













引言
在數據科學,特別是自然語言處理領域,浓缩一直是深受關注的课题。雖然文本浓缩方法已經存在一段時間,但近年來自然語言處理和深度學習的發展中有顯著進步。在浓缩領域,如同最近的ChatGPT,網絡巨頭们纷纷发表相關研究論文。儘管對這個研究领域做了大量工作,但關於AI驅動浓缩的實際實施的讨论卻非常有限。解析廣泛而笼統的陈述的困難是有效浓缩的障礙。
浓缩新聞文章和財務报告会是一项不同的任務。當處理文本特徵在長度或主題上有所不同(如技術、運動、財務、旅行等)時,浓缩變得是一個具有挑戰性的數據科學工作。在深入了解應用之前,先掌握浓缩理論的基本知識是至關重要的。
抽取式浓缩
抽取式摘要的過程涉及從文章中選擇最相關的句子並系統性地組織它們。摘要在很大程度上取自原始材料,並照搬原文。
目前的抽取式摘要在三個基本操作周围圍繞:
建立輸入文本的中表示
topic representation 和 indicator representation 是表示基礎方法 exemplars。為了理解文中提及的主題,topic representation將文本轉換為中表示。
根據表示對句子進行評分
在生成中表示的时候,每個句子都被授予一個重要性得分。當使用topic representation的相關方法時,句子的得分反映了它如何有效地阐明文中的关键技术概念。在 indicator representation 中,得分是通過聚合不同加權指標的證據來計算的。
選擇包括數句摘要的方法
為了產生摘要,摘要在 bottleneck 階段會選擇 top-k 的重要句子。例如,有些方法使用贪心算法來挑選最具相關性的句子,而其它的方法可能將句子選擇問題轉化為優化問題,選擇一個句子集合,在滿足總體重要性和连贯性最大化的同時,冗餘信息的量化最小化。
我們來深入探讨一下前面提到的方法:
主題表示方法
主題詞:使用這種方法,可以在輸入文件中找到與主題相關的詞彙。句子的重要性可以通過兩種方式計算:第一種是根據它包含的主題签名數量;第二種是根據它含蓋的主題签名比例。
頻率驅動的方法的: 透過這種方法,給予詞語相對重要性。如果詞語符合主題,則獲得1分;否則,達到零分。取決於實現方式,權重可能會是連續的。主題表示可以透過兩種方法之一来实现:
詞語機率:它只取詞語的頻率來表示其重要性。計算詞語 w 的可能性時,我們將其出現的頻率 f(w) 除以詞語總數 N。
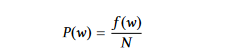
使用詞語機率,句子中詞語的平均重要性给予了句子的重要性。
TFIDF(詞語頻率反文档頻率): 此方法是在詞語機率方法上的提升。在這裡,權重是通過使用TF-IDF方法來確定。詞語頻率反文档頻率(TFIDF)技術給予经常出現在大部分文件中的詞語較少的重要性。 document d 中每個詞語 w 的權重如下計算:
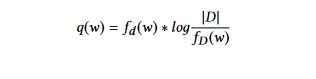
其中 fd (w) 是詞語 w 在文件 d 中的詞頻,fD (w) 是包含詞語 w 的文件數量,而 |D| 是集合 D 中文件的數量。
潛在語義分析: 潛在語義分析(LSA)是一種無監督方法,用於根據觀察到的詞語提取文本語義的表示。LSA過程從建立一個詞語-句子矩陣(n 由 m 構成)開始,其中每一行代表輸入中的一個詞語(n個詞語),每一列代表一個句子(m個句子)。在矩陣中,詞語i在句子j中的權重由項目aij定義。根據TFIDF技術,句中的一個詞語被授予某種權重,未包含在句子中的詞語則分配零值。
指標表示方法
圖基方法
圖形方法受到PageRank算法的影响,將文件表示為一個連通圖。句子形成圖的頂點,而連接句子的邊則顯示兩個句子之間的相關性程度。 linking two vertices is to assess the degree to which two sentences are similar, and if the degree of similarity is higher than a certain threshold, the vertices are connected. 這種圖表示法可能出現兩種結果。首先,圖的分區(子圖)確定文件覆蓋的個別資訊類別。第二個結果是,文件的关键句子被突出顯示。在分区中connected to many other sentences 的句子可能是圖的中心,並更有可能被包括在摘要在内。單文件和多文件摘要在使用圖形技術方面都能受益。
Machine Learning
機器學習技術將摘要在問題視為分類挑戰。模型嘗試根據其特性將句子分類為摘要在和非摘要在類別。我們有一個訓練集中的文件和由人類評估的提取摘要在内,用來訓練我們的算法。這通常使用Naive Bayes, 決策樹或支持向量機來完成。
抽象摘要
與抽取式摘要在內,抽象摘要是一種更有效的技法。這種技法能從文字來源创造出獨特的句子,傳達重要信息,因而逐漸受歡迎。
抽象摘要在表示資料時,能保持 logic、有序及語法正確。透過提高可讀性或改善語言質量,可以顯著提升摘要的質量。(包括圖片)。
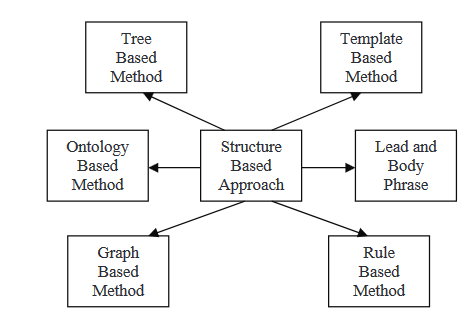
目前有兩種方法:結構基礎法和語義基礎法。
結構基礎法
結構基礎法首先將文件中最重要信息使用如模板、抽取規則和替代結構等心理特徵架构建模,包括樹、本體、導言和正文、規則以及圖形結構。接下來,我們將閱讀到這種策略中融合的一些不同方法。
樹狀方法
在這種方法中,文件的內容被表示為依賴樹。為大纲選擇內容可以通過幾種技術來實現,例如一個主題交義算法程式的或是利用本地對齊嘗試跨越分析句子之一。這種方法使用語言生成器或相關算法來生成大綱。在這篇文章中,作者提出一種使用由下而上之本地多序列對齊找出共通信息短語的句子融合方法。多基因概述系統使用一種稱為句子融合的技術。
在這種方法中,一組文件用作輸入,使用主題選擇算法來提取中心主題,然後使用聚類算法來根據重要性排名短語。將句子排好序後,它們使用句子融合來融合,並生成統計概述。結構化方法將文件( files)中最重要的數據使用如模板、提取規則等心理特征架构進行編碼,以及如樹狀結構、本體、導言和正文、規則、圖形結構等替代結構。
模板基礎方法
此方法中使用一本指南來表示整個文件。將語言模式或抽取標準與指南中的槽位進行比較,以識別可以映射到槽位中的文字片段。這些文字片段是大纲內容的區塊指示器。本論文建議了兩種方法(單文件與多文件他要撮要)用於文件撮要。為了從文件中創建摘錄和要點,他們遵循了GISTEXTER中所述的方法。
用於資訊抽取的GISTEXTER是一個撮要系統,它能在輸入文本中識別與主題相關的資訊,並將其轉化為數據庫條目;然後根據用戶要求將句子添加到摘要中。

本體基礎方法
許多研究人員嘗試通過使用本體論(知識庫)來提高摘要的成效。大部分互聯網文件都有共通領域,意味著它們都處理相同的 général 主題。本體論是每個領域獨特的資訊結構強大的表現。
該論文建議使用模糊本體,它模擬不確定性並精確地描述領域知識,以综述中國新聞。在這個方法中,領域專家首先為新聞事件定義領域本體,然後文檔準備階段從新聞語料庫和中國新聞詞典中提取語義詞。
導言和主体的短語方法
這種方法涉及通過對導言和句子主体的相同句法頭片段進行操作(插入和替換)來重寫導言句子。使用短語片段的句法分析,田中 建議了一種综述廣播新聞的技術。句子融合方法用於推導這個概念的基础。
摘要新聞播報涉及尋找頭條和正文區共享的詞組,然後插入和替換這些詞組以透過句子修订產生摘要。首先,對頭條和正文區應用語法分析器。接著,識別觸發搜寻對,最後,使用各種相似性和對齊標準對詞組進行對齊。最後的階段可能是插入或替換,或兩者都有。
插入過程包括選擇插入點、檢查冗餘,並檢查語篇内部的連貫性,以確保連貫性並消除冗餘。替換步驟通過替換頭條區中的正文詞組提供更多信息。
規則基礎方法
在這種技術中,需概要化的文件是以類和方面清單的形式表示。內容選擇模組從由數據提取規則生成的那些中選擇最有效的候選者,以回答一個或多個方面的類別。最後,生成模式用於生成大纲句子。
為識別語義上相關的名詞和動詞,Pierre-Etienne 等人 提出了 Informaation Extraction 的一套標準。一旦 extracts,數據就会被傳送到內容選擇步驟,該步驟努力過濾掉混杂的候選詞。它用於直觀生成模式的句法和詞彙。生成後,執行內容導向的摘要。
圖基方法
許多研究者使用圖形數據結構來表示語言文件。圖形是表示文件在語言學研究社區中是一個popular choice。系統中的每個節點代表一個詞彙單元,與指向邊一起定義了句子的結構。為了提高概要性能,Dingding Wang 等人。建議使用各種策略的多文件概要系統,例如以重心为基础的方法、圖形基礎方法等,以評估各種基線組合方法,例如平均分數、平均排名、Borda 計數、中位數聚合等。
一種独特的加权共识方法被開發出来,以收集不同概要策略的結果。在語義基礎方法中,使用文件或文件的語言说明來哺養自然語言生成(NLG)系統。此技術专门用於通過語言數據識別名詞短語和動詞短語。
語義基礎方法
語義基礎方法使用文件的語言說明來哺養自然語言生成(NLG)系統。該方法處理語言數據以識別名詞短語和動詞短語。
- 多模态語義模型:此方法中,建立一個捕捉概念及想法之間的關係的語言學模型,用來描述如文字和圖像的多模態文件內容。关键是使用若干標準對想法進行评级,然後選擇出的概念表達為句子以形成摘要。
- 資訊項目基礎方法:在此方法中,不是使用供給文件中的句子,而是使用這些文件的抽象表示來生成摘要內容。抽象描繪是資訊項目,文本中 coherent information 的最小部分。
- 語義圖模型:此技術旨在通過為原始文件建立豐富語義圖 (RSG)來概述文件,然後減少創建的語言學圖並從減少后的語言學圖生成的最終抽象概述。
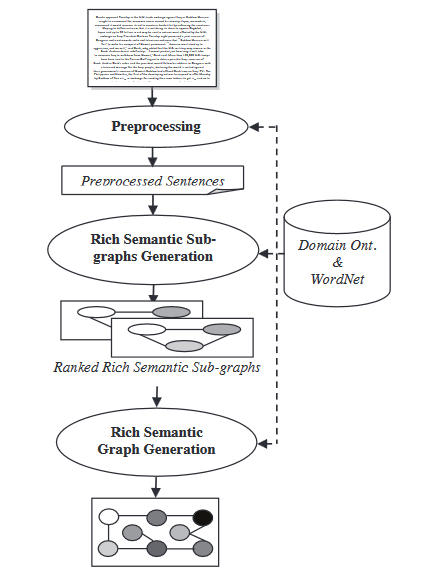
在豐富語義圖生成模組中,對生成的豐富語義圖應用一組启发式規則來減少它,通過合併、刪除或巩固圖節點。
- 語義文本表示模型:此技術通過使用詞語的語義而非文本的語法/結構來分析輸入文本。
商業案例研究
- 電腦程式設計:已經有多少努力投入於開發能獨立撰寫程式碼和開發網站的人工智慧技術。未來,程式设计师或许能夠倚賴於专门的「程式碼概要化器」來提取新等项目的基本要素。
- 幫助身障者:那些聽力上有困難的人可能會發現概要化技術能幫助他們更好地跟進內容,隨著語音到文字技術的進步。
- 會議和其他視頻會議:由於遠距工作嘅扩展,記錄下交流中重要想法和內容的能力日益被需要。如果你的團隊會議能透過語音到文字的方式進行概要化,那就太棒了。
- 搜寻專利:尋找相關的專利信息可能會耗費大量時間。一個專利概要生成器或許能帮到你,無論你是在進行市場 intelligences 研究還是準備註冊新的專利。
- 書籍和文學:概要化是有幫助的,因為它們為讀者提供了關於他們可能從一本书中期待內容的簡潔概述,幫助他們決定是否購買。
- 通過社交媒體進行廣告: creates white papers, 電子書和公司部落格的组织或许會使用概要化,以讓他們的工作更易於消化和分享,在如Twitter和Facebook等平台上。
- 經濟研究:投資銀行业的决策过程中,會投入大量资金用于数据获取,例如计算机化股票交易。任何整天翻阅市場數據和新聞的金融分析師最終都會達到信息過載。金融文件,如盈利報告和財務新聞,可能會從能夠讓分析師快速從內容中提取市場信號的摘要系統中受益。
- 使用搜索引擎優化(SEO)推廣您的业务:搜索引擎優化(SEO)評估需要對競爭對手內容中討論的議題有深入的了解。在Google最近算法修改以及隨後的對主題權威的強調面前,這至關重要。能夠快速摘要數個文件、識別共通點和扫瞄關鍵信息可能是一個強大的研究工具。
結論
儘管抽象摘要不如提取方法的可靠性高,但它對於產生與人類寫作方式一致的摘要來說,擁有更驚人的前景。因此,這個領域可能會出現大量的最新計算、認知和語言技術。
參考文獻
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques