













Introductie
In deze tutorial ga je een Python-toepassing bouwen die in staat is om audio uit een invoervideo te extraheren, de geëxtraheerde audio te transcriberen, op basis van de transcriptie een ondertitelbestand te genereren, en vervolgens de ondertitel toe te voegen aan een kopie van de invoervideo.
Om deze toepassing te bouwen, zul je FFmpeg gebruiken om audio uit een invoervideo te extraheren. Je zult OpenAI’s Whisper gebruiken om een transcript te genereren voor de geëxtraheerde audio en vervolgens dit transcript gebruiken om een ondertitelbestand te genereren. Daarnaast zul je FFmpeg gebruiken om het gegenereerde ondertitelbestand toe te voegen aan een kopie van de invoervideo.
FFmpeg is een krachtige en open-source software suite voor het verwerken van multimediagegevens, inclusief taken voor audio- en videobewerking. Het biedt een opdrachtregeltool waarmee gebruikers multimediabestanden kunnen converteren, bewerken en manipuleren met een breed scala aan formaten en codecs.
OpenAI’s Whisper is een automatisch spraakherkenningssysteem (ASR) dat is ontworpen om gesproken taal om te zetten in geschreven tekst. Getraind op een grote hoeveelheid meertalige en multitaskende begeleide gegevens, blinkt het uit in het transcriberen van diverse audiocommunicatie met een hoge nauwkeurigheid.
Aan het einde van deze tutorial heb je een toepassing die in staat is om ondertitels toe te voegen aan een video:
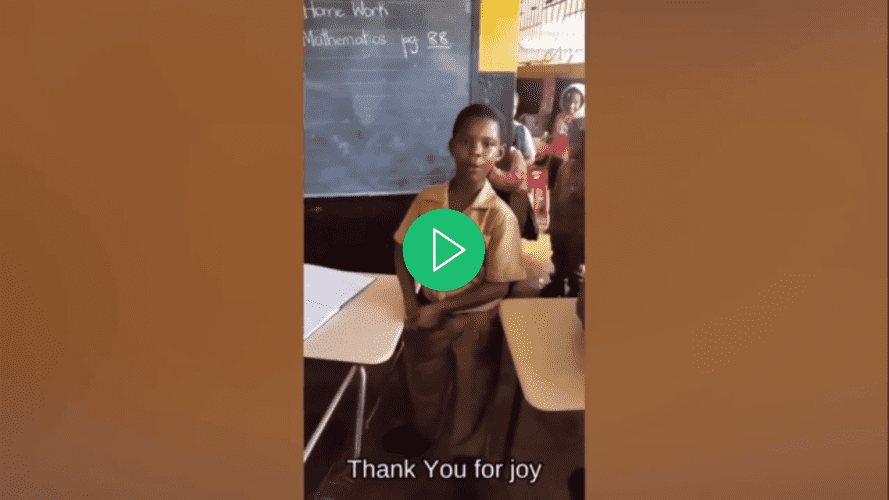
Vereisten
Om deze tutorial te volgen heeft de lezer de volgende tools nodig:
-
FFmpeg geïnstalleerd.
-
Een basaal begrip van Python. Je kunt deze tutorialserie volgen om te leren coderen in Python.
Stap 1 — Het Project Hoofddirectory Aanmaken
In dit gedeelte zul je de projectdirectory aanmaken, de invoervideo downloaden, een virtuele omgeving creëren en activeren, en de vereiste Python-pakketten installeren.
Open een terminalvenster en navigeer naar een geschikte locatie voor je project. Voer het volgende commando uit om de projectdirectory aan te maken:
Navigeer naar de projectdirectory:
Download deze bewerkte video en sla het op in de hoofdmap van je project als input.mp4. De video toont een kind genaamd Rushawn dat Jermaine Edwards’ “Beautiful Day” zingt. De bewerkte video die je in deze tutorial gaat gebruiken, is afkomstig van de volgende YouTube-video:
Maak een nieuwe virtuele omgeving aan en noem deze env:
Activeer de virtuele omgeving:
Gebruik nu het volgende commando om de benodigde pakketten voor deze toepassing te installeren:
Met het bovenstaande commando heb je de volgende bibliotheken geïnstalleerd:
-
faster-whisper: is een herontworpen versie van het OpenAI Whisper-model dat gebruikmaakt van CTranslate2, een high-performance inferentiemotor voor Transformer-modellen. Deze implementatie behaalt tot vier keer snellere snelheid dan openai/whisper met vergelijkbare nauwkeurigheid, en dat allemaal met minder geheugenverbruik. -
ffmpeg-python: is een Python-bibliotheek die een omhulsel biedt rond de FFmpeg-tool, waardoor gebruikers gemakkelijk met FFmpeg-functionaliteiten kunnen omgaan in Python-scripts. Via een Pythonic-interface maakt het video- en audiobewerkingstaken mogelijk, zoals bewerken, converteren en manipuleren.
Voer de volgende opdracht uit om pakketten die zijn geïnstalleerd met pip in de virtuele omgeving op te slaan in een bestand met de naam requirements.txt:
Het bestand requirements.txt moet er ongeveer zo uitzien:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
In dit gedeelte heb je de projectdirectory gemaakt, de invoervideo gedownload die in deze tutorial zal worden gebruikt, een virtuele omgeving opgezet, deze geactiveerd en de noodzakelijke Python-pakketten geïnstalleerd. In het volgende gedeelte genereer je een transcriptie voor de invoervideo.
Stap 2 — Genereren van de video-transcriptie
In dit gedeelte maak je het Python-script waar de applicatie zal draaien. Binnen dit script gebruik je de ffmpeg-python bibliotheek om het audiokanaal uit de in de vorige sectie gedownloade video te extraheren en op te slaan als een WAV-bestand. Vervolgens gebruik je de faster-whisper bibliotheek om een transcript te genereren voor het geëxtraheerde audiofragment.
In de hoofdmap van je project maak je een bestand met de naam main.py en voeg je de volgende code toe:
Hier begint de code met het importeren van verschillende bibliotheken en modules, waaronder time, math, ffmpeg van ffmpeg-python, en een aangepaste module genaamd WhisperModel van faster_whisper. Deze bibliotheken worden gebruikt voor videobewerking, audiobewerking, transcriptie en ondertitelgeneratie.
Vervolgens stelt de code de naam van het invoervideobestand in, slaat het op in een constante met de naam input_video, en slaat het vervolgens de naam van het videobestand zonder de extensie .mp4 op in een constante met de naam input_video_name. Het instellen van de invoerbestandsnaam hier maakt het mogelijk om aan meerdere invoervideo’s te werken zonder de ondertitel- en uitvoervideobestanden die voor hen zijn gegenereerd, te overschrijven.
Voeg de volgende code toe aan het einde van je main.py:
De bovenstaande code definieert een functie met de naam extract_audio() die verantwoordelijk is voor het extraheren van audio uit de invoervideo.
Eerst wordt de naam van het audiofragment dat zal worden geëxtraheerd ingesteld op een naam die wordt gevormd door audio- toe te voegen aan de basenaam van de invoervideo met een .wav-extensie, en deze naam wordt opgeslagen in een constante genaamd extracted_audio.
Vervolgens roept de code de methode ffmpeg.input() van de bibliotheek ffmpeg aan om de invoervideo te openen en maakt een invoerstroomobject genaamd stream aan.
De code roept vervolgens de methode ffmpeg.output() aan om een uitvoerstroomobject te maken met de invoerstroom en de gedefinieerde naam van het geëxtraheerde audiobestand.
Nadat de uitvoerstroom is ingesteld, roept de code de methode ffmpeg.run() aan, waarbij de uitvoerstroom als parameter wordt doorgegeven om het proces van audiouittrekking te starten en het geëxtraheerde audiobestand op te slaan in de rootdirectory van je project. Bovendien is een booleaanse parameter, overwrite_output=True, inbegrepen om een eventueel al bestaand uitvoerbestand te vervangen door het nieuw gegenereerde bestand als zo’n bestand al bestaat.
Tenslotte geeft de code de naam van het geëxtraheerde audiobestand terug.
Voeg de volgende code toe onder de functie extract_audio():
Hier definieert de code een functie genaamd run() en roept deze vervolgens aan. Deze functie roept alle benodigde functies aan om ondertitels te genereren en toe te voegen aan een video.
In de functie roept de code de functie extract_audio() aan om audio uit een video te extraheren en slaat vervolgens de geretourneerde audiobestandsnaam op in een variabele genaamd extracted_audio.
Ga terug naar je terminal en voer de volgende opdracht uit om het script main.py uit te voeren:
Na het uitvoeren van het bovenstaande commando, wordt de FFmpeg-uitvoer weergegeven in de terminal, en een bestand met de naam audio-input.wav met daarin het geëxtraheerde audio van de invoervideo wordt opgeslagen in de hoofdmap van je project.
Ga terug naar je main.py-bestand en voeg de volgende code toe tussen de extract_audio()– en run()-functies:
De bovenstaande code definieert een functie met de naam transcribe die verantwoordelijk is voor het transcriberen van het audiobestand dat is geëxtraheerd uit de invoervideo.
Eerst maakt de code een instantie van het WhisperModel-object en stelt het modeltype in op small. OpenAI’s Whisper heeft de volgende modeltypes: tiny, base, small, medium en large. Het tiny-model is het kleinst en snelst en het large-model is het grootst en langzaamst maar het meest accuraat.
Vervolgens roept de code de methode model.transcribe() aan met het geëxtraheerde audio als argument om de functie segments en de audio-informatie op te halen en ze respectievelijk op te slaan in variabelen genaamd info en segments. De segments-functie is een Python-generator, dus de transcriptie begint pas wanneer de code erover itereert. De transcriptie kan worden voltooid door de segments te verzamelen in een list of een for-loop.
Vervolgens slaat de code de gedetecteerde taal in het audio op in een constante genaamd info en print het naar de console.
Na het detecteren van de taal print de code de transcriptiesegmenten in een lijst om de transcriptie uit te voeren en de verzamelde segmenten in een variabele met de naam segments op te slaan. Vervolgens loopt de code over de lijst met transcriptiesegmenten en print elk segment zijn starttijd, eindtijd en tekst naar de console.
Uiteindelijk retourneert de code de gedetecteerde taal in de audio en de transcriptiesegmenten.
Voeg de volgende code toe binnen de run()-functie:
De toegevoegde code roept de functie transcribe aan met de geëxtraheerde audio als argument en slaat de geretourneerde waarden op in constanten met de naam language en segments.
Ga terug naar je terminal en voer het volgende commando uit om het script main.py uit te voeren:
De eerste keer dat je dit script uitvoert, zal de code eerst het Whisper Small-model downloaden en cachen, daaropvolgende runs zullen veel sneller zijn.
Na het uitvoeren van het bovenstaande commando zou je de volgende output in de console moeten zien:
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
De bovenstaande output toont aan dat de taal gedetecteerd in de audio Engels is (en). Daarnaast toont het de start- en eindtijd in seconden van elk transcriptiesegment en de tekst.
Waarschuwing: Hoewel de Whisper-spraakherkenning van OpenAI zeer nauwkeurig is, is het niet 100% nauwkeurig, het kan onderhevig zijn aan beperkingen en incidentele fouten, met name in uitdagende linguïstische of audio-scenario’s. Controleer dus altijd de transcriptie handmatig.
In dit gedeelte heb je een Python-script gemaakt voor de applicatie. Binnen het script werd ffmpeg-python gebruikt om de audio uit de gedownloade video te extraheren en op te slaan als een WAV-bestand. Vervolgens werd de faster-whisper-bibliotheek gebruikt om een transcript te genereren voor de geëxtraheerde audio. In het volgende gedeelte ga je een ondertitelbestand genereren op basis van het transcript en vervolgens voeg je de ondertitel toe aan de video.
Stap 3 — Genereren en toevoegen van de ondertitel aan de video
In dit gedeelte ga je eerst begrijpen wat een ondertitelbestand is en hoe het is gestructureerd. Vervolgens ga je de transcriptsegmenten gebruiken die zijn gegenereerd in het vorige gedeelte om een ondertitelbestand te maken. Nadat je het ondertitelbestand hebt gemaakt, ga je de ffmpeg-python-bibliotheek gebruiken om het ondertitelbestand toe te voegen aan een kopie van de invoervideo.
Begrip van Ondertitels: Structuur en Soorten
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
Ondertitel Index: Een opeenvolgend nummer dat de volgorde van de ondertitel in het bestand aangeeft.
-
Tijdscodes: Start- en eindtijdaanduidingen die aangeven wanneer de tekst van de ondertiteling moet worden weergegeven. De tijdscodes zijn meestal opgemaakt als
HH:MM:SS,sss(uren, minuten, seconden, milliseconden). -
Tekst van de ondertiteling: De daadwerkelijke tekst van de ondertitelingsinvoer, die gesproken of geschreven inhoud vertegenwoordigt. Deze tekst wordt op het scherm weergegeven tijdens het gespecificeerde tijdsinterval.
Bijvoorbeeld, een ondertitelingsinvoer in een SRT-bestand kan er als volgt uitzien:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
In dit voorbeeld is het indexnummer 1, geven de tijdscodes aan dat de ondertiteling moet worden weergegeven van 10.5 seconden tot 15 seconden, en de ondertiteltekst is Dit is een voorbeeld ondertitel.
Ondertitels kunnen worden onderverdeeld in twee primaire typen:
-
Zachte ondertitels: Ook bekend als gesloten bijschriften, worden extern opgeslagen als aparte bestanden (zoals SRT) en kunnen onafhankelijk van de video worden toegevoegd of verwijderd. Ze bieden kijkers flexibiliteit, waardoor ze kunnen schakelen, van taal kunnen wisselen en instellingen kunnen aanpassen. Hun effectiviteit is echter afhankelijk van de ondersteuning van de videospeler, en niet alle spelers bieden universeel ondersteuning voor zachte ondertitels.
-
Harde ondertitels: Worden permanent ingebed in videoframes tijdens het bewerken of coderen en blijven een vast onderdeel van de video. Hoewel ze zorgen voor constante zichtbaarheid, zelfs op spelers die geen ondersteuning bieden voor externe ondertitelbestanden, vereisen aanpassingen of uitschakelen het opnieuw coderen van de volledige video, waardoor de gebruikerscontrole wordt beperkt
Het maken van het ondertitelbestand
Ga terug naar je main.py bestand en voeg de volgende code toe tussen de functies transcribe() en run():
Hier definieert de code een functie genaamd format_time(), die verantwoordelijk is voor het converteren van de start- en eindtijd van een gegeven transcriptiesegment in seconden naar een ondertitelbaar tijdformaat dat uren, minuten, seconden en milliseconden weergeeft (HH:MM:SS,sss).
De code berekent eerst uren, minuten, seconden en milliseconden uit de gegeven tijd in seconden, formatteert ze dienovereenkomstig en retourneert vervolgens de geformatteerde tijd.
Voeg de volgende code toe tussen de functies format_time() en run():
De toegevoegde code definieert een functie genaamd generate_subtitle_file(), die als parameters de gedetecteerde taal in de geëxtraheerde audio en de transcriptiesegmenten krijgt. Deze functie is verantwoordelijk voor het genereren van een SRT-ondertitelbestand op basis van de taal en de transcriptiesegmenten.
Eerst stelt de code de naam van het ondertitelbestand in op een naam die wordt gevormd door sub- toe te voegen aan de gedetecteerde taal aan de basennaam van de invoervideo met de extensie “.srt”, en slaat deze naam op in een constante genaamd subtitle_file. Daarnaast definieert de code een variabele genaamd text waarin je de ondertitelvermeldingen zult opslaan.
Vervolgens doorloopt de code de getranscribeerde segmenten, formatteert de start- en eindtijden met behulp van de functie format_time(), gebruikt deze geformatteerde waarden samen met het segmentindex en de tekst om een ondertitelvermelding te maken, en voegt vervolgens een lege regel toe om elke ondertitelvermelding te scheiden.
Tenslotte maakt de code een ondertitelbestand in de hoofdmap van je project met de eerder ingestelde naam, voegt de ondertitelitems toe aan het bestand en retourneert de bestandsnaam van het ondertitelbestand.
Voeg de volgende code toe onderaan je run() functie:
De toegevoegde code roept de generate_subtitle_file() functie aan met de gedetecteerde taal en transcriptiesegmenten als argumenten, en slaat de naam van het ondertitelbestand op in een constante genaamd subtitle_file.
Keer terug naar je terminal en voer de volgende opdracht uit om het main.py script uit te voeren:
Nadat je de bovenstaande opdracht hebt uitgevoerd, wordt er een ondertitelbestand met de naam sub-input.en.srt opgeslagen in de hoofdmap van je project.
Open het ondertitelbestand sub-input.en.srt en je zou iets soortgelijks moeten zien als het volgende:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
Ondertitels toevoegen aan video’s
Voeg de volgende code toe tussen de generate_subtitle_file() en de run() functie:
Hier definieert de code een functie genaamd add_subtitle_to_video() die als parameters een boolean-waarde aanneemt die wordt gebruikt om te bepalen of er een zachte ondertitel of een harde ondertitel moet worden toegevoegd, de naam van het ondertitelbestand en de gedetecteerde taal in de transcriptie. Deze functie is verantwoordelijk voor het toevoegen van zachte of harde ondertitels aan een kopie van de invoervideo.
Eerst gebruikt de code de ffmpeg.input() methode met de invoervideo en het ondertitelbestand om invoerstroomobjecten voor de invoervideo en het ondertitelbestand te maken en slaat ze op in constanten genaamd video_input_stream en subtitle_input_stream respectievelijk.
Na het maken van de invoerstromen stelt de code de naam van het uitvoervideobestand in op een naam die wordt gevormd door output- toe te voegen aan de basisnaam van de invoervideo met de extensie “.mp4”, en slaat deze naam op in een constante genaamd output_video. Bovendien stelt het de naam van het ondertitelnummer in op de naam van het ondertitelbestand zonder de .srt extensie en slaat deze naam op in een constante genaamd subtitle_track_title.
Vervolgens controleert de code of de boolean soft_subtitle is ingesteld op True, wat aangeeft dat het een zachte ondertitel moet toevoegen.
Als dat het geval is, roept de code de ffmpeg.output() methode aan om een uitvoerstroomobject te maken met de invoerstromen, de naam van het uitvoervideobestand en de volgende opties voor de uitvoervideo:
-
"c": "copy": Hiermee wordt aangegeven dat de videocodec en andere videoparameters rechtstreeks van de invoer naar de uitvoer moeten worden gekopieerd zonder opnieuw te worden gecodeerd. -
"c:s": "mov_text": Hiermee wordt gespecificeerd dat de ondertitelcodec en parameters ook van de invoer naar de uitvoer moeten worden gekopieerd zonder opnieuw te worden gecodeerd.mov_textis een veelvoorkomende ondertitelcodec die wordt gebruikt in MP4/MOV-bestanden. -
”metadata:s:s:0”: f"language={subtitle_language}": Hiermee wordt de taalmetadata ingesteld voor de ondertitelstroom. De taal wordt ingesteld op de waarde die is opgeslagen insubtitle_language -
"metadata:s:s:0": f"title={subtitle_track_title}": Hiermee wordt de titelmetadata ingesteld voor de ondertitelstroom. De titel wordt ingesteld op de waarde die is opgeslagen insubtitle_track_title
Tenslotte roept de code de methode ffmpeg.run() aan, waarbij de uitvoerstroom als parameter wordt doorgegeven om de zachte ondertiteling aan de video toe te voegen en het uitvoervideobestand op te slaan in de hoofdmap van je project.
Voeg de volgende code toe onderaan je functie add_subtitle_to_video():
De gemarkeerde code wordt uitgevoerd als de boolean soft_subtitle is ingesteld op False, wat aangeeft dat er een harde ondertitel moet worden toegevoegd.
Als dat het geval is, roept de code eerst de methode ffmpeg.output() aan om een uitvoerstreamobject te maken met de invoervideostream, de uitvoervideobestandsnaam en de parameter vf=f"subtitles={subtitle_file}". De vf staat voor “video filter” en wordt gebruikt om een filter toe te passen op de videostream. In dit geval is het toevoegen van de ondertitel het toegepaste filter.
Tenslotte roept de code de methode ffmpeg.run() aan, waarbij de uitvoerstream als parameter wordt doorgegeven om de harde ondertitel aan de video toe te voegen en het uitvoervideobestand op te slaan in de hoofdmap van je project.
Voeg de volgende gemarkeerde code toe aan de functie run():
De gemarkeerde code roept de methode add_subtitle_to_video() aan met de parameter soft_subtitle ingesteld op True, de naam van het ondertitelbestand en de taal van de ondertitel om een zachte ondertitel toe te voegen aan een kopie van de invoervideo.
Ga terug naar je terminal en voer de volgende opdracht uit om het script main.py uit te voeren:
Na het uitvoeren van de bovenstaande opdracht wordt een uitvoervideobestand met de naam output-input.mp4 opgeslagen in de hoofdmap van je project.
Open de video met je favoriete videospeler, selecteer een ondertitel voor de video en merk op hoe de ondertitel pas wordt weergegeven nadat je deze hebt geselecteerd:
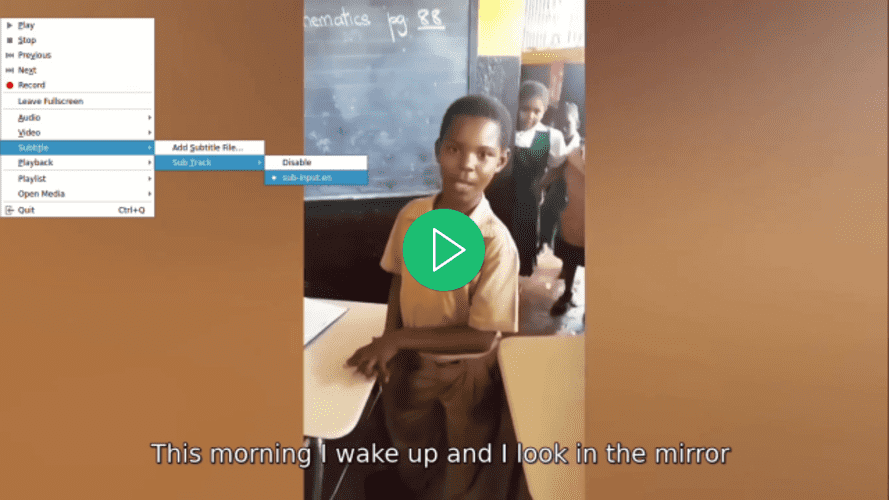
Ga terug naar het main.py bestand, navigeer naar de run() functie, en bij de oproep van de add_subtitle_to_video() functie stel je de soft_subtitle parameter in op False:
Hier stel je de soft_subtitle parameter in op False om harde ondertitels aan de video toe te voegen.
Ga terug naar je terminal en voer de volgende opdracht uit om het main.py script uit te voeren:
Na het uitvoeren van de bovenstaande opdracht zal het output-input.mp4 videobestand dat zich in de hoofdmap van je project bevindt, worden overschreven.
Open de video met je voorkeursvideospeler, probeer een ondertitel voor de video te selecteren, en merk op hoe deze niet beschikbaar is terwijl er wel een ondertitel wordt weergegeven:

In dit gedeelte heb je inzicht gekregen in de structuur van een SRT-ondertitelbestand en heb je de transscriptiesegmenten uit het vorige gedeelte gebruikt om er een te maken. Vervolgens werd de ffmpeg-python bibliotheek gebruikt om het gegenereerde ondertitelbestand aan de video toe te voegen.
Conclusie
In deze tutorial heb je de ffmpeg-python en faster-whisper Python-bibliotheken gebruikt om een applicatie te bouwen die in staat is om audio uit een invoervideo te extraheren, de geëxtraheerde audio te transcriberen, op basis van de transcriptie een ondertitelbestand te genereren en de ondertitel aan een kopie van de invoervideo toe te voegen.