













2024年12月11日,OpenAI服务经历了重大的停机事件,原因是由于新的遥测服务部署引发的问题。这一事件影响了API、ChatGPT和Sora服务,导致服务中断持续了数小时。作为一个旨在提供准确高效AI解决方案的公司,OpenAI已经分享了一份详细的事后报告,以透明地讨论出了什么问题,以及他们计划如何防止类似事件在未来发生。
在本文中,我将描述该事件的技术方面,分解根本原因,并探讨开发人员和管理分布式系统的组织可以从这次事件中得到的关键教训。
事件时间线
以下是2024年12月11日事件的发展快照:
| Time (PST) | Event |
|---|---|
| 下午3:16 | 开始出现轻微客户影响;观察到服务降级 |
| 下午3:27 | 工程师开始将流量从受影响的集群中重定向 |
| 下午3:40 | 记录到最大的客户影响;所有服务出现重大中断 |
| 下午4:36 | 第一个Kubernetes集群开始恢复 |
| 下午5:36 | API服务开始有显著恢复 |
| 下午5:45 | 观察到ChatGPT有显著恢复 |
| 晚上7:38 | 所有服务在所有集群中完全恢复 |
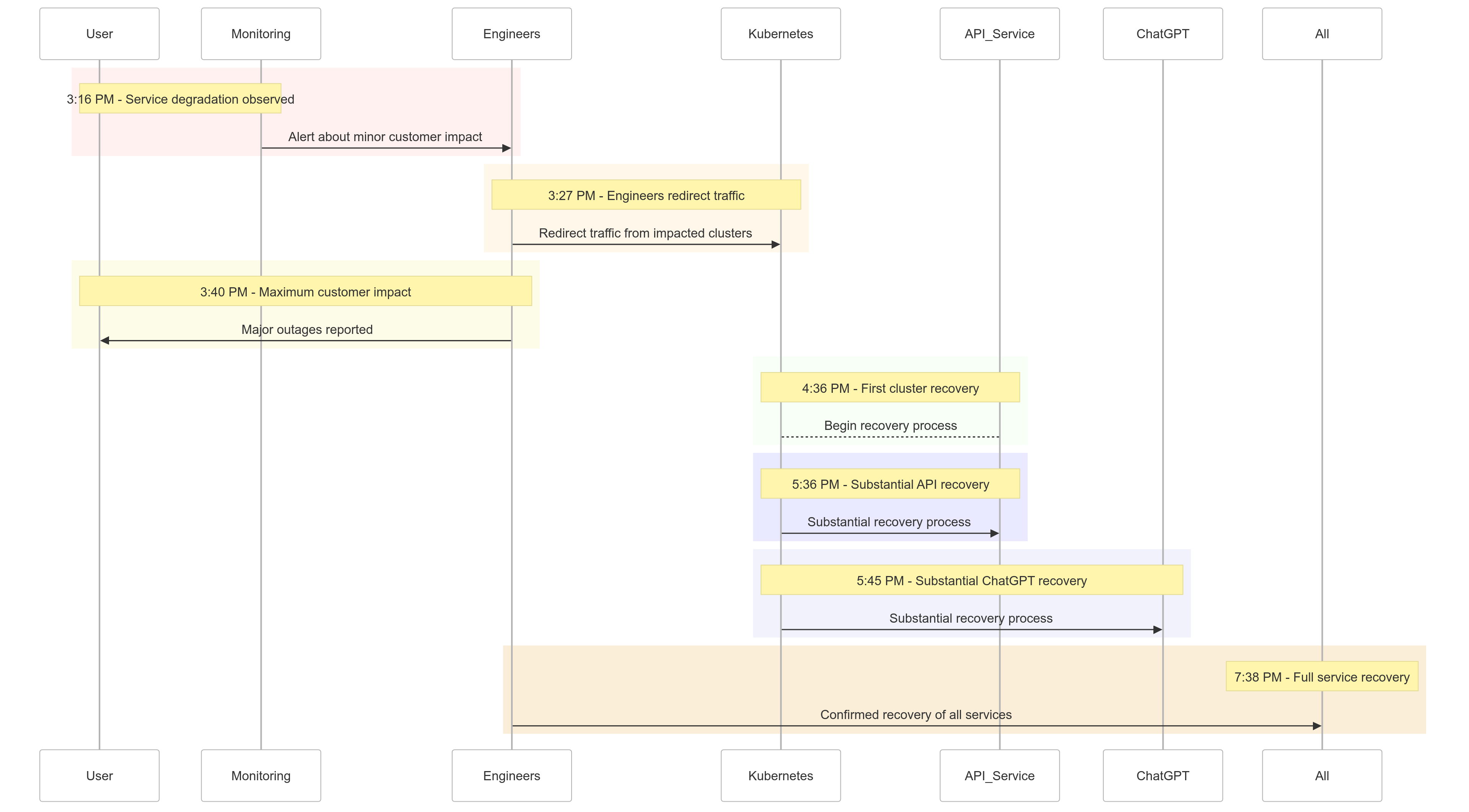
图1:OpenAI事件时间线 – 服务恶化到完全恢复。
根本原因分析
事件的根源在于下午3:12部署的新遥测服务,旨在改善Kubernetes控制平面的可观察性。这项服务意外地使多个集群中的Kubernetes API服务器不堪重负,导致级联故障。
详细分析
遥测服务部署
遥测服务旨在收集详细的Kubernetes控制平面指标,但其配置意外地触发了同时跨数千个节点的资源密集型Kubernetes API操作。
过载的控制平面
负责集群管理的Kubernetes控制平面变得不堪重负。虽然数据平面(处理用户请求)部分功能正常,但它依赖控制平面进行DNS解析。随着缓存的DNS记录过期,依赖实时DNS解析的服务开始失败。
不充分的测试
部署在演练环境中进行了测试,但演练集群未能反映生产集群的规模。因此,在测试期间未能检测到API服务器负载问题。
问题是如何缓解的
当事件发生时,OpenAI工程师迅速确定了根本原因,但面临挑战,因为超载的Kubernetes控制平面阻止了对API服务器的访问。采取了多管齐下的方法:
- 缩减集群规模: 降低每个集群中节点的数量降低了API服务器负载。
- 阻止对Kubernetes管理员API的网络访问:阻止了额外的API请求,使服务器恢复。
- 扩展Kubernetes API服务器:提供额外资源帮助清除待处理请求。
这些措施使工程师重新访问控制平面并移除问题遥测服务,恢复了服务功能。
汲取的教训
此事件凸显了分布式系统中强大测试、监控和故障安全机制的关键性。以下是OpenAI从此次故障中学到的(并实施的)内容:
1. 强大的分阶段部署
现在所有基础设施更改都将遵循分阶段部署并进行持续监控。这确保问题能够在扩展到整个系统之前被及早发现和缓解。
2. 故障注入测试
通过模拟故障(例如禁用控制平面或引入错误更改),OpenAI将验证他们的系统能够自动恢复并在影响客户之前检测到问题。
3. 紧急控制平面访问
“打破玻璃”机制将确保工程师即使在负载较重的情况下也能访问Kubernetes API服务器。
4. 控制平面和数据平面解耦
为了减少依赖关系,OpenAI将解耦处理工作负载的Kubernetes数据平面与负责编排的控制平面,确保关键服务即使在控制平面故障期间也能继续运行。
5. 更快的恢复机制
新的缓存和速率限制策略将改善集群启动时间,确保在故障期间更快地恢复。
示例代码:分阶段部署示例
以下是使用Helm和Prometheus进行可观察性的Kubernetes分阶段部署示例。
使用分阶段部署的Helm部署:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
用于监控API服务器负载的Prometheus查询:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
此查询有助于跟踪API服务器请求的响应时间,确保及早发现负载峰值。
故障注入示例
使用chaos-mesh,OpenAI可以模拟Kubernetes控制平面的故障。
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
此配置有意地终止API服务器Pod以验证系统的弹性。
这对您意味着什么
这一事件强调了设计弹性系统和采用严格测试方法的重要性。无论您是大规模管理分布式系统还是为工作负载实施 Kubernetes,以下是一些要点:
- 定期模拟故障:使用诸如 Chaos Mesh 的混沌工程工具在现实条件下测试系统的稳健性。
- 多层级监控: 确保您的可观察性架构同时跟踪服务级别指标和集群健康指标。
- 解耦关键依赖:减少对单点故障的依赖,例如基于 DNS 的服务发现。
结论
虽然没有系统能够完全免疫于故障,但像这样的事件提醒我们透明度、快速修复和持续学习的价值。OpenAI 主动分享这份事后分析,为其他组织改善运营实践和可靠性提供了蓝图。
通过优先考虑稳健的分阶段推出、故障注入测试和弹性系统设计,OpenAI 树立了如何处理和学习大规模故障的良好榜样。
对于管理分布式系统的团队而言,此事件是如何进行风险管理和最小化核心业务流程停机时间的一个优秀案例研究。
让我们借此机会共同建立更好、更具弹性的系统。
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident