













Distance metrics form the backbone of numerous algorithms in data science and machine learning, enabling the measurement of similarity or dissimilarity between data points. In this guide, we’ll explore the foundations of Minkowski distance, its mathematical properties, and its implementations. We’ll examine how it relates to other common distance measures and demonstrate its use through coding examples in Python and R.
Whether you’re developing clustering algorithms, working on anomaly detection, or fine-tuning classification models, understanding Minkowski distance can enhance your approach to data analysis and model development. Let’s take a look.
What is Minkowski Distance?
Minkowski distance is a versatile metric used in normed vector spaces, named after the German mathematician Hermann Minkowski. It’s a generalization of several well-known distance measures, making it a fundamental concept in various fields such as math, computer science, and data analysis.
At its core, Minkowski distance provides a way to measure the distance between two points in a multi-dimensional space. What makes it particularly useful is its ability to encompass other distance metrics as special cases, primarily through a parameter p. This parameter allows the Minkowski distance to adapt to different problem spaces and data characteristics. The general formula for Minkowski distance is:
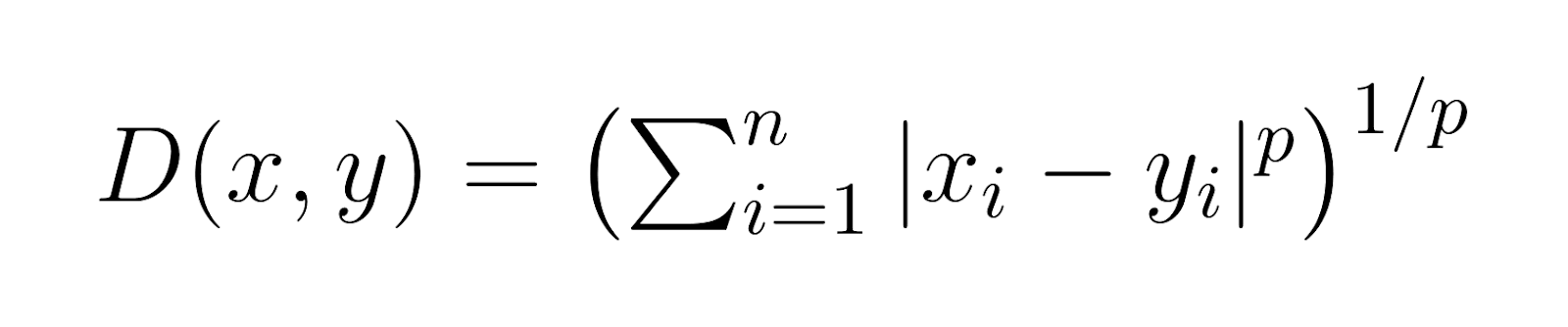
Where:
-
xandyare two points in an n-dimensional space -
pis a parameter that determines the type of distance (p ≥ 1) -
|xi - yi|represents the absolute difference between the coordinates of x and y in each dimension
Minkowski distance is useful for two main reasons. For one, it gives you flexibility to toggle between Manhattan or Euclidean distance as needed. Secondly, it recognizes that not all datasets (think high-dimensional spaces) are well-suited to either purely Manhattan or purely Euclidean distance.
In practice, the parameter p is typically chosen by incorporating a train/test validation workflow. By testing different values of p during cross-validation, you can determine which value provides the best model performance for your specific dataset.
How Minkowski Distance Works
Let’s take a look at how Minkowski distance relates to other distance formulas, and then walk through an example.
Generalization of other distance metrics
The first thing to consider is how the Minkowski distance formula contains within it the formulas for Manhattan, Euclidean, and Chebyshev distances.
Manhattan Distance (p = 1):
When p is set to 1, the Minkowski distance becomes Manhattan distance.
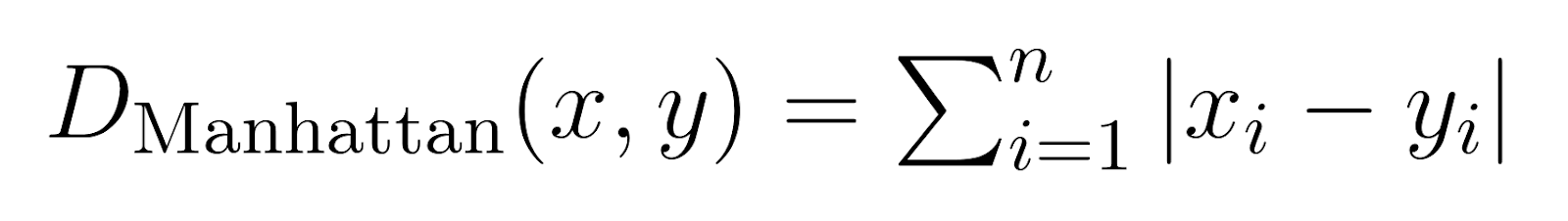
Also known as city block distance or L1 norm, Manhattan Distance measures the sum of absolute differences.
Euclidean Distance (p = 2):
When p is set to 2, Minkowski distance becomes Euclidean distance.
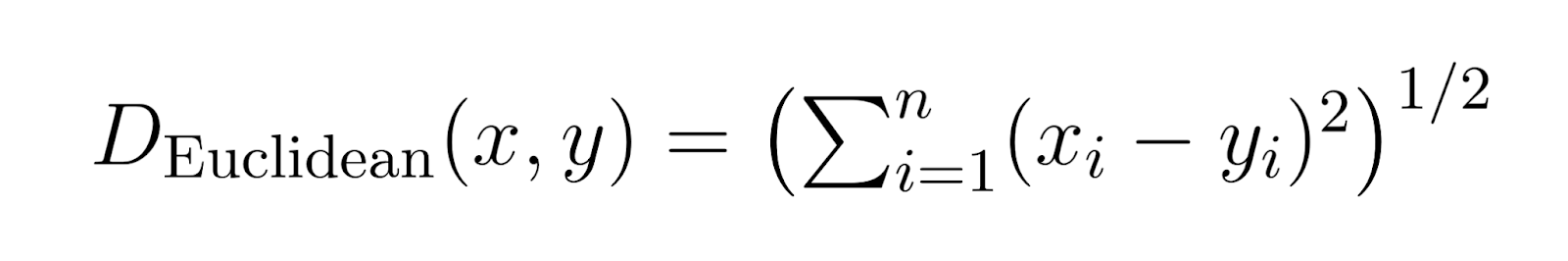
Euclidean distance is the most common distance metric, representing the straight-line distance between two points.
Chebyshev Distance (p → ∞):
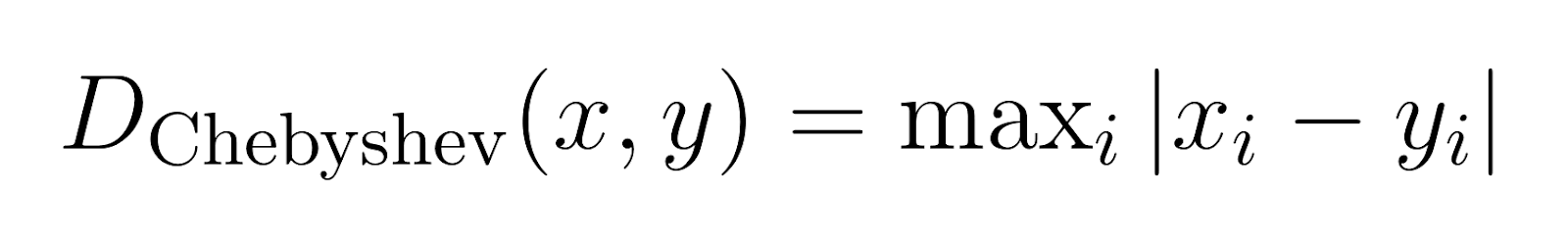
Chebyshev distance, also known as chessboard distance, measures the maximum difference along any dimension.
Working through an example
To truly grasp the functionality and power of Minkowski distance, let’s work through an example. This exploration will help us understand how the parameter p affects the calculation and interpretation of distances in multi-dimensional spaces.
Let’s consider two points in a 2D space:
- Point A: (2, 3)
- Point B: (5, 7)
We’ll calculate the Minkowski distance between these points for different p values.

The parameter p in the Minkowski distance formula controls the metric’s sensitivity to differences in individual components:
- When p=1: All differences contribute linearly.
- When p=2: Larger differences have a more significant impact due to squaring.
- When p>2: Even more emphasis is placed on larger differences.
- When p→∞: Only the maximum difference among all dimensions matters.
As p increases, the Minkowski distance generally decreases, approaching the Chebyshev distance. This is because higher p values give more weight to the largest difference and less to smaller differences.
To visualize how different values of p affect the distance calculation between our points A(2, 3) and B(5, 7), let’s examine the following graph:
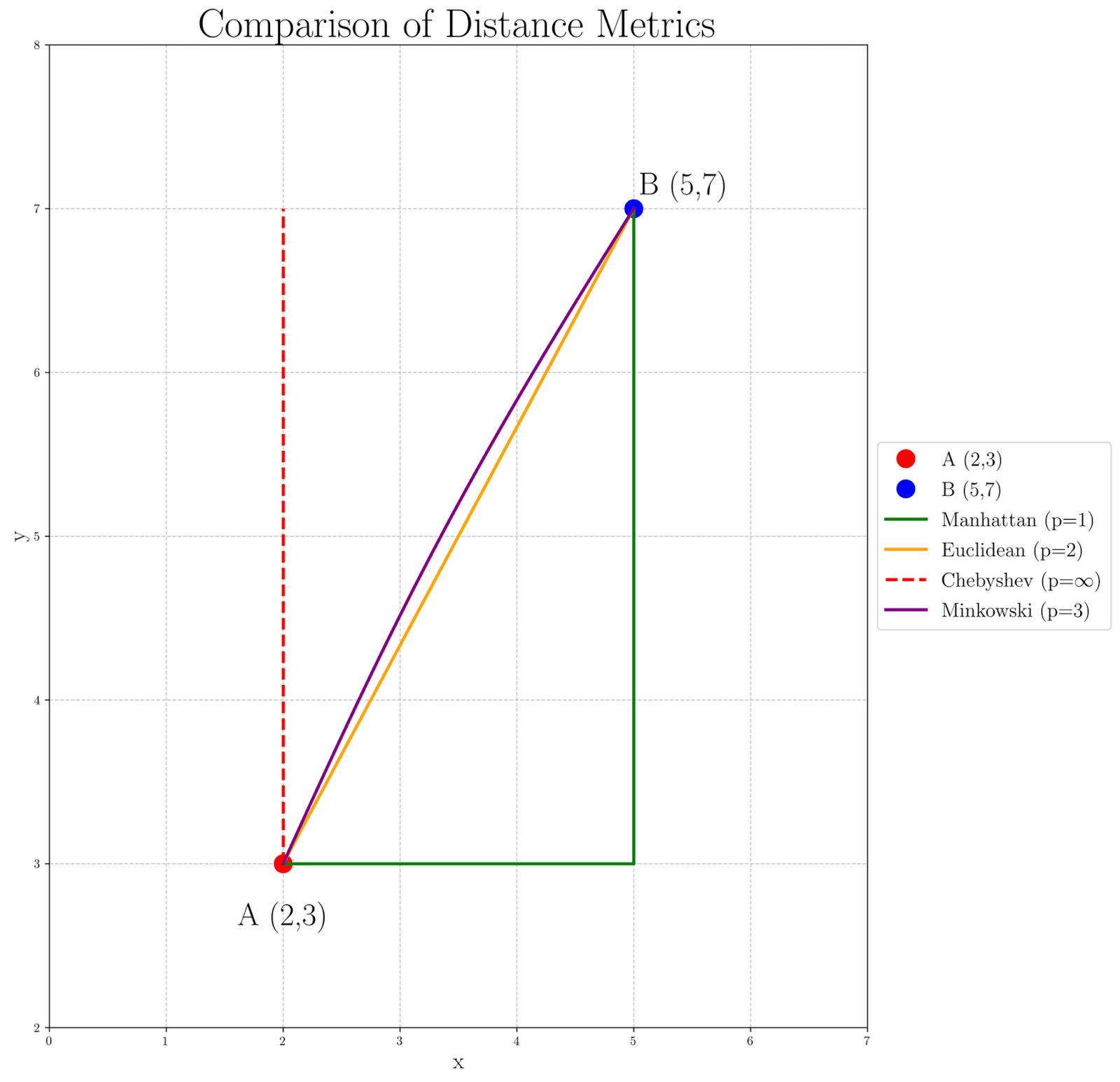
Observing the graph, we can see how the distance measure changes as p increases:
- The Manhattan distance (p=1), represented by the green path, yields the longest path, as it strictly follows the grid.
- The Euclidean distance (p=2), shown by the orange straight line, provides a direct, straight-line path.
- The Chebyshev distance (p=∞), depicted by the red dashed lines, focuses solely on the largest coordinate difference, creating a path that moves maximally in one dimension before addressing the other.
- The Minkowski distance with p=3 in purple shows a slight curve, hinting at the transition between Euclidean and Chebyshev distances.
This visualization helps us understand why different p values might be chosen for various applications. For instance, Manhattan distance might be more appropriate in city navigation problems, while Euclidean distance is often used in physical space calculations. Higher p values, like in the Minkowski p=3 case, can be useful in scenarios where larger differences should be emphasized, and Chebyshev distance might be preferred when the maximum difference in any dimension is the most critical factor.
Applications of Minkowski Distance
The Minkowski distance, with its adjustable parameter p, is a flexible tool used across various fields. By changing p, we can tailor how we measure the distance between points, making it suitable for different tasks. Below are four applications where Minkowski distance plays an important role.
Machine learning and data science
In machine learning and data science, Minkowski distance is fundamental for algorithms that rely on measuring the similarity or dissimilarity between data points. One prominent example is the k-Nearest Neighbors (k-NN) algorithm, which classifies data points based on the categories of their nearest neighbors. By using Minkowski distance, we can adjust the parameter p to change how we calculate the “closeness” between points.
Pattern recognition
Pattern recognition involves identifying patterns and regularities in data, such as handwriting recognition or facial feature detection. In this context, Minkowski distance measures the difference between feature vectors representing patterns. For example, in image recognition, each image can be represented by a vector of pixel values. Calculating the Minkowski distance between these vectors allows us to quantify how similar or different the images are.
By adjusting p, we can control the sensitivity of the distance measure to differences in specific features. A lower p might consider overall differences across all pixels, while a higher p could emphasize significant differences in certain regions of the image.
Anomaly detection
Anomaly detection aims to identify data points that deviate significantly from the majority, which is crucial in areas like fraud detection, network security, and fault detection in systems. Minkowski distance is used to measure how far a data point is from others in the dataset. Points with large distances are potential anomalies. By choosing an appropriate p, analysts can improve the sensitivity of anomaly detection systems to the kinds of deviations that are most relevant to their specific context.
Computational geometry and spatial analysis
In computational geometry and spatial analysis, Minkowski distance is used to compute distances between points in space, which is the basis for many geometric algorithms. For example, collision detection in these domains relies on Minkowski distance to determine when objects are close enough to interact. By adjusting p, developers can create diverse collision boundaries, ranging from angular (lower p) to rounded (higher p).
Beyond collision detection, Minkowski distance can be useful in spatial clustering and shape analysis. Varying the value of p allows researchers to emphasize different aspects of spatial relationships, from city block distances to overall shape similarities.
Mathematical Properties of Minkowski Distance
The Minkowski distance is not only a versatile tool in practical applications but also an important concept in mathematical theory, particularly in the study of metric spaces and norms.
Metric space properties
The Minkowski distance satisfies the four essential properties required for a function to be considered a metric in a metric space:
- Non-negativity: The Minkowski distance between any two points is always non-negative, d(x,y)≥0. This is evident as it is the p-th root of a sum of non-negative terms (absolute values raised to the power p).
- Identity of Indiscernibles: The Minkowski distance between two points is zero if and only if the two points are identical. Mathematically, d(x,y) = 0 if and only if x=y. This follows because the absolute difference between identical components is zero.
- Symmetry: The Minkowski distance is symmetric, meaning d(x,y)=d(y,x). This property holds because the order of subtraction in the absolute value terms does not affect the outcome.
- Triangle Inequality: The Minkowski distance satisfies the triangle inequality, which states that for any three points x, y, and z, the distance from x to z is at most the sum of the distance from x to y and from y to z; formally, d(x,z)≤d(x,y)+d(y,z). This property is less intuitive to prove directly from the formula and generally requires more advanced mathematics but essentially ensures that taking a direct path between two points is the shortest route.
Norm generalization
The Minkowski distance acts as a general framework that unifies various ways to measure distances in mathematical spaces through the concept of norms. In simple terms, a norm is a function that assigns a non-negative length or size to a vector in a vector space, essentially measuring how “long” the vector is. By adjusting the parameter p in the Minkowski distance formula, we can smoothly transition between different norms, each providing a unique method for calculating vector length.
For example, when p=1, the Minkowski distance becomes the Manhattan norm, measuring distance as the sum of absolute differences along each dimension—imagine navigating a grid of city streets. With p=2, it turns into the Euclidean norm, calculating the straight-line (“as-the-crow-flies”) distance between points. As p approaches infinity, it converges to the Chebyshev norm, where the distance is determined by the largest single difference among dimensions. This flexibility allows the Minkowski distance to adapt to various mathematical and practical contexts, making it a versatile tool for measuring distances in different scenarios.
Calculating Minkowski Distance in Python and R
Let’s explore implementations of Minkowski distance calculations using both Python and R. We’ll examine readily available packages and libraries that can achieve this.
Python example
To calculate Minkowski distance in Python, we can use the SciPy library, which provides efficient implementations of various distance metrics. Here’s an example that calculates Minkowski distance for different p values:
import numpy as np from scipy.spatial import distance # Example points point_a = [2, 3] point_b = [5, 7] # Different p values p_values = [1, 2, 3, 10, np.inf] print("Minkowski distances using SciPy:") for p in p_values: if np.isinf(p): # For p = infinity, use Chebyshev distance dist = distance.chebyshev(point_a, point_b) print(f"p = ∞, Distance = {dist:.2f}") else: dist = distance.minkowski(point_a, point_b, p) print(f"p = {p}, Distance = {dist:.2f}")
By running this code, readers can observe how the distance changes with different p values, reinforcing the concepts discussed earlier in the article.
Minkowski distances using SciPy: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
This code demonstrates:
- How to use SciPy’s distance functions for Minkowski and Chebyshev distances.
- Calculation of distances for various p values, including infinity.
- The relationship between Minkowski distance and other metrics (Manhattan, Euclidean, Chebyshev).
R example
For R, we will utilize the dist() function from the stats library:
# Define the Minkowski distance function using stats::dist minkowski_distance <- function(x, y, p) { points <- rbind(x, y) if (is.infinite(p)) { # For p = Inf, use method = "maximum" for Chebyshev distance distance <- stats::dist(points, method = "maximum") } else { distance <- stats::dist(points, method = "minkowski", p = p) } return(as.numeric(distance)) } # Example usage point_a <- c(2, 3) point_b <- c(5, 7) # Different p values p_values <- c(1, 2, 3, 10, Inf) cat("Minkowski distances between points A and B using stats::dist:\n") for (p in p_values) { distance <- minkowski_distance(point_a, point_b, p) if (is.infinite(p)) { cat(sprintf("p = ∞, Distance = %.2f\n", distance)) } else { cat(sprintf("p = %g, Distance = %.2f\n", p, distance)) } }
This code demonstrates:
-
How to create a function
minkowski_distanceusing thedist()function fromstats. -
Handling of different p values, including infinity for Chebyshev distance.
-
Calculation of Minkowski distance for various p values.
-
Formatting output to display distances rounded to 2 decimal places.
The output of this code will be:
Minkowski distances between points A and B using stats::dist: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
This R implementation provides a counterpart to the Python example, allowing readers to see how Minkowski distance can be calculated in different programming environments.
Conclusion
Minkowski distance provides a flexible and adaptable approach to measuring distances in multi-dimensional spaces. Its ability to generalize other common distance metrics through the parameter p makes it a valuable tool across various fields in data science and machine learning. By adjusting p, practitioners can tailor their distance calculations to the specific characteristics of their data and the requirements of their projects, potentially enhancing results in tasks ranging from clustering to anomaly detection.
As you apply Minkowski distance in your own work, we encourage you to experiment with different p values and observe their impact on your results. For those looking to deepen their understanding and skills, we recommend exploring the Designing Machine Learning Workflows in Python course and considering our Data Scientist Certification career program. These resources can help you build on your knowledge of distance metrics and apply them effectively in various scenarios.
Source:
https://www.datacamp.com/tutorial/minkowski-distance