













Configuración de Amazon Polly
¡Ahora, pongámonos manos a la obra y configuremos Amazon Polly! Esta sección proporciona una descripción general de cómo hacerlo.
Paso 1: Creando una cuenta de AWS
Para usar Amazon Polly, primero necesitas una cuenta de AWS. Si aún no tienes una, ve a la página de registro en AWS y sigue los pasos para crearla. Asegúrate de proporcionar información de facturación válida, ya que los servicios de AWS, incluido Polly, se facturan según el uso.
Configuración de IAM para permisos
Te recomiendo configurar un usuario de IAM (Identidad y Acceso Administrado) con los permisos necesarios para administrar los recursos de Amazon Polly. Asigna la política AmazonPollyFullAccess para asegurar que el usuario pueda acceder a todas las funciones de Polly.
Paso 2: Navegar a Amazon Polly
Después de iniciar sesión en la Consola de Administración de AWS, busca Polly en la barra de búsqueda en la parte superior.
El menú de búsqueda en la consola de AWS.
Haz clic en el servicio de Amazon Polly para acceder a la interfaz de Polly.
Uso de Amazon Polly para Texto a Voz
Normalmente, los desarrolladores utilizan la API de Amazon Polly para integrar funcionalidades de texto a voz directamente en sus aplicaciones. Sin embargo, también puedes usar la interfaz de AWS Polly para probar rápidamente diferentes voces y configuraciones sin necesidad de escribir código. Para hacerlo, haz clic en el botón Polly. Este botón te permite experimentar con diferentes entradas de texto, tipos de voz y formatos de salida desde la Consola de AWS, facilitando la exploración de las capacidades de Polly antes de implementarlas programáticamente.
Conversión básica de texto a voz
Para realizar una conversión básica de texto a voz, ingresa una oración como “¡Hola, bienvenido a Amazon Polly!” en el cuadro de entrada. También puedes elegir el tipo de motor (por ejemplo, generativo, de larga duración, neuronal o estándar), idioma y voz. Haz clic en Escuchar para escuchar de inmediato la salida o haz clic en Descargar para descargarlo como un archivo .mp3.
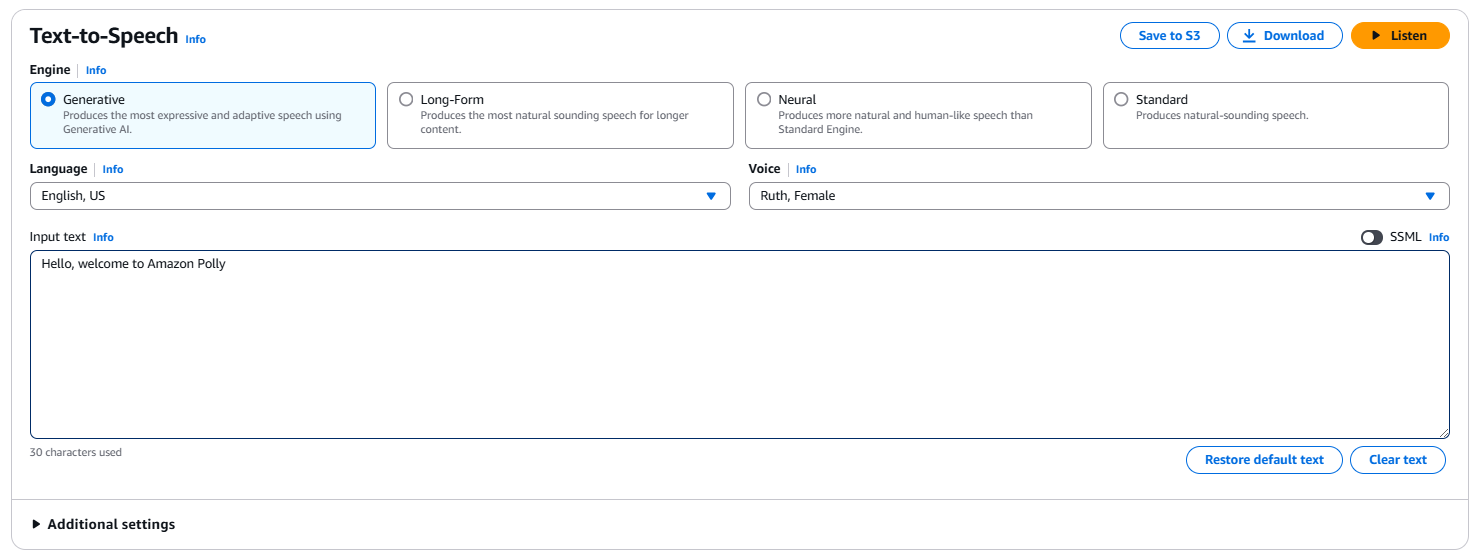
La interfaz de Amazon Polly en la consola de AWS.
Configuración del SDK de AWS para texto a voz
Necesitas configurar el SDK de AWS para integrar Amazon Polly en tus aplicaciones de forma programática. Esto te permite interactuar con Amazon Polly directamente desde tu código, lo que habilita funcionalidades de texto a voz más dinámicas y personalizables.
En este tutorial, usaremos el SDK de Python (boto3). Instala boto3 a través de pip:
pip install boto3
Luego, configura tus credenciales de AWS utilizando el AWS CLI:
aws configure
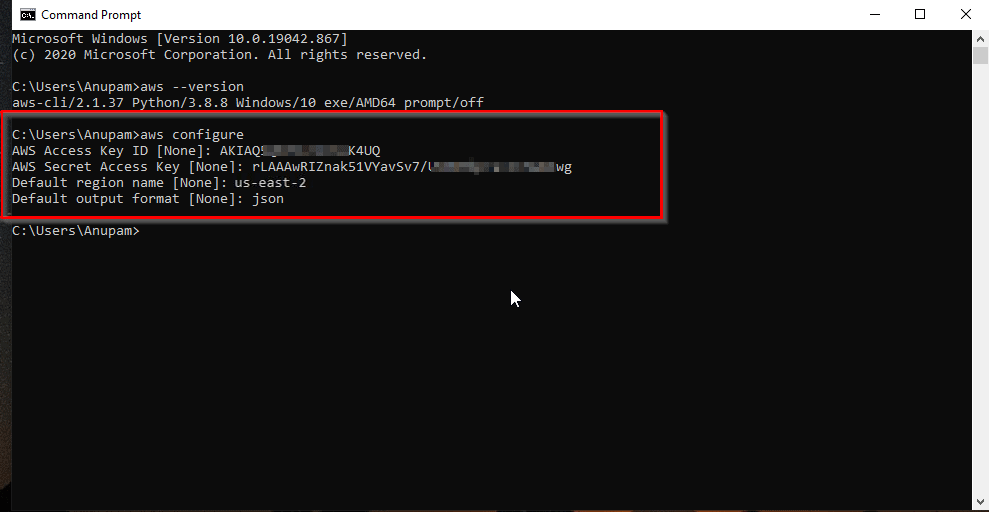
El comando aws configure en la CLI.
Generando voz a través del SDK
Aquí tienes un script simple en Python para convertir texto a voz usando Amazon Polly:
import boto3 polly = boto3.client('polly') response = polly.synthesize_speech( Text='Hello, this is a test of Amazon Polly.', OutputFormat='mp3', VoiceId='Joanna' ) with open('speech.mp3', 'wb') as file: file.write(response['AudioStream'].read())
Este script genera voz a partir de texto y lo guarda como un archivo mp3.
Funciones Avanzadas de Amazon Polly
Aunque Amazon Polly es ampliamente conocido por su funcionalidad básica de texto a voz, también ofrece una variedad de funciones avanzadas que permiten a los desarrolladores crear experiencias de voz más sofisticadas e interactivas.
Usando SSML (Speech Synthesis Markup Language)
SSML (Speech Synthesis Markup Language) permite a los desarrolladores controlar varios aspectos del habla, como el tono, la velocidad, el volumen y la énfasis, haciendo que la salida de audio sea más expresiva y natural.
Usando etiquetas SSML, puedes agregar pausas, ajustar estilos de habla e incluso deletrear acrónimos letra por letra. Esta flexibilidad es particularmente útil para escenarios como narración de historias, plataformas de aprendizaje electrónico y aplicaciones de servicio al cliente, donde el tono y el estilo de entrega impactan significativamente en la participación del usuario.
Por ejemplo, puedes enfatizar ciertas palabras para transmitir importancia o alterar la velocidad de habla para contenido instructivo y garantizar la claridad.
Aquí te mostramos cómo usar SSML con el SDK de Polly:
response = polly.synthesize_speech( Text="<speak><emphasis level='strong'>Important</emphasis> message!</speak>", TextType='ssml', OutputFormat='mp3', VoiceId='Matthew' ) # Guardar el archivo de audio with open('speech_ssml.mp3', 'wb') as file: file.write(response['AudioStream'].read())
Este ejemplo enfatiza la palabra “Importante” para hacerla destacar en el mensaje hablado, realzando el impacto emocional en el oyente. SSML también admite funciones avanzadas como la pronunciación de fonemas, susurros y la adición de efectos de sonido, brindando a los desarrolladores un control total sobre la experiencia vocal.
Marcas de discurso para sincronización de labios
Las marcas de discurso proporcionan metadatos alineados en el tiempo, lo que permite a los desarrolladores sincronizar el habla con animaciones, resaltado de texto o movimientos de labios de personajes.
Esta función es especialmente valiosa para aplicaciones interactivas como personajes virtuales, juegos educativos o resaltado de texto al estilo karaoke.
Al solicitar marcas de discurso junto con la síntesis del habla, obtienes información detallada sobre el tiempo para cada palabra o oración, lo que te permite crear experiencias multimedia dinámicas y sincronizadas.
Por ejemplo, puedes animar los movimientos de la boca de un personaje sincronizados con las palabras habladas o resaltar texto en tiempo real a medida que se narra. Así es como se solicitan las marcas de habla:
response = polly.synthesize_speech( Text='Hello, world!', OutputFormat='json', VoiceId='Emma', SpeechMarkTypes=['word'] ) # Guardar las marcas de habla en un archivo JSON with open('speech_marks.json', 'wb') as file: file.write(response['AudioStream'].read())
JSON de salida:
{"time":6,"type":"word","start":0,"end":5,"value":"Hello"} {"time":714,"type":"word","start":7,"end":12,"value":"world"}
En el ejemplo anterior se solicitan las marcas de habla para cada palabra, devolviendo un objeto JSON con marcas de tiempo y datos de texto. Los desarrolladores pueden utilizar esta información para sincronizar animaciones cuadro por cuadro, haciendo que la experiencia audiovisual sea más atractiva y realista.
Streaming en tiempo real con Amazon Polly
Para aplicaciones en tiempo real como asistentes de voz, comentarios en vivo o chatbots interactivos, Amazon Polly admite streaming utilizando el protocolo WebSocket o reproductores multimedia que admiten HLS (HTTP Live Streaming).
Esto permite que las aplicaciones comiencen a reproducir audio mientras se está sintetizando, reduciendo la latencia y creando una experiencia de usuario más receptiva. La transmisión en tiempo real es ideal para escenarios donde la inmediatez es crucial, como el soporte al cliente en vivo o la inteligencia artificial conversacional.
Los desarrolladores pueden aprovechar esta función para construir dispositivos activados por voz, lectores de noticias o aplicaciones de narración interactiva que respondan a la entrada del usuario al instante.
Gestión de Recursos de Amazon Polly
La gestión efectiva de los recursos de Amazon Polly es crucial para optimizar el rendimiento, el costo y la escalabilidad. Al almacenar estratégicamente archivos de voz y monitorear el uso, se puede garantizar una utilización eficiente de los recursos manteniendo una experiencia de usuario de alta calidad.
Amazon Polly se integra perfectamente con otros servicios de AWS, como Amazon S3 para almacenamiento y el panel de control de facturación de AWS para monitoreo de costos, facilitando la gestión de recursos.
Creación y gestión de archivos de voz
Amazon Polly te permite almacenar voz sintetizada en Amazon S3 para un almacenamiento escalable y fácil recuperación. Este enfoque es especialmente útil para aplicaciones con requisitos de audio recurrentes, como plataformas de e-learning, audiolibros o bots de atención al cliente, donde puedes reutilizar archivos de audio en lugar de sintetizar voz cada vez.
Almacenando salidas de voz frecuentemente utilizadas en S3, puedes reducir costos y mejorar el rendimiento al servir archivos de audio en caché directamente desde la nube.
s3 = boto3.client('s3') s3.upload_file('speech.mp3', 'your-bucket-name', 'speech.mp3')
Monitoreo de uso y costos
Aproveche el Panel de control de facturación y costos de AWS para monitorear de manera eficiente el uso y los costos. Este panel proporciona desgloses detallados de costos, informes de uso y la capacidad de establecer presupuestos y alertas para evitar cargos inesperados.
Es especialmente importante monitorear los costos al usar voces neuronales, que son más costosas que las voces estándar. También puede realizar un seguimiento de métricas de uso como el número de caracteres sintetizados y la frecuencia de llamadas a la API, lo que puede ayudarlo a optimizar la utilización de recursos.
Ejemplo de un panel de costos de AWS.
Mejores prácticas para usar Amazon Polly
Al utilizar Amazon Polly, adoptar las mejores prácticas garantiza un rendimiento óptimo, eficiencia de costos y experiencia del usuario. Aquí hay algunas pautas clave:
Elegir la voz adecuada
Elegir la voz adecuada depende del propósito de la aplicación y del público objetivo. Amazon Polly ofrece una variedad de voces, incluidas voces estándar y voces neuronales, cada una con tonos y características únicas.
- Las voces neuronales proporcionan un sonido más natural y expresivo, pero son más costosas. Por lo tanto, son ideales para aplicaciones que requieren un alto compromiso emocional, como audiolibros o cuentacuentos.
- Las voces estándar ofrecen una solución rentable para aplicaciones basadas en utilidad, como chatbots de soporte al cliente. Probar diferentes voces con la retroalimentación de los usuarios ayuda a seleccionar la voz más adecuada para las necesidades de tu aplicación.
Optimización de la salida de voz
Aprovecha el SSML (Lenguaje de Marcado de Síntesis de Voz) para mejorar la calidad del habla ajustando los parámetros de tono, velocidad y volumen. Puedes crear una experiencia auditiva más dinámica y atractiva al perfeccionar estos ajustes.
Por ejemplo, ralentizar la velocidad de habla mejora la claridad para el contenido instructivo, mientras que enfatizar frases clave realza la narración. Experimentar con diferentes etiquetas SSML te ayuda a lograr un habla más natural.
Reducir costos
Estrategias como gestionar la frecuencia de generación de habla y almacenar archivos de audio utilizados con frecuencia en S3 para reutilización deben considerarse para optimizar costos al usar Amazon Polly. Este enfoque minimiza las llamadas repetitivas a la API y reduce los costos de síntesis.
Además, utilizar estratégicamente una combinación de voces estándar y neuronales puede equilibrar costos y calidad.
Por ejemplo, utilizar voces neurales solo para puntos críticos como mensajes de bienvenida, mientras que las voces estándar manejan contenido informativo. Establecer límites de uso y alertas de costos en el Panel de facturación de AWS ayuda a mantener el control del presupuesto y evitar gastos inesperados.
Conclusión
Amazon Polly es un potente servicio de texto a voz que aprovecha tecnologías avanzadas de aprendizaje profundo para convertir texto en un discurso realista, mejorando las experiencias de usuario y la accesibilidad.
En este tutorial, exploramos las características fundamentales de Amazon Polly, desde la configuración del SDK de AWS hasta la generación de voz de forma programática. También cubrimos capacidades avanzadas, como el uso de SSML para una salida de voz personalizada, aprovechando Marcas de voz para la sincronización de labios y animaciones, e implementando transmisión en tiempo real para aplicaciones de voz dinámicas.
Integrar Amazon Polly en tus aplicaciones te permite crear experiencias de voz altamente interactivas y personalizadas que satisfacen a una audiencia global. Ya sea que estés construyendo asistentes virtuales, audiolibros, plataformas educativas o herramientas de accesibilidad, Amazon Polly proporciona la flexibilidad, escalabilidad y características avanzadas necesarias para dar vida a tus ideas.
Si eres nuevo en AWS y deseas fortalecer tus habilidades en la nube, considera explorar estos cursos relacionados:
- Conceptos de AWS – Aprende los conceptos fundamentales detrás de la computación en la nube de AWS.
- Tecnología y Servicios en la Nube de AWS – Practica con los servicios clave de AWS y sus aplicaciones prácticas.
- Seguridad y Gestión de Costos en AWS – Comprende las mejores prácticas para asegurar los recursos de AWS y optimizar los costos.
- Ruta de Certificación de AWS Cloud Practitioner – Prepárate para el examen AWS Cloud Practitioner CLF-C02 con un camino de aprendizaje estructurado.