhängigkeit in der gesamten pom.xml-Datei suchen zu müssen.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>io.github.mfaisalkhatri</groupId>
<artifactId>shadowdom-selenium</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<selenium.java.version>4.4.0</selenium.java.version>
<testng.version>7.6.1</testng.version>
<webdrivermanager.version>5.2.1</webdrivermanager.version>
<maven.compiler.version>3.10.1</maven.compiler.version>
<surefire-version>3.0.0-M7</surefire-version>
<java.release.version>11</java.release.version>
<maven.source.encoding>UTF-8</maven.source.encoding>
<suite-xml>testng.xml</suite-xml>
<argLine>-Dfile.encoding=UTF-8 -Xdebug -Xnoagent</argLine>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.java.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.testng/testng -->
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>${testng.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>${webdrivermanager.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.release.version}</release>
<encoding>${maven.source.encoding}</encoding>
<forceJavacCompilerUse>true</forceJavacCompilerUse>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-version}</version>
<executions>
<execution>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
<properties>
<property>
<name>usedefaultlisteners</name>
<value>false</value>
</property>
</properties>
<suiteXmlFiles>
<suiteXmlFile>${suite-xml}</suiteXmlFile>
</suiteXmlFiles>
<argLine>${argLine}</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project>Lassen Sie uns nun zum Code übergehen; das Seitenobjektmodell (POM) wurde in diesem Projekt verwendet, da es dazu beiträgt, Code-Duplizierung zu reduzieren und die Wartung von Testfällen zu verbessern.
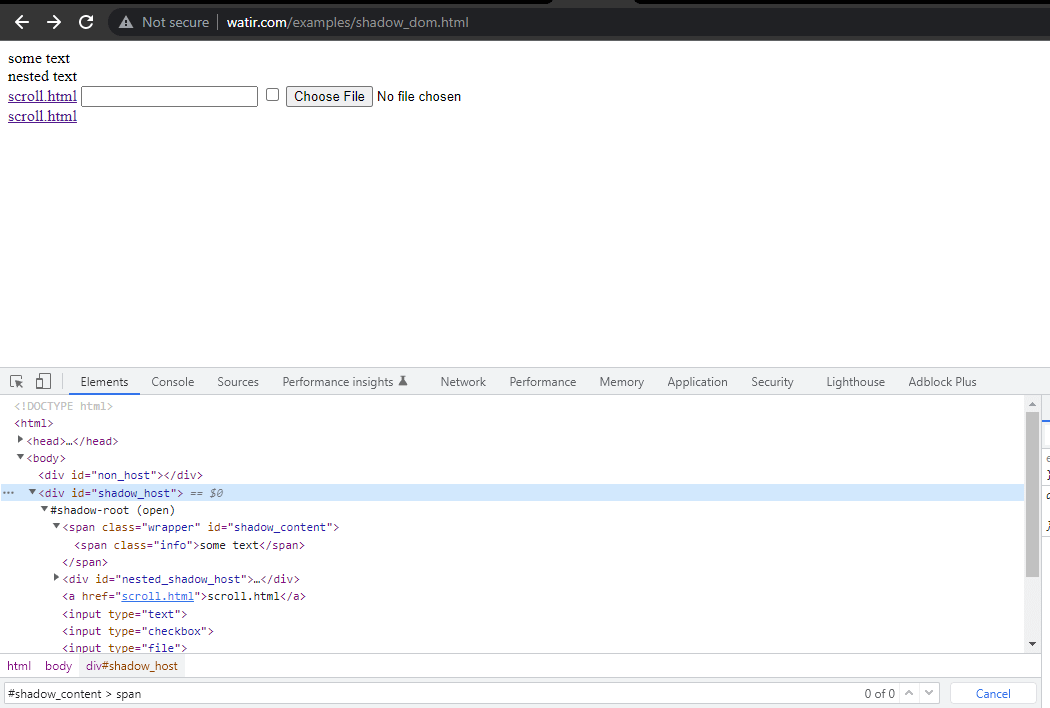
Zuerst würden wir den Locator für „some text“ und „nested text“ auf der Startseite finden.
public class HomePage {
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
public String getSomeText () {
return getDriver ().findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
}
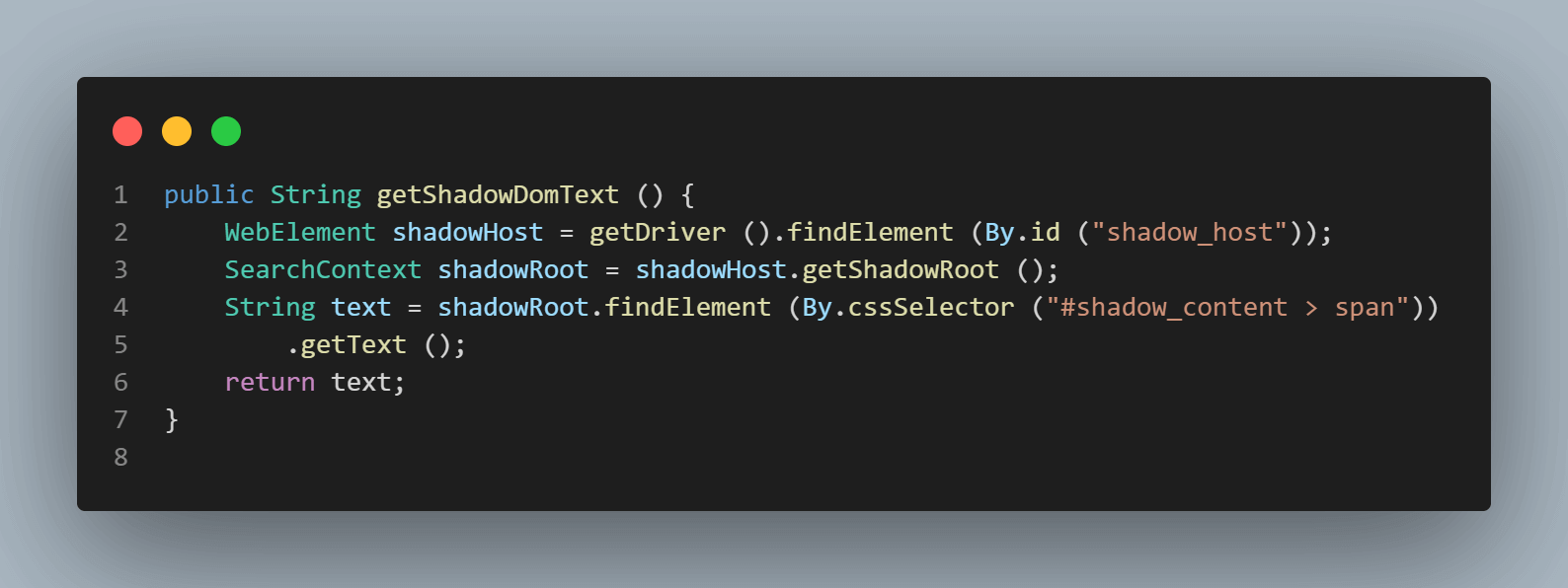
public String getShadowDomText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();
return text;
}
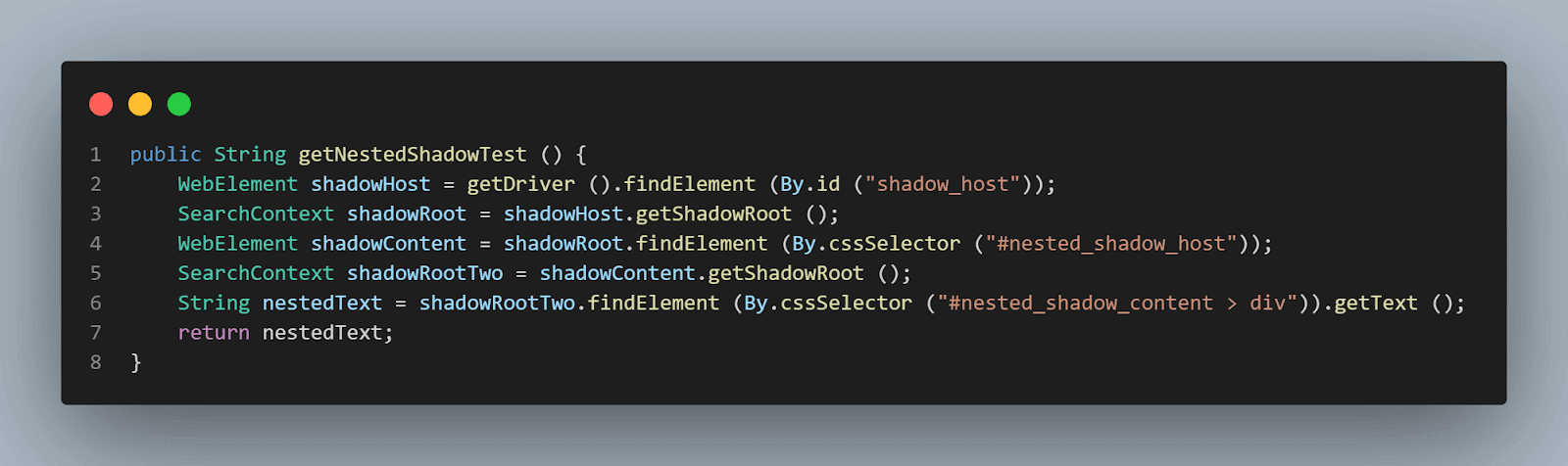
public String getNestedShadowText () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText ();
return nestedText;
}
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host")).getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}
public String getNestedTextUsingJSExecutor () {
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);
return shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();
}
}Code Walkthrough
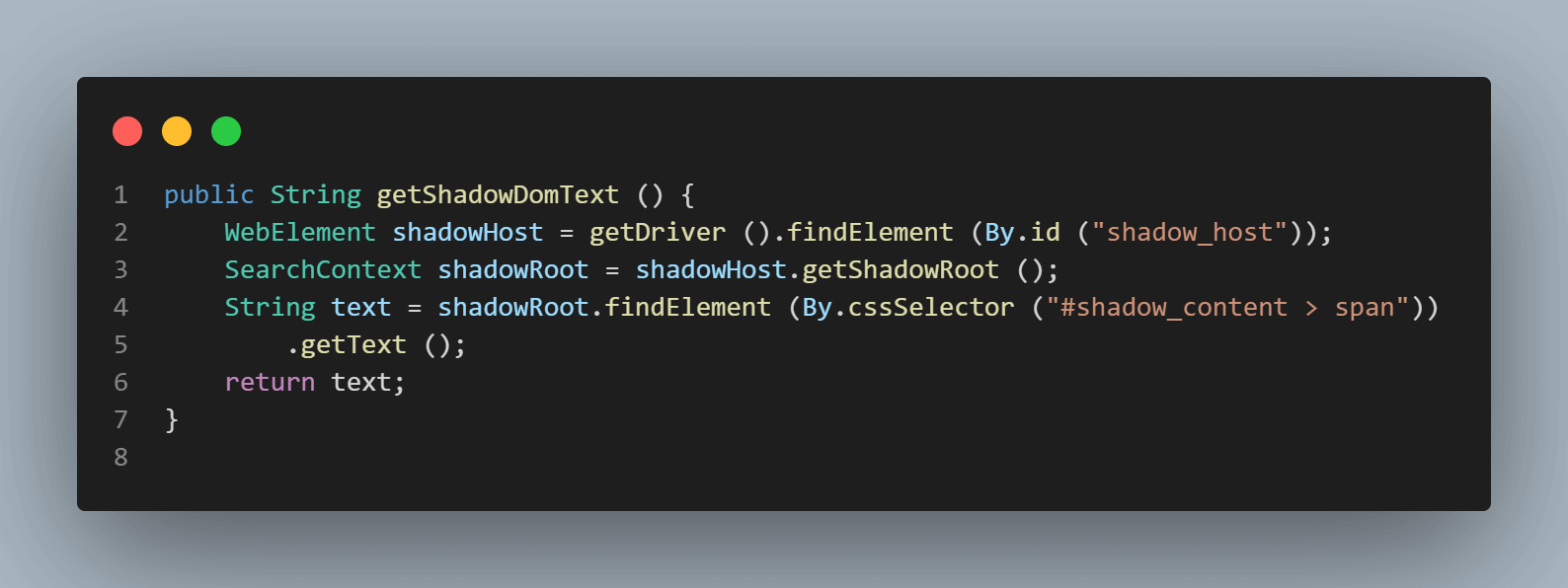
Das erste Element, das wir im < div id = "shadow_host" > durch Verwendung der Locatorstrategie – id.
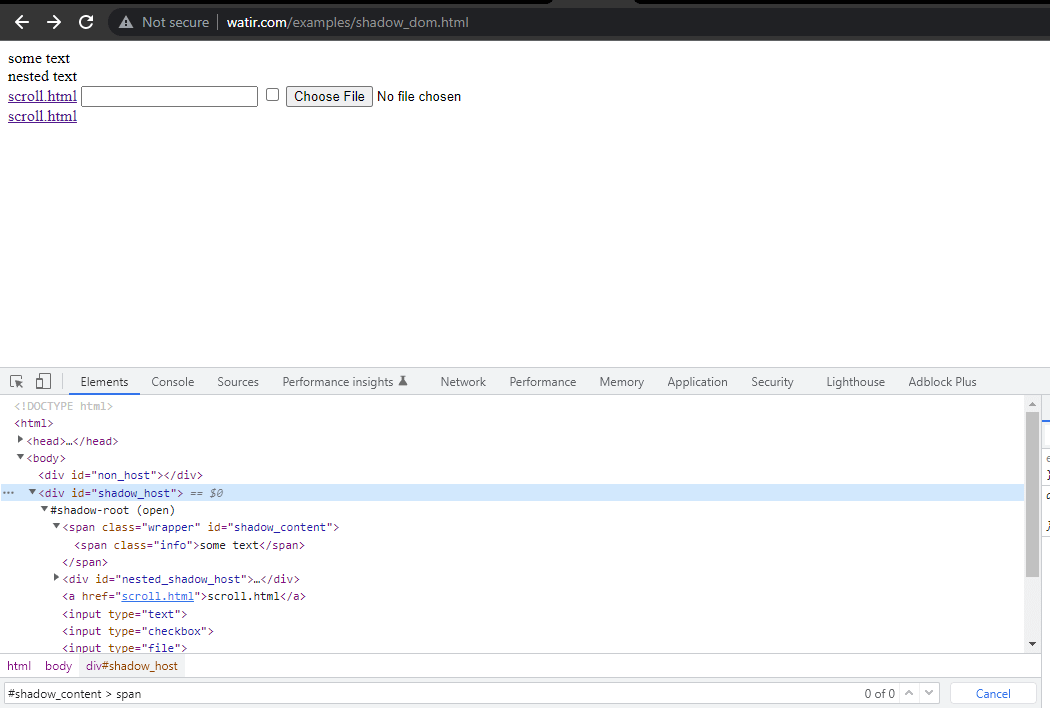
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Als nächstes suchen wir nach dem ersten Shadow Root im DOM daneben. Dafür haben wir das SearchContext-Interface verwendet. Der Shadow Root wird mit der Methode getShadowRoot() zurückgegeben. Wenn Sie das obige Screenshot überprüfen, #shadow-root (open), ist es neben dem < div id = "shadow_host" >.
Um den Text – „some text,“ zu lokalisieren, gibt es nur ein Shadow DOM-Element, das wir durchgehen müssen.
Die folgende Codezeile hilft uns, das Shadow Root-Element zu erhalten.
SearchContext shadowRoot = downloadsManager.getShadowRoot();Sobald das Shadow Root gefunden ist, können wir nach dem Element suchen, um den Text – „some text“ – zu lokalisieren. Die folgende Codezeile hilft uns, den Text zu erhalten:
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span"))
.getText ();Als Nächstes finden wir den Locator für “nested text,”, der ein eingebettetes Shadow-root-Element enthält, und erfahren, wie man sein Element lokalisieren kann.
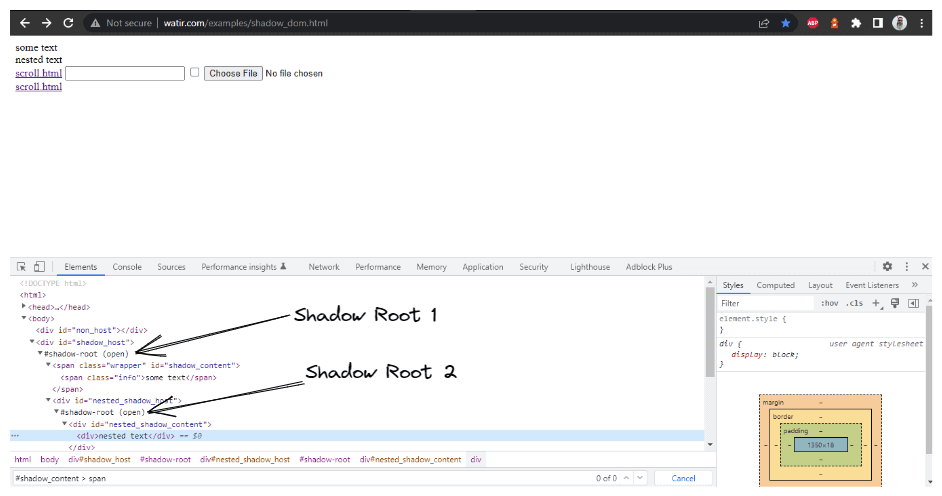
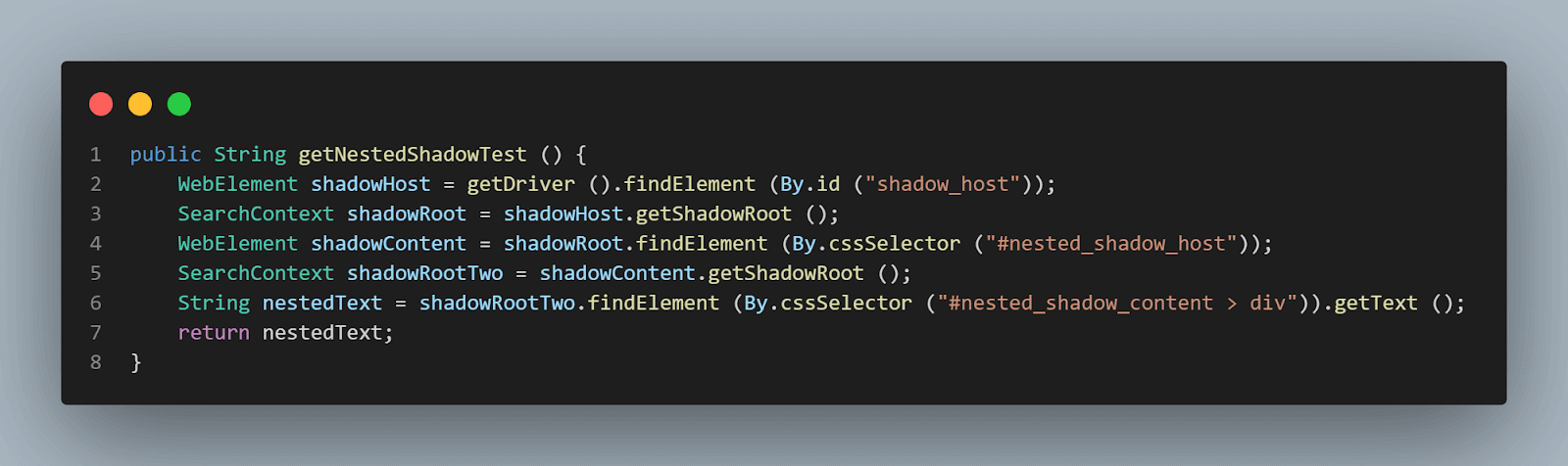
getNestedShadowText() Methode:
Beginnend von oben, wie im vorherigen Abschnitt besprochen, müssen wir das Element < div id = "shadow_host" > mithilfe der Locator-Strategie – id finden.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));Danach müssen wir das Shadow Root Element mithilfe der getShadowRoot() Methode finden; sobald wir das Shadow Root Element erhalten, müssen wir beginnen, das zweite Shadow Root zu finden, indem wir cssSelector für die Lokalisierung verwenden:
<div id ="nested_shadow_host">
SearchContext shadowRoot = shadowHost.getShadowRoot ();
WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host"));Als nächstes müssen wir das zweite Shadow Root Element mithilfe der getShadowRoot() Methode finden. Schließlich ist es an der Zeit, das tatsächliche Element für das Abrufen des Textes – “nested text.”
Die folgende Codezeile hilft uns bei der Lokalisierung des Textes:
SearchContext shadowRootTwo = shadowContent.getShadowRoot ();
String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"Schreiben des Codes in einer fließenden Weise
Im obigen Abschnitt dieses Blogs über Shadow DOM in Selenium haben wir einen langen Weg gesehen, von dem aus wir das tatsächliche Element finden müssen, mit dem wir arbeiten möchten, und wir müssen mehrere Initialisierungen der WebElement und SearchContext Schnittstellen durchführen und mehrere Codezeilen schreiben, um ein einzelnes Element zum Arbeiten zu finden.
Wir haben auch eine fließende Art des Schreibens dieses gesamten Codes, und so können Sie das tun:
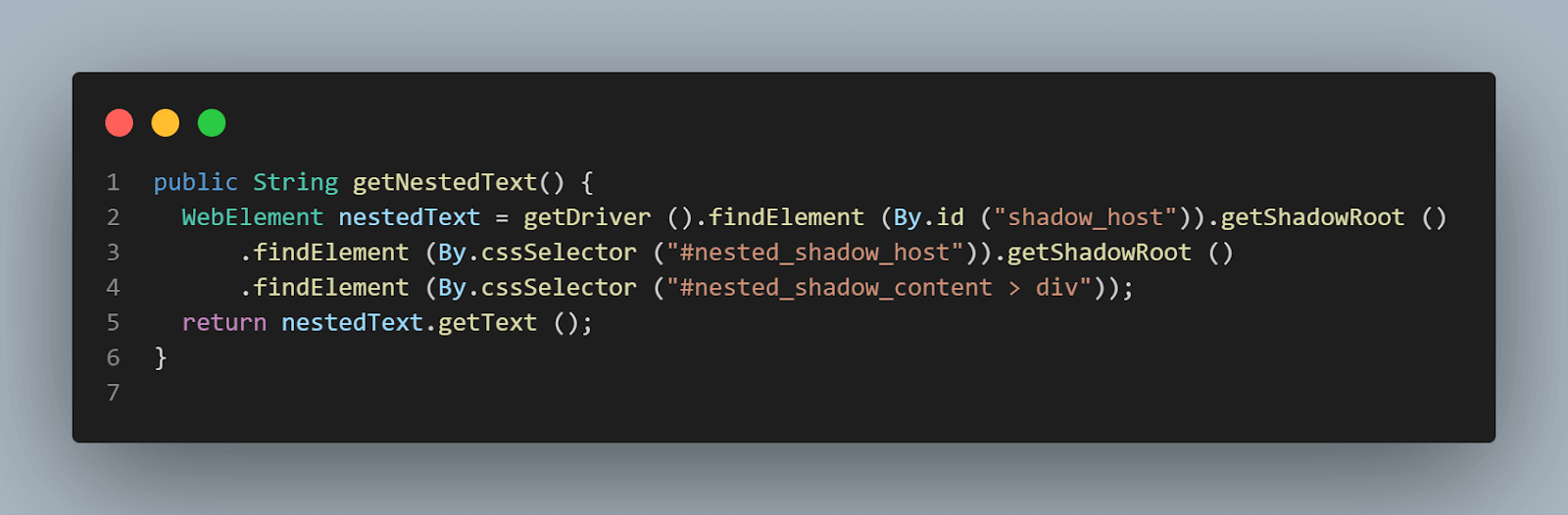
public String getNestedText() {
WebElement nestedText = getDriver ().findElement (By.id ("shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_host"))
.getShadowRoot ()
.findElement (By.cssSelector ("#nested_shadow_content > div"));
return nestedText.getText ();
}Die Design-Philosophie des Fluent Interface beruht stark auf der Methode der Methodenkette. Das Fluent Interface-Muster hilft uns, Code zu schreiben, der leicht lesbar ist und ohne technisches Verständnis des Codes verstanden werden kann. Dieser Begriff wurde erstmals im Jahr 2005 von Eric Evans und Martin Fowler geprägt.
Dies ist eine Methode der Verkettung, die wir zur Lokalisierung des Elements durchführen würden.
Dieser Code führt die gleiche Aktion wie in den obigen Schritten durch.
- Zuerst würden wir das Element shadow_host anhand seiner ID lokalisieren, anschließend würden wir das Shadow Root-Element mithilfe der Methode
getShadowRoot()abrufen. - Als Nächstes würden wir nach dem Element nested_shadow_host mithilfe des CSS-Selektors suchen und das Shadow Root-Element mithilfe der Methode
getShadowRoot()abrufen. - Schließlich würden wir den Text „nested text“ mithilfe des CSS-Selektors – nested_shadow_content > div – abrufen.
So finden Sie Shadow DOM in Selenium mit JavaScriptExecutor
In den obigen Codebeispielen haben wir Elemente mithilfe der Methode getShadowRoot() lokalisiert. Schauen wir uns nun an, wie wir Shadow Root-Elemente mithilfe von JavaScriptExecutor in Selenium WebDriver lokalisieren können.
getNestedTextUsingJSExecutor() Methode wurde innerhalb der HomePage-Klasse erstellt,
wo wir das Shadow Root-Element basierend auf dem WebElement erweitern, das wir im Parameter übergeben. Im DOM (wie im Screenshot oben gezeigt) haben wir festgestellt, dass wir zwei Shadow Root-Elemente erweitern müssen, bevor wir zum tatsächlichen Locator für das Abrufen des Textes kommen – verschachtelter Text. Daher wurde die expandRootElement() Methode erstellt, anstatt den gleichen JavaScript-Executor-Code jedes Mal zu kopieren.
Wir würden die SearchContext-Schnittstelle implementieren, die uns bei JavaScriptExecutor hilft und das Shadow Root-Element basierend auf dem WebElement zurückgibt, das wir im Parameter übergeben.
public SearchContext expandRootElement (WebElement element) {
SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript (
"return arguments[0].shadowRoot", element);
return shadowRoot;
}
getNestedTextUsingJSExecutor() Methode
Das erste Element, das wir lokalisieren würden, ist das < div id = "shadow_host" > unter Verwendung der Suchstrategie – id.
Als nächstes würden wir das Root-Element basierend auf dem gesuchten shadow_host-WebElement erweitern.
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host"));
SearchContext shadowRootOne = expandRootElement (shadowHost);Nachdem das Shadow Root erweitert wurde, können wir nach einem anderen WebElement suchen, indem wir cssSelector verwenden, um zu lokalisieren:
<div id ="nested_shadow_host">
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host"));
SearchContext shadowRootTwo = expandRootElement (nestedShadowHost);Schließlich ist es jetzt an der Zeit, das tatsächliche Element für das Abrufen des Textes zu lokalisieren – “verschachtelter Text.”
Die folgende Codezeile hilft uns dabei, den Text zu lokalisieren:
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div"))
.getText ();Demonstration
In diesem Abschnitt des Artikels über Shadow DOM in Selenium schreiben wir schnell einen Test und überprüfen, ob die Locators, die wir in den vorherigen Schritten gefunden haben, uns den erforderlichen Text liefern. Wir können Assertions auf den geschriebenen Code ausführen, um zu verifizieren, dass das, was wir vom Code erwarten, funktioniert.
@Test
public void testShadowDomWatir () {
getDriver ().get ("http://watir.com/examples/shadow_dom.html");
HomePage homePage = new HomePage ();
// assertEquals (homePage.getSomeText(), "some text");
assertEquals (homePage.getShadowDomText (), "some text");
assertEquals (homePage.getNestedShadowText (),"nested text");
assertEquals (homePage.getNestedText (), "nested text");
assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text");
}Dies ist nur ein einfacher Test, um zu bestätigen, dass die Texte korrekt wie erwartet angezeigt werden. Wir würden das mit der assertEquals() Assertion in TestNG überprüfen.
Im tatsächlichen Wert würden wir die gerade geschriebene Methode zur Texterfassung von der Seite bereitstellen, und im erwarteten Wert würden wir den Text “some text” oder “nested text,” je nach den getätigten Assertions übergeben.
Es werden vier assertEquals-Anweisungen im Test bereitgestellt.
- Überprüfung des Shadow DOM-Elements mithilfe der
getShadowRoot()Methode:
- Überprüfung des verschachtelten Shadow DOM-Elements mithilfe der
getShadowRoot()Methode:
- Überprüfung des verschachtelten Shadow DOM-Elements mithilfe der
getShadowRoot()Methode und flüssiges Schreiben:
Ausführung
Es gibt zwei Möglichkeiten, die Tests zur Automatisierung des Shadow DOM in Selenium auszuführen:
- Vom IDE mithilfe von TestNG
- Vom CLI mithilfe von Maven
Automatisierung des Shadow DOM in Selenium WebDriver unter Verwendung von TestNG
TestNG wird als Testlaufsteuerung verwendet. Daher wurde testng.xml erstellt, mit dem wir die Tests durch Rechtsklick auf die Datei und Auswahl der Option Run ‘…\testng.xml’ ausführen. Bevor wir die Tests ausführen, müssen wir jedoch den LambdaTest-Benutzernamen und den Zugriffsschlüssel in den Laufzeitkonfigurationen hinzufügen, da wir den Benutzernamen und den Zugriffsschlüssel aus der Systemeigenschaft lesen.
LambdaTest bietet Cross-Browser-Tests auf einem Online-Browser-Farm von über 3000 echten Browsern und Betriebssystemen, um Ihnen zu helfen, Java-Tests sowohl lokal als auch/oder in der Cloud auszuführen. Sie können Ihre Selenium-Tests mit Java beschleunigen und die Testausführungszeit durch mehrfache parallele Tests auf verschiedenen Browsern und Betriebssystemkonfigurationen verringern.
- Fügen Sie die Werte in der Laufzeitkonfiguration wie folgt hinzu:
- Dusername =
< LambdaTest username > - DaccessKey =
< LambdaTest access key >
- Dusername =
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Sauce Demo Website Tests">
<test name="Shadow DOM Tests on Watir Website">
<parameter name="browser" value="remote-chrome"/>
<classes>
<class name="ShadowDomTests">
<methods>
<include name="testShadowDomWatir"/>
</methods>
</class>
</classes>
</test> <!-- Test -->
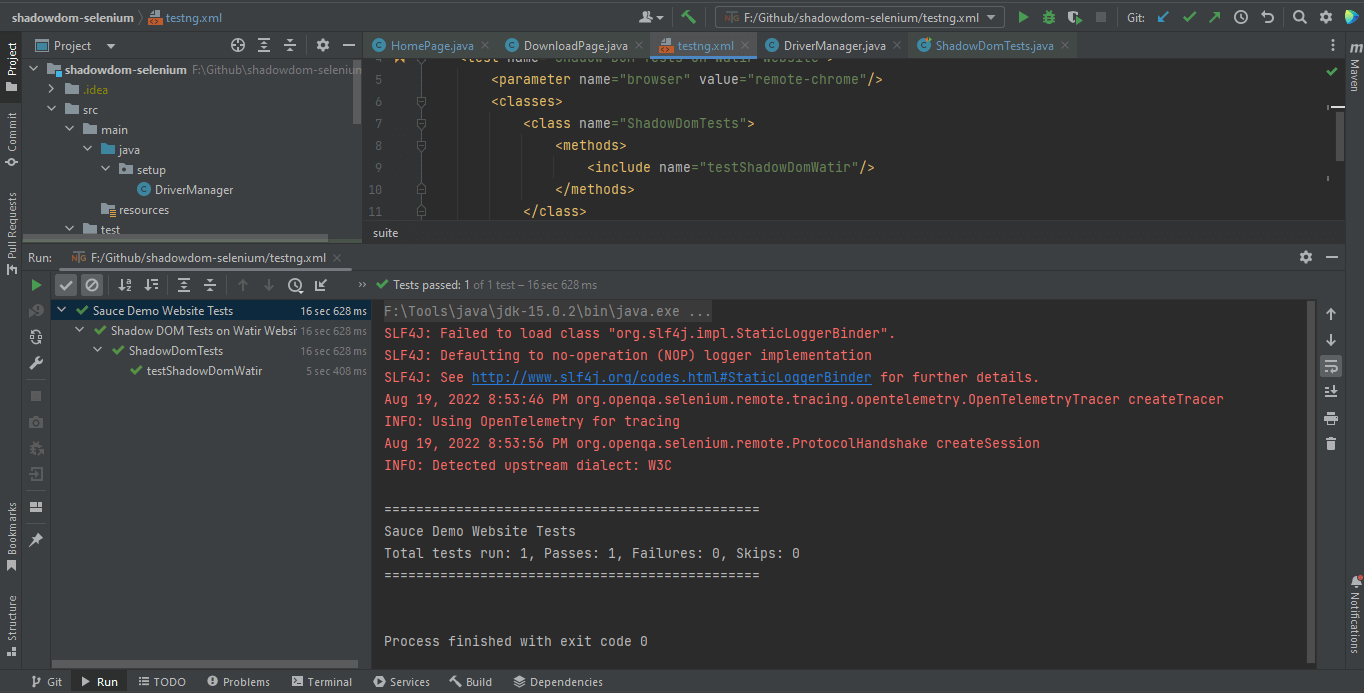
</suite>Hier ist ein Screenshot des lokalen Testlaufs für Shadow DOM in Selenium unter Verwendung von Intellij IDE.
Automatisieren von Shadow DOM in Selenium WebDriver mit Maven
Um die Tests mit Maven auszuführen, müssen die folgenden Schritte ausgeführt werden, um Shadow DOM in Selenium zu automatisieren:
- Öffnen Sie das Kommandozeilenfenster/Terminal.
- Navigieren Sie zum Stammverzeichnis des Projekts.
- Geben Sie den Befehl ein:
mvn clean install -Dusername=< LambdaTest username > -DaccessKey=< LambdaTest accessKey >.
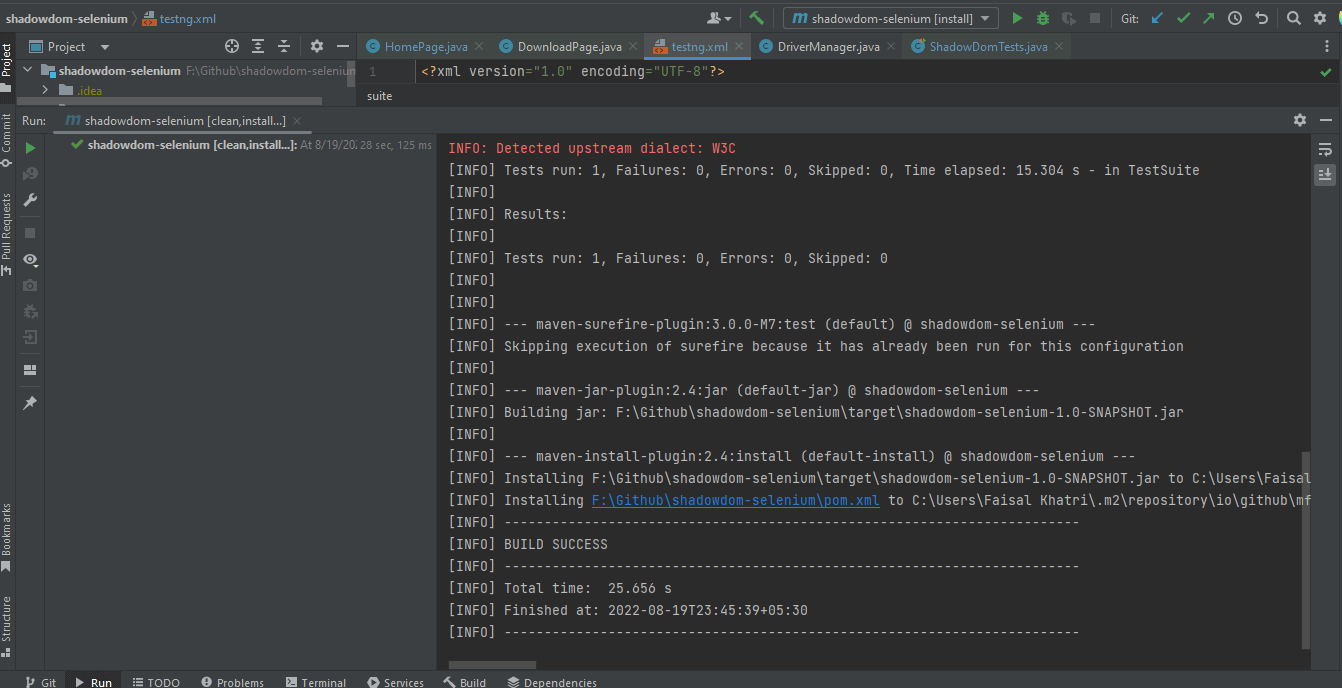
Folgendes ist ein Screenshot von IntelliJ, der den Ausführungsstatus der Tests mit Maven zeigt:
Sobald die Tests erfolgreich ausgeführt wurden, können wir das LambdaTest-Dashboard überprüfen und alle Videobearbeitungen, Screenshots, Gerätelogs und schrittweise detaillierte Informationen zum Testlauf ansehen. Schauen Sie sich die untenstehenden Screenshots an, die Ihnen einen guten Eindruck vom Dashboard für automatisierte App-Tests geben.
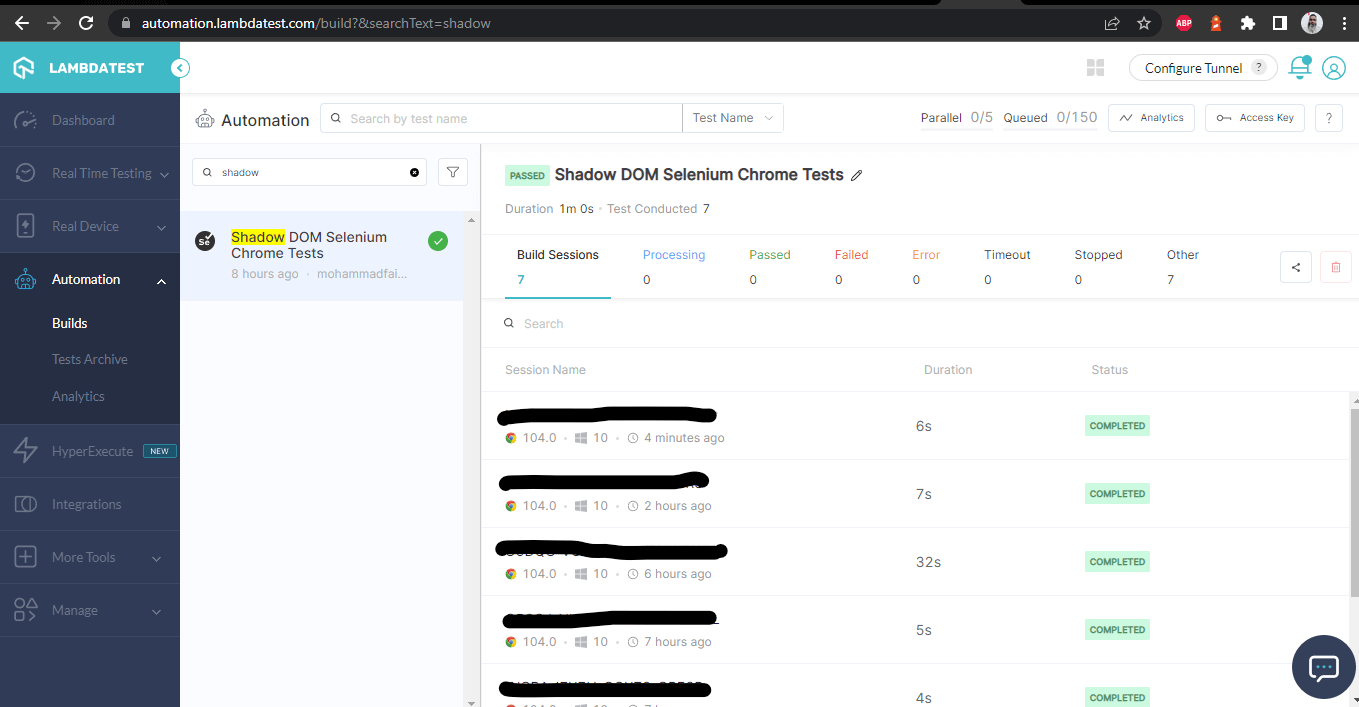 LambdaTest Dashboard
LambdaTest Dashboard
Die folgenden Screenshots zeigen die Details des Builds und der Tests, die zur Automatisierung von Shadow DOM in Selenium durchgeführt wurden. Wiederum sind der Testname, der Browsername, die Browserversion, der Betriebssystemname, die jeweilige Betriebssystemversion und die Bildschirmauflösung für jeden Test korrekt sichtbar.
Es enthält auch das Video des durchgeführten Tests, was einen besseren Eindruck davon vermittelt, wie die Tests auf dem Gerät ausgeführt wurden.
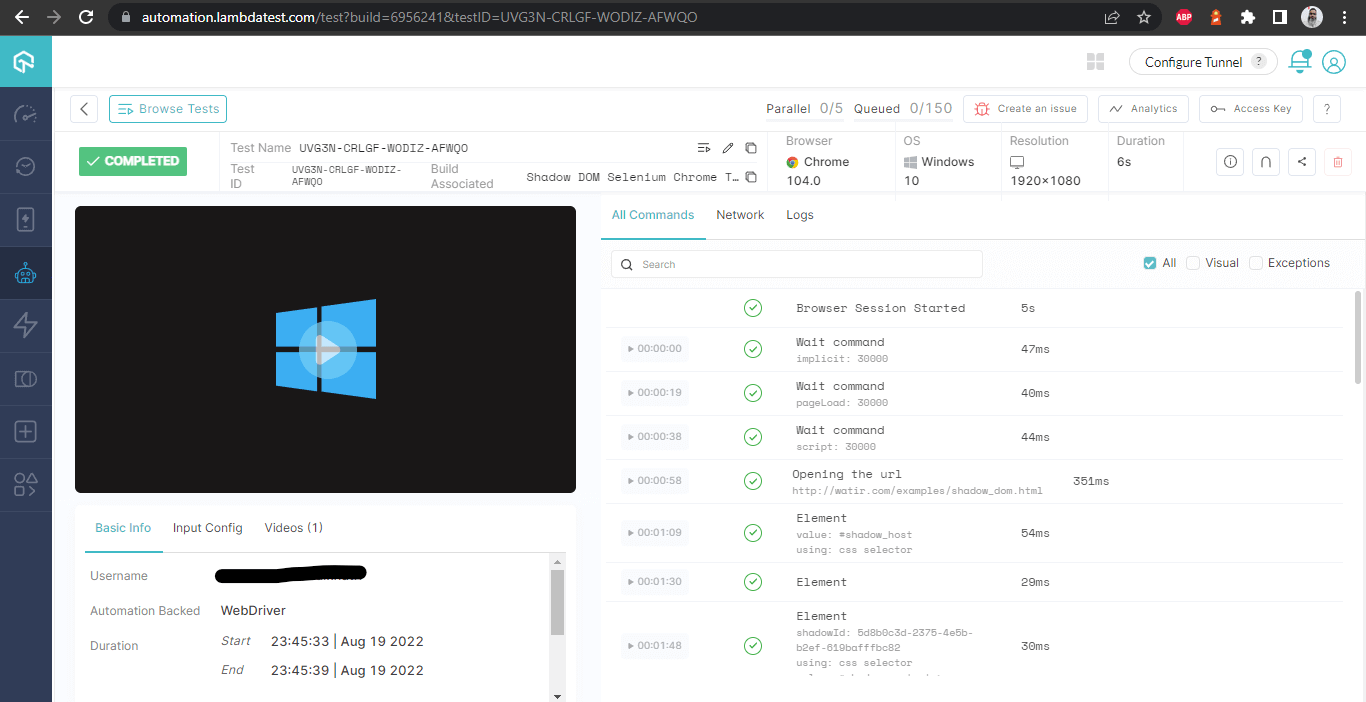 Build Details
Build Details
Diese Ansicht zeigt alle Metriken im Detail, die aus Sicht des Tester sehr hilfreich sind, um zu überprüfen, welcher Test auf welchem Browser ausgeführt wurde und entsprechend die Logs für die Automatisierung von Shadow DOM in Selenium anzuzeigen.
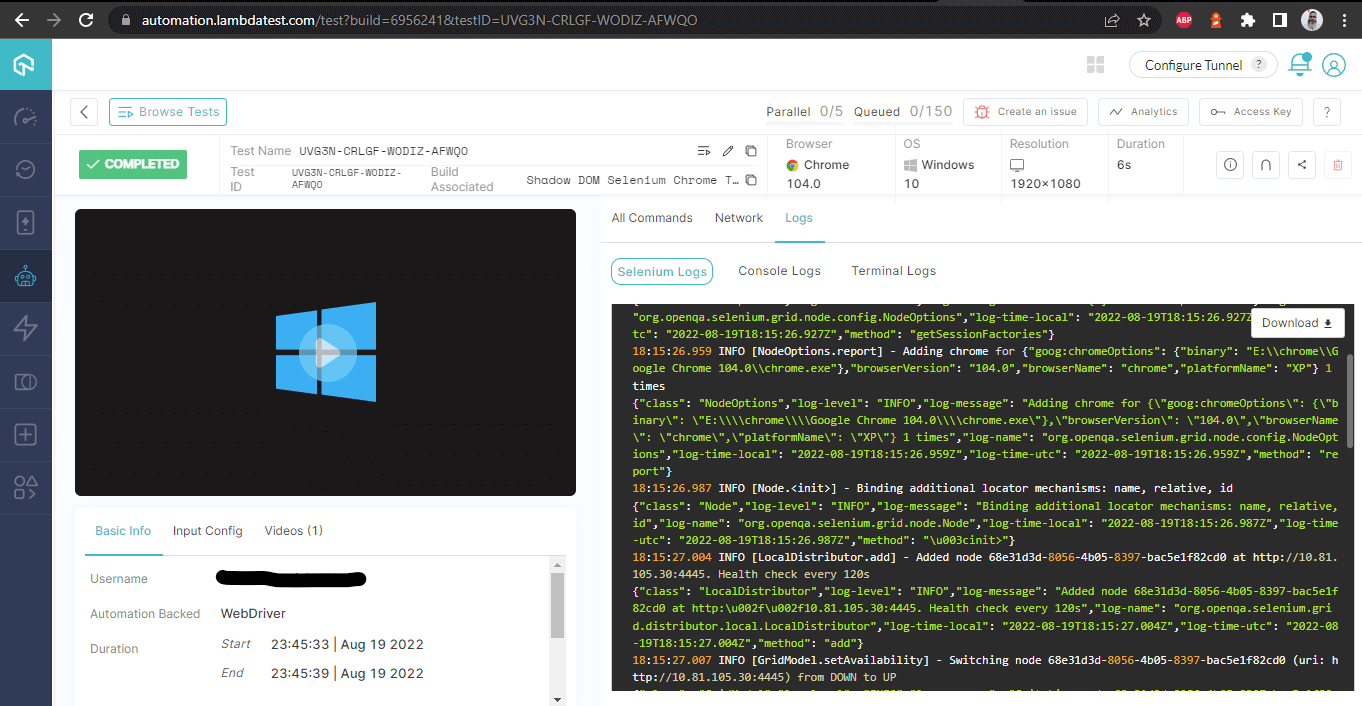 Baubeschreibungen – mit Protokollen
Baubeschreibungen – mit Protokollen
Sie können die neuesten Testresultate, deren Status und die Gesamtzahl der bestandenen oder nicht bestandenen Tests im LambdaTest Analytics Dashboard einsehen. Darüber hinaus können Sie Screenshots von kürzlich ausgeführten Testläufen im Abschnitt Testübersicht sehen.
Schlussfolgerung
In diesem Blogbeitrag über die Automatisierung des Shadow DOM in Selenium haben wir besprochen, wie man Shadow DOM-Elemente findet und sie mit der Methode getShadowRoot() automatisieren kann, die in der Version 4.0.0 und höher von Selenium WebDriver eingeführt wurde.
Wir haben auch besprochen, wie man Shadow DOM-Elemente mit JavaScriptExecutor in Selenium WebDriver lokalisiert und automatisieren kann und die Tests auf der Plattform von LambdaTest ausführt, die genaue Details der durchgeführten Tests mit Selenium WebDriver-Protokollen zeigt.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM elements using Selenium WebDriver.
Viel Erfolg beim Testen!
Source:
https://dzone.com/articles/how-to-automate-shadow-dom-in-selenium-webdriver