













1. Tableau 導論
概觀
Tableau Software 是一家總部位於華盛頓州西雅圖的軟件公司,專門生產聚焦於商業智能的互動式數據視覺化產品。Tableau 是在1997年至2002年間於史丹福大學計算機科學系創立的(維基百科)
Tableau 提供的主要產品包括:

Tableau Desktop、Tableau Public 和 Tableau Online,它們都提供數據視覺創作功能,選擇取決於工作的類型。
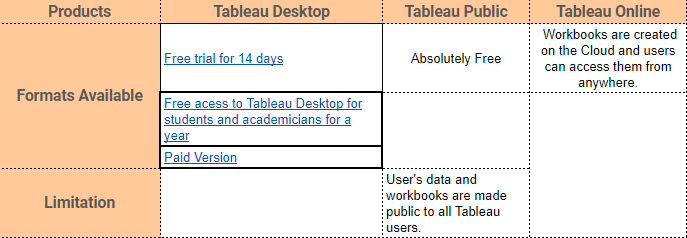
在本教學中,我們將使用 Tableau Desktop。參考來源的連結在這裡。
安裝
根據產品選擇,將軟體下載到電腦上。在接受許可協議後,您可以通過點擊 Tableau 圖標來驗證安裝。如果出現以下螢幕,您就可以開始了。
2. 入門
在本節中,我們將學習 Tableau 中的一些基本操作,以熟悉其界面。
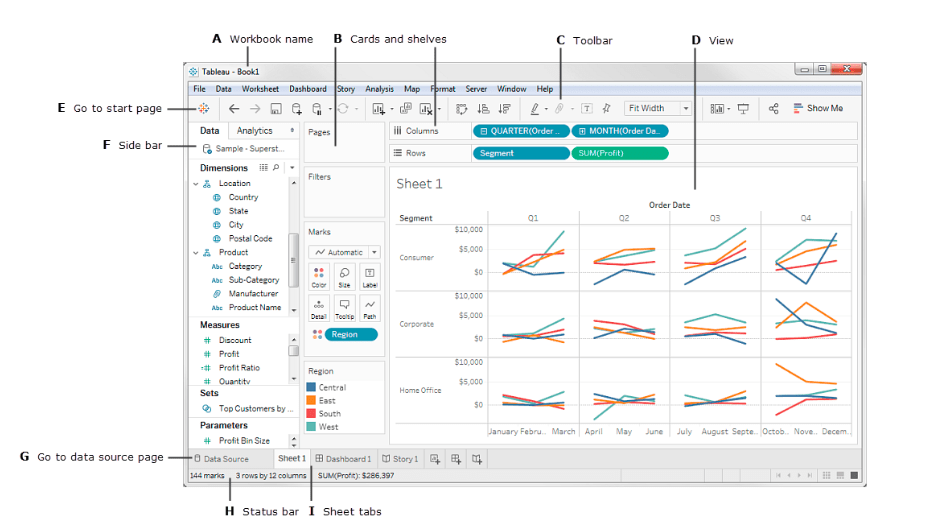
Tableau 工作空間
Tableau 工作空間是由工作表、選單欄、工具欄、標記卡、架子和許多其他元素組成的集合,我們將在後面的章節中學習這些元素。工作表可以是工作表、儀表板,或是故事。下圖突出了工作空間的主要組件。然而,一旦我們開始使用實際數據,將會更加熟悉。
連接到數據源
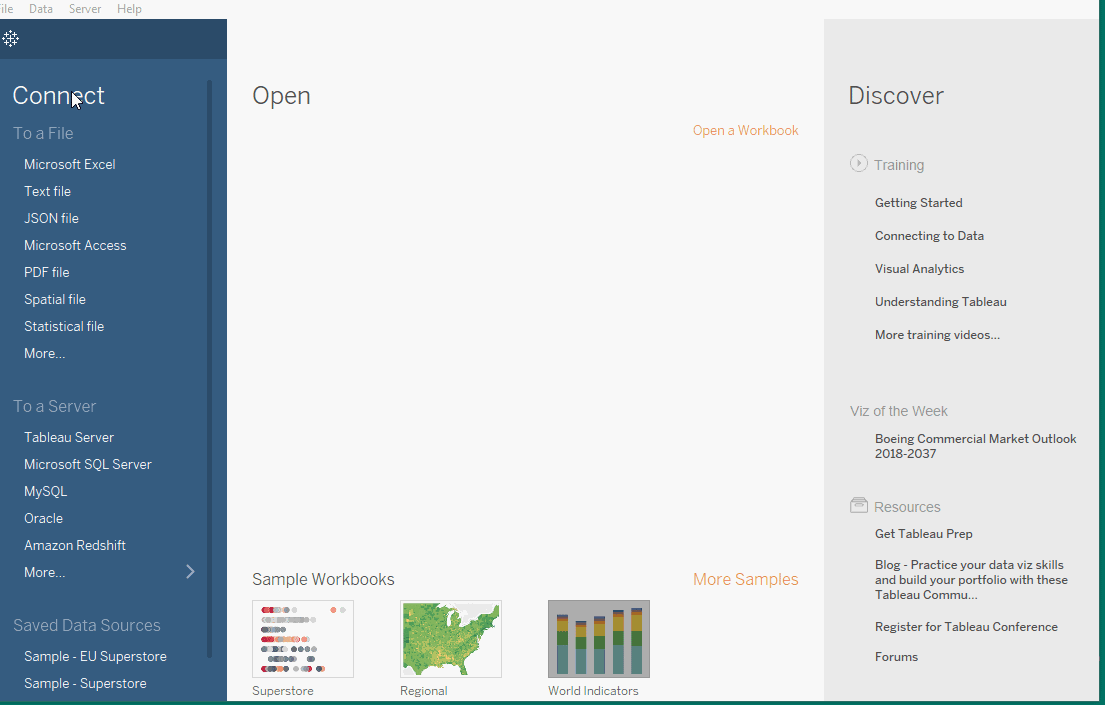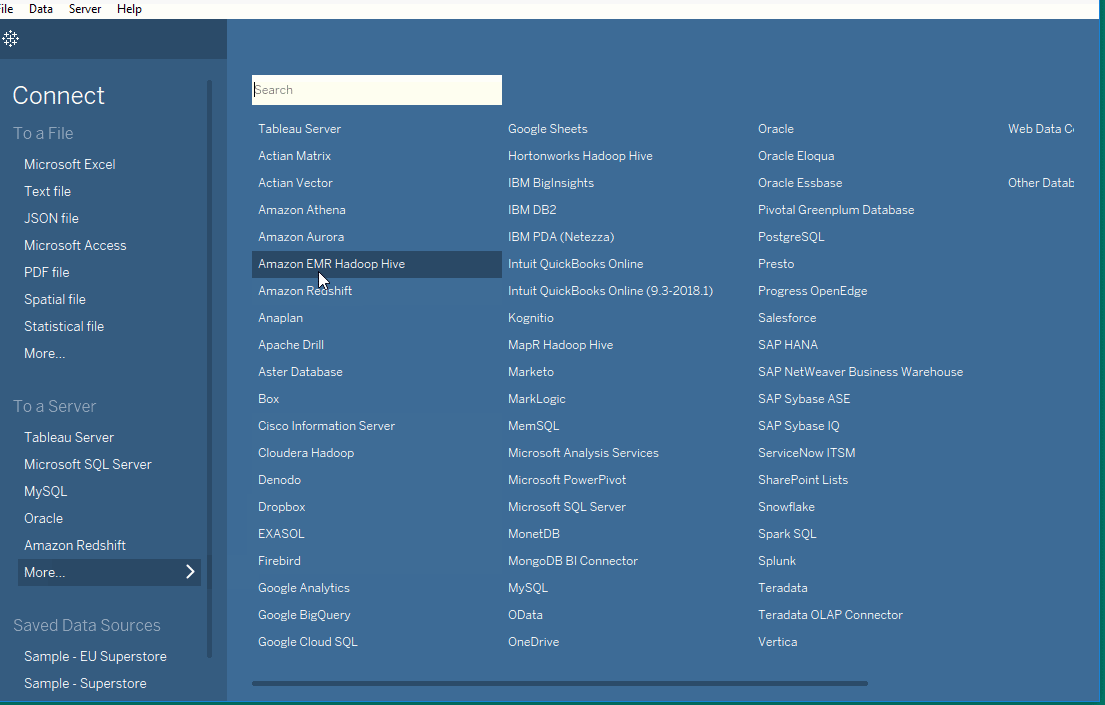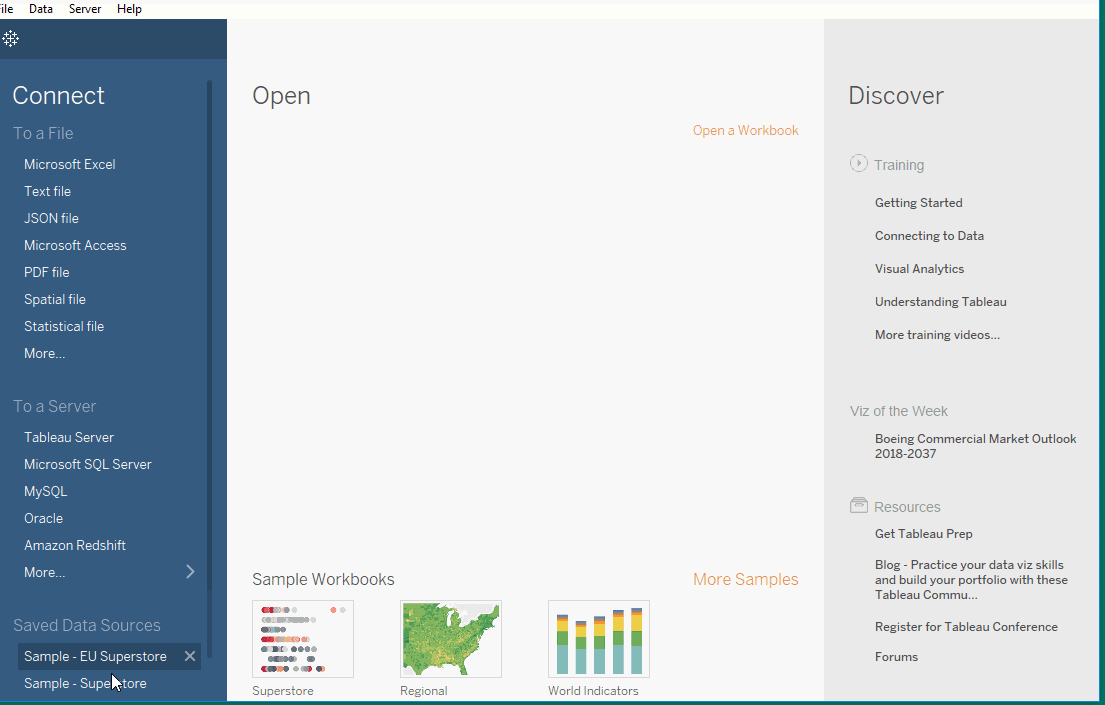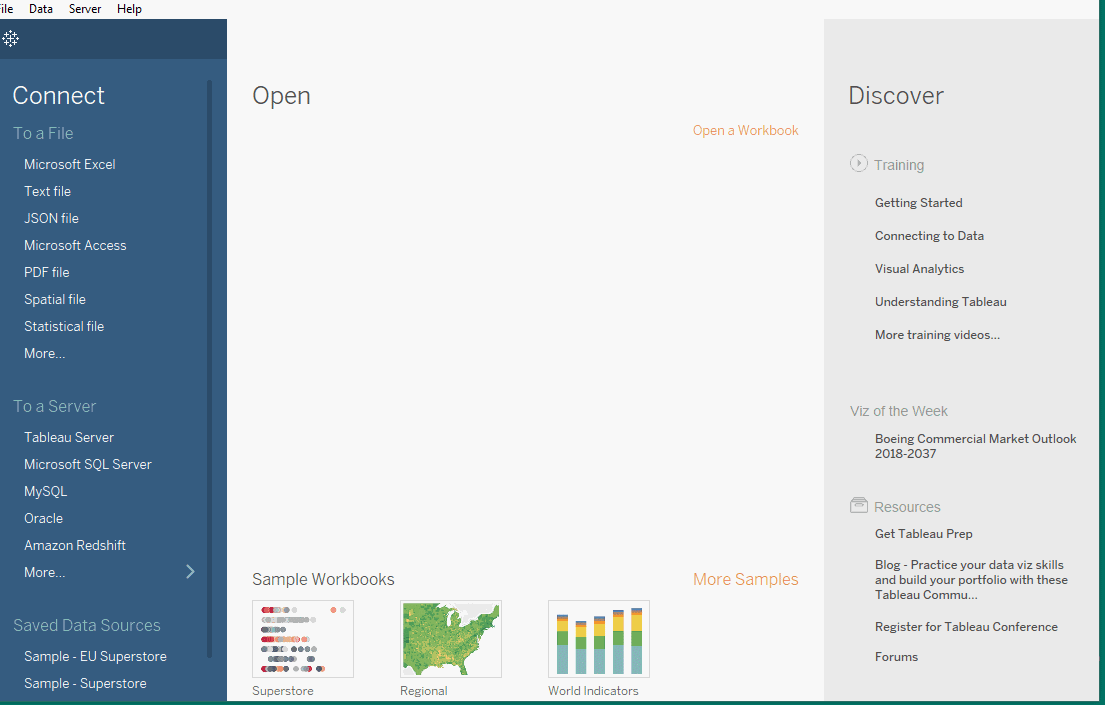
To begin 使用 Tableau,我們需要將 Tableau 連接到數據源。Tableau 支援許多數據源。Tableau 支持的數據源會顯示在開啟畫面的左側。一些常用的數據源包括 excel、文本文件、關係數據庫甚至服務器。也可以連接到如 Google Analytics、Amazon Redshift 等雲端數據源。
Tableau 桌面版的啟動畫面顯示了可以連接的可用數據源。這也取決於 Tableau 的版本,因為付費版本提供了更多的可能性。在螢幕左側有一個連接窗格,突出顯示了可用的數據源。文件類型首先列出,然後是常見的服務器類型,或者是最近連接過的服務器。在打開標籤下,您可以打開之前創建的工作簿。Tableau 桌面版還在示例工作簿下提供了一些示例工作簿。
親自操作
連接到示例超級商店數據集
我們將合作一個名為Superstore 數據集的樣本數據集,該數據集随表哥一起预加载。然而,我们将从這裡下载文件,以便我们能了解如何连接到 Excel 数据源。这些数据是超级市场的数据,包含有关产品,销售,利润等信息。作为数据分析师,我们的目标是分析数据并在此虚构公司的关键改进领域找到答案。
步驟
-
從電腦將數據匯入 Tableau 工作區。
-
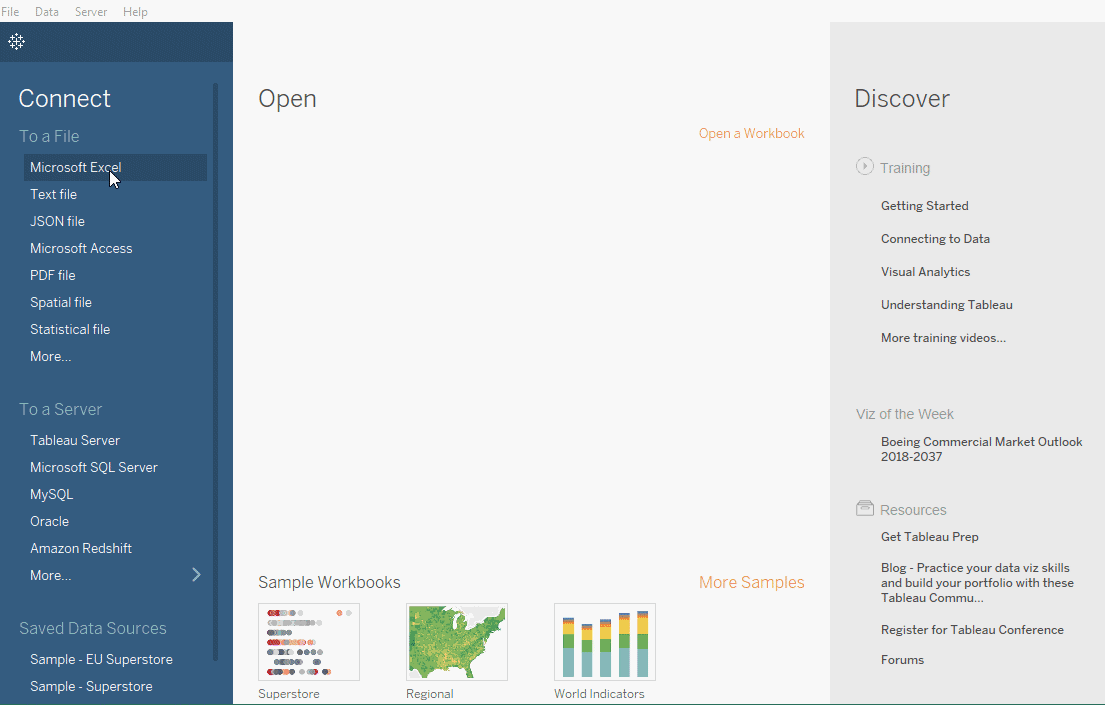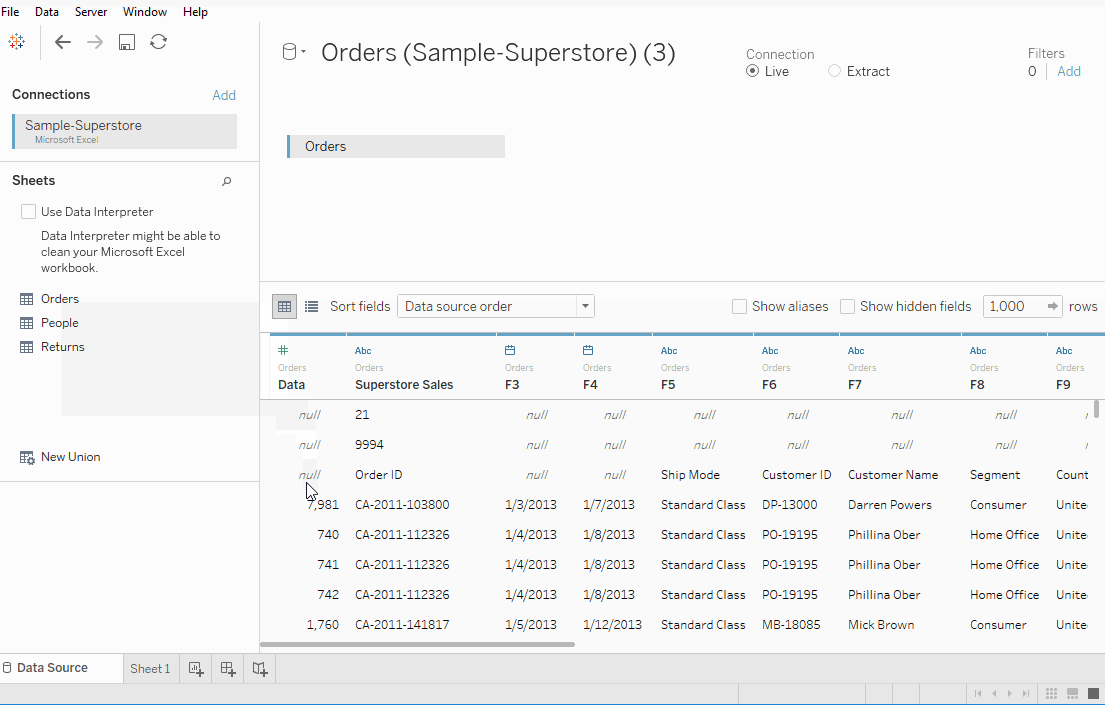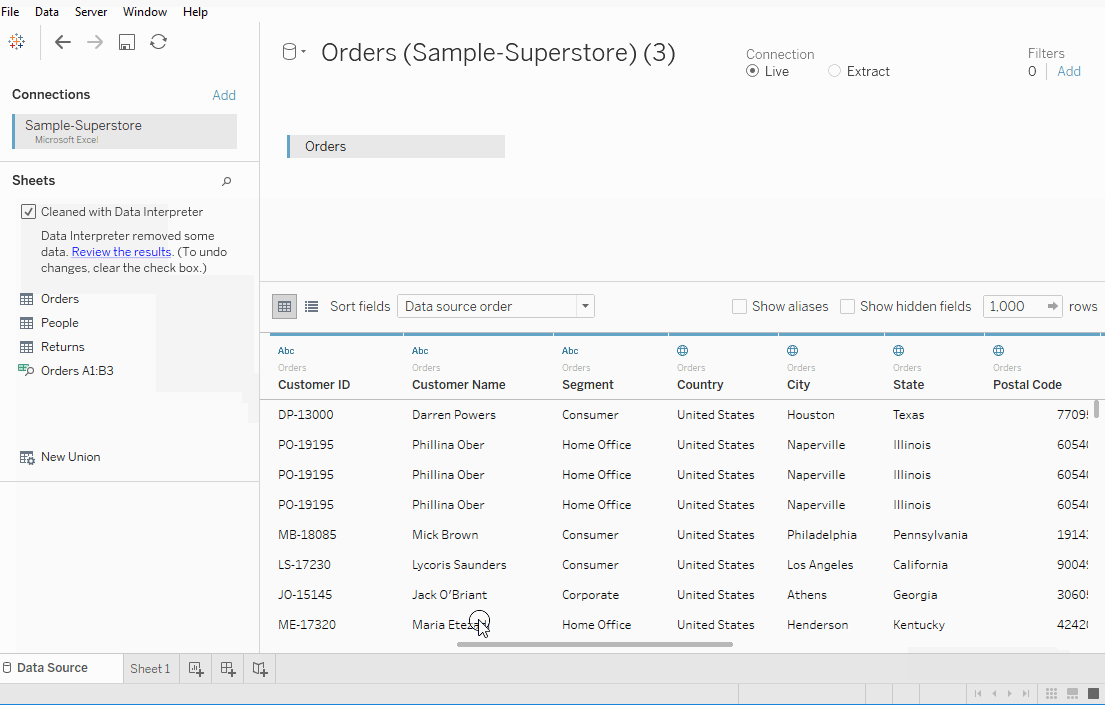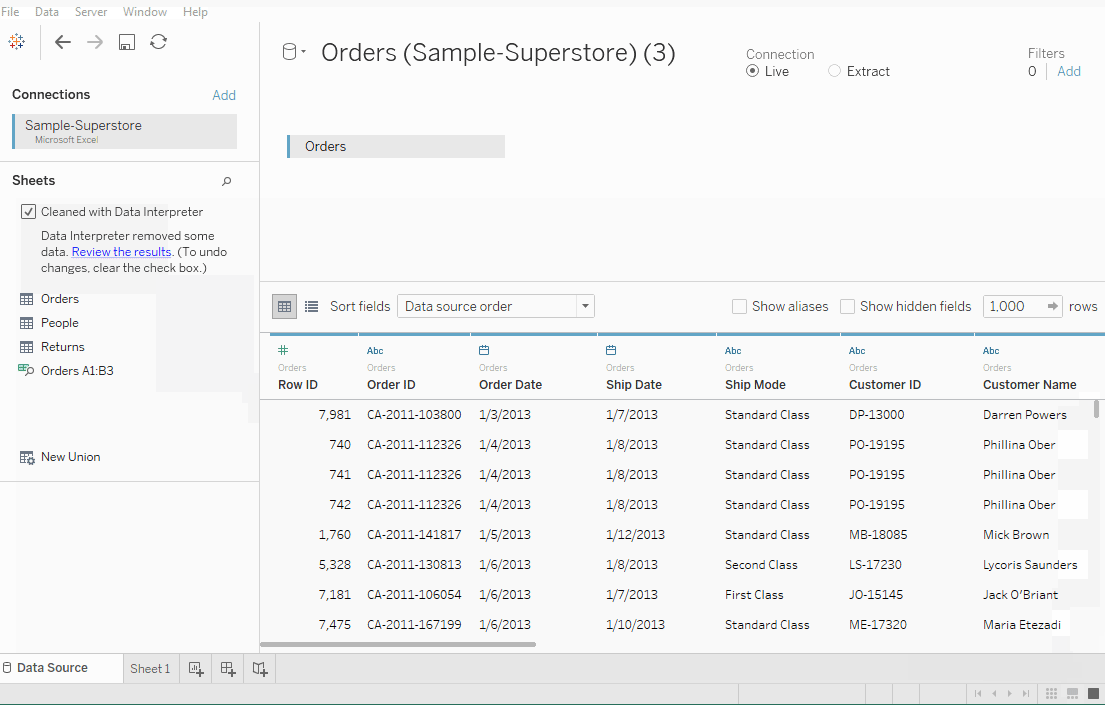
在 Sheets 标签下,将显示三个工作表,分别是 Orders,People 和 Returns。然而,我们只关注 Orders 数据。双击 Orders 工作表,它就像电子表格一样打开。
-
我们观察数据的前三行看起来有点不同,并且不是我们期望的格式。在这里我们利用數據解讀器,也位于 Sheets 标签下。点击它,我们得到一个格式良好的工作表。
动手操作
創建視圖
我們將從生成一個簡單的图表開始。在這一節,我們將熟悉我們的數據,並開始對數據提問以獲得洞察力。在本節中,我們將遇到一些重要的術語。
維度
度量
聚合
維度 是類定性數據,如名稱或日期。預設情況下,Tableau會自動將包含類定性或分類信息的數據标识為維度,例如,任何含有文字或日期值的字段。這些字段通常作為數據行的列標題,如客戶名稱或訂單日期,並定義了在視圖中顯示的粒度级别。
度量 是定量數值數據。預設情況下,Tableau將任何含有這種類型的數據标识為度量,例如,銷售交易或利潤。被標識為度量的數據可以根據給定的維度進行聚合,例如,按地區(維度)分的總銷售額(度量)。
聚合是指將行級數據彙總到更高類別,例如銷售總額或總利潤。
Tableau會自動對度量值和維度中的字段進行排序。然而,對於任何異常情況,也可以手動更改。
步驟
-
前往工作表。點擊工作區左下角的
工作表1標籤。
-
進入工作表後,從數據窗格下的
維度中,將訂單日期拖動到列架。將
訂單日期拖動到列架時,數據集中會為每個訂單年份創建一列。每列下都會有一個’Abc’指示器,這意味著可以在此處拖動文本、數值或文本數據。另一方面,如果我們在這裡拉動銷售,將創建一個交叉表,顯示每年的總銷售額。 -
同樣地,從
度量標籤,將銷售字段拖曳到行架。
Tableau會以銷售總和形式填充圖表。按訂單日期顯示每個年的銷售總聚合。Tableau對於包含時間字段(在這個例子中是訂單日期)的視圖总是填充線形圖表。.
手動操作
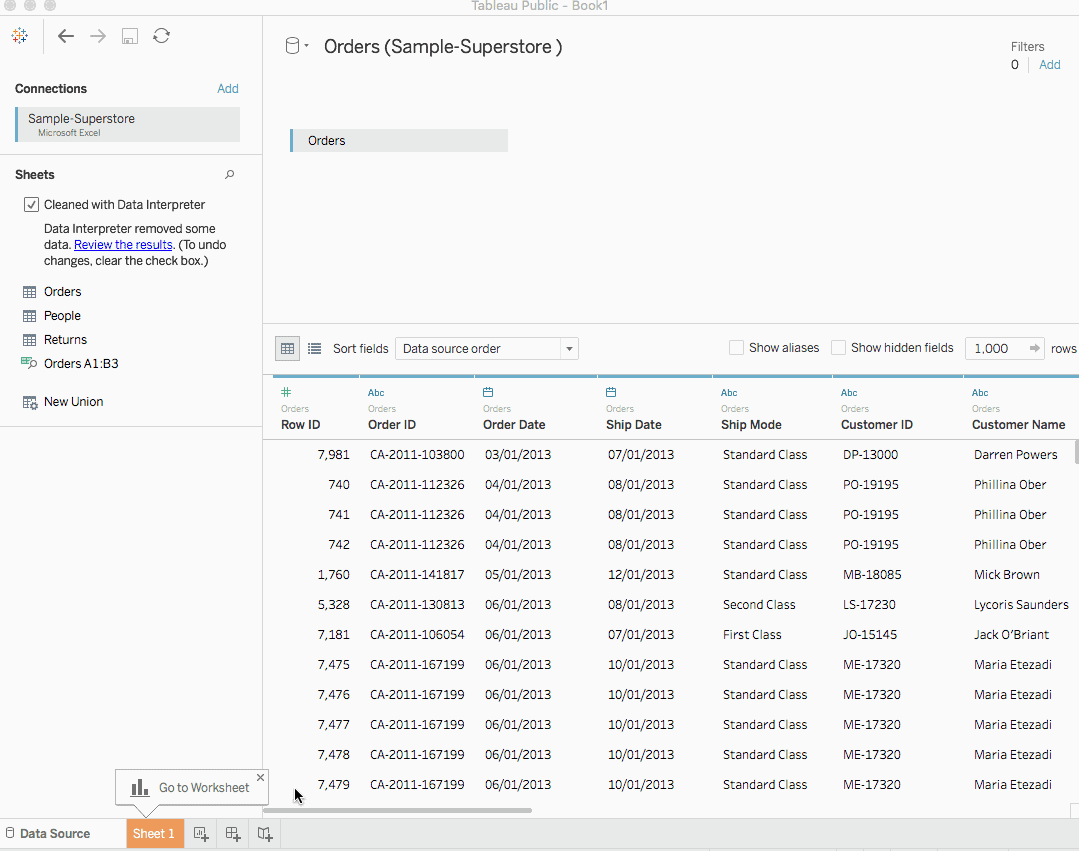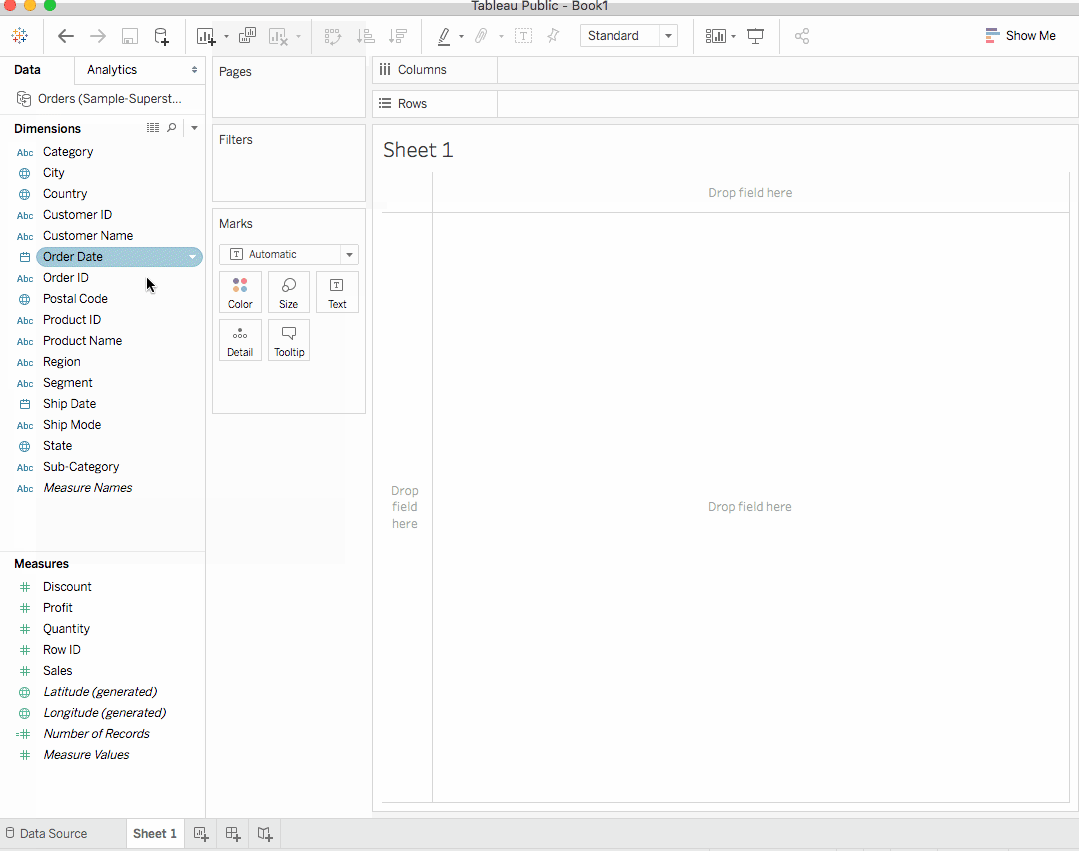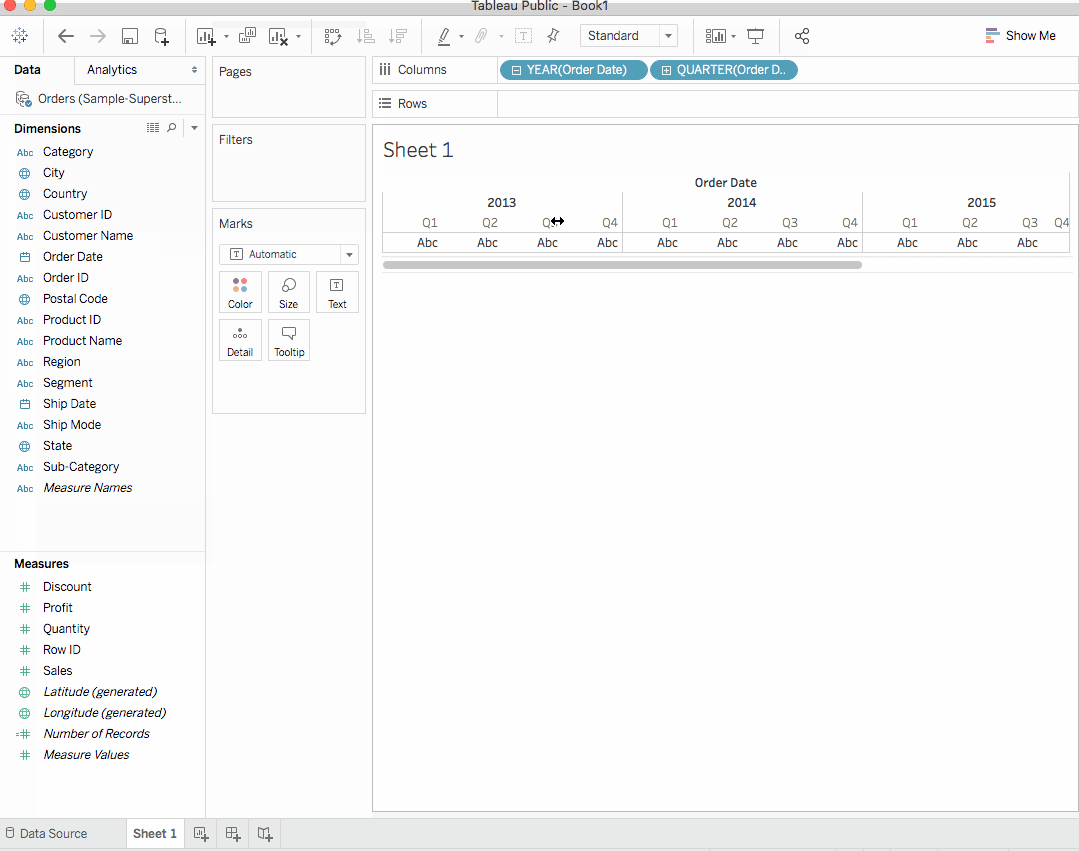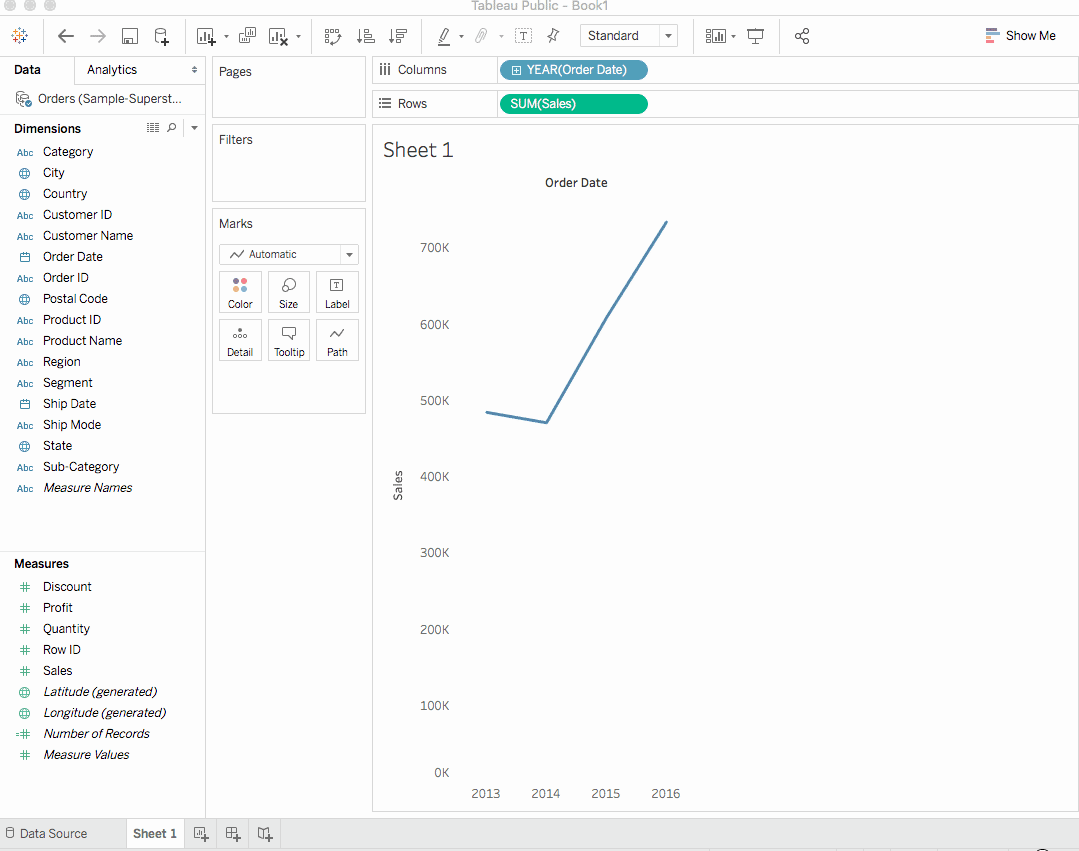
上面的線形圖 convey了什麼?嗯,它顯示銷售前景看起來非常Promising並且隨著時間增加。這是一個有價值的見解,但它幾乎沒有說太多關於哪些產品 contributes to 增加銷售。讓我們深入挖掘以獲得更多見解。
refined the View
讓我們深入挖掘並嘗試找出關於哪些產品推动更多銷售的更多信息。讓我們從添加產品類別開始,以不同的方式查看銷售總額。
步驟
-
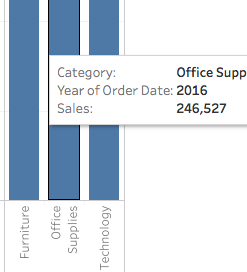
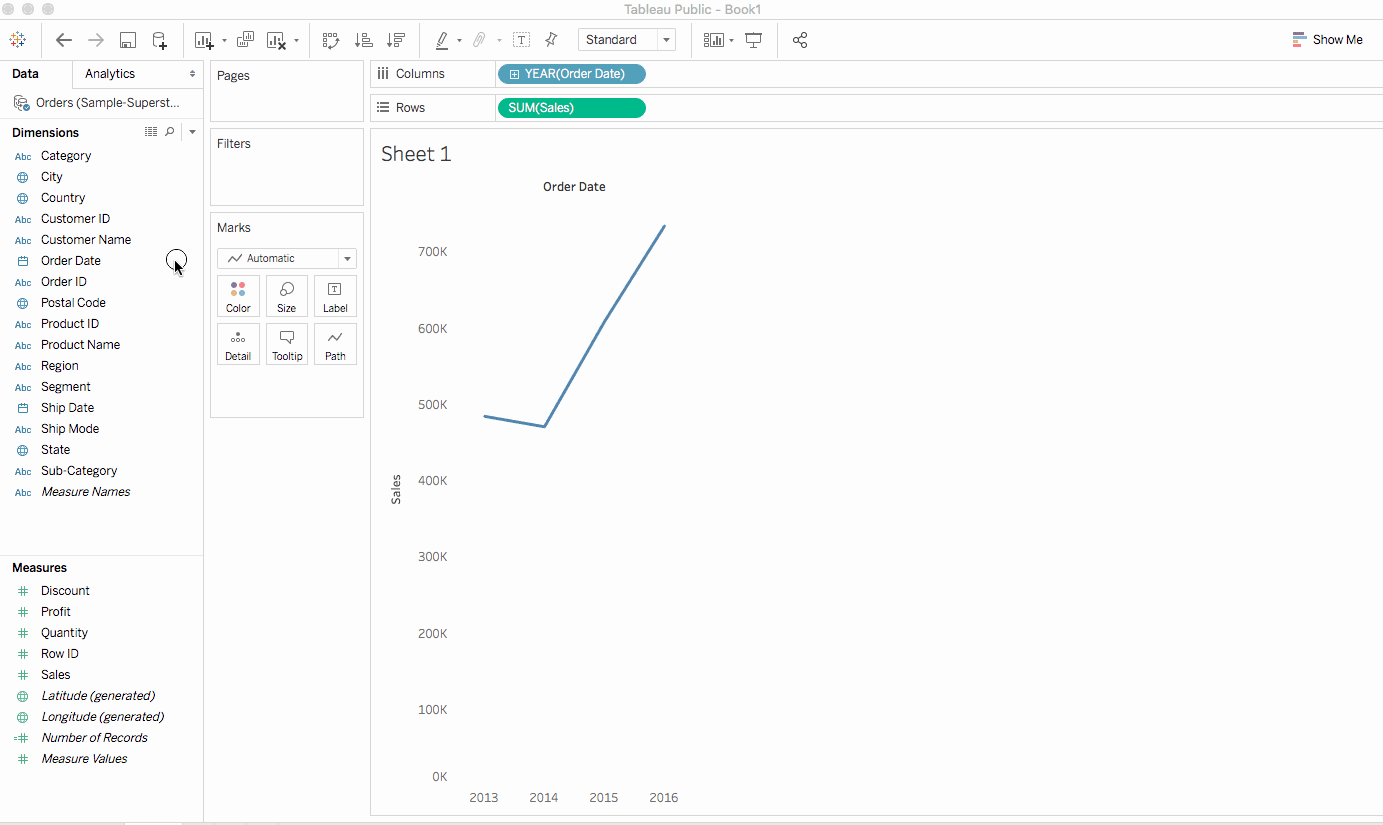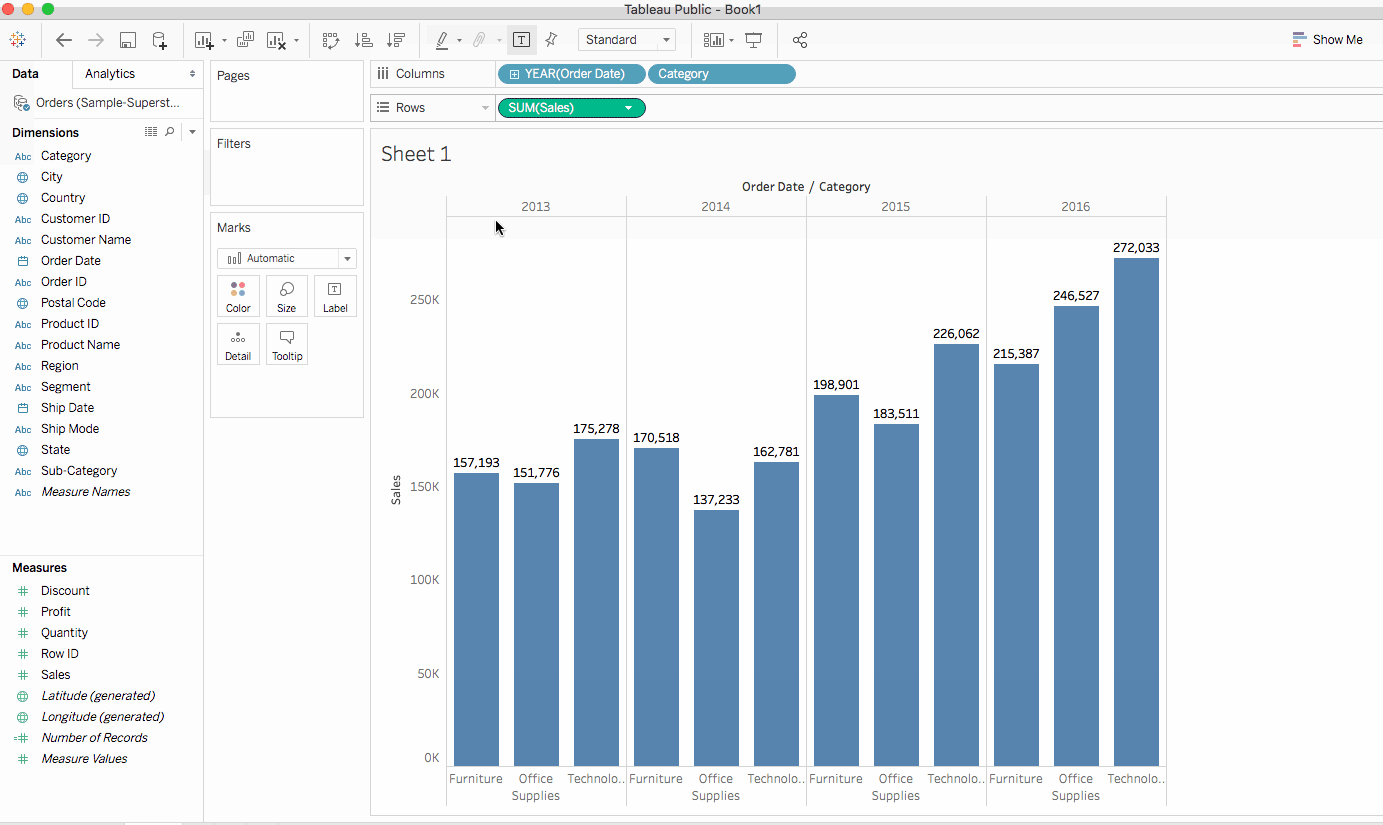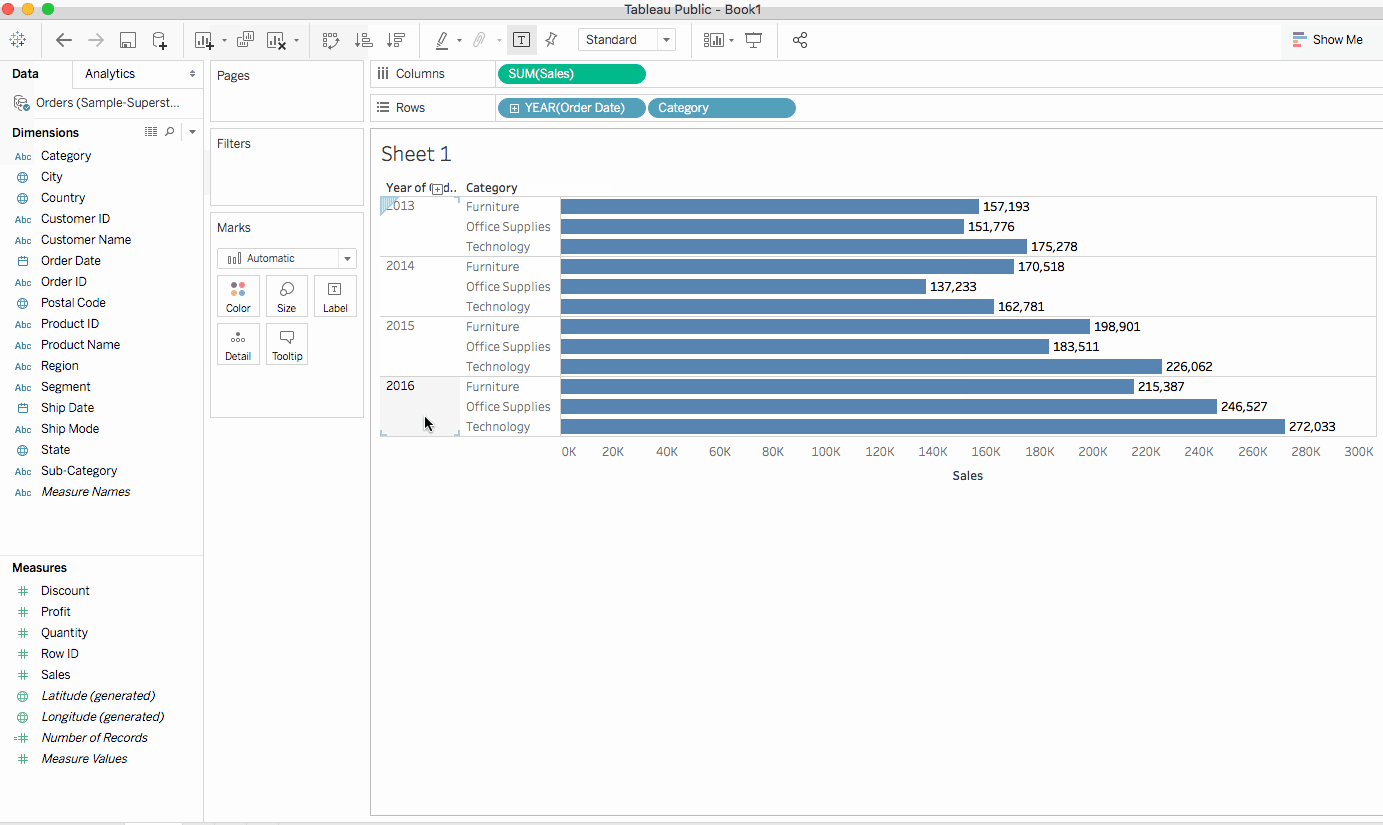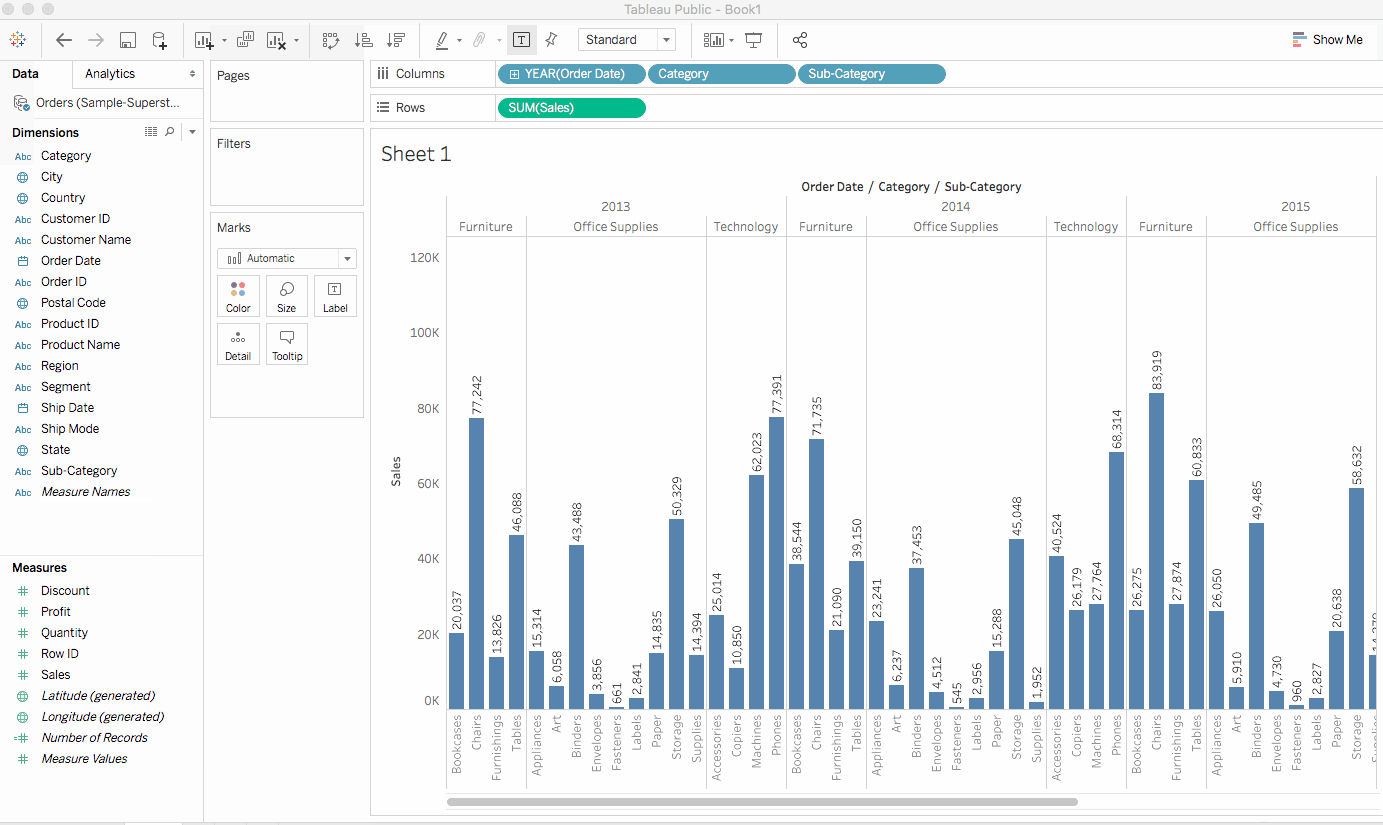
類別位於維度窗格中。將其拖動至列架並放在YEAR(訂單日期)旁邊。類別應該放在年份的右邊。這樣做之後,視圖會立即從線形圖變為條形圖。這張圖表顯示每年每個產品的總銷售情況。了解更多要查看視圖中每個數據點(即標記)的資訊,請將鼠標懸停在 其中一個條上以顯示工具提示。工具提示顯示該類別的總銷售額。以下是2016年辦公用品類別的工具提示:
要為視圖添加標籤,請在工具欄上點擊
顯示標記標籤。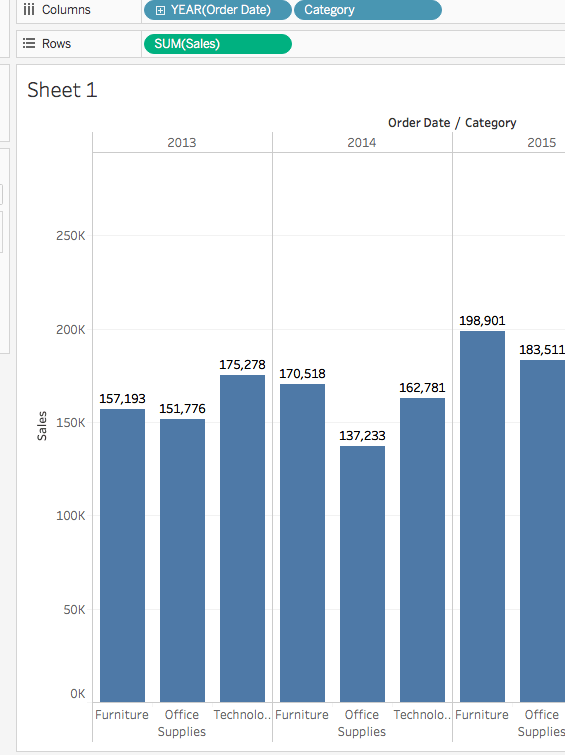
條形圖也可以水平顯示而不是垂直顯示。在工具欄上點擊
交換以實現這一點。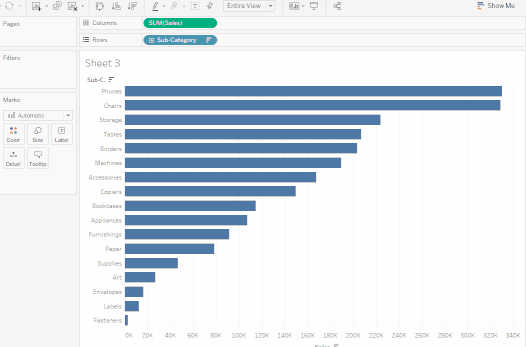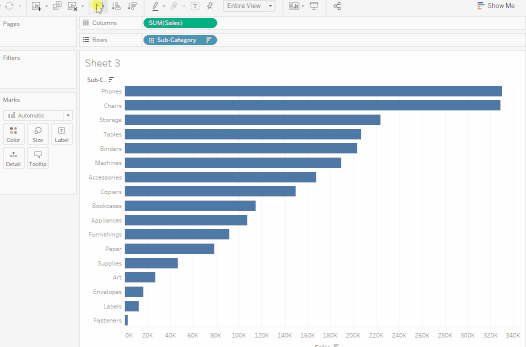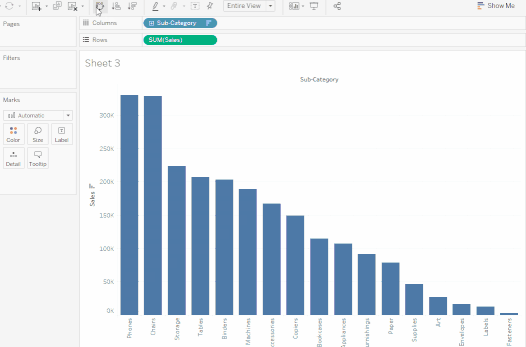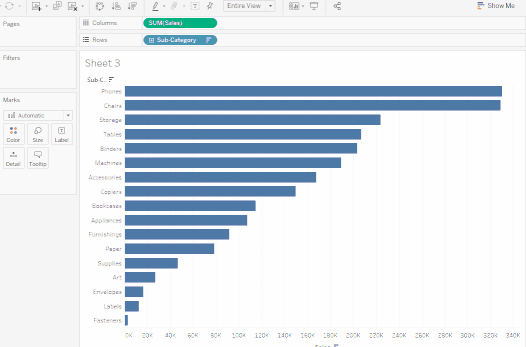
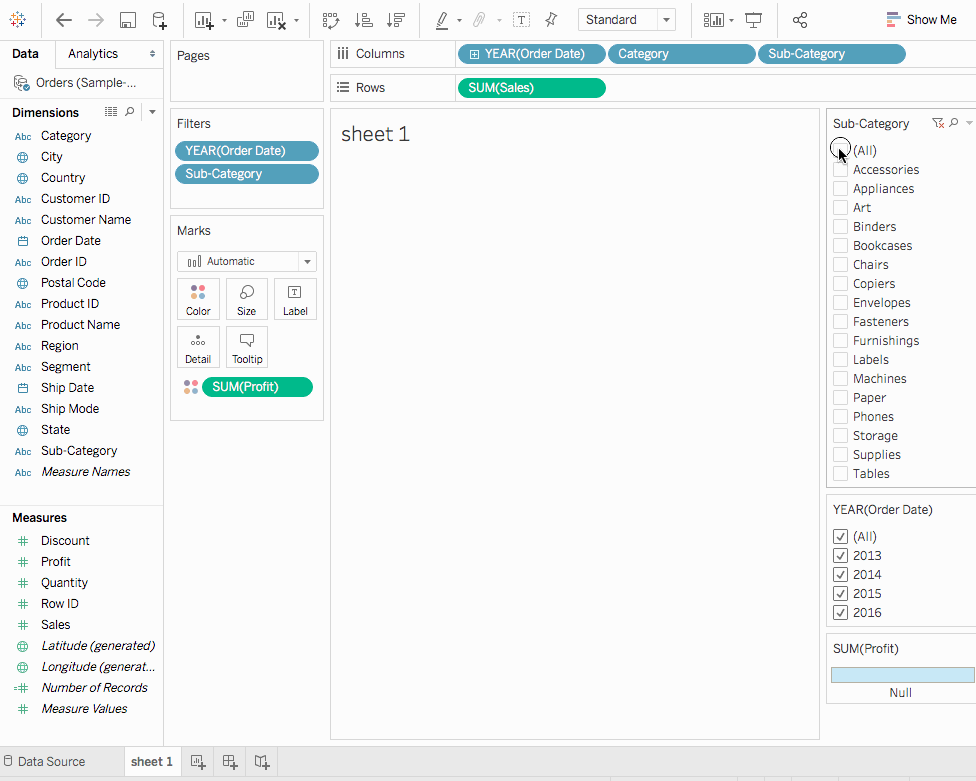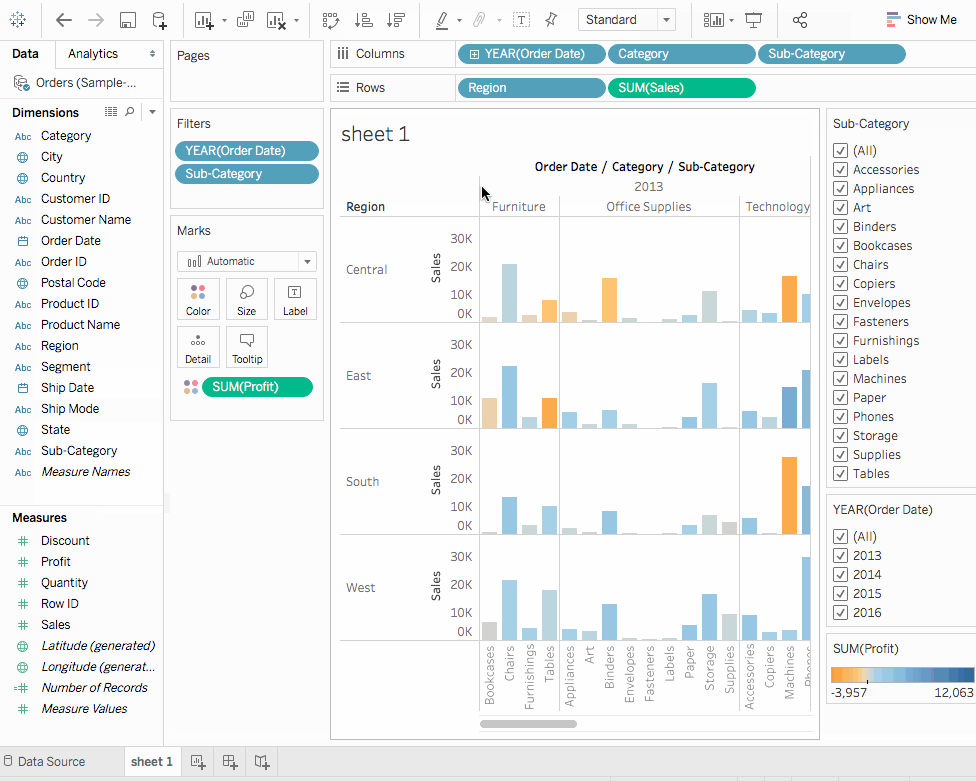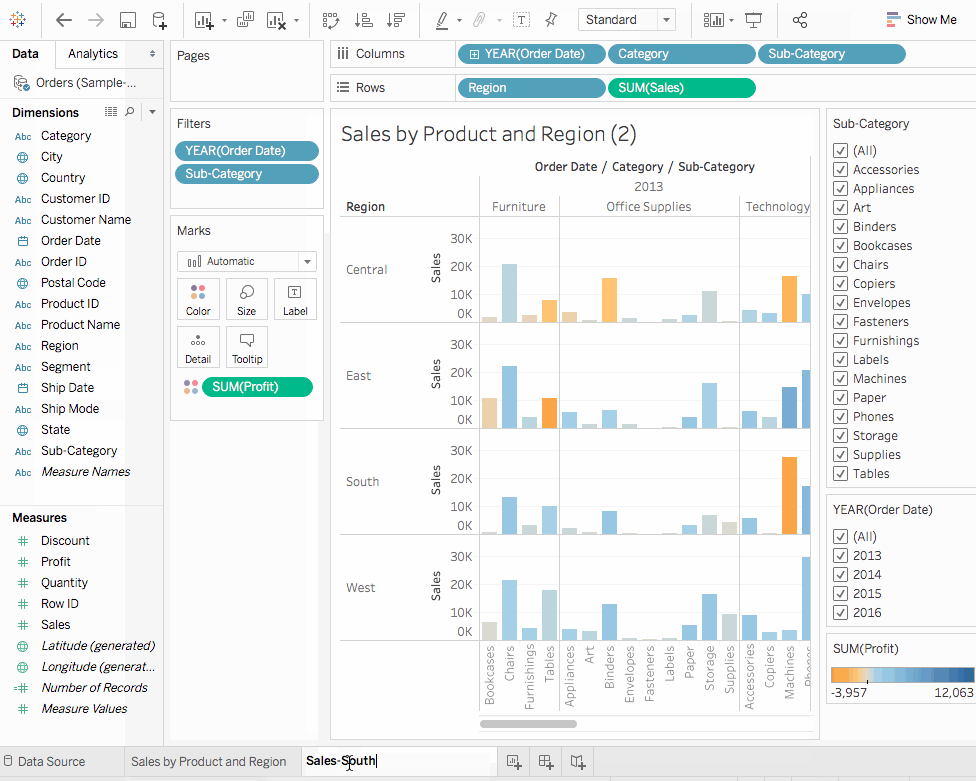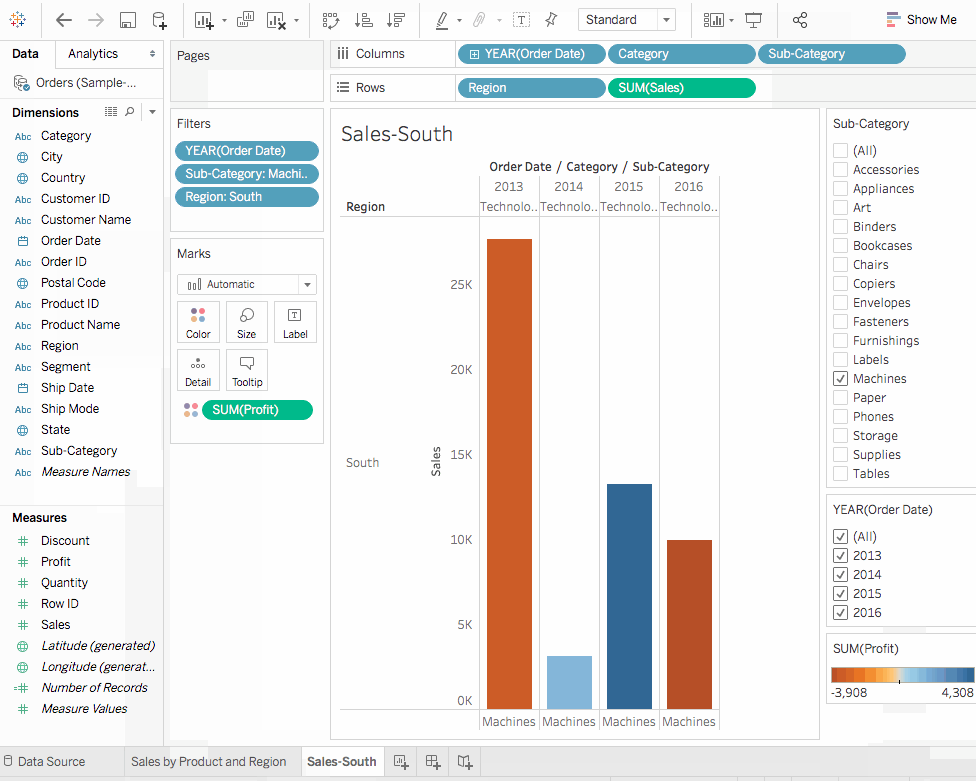
2. 上述視圖很好地展示了按類別分組的銷售,即家具、辦公用品和科技產品。我們也可以推斷,除了2016年,家具銷售的增長速度超過了辦公用品的銷售。因此,將銷售努力集中在家具上而不是辦公用品將是明智的選擇。但家具是一個龐大的類別,包含許多不同的物品。我們如何識別哪種家具產品對銷售貢獻最大?
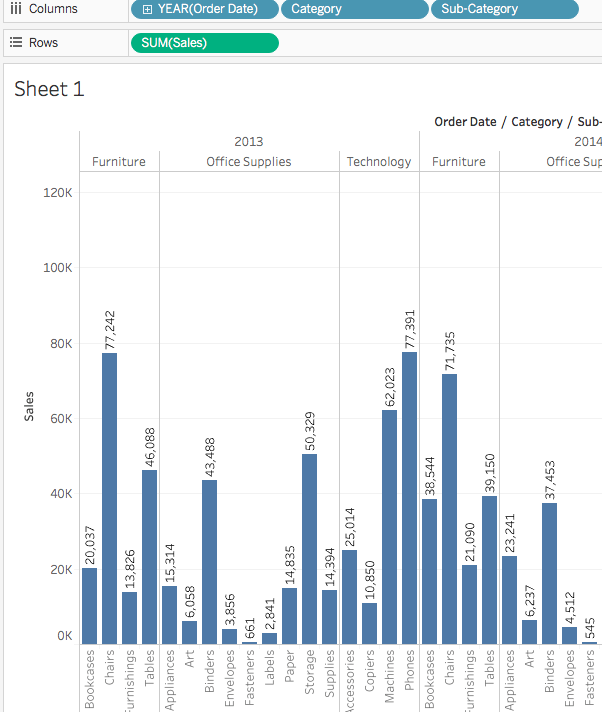
為了幫助回答這個問題,我們決定查看按子類別分組的產品,以了解哪些產品是熱銷商品。假設對於家具類別,我們只想了解書架、椅子、裝飾和桌子的細節。我們將雙擊或將子類別維度拖放到列架。
子類別是另一個離散字段。它進一步剖析了類別,並為每個按類別和年份分類的子類別顯示一個長條。然而,這是視覺上需要理解的大量數據。在下一部分中,我們將學習過濾器、顏色和其他使視圖更易於理解的方法。
手把手
3. 強調結果
在這一節中,我們將試圖集中于特定的結果。過濾器與顏色是用來加强对我們感興趣的細節焦点的手段。
向查看添加過濾器
過濾器可以用來包括或排除查看中的值。在這裡,我們嘗試向工作表中添加兩個簡單的過濾器,以使其更易于查看特定年份的產品銷售按子類別分佈。
步驟
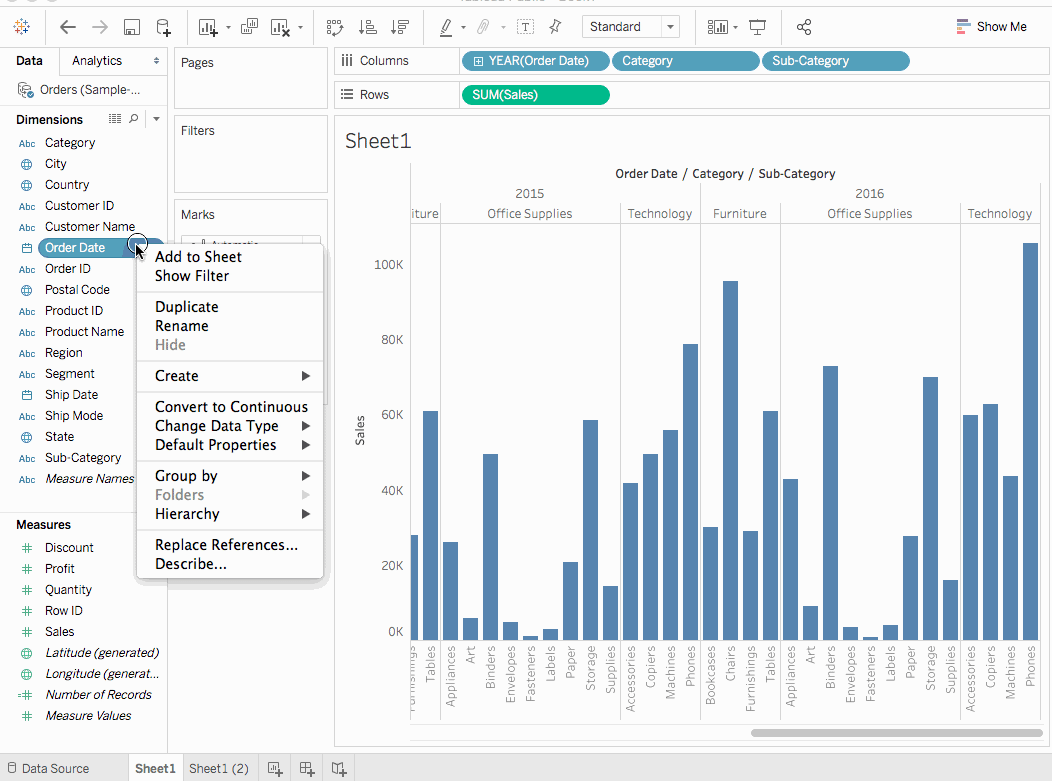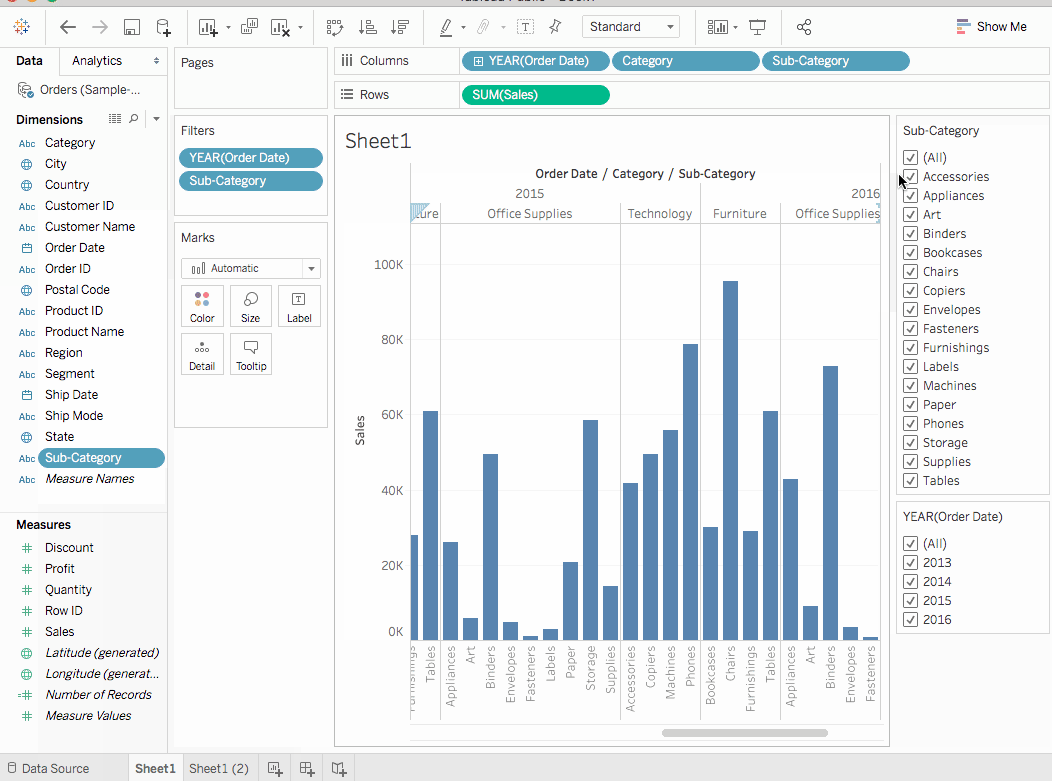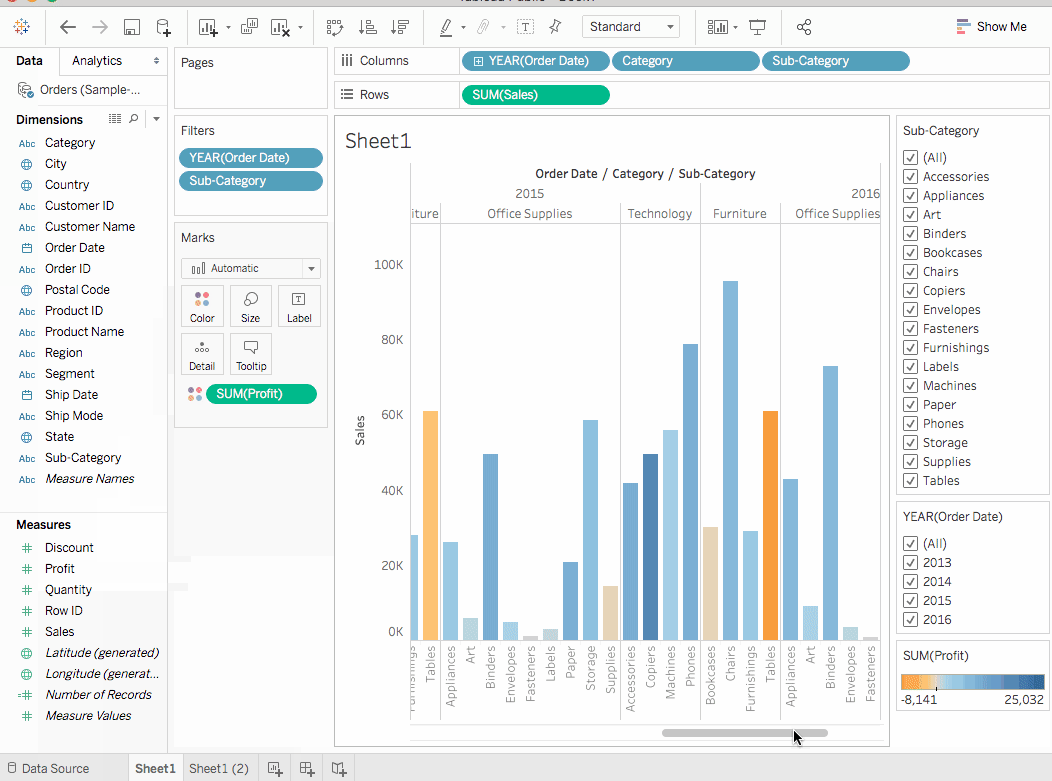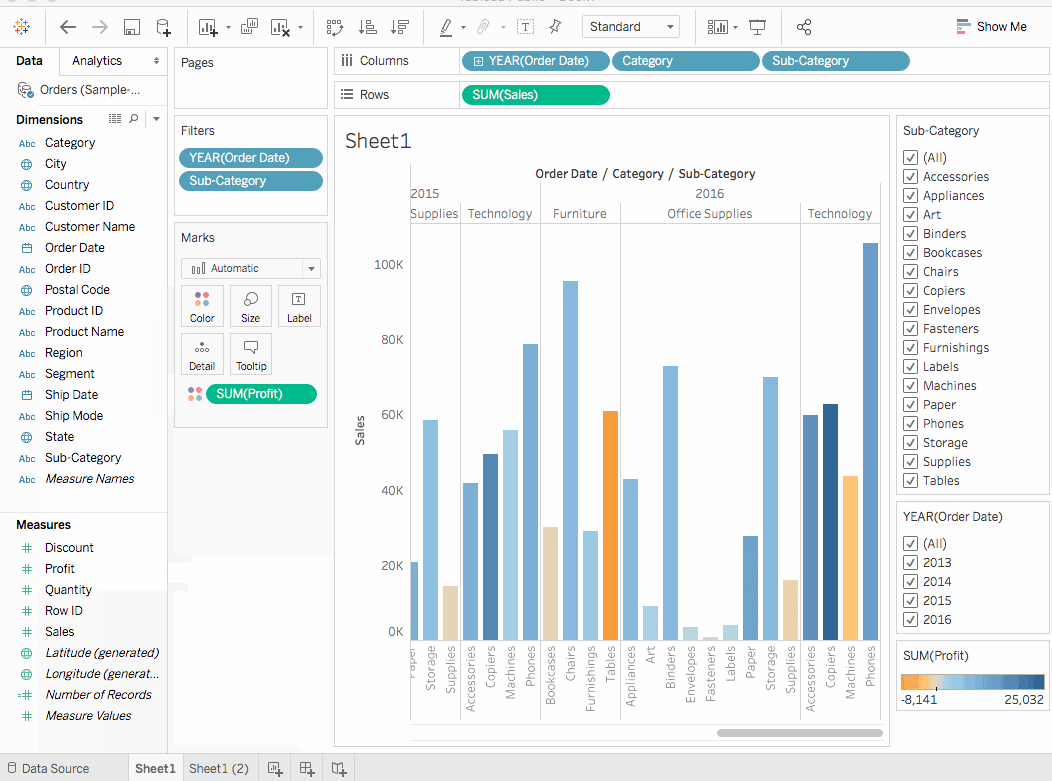
在數據面板中,在維度下,右鍵點擊訂單日期並選擇顯示過濾器。同樣為「子」->>「類別」字段重複進行。
過濾器是卡片的一種类型,並且可以通過簡單拖拽在工作表上移動。
向查看添加顏色
顏色在視覺識別模式上很有幫助。
步驟
在數據面板中,在度量下,將獲利拖動到标记卡上的顏色。

可以看到,書架、桌子甚至是機械设备對盈利有負面影響,即亏损。這是一個有力的洞見。
手把手

關鍵發現
讓我們更仔細地查看過濾器,以找出更多关于無利潤產品的資訊。
步驟
- 在檢視中,在
細分类過濾卡片中,除書架、桌子和機器以外的所有方塊取消勾選。這讓我發現一個有趣的事實。在某些年份,書架和機器實際上是獲利的。然而,在2016年,機器變得無利可图。 - 在
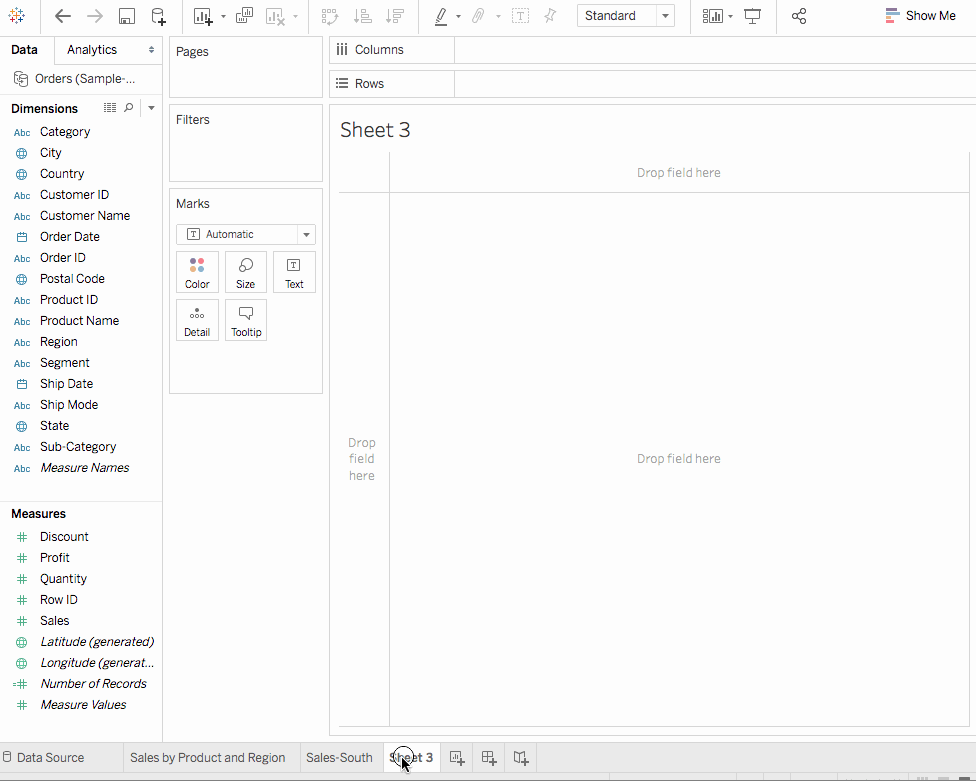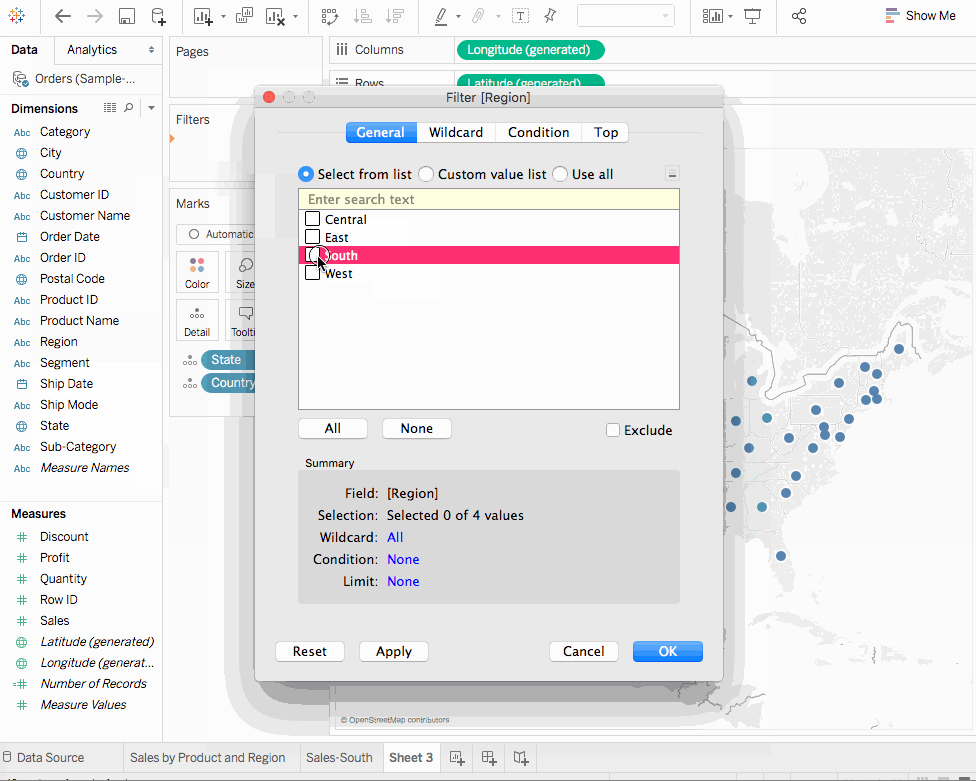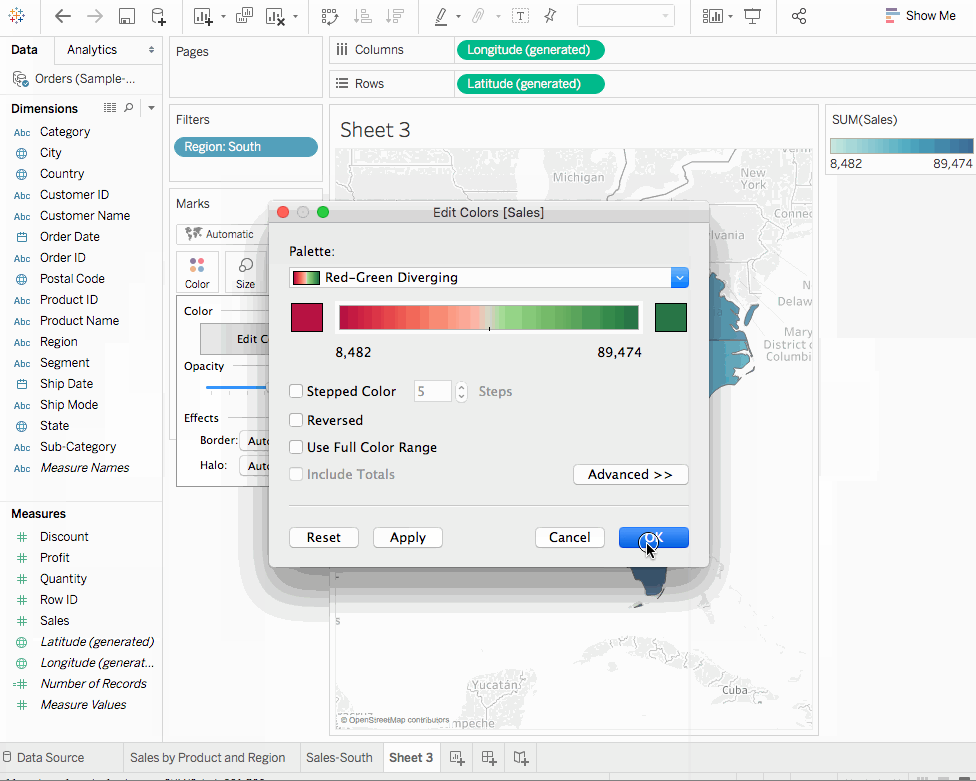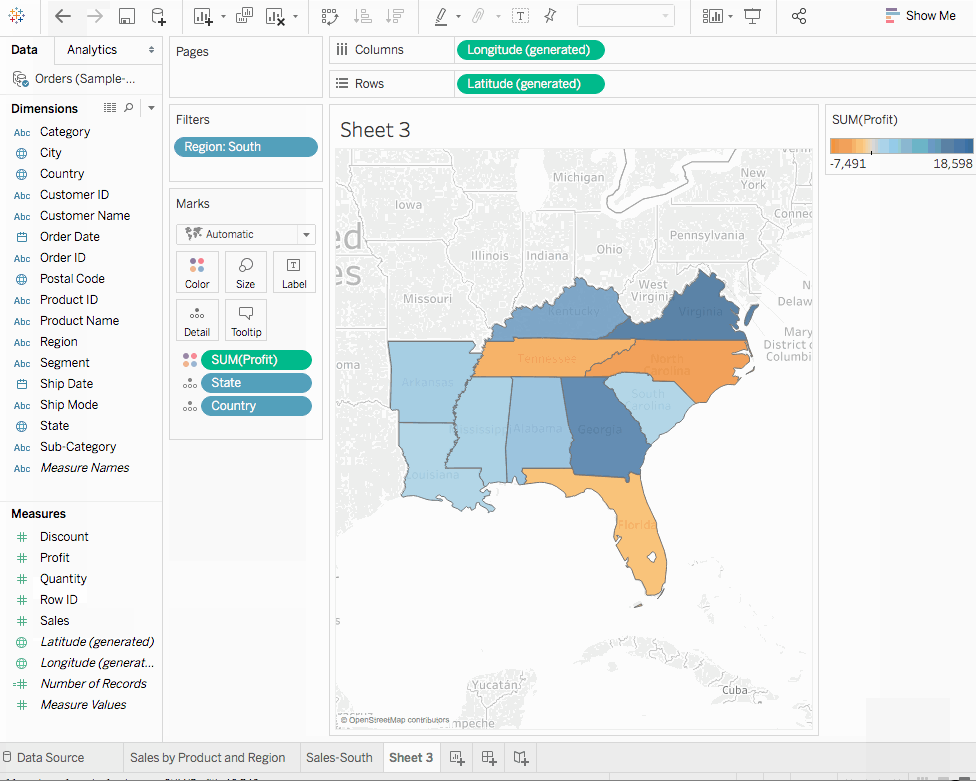
細分类過濾卡片中選擇全部,以顯示所有細分目錄。 - 從維度中,將
地區拖動到行架子,並將其置於Sum(Sales)標籤的左邊。我們發現,南部地區的機器報告的总体亏損程度比您其他地區要高。 - 現在給工作表命名。在工作區底部的左邊,雙擊
Sheet 1並輸入產品和地區銷售。 - 為了保留檢視,Tableau讓我們複製我們的等工作表,這樣我們可以在另一張表單中從我們停止的地方繼續。
- 在您的工作簿中,右擊
產品和地區銷售表單,選擇複製,並將複製的表單重命名為銷售-南部。 - 在新的工作表中,從維度中,將
地區拖動到過濾架子,作為檢視中的過濾器。 - 在
過濾地區對話框中,除南部以外的所有方塊清除勾選,然後點擊確定。現在我們可以專注於南部地區的銷售和利潤。我們發現,2014年和2016年機器的銷售均出現虧損。我們在下個部分調查這點。 - 最後,不要忘記透過選擇
檔案 > 另存新檔來儲存結果。讓我們將我們的工作簿命名為地區銷售與利潤。
實作
4. 地圖視圖
建立地圖視圖
當我們查看地理資料(地區字段)時,地圖視圖非常有用。在當前例子中,Tableau 自動識別國家、州、城市和郵政編碼字段包含地理資訊。
步驟
- 建立新的工作表。
- 在資料窗格下將
州和國家加入到標記卡上的細節中。我們獲得地圖視圖。 - 將
地區拖到過濾器櫃上,然後過濾至只有南部。地圖視圖現在縮放到只有南部地區,並且每個州都有一個標記。 - 將
銷售衡量指標拖到標記卡上的顏色標籤。我們得到一個填色地圖,顏色顯示每個州的銷售範圍。 - 我們可以透過點擊標記卡上的
顏色並選擇編輯顏色來更改顏色方案。我們可以嘗試可用的色調板。 - 我們觀察到 佛羅里達 在銷售方面的表現最佳。如果我們將鼠標懸停在佛羅里達上,它顯示總銷售額為89,474美元,與南卡羅來納州相比,例如,後者只有8,482美元的銷售額。現在我們來衡量一下
利潤的表現,因為利潤是比單獨銷售更好的指標。 - 拽動
Profit至Color在標記卡上。我們現在看到田納西州、北卡羅來納州和佛羅里達州的利潤為負,即使它們在銷售方面看起來表現良好。將工作表重命名為利潤地圖
實際操作
深入了解細節
地圖使我們能夠廣泛地視覺化數據。在上一個步驟中,我們發現田納西州、北卡羅來納州和佛羅里達州的利潤為負。在這一部分,讓我們繪製一個條形圖來探索負利潤的原因。
步驟
-
複製利潤地圖工作表,並將其命名為負利潤條形圖。
-
在負利潤條形圖工作表上點擊
顯示我。顯示我會展示在工作表中提到的項目之間可以繪製圖表的種種方式。從顯示我選擇水平條形選項,視圖會立即從垂直條變更為水平條。 -
我們可以透過單純點選並拖動滑鼠游標來同時選擇多個條形圖。我們只想專注於三個州,即田納西州、北卡羅來納州和佛羅里達州。因此,我們只會選擇與它們相關的條形圖。
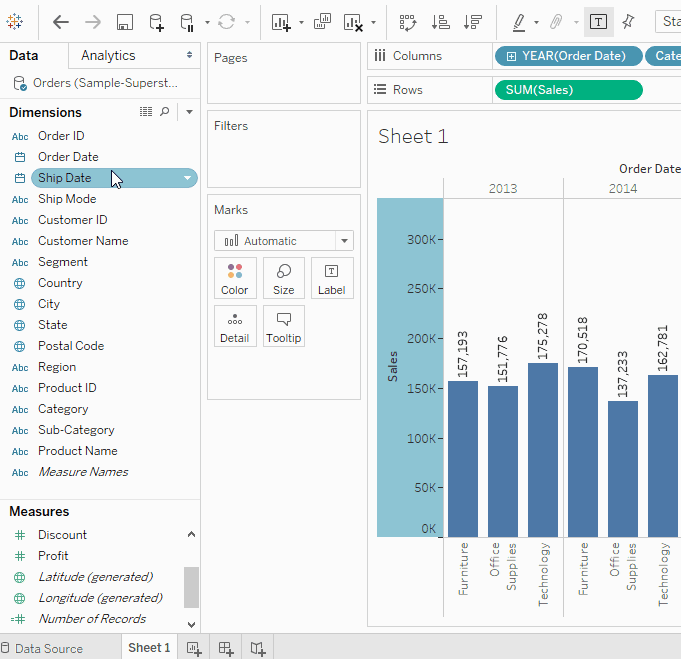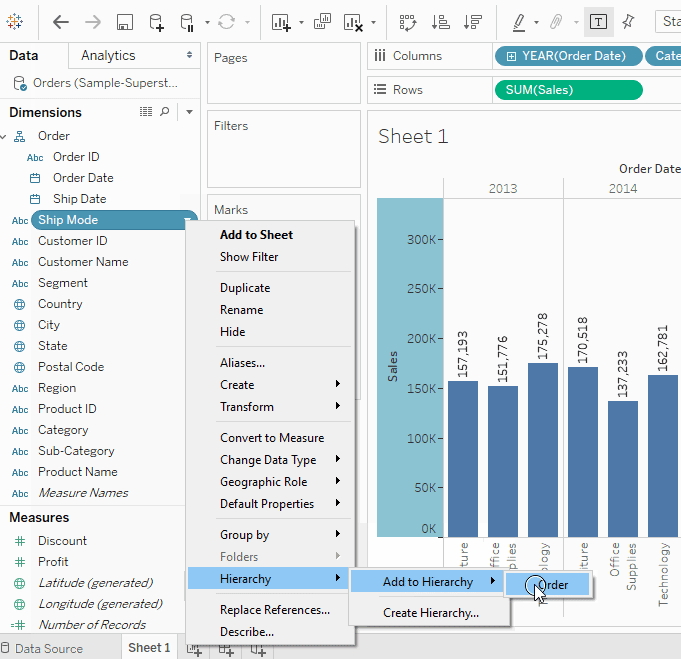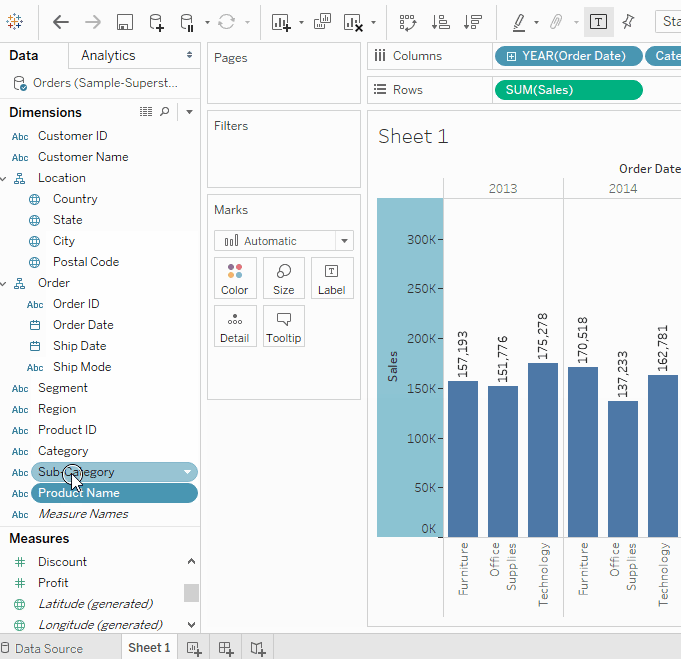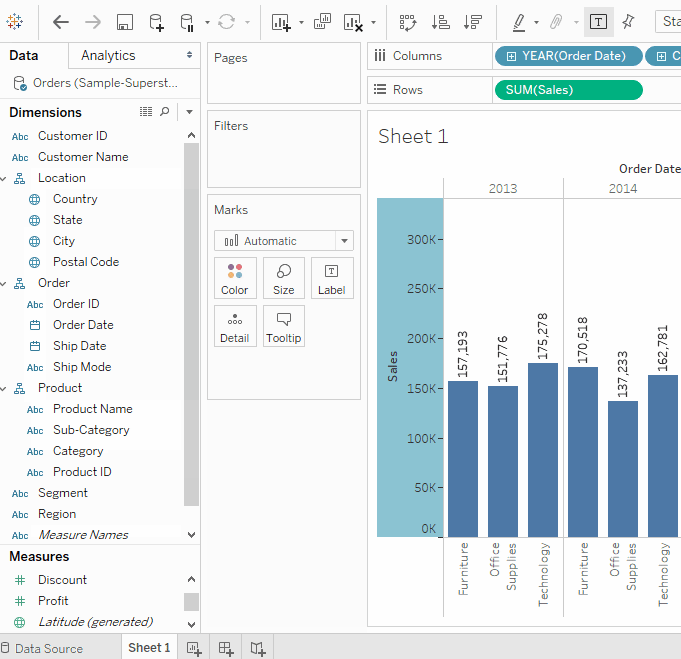
了解更多建立層次結構
當我們想要將相似的欄位分組,以便在viz中快速切換不同層次時,層次結構就非常有用。- 在資料窗格中,將一個欄位拖動並直接放在另一個欄位上方,或右鍵點擊該欄位並選擇
- 將其他任何欄位拖入層次結構中。也可以透過簡單地將欄位拖動到新位置來重新排序層次結構中的欄位。在當前的viz中,我們將建立以下層次結構:位置、訂單和產品。
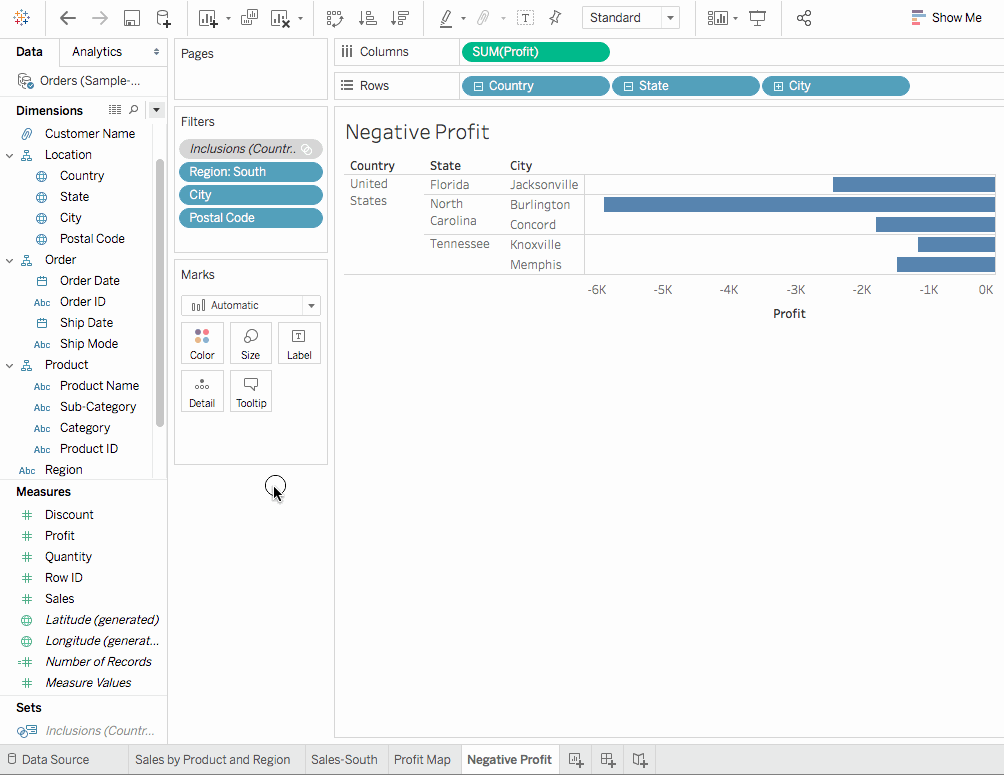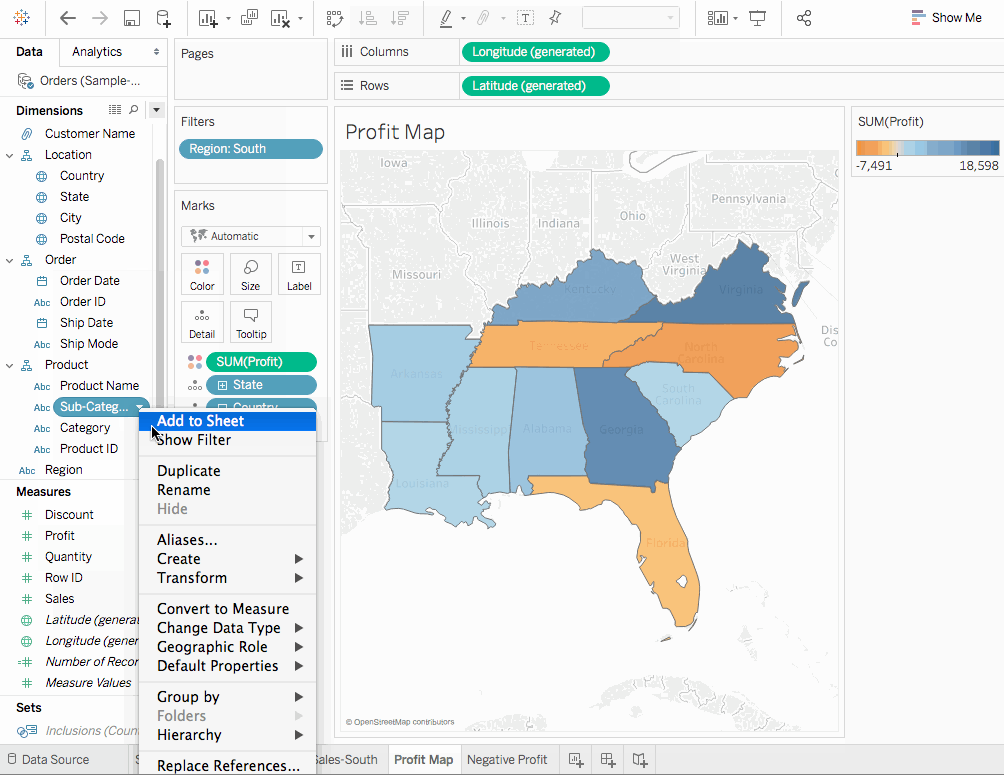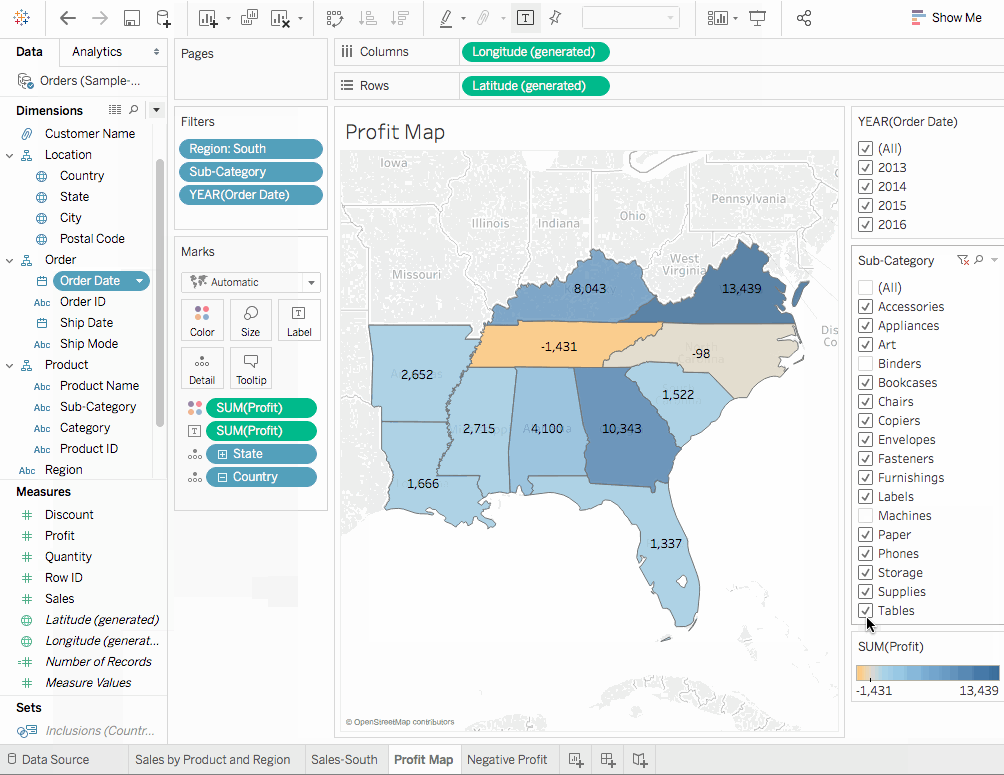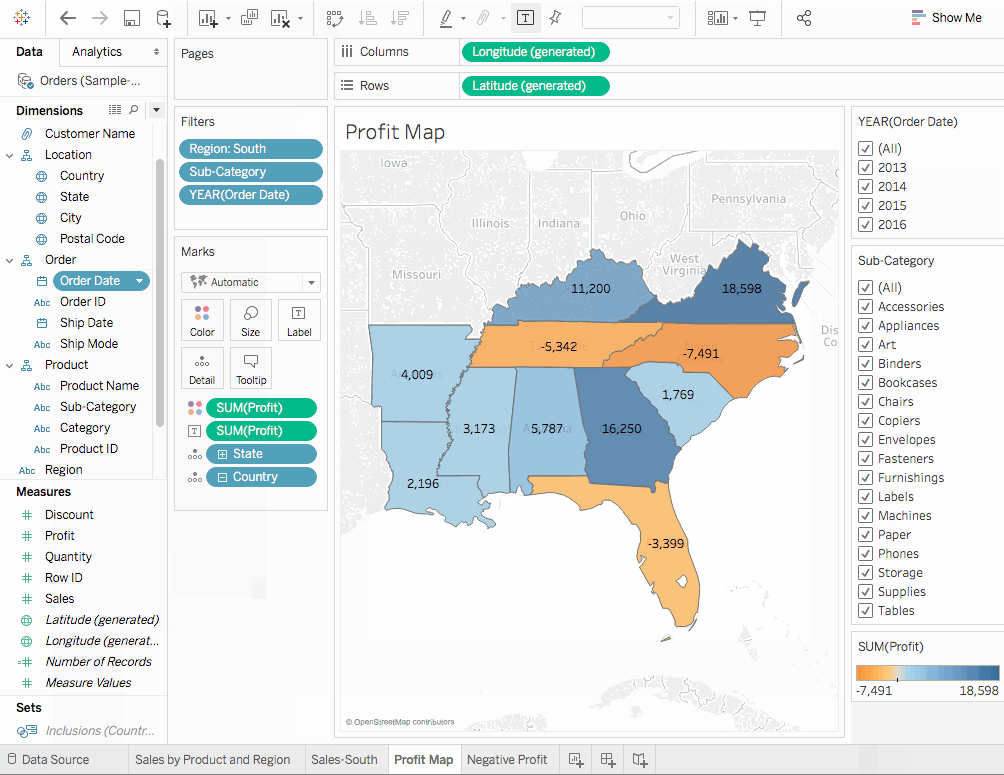
-
在列架上,點擊
州字段的加號圖示,以便钻取到城市層次。- 數據量很大。我們可以使用
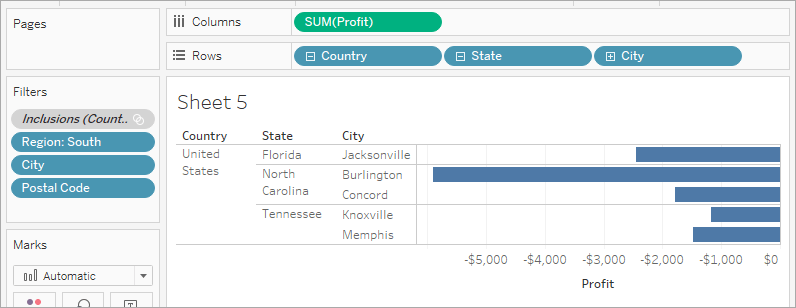
N-Filter來筛选並顯示表現最差者。为此,從數據面板拖曳城市到筛选架。點擊按字段,然後點擊頂部下拉選項並選擇底部以顯示表現最差者。在文本框中輸入5,以在數據集中的显示表现最差的5个。
- 數據量很大。我們可以使用
我們現在看到佛罗里達州的杰克遜维尔和邁阿密;北卡罗來纳州的柏靈頓;以及田纳西州的諾克斯维尔和孟菲斯是盈利表現最不佳的城市。這裡还有一个标记——北卡罗來纳州的杰克遜维尔——不應該出现在這裡,因為它有营利性的銷售。這意味著我們應用的人民过滤器有問題。我們將借助Tableau順序操作來解決。
-
在過濾器架上,右擊包含(國家,州)集合,並選擇
添加到上下文。我們發現現在康cord(北卡羅來纳州)出现在视图中,而邁阿密(佛羅里達州)消失了。這現在是有道理的。 -
但杰克遜维尔(北卡羅來纳州)仍然存在,這是錯誤的。在行架上,點擊
城市標籤上的加號圖示,钻取到郵政編碼層。右擊杰克遜维尔,NC 28540的郵政編碼,然後選擇排除,手動排除杰克遜维尔。 -
拖曳行架上的郵政局代碼。這是最終視圖。
动手
研究发现
現在我們只关注那些亏损企業,也就是產品,並讓我們確定這些產品售出的地點。
步骤
- 拖曳
子類別到行以進行更深入的分析。 - 同樣地,將
盈利拖曳到顏色上於标记卡。這讓我們能快速發現盈利為負的產品。 - 右擊
訂單日期並選擇顯示過濾器。看来 Machines, tables, 和 binders 表現不佳。那麼我們應該做什麼?一個解決方案可能就是要停止在這些產品上销售在Jacksonville, Concord, Burlington, Knoxville, 和 Memphis。讓我們確認一下我們的決定是否正確。 - 讓我們回到之前創建的
盈利地圖表單标签。 - 現在,點擊
子類別字段以選擇顯示過濾器選項。 - 將
Profit從度量下拉至標籤标记卡。 - 再次,點擊
訂單日期並選擇顯示過濾器。從過濾器中我們清除了我們認為對負利润有貢獻的項目。因此,分別取消勾選Binders、Machines和Tables前面的方框。現在我們只剩下了盈利实体。這表明像Binders、機器和桌子這樣的实体在某些地區實際上正在造成損失,我們的發現是正確的。
手把手
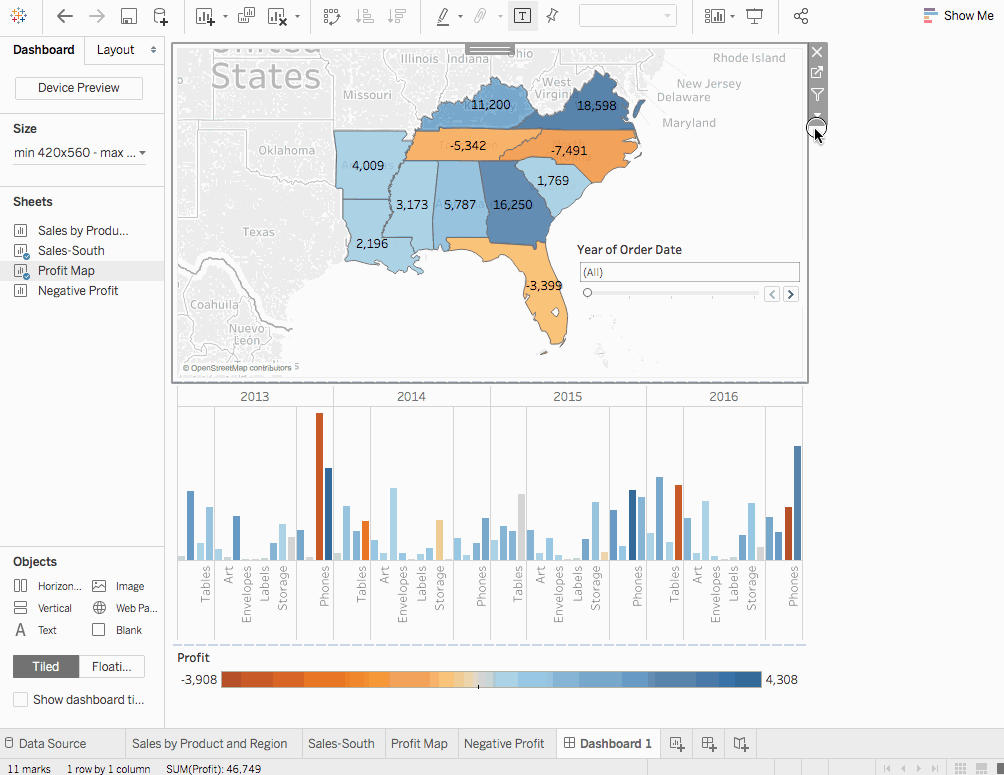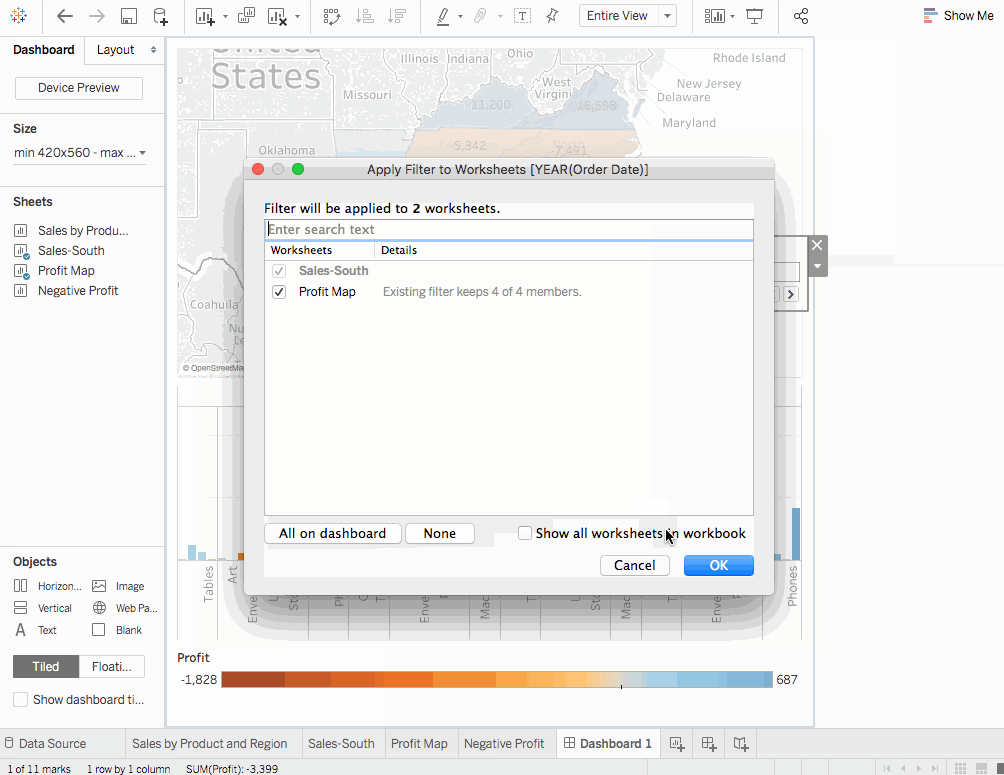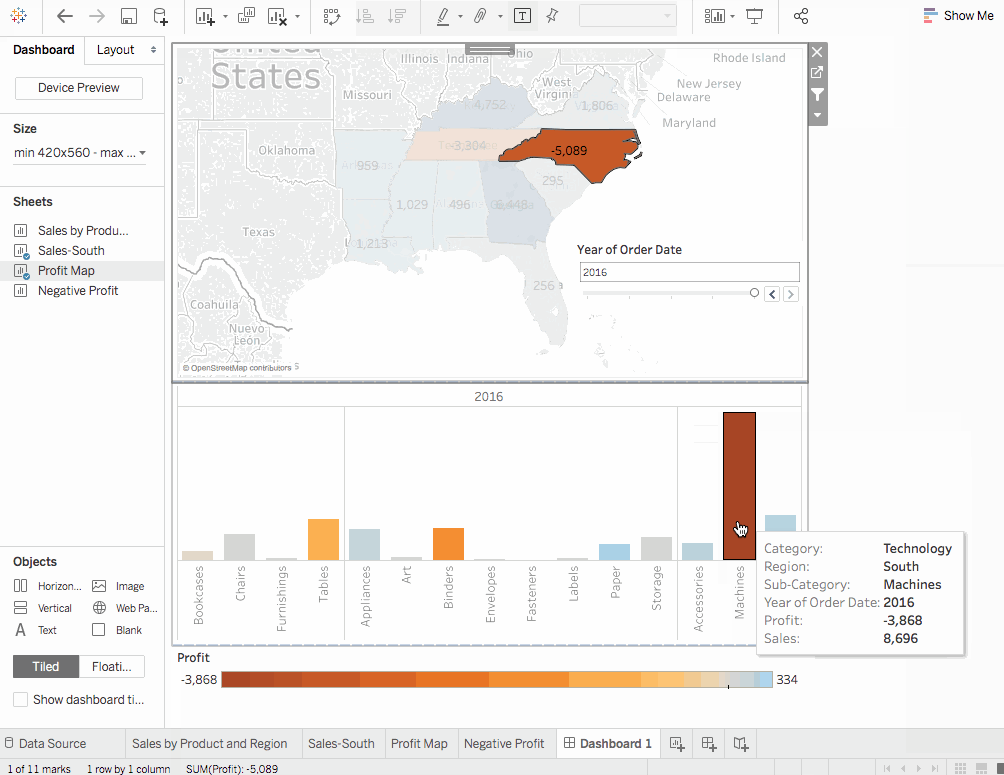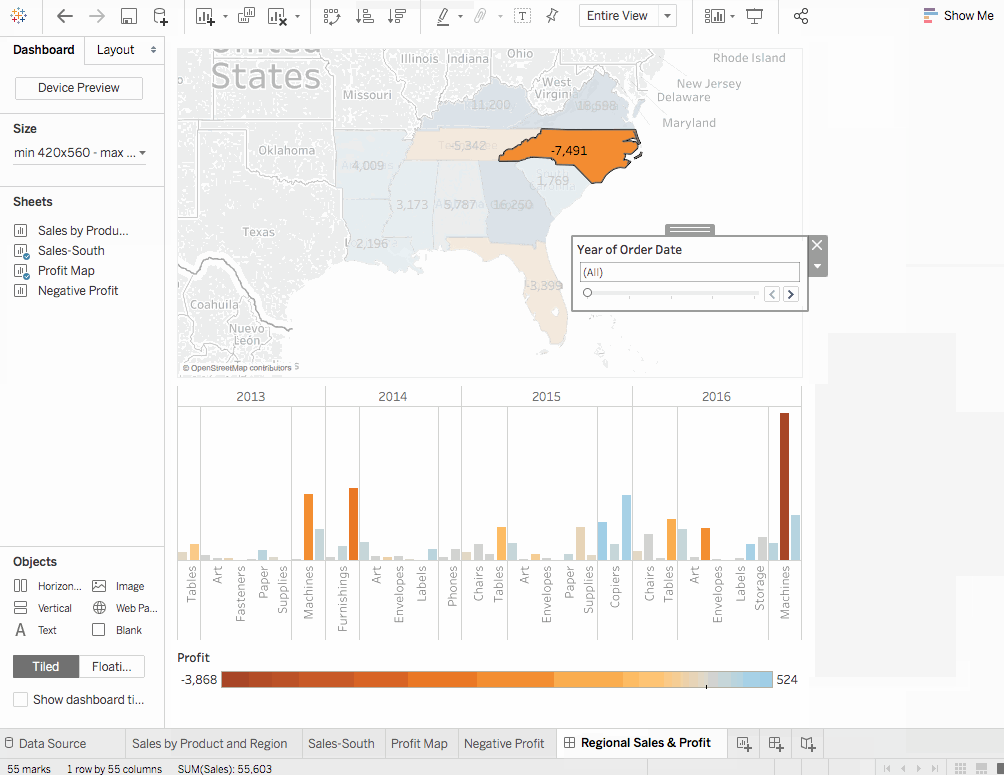
5. 控制面板
控制面板是多個查看器的集合,讓您同時比較各種數據。
創建控制面板
步驟
- 點擊
新建控制面板按鈕。 - 將
南部銷售拖到空控制面板中。 - 將
利润地圖拖到控制面板中,並將它拖到南部銷售視圖上方。兩個視圖可以同時查看。為了能夠以其他人能夠理解的方式呈現數據,我們可以將控制面板按照喜好排布。 - 在控制面板視圖中的
南部銷售工作表上,點擊地區下方,取消顯示標題。為所有其他標題重複相同過程。這有助於強調所需的內容,並隱藏不那麼重要的信息。 - 在
利潤地圖上,也隱藏標題,並對南部銷售地圖進行相同的步驟。 - 我們可以看到
子類別過濾卡片和訂單日期年份在右側重複了。讓我們通過簡單地劃掉它們來消除多餘的部分。最後,點擊訂單日期年份。出現一個下拉箭頭,選擇單個值(滑塊)的選項。現在讓魔法展開。通過在滑塊上選擇不同的年份來進行實驗,銷售也會相應變化。 - 將
SUM(利潤)過濾器拖放到南部銷售下面的儀表板底部以獲得更好的視圖。
實際操作
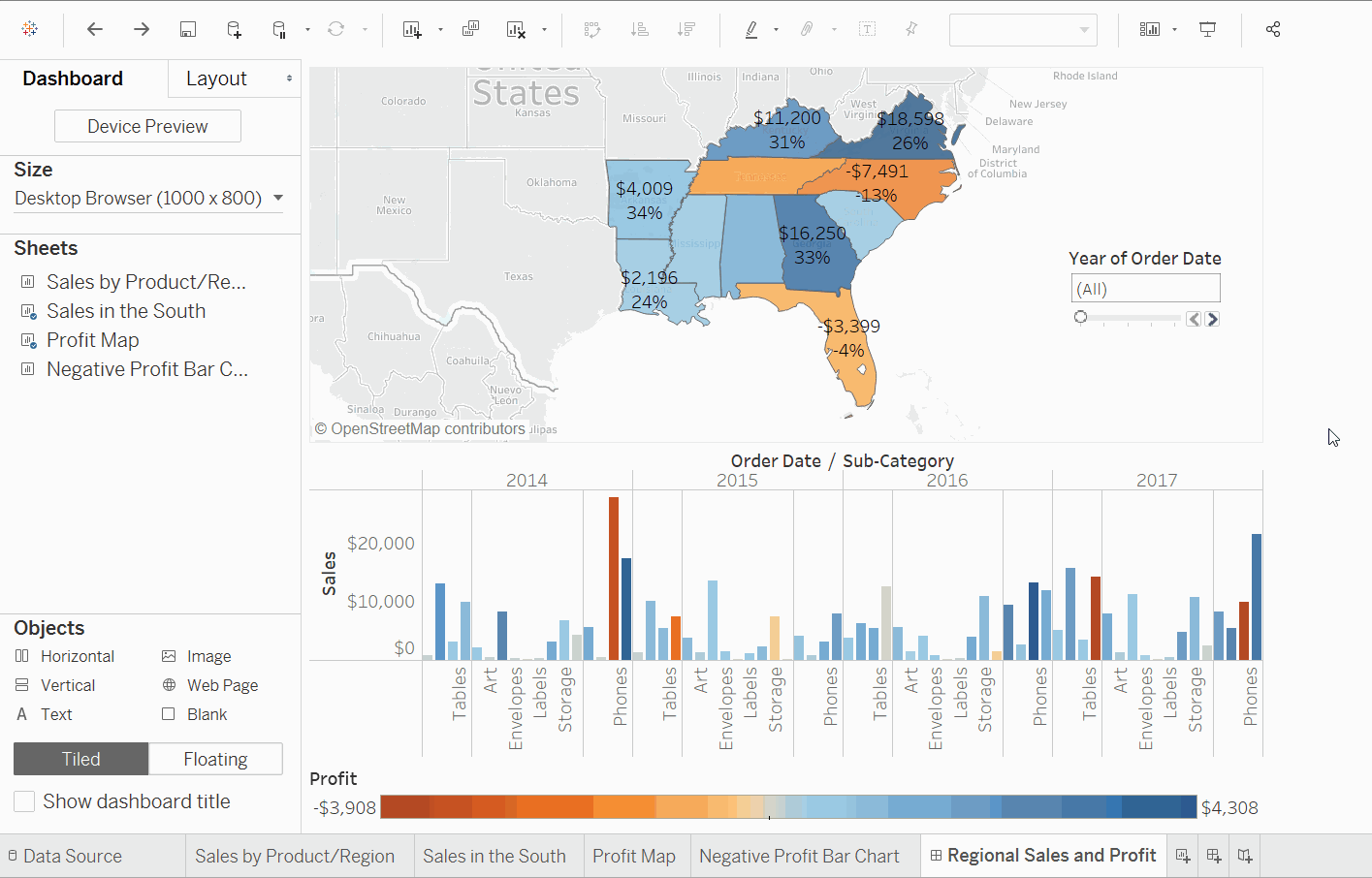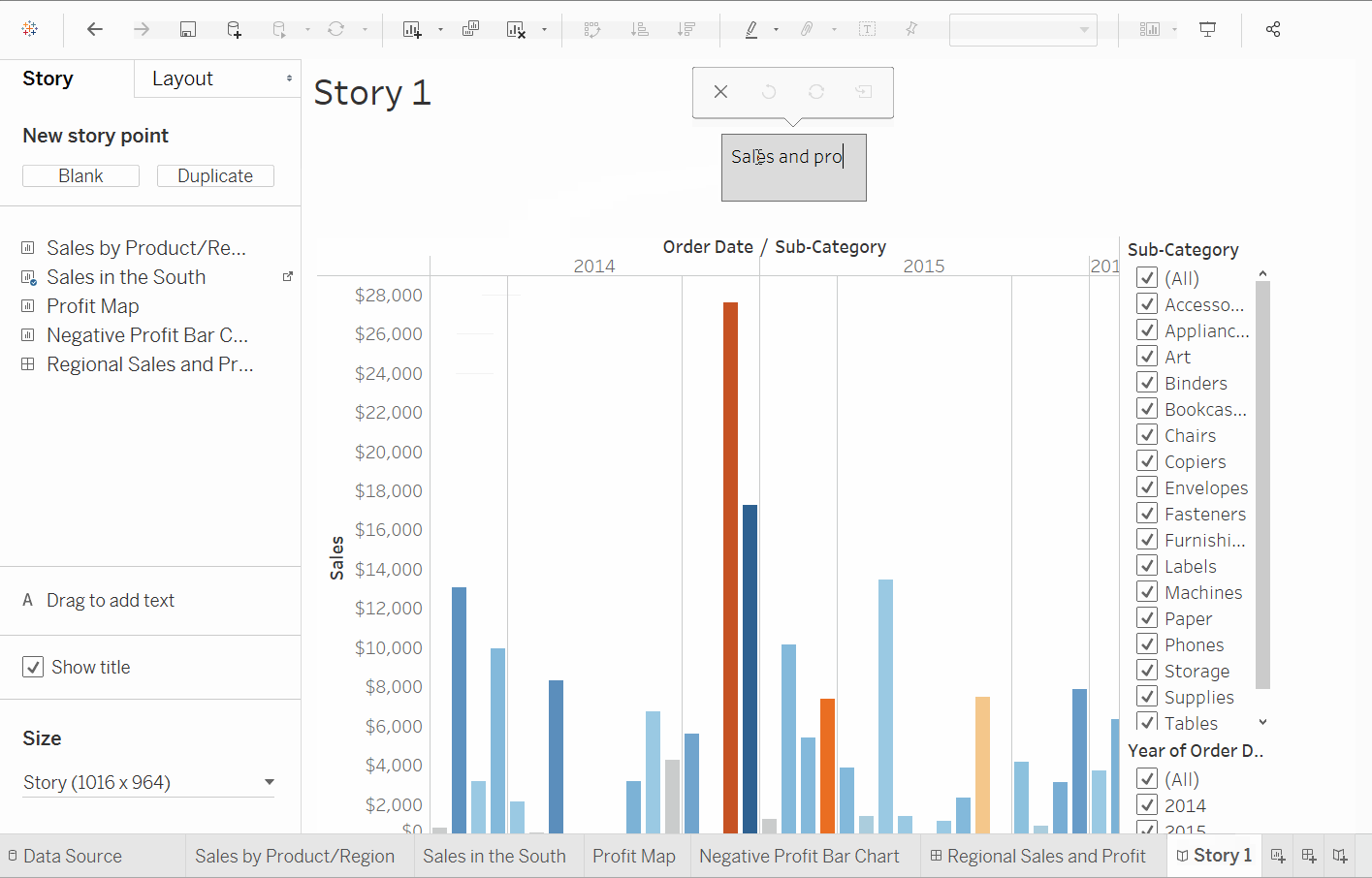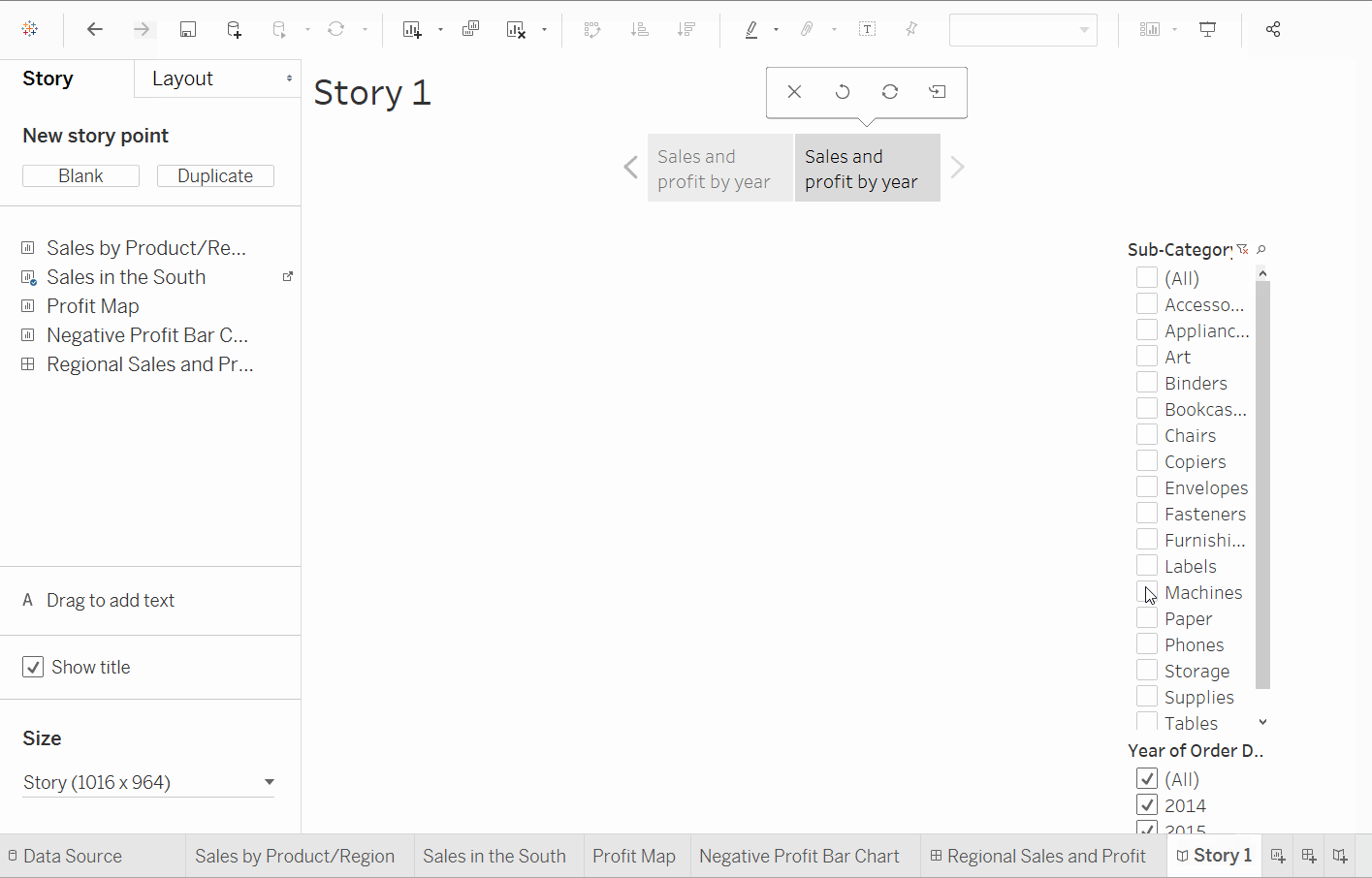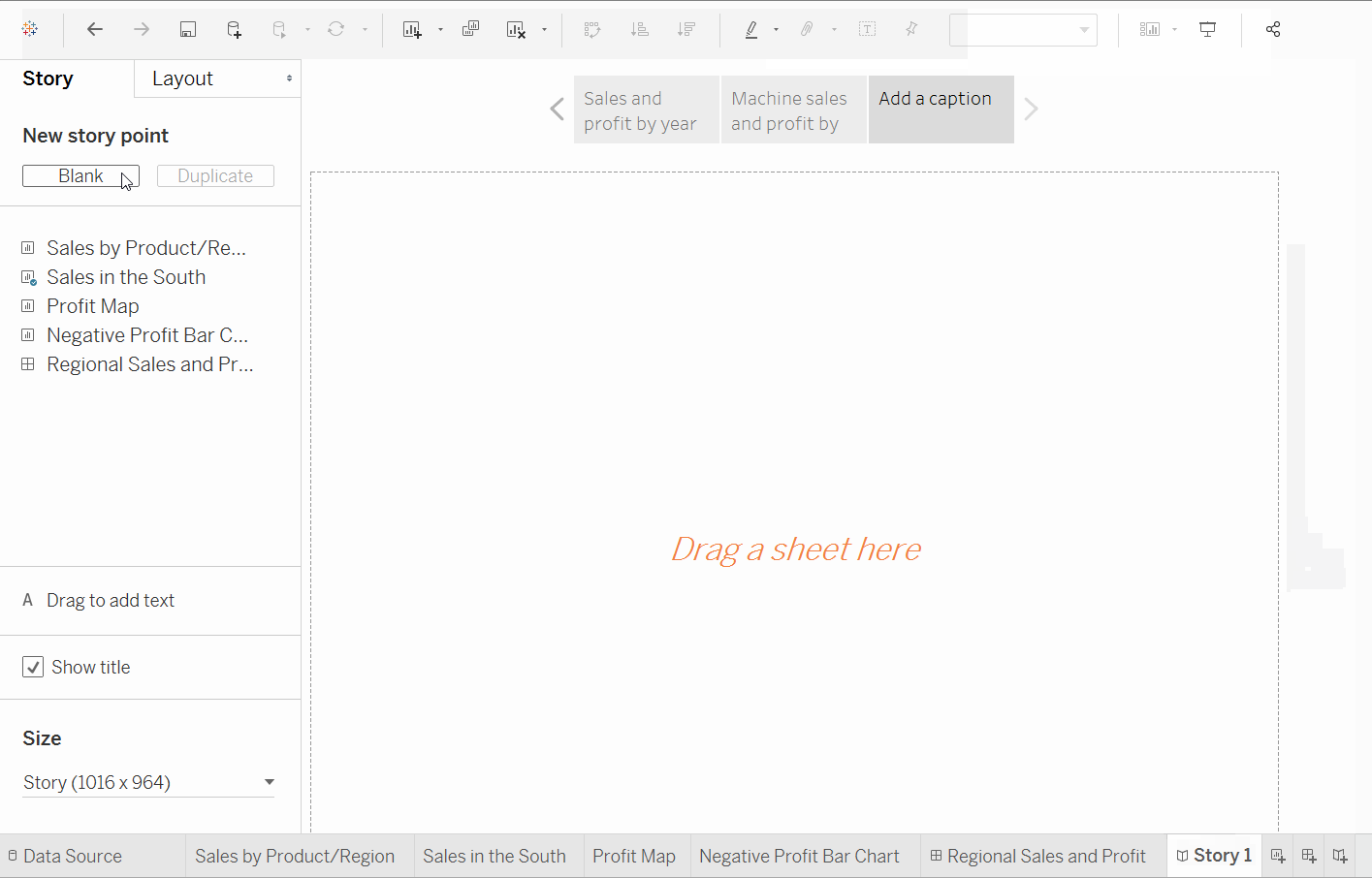
添加互動性
為了使儀表板更具互動性,例如查看哪些子類別在哪些州是盈利的,需要進行一些更改。
步驟
- 從
利潤地圖開始。點擊地圖後,右上角會出現一個用作過濾器的圖標。點擊它。如果我們選擇任何地圖,對應於該州的銷售將在南部銷售地圖中被突出顯示。 - 對於
訂單日期年份,點擊下拉選項,前往應用至工作表 > 選定工作表。會打開一個對話框。選擇全部選項,然後點擊確定。這個選項是幹嘛的?它將過濾器應用於所有具有相同數據源的工作表。 - 探索和實驗。在下面的視覺化中,我們可以過濾掉
南部銷售地圖,只查看在北卡羅來納州銷售的產品。我們可以輕鬆地探究每年的利潤。 - 將儀表板重新命名為
地區銷售與利潤。
動手實作
因此,在北卡羅來納州銷售機器並未給公司帶來任何利潤。
6. 說故事
儀表板是一項很酷的功能,但Tableau也提供了讓我們以展示模式呈現我們結果的故事形式,我們將在本節中討論這些故事。
建立故事
步驟
- 點擊
新建故事�按鈕。 - 從左側的故事窗格中,將之前創建的
南部銷售工作表拖放到視圖中。 - 編輯工作表上方灰色框中的文字。這是標題。將其命名為
按年銷售與利潤。 - 故事非常具體。在這裡,我們將講述在北卡羅來納州銷售機器的故事。在故事窗格中,點擊
複製來複製第一個標題,或者您可以創建一個新的。 - 在
子類別中,過濾器選擇僅機器。這有助於按年衡量機器的銷售和利潤。 - 將標題重命名為
按年機器銷售與利潤。
動手實作
得出結論
北卡羅來納州的機器導致利潤流失是顯而易見的。然而,這不能通過查看整體的利潤和銷售來證明。為此,我們需要區域利潤。
步驟
- 在故事窗格中,選擇
空白。將已創建的儀表板區域銷售和利潤拖放到畫布上。 - 標題為
南部表現不佳的項目。 - 選擇
複製以使用區域利潤儀表板創建另一個故事點。在條形圖上選擇北卡羅來納州,因為我們感興趣的是顯示更多關於它的資訊。 - 選擇所有年份。
- 為了清晰,添加一個標題,例如
北卡羅來納州的利潤:2013-2016。 - 選擇任何一年,例如2014年。添加一個標題,例如
北卡羅來納州2014年的利潤,然後點擊複製按鈕。對所有剩餘的年份重複相同的步驟。 - 點擊演示模式,讓
故事展開。
實際操作
現在我們對北卡羅來納州市場何時引入了哪些產品以及它們的表現有了了解。我們不但已經找出一種解決負利潤的方法,而且還成功地以數據支持了這一點。這就是Tableau中故事的優勢。
7. Tableau與R、Python和SQL的整合。
除了Tableau提供的各種視覺化優點外,它還具有驚人的開箱連接功能。Tableau可以輕鬆與Python和R等語言集成,甚至可以與SQL等DBMS進行集成。這為功能性提供了增加了優點,對於習慣於在Python或R中工作的數據科學家來說非常便利。他們可以直接將R和Python腳本導入Tableau,並利用其遠比這些語言更出色的視覺化功能。此外,Tableau的視覺化功能易於使用且非常直觀,從而為數據科學家節省了很多的時間。
在這一節中,我們將了解如何將Tableau與這些外部來源連接以及這些連接的優點。
Tableau和R
R是一種流行的統計語言,用於執行複雜的預測分析,如線性和非線性建模、統計測試、時間序列分析、分類、聚類等。(見表8.1和R)將Tableau與R結合使用具有以下優點:
- 通過讓用戶访问複雜的R庫,從而充分利用Tableau的統計能力,從數據中獲得更好的深入了解。
- Tableau enhanced data exploration options and the ability to connect to multiple sources come in handy for R users.
- 此外,它還使Tableau用戶能夠在没有實際掌握該語言的情況下,從R語言的实用性中受益。
如何在 Tableau 中與 R 整合?
R 函數和模型可以通過創建新的計算字段來在 Tableau 中使用,這些字段動態調用 R 引擎並將值傳遞給 R。這些結果然後返回到 Tableau,用於視覺化目的。
設定 Tableau Desktop 與 R
- 下載並安裝
Rserve。
您需要下載並安裝 Rserve 套件,以便 Tableau 連接並利用 R 腳本函數。在 R console 中,輸入以下命令:
install.packages(“Rserve”) library(Rserve) Rserve() / Rserve(args = ‘ — no-save’)
將 Tableau 連接到 R 伺服器
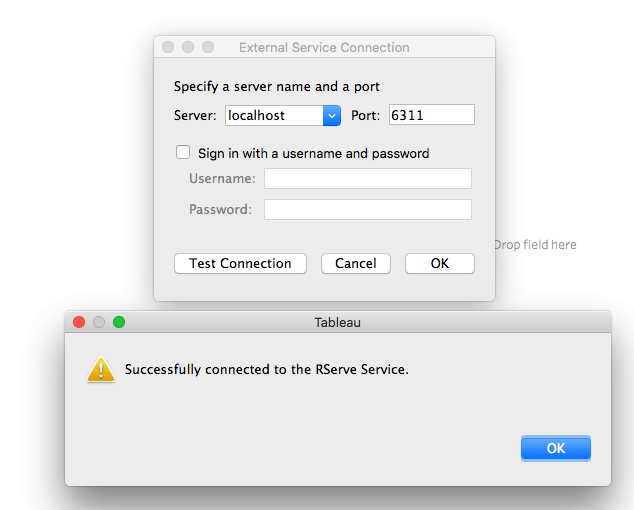
成功安裝 Rserve 後,打開 Tableau Desktop 並遵循以下提到的步驟。
-
前往
幫助 > 設定和偏好設定,然後選擇管理外部服務連接。
-
輸入伺服器名稱為“Localhost”(或“127.0.0.1”)以及端口“6311”。
-
點擊“測試連接”按鈕。您應該會看到成功的提示信息。點擊確定以關閉。

開始在Tableau中使用R腳本
在成功地完成上述步驟後,我們將能夠在Tableau Desktop中創建新的計算字段,這些字段使用SCRIPT_*函數來調用R功能。
讓我們開始工作,看看我們如何可以使用Tableau的功能與R。我們將使用內置的Sample Superstore數據集來計算利潤,既使用R腳本也使用Tableau的拖曳和放放手動功能。然後我們將比較這兩種方法的結果。
步驟
- 開啟Tableau工作簿並連接到sample superstore數據。
- 連接到Rserve。一旦Tableau Desktop連接到Rserve,它就可以通過計算字段調用R引擎。
-
我們現在將創建一個稱為Expected Profit的計算字段。
有四種可用與R配合使用的函數,它們都以script開頭。這些函數為:
- SCRIPT_REAL:返回實數作為結果
- SCRIPT_STR:返回字符串
- SCRIPT_INT : 返回整數
- SCRIPT_BOOL:返回布爾值
- 對於本例,我們將使用SCRIPT_REAL函數。我們將在Tableau中創建一個簡單的
線性回歸。
-
開啟計算字段並插入以下腳本。
SCRIPT_REAL("fit <- lm(.arg1 ~ .arg2 + .arg3 + .arg4) fit$fitted ", SUM([Profit]), AVG([Sales]), AVG([Quantity]), AVG([Discount]))上面的腳本與R中的線性迴歸模型有關。該模型將有一個依變量(arg1)和三個自變量(arg2, arg3, arg4)。這些參數只是占位符,當腳本返回給R時,這些參數將被它們對應的表單列替換。5. 輸入對應於每個變量的人才表字段。這裡的依變量是利潤,所以我們將
SUM(Profit)放在第一位,因為那與參數1對應。同樣地,我們將使用平均單價、平均訂單數量和平均折扣分別對應其他三個參數。 -
這些輸入現在都會被拉入模型以確定预期的利润水平。我們現在已經準備好在Tableau視覺化中使用此計算。將類別拖動到行上,然後將
Profit拖動到列上。現在將預估利潤拖動到列上。 -
我們現在可以分析模型,看看在R中計算的
預期利潤與實際利潤的對比。我們可以進一步將客戶段拉到色彩上進行分析,現在我們已經創建了一個堆疊條形圖,並且還可以利用有序日期來按照年份或季度來劃分數據。
親自操作
有人可能會想,上述所有的計算都可以在不使用R的情況下在Tableau中完成。那麼,為什麼我們要經歷下載和配置Tableau中的Rserve並撰寫腳本呢?R是一種強大的語言,因為它擁有預測的能力,利用廣泛使用的庫,這些庫包含了易於使用的知名演算法。想像一下,如果我們能在Tableau中通過調用一個簡單的R腳本來為我們的業務進行預測,並將其融入到Tableau的可視化中,將是多麼的美好。
Tableau與Python
Python是一種廣泛使用的通用程式設計語言。Python提供了大量的函式庫來進行統計分析、預測建模或機器學習。將Tableau與Python連接起來是進行預測分析的最佳方法之一。Tabpy是一個用於此目的的套件。為了讓Tableau能夠利用Python的力量,它可以連接到TabPy伺服器上即時執行Python程式碼,並以視覺化形式呈現結果。
Tableau如何與Python整合?
當我們在Tableau中使用TabPy時,我們可以在Python中定義計算字段,從而在我們的視覺化中利用大量機器學習函式庫的力量。
設定Tableau Desktop與Python
下載並安裝Tabpy。
在Tableau工作簿內運行Python程式碼需要一個Python伺服器來執行它。TabPy框架就是完成這項工作。從以下連結在Github上下載TabPy。或者,您可以按照以下步驟操作:
conda install -c anaconda tabpy-server
然後cd到包含下載的tabpy伺服器的目錄並運行。
python setp.py
將Tableau與TabPy連接
下一步是將Tableau與TabPy連接起來。這可以通過進入幫助 > 設定和效能 > 管理外部服務連接:來完成
測試連接。如果一切順利,您應該會看到“成功連接”的提示。
開始在Tableau中使用Python腳本
Python 在 Tableau 中的整合是一個非常實用的功能。以情感分析問題為例,這是機器學習社區中的一個常見問題,並且可以通過各種機器學習算法來實現。然而,通過結合 Tableau 和 Python,同樣可以在幾行程式碼中達成。然後,結果可以在 Tableau 中視覺化,以進一步獲得洞察。讓我們通過一個例子來看看這一點(利用 TabPy 在 Tableau 中發揮 Python 的力量)
使用 Tabpy 進行情感分析
我們將使用手機評論數據集,您可以從這裡下載。
步驟:
- 將數據集導入 Tableau Desktop
- 連接到 Tabpy。一旦 Tableau Desktop 連接到
Tabpy,它就可以通過計算字段調用 Python 引擎。 -
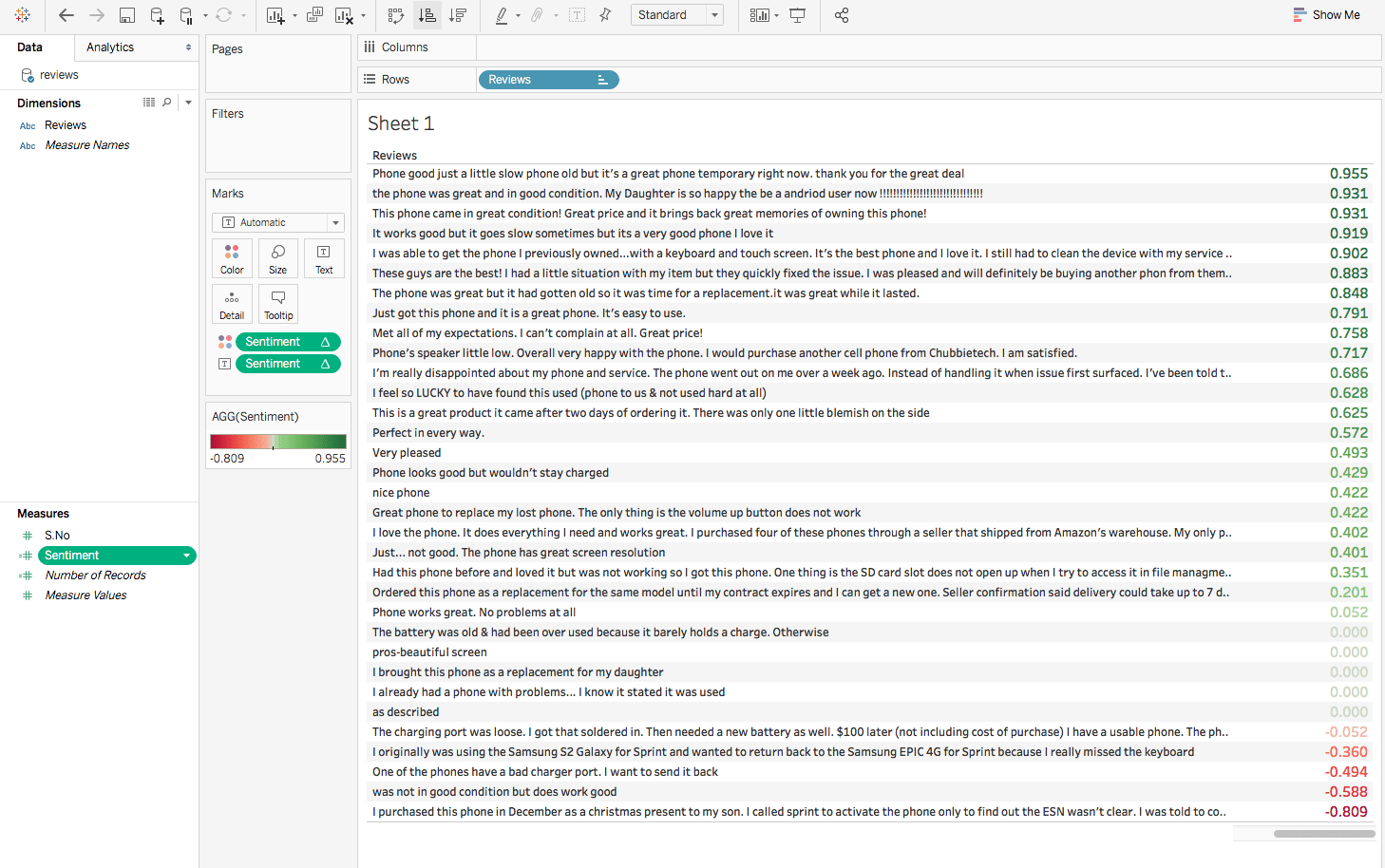
我們現在將創建一個計算字段,稱為
情感,如下所示:SCRIPT_REAL("from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer vs = [] analyzer = SentimentIntensityAnalyzer() for i in range(0,len(_arg1)): a = analyzer.polarity_scores(_arg1[i])['compound'] vs.append(a) return vs",ATTR([Reviews]))`我們在此使用
VADER情感分析工具。它是一個基於詞典和規則的情感分析工具,专门校准於社交媒體中表達的情感。要使用此工具,您需要先安裝它。請在他們的GitHub頁面上了解更多。 -
現在,將
評論拖到行上,將情感拖到文字和顏色標記卡上,看著奇蹟發生。我們毫不費力地完成了評論的情感分析。此外,視覺化結果也變得非常容易。正面評論按 green 逐漸加深,而負面評論則為紅色。
上述範例清楚顯示了Tableau與Python整合所帶來的強大功能。藉由擁有情感分數,我們可以利用它深入挖掘細節。例如,作為一個企業主,我可以篩選出負面評論並思考其原因。我也可以篩選出正面評論以瞭解哪些產品讓消費者感到滿意。
Tableau與SQL Server
在我們的Microsoft SQL Server數據中隱藏著價值,這些價值被埋藏在標準報告和複雜的商業智能工具之下。Tableau通過讓任何人都能對SQL Server數據進行高級視覺分析,從而在各處提供洞察力。我們可以將Tableau實時連接到SQL Server以進行調優的、平台特定的查詢,或者直接將數據帶入Tableau的分析引擎以減輕數據庫的負擔。
Tableau提供了一個優化的、實時的SQL Server連接器,使我們能夠在直接處理數據的同時創建圖表、報告和儀表板。隨著我們深入分析,Tableau會識別SQL Server中使用的任何模式,因此我們不必操作數據。
讓我們通過一個例子來演示如何將SQL Server數據庫連接到Tableau Desktop,然後使用它來創建可視化。
步驟:
- 登錄SQL Server
- 打開Tableau Desktop並在伺服器下連接到MS SQL。
- 在彈出的對話方塊中貼上伺服器名稱,然後按確定。這將將Tableau連接到SQL Server。選擇所需的數據庫。在這個示例中,我們選擇salesDB。我們然後可以从列表中選擇TABLE,例如, Sales Log。該表被導入Tableau環境中。現在我們可以選擇提取全部數據或其部分到新的工作表。我們甚至可以指定要提取的行數。
- 在新型工作表中,我們已有從MS SQL導入的數據,從這裡我們可以像處理任何其他Tableau工作表一樣工作。
手把手教程:
這就是我們如何輕鬆將SQL Server連接到Tableau並直接提取數據到其中。Tableau讓用戶可以輕點按鈕切換連接以對較大數據集應用記憶體查询。
8. 保存工作
Tableau 桌面
要在本地保存Tableau工作簿,請選擇文件 > 保存。在另存為對話方塊中指定工作簿文件名稱。Tableau默認為文件加上.twb擴展名。
Tableau 公開
使用Tableau 公開,所有的視圖和數據都是公開的,任何人都可以在互聯網上存取。選擇伺服器 > Tableau 公開 > 保存至Tableau 公開,並輸入凭证。
Tableau 伺服器
在數據為機密且故事需要與整個團隊分享的情況下,Tableau Server 變得非常方便。要在 Tableau Server 發布故事,請選擇選擇服務器 > 發布工作簿或在工作栏上點擊分享。但請確保先創建一個帳戶。
結論
这就是我们在 Tableau 中创建良好可视化的所有步骤,尽管在这里我们可能在每个阶段都需要進行更多的修改。因此,通過實驗和練習,Tableau 會變得更加熟悉,並釋放出驚人的功能來幫助我們分析和解讀數據。如有疑問或問題,請在下方留评论区,祝您可视化愉快。
Source:
https://www.datacamp.com/tutorial/data-visualisation-tableau