













1. Tableau 简介
概览
Tableau Software는 华盛顿州西雅图에 based하는 소프트웨어 회사로서 ビジネス 지능을 초점으로 인터랙티브 数据分析제품을 생산합니다. Tableau는 1997년부터 2002년까지 스탠퍼드 대학교 计算机科学系에서 設立되었습니다. (Wikipedia)
Tableau가 제시하는 주요 제품은 다음과 같습니다:

Tableau Desktop, Tableau Public, Tableau Online이며, 모두 Data Visual Creation을 제공합니다. 작업 유형에 따라 선택이 달라집니다。
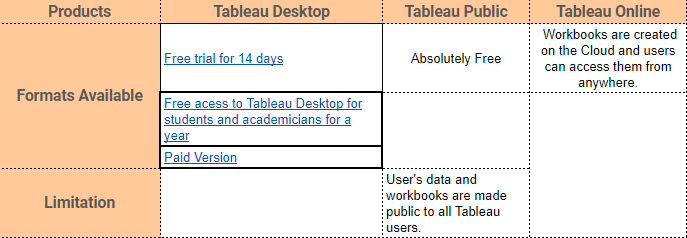
이 자습서에서는 Tableau Desktop으로 작업합니다. 참조할 수 있는 원본 링크는 here.
설치
선택한 제품에 따라 소프트웨어를 컴퓨터에 다운로드합니다. 사용권 계약에 동의한 후 Tableau 아이콘을 클릭하여 설치를 확인할 수 있습니다. 다음 화면이 나타나면 설치가 완료된 것입니다.
2. 시작하기
이 섹션에서는 Tableau의 인터페이스에 익숙해지기 위한 몇 가지 기본 작업을 배웁니다.
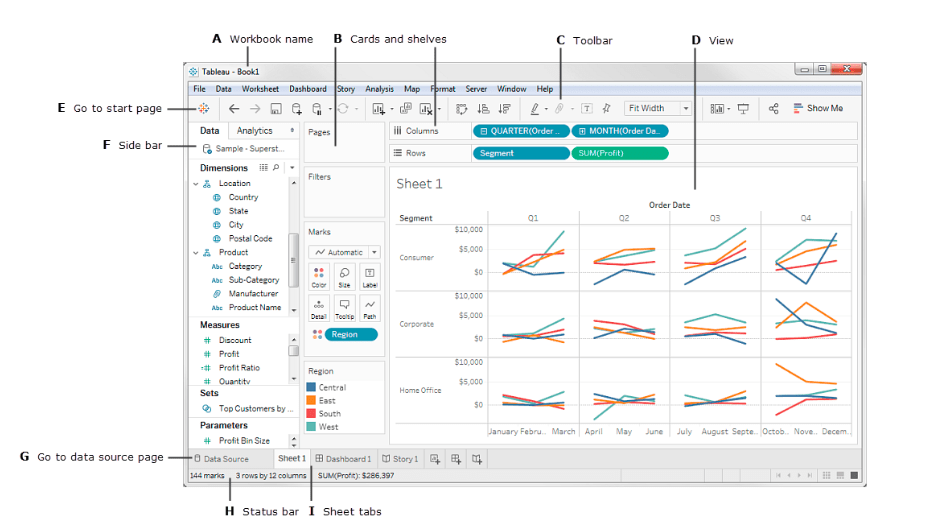
Tableau 작업 영역
Tableau 작업 영역은 워크시트, 메뉴 모음, 툴바, 마크 카드, 선반 및 향후 섹션에서 학습할 기타 많은 요소의 집합체입니다. 시트는 워크시트, 대시보드 또는 스토리가 될 수 있습니다. 아래 이미지는 워크스페이스의 주요 구성 요소를 강조하고 있습니다. 하지만 실제 데이터로 작업하면 더 친숙해질 것입니다.
데이터 원본에 연결하기
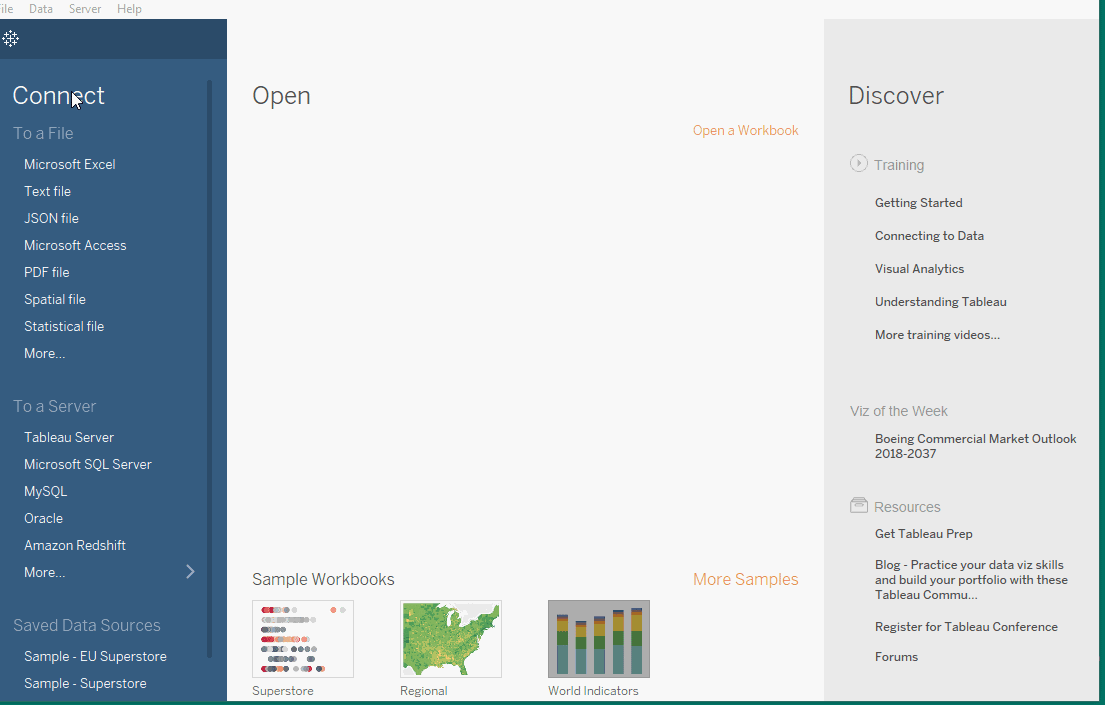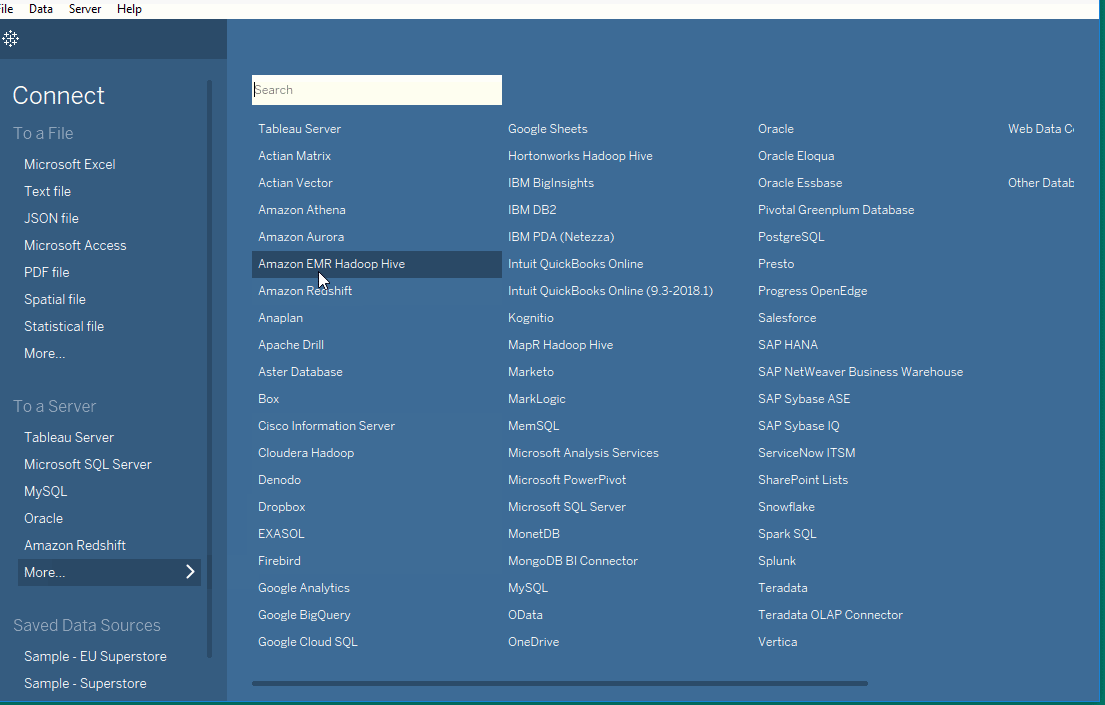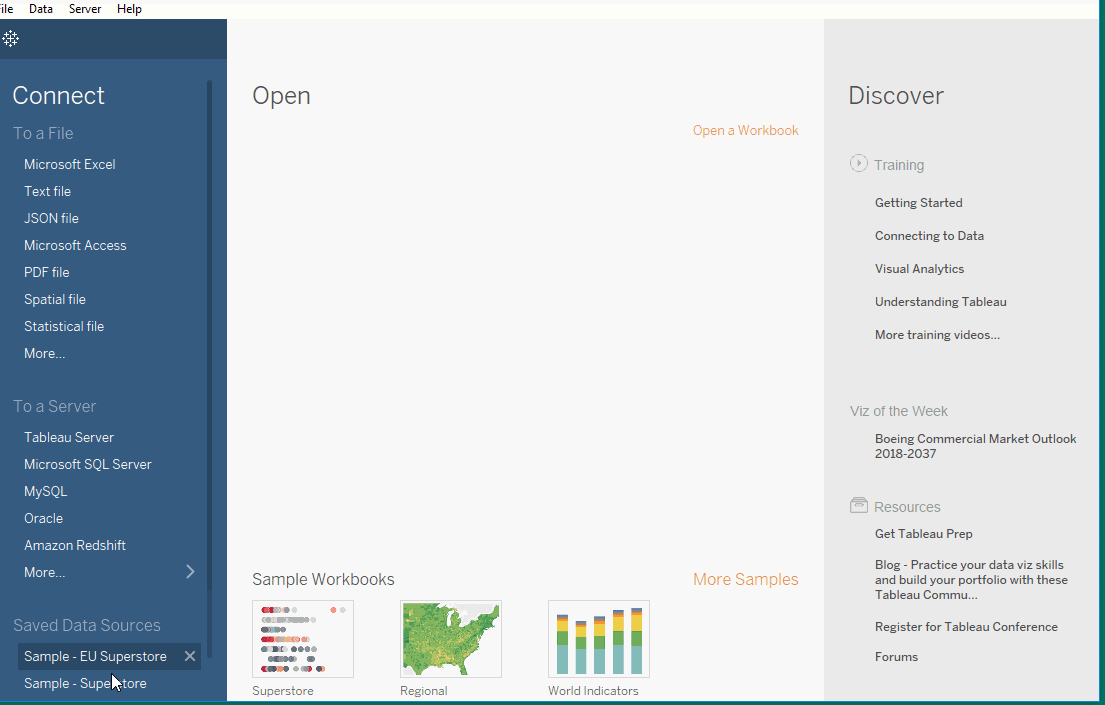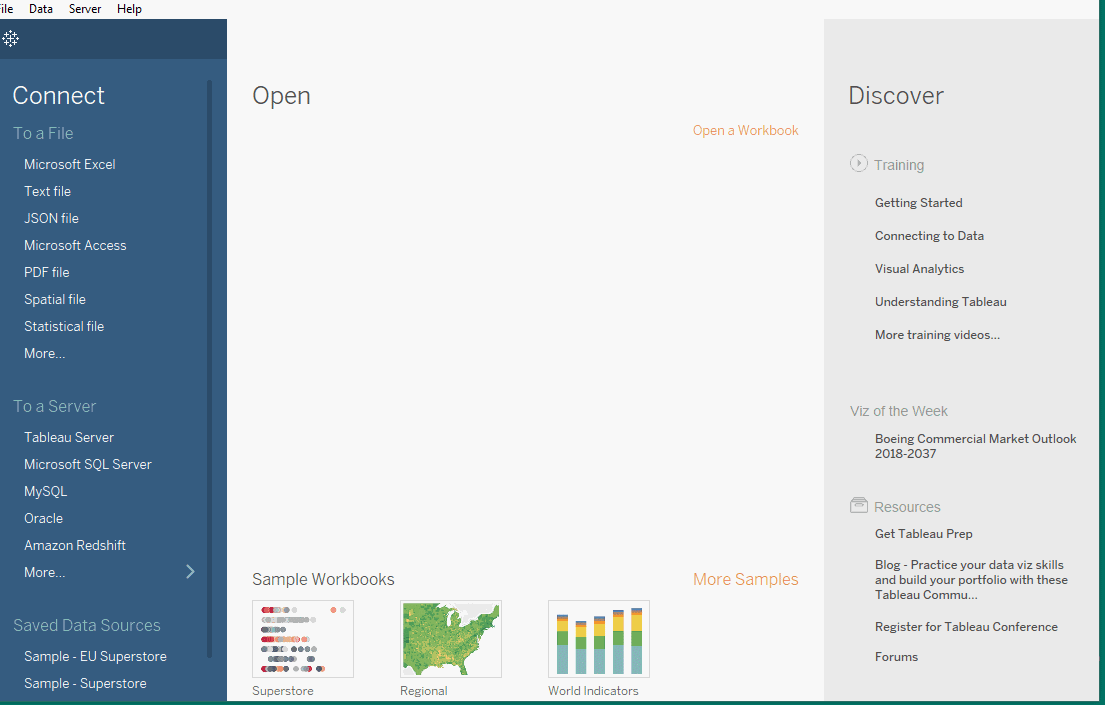
시작하려면 Tableau 작업을 위해 Tableau를 데이터 소스에 연결해야 합니다. Tableau는 많은 데이터 소스와 호환됩니다. Tableau에서 지원하는 데이터 소스는 시작 화면의 왼쪽에 나타납니다. 일반적으로 사용되는 데이터 소스로는 엑셀, 텍스트 파일, 관계형 데이터베이스 또는 서버에 있는 데이터가 있습니다. Google Analytics, Amazon Redshift 등과 같은 클라우드 데이터베이스 소스에도 연결할 수 있습니다.
Tableau Desktop의 시작 화면에는 연결할 수 있는 데이터 소스가 표시됩니다. 이는 Tableau의 버전에 따라 다르며, 유료 버전은 더 많은 가능성을 제공합니다. 화면의 왼쪽에는 사용 가능한 소스를 강조 표시하는 Connect 창이 있습니다. 파일 유형이 먼저 나열되고, 그 다음에 일반적인 서버 유형 또는 최근에 연결된 서버가 나열됩니다. Open 탭에서 이전에 만든 워크북을 열 수 있습니다. Tableau Desktop은 Sample Workbooks 아래에 몇 가지 샘플 워크북도 제공합니다.
Hands On
Sample-Superstore 데이터 세트에 연결하기
Superstore 데이터셋은 Tableau에 사전 설치되어 있는 데이터셋입니다. 그러나 우리는 여기에서 파일을 다운로드하여 Excel 데이터 소스에 연결하는 방법을 알아보겠습니다. 데이터는 슈퍼스토어의 정보입니다. 제품, 판매, 이익 등의 정보를 포함합니다. 데이터分析师으로서 우리의 목표는 데이터를 분석하여 이 가상 기업의 중요한 개선 영역을 발견하는 것입니다.
알고리즘
-
컴퓨터에서 Tableau 작업 공간으로 데이터를 가져옵니다.
-
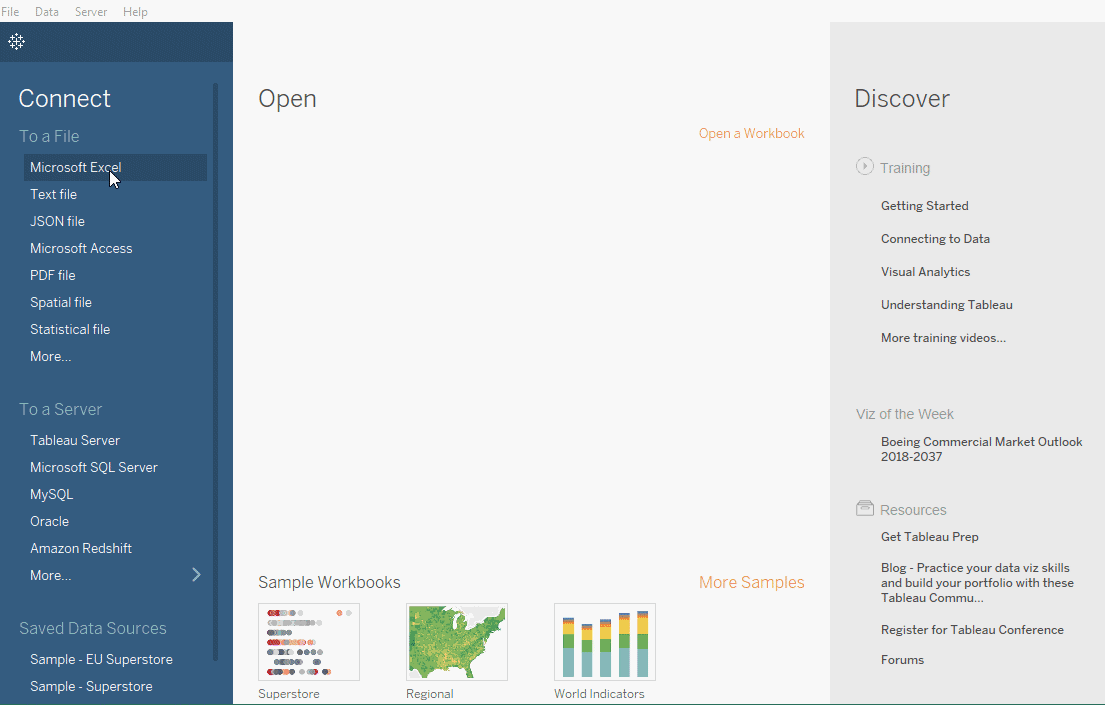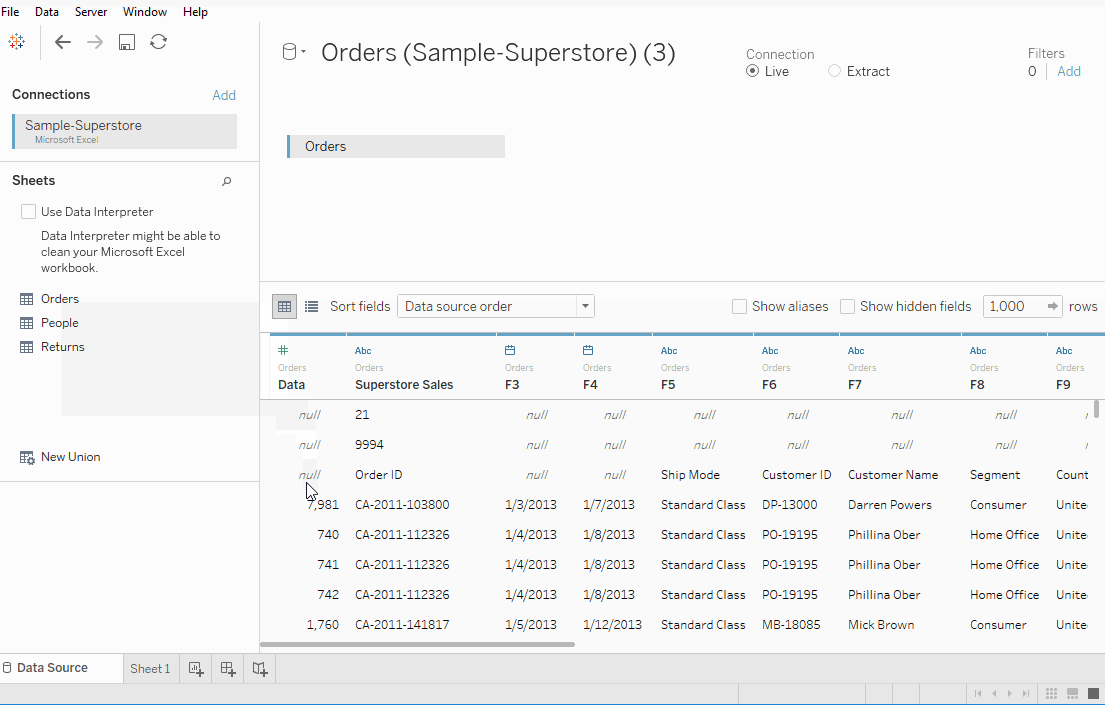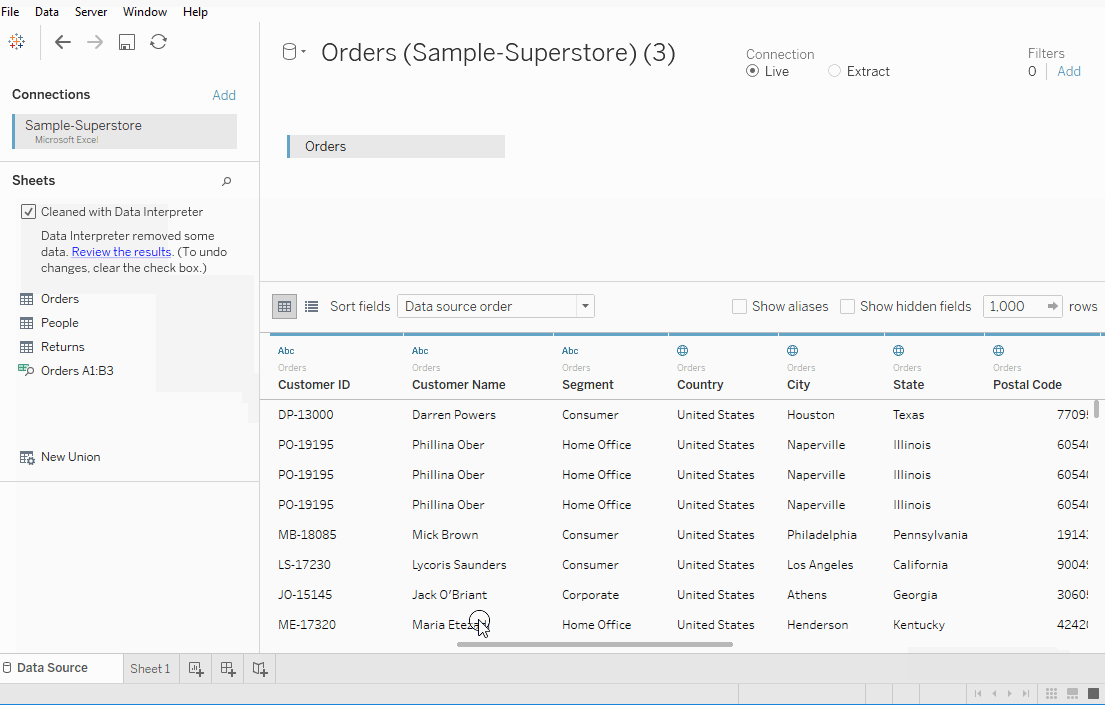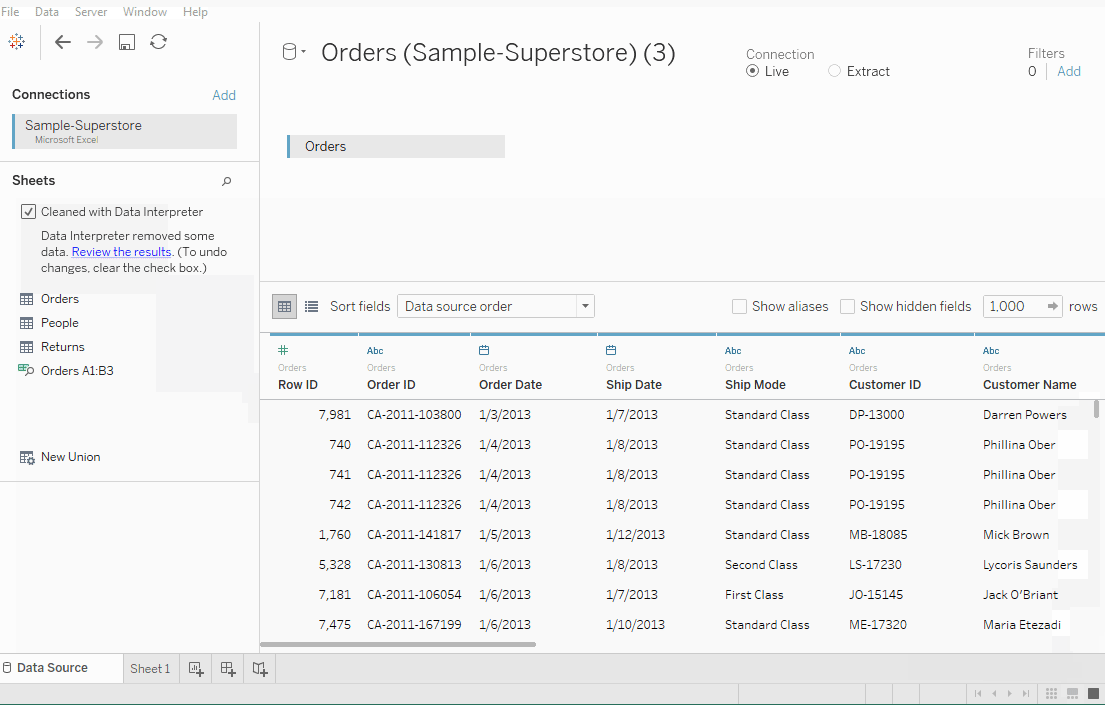
Sheets 탭 아래에는 Orders, People, Returns로 명명된 세 개의 시트가 보입니다. 그러나 우리는 오직 Orders 데이터에만 집중합니다. Orders 시트를 더블 클릭하면 스프레드시트처럼 열립니다.
-
첫 세 줄의 데이터가 조금 다르고 원하는 형식이 아닌 것을 관찰합니다. Sheets 탭 아래에 있는 데이터 해석기를 사용하면 좋은 형식의 시트를 얻을 수 있습니다.
Hands On
뷰 생성
시작하기 전에 간단한 그래프를 생성하겠습니다. 이 섹션에서는 我们的 데이터에 대해 이해하고 데이터에 대한 질문을 시작하여 洞見을 얻을 것입니다. 이 섹션에서 我们에게 首次 Meeting할 수 있는 중요한 용어가 있습니다.
Dimension
Measures
Aggregation
Dimensions는 이름이나 날짜와 같은 정성적 데이터로, 的气质적 또는 分类적 정보가 포함된 데이터를 제공합니다. 기본적으로 Tableau는 이러한 데이터를 제공하는 필드를 제공하는 제공자로 지정합니다. 예를 들어 텍스트 또는 날짜 값을 포함하는 필드는 기본적으로 维形(Dimension)으로 지정됩니다. 이러한 필드는 대량의 데이터에 대한 열 헤더로 나타나고, 예를 들어 고객 이름 또는 주문 날짜와 같습니다. 또한 보여지는 시각에서 결정적인 해상도를 정의합니다.
Measures는 질량적인 숫자 데이터로, 이러한 데이터를 포함하는 필드는 기본적으로 Tableau는 제공하는 제공자로 지정합니다. 예를 들어 매출 거래 또는 이익을 제공합니다. 이러한 데이터를 제공하는 필드가 제공되면 주어진 维形(Dimension)에 따라 합계화를 적용할 수 있습니다. 예를 들어 지역(维形 Dimension)에 따라 총 매출(Measure)을 구할 수 있습니다.
집계는 銷售의 합계나 전체 이익과 같은 高层次로 이동되는 行 级 데이터를 말합니다.
Tableau는 자동적으로 計画(Measures)과 维度(Dimensions)의 필드를 정렬합니다. 그러나 이상적인 경우는 수동으로 변경할 수 있습니다.
Passos
-
작업 시트로 가기. 테이블어 작업 공간의 하 leFT 아래의
Sheet 1탭을 클릭하세요.
-
작업 시트에 있으면, 데이터 대면의
DimensionsからOrder Date를 열 서랍에 끌어다가 放下하세요.Order Date를 열 서랍에 끌어 放下하면, 모든 주문의 년도별 열이 datasets에 생성됩니다. 각 열 下面에 ‘Abc’ 지표가 보입니다. 이것은 텍스트나 숫자 또는 텍스트 데이터가 여기로 끌어다 放下할 수 있음을 의미합니다. 그러나 우리가Sales를 여기로 끌었을 때, 이 cross-tab이 생성되고, 각 년도의 총 銷售을 보여줍니다. -
측정탭에서판매필드를 행 보관함으로 드래그하세요.
Tableau는 판매를 합계로 묶인 차트를 생성합니다. 각 해에 대한 주문일자별 집계된 판매总额이 표시됩니다. Tableau는 시간 필드를 포함하는 뷰에 라인 차트를 항상 채웁니다. 이 예제에서는 주문일자입니다.
핸즈온
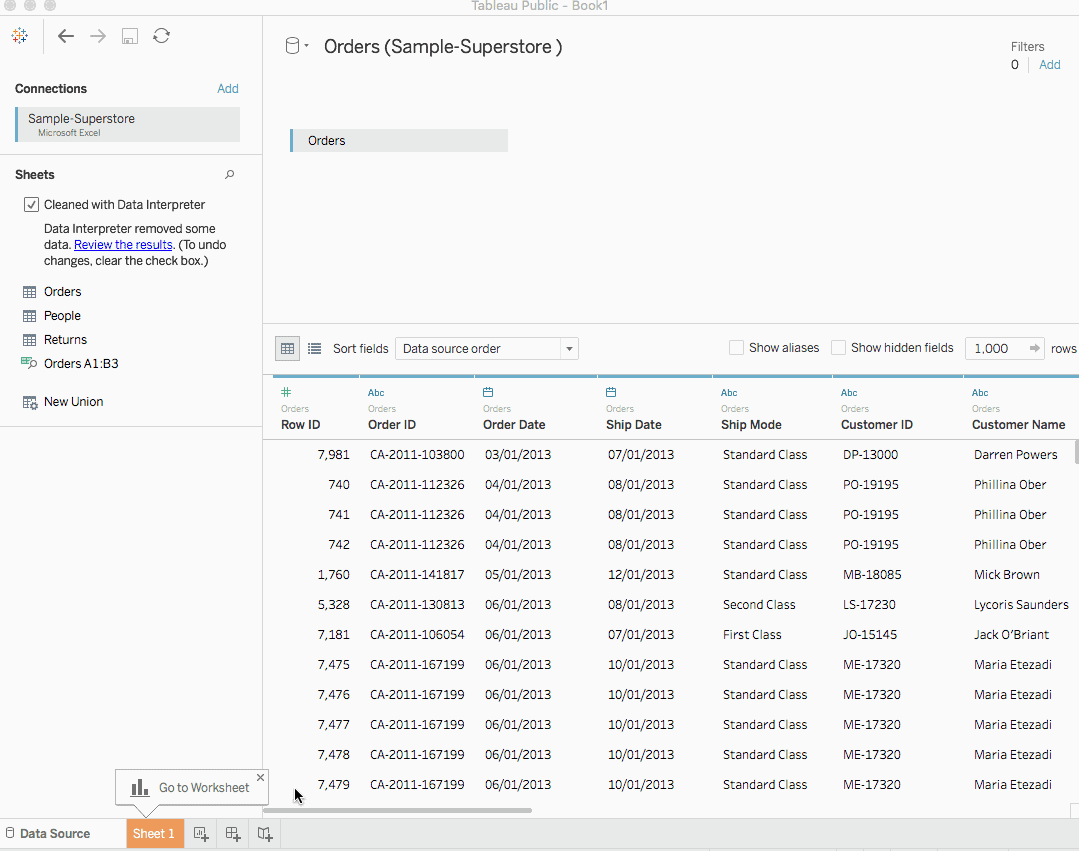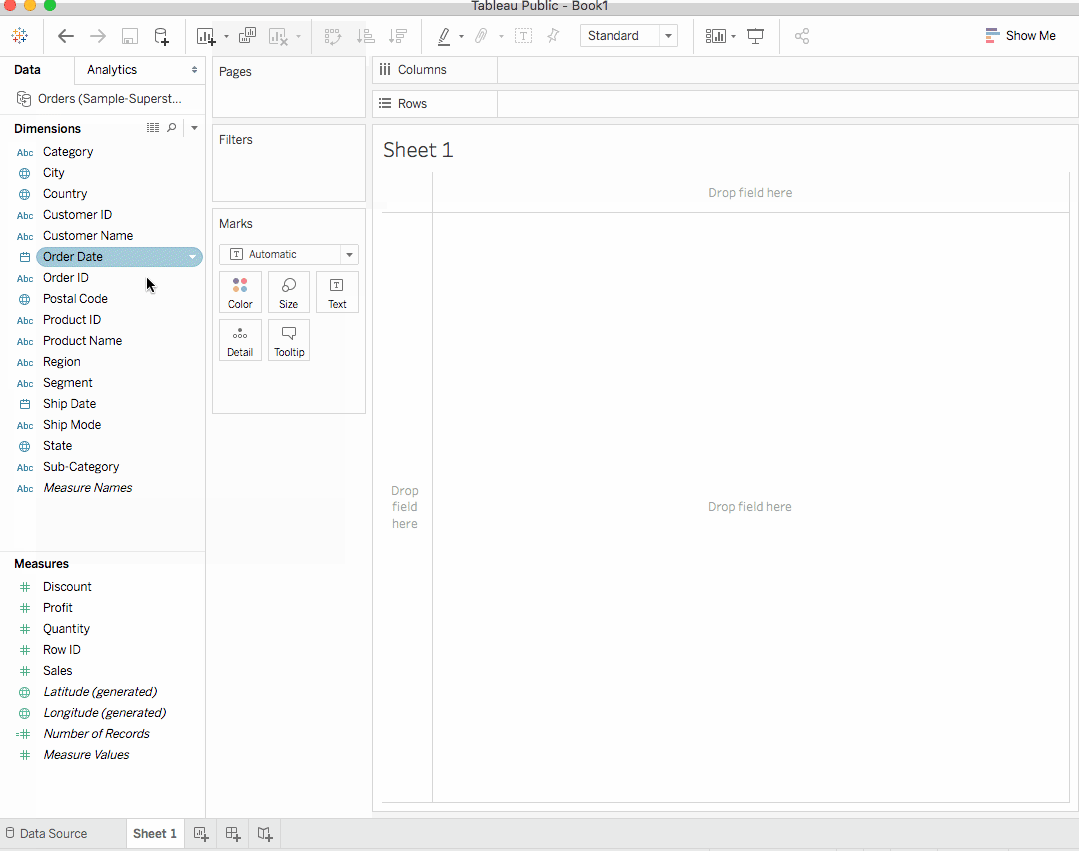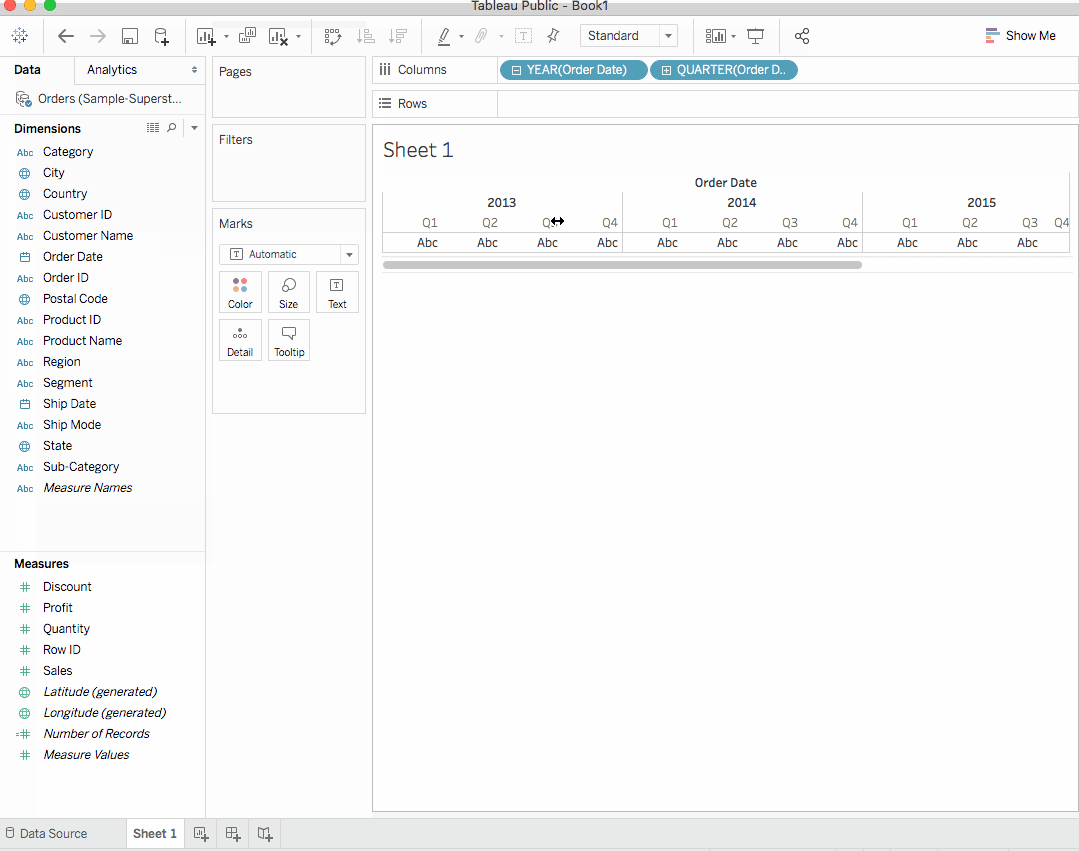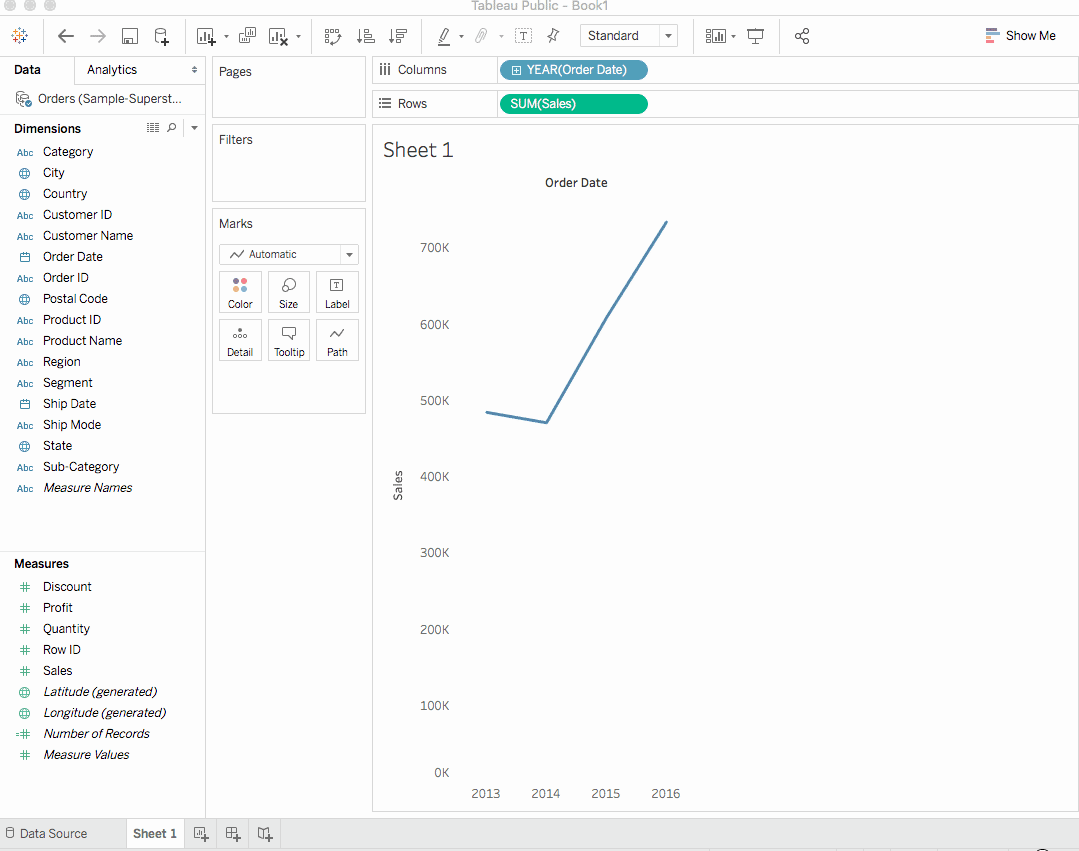
위의 라인 차트는 어떤 의미를传达하고 있을까요? 보통, 판매가 시간이 지나면서 더욱 기대되고 증가하는 경향을 보입니다. 이는 값진 인사이트입니다만, 증가하는 판매에 기여하는 제품에 대해서는 거의 얘기하지 않습니다. 더 많은 인사이트를 얻기 위해 좀 더 깊이 들어가봅시다.
뷰求精
제품이 얼마나 많은 판매를 돕는지에 대한 인사이트를 더 많이 발견하고자 더 깊이 들어가봅시다. 제품 카테고리를 추가하여 판매总额을 다른 방식으로 볼 수 있도록 시작합시다.
단계
-
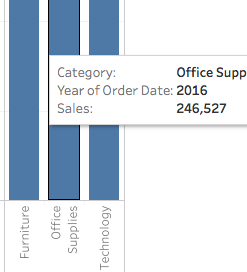
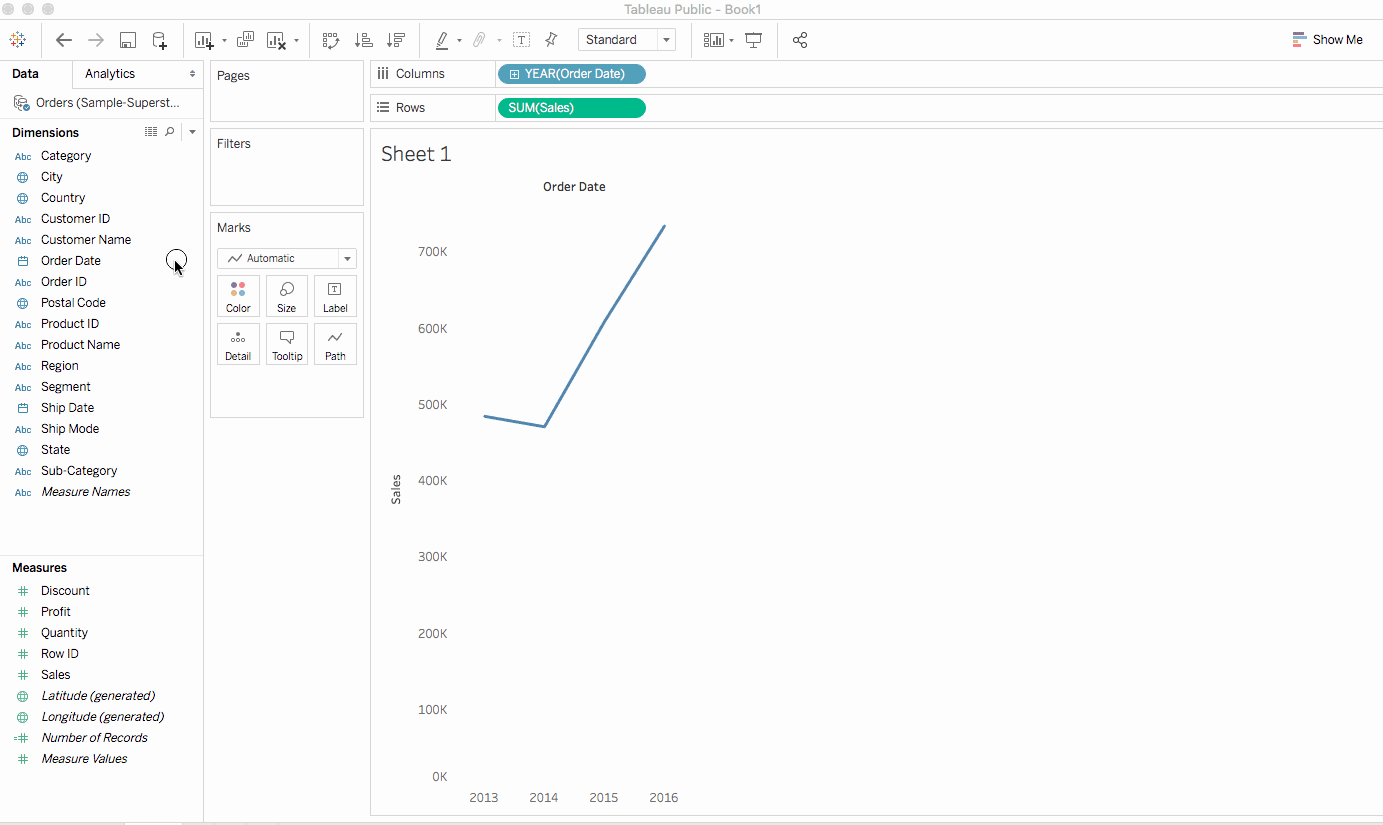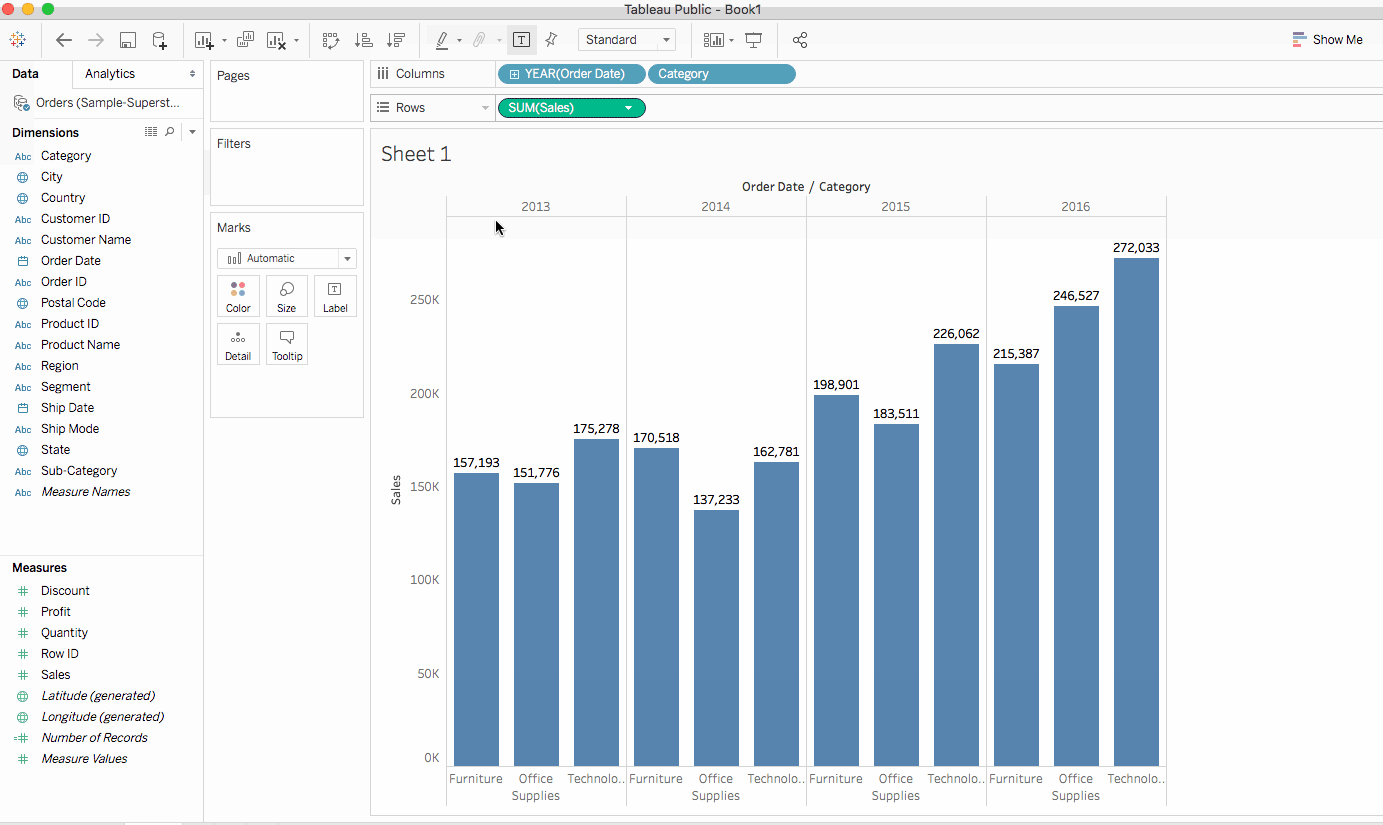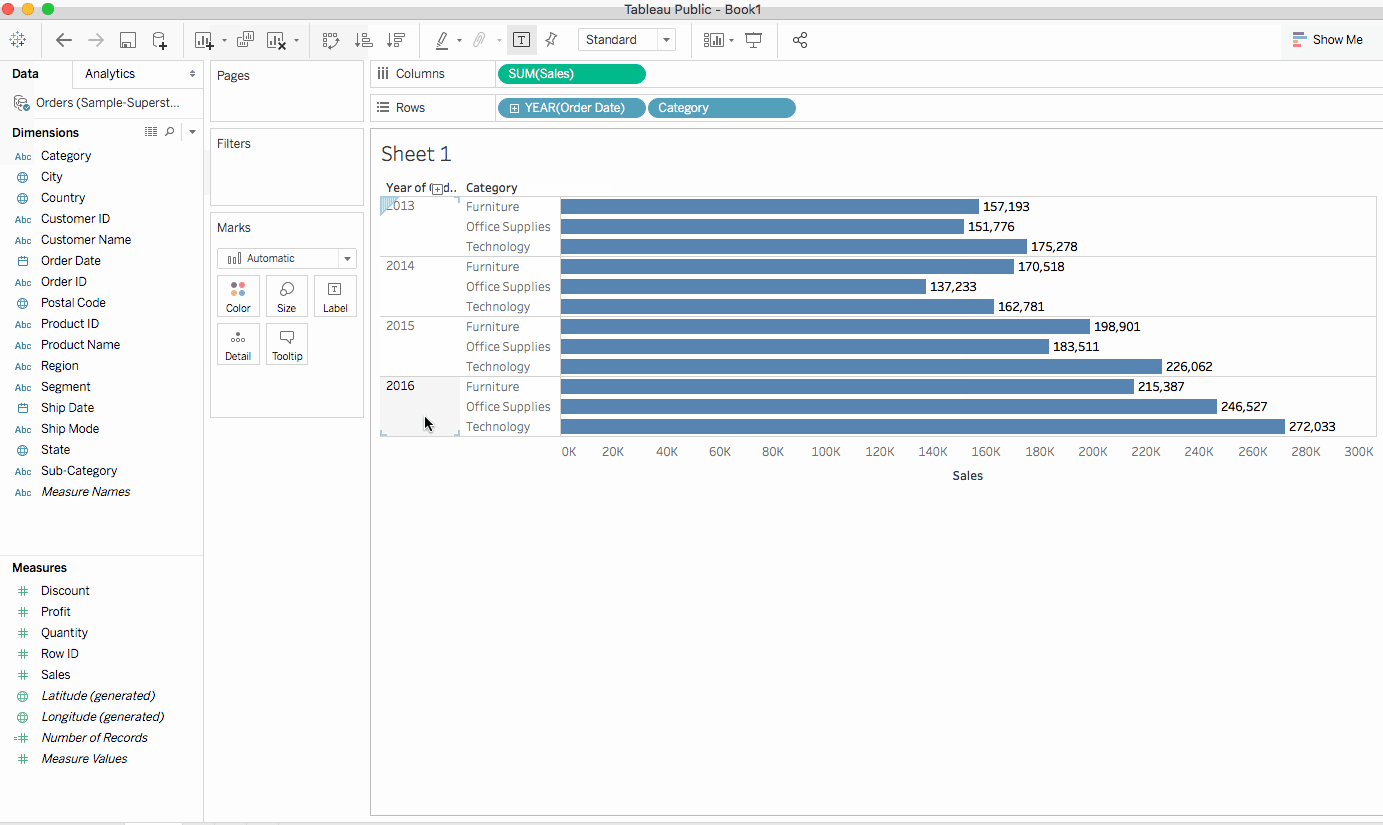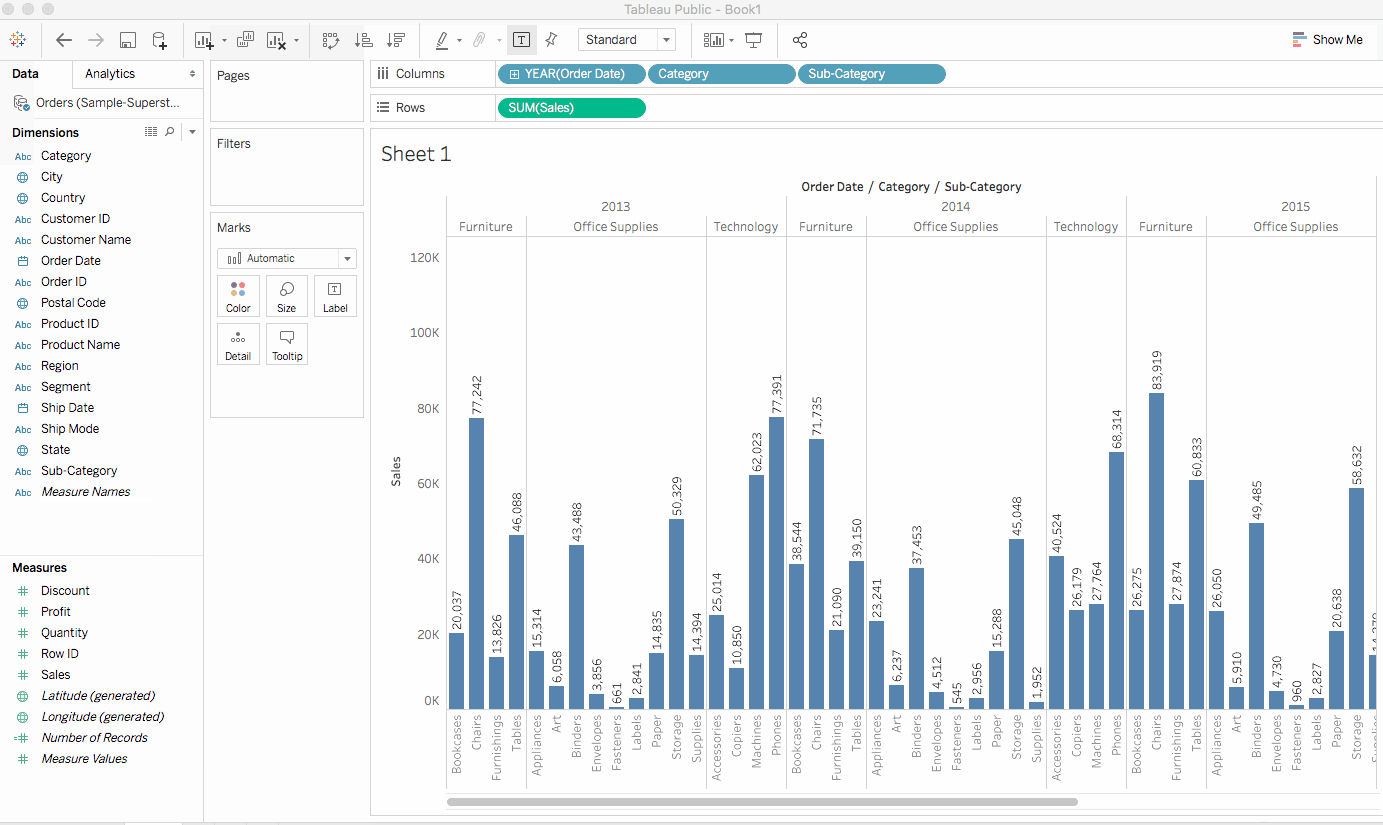
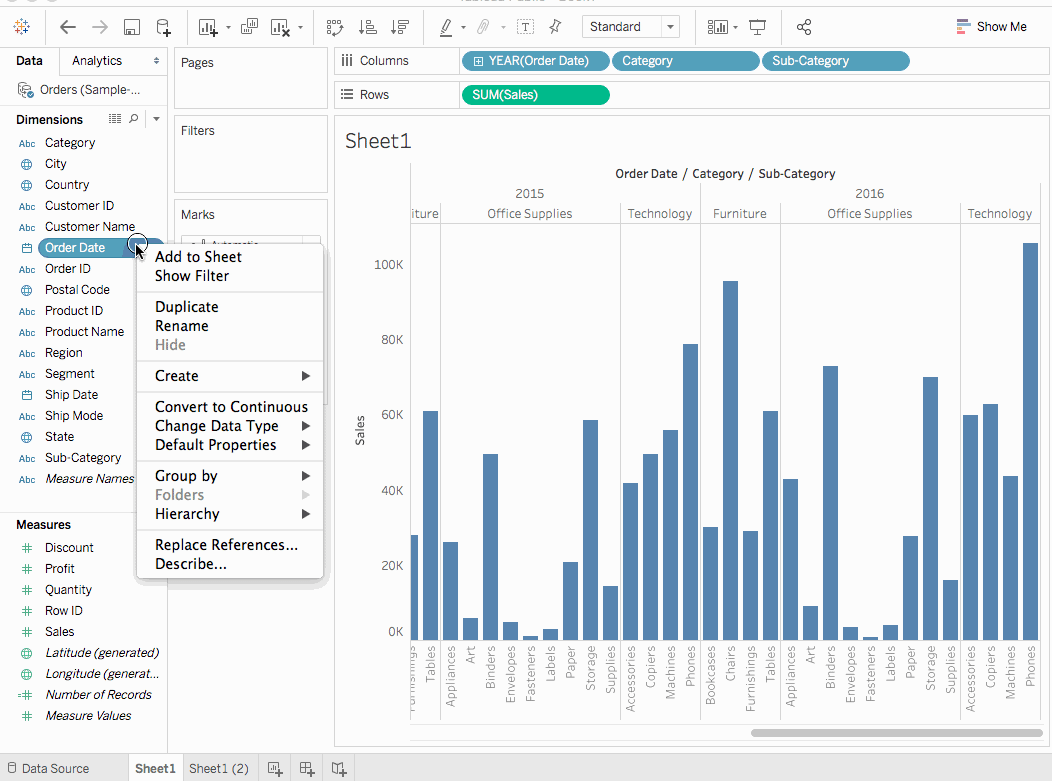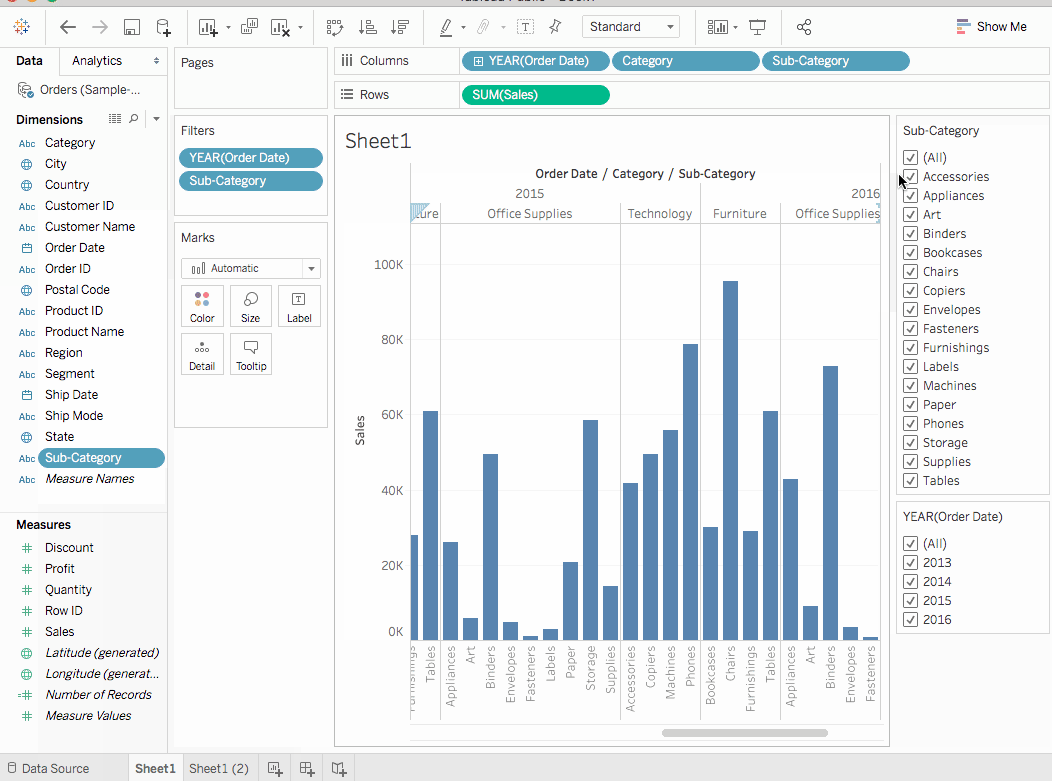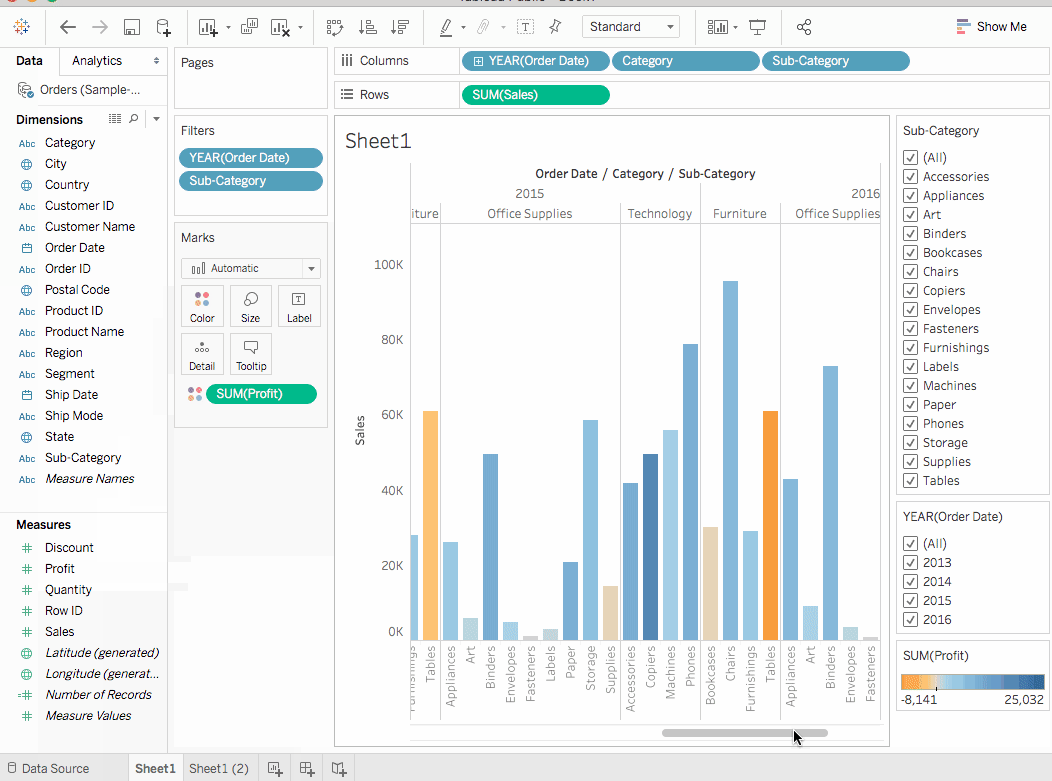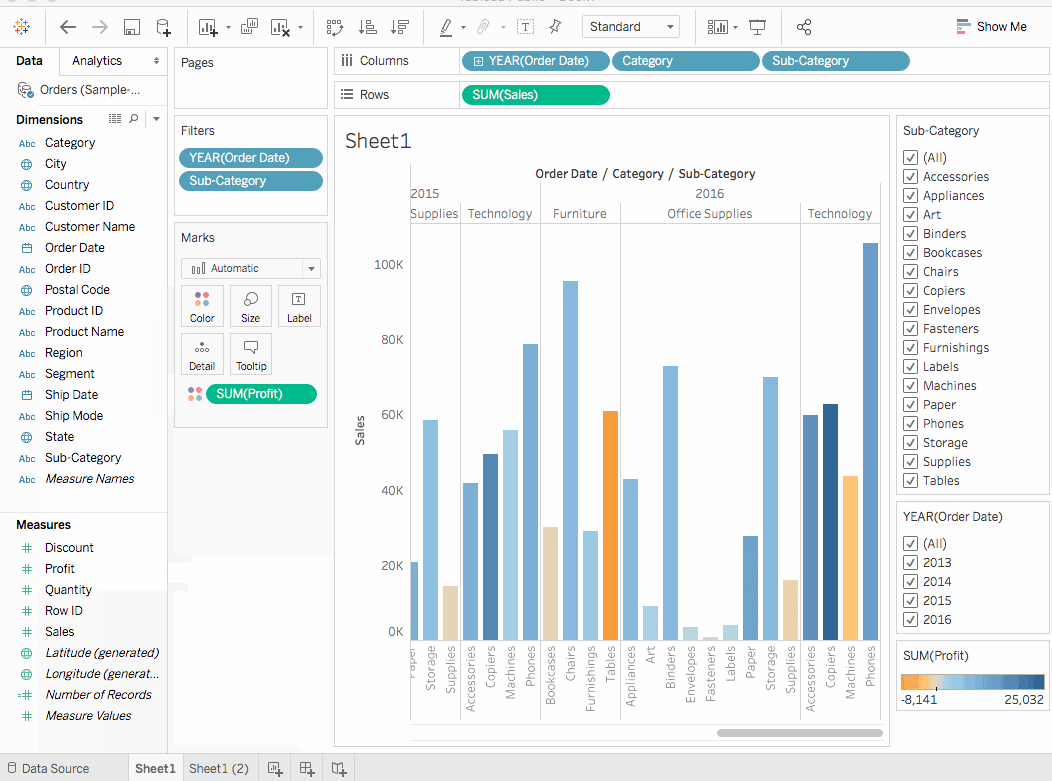
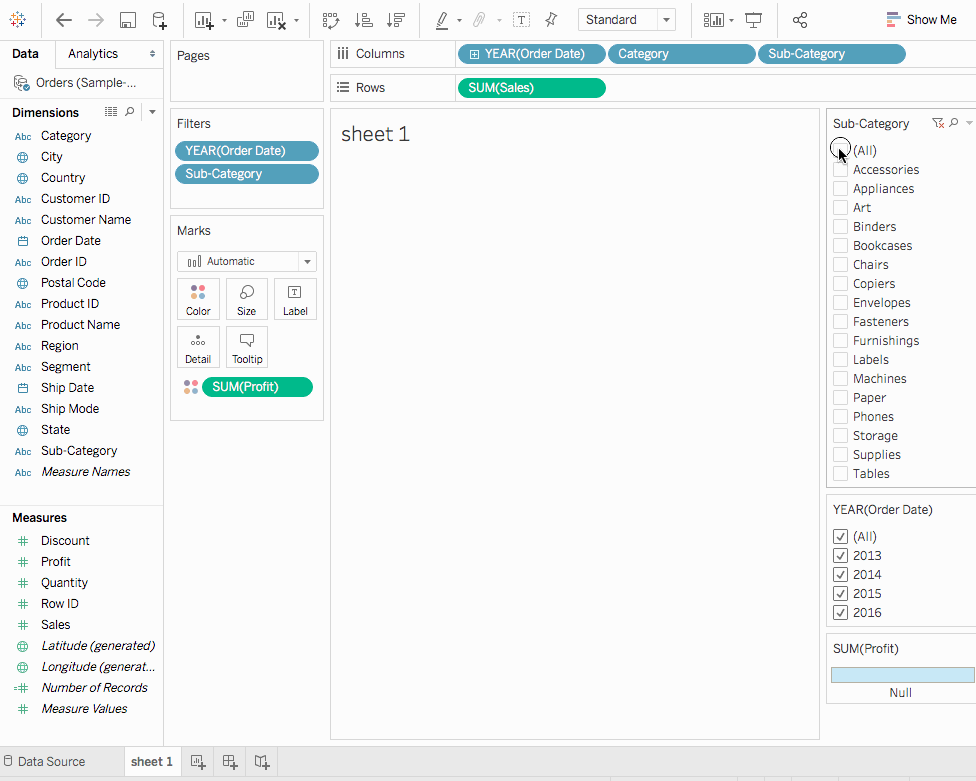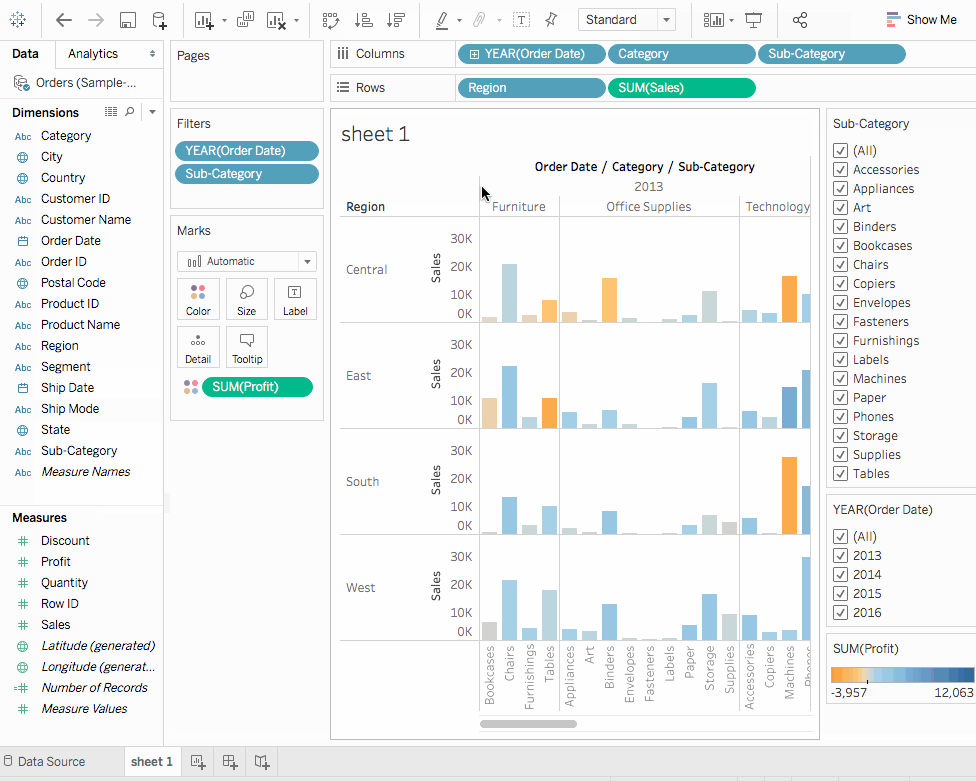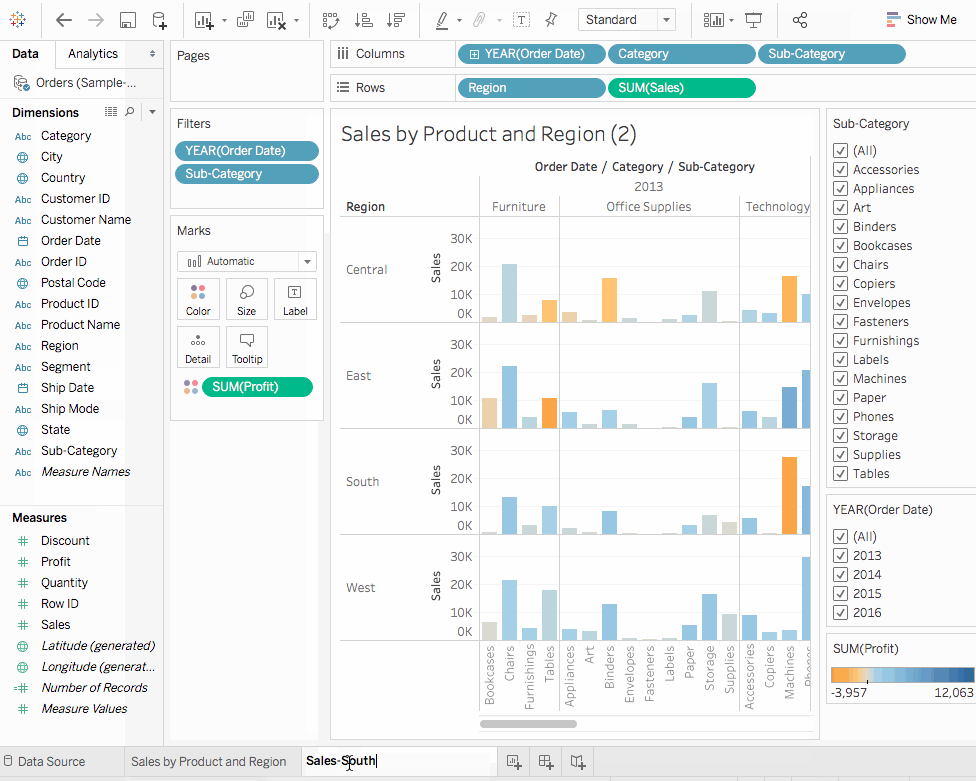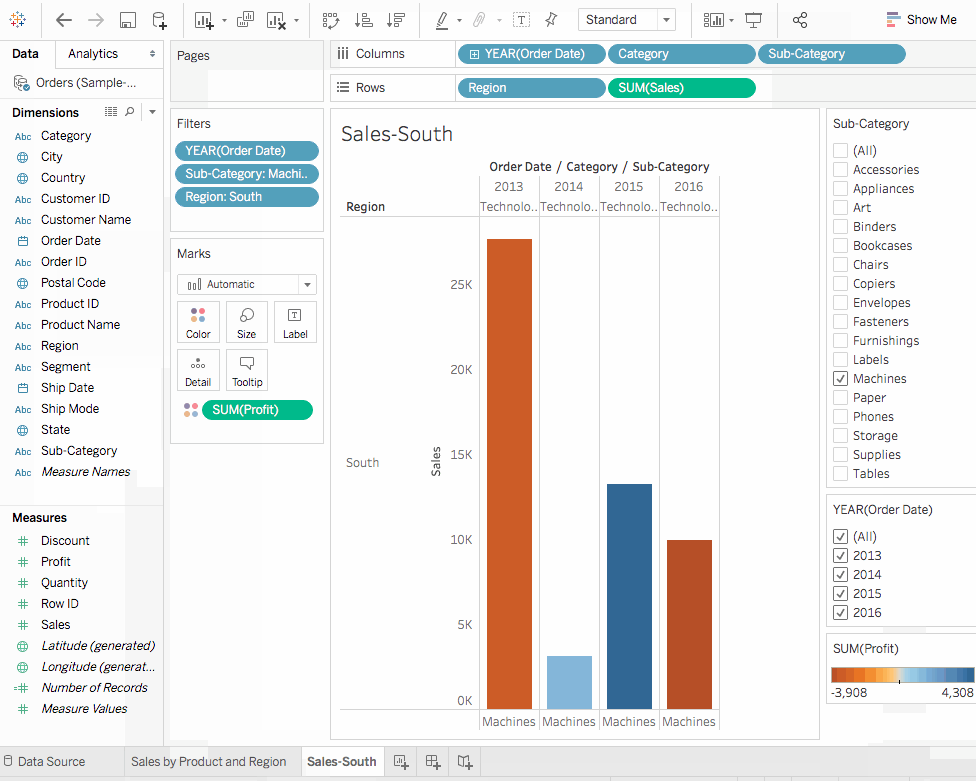
분류는 Dimenstions窗格의 하단에 있습니다. 이를 열 shelf로 드래그하고YEAR(Order Date)옆에 위치시킵니다.Category는Year옆에 배치되어야 합니다. 이렇게하면 뷰가 즉시 선형에서 막대 차트 유형으로 바뀝니다. 차트는 각Product의 연간판매전체를 보여줍니다.자세히 알아보기뷰 안의 각 데이터 포인트(즉, 마크)에 대한 정보를 보려면, 마크를 위해 마우스를 가져다 대면 툴팁이 나타납니다. 툴팁은 해당 분류의 총 판매액을 보여줍니다. 여기는 2016년 Office Supplies 분류의 툴팁입니다:
뷰에 레이블을 추가하려면, 툴바에서
Mark 레이블 표시을 클릭하세요.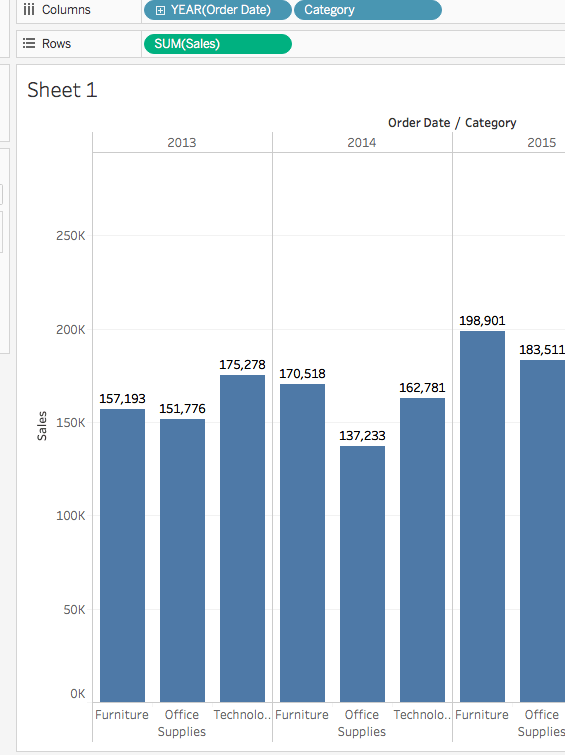
막대 차트는 세로 대신 가로로 표시될 수도 있습니다. 같은 목적으로 툴바에서
스왑을 클릭하세요.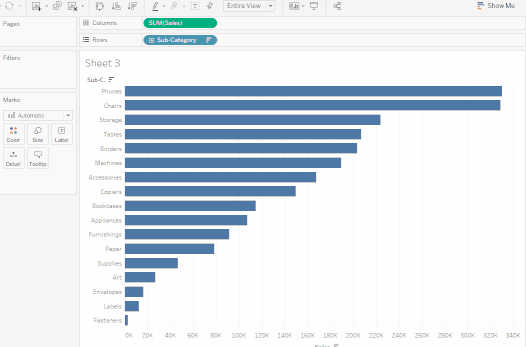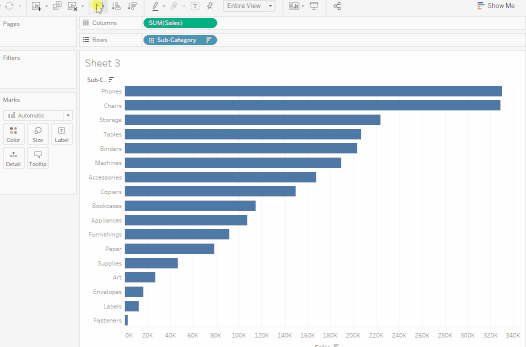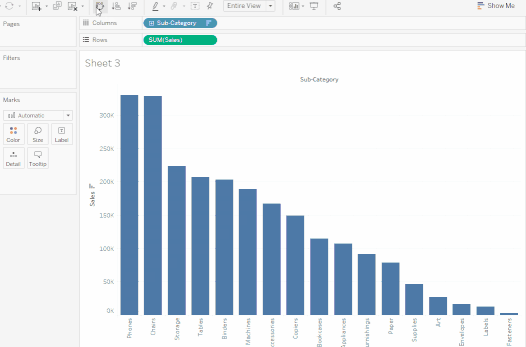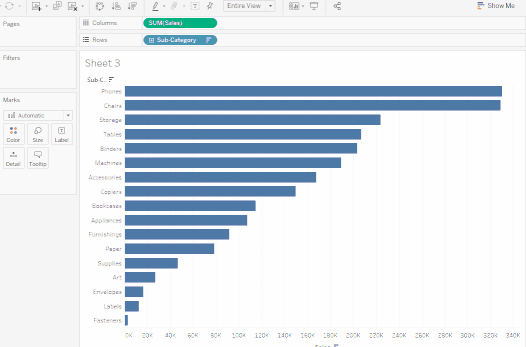
2. 위의 뷰는 카테고리별 판매, 즉 가구, 사무용품, 기술을 잘 보여줍니다. 가구 판매가 2016년을 제외하고 사무용품 판매보다 빠르게 성장하고 있음을 추론할 수 있습니다. 따라서 판매 노력을 사무용품 대신 가구에 집중하는 것이 현명할 것입니다. 하지만 가구는 방대한 카테고리이며 여러 다른 품목으로 구성되어 있습니다. 어떻게 하면 어느 가구 품목이 최대 판매에 기여하고 있는지 식별할 수 있을까요?
이 질문에 답하기 위해 하위 카테고리별로 제품을 살펴보아 주요 판매 품목을 확인하기로 했습니다. 가구 카테고리의 경우 책꽂이, 의자, 가구 장식품 및 테이블에 대한 세부 정보를 보고자 합니다. 하위 카테고리 차원을 열에 더블 클릭하거나 끌어다 놓습니다.
하위 카테고리는 또 다른 이산 필드입니다. 이는 카테고리를 더 자세히 나누어 카테고리 및 연도별로 나뉜 하위 카테고리별로 막대를 표시합니다. 그러나 시각적으로 이해하기에는 방대한 양의 데이터입니다. 다음 섹션에서는 필터, 색상 및 뷰를 더 이해하기 쉽게 만드는 다른 방법을 배울 것입니다.
practical
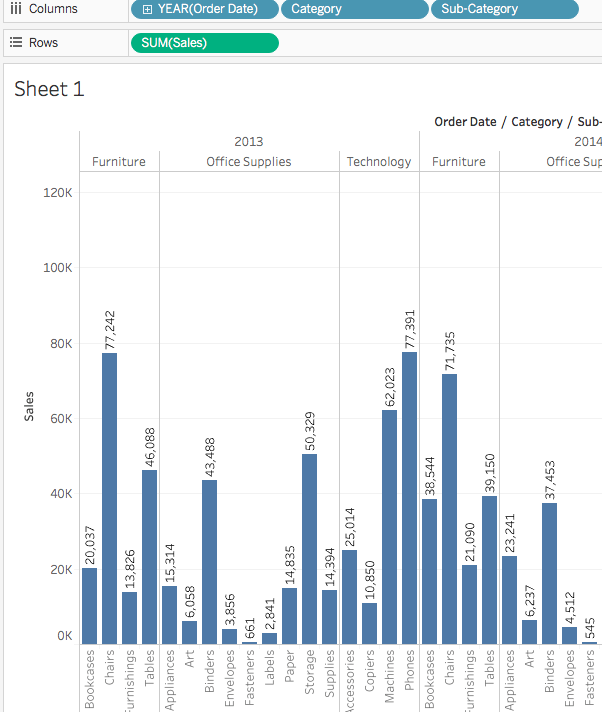
3. 결과를 중요화하기
이 sectiion에서는 특정 결과에 더욱 집중하고자 하며, 필터와 색상은 我們的 관심 있는 세부 정보에 더욱 초점을 추가하는 수단입니다.
시각에 필터 추가하기
필터는 시각에서 값을 포함하거나 제외하는 것을 도울 수 있으며, 이곳에서는 특정 해당 년도의 서브 ategory 별 제품 판매에 더욱 쉽게 관찰할 수 있도록 워크시트에 두 개의 간단한 필터를 추가하겠습니다.
Step
데이터 pan에서 维度(Dimensions)하위에 Order Date를 오른쪽 클릭하여 필터 보기를 선택합니다.Sub->category 필드에서도 마찬가지로 해당 操作을 반복하십시오.
필터는 카드의 종류입니다. 이를 워크시트에서 간단히 드래그 앤 드롭하여 이동할 수 있습니다.
시각에 색상 추가하기
색상은 patrons을 視覚적으로 인식하는 것에 도움이 됩니다.
Step
데이터 pan에서 수치(Measures)하위에 Profit를 Marks card의 Color에 끌어가며 놓입니다.

도서厨(Bookcases), Mesa(Tables) 및 기계가 음수의 이익, 즉, 손실을 함을 보여줍니다. 강력한 洞見(insight)입니다.
practical

주요 발견
불익 제품에 대해 더욱 자세히 필터를 보며 알아보겠습니다.
Step
- 시각에서,
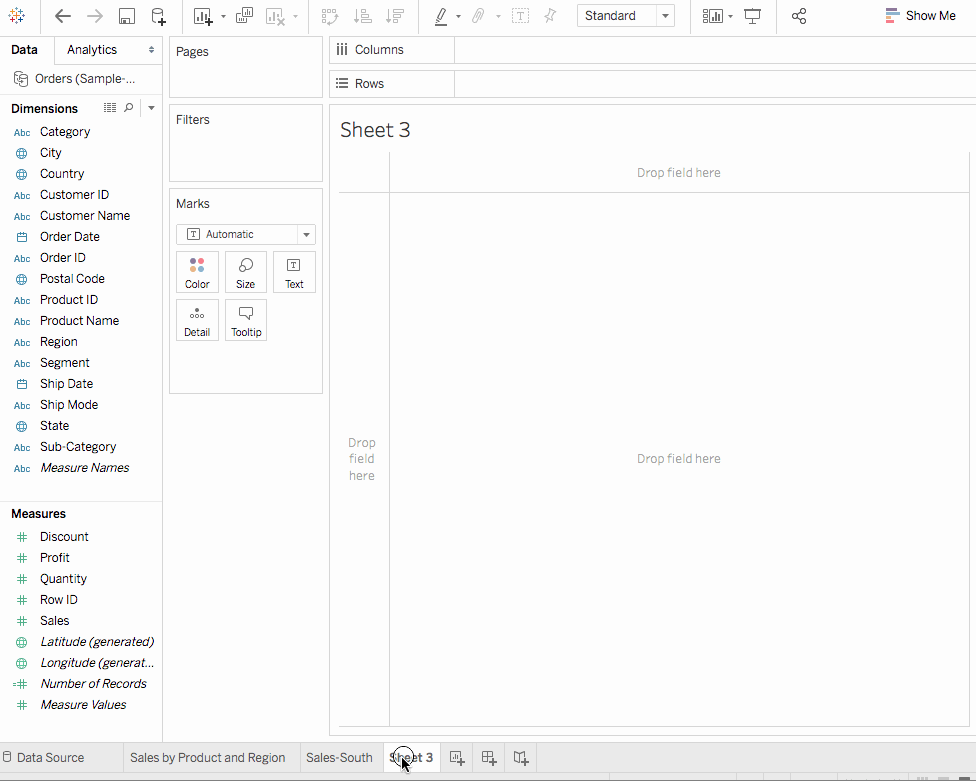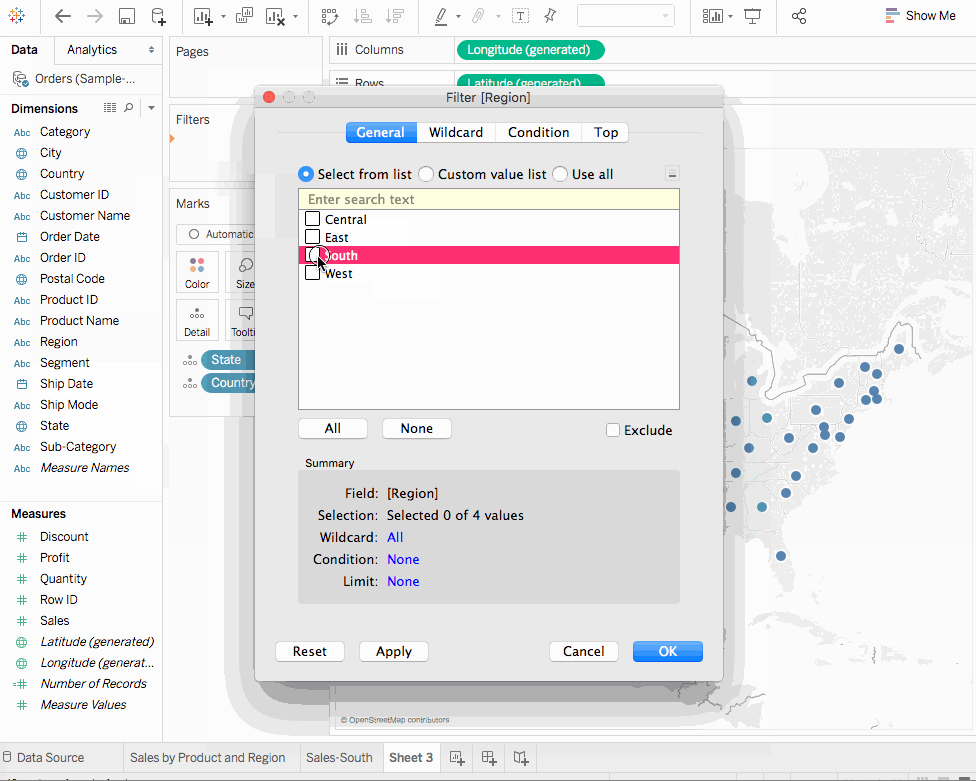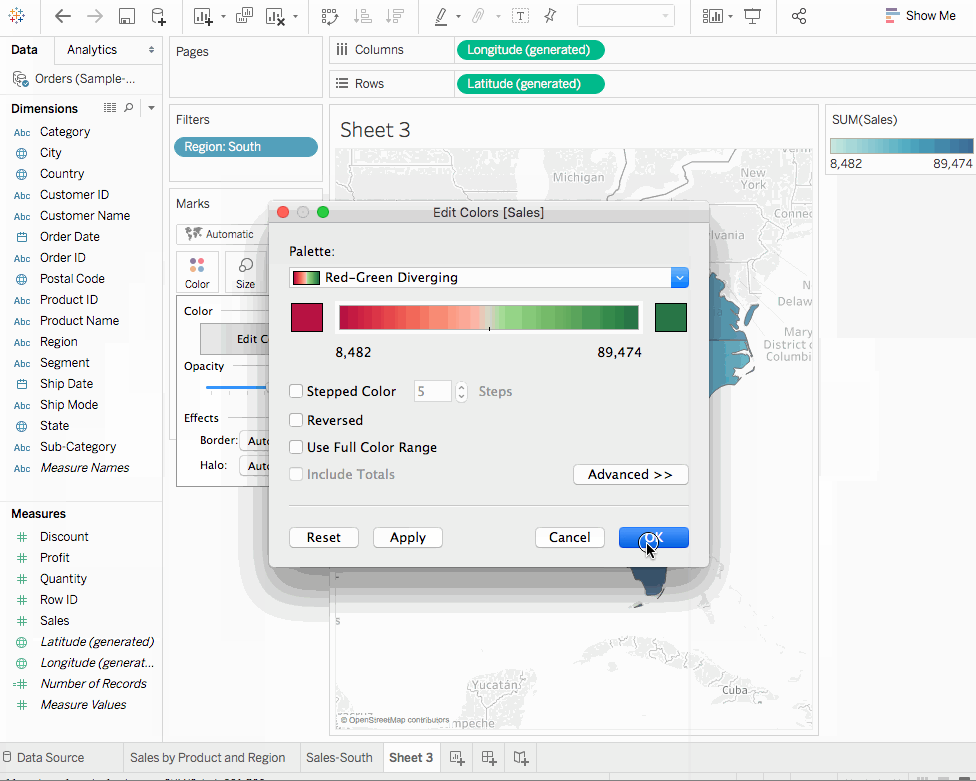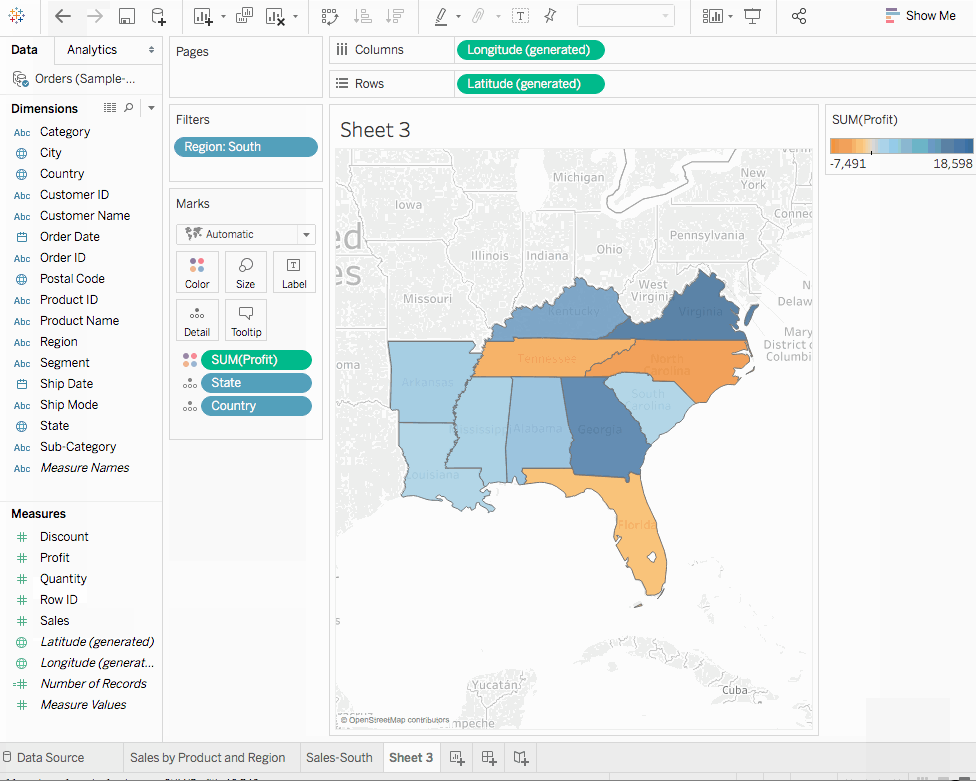
Sub-Category필터 카드에서Bookcases,Tables,Machines를 제외한 모든 方块을 체크 해제 하십시오. 이렇게 一国의 사실을 발견 할 수 있습니다. 일부 년도에서, 도서 상자와 기계가 실제적으로 수익이 나왔습니다. 그러나 2016 년에, 기계가 이익이 나지 않게 되었습니다. Sub-Category필터 카드에서All을 선택하여 다시 모든 서브 카테고리를 표시합니다.- 维度에서
Region을Rows架에 拖动하고 Sum(Sales) 탭의 왼쪽에 放下하십시오. 우리는 南部의 기계가 다른 지역 보다 전반적으로 负面 이익을 보고 있다는 것을 발견합니다. - 지금 시트에 이름을 붙여넣습니다. 작업 공간의 아래 왼쪽에
Sheet 1를 ダブル 클릭하고Sales by Product and Region을 입력합니다. - 시트를 보존하기 위해, Tableau는 우리의 작업 시트를 덮어쓰기 할 수 있으며 어디서부터 시작하여도 다른 시트에서 계속할 수 있습니다.
- ваше 작업 帳本에서
Sales by Product and Region시트 위에 鼠标 오른쪽 클릭하고Duplicate를 선택하고 덮어쓰기 한 시트를Sales-South로 重命名합니다. - 새로운 시트에서 维度에서
Region을Filters架에 拖动하여 보기에 필터를 추가합니다. - 필터 지역 대화 상자에서 모든 方块을 체크 해제 하지 않고 South를 제외하고
OK를 클릭합니다. 이제South의 销售과 이익에 초점을 맞춰서 모니터링할 수 있습니다. 기계 销售은 2014 년과 다시 2016 년에 负面 이익을 보였다는 것을 발견합니다. 다음 절에서 이를 조사하겠습니다. - 마지막으로 결과를
파일 > 다른 이름으로 저장을 선택하여 저장하지 마십시오. 우리의 워크북을지역 판매와 이익으로 명명하십시오.
핸즈온
4. 맵 뷰
맵 뷰 만들기
지리 데이터(지역 필드)를 살펴봐야할 때 맵 뷰가 유용합니다. 현재 예제에서 Tableau는 국가, 주, 도시, 우편번호 필드가 지리 정보를 포함하고 있음을 자동으로 인식합니다.
계骤
- 새 워크시트를 만듭니다.
- 데이터 패널에서
State와Country를 마커 카드의Detail에 추가합니다. 맵 뷰를 얻게 됩니다. Region을Filters쉘에 끌어다 놓고South만 필터링합니다. 맵 뷰는 이제 남부 지역으로만 확대되어 각 주를 나타내는 마크가 표시됩니다.Sales측정값을 마커 카드의Color탭으로 끌어다 놓습니다. 각 주의 판매 범위를 보여주는 채우기 맵을 얻게 됩니다.- 마커 카드에서
Color를 클릭하고색상 편집을 선택하여 색상 스키마를 변경할 수 있습니다. 가능한 팔레트로 실험할 수 있습니다. - 플로리다는 판매 관점에서 가장 좋은 성능을 보입니다. 플로리다를 마우스로 가져가면 89,474 달러의 판매总额을 보여주고, 예를 들어 남한타라이언 주는仅为 8,482 달러의 판매입니다. 이익은 판매만 보다 더 좋은 지표입니다. 이익으로 성능을 측정해보겠습니다.
- 애니메이션
이익을 마크 카드의색으로 끌어다 놓으세요. 이제 테네시, 노스 캐롤라이나, 플로리다가 판매에서는 좋은 성과를 보이지만 음수의 이익을 보이는 것을 알 수 있습니다. 시트를 Profit Map
핸즈 온
자세히 알아보기
맵은 우리가 데이터를 광범위하게 시각화하는 능력을 부여합니다. 지난 단계에서 우리는 테네시, 노스 캐롤라이나, 플로리다가 음수의 이익을 가지고 있다는 것을 발견했습니다. 이 섹션에서 음수 이익의 이유를 탐구하기 위해 막대 차트를 그려보겠습니다.
계骤
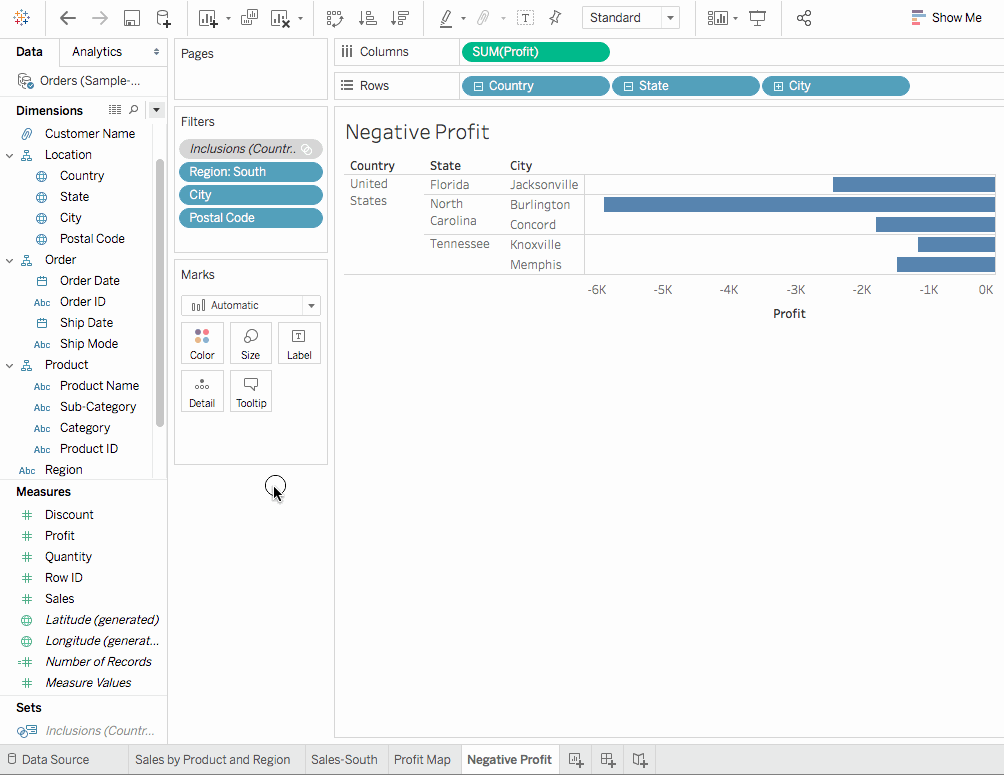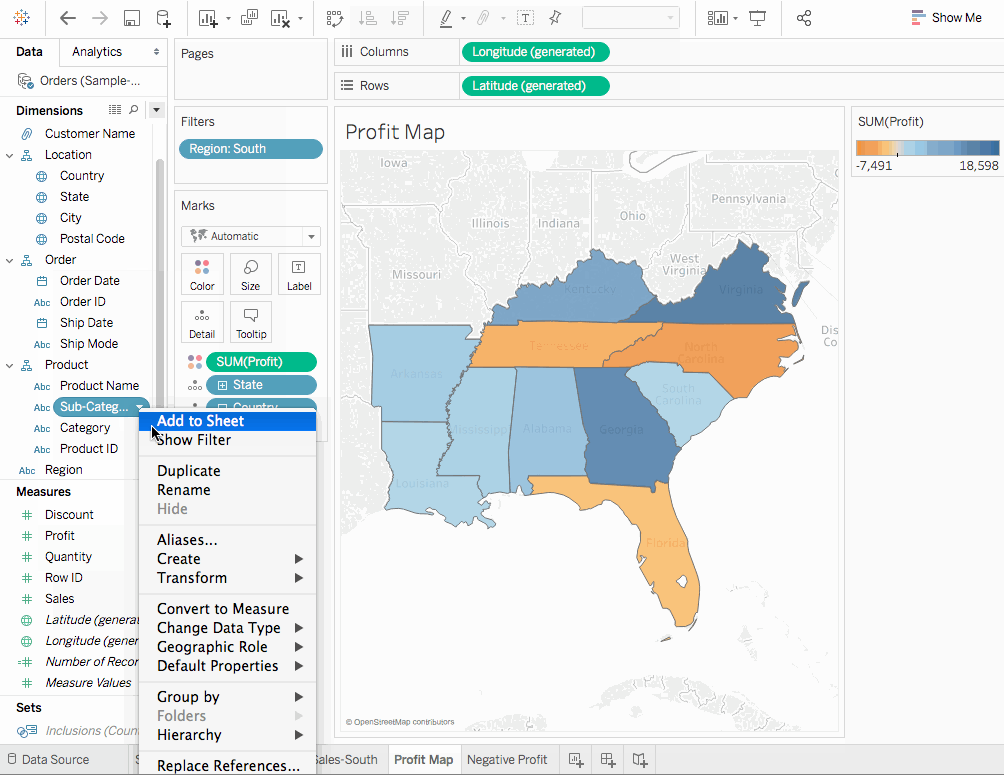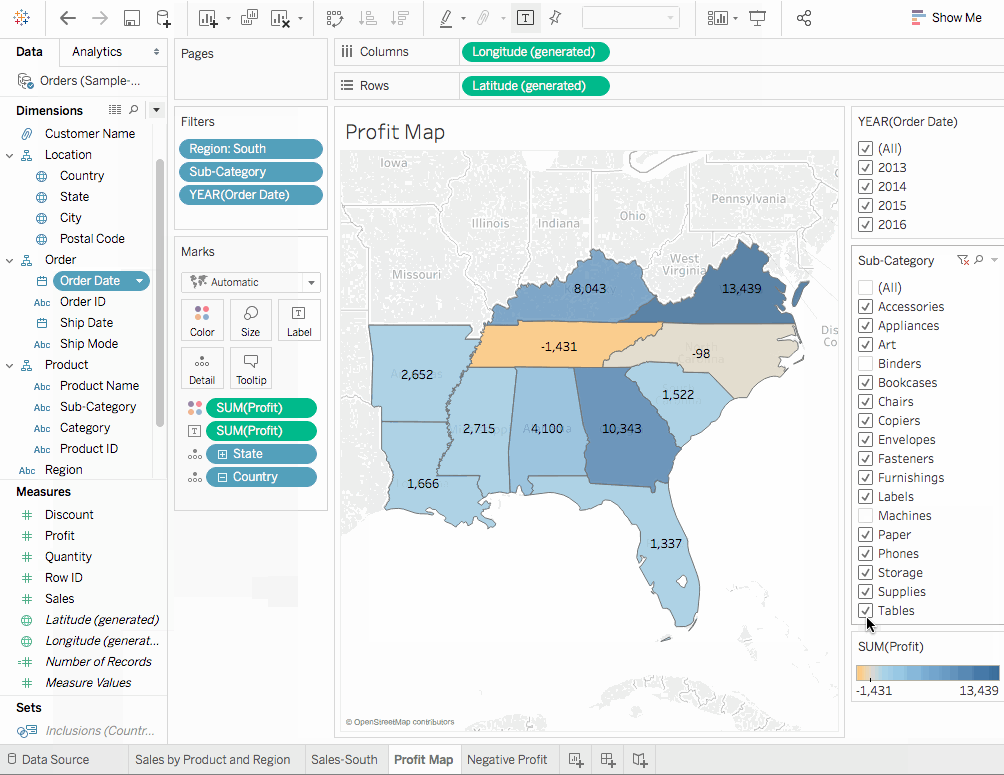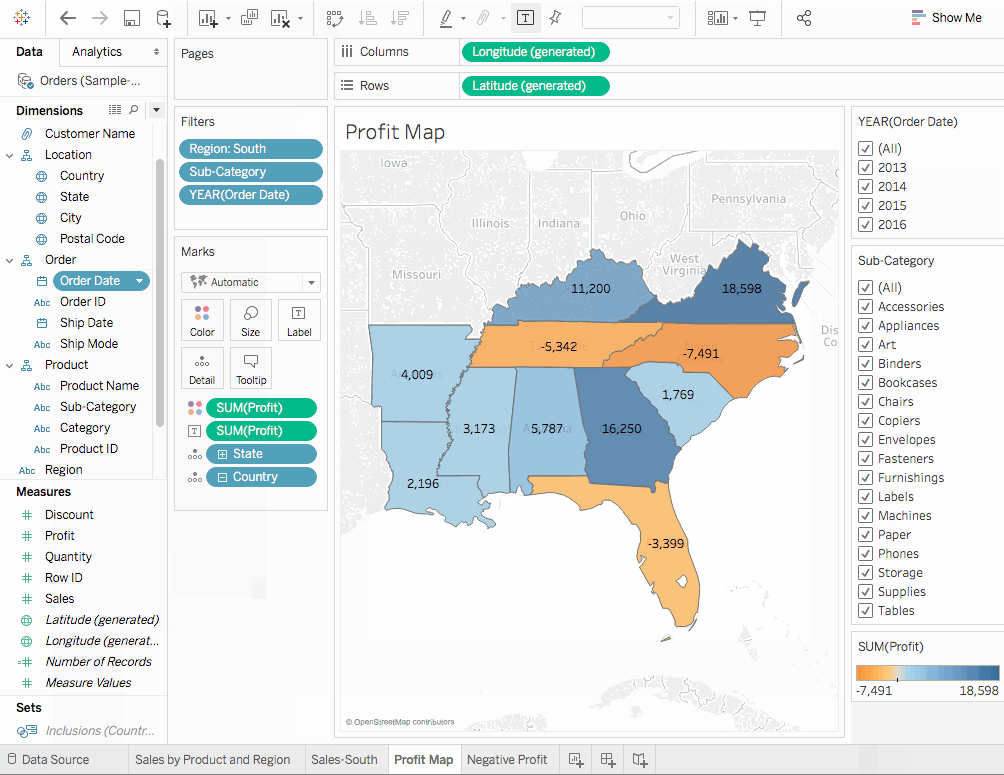
-
Profit Map 워크시트를 복제하고 Negative Profit Bar Chart로 이름을 지정하세요.
-
Negative Profit Bar Chart 워크시트에서
보여줘를 클릭하세요.보여줘는 워크시트에 언급된 항목 사이에 그래프를 그릴 수 있는 방법을 제시합니다.보여줘에서 수평 막대 옵션을 선택하면 뷰가 즉시 세로 막대에서 수평 막대로 업데이트됩니다. -
여러 막대를 한 번에 선택하려면 클릭하고 커서를 드래그하면 됩니다. 우리는 테네시, 노스캐롤라이나, 플로리다 이 세 주에만 집중하고자 합니다. 따라서 해당 주에 관련된 막대만 선택할 것입니다.
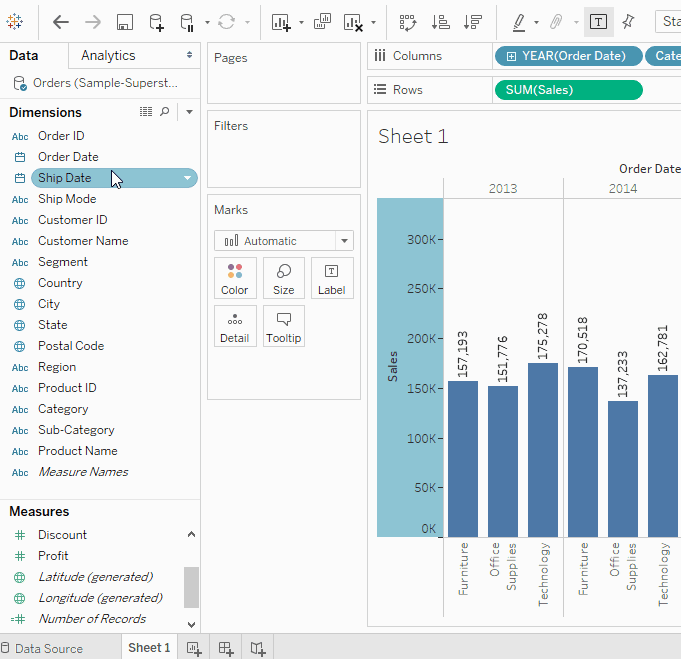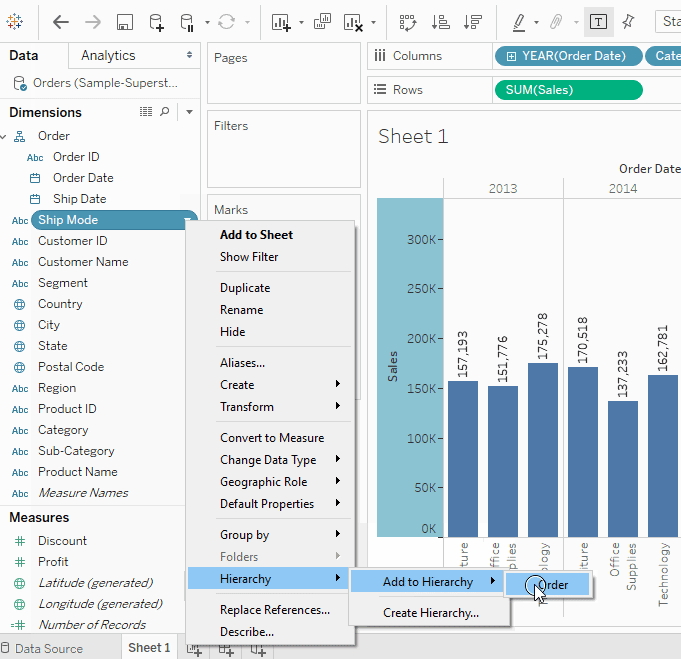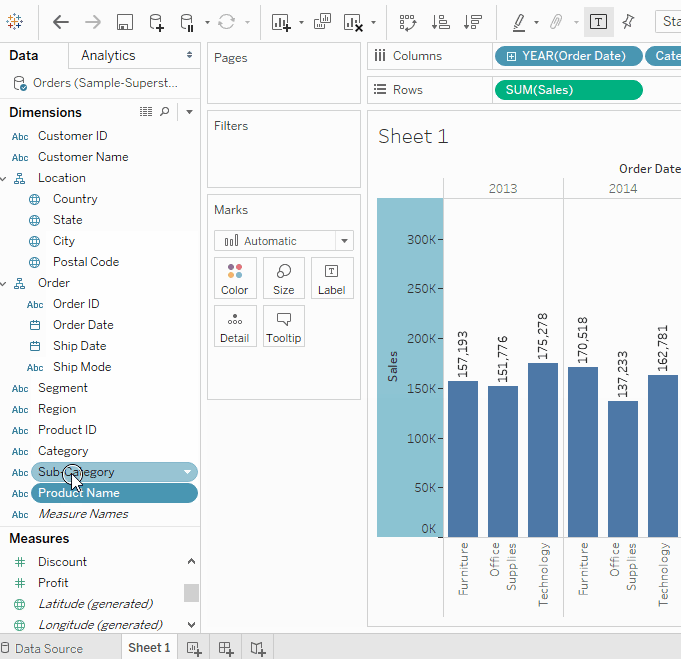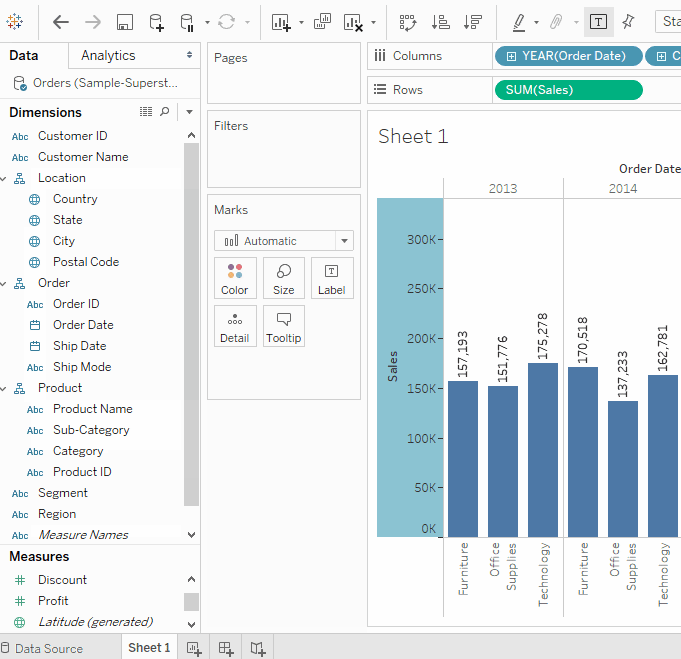
자세히 알아보기계층 만들기
계층은 유사한 필드를 그룹화하여 시각화에서 수준 간에 빠르게 드릴다운할 수 있도록 할 때 유용합니다.- 데이터 창에서 필드를 드래그하여 다른 필드 위에 직접 놓거나 필드를 마우스 오른쪽 버튼으로 클릭하고 선택하십시오
- 계층에 추가 필드를 드래그하십시오. 필드는 새로운 위치로 드래그하여 계층 내에서 재정렬할 수도 있습니다. 현재 시각화에서는 다음과 같은 계층을 생성할 것입니다: 위치, 주문, 제품.
-
행 쉘프트에서
State필드의 더하기 모양의 아이콘을 클릭하여City수준으로 드릴 다운합니다.- 데이터가 많습니다.
N-Filter를 사용하여 필터링하고 가장 약한 성과자를 제시할 수 있습니다. 그러려면Data패널에서City를 필터 쉘프트로 드래그하십시오. 필드로 클릭한 후Top드롭다운을 클릭하고Bottom를 선택하여 가장 약한 성과자를 제시합니다. 텍스트 상자에 5를 입력하여 데이터 세트의 하위 5개 성과자를 보여줍니다.
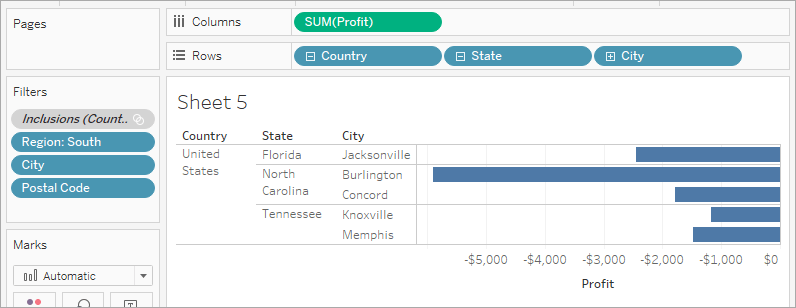
- 데이터가 많습니다.
지금 우리는 플로리다 주의 자케슨维尔와 마이애미, 노스 캐롤라이나 주의 버lington, 테네시 주의诺克斯维尔와 멘�菲利스가 수익이 가장 안 좋은 도시라는 것을 알 수 있습니다. 노스 캐롤라이나 주의 자케슨维尔는 이곳에 없어야 하는데, 수익적인 판매를 가지고 있습니다. 이는 우리가 적용한 필터에 문제가 있다는 것을 의미합니다. Tableau의 우선순위 오퍼레이션을 이용해야 합니다.
-
Filters shelf에서 Inclusions (Country, State) 집합에 마우스 오른쪽 클릭 후
Context에 추가를 선택합니다. 이제 Concord(노스 캐롤라이나)가 보이는 반면 Miami(플로리다)가 사라졌다. 이제 이해할 수 있습니다. -
하지만 자케슨维尔 (노스 캐롤라이나)가 여전히 있어서 잘못됩니다. Rows shelf에서
City탭의 마름모 모양의 아이콘을 클릭하여 우편번호 수준으로 드릴 다운합니다. 노스 캐롤라이나 주 자케슨维尔의 우편번호 28540에 마우스 오른쪽 클릭 후제외를 선택하여 자케슨维尔를 수동으로 제외합니다. -
행 쉘프에 있는 우편번호를 드래그합니다. 이것은 최종 보기입니다.
핸즈 온
주요 발견
이제 손해를 입는 엔티티, 즉 상품들에만 집중하고 그러한 상품을 팔고 있는 위치를 식별하십시오.
단계
서브-카테고리를 행으로 드래그하여 더욱 자세히 드릴 다운합니다.- 마찬가지로
이익을컬러로 마크 카드에 드래그합니다. 이렇게 하면 부정적인 이익을 가진 상품을 빨리 발견할 수 있습니다. 주문 날짜를 우클릭하고필터 보기를 선택합니다. 기계, 테이블, 밴더가 나쁜 성능을 보이고 있습니다. 그럼 어떻게 해야 할까요? 한 가지 해결책은 자켄빌, 콘코드, 버lington, 녹스빌, 메모피스에서 이러한 상품의 판매를 중지하는 것입니다. 저희의 결정이 옳은지 확인해봅시다.- 이전에 생성한
이익 지도시트 탭으로 돌아가십시오. - 클릭하시오
하위카테고리필드를 선택하여필터 표시옵션을 선택하십시오. 손익를측정아래에서레이블마크 카드로 드래그하십시오.- 다시
주문일자를 클릭하고필터 표시를 선택하십시오. 필터에서 우리가 음수적인 손익을 기여하는 것으로 생각되는 항목을 지웁니다. 따라서 각각의 바인더, 기계, 테이블 앞의 체크박스를 해제하십시오. 이제 손익을 생성하는 엔티티만 남았습니다. 이는 바인더, 기계, 테이블과 같은 엔티티가 실제로 어떤 지역에서 손해를 덮친 것이며 우리의 발견이 옳았음을 보여줍니다.
핸즈온
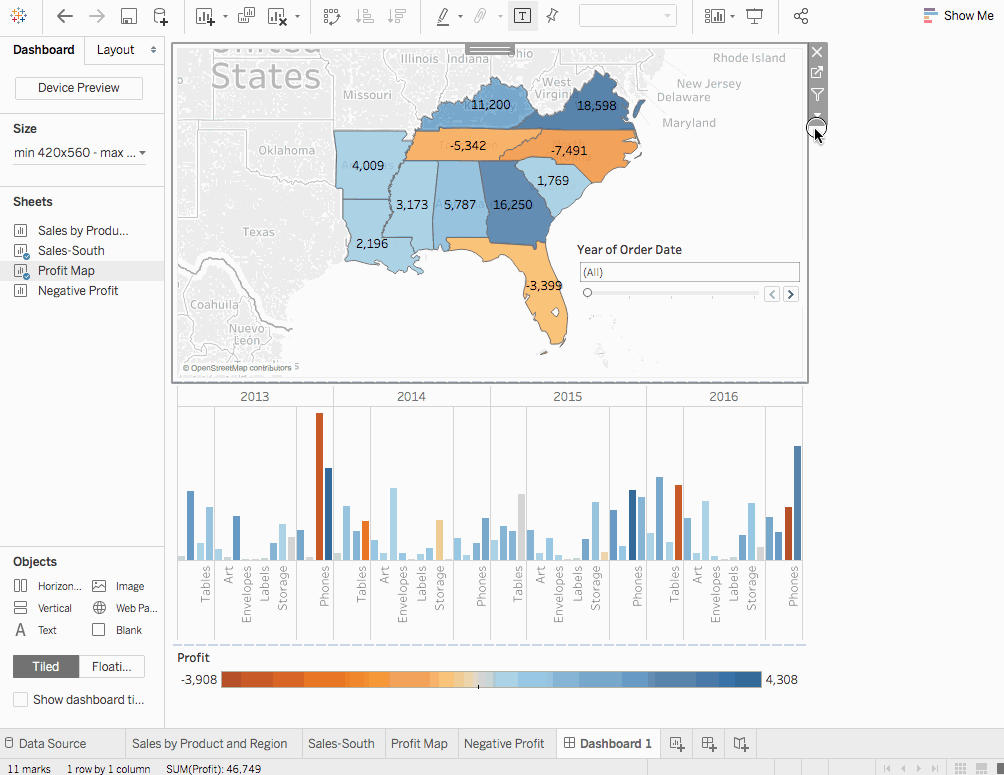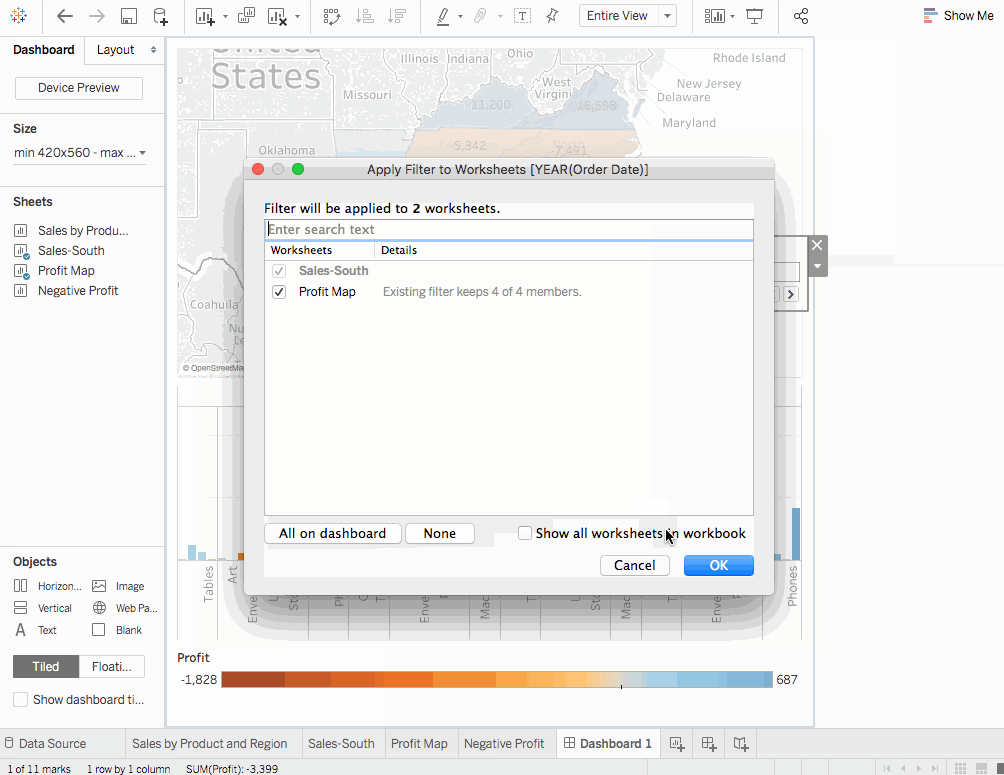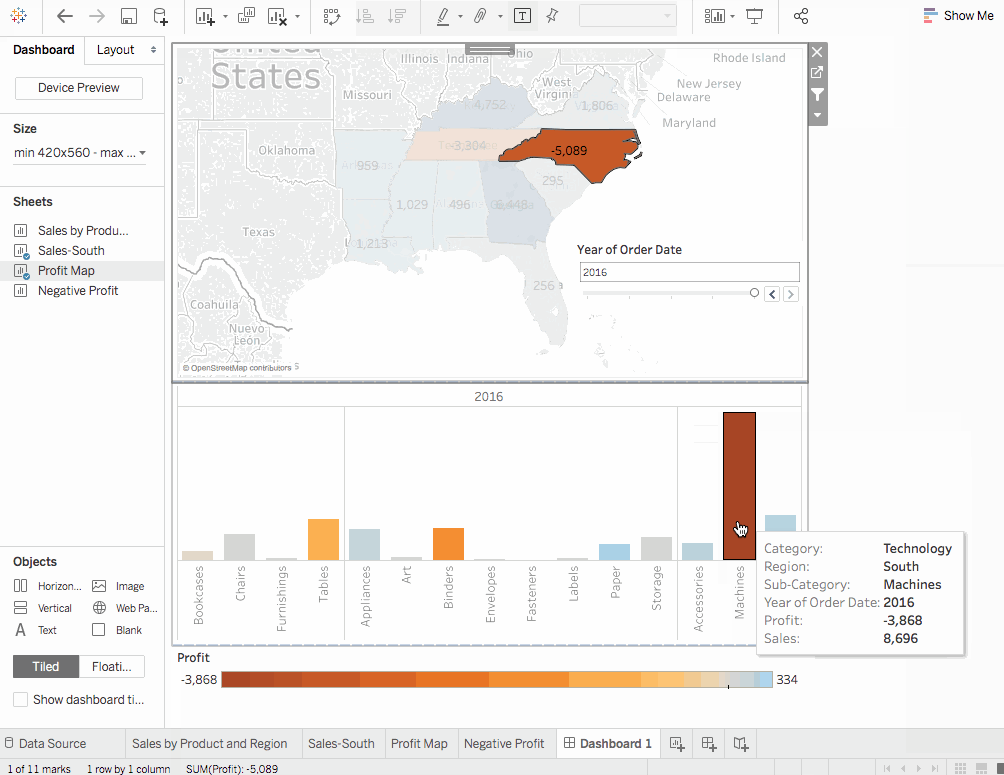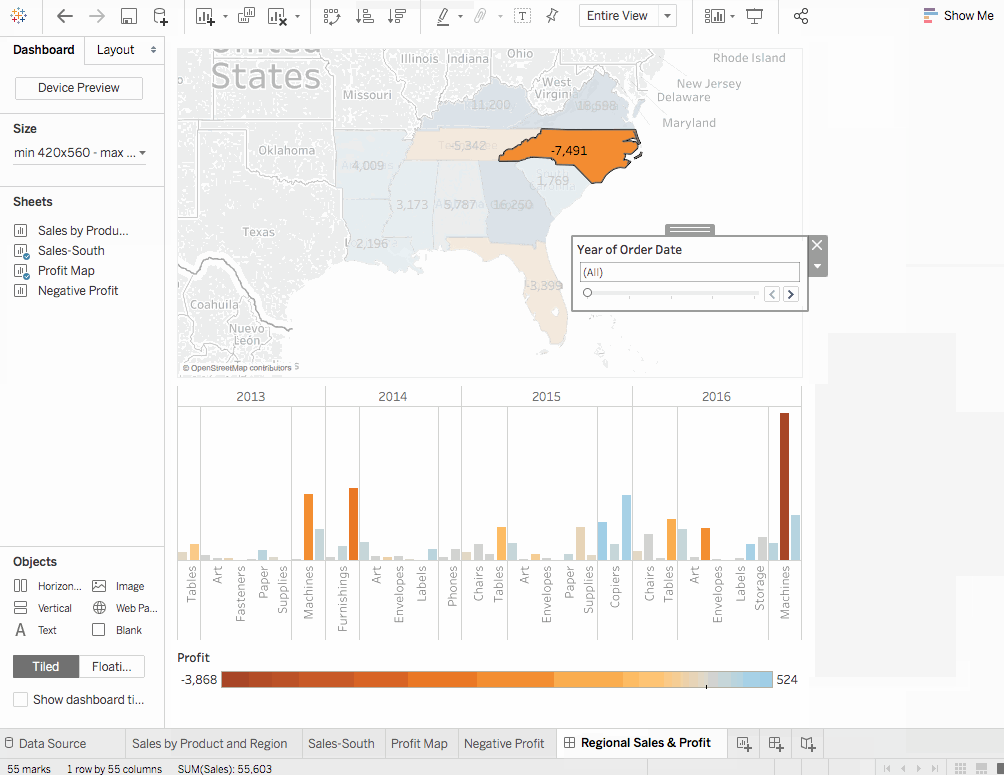
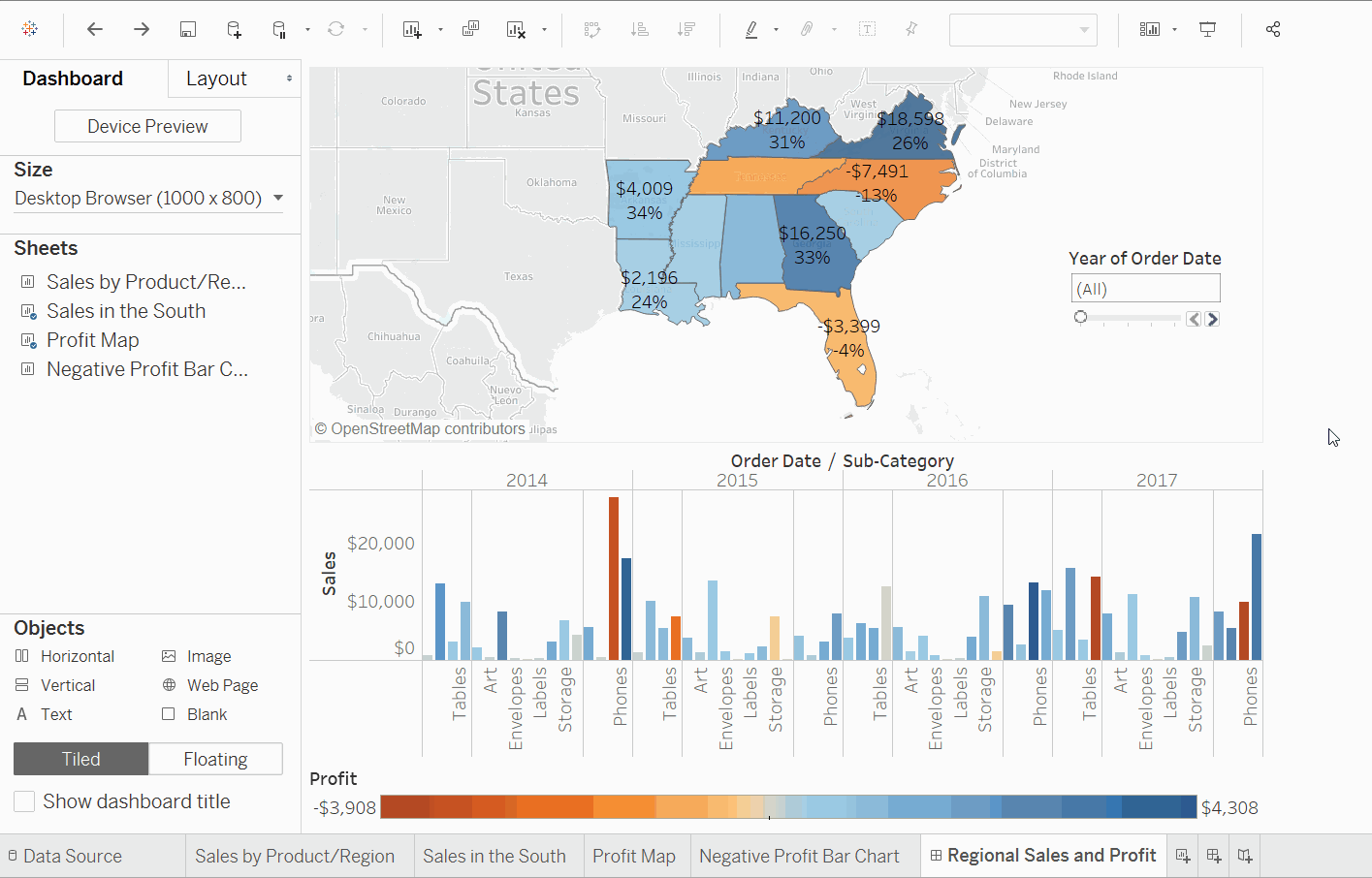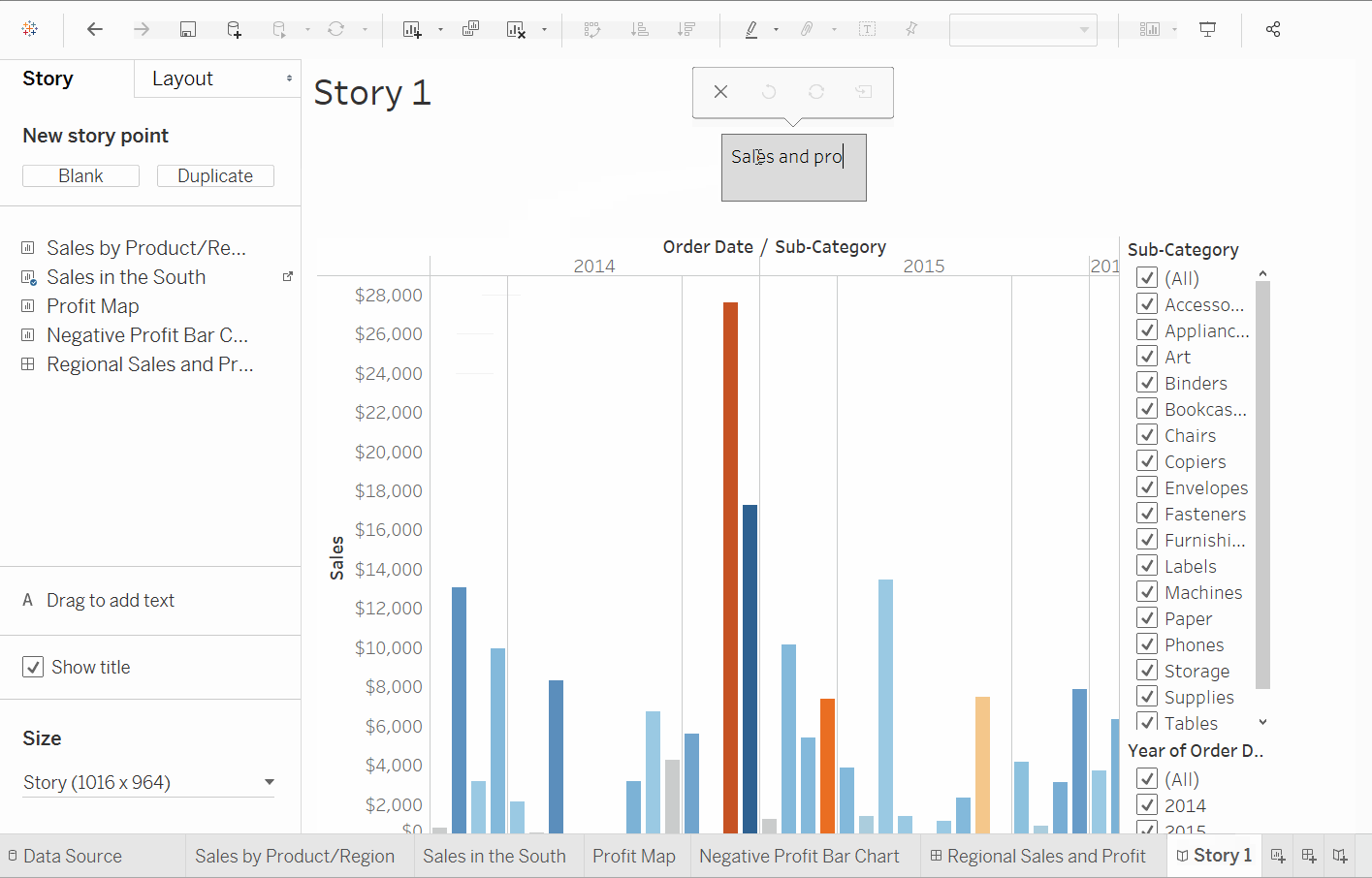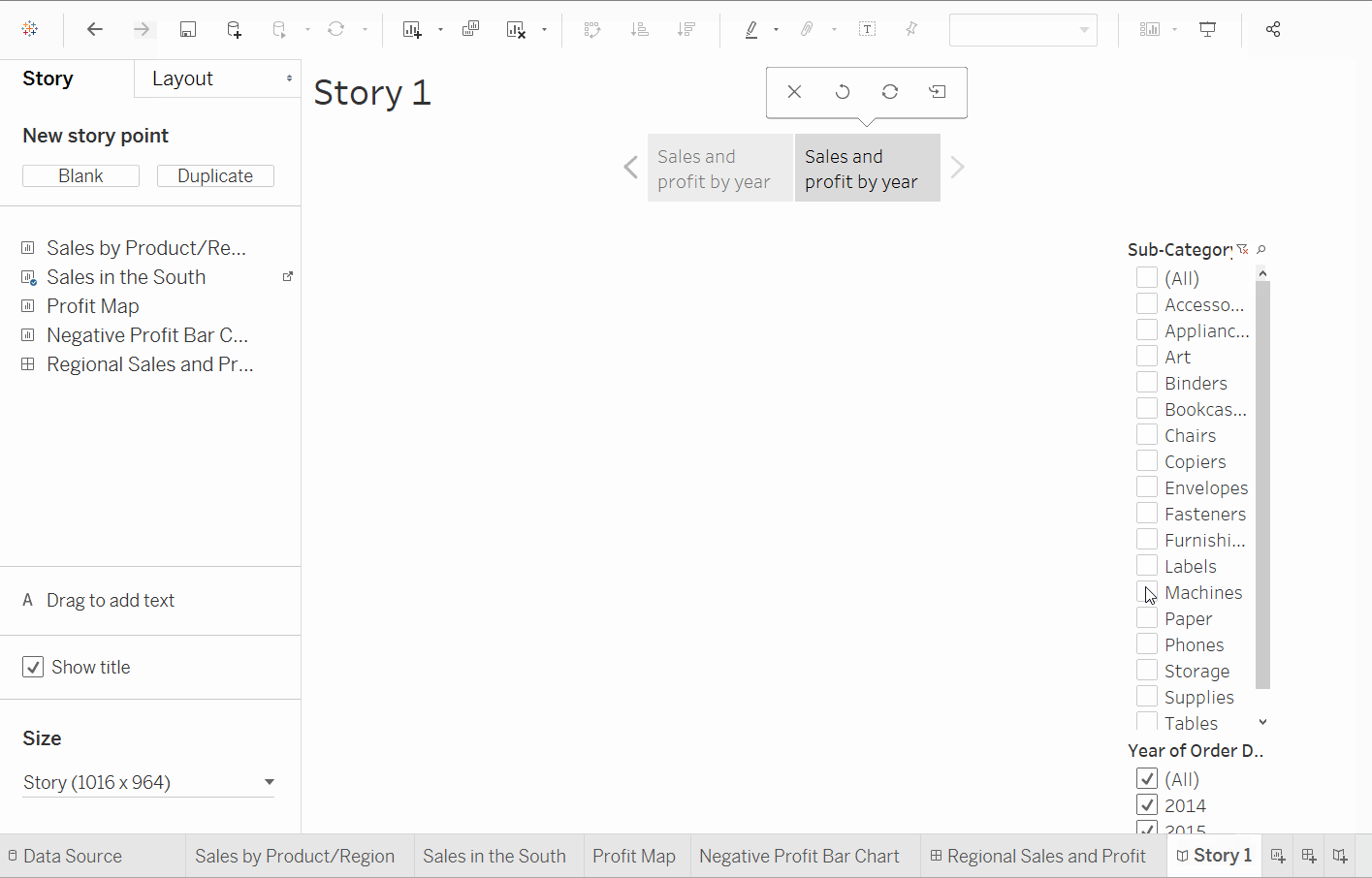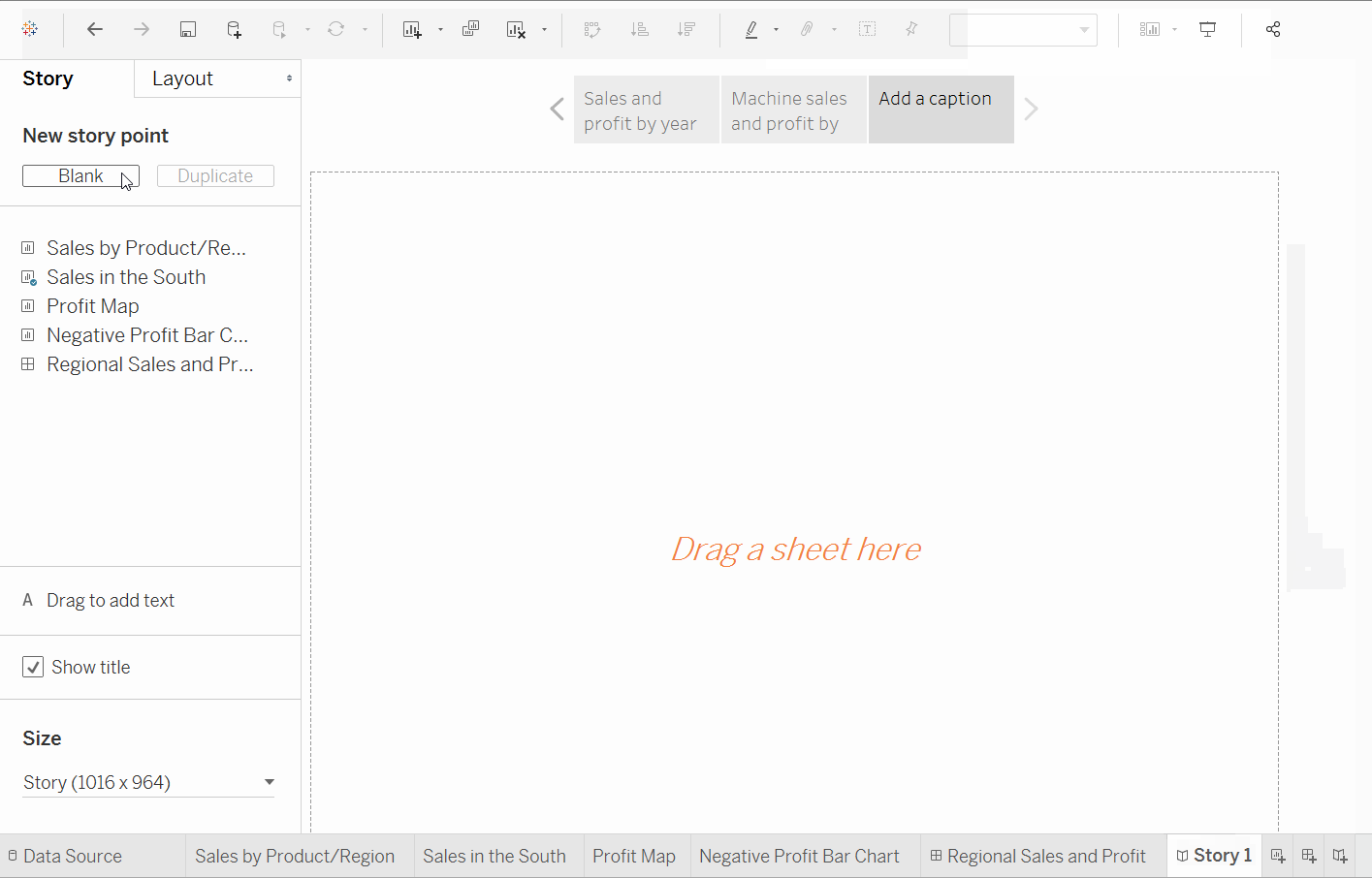
5. 대시보드
대시보드는 여러 가지 보기를 모아놓은 것으로 동시에 여러 가지 데이터를 비교할 수 있습니다.
대시보드 만들기
계骤
신규 대시보드버튼을 클릭하십시오.남부 판매를 빈 대시보드로 드래그하십시오.손익 지도를 대시보드로 드래그하고 남부 판매 보기 위에 놓으십시오. 두 보기를 한번에 볼 수 있습니다. 다른 사람들이 데이터를 이해할 수 있도록 표시하려면 대시보드를 마음대로 배열할 수 있습니다.- 대시보드 뷰의
남부 판매워크시트에서지역밑을 클릭하고헤더 표시를 지웁니다. 다른 모든 헤더에도 같은 작업을 반복하십시오. 이렇게 하면 필요한 것만 강조하고 중요하지 않은 정보를 숨길 수 있습니다. 이익 맵에서 제목도 숨기고도시 상품 销售맵에 대해 同样的 과정을 실시합시다.- 우리는 오른쪽에
하위 대분류필터 카드와주문 날짜의 해가 반복되었음을 확인할 수 있습니다. 이를 unnecessarily 많이 표시하지 않기 위해 그냥 그들을 지우십시오. 결국주문 날짜의 해를 클릭합니다. 다운로드 화살표가 나타나고단일 값 (슬라이더)의 옵션을 선택합니다. 이제 魔法制을 시작하십시오. 다른 년도를 슬라이더에서 선택하여 销售도 따라서 달라지게 만듭니다. 이익필터를 dashboard Sales in South의 아래로 이동하여 좋은 시각화를 위해 끌어놓습니다.
手伝い
交互性 추가
dashboard를 더욱 交互性 있게 만들기 위해서는, 어떤 하위 대분류가 어떤 주소에서 이익이 좋은지 보기 위한 일부 변경이 필요합니다.
단계
- 우리는 시작하기 위해
이익 맵에 대해서 맵을 클릭하면 오른쪽 상위에Use as filter아이콘이 나타납니다. 그것을 클릭합니다. 우리가 어떤 맵을 선택하면 해당 주소의 销售은도시 销售맵에서 강조되게 됩니다. -
주문 날짜의 해에 대해 다운로드 옵션을 클릭하고Apply to Worksheets > Selected Worksheets로 가십시오. 다이얼로그 박스가 열리게 됩니다.All옵션을 선택하고OK를 눌러봅니다. 이 옵션이 무엇을 하는지 기억해둡시다. 同样的 데이터 소스를 가지는 모든 워시트에 필터를 적용합니다. - 탐구하고 실험하세요.下面的的可視化에서 우리는
Sales South지도를 필터링하여 只有北卡罗来纳州에 판매되는 제품을 볼 수 있습니다. 그런 다음 년간의 이익을 쉽게 탐색할 수 있습니다. - 대시보드 이름을
지역 판매 및 이익으로 변경합니다.
핸즈 온
따라서, 北卡罗来纳州에 기계를 판매하면 회사에는 이익이 없었습니다.
6. 스토리
대시보드는 멋진 기능입니다만, Tableau는 스토리 모드로 결과를 프리젠테이션 형태로 보여주는 것도 가능하게 해줍니다. 이는 이번 섹션에서 다룰 내용입니다.
스토리 만들기
단계
새 스토리버튼을 클릭합니다.- 왼쪽 스토리 패널에서 이전에 생성한
남부 판매워크시트를 뷰로 드래그합니다. - 워크시트 위의 회색 박스内的 텍스트를 편집합니다. 이것은 캡션입니다.
년도별 판매와 이익로 명명합니다. - 스토리는 매우 특정적입니다. 여기서 우리는 北卡罗来纳州에서 기계를 판매하는 스토리를 다룰 것입니다. 스토리 패널에서
복제를 클릭하여 처음의 캡션을 복제하거나 새로 만들 수 있습니다. 하위 카테고리에서선택하여 只有기계를 필터링합니다. 이를 통해 년도별 기계의 판매와 이익을 측정할 수 있습니다.- 캡션 이름을
년도별 기계 판매와 이익으로 변경합니다.
핸즈 온
결론 만들기
북캐롤라이나의 기계들이 이익 손실을 초래하고 있다는 것이 명확합니다. 그러나, 전체적인 이익과 판매를 살펴보는 것으로는 이를 입증할 수 없습니다. 이를 위해서는 지역별 이익이 필요합니다.
단계
- 스토리 창에서
빈을 선택합니다. 이미 만들어진 대시보드지역별 판매 및 이익을 캔버스로 끌어옵니다. - 이를
남부의 저성능 품목으로 캡션을 붙입니다. 복제를 선택하여 지역 이익 대시보드가 포함된 또 다른 스토리 포인트를 만듭니다. 바 차트에서 북캐롤라이나를 선택합니다, 왜냐하면 우리는 그것에 대해 더 많은 것을 보여주고 싶기 때문입니다.- 모든 연도를 선택합니다.
- 명확성을 위해
북캐롤라이나의 이익: 2013-2016과 같은 캡션을 추가합니다. - 2014년과 같은 연도를 선택합니다.
북캐롤라이나의 이익: 2014과 같은 캡션을 추가한 다음 복제 탭을 클릭합니다. 나머지 모든 연도에 대해 동일한 단계를 반복합니다. - 프레젠테이션 모드를 클릭하고
스토리가 전개되도록 합니다.
실습
이제 우리는 북캐롤라이나 시장에 언제 어떤 제품이 도입되었고, 어떻게 성과를 냈는지에 대한 아이디어를 얻었습니다. 우리는 단순히 부정적인 이익을 해결하는 방법을 찾은 것이 아니라, 데이터를 통해 이를 성공적으로 뒷받침했습니다. 이것이 Tableau의 스토리의 장점입니다.
7. Tableau의 R, Python 및 SQL과의 통합
, , , , , ,
Tableau의 다양한 시각화 장점 외에도, 이는 굉장한 기본적인 연결 기능을 가지고 있습니다. Tableau는 Python과 R같은 언어와 SQL 같은 DBMS와도 쉽게 통합할 수 있습니다. 이는 기능성에 대한 이점을 증가시키고, Python이나 R에서 작업하고慣れ어진 데이터 과학자에게 큰 도움이 됩니다. 데이터 과학자는 Tableau에서 직접 R과 Python 스크립트를 가져와서 이 언어들보다 훨씬 우수한 시각화 기능을 이용할 수 있습니다. 또한, Tableau의 시각화 기능은 사용하기 쉽고 직관적이며, 데이터 과학자가 많은 시간을節约할 수 있습니다.
이 절에서 우리는 Tableau를 외부 소스와 어떻게 연결하고 해당 연결의 이점을 살펴볼 것입니다.
Tableau와 R
R은 선형 및 비선형 모델링, 통계적 시험, 시계열 분석, 분류, 군집화 등과 같은 고급 예측 분석을 수행하는데 사용되는 유명한 통계 언어입니다.(Tableau 8.1과 R) Tableau와 R를 함께 사용하는 것에는 다음과 같은 이점이 있습니다:
- Tableau 사용자는 고급 R 라이브러리를 사용하여 데이터에서 더 나은 깊은 인사이트를 얻을 수 있게 해서 Tableau의 통계적 파워를 활용할 수 있습니다.
- Tableau의 강화된 데이터 탐색 옵션과 다수의 소스와 연결할 수 있는 기능은 R 사용자에게 큰 도움이 됩니다.
- 더욱이, Tableau 사용자는 R 언어의 유용함을 실제로 알지 않아도 이를 이용할 수 있게 해줍니다.
태블로어는 R로 어떻게 통합되는가?
R 함수와 모델은 새로운 계산된 필드를 만들어 R 엔진을 동적으로 호출하고 R로 값을 전달함으로써 태블로어에서 사용할 수 있습니다. 이 결과는 다시 태블로어로 돌아가 시각화 목적으로 사용됩니다.
태블로어 데스크톱을 R로 설정
Rserve를 다운로드하고 설치합니다.
태블로어가 R 스크립트 함수를 연결하고 사용할 수 있게 Rserve 패키지를 다운로드하고 설치해야 합니다. R 콘솔에 다음 명령을 입력하세요:
install.packages(“Rserve”) library(Rserve) Rserve() / Rserve(args = ‘ — no-save’)
태블로어를 R 서버에 연결
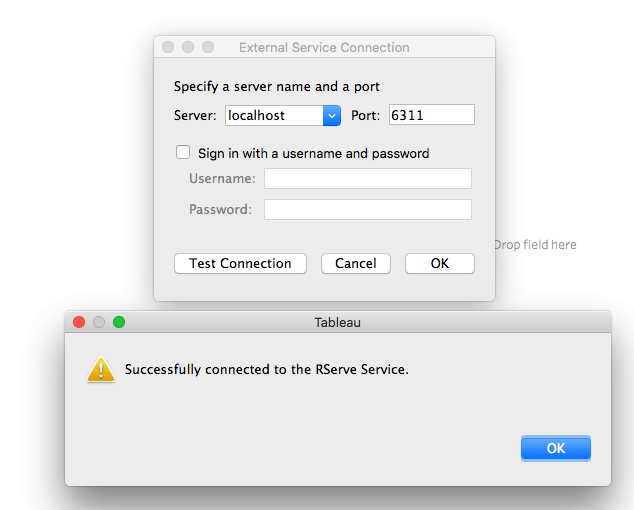
Rserve를 성공적으로 설치한 후, 태블로어 데스크톱을 여십시오. 다음과 같은 단계를 따릅니다.
-
도움말 > 설정 및 기본 설정 선택하고 외부 서비스 연결 관리를 가리킵니다.
-
서버 이름을 “Localhost” (또는 “127.0.0.1”)로 입력하고 포트를 “6311”로 설정합니다.
-
“연결 테스트” 버튼을 클릭합니다. 성공 메시지 프롬프트를 보게 됩니다. 닫으려면 OK를 클릭하세요.

Tableau 내에 R 스크립트를 시작하기
위에서 실제로 성공적으로 이 단계를 통과한 후, SCRIPT_* 함수를 사용하여 R 기능을 호출하는 새로운 계산 필드를 Tableau Desktop에 생성할 수 있을 것입니다.
让我们开始工作,看看我们如何可以使用 Tableau 的功能与 R 一起。我们将使用内建的 Sample Superstore 데이터셋来计算利润,一方面通过 R 脚本,另一方面通过 Tableau 的拖放功能。 之后我们比较这两个结果。
步驟
- 打开 Tableau 工作簿并连接到样本超级商店数据。
- 连接到 Rserve。一旦 Tableau Desktop 连接到 Rserve,它就可以通过계산 필드来调用 R 引擎。
-
이제 예상 수익을 denote하는 계산 필드를 만듭니다.
R 사용을 위해 사용 가능한 네 가지 함수가 있으며, 모두 单词 script로 시작합니다. 이 functions는 다음과 같습니다;
- SCRIPT_REAL: 실수 값을 결과로 돌려줍니다.
- SCRIPT_STR: 문자열을 돌려줍니다.
- SCRIPT_INT : 정수를 돌려줍니다.
- SCRIPT_BOOL: 布이uals를 돌려줍니다.
- 이 예제에서는 SCRIPT_REAL 함수를 사용하고자 합니다. Tableau에서 간단한 선형 회귀를 생성하겠습니다.
-
계산된 필드를 열고 다음 스크립트를 삽입하세요.
SCRIPT_REAL("fit <- lm(.arg1 ~ .arg2 + .arg3 + .arg4) fit$fitted ", SUM([Profit]), AVG([Sales]), AVG([Quantity]), AVG([Discount]))위의 스크립트는 R의 선형 회귀 모델과 관련이 있습니다. 이 모델은 하나의 종속 변수(arg1)와 세 개의 독립 변수(arg2, arg3, arg4)를 갖게 됩니다. 이 인수들은 단지 자리 표시자이며, 스크립트가 R로 전달되면 해당 인수들은 대응하는 태블로 열로 대체됩니다. 5. 각 변수에 해당하는 태블로 필드를 입력하세요. 여기서 종속 변수는 이익이므로
SUM(Profit)을 첫 번째 인수로 넣습니다. 마찬가지로, 나머지 세 인수에 각각평균 단가, 평균 주문 수량및평균 할인을 사용합니다. -
이러한 입력은 모델로 기대 이익 수준을 deter mining 하기 위해 모두 끌립니다. Tableau visualization 에서 이 계산을 사용할 준비가 되었습니다. ategor 을 行에 拖动하고
Profit를 열에 拖动하세요. 그 다음Expected Profit을 열로 拖动하세요. -
우리는 이제 모델을 분석하여 R에서 계산된 예상 이익이 실제 이익과 어떻게 비교되는지 볼 수 있습니다. 고객 세그먼트를 색상에 추가하여 더 깊이 분석할 수 있으며, 이제 스택형 막대 차트를 만들어 연도별 또는 분기별로 데이터를 분할할 수 있습니다.
실습
위의 모든 계산이 R을 사용하지 않고 Tableau에서 수행될 수 있다고 생각할 수도 있습니다. 그래서 왜 Tableau에서 Rserve를 다운로드하고 구성하며 스크립트를 작성해야 할까요? R은 널리 사용되는 알고리즘이 포함된 라이브러리를 쉽게 활용하여 예측할 수 있는 강력한 언어입니다. 단순한 R 스크립트를 호출하고 이를 Tableau의 시각화에 통합하여 비즈니스 예측을 할 수 있다면 얼마나 좋을까요?
Tableau와 Python
파이썬은 널리 사용되는 일반적인 프로그래밍 언어입니다. 파이썬은 통계 분석, 예측 모델링, 머신러닝을 수행하기 위한 많은 라이브러리를 제공합니다. Tableau와 파이썬을 연결하는 것은 예측 분석을 위한 最佳의 방법之一입니다. Tabpy는 같은 작업을 수행하기 위해 개발된 패키지입니다. Tableau가 파이썬의 힘을 이용하도록 하려면 TabPy 서버에 연결하여 파이썬 코드를 실시간으로 실행하고 시각화 형태로 결과를 표시할 수 있습니다.
Tableau는 어떻게 파이썬과 통합되는가?
TabPy를 Tableau와 함께 사용할 때, 우리는 파이썬으로 계산된 필드를 정의할 수 있으며, 시각화에서 직접 많은 수의機械学習 라이브러리의 힘을 이용할 수 있습니다.
Tableau Desktop와 파이썬 설정
`Tabpy`을 다운로드하고 설치합니다.
Tableau 워크북 내에서 파이썬 코드를 실행하려면 파이썬 서버가 필요합니다. TabPy 프레임워크는 이를 수행합니다. TabPy를 다음 링크에서Github에서 다운로드하세요. 그렇지 않으면 다음 단계를 따라가세요:
conda install -c anaconda tabpy-server
그런 다음 다운로드한 tabpy 서버가 있는 디렉토리로 cd하고 실행하세요.
python setp.py
Tableau와 TabPy 연결
다음 단계는 Tableau와 TabPy를 연결하는 것입니다. 도움말 > 설정과 성능 > 외부 서비스 연결 관리:를 선택하여 이를 수행할 수 있습니다.
연결을 테스트합니다. 모두 잘 되면 “성공적으로 연결되었습니다” 메시지가 표시됩니다.
Tableau에서 파이썬 스크립트 사용 시작
파이썬을 Tableau에 통합하는 기능은 매우 유용합니다. 예를 들어 감정 분석 문제를 생각해 보세요. 이는 머신 러닝 커뮤니티에서 공통적인 문제이며 다양한 머신 러닝 알고리즘을 사용하여 수행할 수 있습니다. 그러나 Tableau와 파이썬의 결합을 사용하면 같은 작업을 몇 줄의 파이썬 코드로 수행할 수 있습니다. 그 결과는 Tableau로 시각화되어 더 깊이 있는 인사이트를 얻을 수 있습니다. 예제를 통해 이를 살펴봅시다(TabPy를 사용하여 Tableau에서 파이썬의 능력을 활용하기)
Tabpy로 감정 분석
우리는 모바일 리뷰 데이터셋을 사용할 것입니다. 데이터셋은 여기에서 다운로드할 수 있습니다.
방법:
- Tableau Desktop에 데이터셋을 가져오기
- Tabpy에 연결합니다. Tableau Desktop가
Tabpy에 연결되면 계산된 필드를 통해 파이썬 엔진을 호출할 수 있습니다. -
우리는 이제 다음과 같이
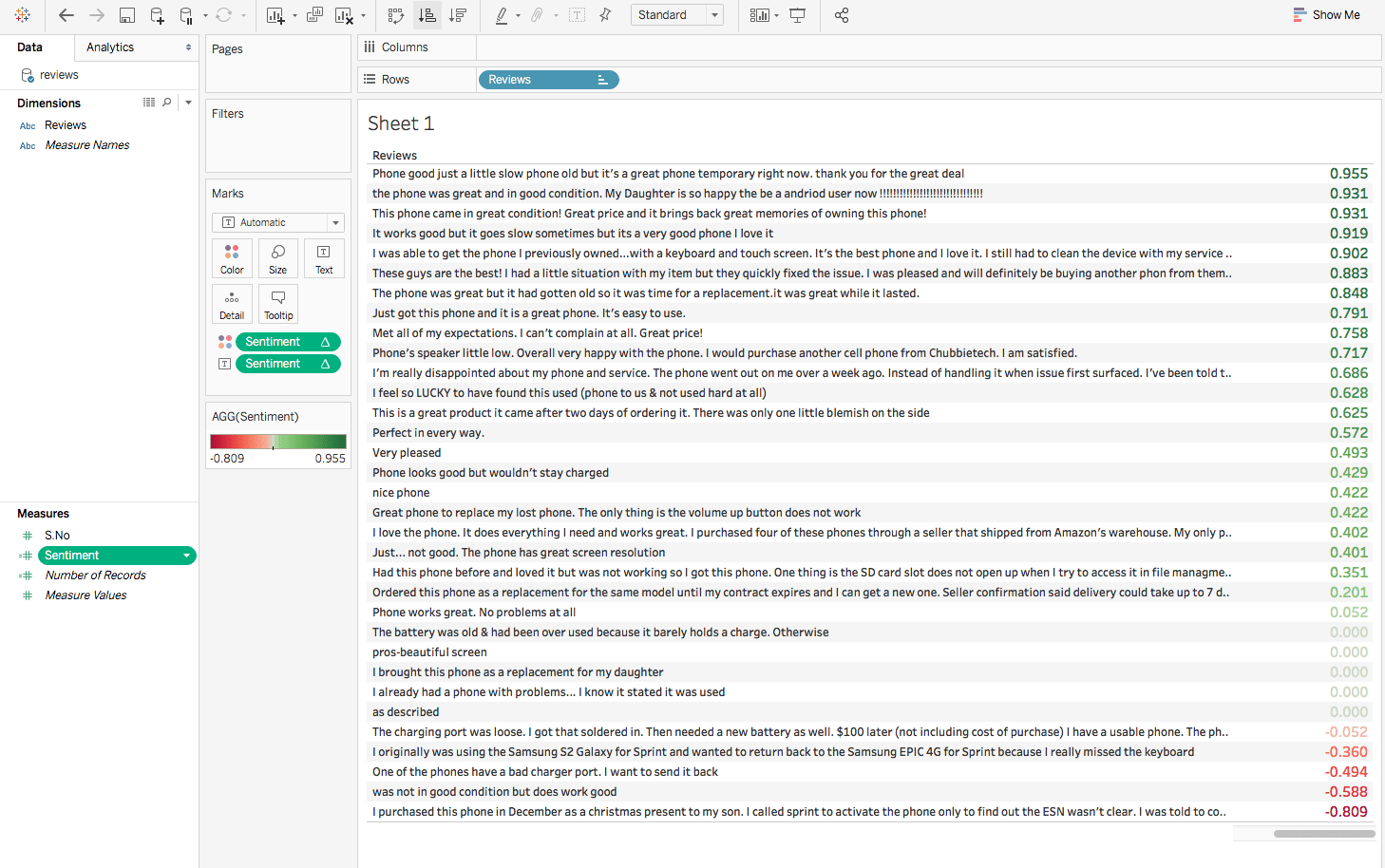
감성이라는 계산된 필드를 생성할 것입니다: `SCRIPT_REAL("from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer vs = [] analyzer = SentimentIntensityAnalyzer() for i in range(0,len(_arg1)): a = analyzer.polarity_scores(_arg1[i])['compound'] vs.append(a) return vs",ATTR([Reviews]))"우리는
VADER 감성 분석도구를 사용하고 있습니다. 이는 사전과 규칙 기반의 감성 분석 도구로 소셜 미디어에서 표현된 감성에 특별히 적합합니다. 이 도구를 사용하려면 먼저 설치해야 합니다. 자세한 내용은 그들의 깃허브 페이지를 참고하세요. -
이제
리뷰를 로우로,감성을 텍스트와 색상 마크 카드로 끌어다 놓으세요. 마법 같은 일이 벌어지게 됩니다. 리뷰의 감성 분석을 어렵지 않게 받아올 수 있습니다. 또한 결과를 시각화하는 것도 매우 쉽습니다. 긍정적인 리뷰는 초록색으로 증가하는 순서대로, 부정적인 리뷰는 빨간색입니다.
위의 예제는 Tableau가 Python과 통합되어 가져오는 힘을 명확하게 보여줍니다. Sentiment 得分을 이용하여 자세한 정보를 시도할 수 있습니다. 例如, 사업자이면 负面情绪를 過濾하고 이를 이유로 meditation 할 수 있습니다. 또한 积极评价를 過濾하여 고객이 행복하게 만들 수 있는 제품에 대한 아이디어를 얻을 수 있습니다.
Tableau와 SQL Server
Microsoft SQL Server 데이터에 隐藏的 价值가 있으며, 표준 보고서와 複雑한 사업 지능 도구 아래에 bury 되어 있습니다. Tableau는 SQL Server 데이터에 대한 Sophisticated 이미지 분석을 수행할 수 있는 任何人을 위한 洞見 제공을 통해 omnipresent 洞見을 제공합니다. Tableau를 SQL Server에 실시간으로 연결하여 조정되었고, 플랫폼 spe specific queries를 수행할 수 있으며, 데이터베이스에 부하를 제거하기 위해 Tableau의 분석 엔진에 데이터를 그대로 가져올 수 있습니다.
Tableau는 SQL Server에 대한 최적화된 실시간 connector를 제공하여 데이터와 직접 작업하면서 차트, 보고서, 대시보드를 생성할 수 있습니다. 我们的 분석을 深化하면 Tableau가 SQL Server에서 사용된 스키마를 인식합니다. 따라서 우리는 자신의 데이터를 조작할 필요가 없습니다.
Tableau Desktop과 SQL Server 데이터베이스를 연결하고 그 사용을 시각화 생성에 이용하는 예를 통해 예제를 통해 보죠.
Step:
- SQL Server에 로그인하십시오
- Tableau Desktop을 열고 Servers 하위에 MS SQL로 연결하십시오.
- 서버 이름을 열리는 대화 상자에 붙여넣고 OK를 클릭하여 Tableau가 SQL Server로 연결되게 합니다. 선택하고자 하는 데이터베이스를 지정합니다. 이 예에서는 salesDB을 지정합니다. 그 다음 TABLES의 목록에서 지정할 수 있습니다. 예를 들어, Sales Log입니다. 테이블이 Tableau 환경으로 導入되면 전체 데이터나 일부를 새로운 워크시트로 抽出할 수 있습니다. 抽出할 行의 개수를 지정할 수 있습니다.
- 새로운 워크시트에 MS SQLから抽出한 데이터가 있습니다. 여기서는 다른 Tableau 워크시트와 마찬가지로 작업할 수 있습니다.
Hands On:
SQL Server를 Tableau에 쉽게 연결하고 데이터를 그에 직접 導入할 수 있습니다. Tableau는 사용자들이 클릭으로 接続을 전환하여 larger dataset에 대해 in-memory queries를 적용할 수 있게 합니다.
8. 작업 저장
Tableau Desktop
Tableau 워크북을 로컬에 저장하려면, 파일을 선택한 다음 Save를 선택합니다. Save As 대화 상자에 워크북 파일 이름을 지정합니다. Tableau는 기본적으로 파일을 .twb 확장자로 저장합니다.
Tableau Public
Tableau Public에서는 모든 보기와 데이터가 공개되며, 인터넷上的 모든 사용자가 액세스할 수 있습니다. Server를 선택하고 Tableau Public를 지정하고 Save to Tableau Public에 들어가 인증 정보를 입력합니다.
Tableau Server
데이터가 confident 하고, 이야기가 전체 团队에 공유되어야 하는 경우, Tableau Server가 유용하게 나타낼 수 있습니다. Tableau Server로 이야기를 发布하려면, 툴 栏에 Select Server > Publish Workbook을 선택하거나 click Share를 클릭합니다. 그러나 먼저 계정을 만들어야 합니다.
결론
이렇게 하면 Tableau에서 좋은 的可视化을 만들 수 있습니다. 하지만, 여러분은 여기서 하는 것보다 각 阶段에서 더 많은 수정을 하는 것을 발견할 수 있습니다. 따라서 실험과 연습으로 Tableau가 훨씬 familier 하게 되며, 数据分析하고 보고서를 제시하는 것을 도울 수 있는 멋진 기능을 발휘하게 됩니다. 문의 또는 질문이 있으면 아래에 코멘트를 남겨주세요. 可视化 하시는 것을 기쁘게 합니다.
Source:
https://www.datacamp.com/tutorial/data-visualisation-tableau