













设置 Amazon Polly
现在,让我们动手设置 Amazon Polly!本部分概述了如何进行设置。
步骤 1:创建 AWS 账户
要使用Amazon Polly,您首先需要一个AWS账户。如果您还没有账户,请前往AWS注册页面并按照步骤创建。请确保提供有效的计费信息,因为AWS服务(包括Polly)基于使用量计费。
权限的IAM设置
我建议设置一个具有必要权限来管理Amazon Polly资源的IAM(身份和访问管理)用户。分配AmazonPollyFullAccess策略以确保用户可以访问所有Polly功能。
第2步:导航到Amazon Polly
登录到AWS管理控制台后,在顶部的搜索栏中搜索Polly。
AWS控制台中的搜索菜单。
单击Amazon Polly服务以进入Polly界面。
使用Amazon Polly进行文字转语音
通常,开发人员使用Amazon Polly API将文本转语音功能直接集成到他们的应用程序中。但是,您也可以使用AWS Polly界面快速尝试不同的语音和设置,而无需编写代码。要做到这一点,请在 Polly Polly界面中单击“尝试”按钮。该按钮允许您从AWS控制台尝试不同的文本输入、语音类型和输出格式,这样您可以在以编程方式实现之前轻松探索Polly的功能。
基本文本转语音转换
要执行基本的文本转语音转换,请在输入框中输入类似于“你好,欢迎来到Amazon Polly!”的句子。您还可以选择引擎类型(例如生成式、长篇、神经或标准)、语言和语音。单击听立即听取输出或单击下载将其下载为.mp3文件。
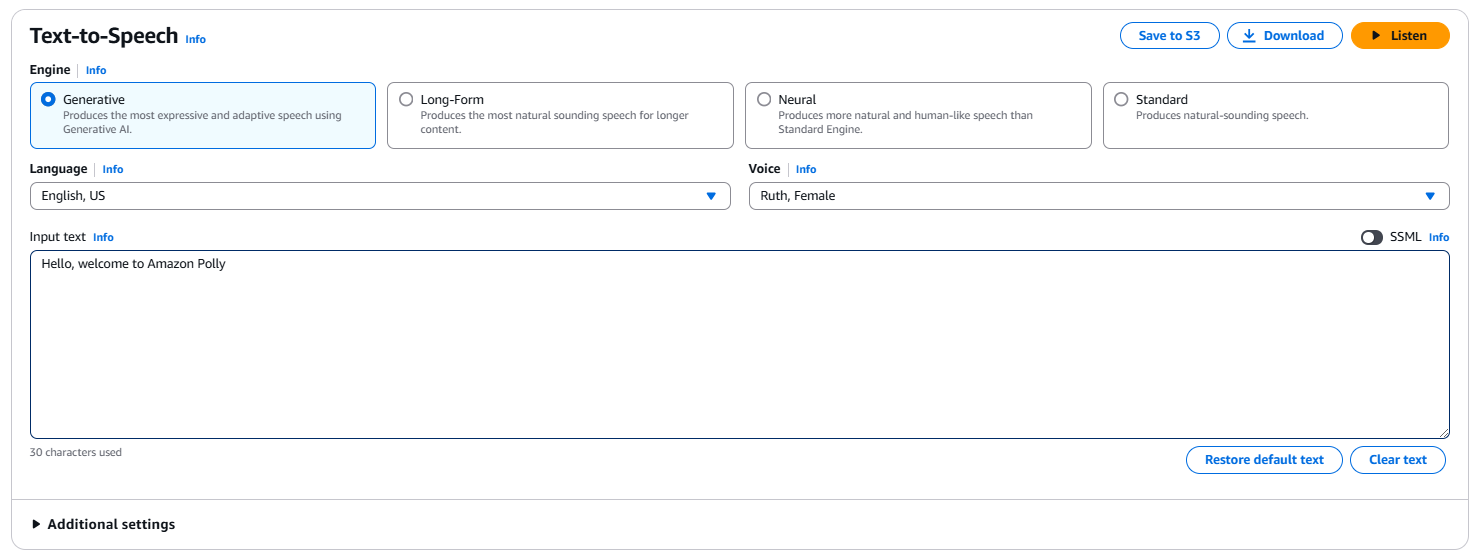
AWS控制台中的Amazon Polly界面。
为文本转语音设置AWS SDK
您需要设置AWS SDK以将Amazon Polly集成到您的应用程序中。这样您就可以直接从您的代码与Amazon Polly进行交互,实现更多动态和可定制的文本转语音功能。
在本教程中,我们将使用Python SDK(boto3)。通过pip安装boto3
pip install boto3
然后,使用AWS CLI配置您的AWS凭证:
aws configure
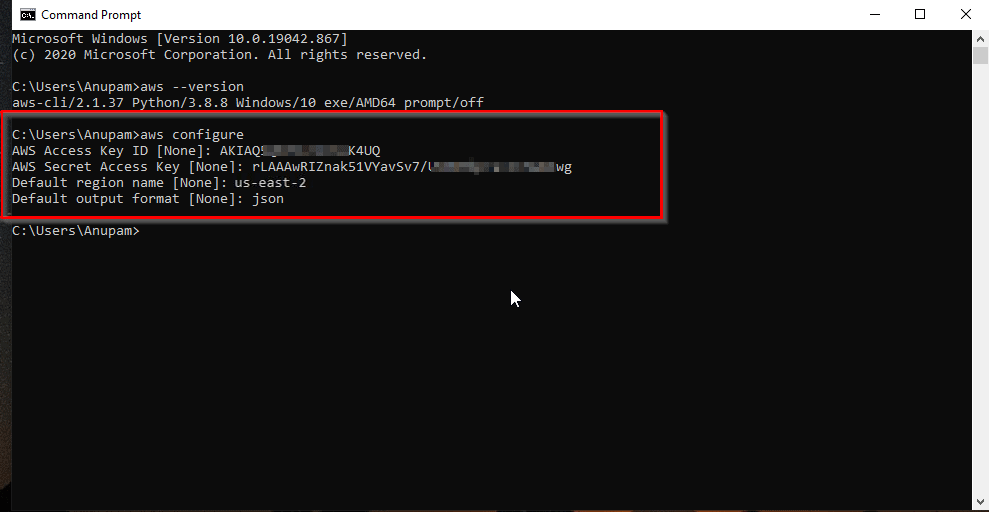
在CLI上使用aws configure命令。
通过SDK生成语音
以下是一个简单的Python脚本,使用Amazon Polly将文本转换为语音:
import boto3 polly = boto3.client('polly') response = polly.synthesize_speech( Text='Hello, this is a test of Amazon Polly.', OutputFormat='mp3', VoiceId='Joanna' ) with open('speech.mp3', 'wb') as file: file.write(response['AudioStream'].read())
此脚本从文本生成语音并将其保存为mp3文件。
Amazon Polly的高级功能
尽管Amazon Polly以其基本的文本转语音功能而闻名,但它还提供了一系列高级功能,使开发人员能够创建更复杂和交互式的语音体验。
使用 SSML(语音合成标记语言)
SSML(语音合成标记语言)允许开发人员控制各种语音方面,如音调、速率、音量和重音,使音频输出更具表现力和自然。
使用 SSML 标记,您可以添加停顿,调整说话风格,甚至逐字拼写首字母缩写。这种灵活性特别适用于像讲故事、电子学习平台和客户服务应用等场景,在这些场景中,语调和交付风格对用户参与度产生重大影响。
例如,您可以强调某些词以传达重要性,或者调整说话速率以确保清晰度,用于说明内容。
以下是如何在 Polly SDK 中使用 SSML:
response = polly.synthesize_speech( Text="<speak><emphasis level='strong'>Important</emphasis> message!</speak>", TextType='ssml', OutputFormat='mp3', VoiceId='Matthew' ) # 保存音频文件 with open('speech_ssml.mp3', 'wb') as file: file.write(response['AudioStream'].read())
这个例子强调了单词“重要”在口头信息中的突出显示,增强了对听众的情感影响。SSML还支持高级功能,如音素发音、低语音、添加音效,让开发者完全控制语音体验。
用于配合口型同步的语音标记
语音标记提供了与时间对齐的元数据,使开发者能够将语音与动画、文本高亮显示或角色的口型动作同步。
这个功能对于互动应用特别有价值,比如虚拟角色、教育游戏或卡拉OK风格的文本高亮显示。
通过在语音合成中请求语音标记,您可以获得每个单词或句子的详细定时信息,从而创建动态、同步的多媒体体验。
例如,您可以使角色的嘴部动作与口语同步或在实时朗读时突出显示文本。以下是请求语音标记的方法:
response = polly.synthesize_speech( Text='Hello, world!', OutputFormat='json', VoiceId='Emma', SpeechMarkTypes=['word'] ) # 将语音标记保存到 JSON 文件中 with open('speech_marks.json', 'wb') as file: file.write(response['AudioStream'].read())
输出 JSON:
{"time":6,"type":"word","start":0,"end":5,"value":"Hello"} {"time":714,"type":"word","start":7,"end":12,"value":"world"}
上述示例请求每个单词的语音标记,返回带有时间戳和文本数据的 JSON 对象。开发人员可以利用这些信息逐帧同步动画,使音视频体验更具吸引力和真实感。
使用 Amazon Polly 进行实时流式传输
对于语音助手、实时评论或交互式聊天机器人等实时应用,Amazon Polly 支持使用 WebSocket 协议或支持 HLS(HTTP Live Streaming)的媒体播放器进行流式传输。
这使应用程序能够在合成音频的同时开始播放,减少延迟,创造更具响应性的用户体验。实时流式传输非常适用于对即时性要求很高的场景,比如实时客户支持或对话式人工智能。
开发人员可以利用这一功能构建语音激活设备、新闻阅读器或根据用户实时输入做出响应的互动式故事应用。
管理亚马逊 Polly 资源
有效管理亚马逊 Polly 资源对于优化性能、成本和可伸缩性至关重要。通过策略性地存储语音文件并监控使用情况,您可以确保资源的高效利用,同时保持高质量的用户体验。
Amazon Polly与其他AWS服务无缝集成,例如用于存储的Amazon S3和用于成本监控的AWS计费仪表板,使资源管理变得更加简单。
创建和管理语音文件
Amazon Polly允许您将合成语音存储在Amazon S3中进行可扩展存储和方便检索。这种方法特别适用于具有重复音频需求的应用程序,例如电子学习平台、有声书或客户支持机器人,在这些应用中您可以重复使用音频文件,而不是每次都合成语音。
通过在S3中存储频繁使用的语音输出,您可以通过直接从云端提供缓存的音频文件来降低成本并提高性能。
s3 = boto3.client('s3') s3.upload_file('speech.mp3', 'your-bucket-name', 'speech.mp3')
监控使用情况和成本
利用AWS计费和成本管理仪表板有效监控使用情况和成本。该仪表板提供详细的成本分解、使用报告,并能够设置预算和警报,以避免意外收费。
在使用神经语音时,监控成本尤为重要,因为其比标准语音更昂贵。您还可以跟踪使用指标,如合成字符数量和API调用频率,这有助于优化资源利用率。
AWS成本仪表板示例。
使用Amazon Polly的最佳实践
在使用Amazon Polly时,采用最佳实践可确保最佳性能、成本效率和用户体验。以下是一些关键指南:
选择合适的语音
选择合适的语音取决于应用程序的目的和目标受众。Amazon Polly提供各种语音,包括标准语音和神经语音,每种语音都具有独特的音调和特点。
- 神经语音提供更自然和富有表现力的声音,但价格较高。因此,它们非常适合需要高情感参与度的应用,如有声读物或讲故事。
- 标准语音为客服支持聊天机器人等基于实用性的应用提供了经济高效的解决方案。通过用户反馈测试不同的语音有助于选择最适合您应用需求的语音。
优化语音输出
通过调整音高、速率和音量参数利用SSML(语音合成标记语言)来增强语音质量。您可以通过微调这些设置创造更具动态和吸引力的音频体验。
例如,减慢语速可提高指导内容的清晰度,而强调关键短语则有助于讲故事。尝试不同的SSML标记可以帮助您实现最自然的语音效果。
降低成本
在使用Amazon Polly时,应考虑管理语音生成的频率,将经常使用的音频文件存储在S3中以便重复使用,以优化成本。这种方法可以减少重复的API调用并降低合成成本。
此外,战略性地使用标准和神经语音的混合可以平衡成本和质量。
例如,仅在欢迎消息等关键接触点使用神经语音,而标准语音处理信息内容。在AWS计费仪表板中设置使用限制和成本警报有助于维持预算控制,避免意外费用。
结论
Amazon Polly是一个强大的文本转语音服务,利用先进的深度学习技术将文本转换为逼真的语音,增强用户体验和可访问性。
在本教程中,我们探讨了Amazon Polly的基本特性,从设置AWS SDK到通过编程生成语音。我们还涵盖了高级功能,如使用SSML进行定制语音输出,利用语音标记进行嘴唇同步和动画,以及实现动态语音应用的实时流式传输。
将Amazon Polly集成到您的应用程序中,可以创建面向全球受众的高度互动和个性化语音体验。无论您是构建虚拟助手、有声读物、教育平台还是辅助工具,Amazon Polly都提供了灵活性、可扩展性和高级功能,帮助您实现创意。
如果您是AWS的新手,想要加强您的云计算技能,请考虑探索以下相关课程:
- AWS概念 – 学习AWS云计算背后的基本概念。
- AWS云技术与服务 – 亲身体验关键AWS服务及其实际应用。
- AWS安全和成本管理 – 了解保护AWS资源和优化成本的最佳实践。
- AWS云从业者认证培训 – 通过结构化学习路径准备AWS云从业者CLF-C02考试。