













Brazilian Portuguese
Seu gerenciamento deseja saber tudo sobre as finanças e produtividade da sua empresa, mas não está disposto a gastar um centavo em ferramentas avançadas de gerenciamento de TI? Não acabe recorrendo a diferentes ferramentas para inventário, faturamento e sistemas de suporte. Você só precisa de um sistema central. Que tal considerar o Power BI Python?
O Power BI pode transformar tarefas tediosas e demoradas em processos automatizados. E neste tutorial, você aprenderá como fatiar e combinar seus dados de maneiras que você nem imaginava.
Vamos lá, e poupe-se do estresse de analisar relatórios complexos!
Pré-requisitos
Este tutorial será uma demonstração prática. Se você quiser acompanhar, certifique-se de ter o seguinte:
- Assinatura do Power BI – O teste gratuito será suficiente.
- A Windows Server – This tutorial uses a Windows Server 2022.
- Power BI Desktop instalado no seu Windows Server – Este tutorial usa o Power BI Desktop v2.105.664.0.
- Servidor MySQL instalado – Este tutorial usa o MySQL Server v8.0.29.
- Um gateway de dados local instalado em dispositivos externos que planejam usar uma versão Desktop.
- Visual Studio Code (VS Code) – Este tutorial utiliza o VS Code v17.2
- Python v3.6 ou superior instalado – Este tutorial utiliza o Python v3.10.5.
- DBeaver instalado – Este tutorial utiliza o DBeaver v22.0.2.
Construindo um Banco de Dados MySQL
O Power BI pode visualizar dados de forma magnífica, mas você precisa buscar e armazenar antes de chegar à visualização dos dados. Uma das melhores maneiras de armazenar dados é em um banco de dados. O MySQL é uma ferramenta de banco de dados gratuita e poderosa.
1. Abra o prompt de comando como administrador, execute o comando mysql abaixo e insira o nome de usuário root (-u) e a senha (-p) quando solicitado.
Por padrão, apenas o usuário root tem permissão para fazer alterações no banco de dados.
2. Em seguida, execute a consulta abaixo para criar um novo usuário de banco de dados (CREATE USER) com uma senha (IDENTIFIED BY). Você pode nomear o usuário de forma diferente, mas a escolha deste tutorial é ata_levi.

3. Após criar um usuário, execute a consulta abaixo para CONCEDER as permissões ao novo usuário (ALL PRIVILEGES), como a criação de um banco de dados no servidor.

4. Agora, execute o comando \q abaixo para sair do MySQL.

5. Execute o comando mysql abaixo para fazer login como o usuário de banco de dados recém-criado (ata_levi).
6. Por fim, execute a seguinte consulta para CRIAR um novo BANCO DE DADOS chamado ata_database. Mas, é claro, você pode nomear o banco de dados de forma diferente.

Gerenciando Bancos de Dados MySQL com DBeaver
No gerenciamento de bancos de dados, geralmente é necessário ter conhecimento em SQL. Mas com o DBeaver, você tem uma interface gráfica para gerenciar seus bancos de dados com alguns cliques, e o DBeaver cuidará das instruções SQL para você.
1. Abra o DBeaver a partir da sua área de trabalho ou do menu Iniciar.
2. Quando o DBeaver abrir, clique na lista suspensa Nova Conexão de Banco de Dados e selecione MySQL para iniciar a conexão com o seu servidor MySQL.
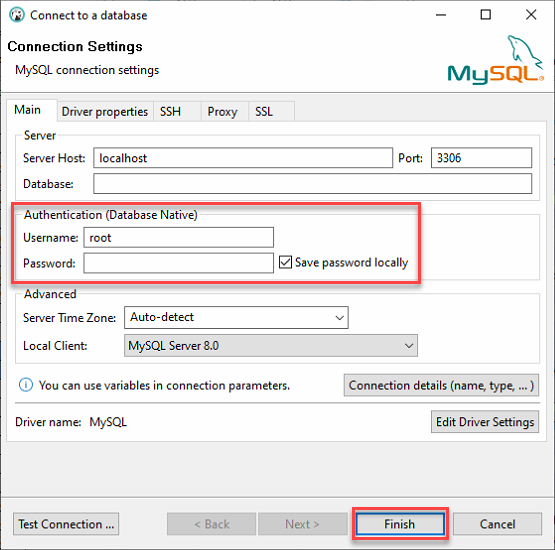
3. Faça login no seu servidor MySQL local com o seguinte:
- Mantenha o Host do Servidor como localhost e a Porta em 3306, já que você está se conectando a um servidor local.
- Forneca as credenciais do usuário ata_levi (Nome de Usuário e Senha) do passo dois da seção “Construindo um Banco de Dados MySQL” e clique em Concluir para fazer login no MySQL.
4. Agora, expanda seu banco de dados (ata_database) no Navegador de Banco de Dados (painel esquerdo) → clique com o botão direito em Tabelas e selecione Criar Nova Tabela para iniciar a criação de uma nova tabela.
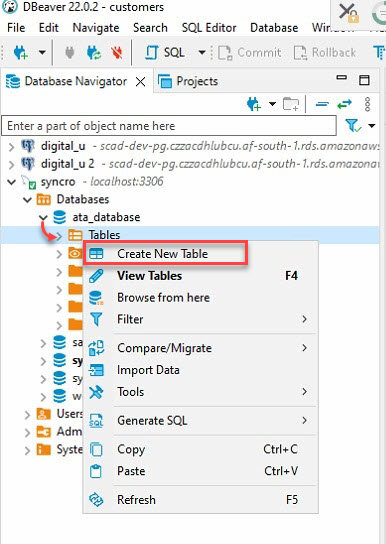
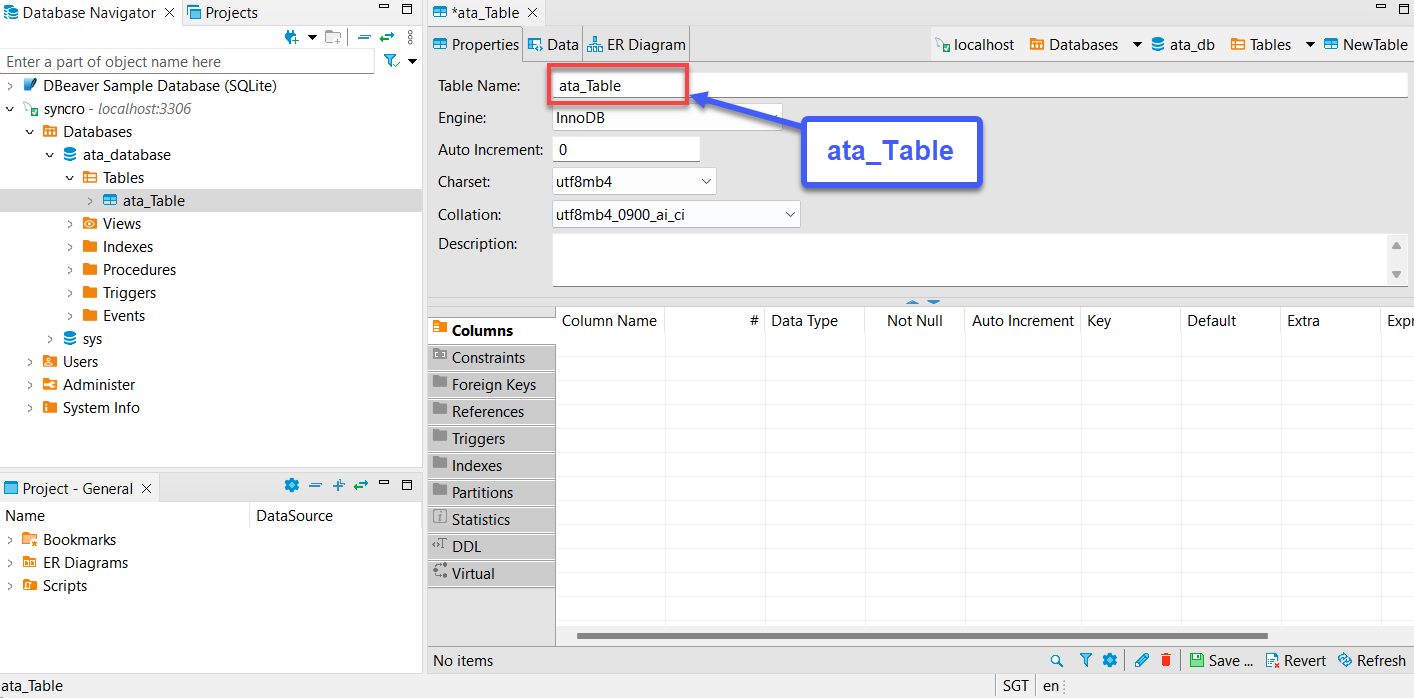
5. Nomeie sua nova tabela, mas a escolha deste tutorial é ata_Table, como mostrado abaixo.
Certifique-se de que o nome da tabela corresponde ao nome da tabela que você especificará no método to_sql (“Nome da Tabela”) no passo sete da seção “Obtendo e Consumindo Dados da API”.
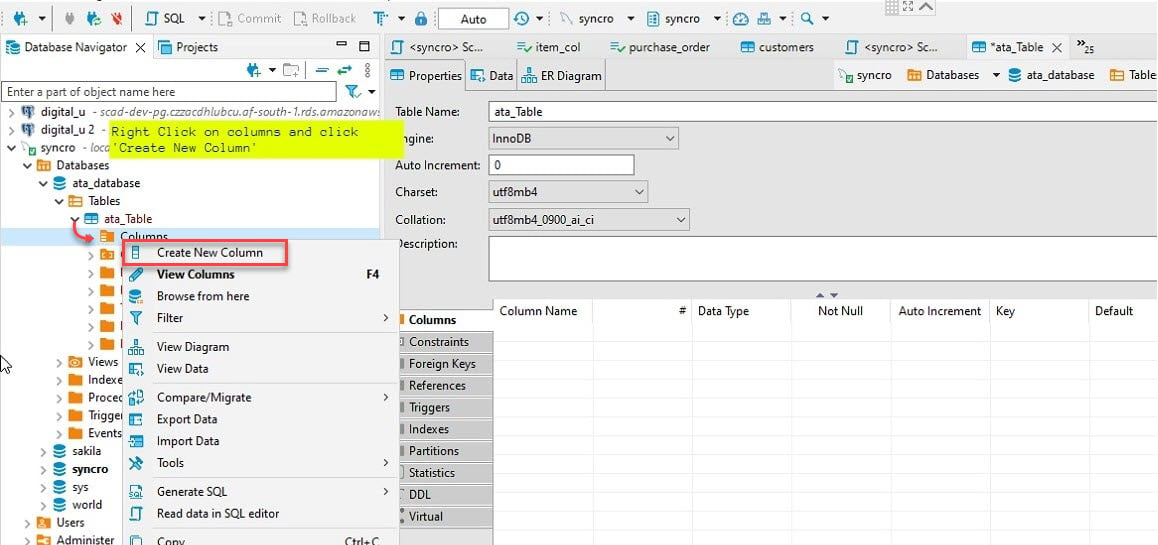
6. Em seguida, expanda a nova tabela (ata_table) → clique com o botão direito em Colunas → Criar Nova Coluna para criar uma nova coluna.
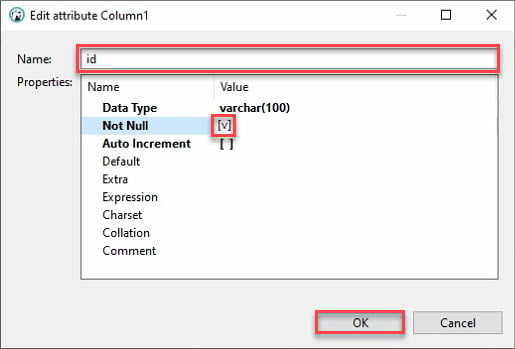
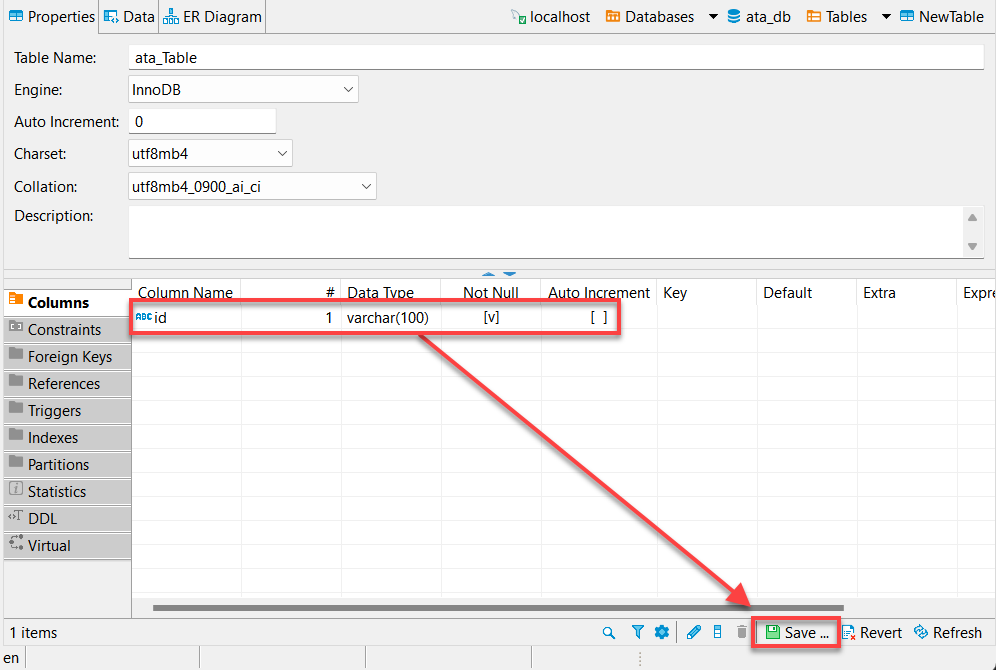
7. Forneça um Nome de coluna, como mostrado abaixo, e marque a caixa Not Null e clique em OK para criar a nova coluna.
Idealmente, você gostaria de adicionar uma coluna chamada “id”. Por quê? A maioria das APIs terá um id, e o data frame do pandas do Python preencherá automaticamente as outras colunas.
8. Clique em Salvar (canto inferior direito) ou pressione Ctrl+S para salvar as alterações assim que você verificar a coluna recém-criada (id), como mostrado abaixo.
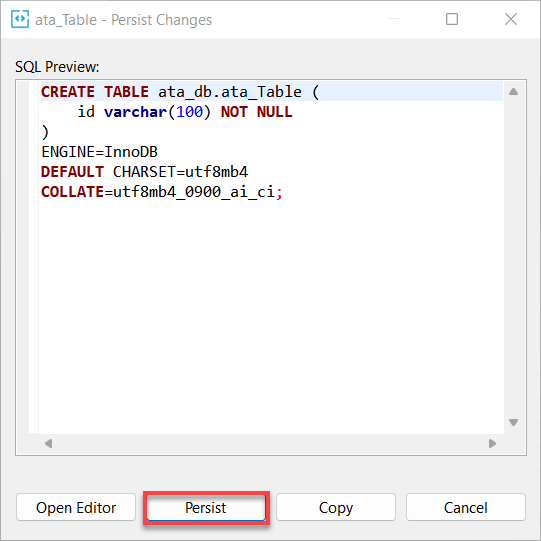
9. Por último, clique em Persistir para persistir as alterações que você fez no banco de dados.
Obtendo e Consumindo Dados da API
Agora que você criou o banco de dados para armazenar dados, você precisa buscar os dados do seu respectivo provedor de API e enviá-los para o seu banco de dados usando Python. Você vai obter seus dados para serem visualizados no Power BI.
Para se conectar ao seu provedor de API, você precisará de três peças-chave de informações: o método de autorização, URL base da API e o endpoint da API. Se tiver dúvidas sobre como obter essa informação, visite o site de documentação do seu provedor de API.
Abaixo está uma página de documentação da Syncro.
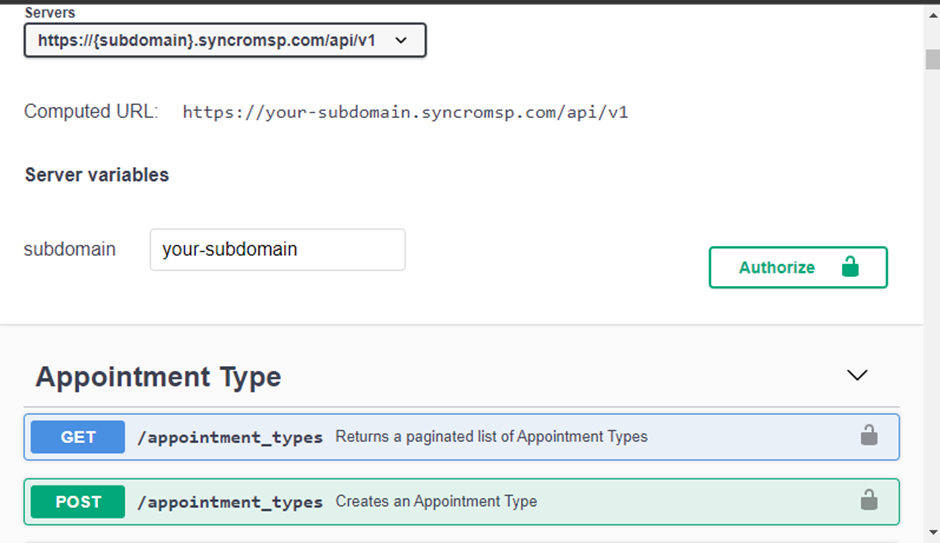
1. Abra o VS Code, crie um arquivo Python e nomeie o arquivo de acordo com os dados da API esperados do arquivo. Este arquivo será responsável por buscar e enviar os dados da API para o seu banco de dados (conexão com o banco de dados).
Múltiplas bibliotecas Python estão disponíveis para auxiliar na conexão com o banco de dados, mas neste tutorial, você utilizará o SQLAlchemy.
Execute o comando pip abaixo no terminal do VS Code para instalar o SQLAlchemy em seu ambiente.

2. Em seguida, crie um arquivo chamado connection.py, preencha o código abaixo, substitua os valores conforme necessário e salve o arquivo.
Ao começar a escrever scripts para se comunicar com o seu banco de dados, uma conexão com o banco deve ser estabelecida antes que o banco de dados aceite qualquer comando.
Mas, em vez de reescrever a string de conexão do banco de dados para cada script que você escrever, o código abaixo é dedicado a fazer essa conexão para ser chamado/referenciado por outros scripts.
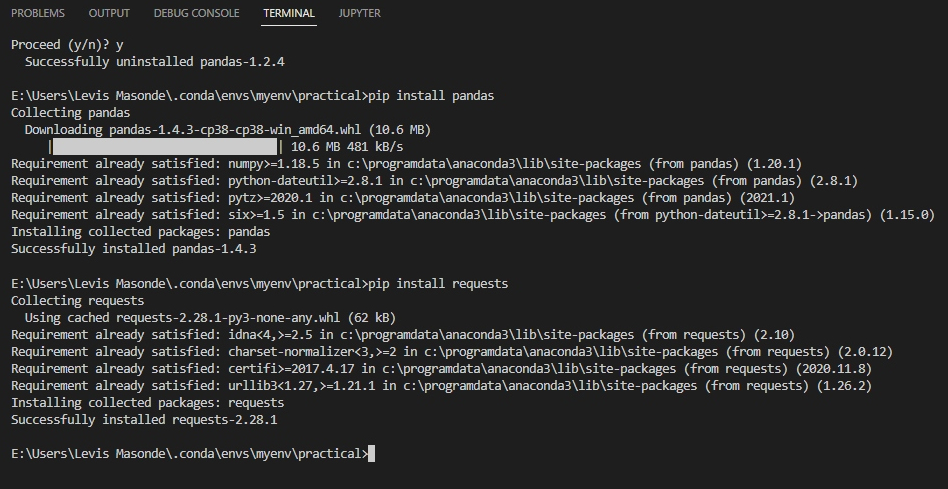
3. Abra o terminal do Visual Studio (Ctrl+Shift+`), e execute os comandos abaixo para instalar o pandas e requests.
4. Crie outro arquivo Python chamado invoices.py (ou dê um nome diferente), e preencha o código abaixo no arquivo.
Você adicionará trechos de código ao arquivo invoices.py em cada etapa subsequente, mas pode visualizar o código completo no GitHub da ATA.
O script invoices.py será executado a partir do script principal descrito na seção seguinte, que extrai seus primeiros dados da API.
O código abaixo realiza o seguinte:
- Consome dados da sua API e os escreve no seu banco de dados.
- Substitui o método de autorização, chave, URL base e pontos finais da API pelos credenciais do seu provedor de API.
5. Adicione o trecho de código abaixo ao arquivo invoices.py para definir os cabeçalhos, por exemplo:
- O formato de dados que você espera receber da sua API.
- A URL base e o ponto final devem acompanhar o método de autorização e a chave respectiva.
Certifique-se de alterar os valores abaixo pelos seus próprios.
6. Em seguida, adicione a seguinte função assíncrona ao arquivo invoices.py.
O código abaixo utiliza AsyncIO para gerenciar vários scripts a partir de um script principal, conforme abordado na seção seguinte. Quando seu projeto se expandir para incluir vários pontos finais de API, é uma boa prática ter scripts de consumo de API em arquivos separados.
7. Por fim, adicione o código abaixo ao arquivo invoices.py, onde uma função get_pages gerencia a paginação da sua API.
Esta função retorna o número total de páginas na sua API e ajuda a função range a iterar por todas as páginas.
Entre em contato com os desenvolvedores da sua API sobre o método de paginação usado pelo fornecedor da sua API.
Se preferir adicionar mais pontos finais da API aos seus dados:
- Repita as etapas quatro a seis da seção “Gerenciando Bancos de Dados MySQL com o DBeaver”.
- Repita todas as etapas da seção “Obtendo e Consumindo Dados da API”.
- Altere o ponto final da API para outro que deseja consumir.
Sincronizando Pontos Finais da API
Agora você tem um banco de dados e uma conexão de API, e está pronto para iniciar o consumo da API executando o código no arquivo invoices.py. Mas fazer isso limitaria você a consumir um ponto final da API simultaneamente.
Como ultrapassar o limite? Você criará outro arquivo Python como um arquivo central que chama funções da API de vários arquivos Python e executa as funções de forma assíncrona usando AsyncIO. Dessa forma, você mantém sua programação organizada e permite agrupar várias funções juntas.
1. Crie um novo arquivo Python chamado central.py e adicione o código abaixo.
Semelhante ao arquivo invoices.py, você adicionará trechos de código ao arquivo central.py em cada etapa, mas pode visualizar o código completo em GitHub da ATA.
O código abaixo importa módulos essenciais e scripts de outros arquivos usando a sintaxe from <filename> import <function name>.
2. Em seguida, adicione o seguinte código para controlar os scripts de invoices.py no arquivo central.py.
Você precisa referenciar/chamar a função call_invoices de invoices.py para uma tarefa AsyncIO (invoice_task) em central.py.
3. Após criar a tarefa AsyncIO, aguarde a execução da função call_invoices de invoice.py assim que a função chain (no passo dois) começar a ser executada.
4. Crie um AsyncIOScheduler para agendar uma tarefa para o script executar. A tarefa adicionada neste código executa a função chain em intervalos de um segundo.
Esta tarefa é importante para garantir que o seu programa continue executando os scripts e mantenha seus dados atualizados.
5. Por fim, execute o script central.py no VS Code, como mostrado abaixo.
Após executar o script, você verá a saída no terminal como a mostrada abaixo.
Abaixo, a saída confirma que as faturas foram adicionadas ao banco de dados.
Desenvolvendo Power BI Visuals
Depois de codificar um programa que se conecta e consome dados de API, e os envia para um banco de dados, você está quase pronto para colher seus dados. Mas antes, você enviará os dados do banco para o Power BI para visualização, o objetivo final.
Muitos dados são inúteis se você não puder visualizá-los e fazer conexões profundas. Felizmente, as visualizações do Power BI são como gráficos que tornam equações matemáticas complicadas simples e previsíveis.
1. Abra o Power BI a partir do seu Desktop ou menu Iniciar.
2. Clique no ícone da fonte de dados acima do menu suspenso Obter dados na janela principal do Power BI. Uma janela pop-up aparece onde você pode selecionar a fonte de dados a ser usada (passo três).
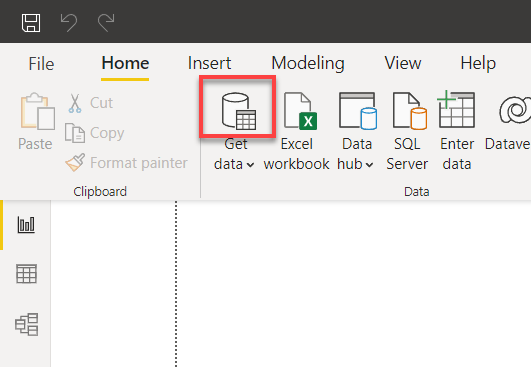
3. Procure por mysql, selecione Banco de Dados MySQL e clique em Conectar para iniciar a conexão com seu banco de dados MySQL.
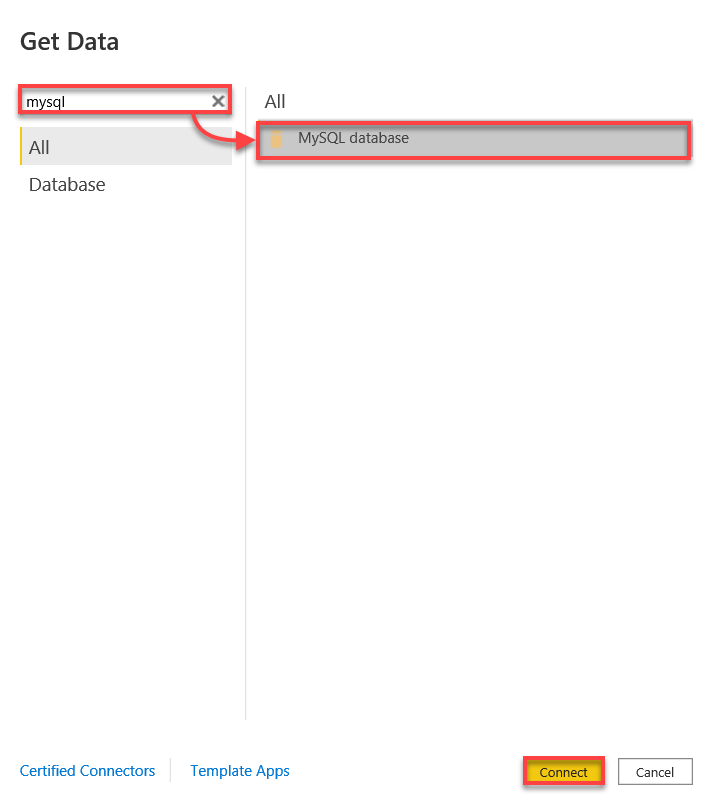
4. Agora, conecte-se ao seu banco de dados MySQL com o seguinte:
- Insira localhost:3306 pois você está se conectando ao seu servidor MySQL local na porta 3306.
- Forneça o nome do seu banco de dados, neste caso, ata_db.
- Clique em OK para se conectar ao seu banco de dados MySQL.

5. Agora, clique em Transformar Dados (canto inferior direito) para ver a visão geral dos dados no Editor de Consulta do Power BI (passo cinco).

6. Após visualizar a fonte de dados, clique em Fechar e Aplicar para voltar à aplicação principal e confirmar se alguma alteração foi aplicada.
O editor de consulta mostra tabelas da sua fonte de dados no canto esquerdo. Ao mesmo tempo, você pode verificar o formato dos dados antes de prosseguir para a aplicação principal.
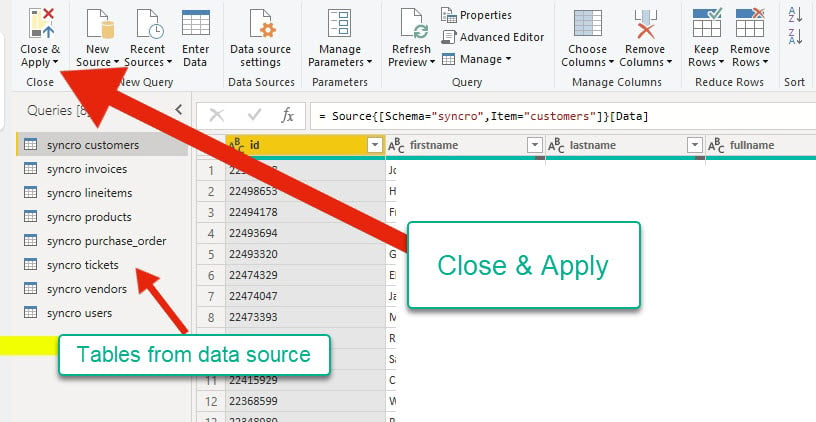
7. Clique na guia de fitas Ferramentas de Tabela, selecione qualquer tabela no Painel de Campos e clique em Gerenciar Relacionamentos para abrir o assistente de relacionamento.
Antes de criar visuais, você deve garantir que suas tabelas estejam relacionadas, então especifique qualquer relacionamento entre suas tabelas explicitamente. Por quê? O Power BI ainda não detecta automaticamente correlações de tabela complexas.

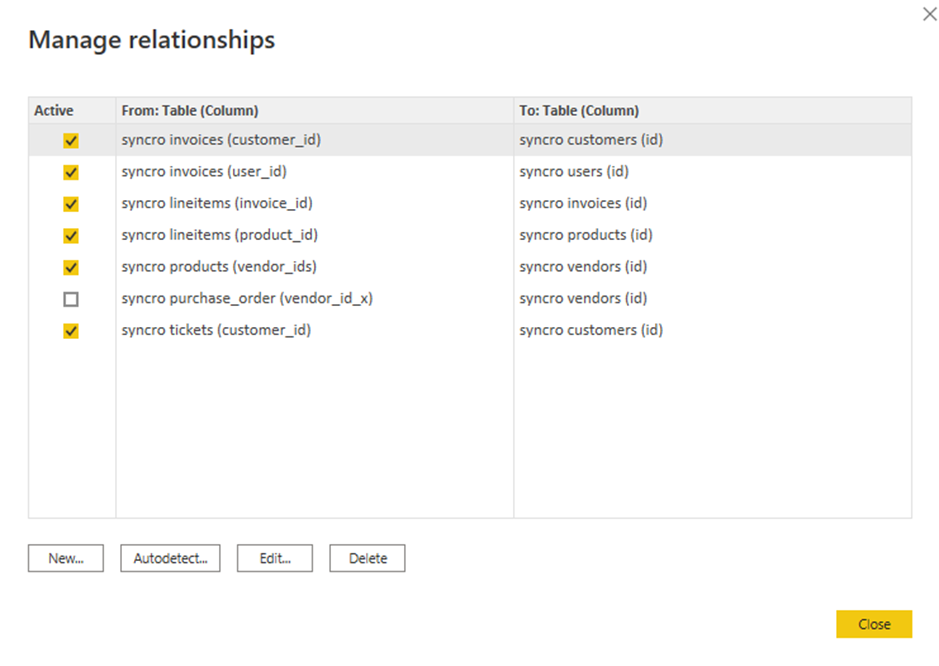
8. Marque as caixas dos relacionamentos existentes para editar e clique em Editar. Uma janela pop-up aparece, onde você pode editar os relacionamentos selecionados (passo nove).
Mas se preferir adicionar um novo relacionamento, clique em Novo em vez disso.
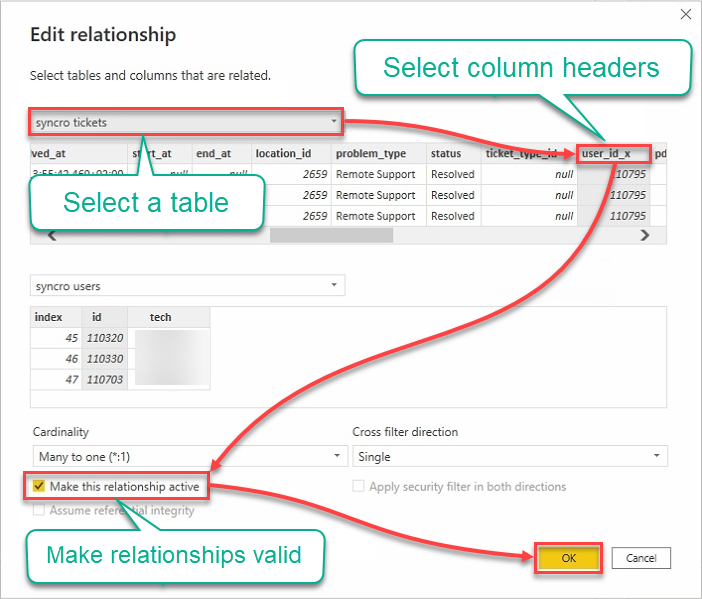
9. Edite os relacionamentos com o seguinte:
- Clique no campo de menu suspenso de tabelas e selecione uma tabela.
- Clique nos cabeçalhos para selecionar as colunas a serem usadas.
- Marque a caixa Tornar este relacionamento ativo para garantir que os relacionamentos sejam válidos.
- Clique em OK para estabelecer o relacionamento e fechar a janela de Edição de relacionamento.
10. Agora, clique no tipo de visualização Tabela sob o painel Visualizações (mais à direita) para criar sua primeira visualização, e uma visualização de tabela vazia aparece (passo 11).
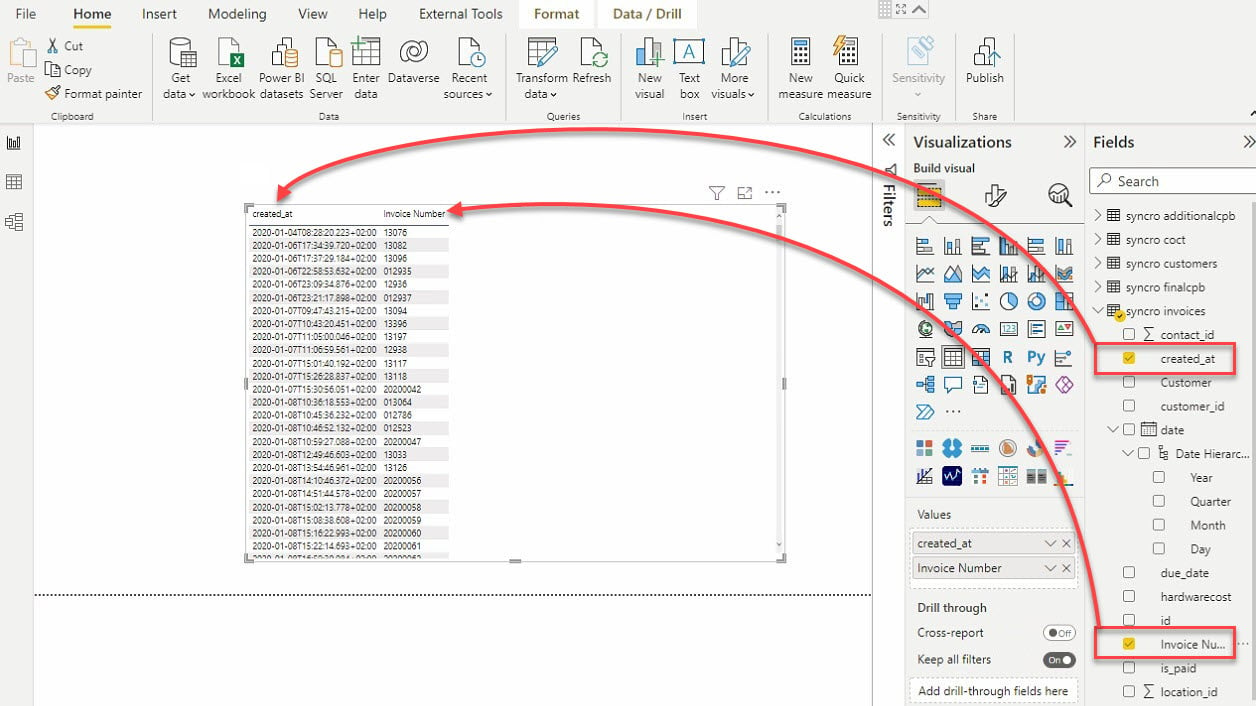
11. Selecione a visualização da tabela e os campos de dados (no painel Campos) para adicionar à sua visualização de tabela, conforme mostrado abaixo.
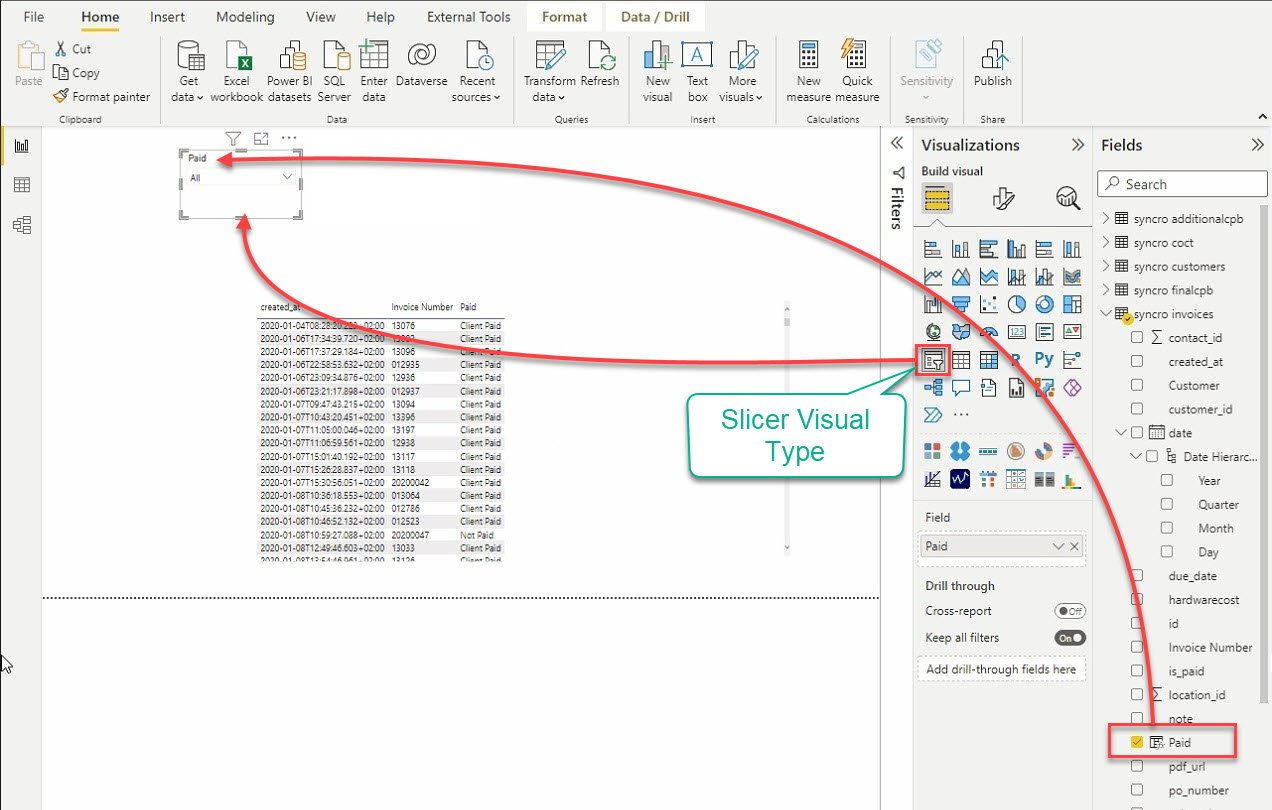
12. Por fim, clique no tipo de visualização Filtro para adicionar outro visual. Como o nome sugere, o visual de filtro fatia dados filtrando outras visualizações.
Depois de adicionar o filtro, selecione dados no painel Campos para adicionar à visualização do filtro.
Alterando Visualizações
As aparências padrão das visualizações são bastante decentes. Mas não seria ótimo se você pudesse mudar a aparência das visualizações para algo menos sem graça? Deixe o Power BI fazer a mágica.
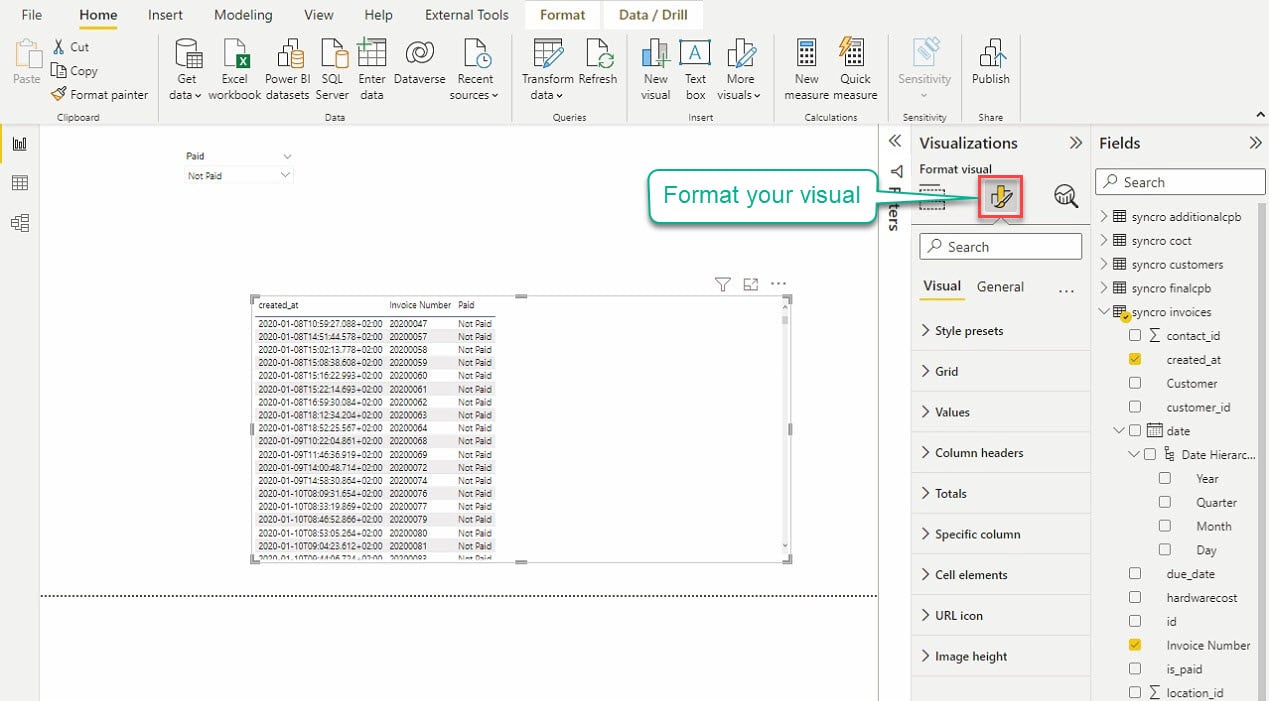
Clique no ícone Formatar sua visualização sob a visualização para acessar o editor de visualização, conforme mostrado abaixo.
Passe algum tempo brincando com as configurações de visualização para obter a aparência desejada para suas visualizações. Suas visualizações se correlacionarão desde que você estabeleça um relacionamento entre as tabelas que envolve em suas visualizações.
Após alterar as configurações de visualização, você pode gerar relatórios como os abaixo.
Agora, você pode visualizar e analisar seus dados sem complexidade ou cansar seus olhos.
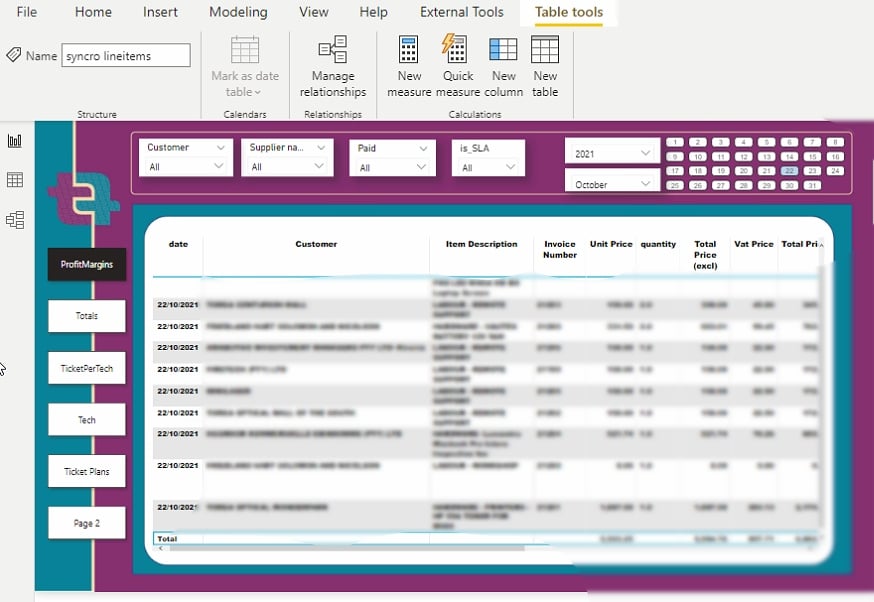
Na seguinte visualização, ao observar o gráfico de tendências, você verá que algo deu errado em abril de 2020. Naquela época, foi quando os bloqueios relacionados à Covid-19 atingiram inicialmente a África do Sul.
Este resultado apenas comprova a eficácia do Power BI em fornecer visualizações de dados precisas.

Conclusão
Este tutorial tem como objetivo mostrar como estabelecer um pipeline de dados dinâmico ao vivo, obtendo seus dados de pontos de extremidade da API. Além disso, processando e enviando dados para seu banco de dados e Power BI usando Python. Com esse conhecimento recém-adquirido, agora você pode consumir dados da API e criar suas próprias visualizações de dados.
Cada vez mais empresas estão criando aplicativos da web Restful API. E, neste momento, você está confiante em consumir APIs usando Python e criar visualizações de dados com o Power BI, o que pode ajudar a influenciar as decisões comerciais.