













您的管理层是否想要了解公司的财务和生产力的方方面面,但却不愿意花一分钱购买顶级的IT管理工具?不要再为了库存、计费和票务系统而使用不同的工具。您只需要一个集中的系统。为什么不考虑使用Power BI Python呢?
Power BI可以将繁琐而耗时的任务转变为自动化的过程。在本教程中,您将学习如何以您无法想象的方式切片和组合您的数据。
快来吧,节省自己在复杂报告中费眼睛的压力吧!
先决条件
本教程将进行实际演示。如果您想跟着做,请确保您具备以下条件:
- Power BI 订阅 – 免费试用即可。
- A Windows Server – This tutorial uses a Windows Server 2022.
- 已安装在您的Windows Server 上的Power BI Desktop – 本教程使用Power BI Desktop v2.105.664.0。
- 已安装的MySQL Server – 本教程使用MySQL Server v8.0.29。
- 已在计划使用桌面版本的外部设备上安装本地数据网关。
- Visual Studio Code(简称 VS Code)- 本教程使用 VS Code v17.2
- 已安装 Python v3.6 或更新版本 – 本教程使用 Python v3.10.5。
- 已安装 DBeaver – 本教程使用 DBeaver v22.0.2。
构建 MySQL 数据库
Power BI 可以美观地可视化数据,但在进行数据可视化之前,您需要获取和存储数据。存储数据的最佳方式之一是使用数据库。MySQL 是一个免费且功能强大的数据库工具。
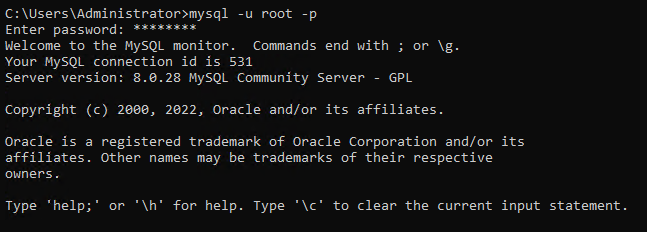
1. 以管理员身份打开 命令提示符,运行下面的 mysql 命令,并在提示时输入 root 用户名 (-u) 和密码 (-p)。
默认情况下,只有 root 用户有权限对数据库进行更改。
2. 接下来,运行以下查询以创建一个新的数据库用户(CREATE USER),并设置密码(IDENTIFIED BY)。您可以为用户命名,但本教程选择的名称是 ata_levi。

3. 创建用户后,运行以下查询以授予新用户权限(ALL PRIVILEGES),例如在服务器上创建数据库。

4. 现在,运行以下 \q 命令以注销 MySQL。

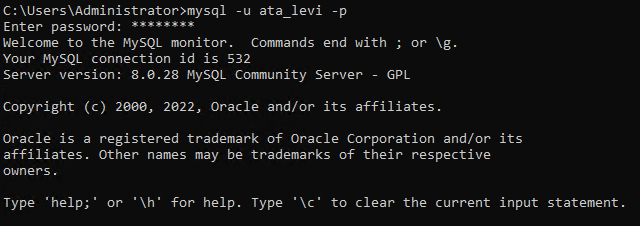
5. 运行以下 mysql 命令以使用新创建的数据库用户(ata_levi)登录。
6. 最后,运行以下查询以创建名为 ata_database 的新数据库。当然,您可以为数据库取不同的名称。

使用 DBeaver 管理 MySQL 数据库
在管理数据库时,通常需要具备 SQL 知识。但是使用 DBeaver,您可以通过几次点击来管理您的数据库,并且 DBeaver 将为您处理 SQL 语句。
1. 从桌面或开始菜单打开 DBeaver。
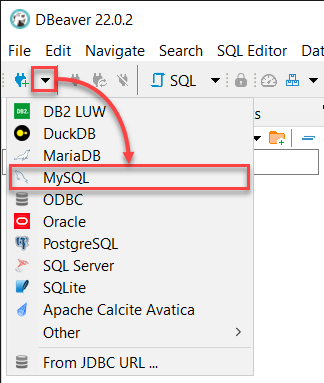
2. 当 DBeaver 打开时,单击新数据库连接下拉菜单,并选择 MySQL 以连接到您的 MySQL 服务器。
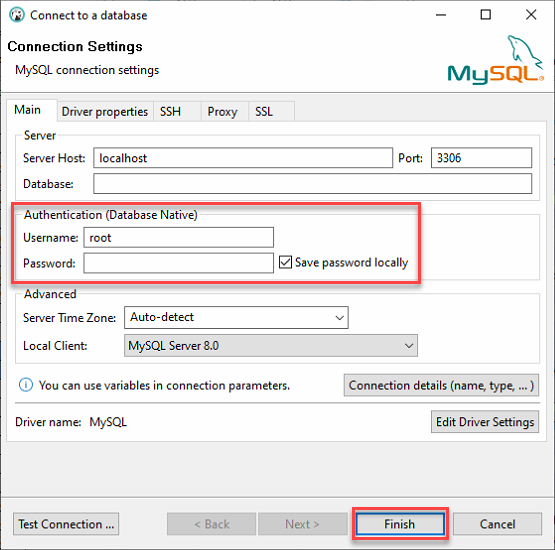
3. 使用以下方式登录到本地 MySQL 服务器:
- 将 服务器主机 保留为 localhost,并将 端口 设置为 3306,因为您正在连接到本地服务器。
- 提供来自“构建 MySQL 数据库”部分第二步的 ata_levi 用户的凭据(用户名和密码),然后单击“完成”以登录到 MySQL。
4. 现在,在数据库导航器(左侧面板)下扩展您的数据库(ata_database) → 右键单击 Tables,然后选择创建新表来初始化创建新表。
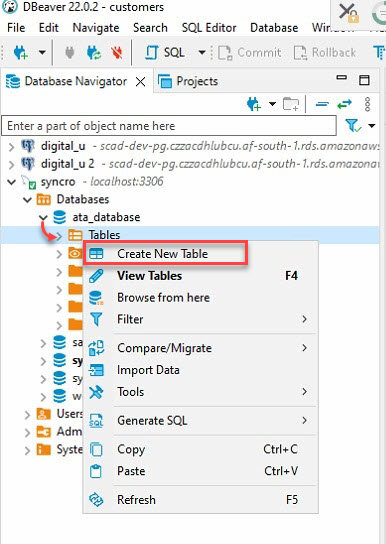
5. 给您的新表取个名字,但本教程的选择是 ata_Table,如下所示。
确保表名与“获取和使用 API 数据”部分第七步中将在 to_sql(“表名”)方法中指定的表名相匹配。
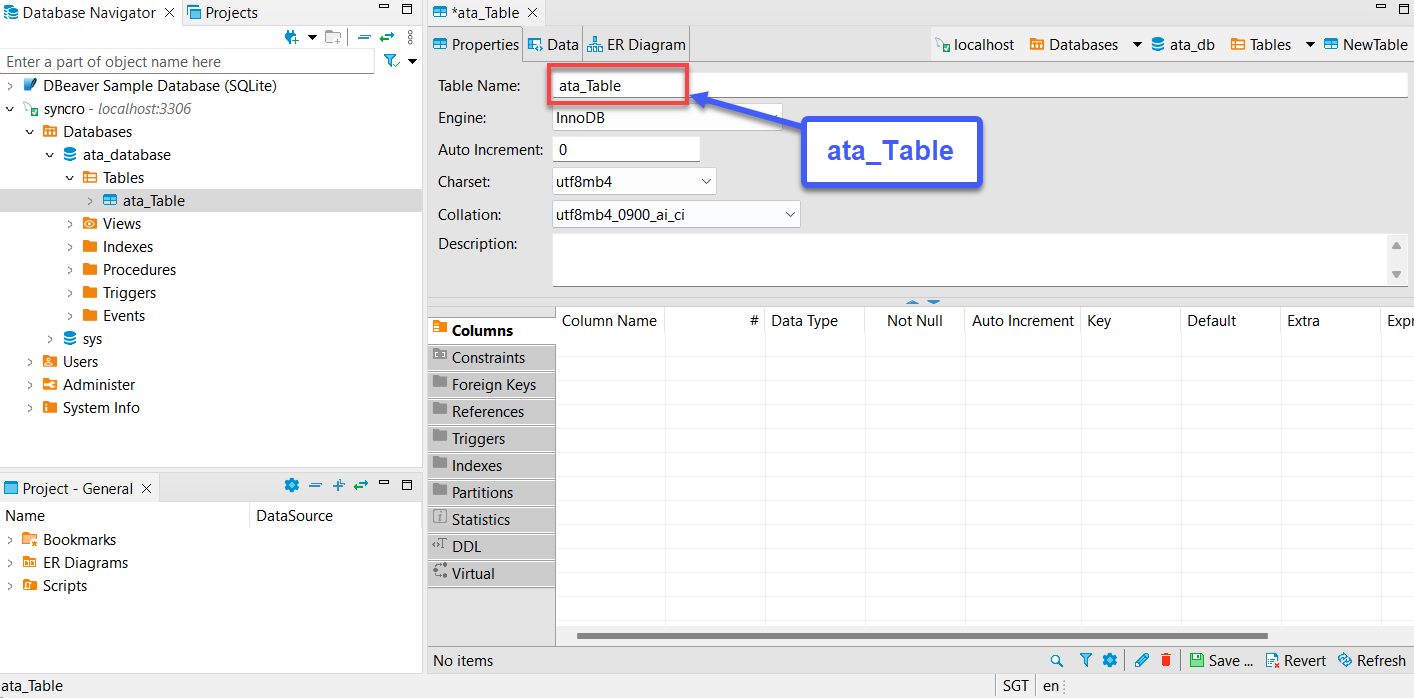
6. 接下来,扩展新表(ata_table) → 右键单击 Columns → 创建新列以创建新列。
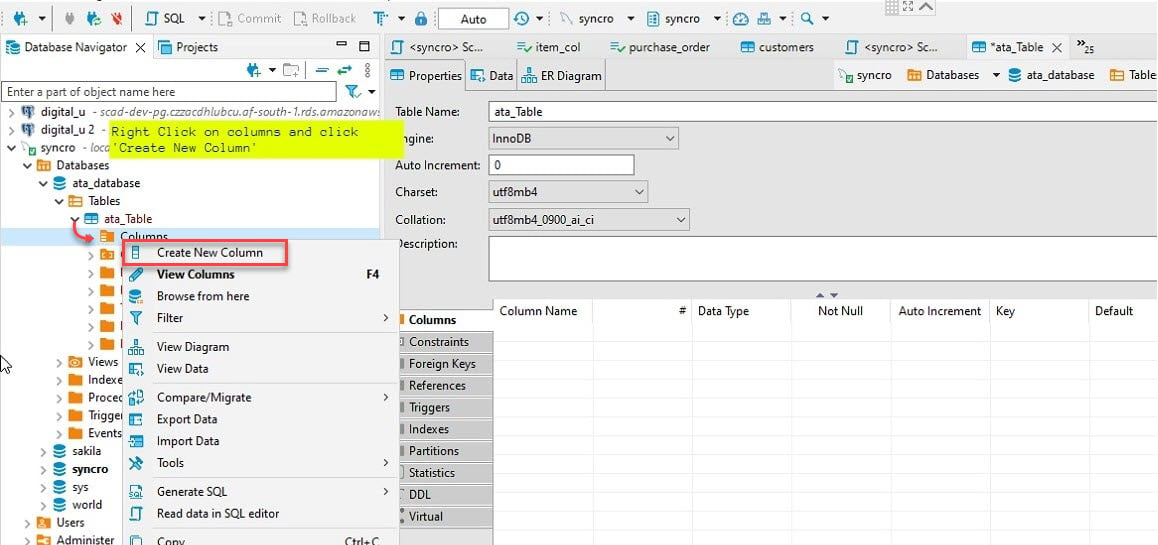
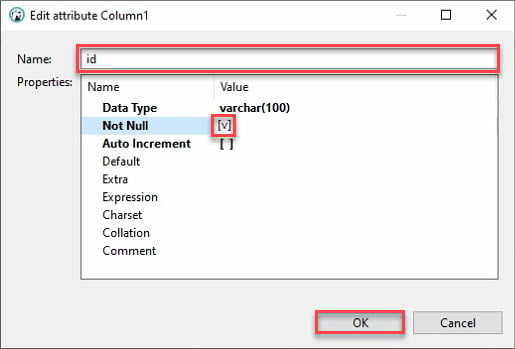
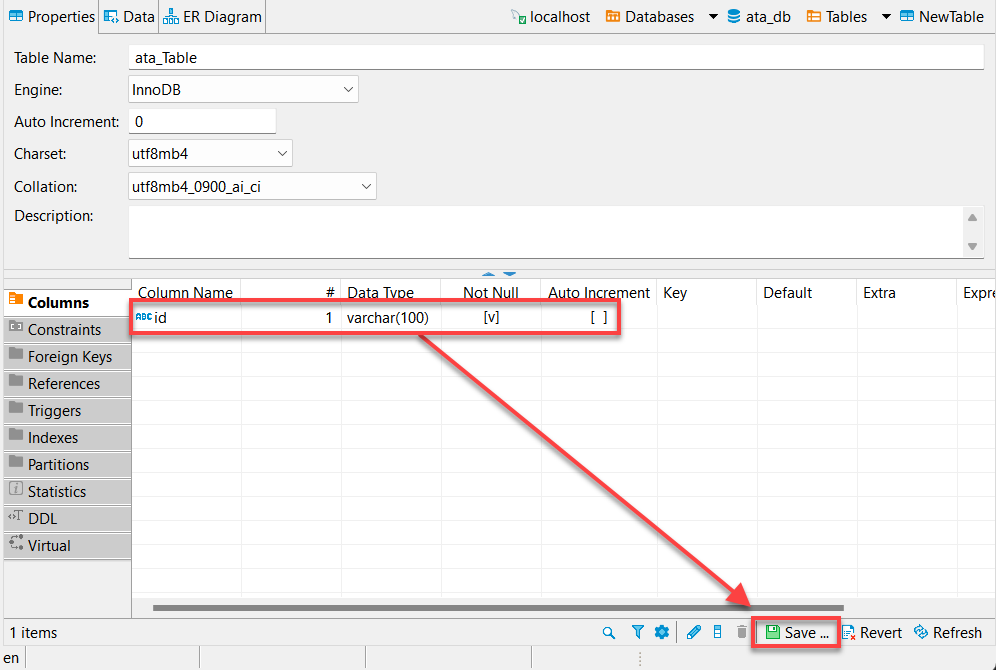
7. 提供列名,如下所示,并选中 Not Null 复选框,然后点击确定以创建新列。
理想情况下,您可能想添加一个名为“id”的列。为什么呢?因为大多数 API 都会有一个 id,而 Python 的 pandas 数据框会自动填充其他列。
8. 点击保存(右下角)或按 Ctrl+S 保存更改,一旦您已验证新创建的列(id)。如下所示。
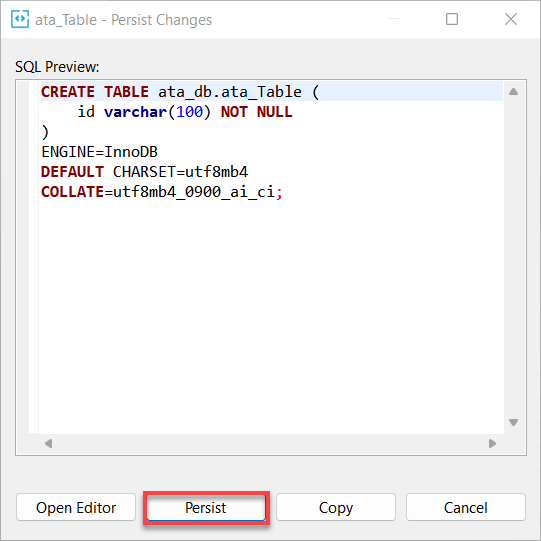
9. 最后,点击 Persist 以将您对数据库所做的更改持久保存。
获取和使用 API 数据
既然您已经创建了用于存储数据的数据库,您需要从相应的 API 提供者那里获取数据,并使用 Python 将其推送到您的数据库。您将源化数据以在 Power BI 上进行可视化。
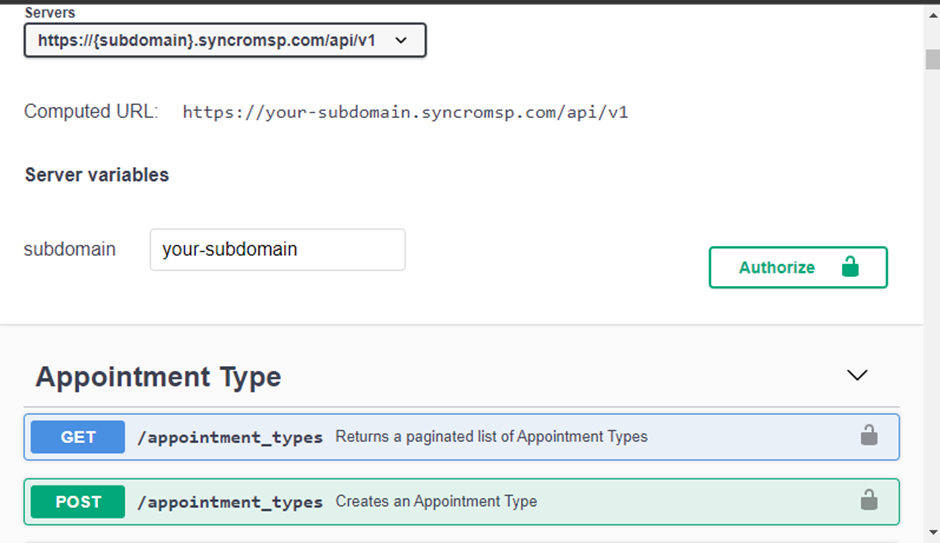
要连接到 API 提供者,您将需要三个关键信息:授权方法、API 基本 URL 和 API 端点。如果对此信息或如何获取此信息有疑问,请访问您的 API 提供者的文档站点。
以下是来自Syncro的文档页面。
1. 打开VS Code,创建一个Python文件,并根据文件预期的API数据命名文件。该文件将负责从API获取数据并将数据推送到您的数据库(数据库连接)。
有多个Python库可用于帮助进行数据库连接,但在本教程中,您将使用SQLAalchemy。
在VS Code的终端上运行下面的pip命令,以在您的环境中安装SQLAalchemy。

2. 接下来,创建一个名为connection.py的文件,填写下面的代码,替换相应的值,并保存文件。
在开始编写与数据库通信的脚本之前,必须在数据库接受任何命令之前建立与数据库的连接。
但是,不必为您编写的每个脚本重新编写数据库连接字符串,下面的代码致力于使此连接能够被其他脚本调用/引用。
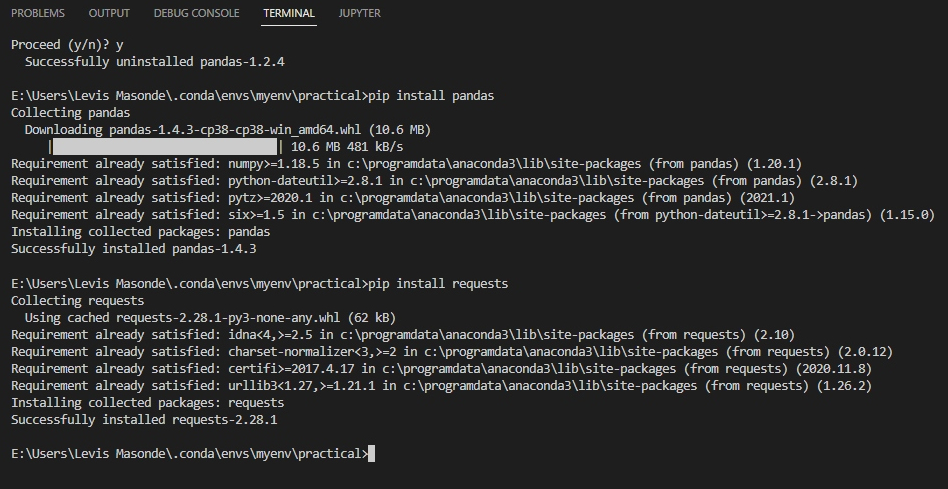
3. 打开 Visual Studio 的终端(Ctrl+Shift+`),并运行以下命令安装 pandas 和 requests。
4. 创建另一个名为 invoices.py 的 Python 文件(或以其他名称命名),并将下面的代码填充到文件中。
您将在随后的每个步骤中向 invoices.py 文件添加代码片段,但您可以在 ATA 的 GitHub 上查看完整的代码。
invoices.py 脚本将从下一节中描述的主要脚本中运行,该主要脚本会拉取您的第一个 API 数据。
以下代码执行以下操作:
- 消费来自您的 API 的数据并将其写入您的数据库。
- 用您的 API 提供者凭据替换授权方法、密钥、基本 URL 和 API 端点。
5. 将下面的代码片段添加到 invoices.py 文件中以定义标题,例如:
- 您期望从您的 API 接收的数据格式类型。
- 基本 URL 和端点应该与授权方法和相应的密钥一起。
请务必将下面的值更改为您自己的值。
6. 接下来,将以下异步函数添加到invoices.py文件中。
下面的代码使用AsyncIO来从一个主脚本管理多个脚本,如下一节所述。当您的项目扩展到包括多个API端点时,有一个良好的实践是让您的API消耗脚本拥有它们自己的文件。
7. 最后,将以下代码添加到invoices.py文件中,其中get_pages函数处理API的分页。
此函数返回API中的总页面数,并帮助range函数迭代所有页面。
联系您的API提供商开发人员了解您的API提供商使用的分页方法。
如果您希望向您的数据添加更多API端点:
- 重复“使用DBeaver管理MySQL数据库”部分的第四到第六步。
- 重复“获取和使用API数据”部分的所有步骤。
- 将API端点更改为您希望使用的另一个端点。
同步API端点
现在您有了数据库和API连接,可以通过运行invoices.py文件来开始API消费。但这样做将限制您同时使用一个API端点。
如何超越极限?您将创建另一个Python文件作为中心文件,该文件调用来自各个Python文件的API函数,并使用AsyncIO异步运行这些函数。这样,您可以保持编程的清晰性,并允许将多个函数捆绑在一起。
1. 创建一个名为central.py的新Python文件,并添加下面的代码。
类似于invoices.py文件,您将在每个步骤中向central.py文件添加代码片段,但是您可以在ATA的GitHub上查看完整的代码。
下面的代码导入了必要的模块,并使用from <filename> import <function name>语法从其他文件导入了脚本。
2. 接下来,在central.py文件中添加以下代码来控制来自invoices.py的脚本。
您需要引用/调用来自invoices.py的call_invoices函数到central.py中的AsyncIO任务(invoice_task)中。
3. 创建AsyncIO任务后,等待任务以执行调用invoice.py中的call_invoices函数,一旦链式函数(在第二步中)开始运行。
4. 创建一个AsyncIOScheduler来为脚本安排一个作业。此代码中添加的作业以一秒的间隔运行链式函数。
此作业很重要,以确保您的程序一直运行脚本以保持数据更新。
5. 最后,在VS Code上运行central.py脚本,如下所示。
运行脚本后,您将在终端上看到如下输出。
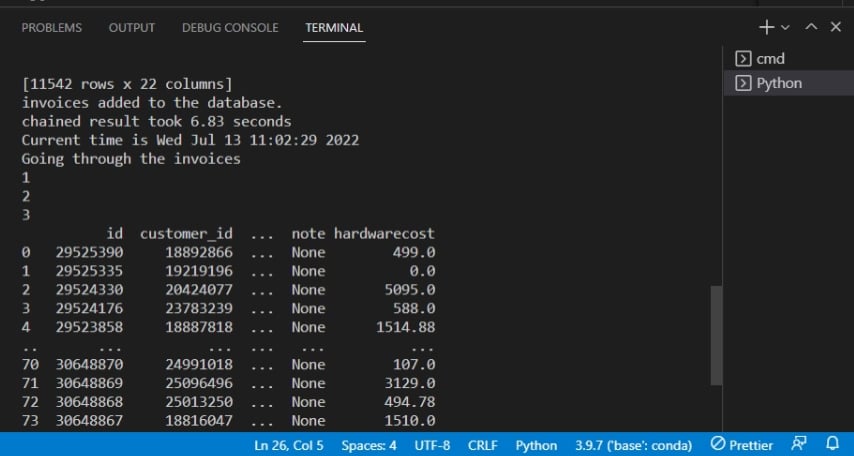
下面的输出确认发票已添加到数据库。
开发Power BI Visuals
在编写一个连接到和使用API数据并将此数据推送到数据库的程序之后,您几乎准备好收获您的数据。但首先,您将把数据库中的数据推送到Power BI进行可视化,这是最终目标。
大量的数据是无用的,如果您无法可视化数据并进行深刻的连接。幸运的是,Power BI可视化就像图表如何使复杂的数学方程式看起来简单而可预测一样。
1. 从您的桌面或开始菜单打开Power BI。
2. 点击Power BI主窗口上方的“获取数据”下拉菜单旁边的数据源图标。弹出一个窗口,您可以在其中选择要使用的数据源(第三步)。
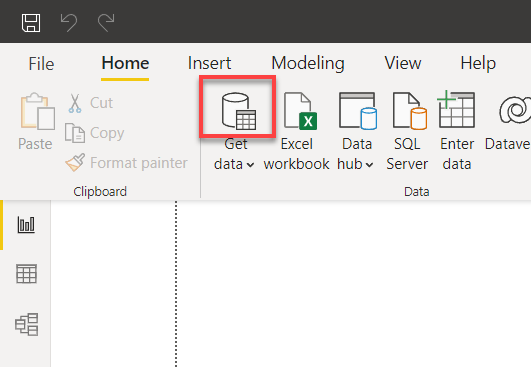
3. 搜索mysql,选择MySQL数据库,然后点击连接以初始化与MySQL数据库的连接。
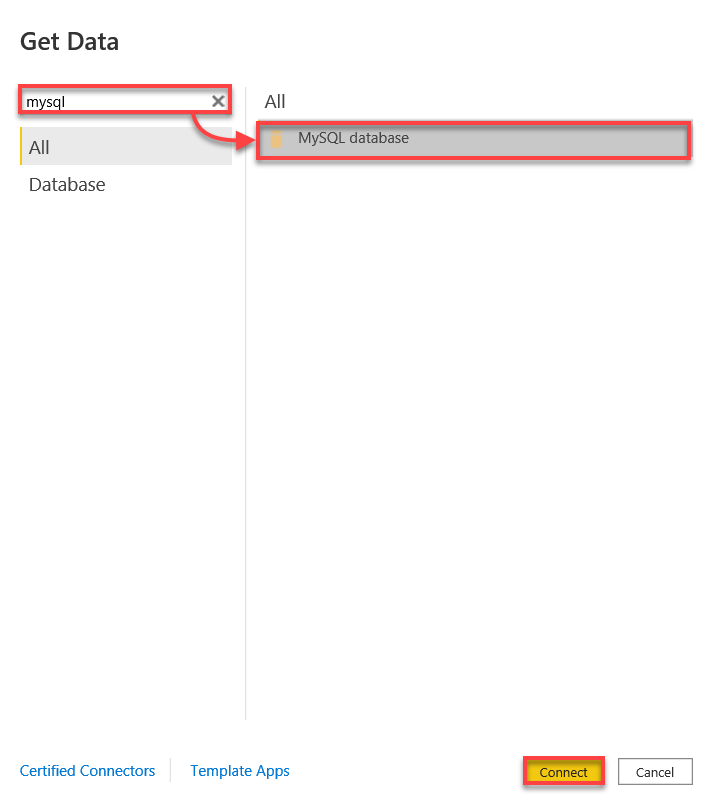
4. 现在,使用以下信息连接到您的MySQL数据库:
- 输入localhost:3306,因为您要连接到本地MySQL服务器的3306端口。
- 提供您的数据库名称,本例中为ata_db。
- 点击“确定”以连接到您的MySQL数据库。

5. 现在,点击“转换数据”(右下角)以查看Power BI查询编辑器中的数据概览(第五步)。

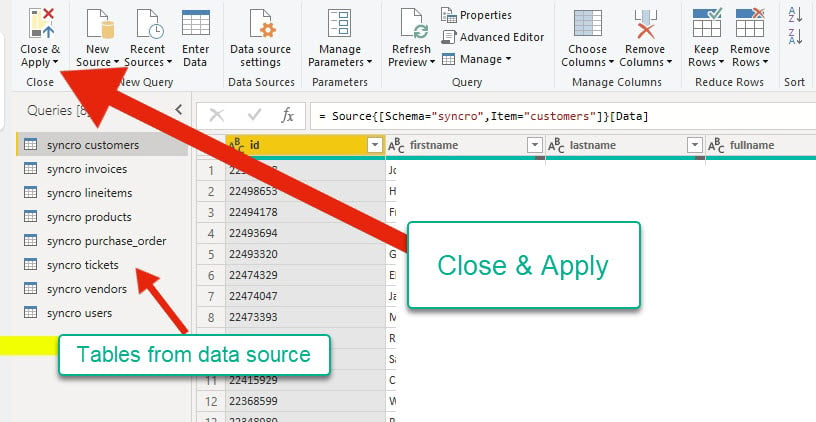
6. 在预览数据源后,点击“关闭并应用”返回到主应用程序,并确认是否应用了任何更改。
查询编辑器在最左侧显示来自数据源的表。同时,您可以在转到主应用程序之前检查数据的格式。
7. 点击“表格工具”选项卡,选择字段窗格上的任何表格,然后点击“管理关系”以打开关系向导。
在创建可视化之前,您必须确保表格之间存在关系,因此明确指定表格之间的任何关系是必要的。为什么呢?因为Power BI尚未自动检测复杂的表关联。

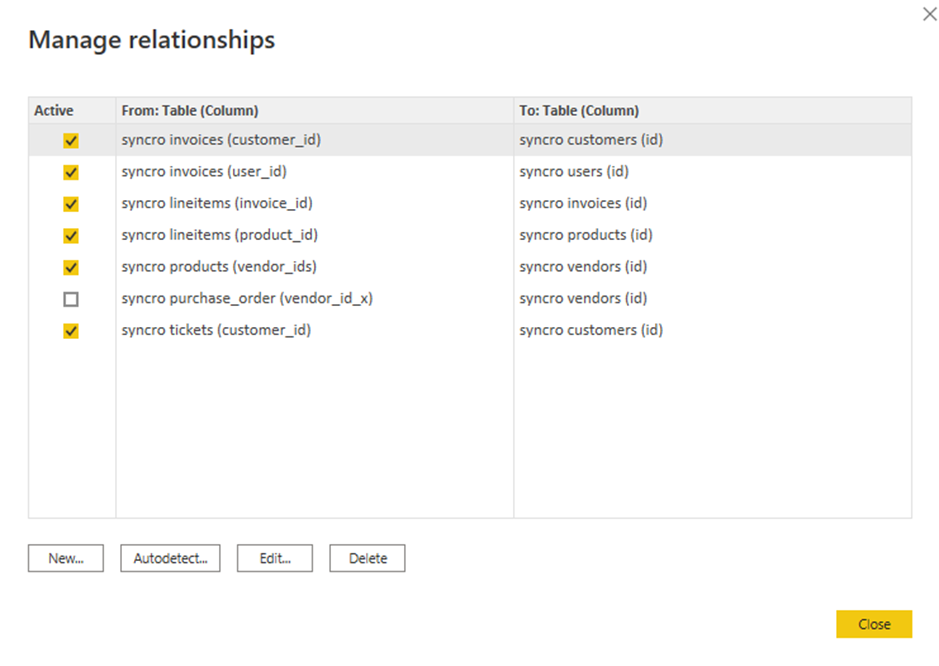
8. 勾选现有关系的框以进行编辑,然后点击“编辑”。弹出一个窗口,您可以在其中编辑所选的关系(第九步)。
但如果您愿意添加新的关系,请点击“新建”按钮。
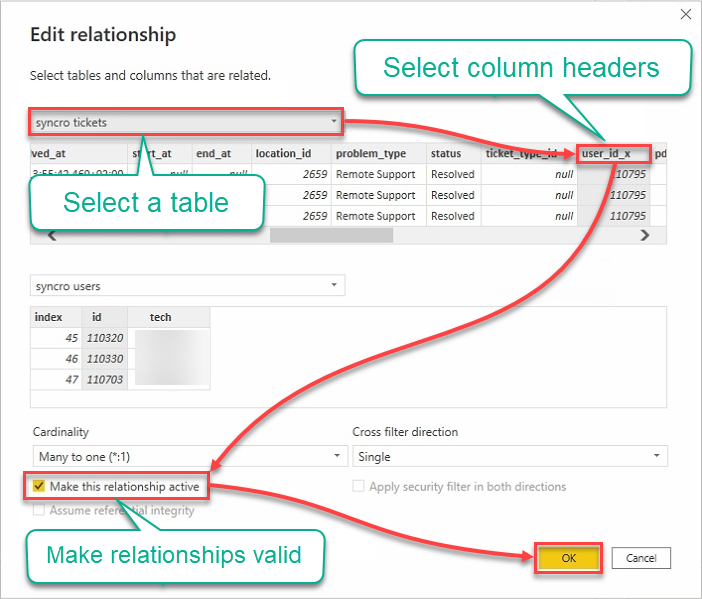
9. 使用以下步骤编辑关系:
- 点击表格下拉菜单,并选择一个表格。
- 点击标题以选择要使用的列。
- 勾选“激活此关系”框以确保关系有效。
- 点击“确定”以建立关系并关闭编辑关系窗口。
10. 现在,点击“可视化”窗格下的“表格”可视化类型(最右侧),以创建您的第一个可视化效果,并显示一个空的表格可视化效果(步骤11)。
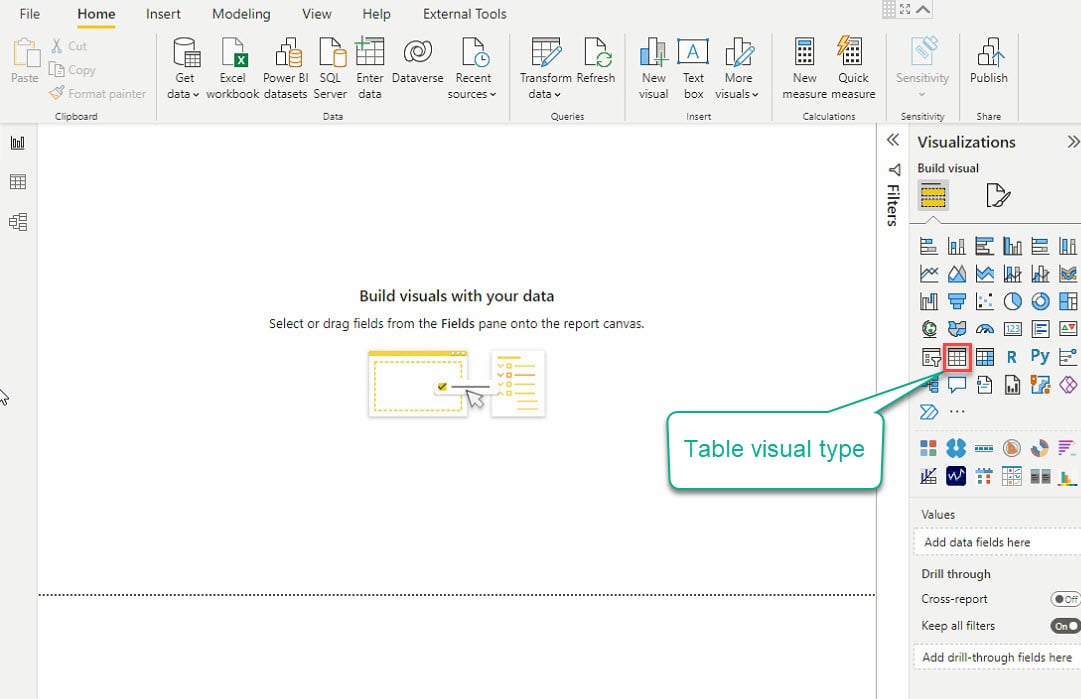
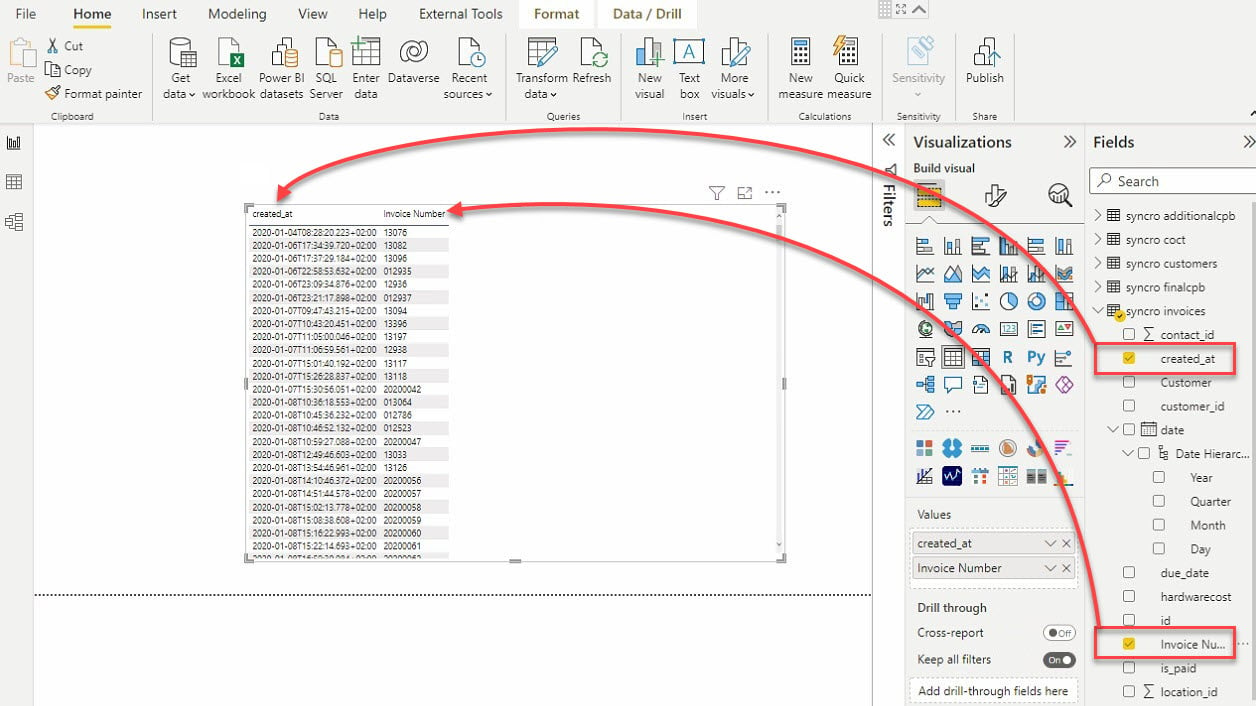
11. 选择表格可视化效果和要添加到表格可视化效果中的数据字段(在字段窗格上),如下所示。
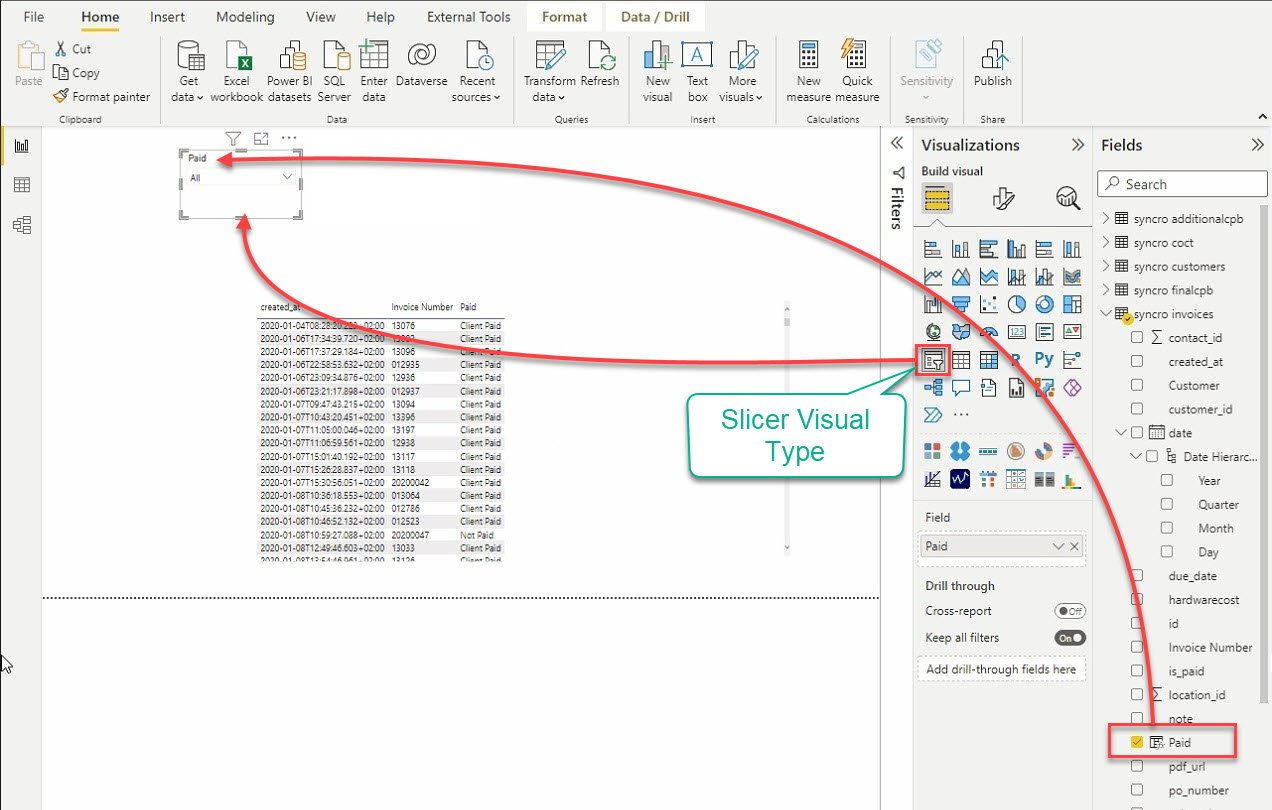
12. 最后,点击“切片器”可视化类型以添加另一个可视化效果。顾名思义,“切片器”可视化效果通过筛选其他可视化效果来切片数据。
添加切片器后,从字段窗格中选择数据以添加到切片器可视化效果中。
更改可视化效果
默认的可视化效果看起来相当不错。但是,如果您能将可视化效果更改为不那么单调的样式,岂不是更好?让 Power BI 来实现吧。
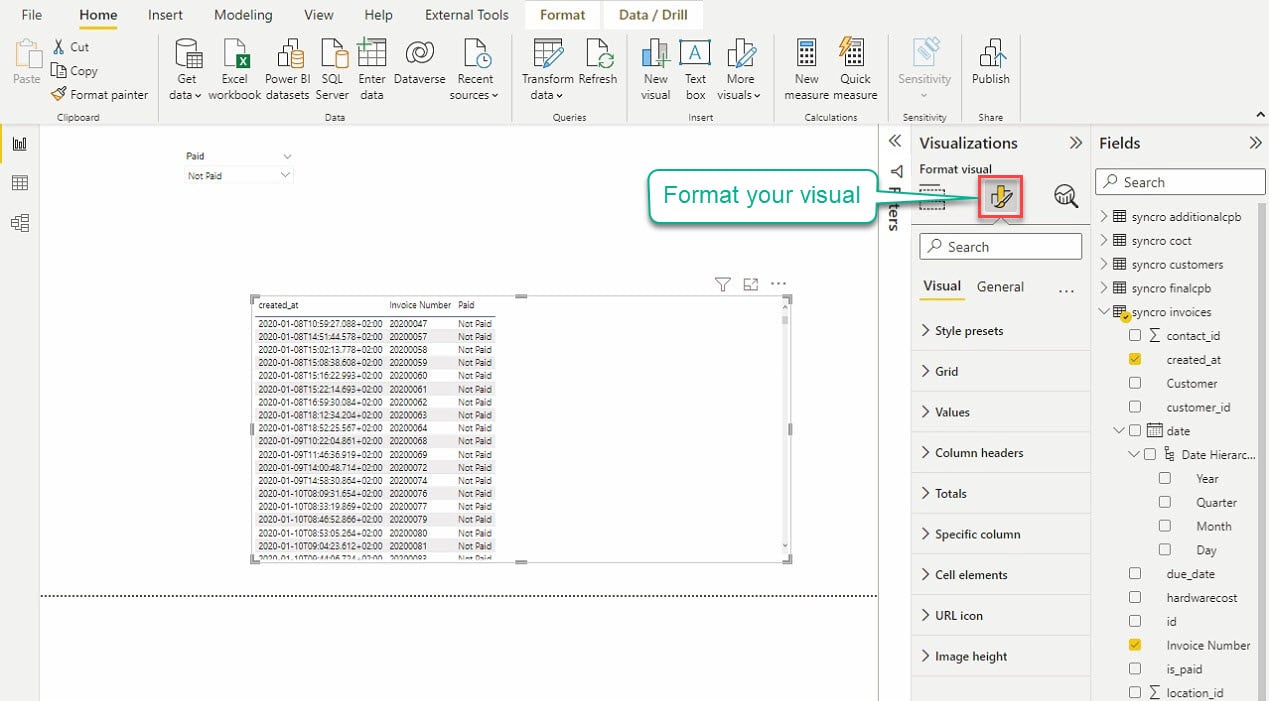
点击可视化下的“格式化您的可视化效果”图标,以访问可视化编辑器,如下所示。
花一些时间调整可视化设置,以获得您所期望的可视化效果。只要您在可视化效果中涉及的表格之间建立了关系,您的可视化效果将会相关联。
更改可视化设置后,您可以生成如下报告。
现在,您可以轻松可视化和分析数据,而不会增加复杂性或伤害您的眼睛。
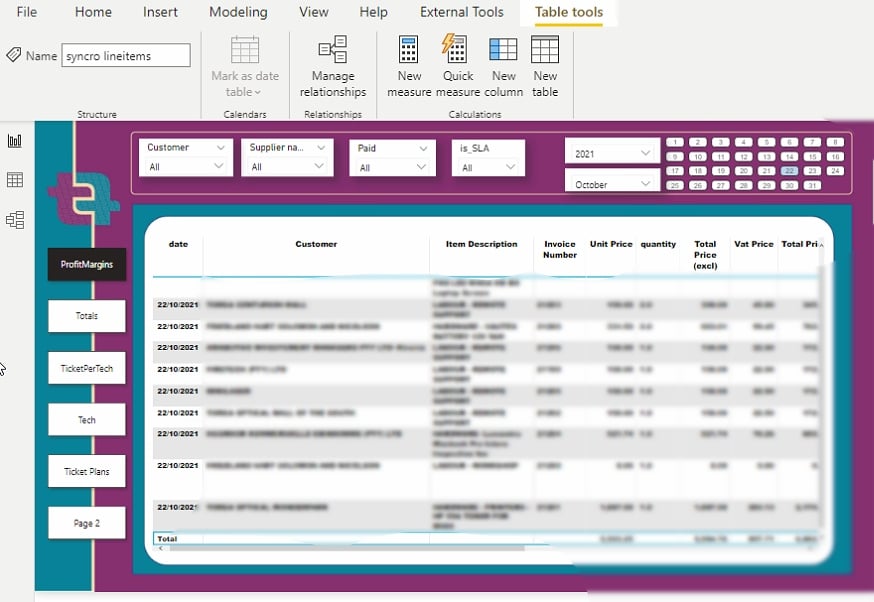
在下面的可视化中,观察趋势图,您会发现2020年4月发生了一些问题。那是 Covid-19 封锁措施首次影响南非的时候。
这个输出仅证明了 Power BI 在提供准确数据可视化方面的能力。

结论
本教程旨在向您展示如何通过从 API 端点获取数据来建立实时动态数据管道。此外,使用 Python 处理和推送数据到您的数据库和 Power BI。有了这些新知识,您现在可以使用 API 数据并创建自己的数据可视化。
越来越多的企业正在创建 Restful API web 应用程序。此时,您已经可以自信地使用 Python 消耗 API 并使用 Power BI 制作数据可视化,这有助于影响业务决策。