













介紹
在這個教程中,你將建立一個Python應用程序,能夠從輸入的視頻中提取音頻,將提取的音頻進行轉錄,根據轉錄生成字幕文件,然後將字幕添加到輸入視頻的副本中。
為了構建這個應用程序,你將使用FFmpeg從輸入視頻中提取音頻。你將使用OpenAI的Whisper生成提取音頻的轉錄,然後使用這個轉錄生成字幕文件。此外,你將使用FFmpeg將生成的字幕文件添加到輸入視頻的副本中。
FFmpeg是一個功能強大的開源軟件套件,用於處理多媒體數據,包括音頻和視頻處理任務。它提供了一個命令行工具,允許用戶使用各種格式和編解碼器轉換、編輯和操作多媒體文件。
OpenAI的Whisper是一個自動語音識別(ASR)系統,旨在將口語語言轉換為書面文本。它在大量多語言和多任務監督數據上進行了訓練,能夠以高精度轉錄各種音頻內容。
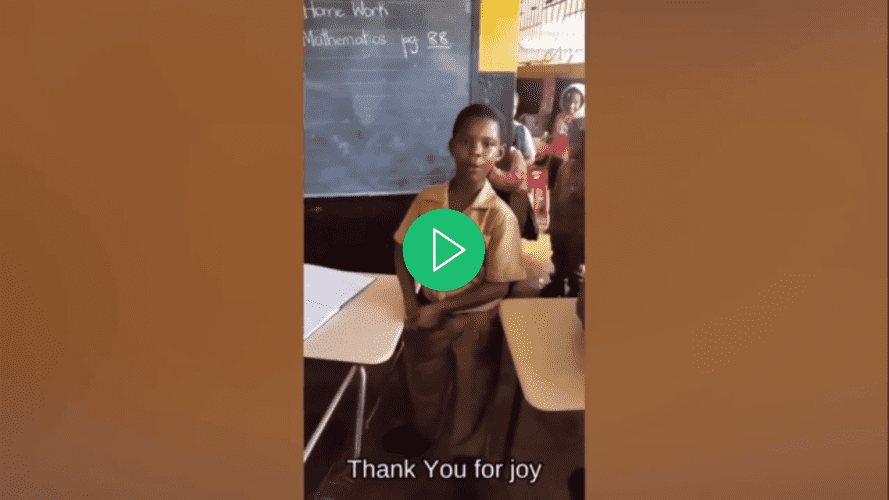
通過本教程的結束,你將擁有一個能夠將字幕添加到視頻的應用程序:
前提條件
為了按照本教程,讀者需要以下工具:
步驟 1 — 創建項目根目錄
在這一部分,您將創建項目目錄,下載輸入視頻,創建和啟用虛擬環境,並安裝所需的 Python 套件。
打開終端窗口並導航到適合的項目位置。運行以下命令來創建項目目錄:
進入項目目錄:
下載這個編輯過的視頻,並將其存儲在您的項目根目錄下,名為input.mp4。該視頻展示了一個名叫 Rushawn 的孩子演唱 Jermaine Edward 的《美麗的一天》。本教程中使用的編輯過的視頻來自以下YouTube 視頻:
創建一個新的虛擬環境並將其命名為env:
激活虛擬環境:
現在,使用以下命令安裝構建此應用程序所需的套件:
通過上面的命令,您安裝了以下庫:
-
faster-whisper:是 OpenAI 的 Whisper 模型的重新設計版本,利用 CTranslate2,這是一個用於 Transformer 模型的高性能推理引擎。該實現在保持可比準確性的同時,速度比 openai/whisper 快四倍,並且消耗的內存更少。 -
ffmpeg-python:是一個Python庫,它提供了對FFmpeg工具的封裝,使用戶可以輕鬆地在Python腳本中與FFmpeg功能進行交互。通過Pythonic接口,它可以實現視頻和音頻處理任務,如編輯、轉換和操作。
運行以下命令將在名為requirements.txt的文件中保存在虛擬環境中安裝的套件:
requirements.txt文件應該類似於以下內容:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
在本節中,您創建了項目目錄,下載了將在本教程中使用的輸入視頻,設置了虛擬環境,激活了它並安裝了必要的Python包。在下一節中,您將為輸入視頻生成一個文本轉錄。
步驟2-生成視頻文本轉錄
在這一部分中,您將創建一個 Python 腳本,應用程序將存在其中。在此腳本中,您將使用 ffmpeg-python 函式庫從前一節下載的輸入視頻中提取音頻軌道並將其保存為 WAV 文件。接下來,您將使用 faster-whisper 函式庫為提取的音頻生成一個轉錄。
在您的項目根目錄中,創建一個名為 main.py 的文件,並將以下代碼添加到其中:
在這裡,代碼首先導入各種庫和模塊,包括 time、math、ffmpeg 從 ffmpeg-python,以及來自 faster_whisper 的自定義模塊 WhisperModel。這些庫將用於視頻和音頻處理、轉錄和字幕生成。
接下來,代碼設置輸入視頻文件名,將其存儲在一個名為 input_video 的常量中,然後將視頻文件名(不包括 .mp4 擴展名)存儲在一個名為 input_video_name 的常量中。在此處設置輸入文件名將使您能夠在多個輸入視頻上工作,而不會覆蓋為它們生成的字幕和輸出視頻文件。
將以下代碼添加到您的 main.py 的末尾:
上面的代碼定義了一個名為 extract_audio() 的函數,該函數負責從輸入視頻中提取音頻。
首先,將要提取的音頻名稱設置為將輸入視頻的基本名稱添加audio-和.wav擴展名所形成的名稱,並將此名稱存儲在名為extracted_audio的常量中。
接下來,代碼調用ffmpeg庫的ffmpeg.input()方法打開輸入視頻,並創建一個名為stream的輸入流對象。
然後,代碼調用ffmpeg.output()方法創建一個帶有輸入流和定義的提取音頻文件名的輸出流對象。
在設置輸出流後,代碼調用ffmpeg.run()方法,將輸出流作為參數傳遞以啟動音頻提取過程並將提取的音頻文件保存在項目的根目錄中。此外,還包括一個布爾參數overwrite_output=True,以替換任何已存在的輸出文件為新生成的文件(如果已存在這樣的文件)。
最後,代碼返回提取的音頻文件名。
在extract_audio()函數下方添加以下代碼:
在這裡,代碼定義了一個名為run()的函數,然後調用它。此函數調用所有需要生成和添加字幕到視頻的函數。
在函數內部,代碼調用extract_audio()函數來從視頻中提取音頻,然後將返回的音頻文件名存儲在名為extracted_audio的變量中。
返回終端並執行以下命令來運行main.py腳本:
執行上述命令後,FFmpeg的輸出將顯示在終端中,並且一個名為audio-input.wav的文件,其中包含從輸入視頻中提取的音頻,將存儲在項目的根目錄中。
返回到你的main.py文件,並在extract_audio()和run()函數之間添加以下代碼:
上面的代碼定義了一個名為transcribe的函數,負責轉錄從輸入視頻中提取的音頻文件。
首先,代碼創建了WhisperModel對象的實例,並將模型類型設置為small。OpenAI的Whisper有以下幾種模型類型:tiny、base、small、medium和large。tiny模型是最小且速度最快的,而large模型是最大且最慢但最準確的。
接下來,代碼使用提取的音頻作為參數調用model.transcribe()方法,以檢索segments函數和音頻信息,並將它們分別存儲在名為info和segments的變量中。segments函數是一個Python生成器,所以只有在代碼迭代它時才會開始轉錄。可以通過將segments收集到list或使用for循環來完成轉錄。
接下來,代碼將檢測到的語言存儲在名為info的常量中並打印到控制台上。
在打印出语言检测后,代码将转录片段收集到一个名为list的列表中以运行转录,并将收集到的片段存储在一个名为segments的变量中。然后,代码循环遍历转录片段列表,并将每个片段的开始时间、结束时间和文本打印到控制台。
最后,代码返回音频中检测到的语言和转录片段。
将以下代码添加到run()函数中:
添加的代码使用提取的音频作为参数调用了transcribe函数,并将返回的值存储在名为language和segments的常量中。
返回终端并执行以下命令来运行main.py脚本:
第一次运行此脚本时,代码将首先下载并缓存Whisper Small模型,后续运行将更快。
执行上述命令后,您应该在控制台中看到以下输出:
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
上面的输出显示音频中检测到的语言为英语(en)。此外,它显示了每个转录片段的开始时间、结束时间(以秒为单位)和文本。
警告:尽管OpenAI的Whisper语音识别非常准确,但并不是100%准确,它可能会受到限制和偶发错误的影响,特别是在复杂的语言或音频场景中。因此,请务必手动检查转录内容。
在這一部分中,您創建了一個用於應用程序的Python腳本。在腳本內部,使用了ffmpeg-python來從下載的視頻中提取音頻並將其保存為WAV文件。然後,使用了faster-whisper庫來生成提取的音頻的轉錄。在下一部分中,您將根據轉錄生成字幕文件,然後將字幕添加到視頻中。
步驟 3 — 生成並添加字幕到視頻
在這一部分中,首先,您將了解字幕文件是什麼以及其結構。接下來,您將使用前一部分生成的轉錄段來創建字幕文件。創建字幕文件後,您將使用ffmpeg-python庫將字幕文件添加到輸入視頻的副本中。
了解字幕:結構和類型
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
字幕索引:按文件中字幕的順序進行編號。
-
時間碼:起始和結束時間標記,指定字幕文本應該顯示的時間。時間碼通常格式為
HH:MM:SS,sss(小時,分鐘,秒,毫秒)。 -
字幕文本:字幕條目的實際文本,表示口述或書寫內容。該文本在指定的時間間隔內顯示在屏幕上。
例如,SRT文件中的一個字幕條目可能如下所示:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
在這個例子中,索引為1,時間碼表示字幕應該從10.5秒顯示到15秒,字幕文本為This is an example subtitle.
字幕可以分為兩種主要類型:
-
軟字幕:也稱為閉路字幕,以外部文件(如SRT)的形式存儲,可以獨立於視頻添加或刪除。它們提供了觀眾的靈活性,允許切換、語言切換和自定義設置。然而,它們的有效性取決於視頻播放器的支持,並非所有播放器都普遍支持軟字幕。
-
硬字幕:在編輯或編碼過程中永久嵌入到視頻幀中,成為視頻的固定部分。雖然它們確保在不支持外部字幕文件的播放器上保持可見,但修改或關閉它們需要重新編碼整個視頻,限制了用戶的控制權。
創建字幕文件
返回到你的main.py文件,在transcribe()和run()函數之間添加以下代碼:
在這裡,代碼定義了一個名為format_time()的函數,該函數負責將給定的轉錄段的起始時間和結束時間(以秒為單位)轉換為字幕兼容的時間格式,顯示小時、分鐘、秒和毫秒(HH:MM:SS,sss)。
代碼首先從給定的時間(以秒為單位)計算出小時、分鐘、秒和毫秒,然後按照相應的格式進行格式化,最後返回格式化後的時間。
在format_time()函數和run()函數之間添加以下代碼:
添加的代碼定義了一個名為generate_subtitle_file()的函數,該函數以檢測到的音頻語言和轉錄段作為參數。該函數負責基於語言和轉錄段生成一個SRT字幕文件。
首先,代碼將字幕文件的名稱設置為將檢測到的語言附加到輸入視頻的基本名稱後面並添加“.srt”擴展名的名稱,並將此名稱存儲在名為subtitle_file的常量中。此外,代碼定義了一個名為text的變量,您將在其中存儲字幕條目。
然後,代碼遍歷轉錄段,使用format_time()函數格式化起始時間和結束時間,使用這些格式化後的值以及段索引和文本來創建一個字幕條目,然後在每個字幕條目之間添加一個空行。
最後,代碼在專案根目錄中創建一個以前設置的名稱命名的字幕文件,將字幕條目添加到文件中,並返回字幕文件名。
將以下代碼添加到run()函數的末尾:
添加的代碼調用generate_subtitle_file()函數,並將檢測到的語言和轉錄片段作為參數傳遞,並將返回的字幕文件名存儲在名為subtitle_file的常量中。
返回終端,執行以下命令運行main.py腳本:
執行上面的命令後,將在專案的根目錄中保存一個名為sub-input.en.srt的字幕文件。
打開sub-input.en.srt字幕文件,您應該會看到類似以下的內容:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
將字幕添加到視頻中
在generate_subtitle_file()和run()函數之間添加以下代碼:
在這裡,代碼定義了一個名為add_subtitle_to_video()的函數,該函數接受一個布爾值作為參數,用於確定是否應該添加軟字幕或硬字幕,以及字幕文件名和在轉錄中檢測到的語言。此函數負責將軟字幕或硬字幕添加到輸入視頻的副本中。
首先,代碼使用ffmpeg.input()方法與輸入的視頻和字幕文件一起創建輸入流對象,並將它們分別存儲在名為video_input_stream和subtitle_input_stream的常量中。
創建輸入流後,代碼將輸出視頻文件的名稱設置為將output-附加到輸入視頻的基本名稱並添加“.mp4”擴展名的名稱,並將此名稱存儲在名為output_video的常量中。此外,將字幕軌道的名稱設置為不帶.srt擴展名的字幕文件名,並將此名稱存儲在名為subtitle_track_title的常量中。
接下來,代碼檢查布爾變量soft_subtitle是否設置為True,表示應該添加軟字幕。
如果是這樣,代碼調用ffmpeg.output()方法使用輸入流、輸出視頻文件名和以下輸出視頻的選項來創建輸出流對象:
-
"c": "copy":它指定視頻編解碼器和其他視頻參數應直接從輸入複製到輸出而無需重新編碼。 -
"c:s": "mov_text":它指定了字幕编解码器和参数也应该从输入复制到输出而不重新编码。mov_text是在MP4/MOV文件中常用的字幕编解码器。 -
”metadata:s:s:0”: f"language={subtitle_language}":它为字幕流设置语言元数据。语言被设置为存储在subtitle_language中的值。 -
"metadata:s:s:0": f"title={subtitle_track_title}":它为字幕流设置标题元数据。标题被设置为存储在subtitle_track_title中的值。
最后,代码调用ffmpeg.run()方法,将输出流作为参数传递,将软字幕添加到视频并将输出视频文件保存在项目的根目录中。
将以下代码添加到add_subtitle_to_video()函数的末尾:
如果布尔变量soft_subtitle设置为False,则突出显示的代码将运行,表示应添加硬字幕。
如果是这种情况,首先,代码调用ffmpeg.output()方法创建一个输出流对象,该对象包括输入视频流、输出视频文件名和vf=f"subtitles={subtitle_file}"参数。vf代表“视频过滤器”,用于对视频流应用过滤器。在此情况下,应用的过滤器是添加字幕。
最后,代码调用ffmpeg.run()方法,将输出流作为参数传递,以将硬字幕添加到视频并将输出视频文件保存在项目的根目录中。
将以下突出显示的代码添加到run()函数中:
突出显示的代码使用soft_subtitle参数设置为True,字幕文件名和字幕语言调用add_subtitle_to_video(),以向输入视频的副本添加软字幕。
返回终端并执行以下命令以运行main.py脚本:
运行上述命令后,将在项目的根目录中保存一个名为output-input.mp4的输出视频文件。
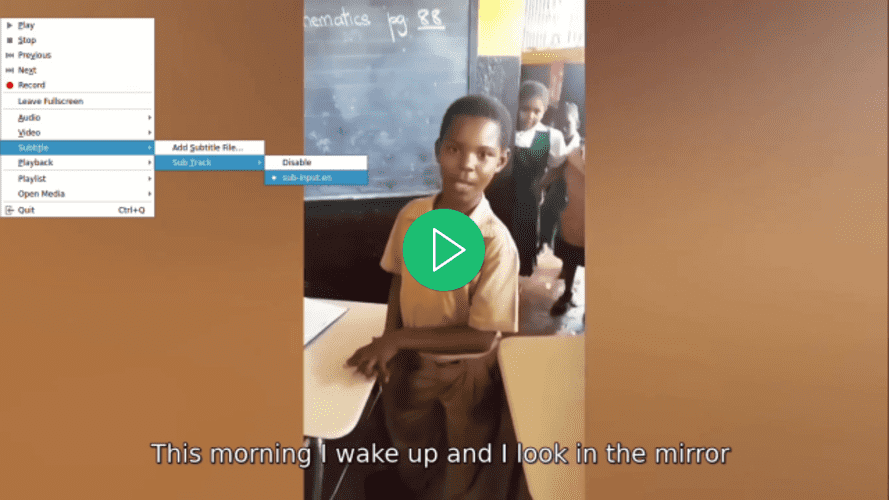
使用首选的视频播放器打开视频,选择视频的字幕,然后注意只有在选择字幕后才会显示字幕:
返回到main.py文件,導航到run()函數,在add_subtitle_to_video()函數調用中將soft_subtitle參數設置為False:
在這裡,您將soft_subtitle參數設置為False,以在視頻中添加硬字幕。
返回到終端並執行以下命令運行main.py腳本:
執行上述命令後,位於項目根目錄中的output-input.mp4視頻文件將被覆蓋。
使用您喜歡的視頻播放器打開視頻,嘗試為視頻選擇字幕,並注意雖然沒有可用的字幕卻顯示了一個字幕:

在本節中,您瞭解了SRT字幕文件的結構,並利用前一節的轉錄段來創建了一個字幕文件。隨後,使用ffmpeg-python庫將生成的字幕文件添加到視頻中。
結論
在本教程中,您使用了ffmpeg-python和faster-whisper Python庫構建了一個應用程序,該應用程序能夠從輸入視頻中提取音頻,對提取的音頻進行轉錄,並基於轉錄生成字幕文件,然後將字幕添加到輸入視頻的副本中。