













距離度量是數據科學和機器學習中众多算法的基础,使能夠度量數據點之間的相似性或差異。在本文指南中,我們將探索Minkowski距離的基礎,其數學性質以及實現方式。我們將研究它與其他常見距離衡量方法的關係,並通過Python和R的程式實例來展示其應用。
無論你是在開發聚合算法,还是在處理異常检测,或者是在微調分類模型,了解Minkowski距離都可以提升你對數據分析與模型開發的方法。讓我們一探究竟。
Minkowski距離是什麼?
闵可夫斯基距離是一種多功能的度量,用於规范化向量空間中,以德國數學家赫尔曼·闵可夫斯基命名。它是一個多名義距離度量的一般化,使其成為各種領域(如數學、電腦科學和數據分析)的基本概念。
在其core中,闵可夫斯基距離提供了一种衡量多維空間中两点之間距離的方法。使其特别有用的是,它通過一個參數p能夠包含其他距離度量作為特殊情形,主要透過一個參數p。這個參數讓闵可夫斯基距離能夠適應不同的問題空間和數據特性。闵可夫斯基距離的一般公式為:
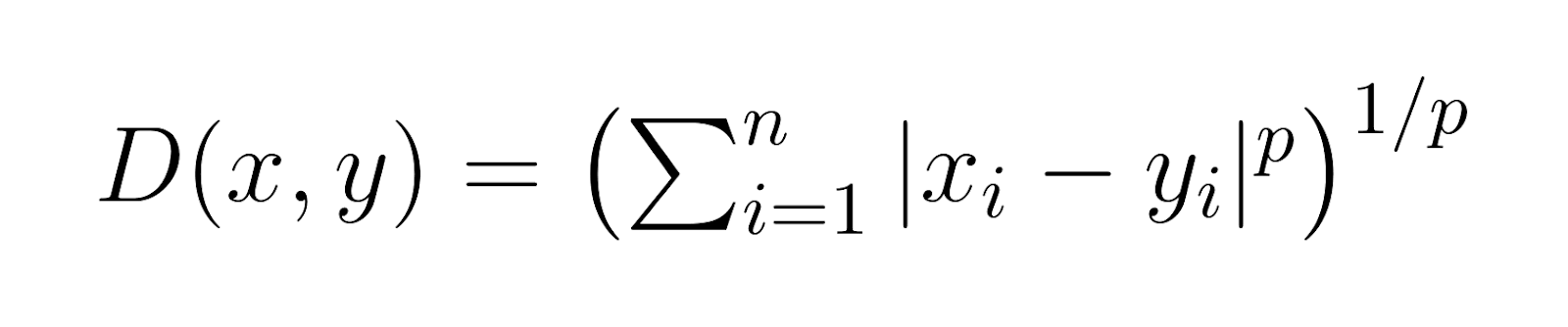
其中:
-
x和y是在 n 維空間中的兩點 -
p是一個決定距離類型的參數(p ≥ 1) -
|xi - yi|表示 x 和 y 在每個維度上坐标的絕對差異
Minkowski 距離有兩個主要用途。第一,它讓你有靈活性,按需切換 Manhattan 或 Euclidean 距離。第二,它認識到不是所有數據集(想想高維度空間)都適合纯粹的 Manhattan 或纯粹的 Euclidean 距離。
在實際中,參數 p 通常通過結合訓練/測試驗證工作流程來選擇。通過在交叉驗證過程中測試不同值的 p,你可以確定對於你的特定數據集哪个值提供最佳模型性能。
Minkowski 距離如何工作
讓我們看一下 Minkowski 距離与其他距離公式有何關係,然後通過一個示例走一遍。
其他距離度量的一般化
首先要考慮的是 Minkowski 距離公式中包含了曼哈頓、歐幾里得和切比雪夫距離的公式。
曼哈頓距離(p = 1):
當 p 設定為 1 時,Minkowski 距離成為曼哈頓距離。
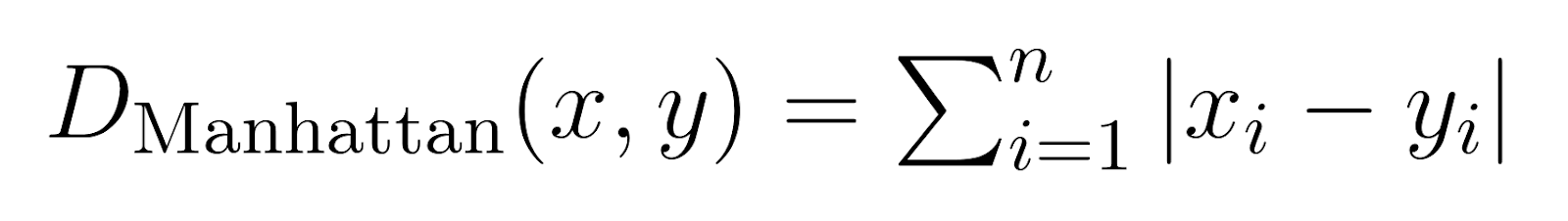
也稱為城市街区距離或 L1 范數,曼哈頓距離 度量的是絕對差的總和。
歐幾里得距離(p = 2):
當 p 設定為 2 時,Minkowski 距離成為歐幾里得距離。
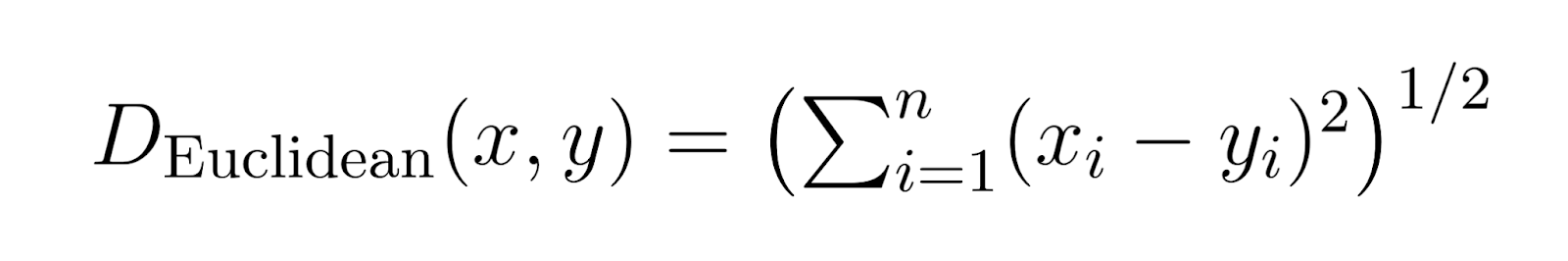
歐幾里得距離
是最常見的距離度量,代表兩點之間的直線距離。
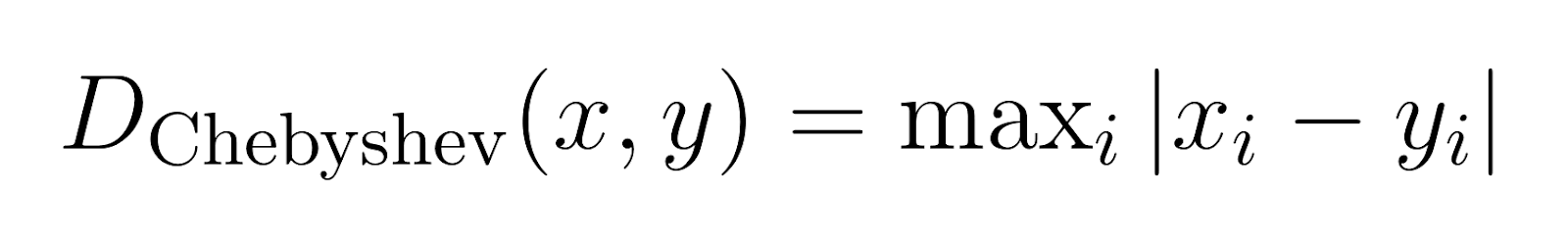
棋盤距離,又稱為Chebyshev距離,度量任何维度上的最大差異。
為了真正掌握Minkowski距離的功能和威力,讓我們通過一個例子來研究。這個探索將幫助我們理解p參數如何影響多維空間中距離的計算和解釋。
讓我們考慮2D空間中的兩個點:
- 點A:(2, 3)
- 點B:(5, 7)
我們将为不同的p值计算這些點之間的Minkowski距離。

p在Minkowski距離公式中的參數控制度量对单个组件差异的敏感性:
- 當p=1:所有差異以線性方式貢獻。
- 當p=2:由于平方,較大的差異具有更大的影響。
- 當p>2:更大的人工差更受重視。
- 當p→∞:在所有維度中只有最大的差異重要。
當p增加時,Minkowski距離通常會減少,逐漸接近Chebyshev距離。這是因為較高的p值会给较大的差異更多的權重,而給較小的差異較少的權重。
為了看看不同的p值如何影響點A(2, 3)和B(5, 7)之間的距離計算,讓我們來查看以下圖表:
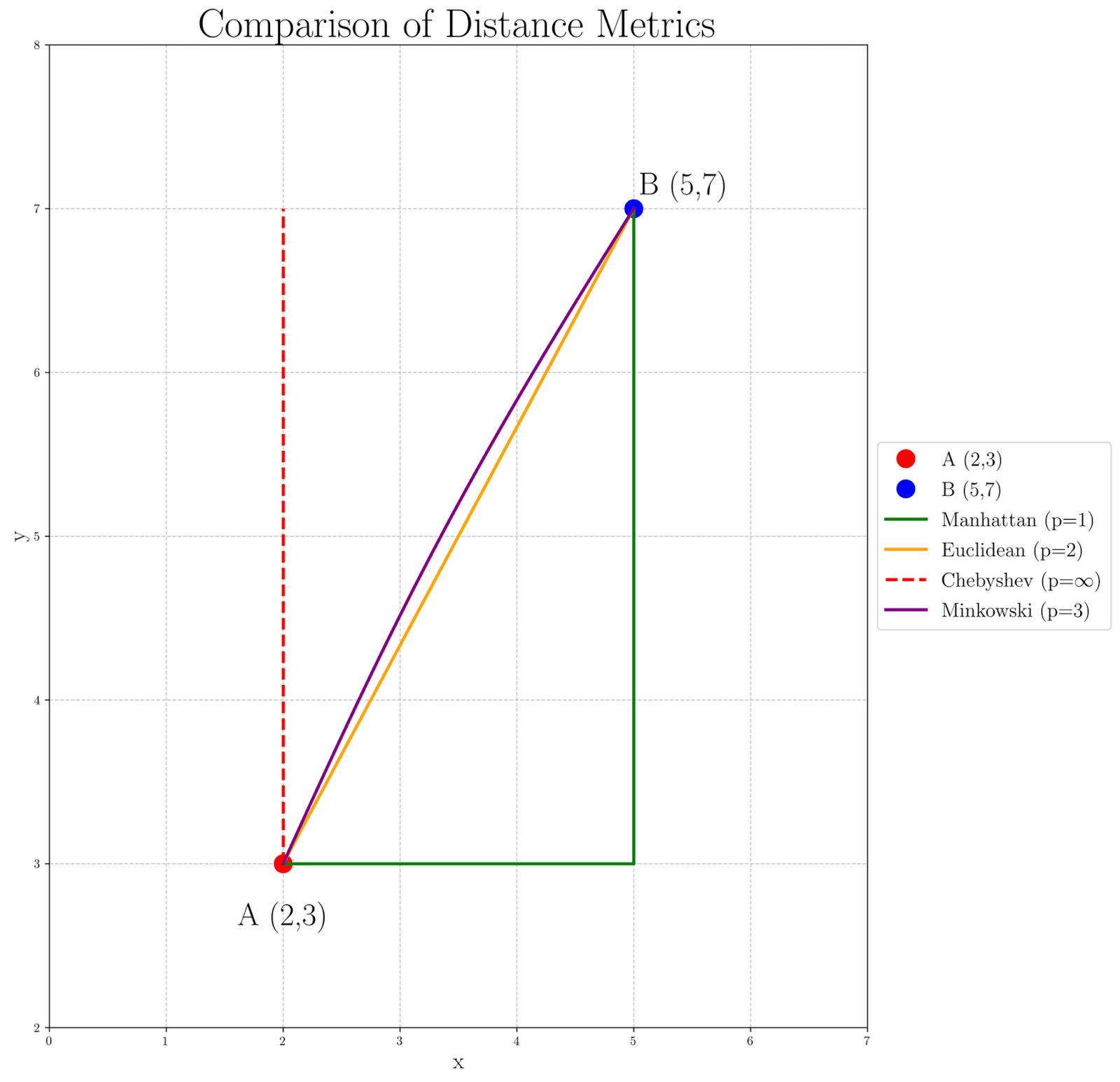
觀察圖表,我們可以看到當p增加時,距離衡量如何變化:
- 曼哈頓距離(p=1),由綠色路徑表示,產生最長的徑道,因為它嚴格跟從格栅。
- 歐幾里得距離(p=2),由橙色直線表示,提供直接的、直線的路徑。
- Chebyshev距離(p=∞),由紅色虛線表示,僅關注最大的坐標差異,創建一個在一個維度上最大限度移动然後才處理其他方面的路徑。
- 具有p=3的Minkowski距離以紫色顯示,顯示輕微的曲線,暗示Euclidean和Chebyshev距離之間的轉變。
這個可视化幫助我們理解為什麼對於不同的應用可能選擇不同的p值。例如,曼哈頓距離在都市導航問題中可能更適合,而歐幾里得距離常用於物理空間計算中。較高的p值(如在Minkowski p=3情況下)在 scenarios where larger differences should be emphasized,而Chebyshev距離可能會在任何維度上的最大差異是最關鍵因子時被偏好。
Minkowski距離的應用
闵可夫斯基距離具有可調節的參數p,是一種靈活的工具,被廣泛應用於各種領域。通過更改p,我們可以 tailored 我們量度點之間距離的方式,使其適合不同任務。以下是有四個應用場景,闵可夫斯基距离起着重要作用。
machine learning 和數據科學
在 machine learning 和數據科學中,闵可夫斯基距离是依賴於量度數據點之間的類似性或不同性 algorithms 的基本元素。一個突出的例子是k-最近邻 (k-NN) 算法,它根據最近的邻居的類別將數據點分類。通過使用闵可夫斯基距离,我們可以更改參數p,以改變點之間的“接近程度”的計算方式。
模式識別
模式識別涉及其在數據中識別模式和規則,如手寫文字識別或面貌特徵侦測。在這種情境下,闵可夫斯基距離衡量表示模式的特性向量之間的差異。例如,在圖像識別中,每個圖像可以由像素值向量表示。計算這些向量之間的闵可夫斯基距離讓我們能夠量化圖像之間的類似性或差異。
透過調整p,我們可以控制距離衡量對特定特徵差異的敏銳度。較低的p可能會考慮所有像素之間的整體差異,而較高的p可能會強調圖像某些區域的顯著差異。
異常檢測
異常檢測的目的是識別與大部分數據點顯著不同的數據點,這在像是詐騙檢測、網絡安全、以及系統中的異常檢測等領域至關重要。Minkowski距離用於衡量數據點與數據集中的其他點之間的距離。距離較大的點可能是潛在的異常。通過選擇合適的p,分析人員可以提高異常檢測系統對與他們特定情境最相關的差異的敏銳度。
計算幾何與空間分析
在計算幾何和空間分析中,Minkowski 距離是用來計算空間中點之間的距離,這是許多幾何算法的基础。例如,這些領域中的碰撞检测依賴於 Minkowski 距離來確定物件何時足夠近以進行互動。通過調整 p,開發者可以創造出多樣化的碰撞邊界,從角狀(較低 p)到圓滑(較高 p)。
除了碰撞檢測外,Minkowski 距離在空間聚類和形狀分析中也是有用的。變動 p 的值讓研究人员能夠強調空間關係的不同方面,從城市區塊距離到整體形狀相似性。
Minkowski 距離的數理特性
Minkowski 距離不僅在實際應用中是一個多功能的工具,也是在數學理論中一個重要的概念,特別是metric spaces 和 norms 的研究中。
度量空間特性
Minkowski 距離滿足度量空間中函數被視為度量所需的四個基本屬性:
- 非負性:任何兩點之間的Minkowski距離 Always non-negative, d(x,y)≥0。這是显而易见的,因為它是一個非負項的總和(將絕對值提升到p次方)的p次方根。
- 不可辨識性同一性:兩點之間的Minkowski距離若為零,當且仅當這兩點是相同的。從數理角度來看,d(x,y) = 0 當且仅當 x=y。這是由於相同成分之間的絕對差異為零所引起的。
- 對稱性:Minkowski距離是對稱的,意味著d(x,y)=d(y,x)。這個屬性之所以成立,是因為在絕對值項中的減法順序不會影響結果。
- 三角形不等式:闵可夫斯基距離滿足三角形不等式,該不合理式指對於任意的三個點 x、y 和 z,從 x 到 z 的距離不大於從 x 到 y 和從 y 到 z 的距離之總和;正式來說,d(x,z)≤d(x,y)+d(y,z)。這個屬性直觀地證明較為困難,通常需要較進階的數學,但基本上確保了兩個點之間取直線路徑是最高效的。
范數一般化
闵可夫斯基距離是一個一般的框架,它通過 norms 的概念统一了在數值空間中量度距離的各種方法。簡單來說,一個范數是一個函數,它將一個向量空間中的向量分配一個非負的長度或大小,從而 essentially 量度向量有多“長”。通過調整 Minkowski 距離公式中的參數 p,我們可以平滑地從一個 norms 过渡到另一個 norms,每個都提供一種計算向量長度的獨特性方法。
例如,當 p=1,Minkowski 距離變成 曼哈頓范數,度量距離為每個維度上的絕對差值的總和 — 想像自己在城市街道的網格中导航。當 p=2,它變成了 歐几里得范數,計算點之間的直線 (“飛鸟直达”) 距離。當 p 逼近無窮大時,它收敛於 切比雪夫范數,其中距離由維度中的最大單一差值決定。這種靈活性讓 Minkowski 距離能夠適應各種數學和實際情境,使其成為度量不同情境中距離的 多功能工具。
在 Python 和 R 中計算 Minkowski 距離
讓我們來探索使用 Python 和 R 实现的 Minkowski 距離計算。我們將檢查可用于實現此功能的現成包包和庫。
Python 示例
在 Python 中計算 Minkowski 距離時,我們可以使用 SciPy 庫,該庫提供各種距離度量的高效實現。以下是一個計算不同 p 值的 Minkowski 距離的示例:
import numpy as np from scipy.spatial import distance # 示例點 point_a = [2, 3] point_b = [5, 7] # 不同的 p 值 p_values = [1, 2, 3, 10, np.inf] print("Minkowski distances using SciPy:") for p in p_values: if np.isinf(p): #對於 p = 无穷大,使用切比雪夫距離 dist = distance.chebyshev(point_a, point_b) print(f"p = ∞, Distance = {dist:.2f}") else: dist = distance.minkowski(point_a, point_b, p) print(f"p = {p}, Distance = {dist:.2f}")
通過運行此代碼,讀者可以觀察到不同 p 值下距離的變化,從而加深對文章中早些时候討論的概念的理解。
Minkowski distances using SciPy: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
此代碼展示了:
- 如何使用SciPy的距離函數來計算Minkowski和Chebyshev距離。
- 包括無限大在内的各種p值的距離計算。
- Minkowski距離與其他度量尺度(曼哈頓,歐几里得,Chebyshev)之間的關係。
R示例
對於R,我們將使用stats庫中的dist()函數:
# 使用stats::dist定義Minkowski距離函數 minkowski_distance <- function(x, y, p) { points <- rbind(x, y) if (is.infinite(p)) { #對於p = Inf,使用method = "maximum"來計算Chebyshev距離 distance <- stats::dist(points, method = "maximum") } else { distance <- stats::dist(points, method = "minkowski", p = p) } return(as.numeric(distance)) } #示例使用 point_a <- c(2, 3) point_b <- c(5, 7) #不同的p值 p_values <- c(1, 2, 3, 10, Inf) cat("Minkowski distances between points A and B using stats::dist:\n") for (p in p_values) { distance <- minkowski_distance(point_a, point_b, p) if (is.infinite(p)) { cat(sprintf("p = ∞, Distance = %.2f\n", distance)) } else { cat(sprintf("p = %g, Distance = %.2f\n", p, distance)) } }
此代碼展示了:
-
如何使用
stats模組中的dist()函式來創建minkowski_distance函式。 -
處理不同的p值,包括Chebyshev距離的無限大。
-
為各種p值計算Minkowski距離。
-
將輸出格式化以顯示保留至小數點後2位的距離。
此代碼的輸出將為:
Minkowski distances between points A and B using stats::dist: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
這個R實現為Python示例提供了一個對應物,讓讀者可以看到Minkowski距離如何在不同的程式設計環境中計算。
結論
Minkowski距離提供了一個靈活且適應性強的方法來測量多維空間中的距離。它通過參數p將其他常見距離度量普遍化,使其成為數據科學和機器學習各種領域的宝贵工具。通過調整p, practitioners可以根據他們的數據特點和項目需求調整距離計算,從聚類到異常檢測等任務中 potentially enhancing results。
當您在自身工作中應用Minkowski距離時,我們鼓勵您嘗試不同的p值並觀察它們對您的結果的影響。對於那些希望深化理解和技能的人,我們建議您學習Python中設計機器學習工作流程課程,並考慮我們的數據科學家用證照職業計劃。這些資源可幫助您建立對距離度量的知識,並 effectively apply them in various scenarios.
Source:
https://www.datacamp.com/tutorial/minkowski-distance