













Einrichten von Amazon Polly
Jetzt lassen Sie uns praktisch werden und Amazon Polly einrichten! Dieser Abschnitt bietet einen Überblick darüber, wie das gemacht wird.
Schritt 1: Erstellen eines AWS-Kontos
Um Amazon Polly zu verwenden, benötigen Sie zunächst ein AWS-Konto. Wenn Sie noch keines haben, gehen Sie zur AWS-Anmeldeseite und folgen Sie den Schritten zur Erstellung. Stellen Sie sicher, dass Sie gültige Abrechnungsinformationen angeben, da AWS-Dienste, einschließlich Polly, basierend auf der Nutzung abgerechnet werden.
IAM-Einrichtung für Berechtigungen
Ich empfehle, einen IAM (Identity and Access Management)-Benutzer mit den erforderlichen Berechtigungen einzurichten, um Amazon Polly-Ressourcen zu verwalten. Weisen Sie dem Benutzer die Richtlinie AmazonPollyFullAccess zu, um sicherzustellen, dass der Benutzer auf alle Polly-Funktionen zugreifen kann.
Schritt 2: Navigieren zu Amazon Polly
Nach dem Einloggen in die AWS Management Console suchen Sie nach Polly in der Suchleiste oben.
Das Suchmenü in der AWS-Konsole.
Klicken Sie auf den Amazon Polly-Dienst, um zur Polly-Benutzeroberfläche zu gelangen.
Die Verwendung von Amazon Polly für Text-to-Speech
Normalerweise verwenden Entwickler die Amazon Polly API, um die Text-in-Sprache-Funktionalität direkt in ihre Anwendungen zu integrieren. Sie können jedoch auch die AWS Polly-Schnittstelle verwenden, um schnell verschiedene Stimmen und Einstellungen auszuprobieren, ohne Code schreiben zu müssen. Klicken Sie dazu auf die Testen Polly-Schaltfläche in der Polly-Schnittstelle. Diese Schaltfläche ermöglicht es Ihnen, mit verschiedenen Texteingaben, Stimmtypen und Ausgabeformaten aus der AWS Console zu experimentieren, um die Fähigkeiten von Polly vor der programmatischen Implementierung zu erkunden.
Grundlegende Text-in-Sprache-Umwandlung
Für eine grundlegende Text-in-Sprache-Konvertierung geben Sie einen Satz wie „Hallo, willkommen bei Amazon Polly!“ in das Eingabefeld ein. Sie können auch den Motorentyp (z. B. Generativ, Langform, Neuronales oder Standard), die Sprache und die Stimme auswählen. Klicken Sie auf Anhören, um sofort die Ausgabe anzuhören, oder klicken Sie auf Herunterladen, um sie als .mp3-Datei herunterzuladen.
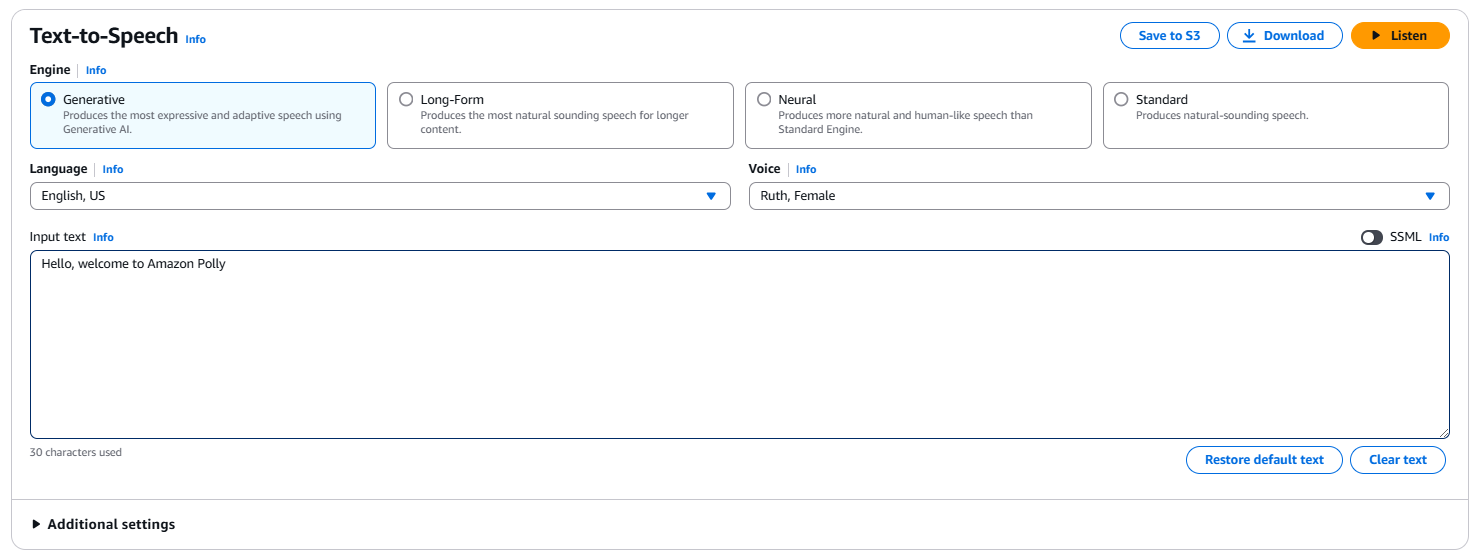
Die Amazon Polly-Benutzeroberfläche in der AWS-Konsole.
Einrichten des AWS SDK für Text-in-Sprache
Sie müssen das AWS SDK einrichten, um Amazon Polly programmgesteuert in Ihre Anwendungen zu integrieren. Dadurch können Sie direkt von Ihrem Code aus mit Amazon Polly interagieren und so dynamischere und anpassbare Text-in-Sprache-Funktionalitäten ermöglichen.
In diesem Tutorial verwenden wir das Python SDK (boto3). Installieren Sie boto3 über pip:
pip install boto3
Konfigurieren Sie dann Ihre AWS-Anmeldeinformationen mithilfe der AWS CLI:
aws configure
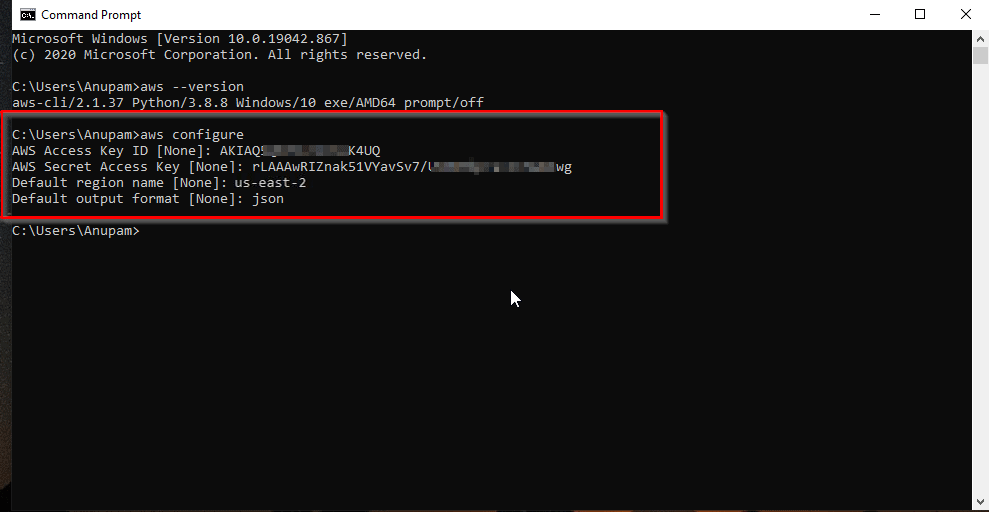
Der aws configure-Befehl auf der CLI.
Generierung von Sprache über das SDK
Hier ist ein einfaches Python-Skript zum Konvertieren von Text in Sprache mit Amazon Polly:
import boto3 polly = boto3.client('polly') response = polly.synthesize_speech( Text='Hello, this is a test of Amazon Polly.', OutputFormat='mp3', VoiceId='Joanna' ) with open('speech.mp3', 'wb') as file: file.write(response['AudioStream'].read())
Dieses Skript generiert Sprache aus Text und speichert sie als mp3-Datei.
Erweiterte Funktionen von Amazon Polly
Obwohl Amazon Polly weitgehend für seine grundlegende Text-in-Sprache-Funktionalität bekannt ist, bietet es auch eine Reihe von erweiterten Funktionen, die es Entwicklern ermöglichen, anspruchsvollere und interaktivere Spracherlebnisse zu schaffen.
Die Verwendung von SSML (Speech Synthesis Markup Language)
SSML (Speech Synthesis Markup Language) ermöglicht Entwicklern die Kontrolle über verschiedene Sprachaspekte wie Tonhöhe, Geschwindigkeit, Lautstärke und Betonung, wodurch die Audioausgabe ausdrucksvoller und natürlicher wird.
Mit SSML-Tags können Sie Pausen einfügen, Sprechstile anpassen und sogar Akronyme Buchstabe für Buchstabe buchstabieren. Diese Flexibilität ist besonders nützlich für Szenarien wie Geschichtenerzählen, E-Learning-Plattformen und Kundenservice-Anwendungen, bei denen der Ton und der Lieferstil das Nutzerengagement erheblich beeinflussen.
Zum Beispiel können Sie bestimmte Wörter betonen, um deren Wichtigkeit zu verdeutlichen, oder die Sprechgeschwindigkeit für Lehrinhalte ändern, um Klarheit zu gewährleisten.
So verwenden Sie SSML mit dem Polly SDK:
response = polly.synthesize_speech( Text="<speak><emphasis level='strong'>Important</emphasis> message!</speak>", TextType='ssml', OutputFormat='mp3', VoiceId='Matthew' ) # Speichern Sie die Audiodatei with open('speech_ssml.mp3', 'wb') as file: file.write(response['AudioStream'].read())
Dieses Beispiel betont das Wort „Wichtig“, um es in der gesprochenen Nachricht hervorzuheben und die emotionale Wirkung auf den Zuhörer zu verstärken. SSML unterstützt auch erweiterte Funktionen wie die Aussprache von Phonemen, Flüstern und das Hinzufügen von Soundeffekten, wodurch Entwickler die volle Kontrolle über das Klangerlebnis haben.
Sprachmarken für Lippen-Synchronisation
Sprachmarken liefern zeitlich abgestimmte Metadaten, die es Entwicklern ermöglichen, Sprache mit Animationen, Text-Hervorhebungen oder Lippenbewegungen von Charakteren zu synchronisieren.
Diese Funktion ist besonders wertvoll für interaktive Anwendungen wie virtuelle Charaktere, Lernspiele oder Text-Hervorhebungen im Karaoke-Stil.
Indem Sie Sprachmarken zusammen mit der Sprachsynthese anfordern, erhalten Sie detaillierte Zeitinformationen für jedes Wort oder jeden Satz, was es Ihnen ermöglicht, dynamische, synchronisierte Multimedia-Erlebnisse zu schaffen.
Zum Beispiel können Sie die Mundbewegungen eines Charakters synchron zu den gesprochenen Worten animieren oder Text in Echtzeit hervorheben, während er vorgelesen wird. So fordern Sie Sprechmarkierungen an:
response = polly.synthesize_speech( Text='Hello, world!', OutputFormat='json', VoiceId='Emma', SpeechMarkTypes=['word'] ) # Speichern Sie die Sprechmarkierungen in einer JSON-Datei with open('speech_marks.json', 'wb') as file: file.write(response['AudioStream'].read())
Ausgabe JSON:
{"time":6,"type":"word","start":0,"end":5,"value":"Hello"} {"time":714,"type":"word","start":7,"end":12,"value":"world"}
Im obigen Beispiel werden Sprechmarkierungen für jedes Wort angefordert, wobei ein JSON-Objekt mit Zeitstempeln und Textdaten zurückgegeben wird. Entwickler können diese Informationen dann verwenden, um Animationen framegenau zu synchronisieren und das audiovisuelle Erlebnis ansprechender und realistischer zu gestalten.
Echtzeit-Streaming mit Amazon Polly
Für Echtzeitanwendungen wie Sprachassistenten, Live-Kommentare oder interaktive Chatbots unterstützt Amazon Polly das Streaming über das WebSocket-Protokoll oder Mediaplayer, die HLS (HTTP Live Streaming) unterstützen.
Dies ermöglicht es Anwendungen, Audio abzuspielen, während es synthetisiert wird, wodurch die Latenz reduziert und ein reaktionsschnelleres Benutzererlebnis geschaffen wird. Echtzeit-Streaming ist ideal für Szenarien, in denen Unmittelbarkeit entscheidend ist, wie z.B. Live-Kundensupport oder konversationale KI.
Entwickler können diese Funktion nutzen, um sprachgesteuerte Geräte, Nachrichtensprecher oder interaktive Storytelling-Anwendungen zu erstellen, die auf Benutzereingaben spontan reagieren.
Verwaltung von Amazon Polly-Ressourcen
Eine effektive Verwaltung der Amazon Polly-Ressourcen ist entscheidend für die Optimierung von Leistung, Kosten und Skalierbarkeit. Durch strategisches Speichern von Sprachdateien und Überwachung der Nutzung können Sie eine effiziente Ressourcennutzung sicherstellen und gleichzeitig ein qualitativ hochwertiges Benutzererlebnis bieten.
Amazon Polly integriert nahtlos mit anderen AWS-Diensten, wie Amazon S3 für Speicherung und dem AWS Billing Dashboard für Kostenüberwachung, was das Ressourcenmanagement erleichtert.
Erstellung und Verwaltung von Sprachdateien
Amazon Polly ermöglicht es Ihnen, synthetisierte Sprache in Amazon S3 für skalierbare Speicherung und einfache Abrufbarkeit zu speichern. Dieser Ansatz ist besonders nützlich für Anwendungen mit wiederkehrenden Audioanforderungen, wie E-Learning-Plattformen, Hörbücher oder Kundensupport-Bots, bei denen Sie Audiodateien wiederverwenden können, anstatt jedes Mal Sprache zu synthetisieren.
Indem Sie häufig verwendete Sprachausgaben in S3 speichern, können Sie Kosten reduzieren und die Leistung verbessern, indem Sie gecachte Audiodateien direkt aus der Cloud bereitstellen.
s3 = boto3.client('s3') s3.upload_file('speech.mp3', 'your-bucket-name', 'speech.mp3')
Überwachung von Nutzung und Kosten
Nutzen Sie das AWS Billing and Cost Management-Dashboard, um den Verbrauch und die Kosten effizient zu überwachen. Dieses Dashboard bietet detaillierte Kostenaufschlüsselungen, Nutzungsberichte und die Möglichkeit, Budgets und Warnmeldungen einzurichten, um unerwartete Gebühren zu vermeiden.
Die Überwachung der Kosten ist besonders wichtig beim Einsatz von neuronalen Stimmen, die teurer sind als Standardstimmen. Sie können auch Nutzungsmetriken wie die Anzahl der synthetisierten Zeichen und die Häufigkeit von API-Aufrufen verfolgen, um die Ressourcennutzung zu optimieren.
Beispiel eines AWS-Kostendashboards.
Best Practices für die Verwendung von Amazon Polly
Bei der Verwendung von Amazon Polly gewährleisten bewährte Verfahren optimale Leistung, Kosteneffizienz und Benutzererfahrung. Hier sind einige wichtige Richtlinien:
Auswahl der richtigen Stimme
Die Auswahl der richtigen Stimme hängt vom Zweck der Anwendung und der Zielgruppe ab. Amazon Polly bietet eine Vielzahl von Stimmen, darunter Standard- und neuronale Stimmen, jede mit einzigartigen Tonlagen und Merkmalen.
- Neuronale Stimmen bieten einen natürlicheren und ausdrucksstärkeren Klang, sind jedoch teurer. Daher eignen sie sich ideal für Anwendungen, die eine hohe emotionale Bindung erfordern, wie Hörbücher oder Geschichtenerzählen.
- Standardstimmen bieten eine kostengünstige Lösung für anwendungsbezogene Anwendungen wie Kundenbetreuungs-Chatbots. Das Testen verschiedener Stimmen mit Benutzerfeedback hilft dabei, die geeignetste Stimme für die Anforderungen Ihrer Anwendung auszuwählen.
Optimierung der Sprachausgabe
Nutzen Sie SSML (Speech Synthesis Markup Language), um die Sprachqualität durch Anpassung von Tonhöhe, Geschwindigkeit und Lautstärkeparametern zu verbessern. Sie können ein dynamischeres und ansprechenderes Klangerlebnis schaffen, indem Sie diese Einstellungen feinabstimmen.
Zum Beispiel verbessert eine Verlangsamung der Sprechgeschwindigkeit die Klarheit für instruktiven Inhalt, während die Hervorhebung von Schlüsselphrasen das Geschichtenerzählen unterstreicht. Durch Experimentieren mit verschiedenen SSML-Tags erreichen Sie die natürlichste Sprachausgabe.
Kostensenkung
Strategien wie die Verwaltung der Häufigkeit der Spracherzeugung und das Speichern häufig verwendeter Audiodateien in S3 zur Wiederverwendung sollten in Betracht gezogen werden, um die Kosten bei der Verwendung von Amazon Polly zu optimieren. Dieser Ansatz minimiert wiederholte API-Aufrufe und reduziert die Synthesekosten.
Zusätzlich kann die strategische Verwendung einer Mischung aus Standard- und neuronalen Stimmen Kosten und Qualität ausbalancieren.
Zum Beispiel verwenden Sie neuronale Stimmen nur für wichtige Berührungspunkte wie Begrüßungsnachrichten, während Standardstimmen Informationsinhalte verarbeiten. Die Einrichtung von Nutzungslimits und Kostenbenachrichtigungen im AWS Billing-Dashboard hilft, das Budget zu kontrollieren und unerwartete Ausgaben zu vermeiden.
Conclusion
Amazon Polly ist ein leistungsstarker Text-to-Speech-Service, der fortschrittliche Deep-Learning-Technologien nutzt, um Text in lebensechte Sprache umzuwandeln und damit Benutzererfahrungen und Zugänglichkeit zu verbessern.
In diesem Tutorial haben wir die grundlegenden Funktionen von Amazon Polly erkundet, vom Einrichten des AWS SDK bis zur programmgesteuerten Erzeugung von Sprache. Wir haben auch fortgeschrittene Funktionen behandelt, wie die Verwendung von SSML für individuelle Sprachausgabe, die Nutzung von Speech Marks für Lippenbewegungen und Animationen sowie die Implementierung von Echtzeit-Streaming für dynamische Sprachanwendungen.
Die Integration von Amazon Polly in Ihre Anwendungen ermöglicht es Ihnen, hochinteraktive und personalisierte Spracherlebnisse zu schaffen, die sich an ein globales Publikum richten. Egal, ob Sie virtuelle Assistenten, Hörbücher, Bildungsplattformen oder Barrierefreiheitswerkzeuge entwickeln, Amazon Polly bietet die Flexibilität, Skalierbarkeit und fortgeschrittenen Funktionen, die erforderlich sind, um Ihre Ideen zum Leben zu erwecken.
Wenn Sie neu bei AWS sind und Ihre Cloud-Fähigkeiten stärken möchten, sollten Sie in Betracht ziehen, diese verwandten Kurse zu erkunden:
- AWS-Konzepte – Lernen Sie die grundlegenden Konzepte hinter der AWS-Cloud-Computing kennen.
- AWS-Cloud-Technologie und -Dienste – Arbeiten Sie mit Schlüsseldiensten von AWS und deren praktischen Anwendungen.
- AWS-Sicherheit und Kostenmanagement – Verstehen Sie bewährte Verfahren zur Sicherung von AWS-Ressourcen und zur Optimierung von Kosten.
- AWS-Cloud-Praktiker-Zertifizierungspfad – Bereiten Sie sich mit einem strukturierten Lernpfad auf die AWS Cloud Practitioner CLF-C02-Prüfung vor.