













如果您将 Azure DevOps Pipeline 作为 CI/CD 流水线的解决方案,那么您无疑会遇到需要动态管理构建和发布中配置值的情况。无论是向 PowerShell 脚本提供构建版本,将动态参数传递给构建任务,还是在构建和发布之间使用字符串,您都需要变量。
如果您曾经问过自己以下问题:
- 如何在 PowerShell 脚本中使用 Azure DevOps 构建流水线变量?
- 如何在构建和发布之间共享变量?
- 预定义变量、用户定义变量和机密变量有何不同?
- 变量组是如何工作的?
…那么您很幸运!在本文中,我们将回答这些问题以及更多。
阅读完本文,您将了解 Azure DevOps 构建变量在 Azure Pipelines 中的工作原理!
Azure DevOps 流水线变量是什么?
在我们深入了解变量的具体内容之前,它们是什么,以及它们如何帮助您构建和自动化高效的构建和发布流水线?
变量允许您将数据块传递到流水线的各个部分。变量非常适合存储可能会在流水线工作流程中发生变化的文本和数字。在流水线中,您几乎可以在任何地方设置和读取变量,而不是在脚本和 YAML 定义中硬编码值。
注意:本文将仅关注YAML管道。我们将不涵盖任何关于传统经典管道的信息。此外,除了一些小的例外,您将不会学到如何通过Web UI处理变量。我们将严格遵循YAML。
变量在运行时被引用并且一些在运行时被定义(参见用户定义的变量)。当管道启动一个作业时,各种过程会管理这些变量并将它们的值传递给系统的其他部分。这个系统提供了一种在不担心每次更改构建定义和脚本的情况下动态运行管道作业的方法。
如果您目前还不理解变量的概念,不要担心。本文的其余部分将教会您一切您需要知道的。
变量环境
在深入了解变量本身之前,首先要重要的是了解Azure管道变量环境。您将在整篇文章中看到对这个术语的各种引用。
在管道中,有两个非正式称为环境的地方,您可以与变量交互。您可以在称为管道环境的YAML构建定义内部工作,也可以在通过任务执行的脚本内部工作,这称为脚本环境。
管道环境
当您在 YAML 构建定义中定义或读取构建变量时,这称为管道环境。例如,您可以在下面看到 YAML 构建定义中定义的 variables 部分,将一个名为 foo 的变量设置为 bar。在这种情况下,变量是在管道环境中定义的。
脚本环境
您还可以在 YAML 定义本身或脚本中定义的代码中使用变量。当您没有现有的脚本时,可以在 YAML 定义中定义和读取变量,如下所示。您将在稍后学习如何在这种情况下使用这些变量的语法。
您还可以通过将相同的语法添加到 Bash 脚本中并执行它来保持在脚本环境中。这是相同的一般概念。
环境变量
在脚本环境中,当管道变量可用时,通过创建一个环境变量来实现。然后可以通过所选语言的典型方法访问这些环境变量。
作为环境变量公开的管道变量将始终大写,并且任何点将被下划线替换。例如,您将看到下面如何每种脚本语言可以访问如下所示的 foo 管道变量。
- 批处理–
%FOO% - PowerShell–
$env:FOO - Bash脚本–
$FOO
管道“执行阶段”
当管道“运行”时,它不仅仅是“运行”。就像它包含的阶段一样,管道在执行时也经历各种阶段。由于Microsoft文档中缺乏官方术语,我将其称为“执行阶段”。
当触发管道时,它经历了三个大致的阶段–排队,编译和运行时。理解这些上下文很重要,因为如果你在Microsoft文档中导航,你会看到对这些术语的引用。
排队时间
管道触发时经历的第一个阶段是排队。在这个阶段中,管道尚未启动,但已排队准备好在代理可用时启动。在定义变量时,您可以通过不在YAML文件中定义它们来设置它们在排队时可用。
您可以在管道最初排队时定义变量的排队时间,如下所示。添加此变量后,它将作为管道中的全局变量提供,并且可以被YAML文件中相同变量名覆盖。
编译
最后,当流水线处理一个YAML文件并且到达需要执行脚本的步骤时,流水线处于编译“阶段”。在这种情况下,代理执行脚本步骤中定义的代码。
运行时
下一个阶段是运行时。这是处理YAML文件时的阶段。在此阶段,每个阶段、作业和步骤都在处理中,但不运行任何脚本。
变量扩展
另一个重要的主题是理解变量扩展。简单来说,变量扩展是指变量返回静态值的过程。变量扩展以显示其保存的值。当读取变量时,这会自动完成,但该扩展可能在流水线运行期间的不同时间完成,这可能会使您感到困惑。
当您开始理解变量语法时,编译与运行时的变量扩展概念会经常出现。
正如您上面所学的,流水线在运行时涵盖了不同的“阶段”。在排除变量扩展问题时,您可能需要了解这些阶段。
您可以在下面看到一个示例。这些“阶段”的概念与变量环境密切相关。
变量在管道运行启动时会展开一次,在每个步骤开始时再次展开。下面您可以看到这种行为的一个简单示例。
变量语法
正如您所学到的,您可以在两个“环境”中设置或读取变量——管道环境和脚本环境。在每个环境中,引用变量的方式略有不同。您需要注意一些微妙之处。
管道变量
管道变量在 YAML 构建定义中被引用,可以通过三种不同的语法方法引用——宏、模板表达式和运行时表达式。
宏语法
您最常见的语法是宏语法。宏语法引用一个变量的值,形式为 $(foo)。 括号表示一个在运行时计算的表达式。
当 Azure 管道处理定义为宏表达式的变量时,它将用变量的内容替换表达式。当使用宏语法定义变量时,它们遵循模式 <variable name>: $(<variable value>) 例如 foo: $(bar)。
如果您尝试使用宏语法引用一个变量,但值不存在,则该变量将简单地不存在。这种行为在语法类型之间有些不同。
模板表达式语法
另一种变量语法称为模板表达式。以这种方式定义管道变量的形式是${{ variables.foo }}:${{ variables.bar }}。正如您所看到的,这比宏语法稍微冗长。
模板表达式语法也有一个附加功能。使用此语法,您还可以展开模板参数。如果使用模板表达式语法定义了一个变量,并引用了它,管道将返回一个空字符串,而不是宏语法返回的空值。
模板表达式变量在编译时处理,然后在运行时被覆盖(如果已定义)。
运行时表达式语法
与语法类型一样,建议的运行时表达式变量仅在运行时展开。这些类型的变量通过格式$[variables.foo]表示。与模板表达式语法变量一样,如果未替换,这些类型的变量将返回一个空字符串。
与宏语法类似,运行时表达式语法要求在定义的左侧具有变量名称,如foo: $[variables.bar]。
脚本变量
在脚本内部处理变量与管道变量有所不同。在任务脚本中定义和引用暴露的管道变量可以通过日志命令语法或环境变量的方式之一完成。
日志命令
在脚本中定义和引用流水线变量的一种方法是使用日志命令语法。这种语法有点复杂,但您会发现在某些情况下是必要的。以这种方式定义的变量在脚本中必须被定义为字符串。
使用日志命令语法设置一个名为foo的变量,其值为bar,看起来像下面这样。
I could not find a way to get the value of variables using logging commands. If this exists, let me know!
环境变量
当流水线变量在脚本中转换为环境变量时,变量名称会略微改变。您会发现变量名称变成大写,并且句点变成下划线。许多预定义或系统变量中包含句点。
例如,如果定义了一个名为[foo.bar](<http://foo.bar>)的流水线变量,您可以通过脚本的本机环境变量引用方法引用该变量,如在PowerShell中使用$env:FOO_BAR或在Bash中使用$FOO_BAR。
我们在上面的脚本环境部分介绍了更多有关环境变量的内容。
变量范围
A pipeline has various stages, tasks and jobs running. Many areas have predefined variable scopes. A scope is namespace where when a variable is defined, its value can be referenced.
基本上有三个不同的变量范围层次。它们是在:
- 根级别定义的变量可用于流水线中的所有作业
- 阶段级别定义的变量可用于特定阶段
- 作业级别定义的变量可用于特定作业
变量在“低”级别定义,如作业,将覆盖在阶段和根级别定义的相同变量,例如。在阶段级别定义的变量将覆盖在“根”级别定义的变量,但会被在作业级别定义的变量覆盖。
下面是一个示例的YAML构建定义,其中使用了每个作用域。
变量优先级
有时您会看到一种情况,即在各种范围内设置了相同名称的变量。当发生这种情况时,该变量的值将根据特定顺序被覆盖,优先考虑最接近的“动作”。
下面您将看到变量将被覆盖的顺序,从在作业中设置的变量开始。这将具有最高的优先级。
- 在作业级别设置的变量(在YAML文件中设置)
- 在阶段级别设置的变量(在YAML文件中设置)
- 在流水线级别设置的变量(全局)(在YAML文件中设置)
- 在队列时间设置的变量
- 在流水线设置UI中设置的流水线变量
例如,看看下面的YAML定义。在这个示例中,同一个变量在许多不同的地方被设置,但最终以作业中定义的值结束。随着每个操作,变量的值被覆盖,管道进入作业。
变量类型
到目前为止,您已经了解了变量是什么,它们是什么样子,它们可以在哪些上下文中执行等等。但我们还没有涵盖的是,并非所有的变量都是相同的。一些变量在管道启动时已经存在,不能更改,而另一些则可以随意创建、更改和删除。
有四种一般类型的变量 – 预定义或系统变量,用户定义变量,输出变量和保密变量。让我们开始涵盖每一个并了解每种类型的变量。
预定义变量
在所有的构建和发布中,你会发现许多不同的默认变量。这些变量被称为预定义或系统变量。预定义变量都是只读的,并且像其他类型的变量一样,代表简单的字符串和数字。
一个Azure管道由许多组件组成,从执行构建的软件代理,到在部署运行时生成的作业,以及其他各种信息。为了表示所有这些领域,预定义或系统变量被非正式地分为五个不同的类别:
- 代理
- 构建
- 管道
- 部署工作
- 系统
每个类别都分散着数十个变量。您不会在本文中了解所有这些变量。如果您想要所有预定义变量的列表,请查看Microsoft文档。
用户定义变量
当您在YAML定义或通过脚本创建变量时,您正在创建一个用户定义的变量。用户定义的变量就是您,用户,在管道中定义和使用的所有变量。您可以为这些变量使用几乎任何名称,但有几个例外。
您不能定义以单词endpoint、input、secret或securefile开头的变量。这些标签是禁止使用的,因为它们为系统使用保留,并且不区分大小写。
此外,您定义的任何变量必须只包含字母、数字、点或下划线字符。如果您尝试定义不遵循此格式的变量,您的YAML构建定义将无法工作。
输出变量
A build definition contains one or more tasks. Sometimes a task sends a variable out to be made available to downstream steps and jobs within the same stage. These types of variables are called output variables.
输出变量用于在管道的各个组件之间共享信息。例如,如果一个任务从数据库查询一个值,而后续任务需要返回结果,则可以使用输出变量。然后,您就不必每次都查询数据库。相反,您可以简单地引用该变量。
注意:输出变量的作用域限定在特定阶段。例如,在“构建”阶段和“测试”阶段中不要期望将输出变量提供给您,
秘密变量
最后一种类型的变量是秘密变量。从技术上讲,这并不是它自己的独立类型,因为它可以是系统或用户定义的变量。但是秘密变量需要属于自己的类别,因为它们与其他变量的处理方式不同。
A secret variable is a standard variable that’s encrypted. Secret variables typically contain sensitive information like API keys, passwords, etc. These variables are encrypted at rest with a 2048-bit RSA key and are available on the agent for all tasks and scripts to use.
– 不要在您的 YAML 文件中定义秘密变量
– 不要将秘密作为输出变量或日志信息返回
秘密变量应该在流水线编辑器中定义。这将秘密变量的作用域限定在全局级别,从而使它们可以在流水线中的任务中使用。
日志中的秘密值是掩码处理的,但不是完全隐藏的。这就是为什么不应该将它们包含在 YAML 文件中的重要原因。您还应该知道不要将任何“结构化”数据作为秘密。例如,如果将{"foo": "bar"}设置为秘密,bar将不会从日志中被掩码。
秘密不会自动解密并映射到环境变量。如果您定义了一个秘密变量,请不要期望它通过
$env:FOO在 PowerShell 脚本中可用,例如。
变量组
最后,我们来看变量组。变量组,正如您可能期望的那样,是可以作为一个整体引用的一组变量。变量组的主要目的是存储您希望在多个流水线中提供的值。
不同于变量,变量组不是在 YAML 文件中定义的。相反,它们在 UI 中的 Library 页下的 Pipelines 下定义。
使用变量组来存储你想要控制并在多个流水线中使用的值。你也可以使用变量组来存储密码和其他可能需要传递到 YAML 流水线中的值。如下所示,变量组在 Library 页下的 Pipelines 中定义和管理。
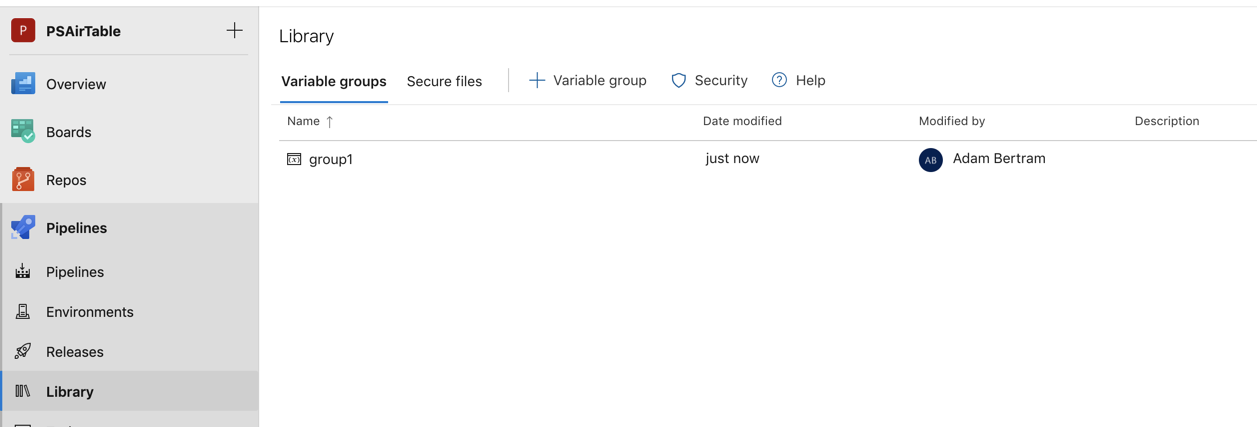
一旦在流水线库中定义,你可以使用以下语法在 YAML 文件中访问该变量组。
默认情况下,变量组不会自动对所有流水线可用。在创建组时会提供此设置。必须授权流水线使用变量组。
一旦在 YAML 文件中访问了变量组,你就可以像访问其他变量一样访问组内的变量。在引用组内变量时,不使用变量组的名称。
例如,如果你定义了一个名为 group1 的变量组,其中包含一个名为 foo 的变量,你可以像访问其他变量一样引用 foo 变量,如 $(foo)。
在变量组中定义的秘密变量不能直接通过脚本访问。相反,它们必须作为任务的参数传递。
如果对变量组内的变量进行更改,该更改将自动应用于所有被授权使用该组的流水线。
摘要
你现在应该对 Azure Pipelines 变量有了牢固的了解。在这篇文章中,你学到了与变量相关的几乎所有概念!现在,拿出你的知识,将其应用到你的 Azure DevOps Pipelines 中,自动化所有事情吧!
Source:
https://adamtheautomator.com/azure-devops-variables/