













Configurer Amazon Polly
Maintenant, mettons-nous au travail et configurons Amazon Polly ! Cette section fournit un aperçu de la façon de procéder.
Étape 1 : Création d’un compte AWS
Pour utiliser Amazon Polly, vous avez d’abord besoin d’un compte AWS. Si vous n’en avez pas déjà, rendez-vous sur la page d’inscription AWS et suivez les étapes pour le créer. Assurez-vous de fournir des informations de facturation valides, car les services AWS, y compris Polly, sont facturés en fonction de l’utilisation.
Configuration IAM pour les autorisations
Je recommande de configurer un utilisateur IAM (Identité et gestion des accès) avec les autorisations nécessaires pour gérer les ressources Amazon Polly. Attribuez la politique AmazonPollyFullAccess pour garantir que l’utilisateur puisse accéder à toutes les fonctionnalités de Polly.
Étape 2 : Naviguer vers Amazon Polly
Après vous être connecté à la console de gestion AWS, recherchez Polly dans la barre de recherche en haut.
Le menu de recherche dans la console AWS.
Cliquez sur le service Amazon Polly pour accéder à l’interface Polly.
Utilisation d’Amazon Polly pour la conversion texte en parole
Normalement, les développeurs utilisent l’API Amazon Polly pour intégrer des fonctionnalités de synthèse vocale directement dans leurs applications. Cependant, vous pouvez également utiliser l’interface AWS Polly pour essayer rapidement différentes voix et paramètres sans écrire de code. Pour ce faire, cliquez sur le Essayer Polly bouton dans l’interface Polly. Ce bouton vous permet d’expérimenter avec diverses entrées de texte, types de voix et formats de sortie depuis la Console AWS, facilitant ainsi l’exploration des capacités de Polly avant de les implémenter par programmation.
Conversion de texte en parole de base
Pour effectuer une conversion de texte en discours de base, saisissez une phrase comme « Bonjour, bienvenue sur Amazon Polly ! » dans la case d’entrée. Vous pouvez également choisir le type de moteur (par exemple, Génératif, long-forme, neuronal ou standard), la langue et la voix. Cliquez sur Écouter pour écouter immédiatement la sortie ou sur Télécharger pour la télécharger sous forme d’un fichier .mp3.
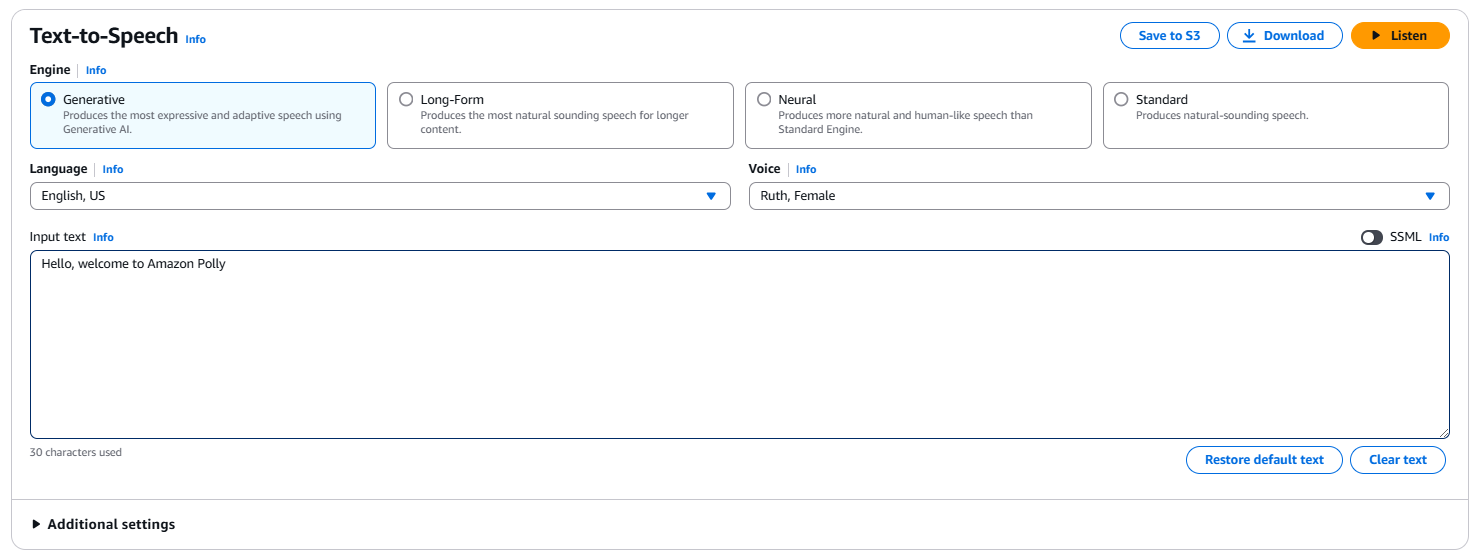
L’interface Amazon Polly dans la console AWS.
Configuration du SDK AWS pour la synthèse de texte-parole
Vous devez configurer le SDK AWS pour intégrer Amazon Polly dans vos applications de manière programmatique. Cela vous permet d’interagir directement avec Amazon Polly à partir de votre code, en activant des fonctionnalités de synthèse vocale de texte plus dynamiques et personnalisables.
Dans ce tutoriel, nous utiliserons le SDK Python (boto3). Installez boto3 via pip :
pip install boto3
Ensuite, configurez vos informations d’identification AWS en utilisant l’interface de ligne de commande AWS:
aws configure
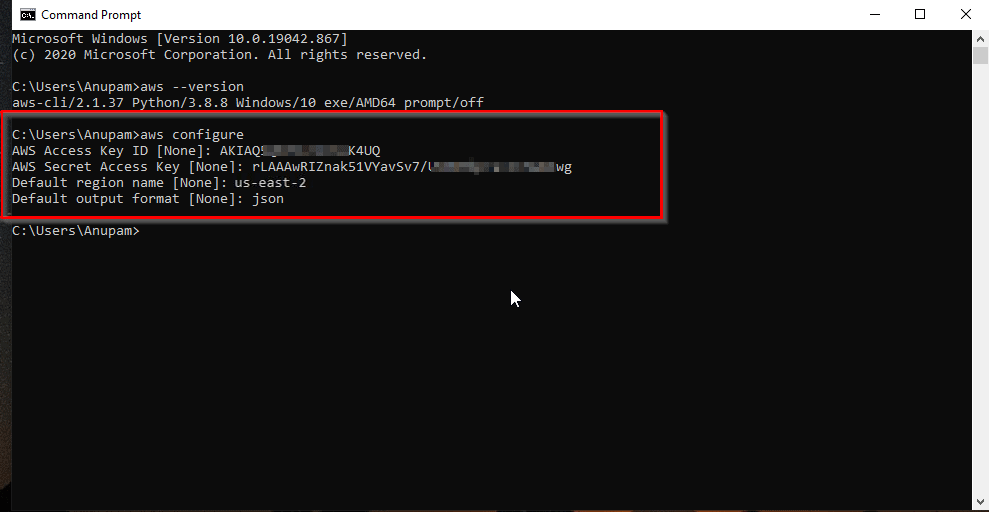
La commande aws configure sur le CLI.
Génération de la parole via le SDK
Voici un script Python simple pour convertir du texte en parole en utilisant Amazon Polly:
import boto3 polly = boto3.client('polly') response = polly.synthesize_speech( Text='Hello, this is a test of Amazon Polly.', OutputFormat='mp3', VoiceId='Joanna' ) with open('speech.mp3', 'wb') as file: file.write(response['AudioStream'].read())
Ce script génère de la parole à partir du texte et l’enregistre sous forme de fichier mp3.
Fonctionnalités avancées d’Amazon Polly
Alors qu’Amazon Polly est largement connu pour sa fonctionnalité de base de texte en parole, il offre également toute une gamme de fonctionnalités avancées qui permettent aux développeurs de créer des expériences vocales plus sophistiquées et interactives.
Utiliser SSML (Speech Synthesis Markup Language)
SSML (Speech Synthesis Markup Language) permet aux développeurs de contrôler divers aspects de la parole, tels que la hauteur, la vitesse, le volume et l’accentuation, rendant la sortie audio plus expressive et naturelle.
En utilisant des balises SSML, vous pouvez ajouter des pauses, ajuster les styles de discours, et même épeler des acronymes lettre par lettre. Cette flexibilité est particulièrement utile pour des scénarios comme le récit d’histoires, les plateformes d’apprentissage en ligne et les applications de service client, où le ton et le style de livraison ont un impact significatif sur l’engagement des utilisateurs.
Par exemple, vous pouvez accentuer certains mots pour transmettre leur importance ou modifier le rythme de la parole pour des contenus d’instruction afin d’assurer la clarté.
Voici comment utiliser SSML avec le SDK Polly :
response = polly.synthesize_speech( Text="<speak><emphasis level='strong'>Important</emphasis> message!</speak>", TextType='ssml', OutputFormat='mp3', VoiceId='Matthew' ) # Enregistrer le fichier audio with open('speech_ssml.mp3', 'wb') as file: file.write(response['AudioStream'].read())
Cet exemple met l’accent sur le mot « Important » pour le faire ressortir dans le message oral, renforçant l’impact émotionnel sur l’auditeur. SSML prend également en charge des fonctionnalités avancées telles que la prononciation phonétique, le chuchotement et l’ajout d’effets sonores, offrant aux développeurs un contrôle total sur l’expérience vocale.
Marks pour la synchronisation des lèvres
Les marques de discours fournissent des métadonnées synchronisées dans le temps, permettant aux développeurs de synchroniser la parole avec des animations, la mise en évidence du texte ou les mouvements des lèvres des personnages.
Cette fonctionnalité est particulièrement précieuse pour les applications interactives telles que les personnages virtuels, les jeux éducatifs ou la mise en évidence du texte de style karaoké.
En demandant des marques de discours en même temps que la synthèse vocale, vous obtenez des informations de synchronisation détaillées pour chaque mot ou phrase, vous permettant de créer des expériences multimédias dynamiques et synchronisées.
Par exemple, vous pouvez animer les mouvements de la bouche d’un personnage en synchronisation avec les mots prononcés ou mettre en évidence le texte en temps réel pendant qu’il est narré. Voici comment demander des marques de discours :
response = polly.synthesize_speech( Text='Hello, world!', OutputFormat='json', VoiceId='Emma', SpeechMarkTypes=['word'] ) # Enregistrer les marques de discours dans un fichier JSON with open('speech_marks.json', 'wb') as file: file.write(response['AudioStream'].read())
Sortie JSON :
{"time":6,"type":"word","start":0,"end":5,"value":"Hello"} {"time":714,"type":"word","start":7,"end":12,"value":"world"}
L’exemple ci-dessus demande des marques de discours pour chaque mot, retournant un objet JSON avec des horodatages et des données textuelles. Les développeurs peuvent alors utiliser ces informations pour synchroniser les animations image par image, rendant l’expérience audio-visuelle plus engageante et réaliste.
Diffusion en temps réel avec Amazon Polly
Pour des applications en temps réel comme les assistants vocaux, les commentaires en direct ou les chatbots interactifs, Amazon Polly prend en charge la diffusion en continu en utilisant le protocole WebSocket ou des lecteurs multimédias qui prennent en charge HLS (HTTP Live Streaming).
Cela permet aux applications de commencer à lire de l’audio au fur et à mesure qu’il est synthétisé, réduisant la latence et offrant une expérience utilisateur plus réactive. La diffusion en temps réel est idéale pour des scénarios où l’immédiateté est essentielle, comme le support client en direct ou l’IA conversationnelle.
Les développeurs peuvent exploiter cette fonctionnalité pour construire des appareils activés par la voix, des lecteurs de nouvelles ou des applications d’histoires interactives qui répondent aux entrées de l’utilisateur en temps réel.
Gestion des ressources Amazon Polly
Une gestion efficace des ressources Amazon Polly est cruciale pour optimiser les performances, les coûts et la scalabilité. En stockant stratégiquement les fichiers audio et en surveillant l’utilisation, vous pouvez garantir une utilisation efficace des ressources tout en maintenant une expérience utilisateur de haute qualité.
Amazon Polly s’intègre parfaitement avec d’autres services AWS, tels que Amazon S3 pour le stockage et le tableau de bord de facturation AWS pour le suivi des coûts, facilitant ainsi la gestion des ressources.
Création et gestion des fichiers audio
Amazon Polly vous permet de stocker la synthèse vocale dans Amazon S3 pour un stockage évolutif et une récupération facile. Cette approche est particulièrement utile pour les applications avec des besoins audio récurrents, tels que les plateformes d’apprentissage en ligne, les livres audio ou les chatbots de support client, où vous pouvez réutiliser des fichiers audio au lieu de synthétiser la parole à chaque fois.
En stockant les sorties vocales fréquemment utilisées dans S3, vous pouvez réduire les coûts et améliorer les performances en servant directement depuis le cloud des fichiers audio mis en cache.
s3 = boto3.client('s3') s3.upload_file('speech.mp3', 'your-bucket-name', 'speech.mp3')
Suivi de l’utilisation et des coûts
Exploitez le tableau de bord de facturation et de gestion des coûts AWS pour surveiller efficacement l’utilisation et les coûts. Ce tableau de bord fournit des détails sur la répartition des coûts, des rapports d’utilisation et la possibilité de configurer des budgets et des alertes pour éviter des frais inattendus.
La surveillance des coûts est particulièrement importante lors de l’utilisation de voix neuronales, qui sont plus coûteuses que les voix standard. Vous pouvez également suivre des indicateurs d’utilisation comme le nombre de caractères synthétisés et la fréquence des appels d’API, ce qui peut vous aider à optimiser l’utilisation des ressources.
Exemple d’un tableau de bord des coûts AWS.
Meilleures pratiques pour utiliser Amazon Polly
Lors de l’utilisation d’Amazon Polly, adopter les meilleures pratiques garantit des performances optimales, une efficacité des coûts et une expérience utilisateur agréable. Voici quelques directives clés :
Choisir la bonne voix
Le choix de la voix appropriée dépend de l’objectif de l’application et du public cible. Amazon Polly propose une variété de voix, y compris des voix standard et neuronales, chacune ayant des tonalités et des caractéristiques uniques.
- Les voix neuronales offrent un son plus naturel et expressif mais sont plus coûteuses. Par conséquent, elles sont idéales pour les applications nécessitant un fort engagement émotionnel, comme les livres audio ou la narration d’histoires.
- Les voix standard offrent une solution économique pour les applications utilitaires comme les chatbots de support client. Tester différentes voix avec des retours d’utilisateurs aide à sélectionner la voix la plus adaptée aux besoins de votre application.
Optimiser la sortie vocale
Exploitez le SSML (Speech Synthesis Markup Language) pour améliorer la qualité de la parole en ajustant les paramètres de hauteur, de débit et de volume. Vous pouvez créer une expérience audio plus dynamique et engageante en affinant ces réglages.
Par exemple, ralentir le débit de parole améliore la clarté du contenu pédagogique tandis que mettre en valeur les phrases clés renforce le récit. Expérimenter avec différents balises SSML vous aide à obtenir une parole qui sonne de manière plus naturelle.
Réduction des coûts
Des stratégies telles que la gestion de la fréquence de génération de la parole et le stockage des fichiers audio fréquemment utilisés dans S3 pour réutilisation devraient être envisagées pour optimiser les coûts lors de l’utilisation d’Amazon Polly. Cette approche réduit les appels API répétitifs et diminue les coûts de synthèse.
De plus, l’utilisation stratégique d’un mélange de voix standard et neurales peut équilibrer coût et qualité.
Par exemple, n’utilisez des voix neurales que pour des points de contact critiques tels que les messages de bienvenue, tandis que des voix standard gèrent le contenu informatif. La définition des limites d’utilisation et des alertes de coût dans le tableau de bord de facturation AWS permet de maintenir le contrôle du budget et d’éviter les dépenses inattendues.
Conclusion
Amazon Polly est un puissant service de synthèse vocale qui exploite des technologies avancées d’apprentissage profond pour convertir du texte en discours réaliste, améliorant ainsi les expériences utilisateur et l’accessibilité.
Tout au long de ce tutoriel, nous avons exploré les fonctionnalités fondamentales d’Amazon Polly, de la configuration du SDK AWS à la génération de discours de manière programmatique. Nous avons également abordé des capacités avancées, telles que l’utilisation de SSML pour une sortie vocale personnalisée, l’exploitation des Speech Marks pour la synchronisation labiale et les animations, ainsi que la mise en œuvre du streaming en temps réel pour des applications vocales dynamiques.
Intégrer Amazon Polly dans vos applications vous permet de créer des expériences vocales hautement interactives et personnalisées qui répondent à un public mondial. Que vous construisiez des assistants virtuels, des livres audio, des plateformes éducatives ou des outils d’accessibilité, Amazon Polly offre la flexibilité, la scalabilité et les fonctionnalités avancées nécessaires pour donner vie à vos idées.
Si vous débutez avec AWS et souhaitez renforcer vos compétences cloud, envisagez d’explorer ces cours connexes :
- Concepts AWS – Apprenez les concepts fondamentaux derrière le cloud computing AWS.
- Technologie et services cloud AWS – Mettez-vous à l’épreuve avec les principaux services AWS et leurs applications pratiques.
- Sécurité et gestion des coûts AWS – Comprenez les meilleures pratiques pour sécuriser les ressources AWS et optimiser les coûts.
- Piste de certification AWS Cloud Practitioner – Préparez-vous à l’examen CLF-C02 AWS Cloud Practitioner avec un parcours d’apprentissage structuré.