













您的管理層是否想要了解公司的財務和生產力的一切,但卻不願意在頂級的IT管理工具上花一分錢?不要最終使用不同的工具來進行庫存、計費和票務系統。您只需要一個中央系統。何不考慮使用 Power BI Python?
Power BI 可將繁瑣且耗時的任務轉變為自動化流程。在這個教程中,您將學習如何以想像不到的方式切片和組合您的數據。
來吧,拋開對複雜報告的煩惱吧!
先決條件
本教程將進行實踐演示。如果您想跟隨進行,請確保您具有以下東西:
- Power BI 訂閱 – 免費試用版即可。
- A Windows Server – This tutorial uses a Windows Server 2022.
- 安裝在您的 Windows Server 上的 Power BI Desktop – 本教程使用 Power BI Desktop v2.105.664.0。
- 已安裝 MySQL Server – 本教程使用 MySQL Server v8.0.29。
- 已安裝在計劃使用桌面版本的外部設備上的 本地數據網關。
- Visual Studio Code(VS Code)- 本教程使用 VS Code v17.2
- 已安裝 Python v3.6 或更新版本 – 本教程使用 Python v3.10.5。
- 已安裝 DBeaver – 本教程使用 DBeaver v22.0.2。
搭建 MySQL 數據庫
Power BI 可以美觀地可視化數據,但您需要在進行數據可視化之前將其提取和存儲。存儲數據的最佳方法之一是使用數據庫。MySQL 是一個免費且功能強大的數據庫工具。
1. 以系統管理員身份打開命令提示符,運行下面的 mysql 命令,並在提示時輸入根用戶名(-u)和密碼(-p)。
默認情況下,只有根用戶有權對數據庫進行更改。
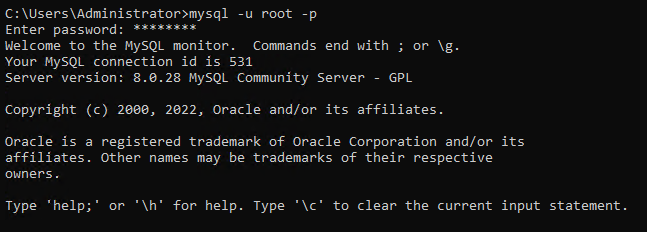
2. 接下來,執行以下查詢以創建新的資料庫使用者(CREATE USER)並設置密碼(IDENTIFIED BY)。您可以給使用者取不同的名稱,但本教程選擇的名稱為 ata_levi。

3. 創建使用者後,執行以下查詢以授予新使用者權限(ALL PRIVILEGES),例如在伺服器上創建資料庫。

4. 現在,執行以下 \q 命令以退出 MySQL。

5. 執行以下 mysql 命令以作為新建的資料庫使用者(ata_levi)登錄。
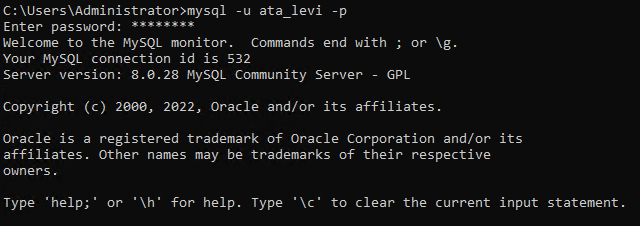
6. 最後,執行以下查詢以創建名為 ata_database 的新資料庫。當然,您可以給資料庫取不同的名稱。

使用 DBeaver 管理 MySQL 資料庫
在管理資料庫時,通常需要具備 SQL 知識。但是使用 DBeaver,您可以通過幾個點擊來管理您的資料庫,DBeaver 將為您處理 SQL 語句。
1. 從桌面或“開始”選單中打開 DBeaver。
2. 當 DBeaver 打開時,點擊“新建資料庫連接”下拉菜單,選擇 MySQL 以開始連接到您的 MySQL 伺服器。
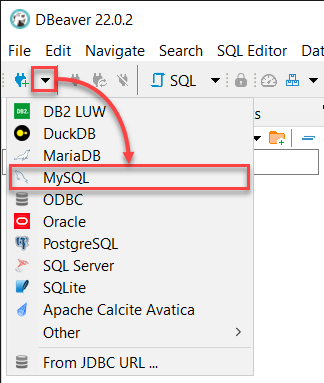
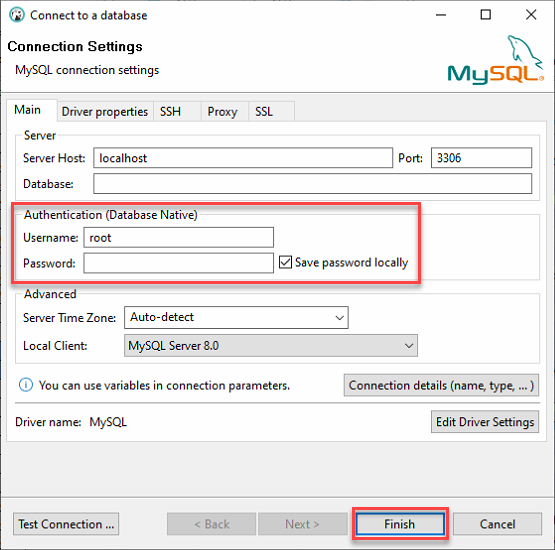
3. 使用以下資訊登錄到本地 MySQL 伺服器:
- 保持 Server Host 為 localhost,並將 Port 設置為 3306,因為您正在連接到本地伺服器。
- 提供第二步“建立 MySQL 資料庫”部分中的 ata_levi 使用者的憑據(用戶名和密碼),然後點擊“完成”以登錄到 MySQL。
4. 現在,在數據庫導航器(左側面板)下擴展您的數據庫(ata_database)→右鍵單擊表,然後選擇創建新表以初始化創建新表。
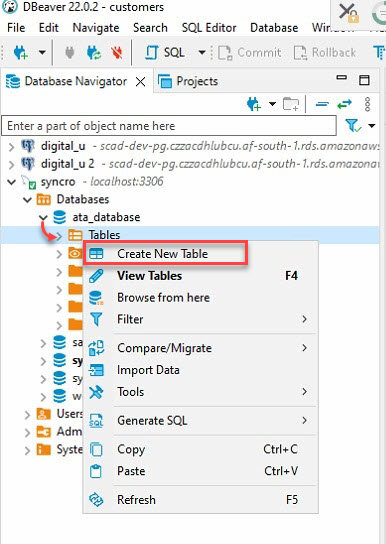
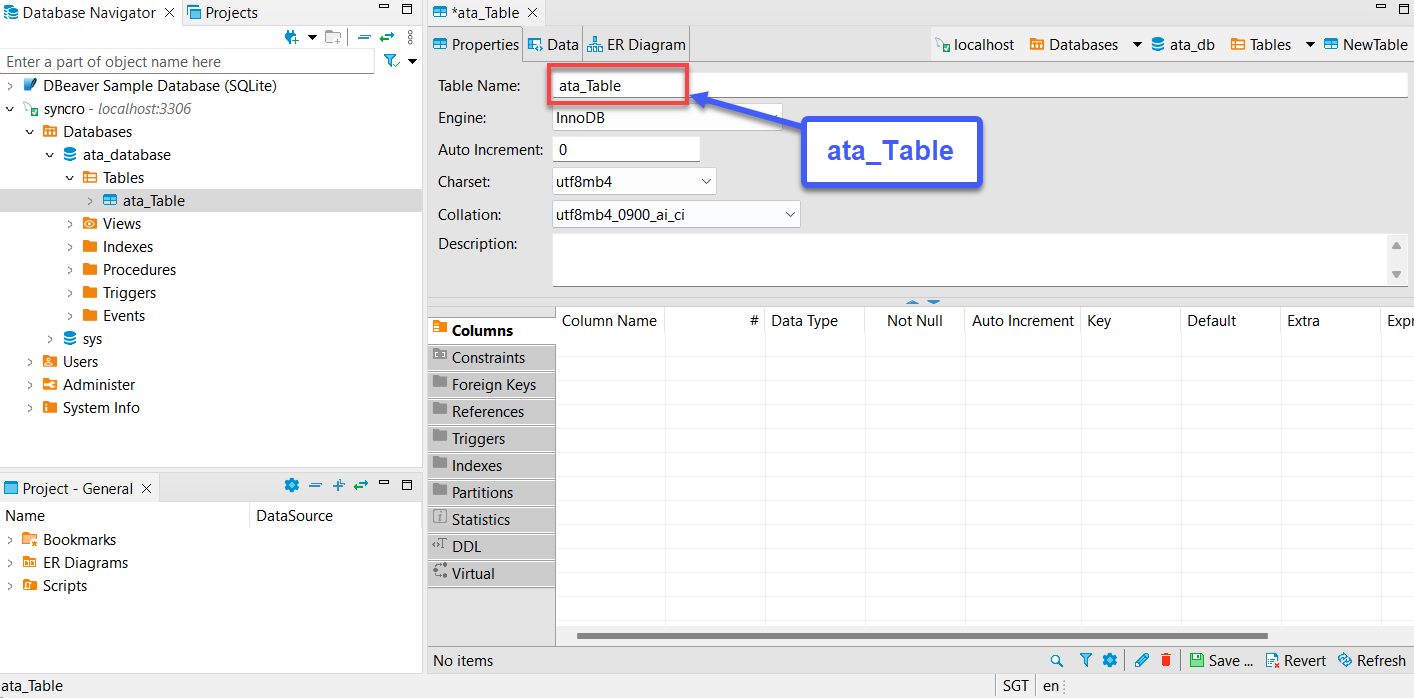
5. 為您的新表命名,但本教程的選擇是ata_Table,如下所示。
請確保表名與您在“獲取和消耗API數據”部分第七步中將在to_sql(“表名”)方法中指定的表名匹配。
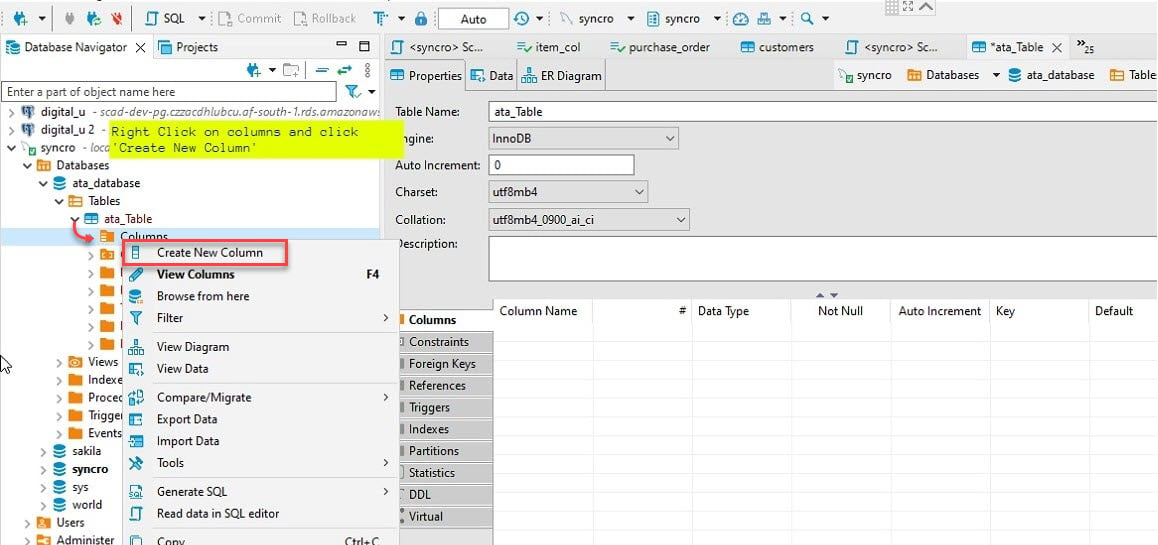
6. 接下來,擴展新表(ata_table)→右鍵單擊列→創建新列以創建新列。
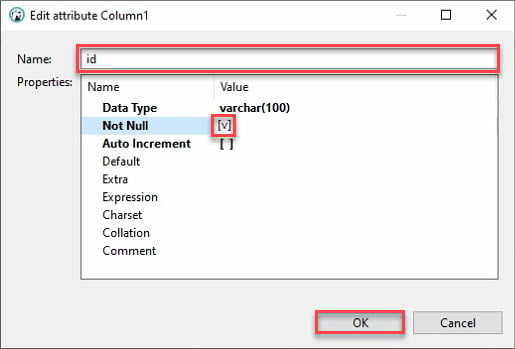
7. 提供列名,如下所示,並選中“Not Null”框,然後點擊“確定”以創建新列。
理想情況下,您希望添加一列名為“id”。為什麼?大多數API都會有一個id,而Python的pandas數據框將自動填充其他列。
8. 即使已驗證了您新創建的列(id),也要單擊“保存”(右下角)或按Ctrl+S保存更改。
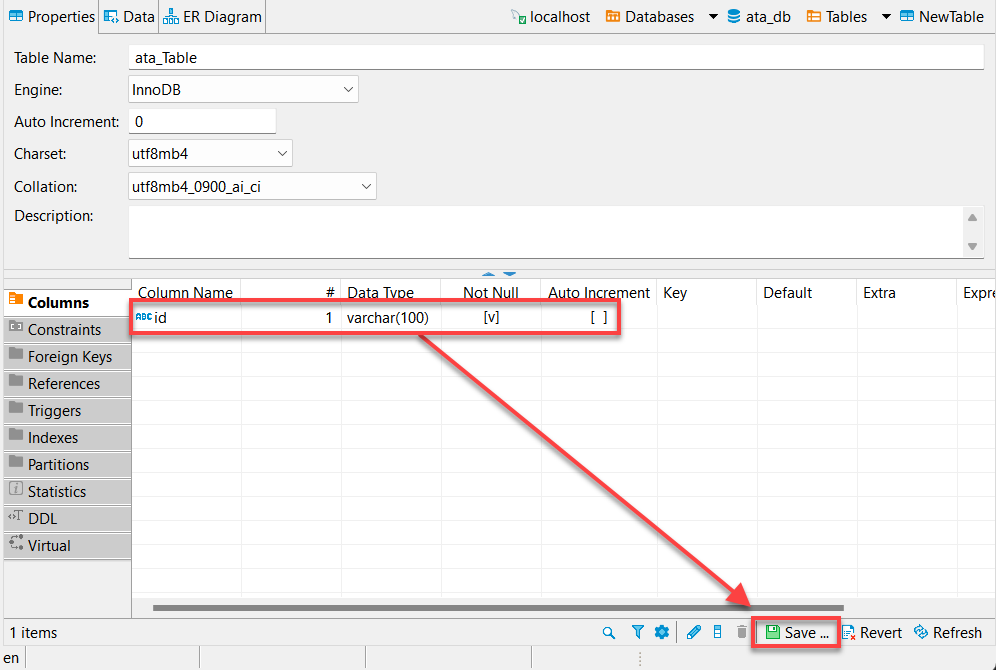
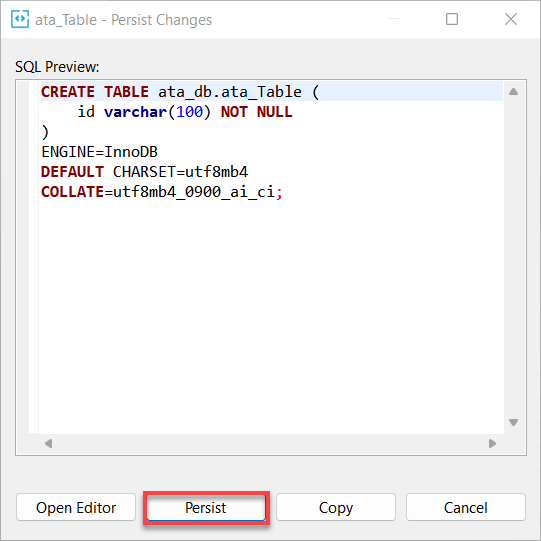
9. 最後,單擊“持久保存”以將您對數據庫所做的更改持久保存。
獲取和消耗API數據
現在您已經創建了存儲數據的數據庫,您需要從您的相應API提供程序那裡提取數據,並使用Python將其推送到您的數據庫。您將源碼數據以在Power BI上進行可視化。
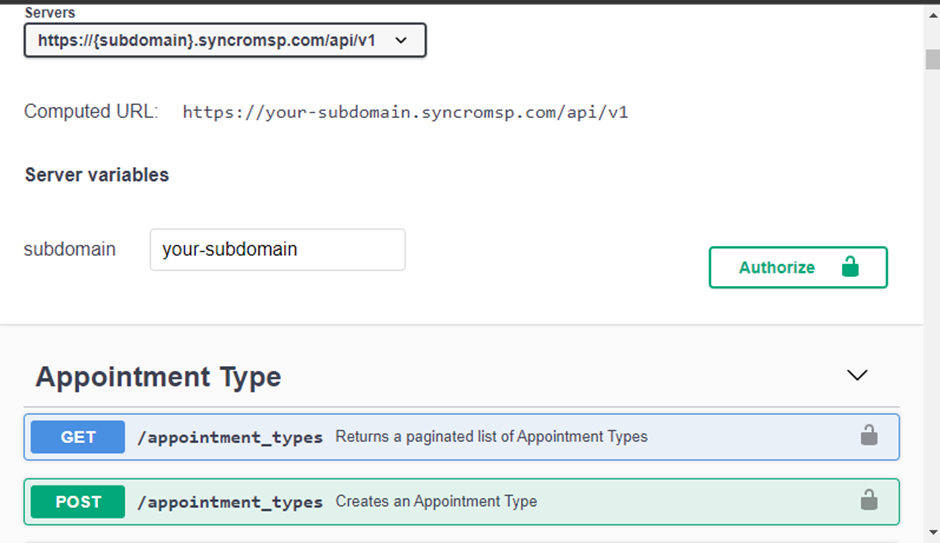
要連接到您的API提供程序,您需要三個關鍵信息;授權方法、API基本URL和API端點。如果對此信息存疑或如何獲取此信息,請訪問您的API提供程序的文檔站點。
以下是Syncro的文档页面。
1. 打开VS Code,创建一个Python文件,并根据文件期望的API数据命名文件。此文件将负责获取和推送API数据到您的数据库(数据库连接)。
有多个Python库可用于帮助进行数据库连接,但在本教程中,您将使用SQLAalchemy。
在VS Code终端上运行以下pip命令,以在您的环境中安装SQLAalchemy。

2. 接下来,创建一个名为connection.py的文件,填充下面的代码,替换相应的值,并保存文件。
一旦您开始编写与数据库通信的脚本,必须在数据库接受任何命令之前建立与数据库的连接。
但是,不要为您编写的每个脚本重写数据库连接字符串,下面的代码专门用于建立此连接,以供其他脚本调用/引用。
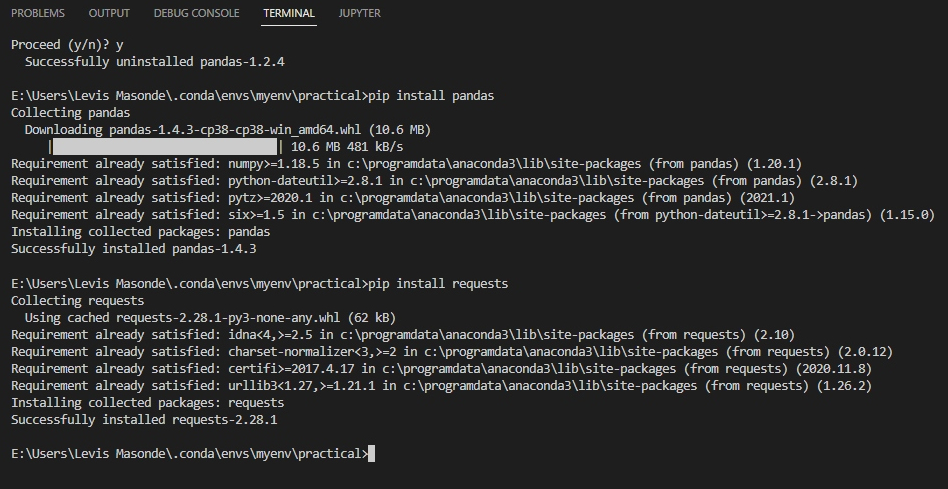
3. 打開 Visual Studio 的終端機(Ctrl+Shift+`),執行以下命令以安裝 pandas 和 requests。
4. 創建另一個名為 invoices.py 的 Python 文件(或命名為其他名稱),並將下面的代碼填入文件。
您將在後續步驟中向 invoices.py 文件添加代碼片段,但您可以在 ATA 的 GitHub 上查看完整的代碼。
invoices.py 腳本將從後面描述的主腳本中運行,該腳本從您的 API 提取第一個數據。
下面的代碼執行以下操作:
- 從您的 API 中提取數據並將其寫入您的數據庫。
- 用您的 API 提供者憑證替換授權方法、密鑰、基本 URL 和 API 端點。
5. 將下面的代碼片段添加到 invoices.py 文件中以定義標頭,例如:
- 您期望從 API 收到的類型數據格式。
- 基本 URL 和端點應該與授權方法和相應的密鑰一起。
請務必使用您自己的值更改下面的值。
6. 接下來,將以下的異步函數添加到 invoices.py 檔案中。
以下的代碼使用 AsyncIO 在一個主腳本中管理多個腳本,詳情請參閱下一節。當您的項目擴展到包含多個 API 端點時,將 API 使用腳本放在它們自己的文件中是一種良好的實踐。
7. 最後,將以下代碼添加到 invoices.py 檔案中,其中一個 get_pages 函數處理您的 API 的分頁。
此函數返回 API 中的總頁數,並幫助 range 函數遍歷所有頁面。
請聯繫您的 API 開發人員了解您的 API 提供程序使用的分頁方法。
如果您希望將更多API端點添加到您的數據中:
- 重復“使用DBeaver管理MySQL數據庫”部分的步驟四至六。
- 重復“獲取和使用API數據”部分下的所有步驟。
- 將API端點更改為您希望使用的另一個端點。
同步API端點
現在您已經有了數據庫和API連接,並且準備通過運行invoices.py文件來開始API消費。但這樣做將限制您同時消費一個API端點。
如何突破限制?您將創建另一個Python文件作為中心文件,該文件從各種Python文件中調用API函數並使用AsyncIO運行函數,使編程保持乾淨,並允許您將多個功能捆綁在一起。
1. 創建一個名為central.py的新Python文件,並添加以下代碼。
與invoices.py文件類似,您將在每個步驟中將代碼片段添加到central.py文件中,但是您可以在ATA的GitHub上查看完整代碼。
以下代碼導入了必要的模塊,並使用from <filename> import <function name>語法從其他文件導入腳本。
2. 接下來,在central.py文件中添加以下代碼以控制invoices.py中的腳本。
您需要將來自invoices.py的call_invoices函數參考/調用為central.py中的AsyncIO任務(invoice_task)。
3. 創建AsyncIO任務後,等待該任務從invoice.py中調用call_invoices函數,一旦鏈功能(在第二步中)開始運行。
4. 創建AsyncIOScheduler以安排腳本執行的工作。此代碼中添加的作業以一秒間隔運行鏈函數。
此作業對於確保您的程序保持運行並持續更新您的數據非常重要。
5. 最後,在VS Code上運行central.py腳本,如下所示。
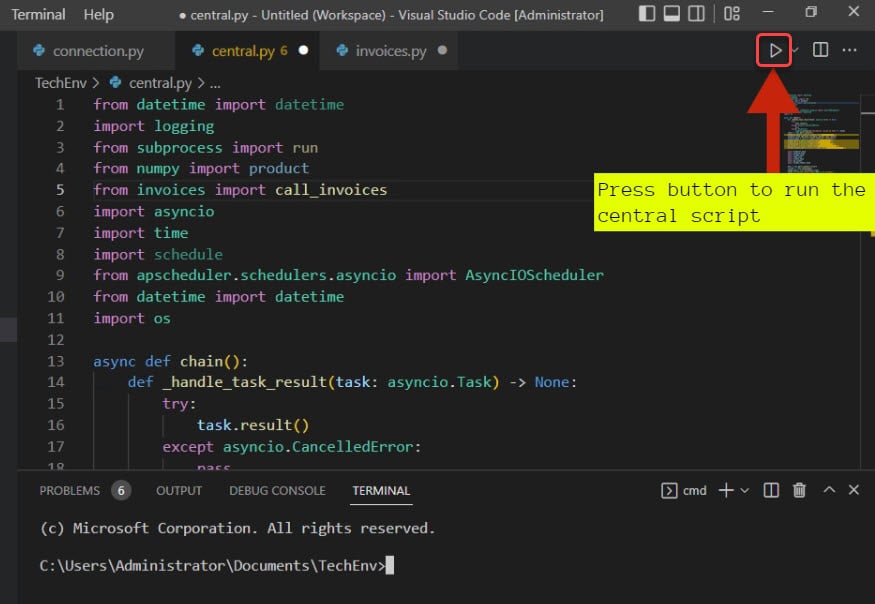
運行腳本後,您將在終端上看到以下輸出。
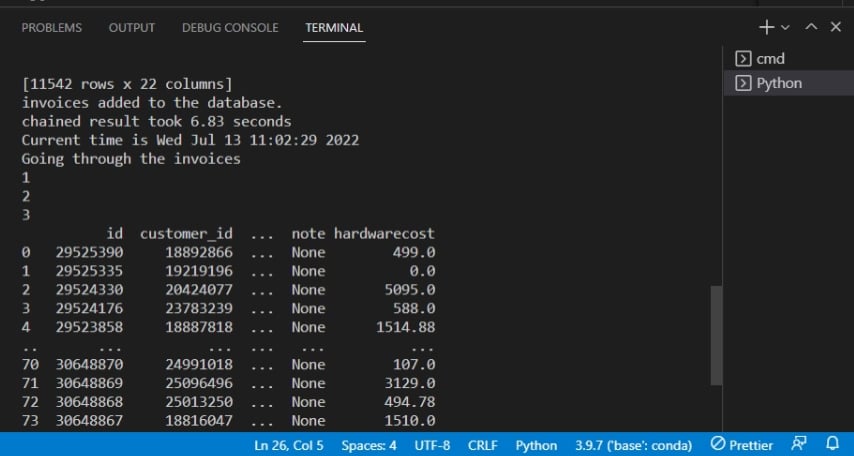
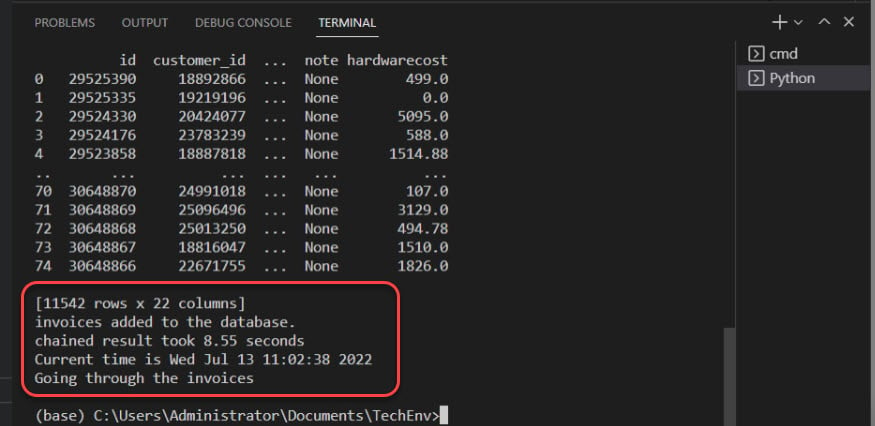
以下是輸出,確認發票已添加到數據庫中。
開發Power BI Visuals
編寫了一個連接到並消耗API數據並將此數據推送到數據庫的程序後,您幾乎準備好收穫您的數據了。但首先,您將數據推送到Power BI進行可視化,這是最終目標。
如果您無法可視化數據並進行深入連接,那麼大量的數據是無用的。幸運的是,Power BI視覺效果就像圖表可以使複雜的數學方程式看起來簡單而可預測一樣。
1. 從桌面或開始菜單中打開Power BI。
2. 點擊 Power BI 主視窗上方的資料來源圖示,下拉選單中會出現一個彈出窗口,您可以在其中選擇要使用的資料來源(步驟三)。
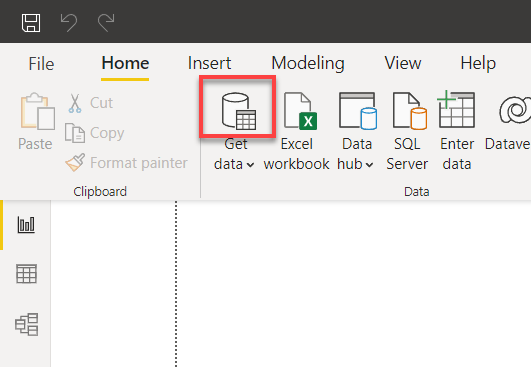
3. 搜尋 mysql,選擇 MySQL 資料庫,然後點擊連線以建立與您的 MySQL 資料庫的連線。
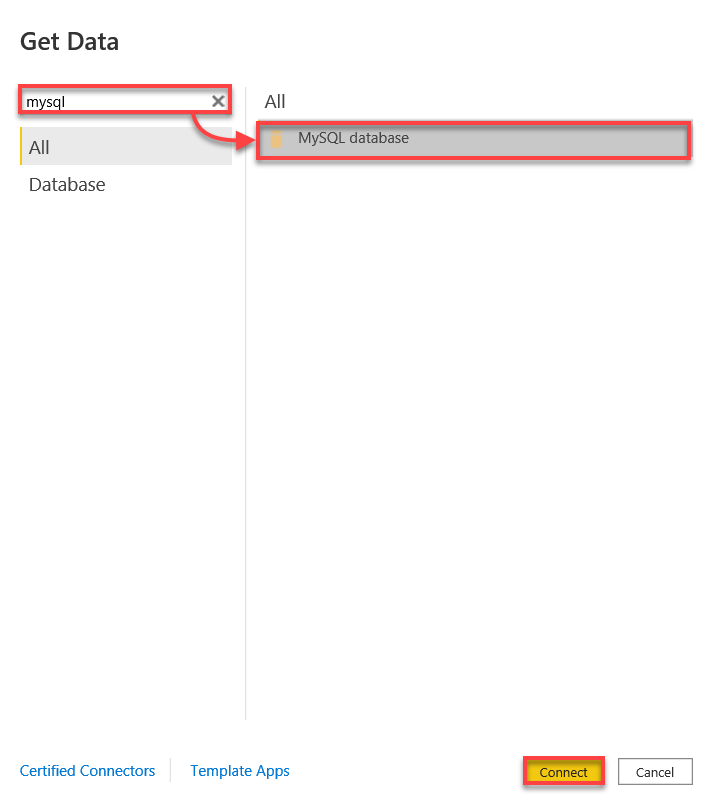
4. 現在,使用以下資訊連線到您的 MySQL 資料庫:
- 輸入 localhost:3306,因為您要連線到本地的 MySQL 伺服器,使用的埠號是 3306。
- 提供您的資料庫名稱,例如 ata_db。
- 點擊確定以連線到您的 MySQL 資料庫。

5. 現在,點擊「轉換資料」(右下角)以在 Power BI 的查詢編輯器中查看資料概覽(步驟五)。

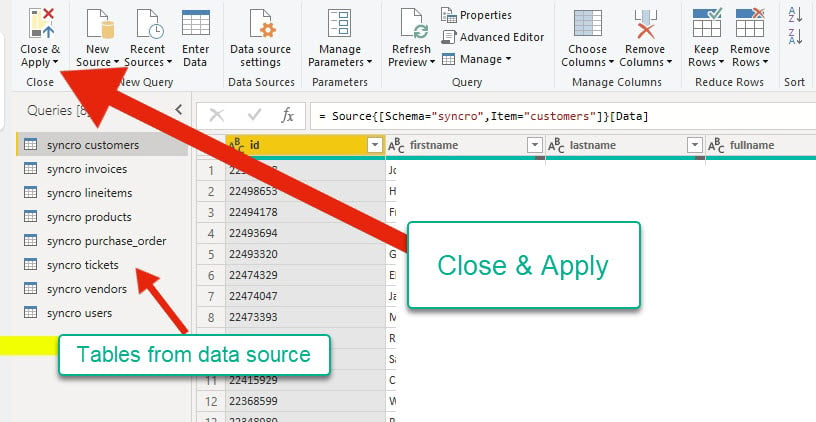
6. 在預覽資料來源後,點擊「關閉並套用」回到主應用程式,並確認是否應用了任何更改。
查詢編輯器會在最左側顯示來自資料來源的資料表。同時,您可以在繼續進入主應用程式之前檢查資料的格式。
7. 點擊「表格工具」功能區標籤,選擇「欄位」窗格上的任何一個表格,然後點擊「管理關聯」以開啟關聯精靈。
在創建視覺元素之前,您必須確保您的資料表已建立關聯,因此請明確指定資料表之間的任何關聯。為什麼呢?因為 Power BI 尚未自動檢測到複雜的表格相關性。

8. 勾選現有關聯的方塊進行編輯,然後點擊「編輯」。一個彈出窗口將出現,您可以在其中編輯所選的關聯(步驟九)。
但如果您更喜欢添加新关系,请点击“新建”按钮。
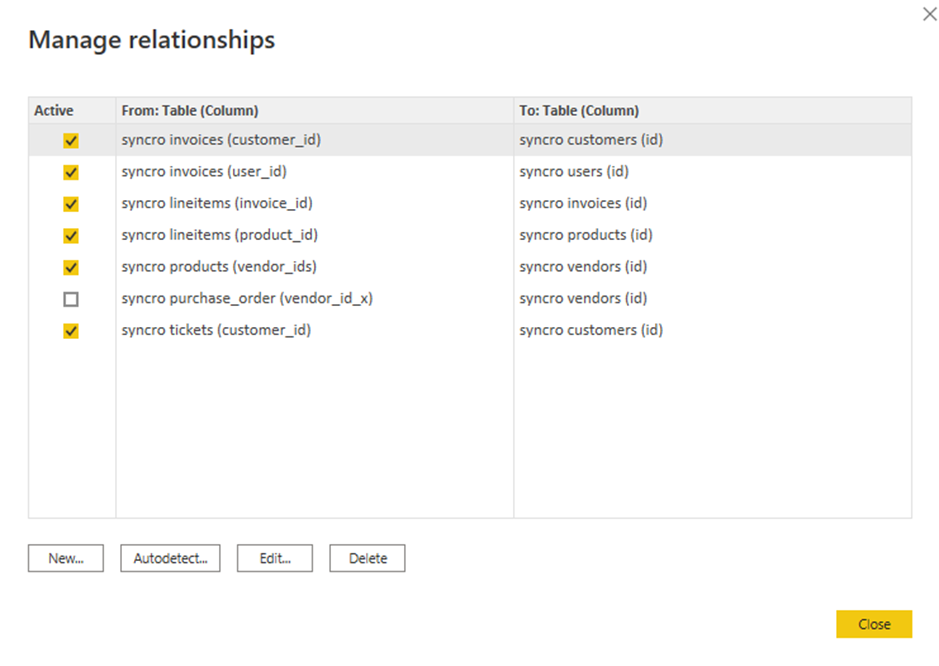
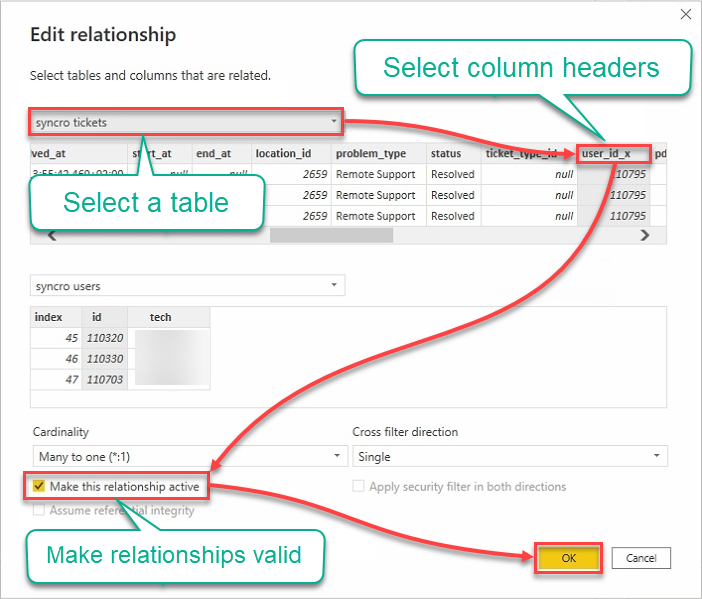
9. 使用以下步骤编辑关系:
- 点击表格下拉字段,并选择一个表格。
- 点击标题以选择要使用的列。
- 勾选激活此关系框以确保关系有效。
- 点击确定以建立关系并关闭编辑关系窗口。
10. 现在,在“可视化”窗格(最右侧)中点击“表格”可视化类型,以创建您的第一个可视化,然后将出现一个空白表格可视化(步骤11)。
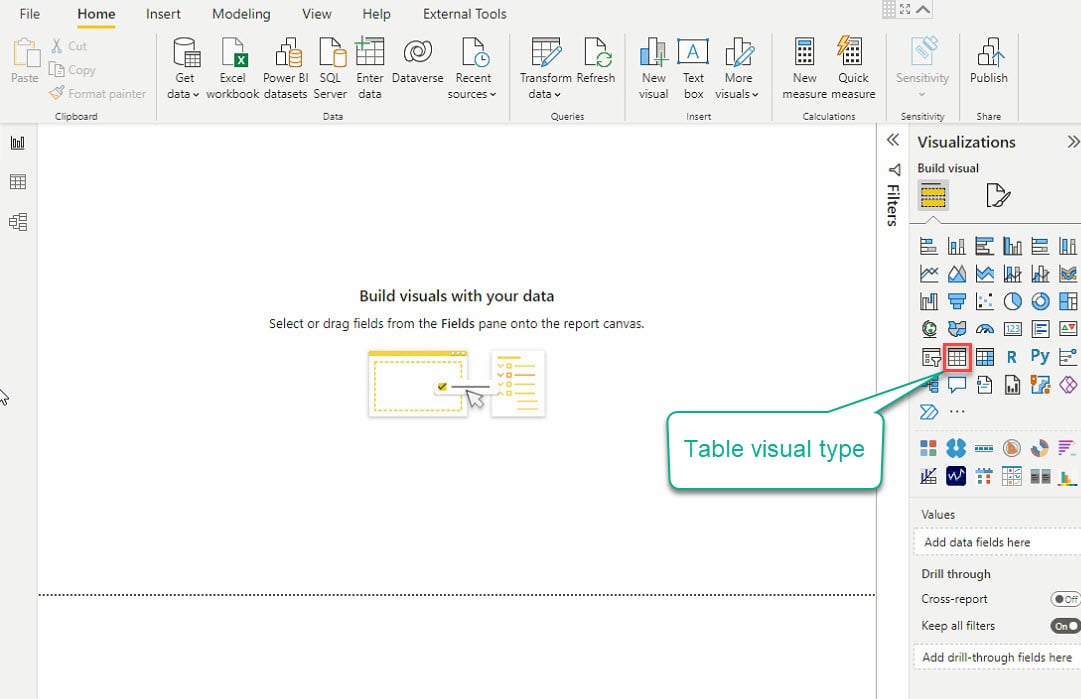
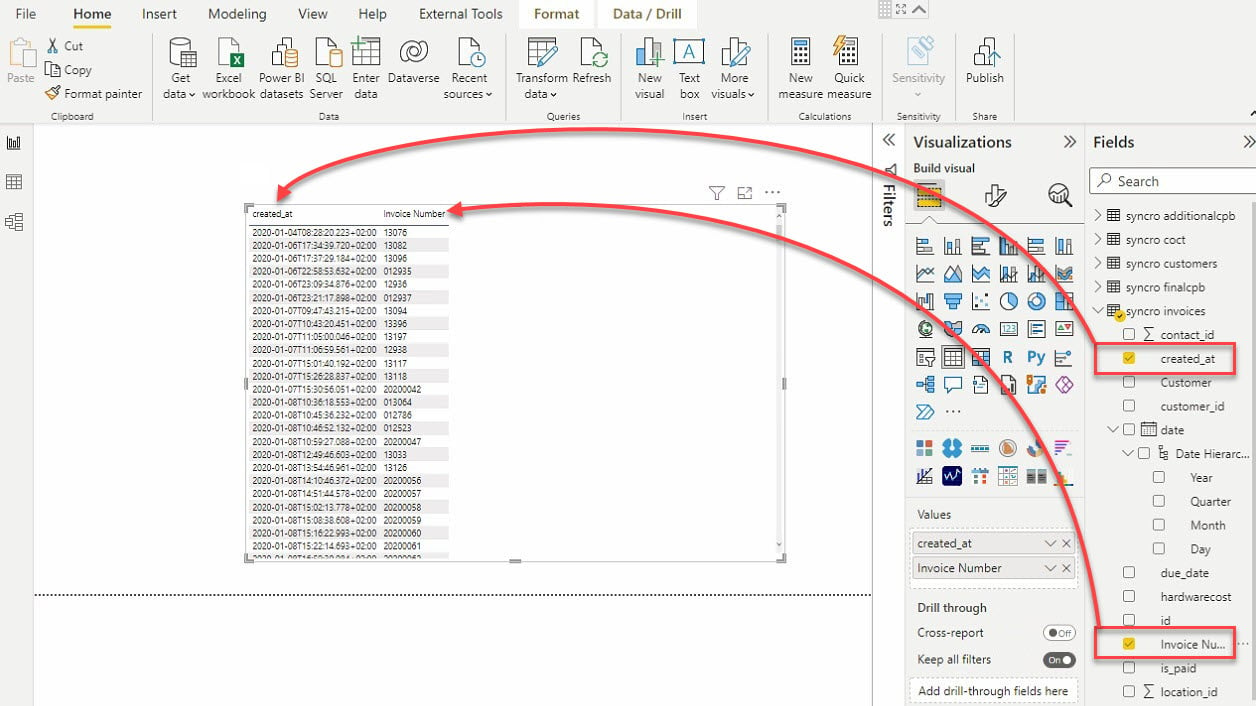
11. 选择表格可视化和要添加到表格可视化的数据字段(在字段窗格上显示),如下所示。
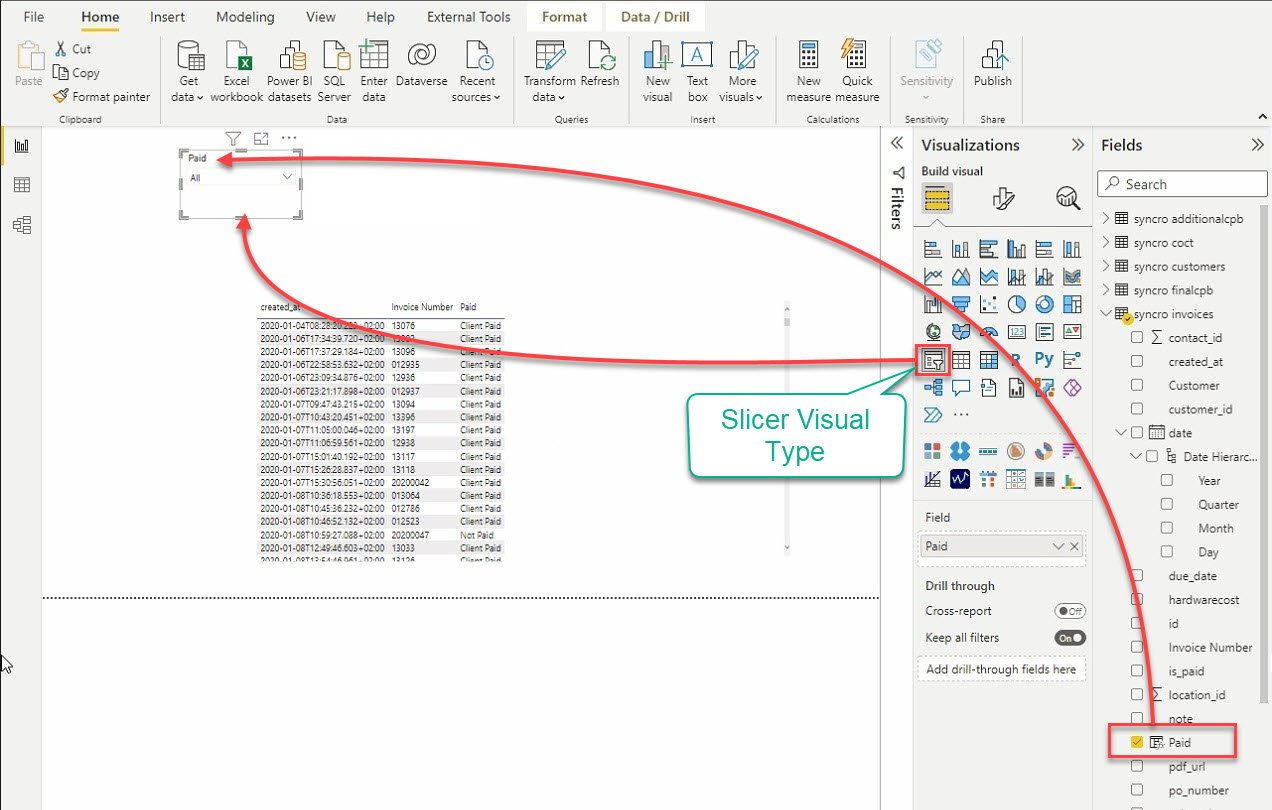
12. 最后,点击“切片器”可视化类型以添加另一个可视化。顾名思义,切片器可视化通过过滤其他可视化来切分数据。
在添加切片器后,从字段窗格中选择数据添加到切片器可视化中。
更改可视化
可视化的默认外观相当不错。但如果您想将可视化的外观更改为不那么单调,让Power BI来完成。
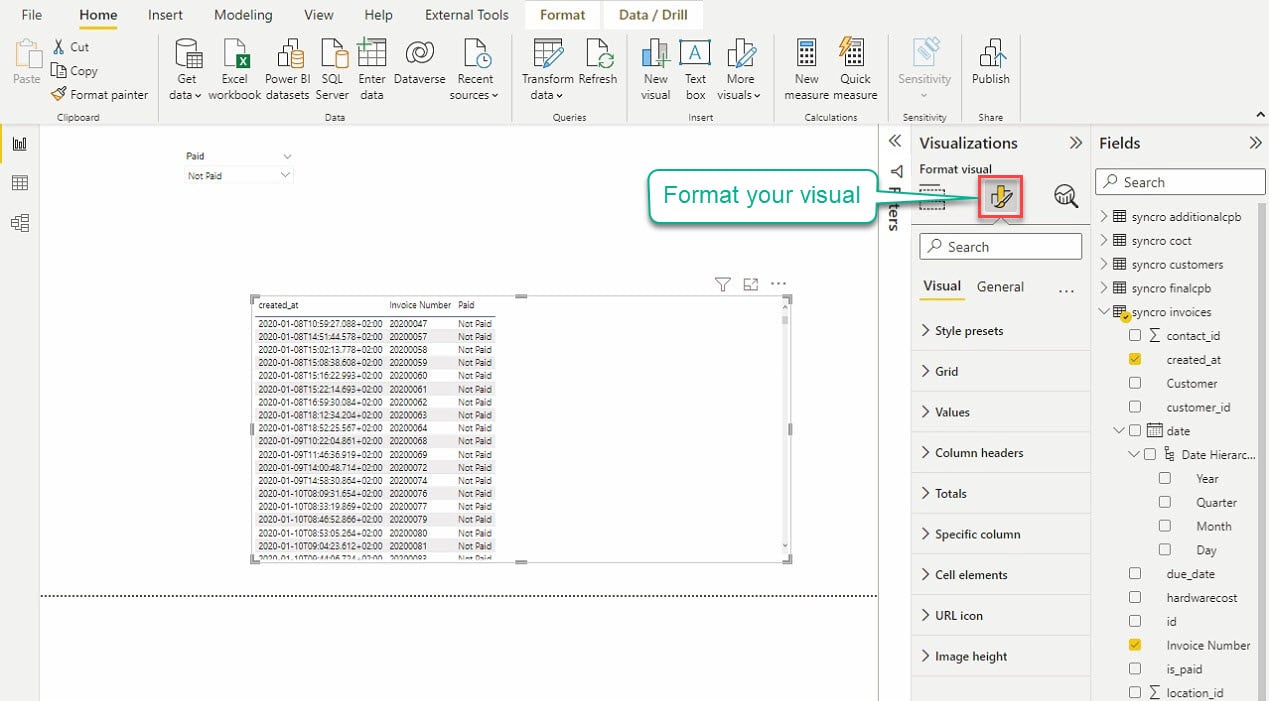
点击可视化下的格式化您的可视化图标,以访问可视化编辑器,如下所示。
花一些时间玩弄可视化设置,以获得您期望的可视化外观。只要在可视化中涉及的表格之间建立关系,您的可视化将相关。
更改可视化设置后,您可以拉取如下报告。
现在,您可以轻松可视化和分析数据,无需复杂操作或伤害眼睛。
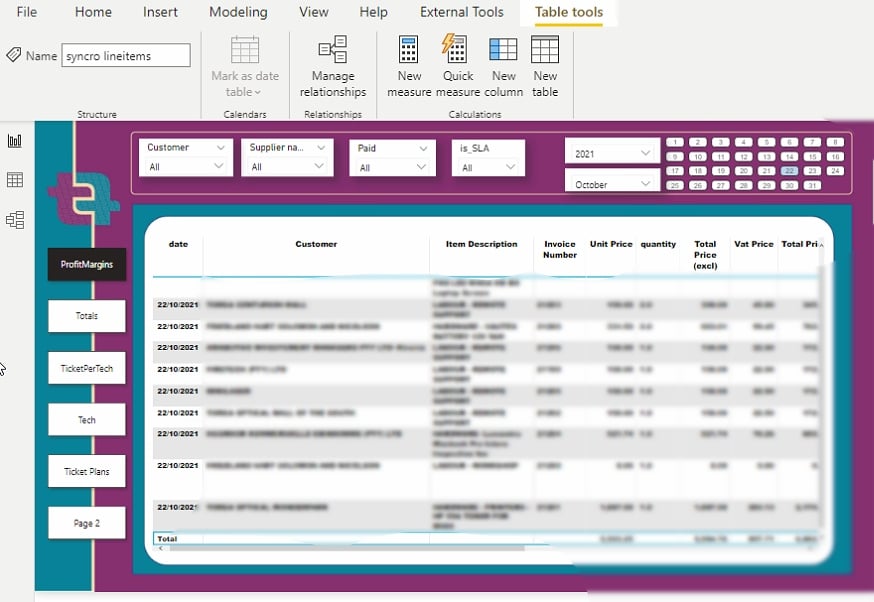
在下面的可视化中,查看趋势图,您会注意到在2020年4月发生了一些问题。那是Covid-19封锁措施首次影响到南非的时候。
这个输出仅证明了Power BI在提供准确数据可视化方面的实力。

结论
本教程旨在向您展示如何通过从API端点获取数据来建立实时动态数据管道。此外,使用Python处理和推送数据到您的数据库和Power BI。有了这些新知识,您现在可以使用API数据并创建自己的数据可视化。
越来越多的企业正在创建Restful API web应用程序。此时,您对使用Python消耗API并使用Power BI制作数据可视化感到自信,这有助于影响业务决策。